
阅读量:0
本文收录于专栏:精通AI实战千例专栏合集
https://blog.csdn.net/weixin_52908342/category_11863492.html 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。
每一个案例都附带关键代码,详细讲解供大家学习,希望可以帮到大家。正在不断更新中~
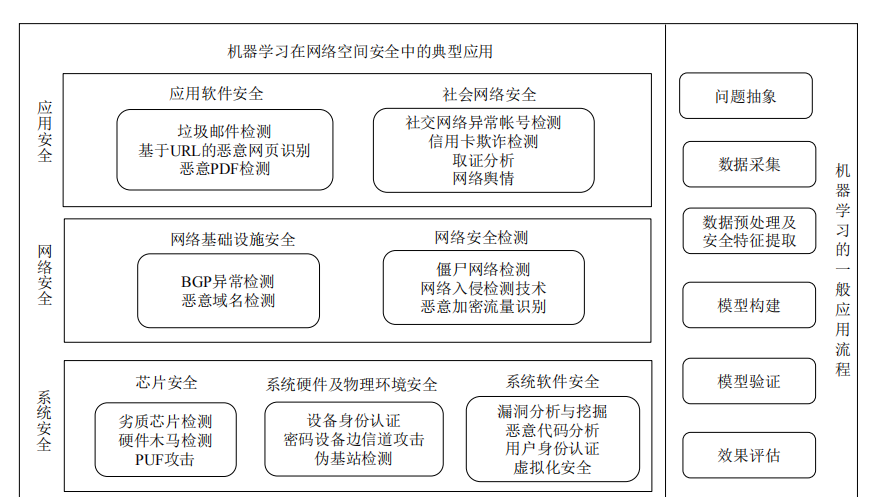
一.机器学习在网络安全中的应用:异常检测与防御
随着互联网的快速发展,网络安全已经成为了企业和个人必须要面对的重要挑战之一。网络攻击的形式层出不穷,从传统的病毒和恶意软件到更加复杂的网络入侵和数据泄露,网络安全人员需要不断地提高对抗这些威胁的能力。在这个背景下,利用机器学习技术进行网络异常检测和安全防御成为了一种有效的方法。
机器学习在网络安全中的价值
传统的网络安全防御方法往往依赖于规则和模式的匹配,但这种方法很难应对日益复杂的网络攻击手段。相比之下,机器学习通过从大量的数据中学习模式和特征,可以更好地识别和预测各种类型的网络异常和攻击。具体来说,机器学习在网络安全中的应用主要体现在以下几个方面:
异常检测: 通过监控网络流量、系统日志等数据,机器学习模型可以识别出与正常行为不符的异常行为,如异常的数据包、异常的登录行为等。
威胁情报分析: 机器学习可以帮助分析大量的威胁情报数据,识别出潜在的威胁和攻击者,以及他们可能采取的攻击手段和目标。
行为分析: 通过分析用户和设备的行为模式,机器学习可以识别出异常的行为,如未经授权的访问、异常的数据传输等。
恶意代码检测: 机器学习可以分析软件代码的特征,识别出潜在的恶意代码,并及时进行阻止和清除。
示例代码:基于机器学习的网络异常检测
下面是一个简单的示例,演示了如何使用Python中的Scikit-learn库实现基于支持向量机(SVM)的网络异常检测模型。
import numpy as np from sklearn import svm from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 准备数据集,假设X是特征,y是标签(0表示正常,1表示异常) X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]]) y = np.array([0, 0, 1, 1, 1]) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 构建支持向量机模型 clf = svm.SVC(kernel='linear') # 在训练集上训练模型 clf.fit(X_train, y_train) # 在测试集上进行预测 y_pred = clf.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) 在实际应用中,我们需要根据具体的网络数据和业务场景进行特征工程和模型调优,以获得更好的检测性能。
进阶示例:基于深度学习的网络异常检测
除了传统的机器学习方法,深度学习在网络异常检测中也展现出了强大的能力。下面是一个使用深度学习技术(具体是基于自编码器)进行网络异常检测的示例代码:
import numpy as np import tensorflow as tf from sklearn.model_selection import train_test_split # 准备数据集,假设X是特征,y是标签(0表示正常,1表示异常) X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]]) y = np.array([0, 0, 1, 1, 1]) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 构建自编码器模型 input_dim = X_train.shape[1] encoding_dim = 2 # 编码维度,可以根据实际情况调整 input_layer = tf.keras.layers.Input(shape=(input_dim,)) encoder = tf.keras.layers.Dense(encoding_dim, activation='relu')(input_layer) decoder = tf.keras.layers.Dense(input_dim, activation='relu')(encoder) autoencoder = tf.keras.models.Model(inputs=input_layer, outputs=decoder) autoencoder.compile(optimizer='adam', loss='mse') # 在训练集上训练自编码器模型 autoencoder.fit(X_train, X_train, epochs=50, batch_size=32, shuffle=True, validation_data=(X_test, X_test)) # 在测试集上进行预测 reconstructed_X = autoencoder.predict(X_test) # 计算重构误差 mse = np.mean(np.power(X_test - reconstructed_X, 2), axis=1) threshold = np.mean(mse) + 2 * np.std(mse) # 设置阈值,超过阈值的样本被认为是异常 # 根据阈值判断样本是否异常 predictions = (mse > threshold).astype(int) print("Predictions:", predictions) 这个示例中,我们使用了一个简单的自编码器模型来对网络数据进行重构,然后计算重构误差,超过一定阈值的样本被认为是异常。实际应用中,我们可以根据具体的网络数据和业务场景调整模型结构和参数,以获得更好的检测性能。
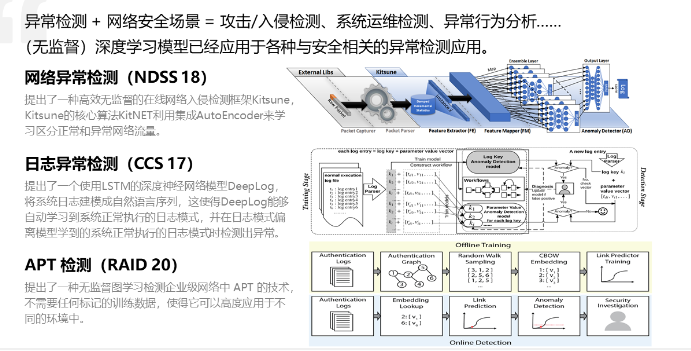
高级示例:使用卷积神经网络进行网络异常检测
卷积神经网络(CNN)在图像处理中取得了巨大成功,但它们也可以用于序列数据的处理,包括网络流量数据。下面是一个示例代码,演示了如何使用CNN对网络流量数据进行异常检测:
import numpy as np import tensorflow as tf from sklearn.model_selection import train_test_split # 准备数据集,假设X是网络流量数据,y是标签(0表示正常,1表示异常) X = np.random.rand(1000, 100, 1) # 假设有1000个样本,每个样本包含100个时间步的网络流量数据 y = np.random.randint(2, size=1000) # 随机生成标签 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 构建卷积神经网络模型 model = tf.keras.Sequential([ tf.keras.layers.Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(100, 1)), tf.keras.layers.MaxPooling1D(pool_size=2), tf.keras.layers.Conv1D(filters=32, kernel_size=3, activation='relu'), tf.keras.layers.MaxPooling1D(pool_size=2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # 在训练集上训练模型 model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test)) # 在测试集上评估模型 loss, accuracy = model.evaluate(X_test, y_test) print("Test Loss:", loss) print("Test Accuracy:", accuracy) 这个示例中,我们使用了一个简单的卷积神经网络模型来处理网络流量数据,通过学习数据中的特征来进行异常检测。实际应用中,我们可以根据具体的网络数据和业务场景调整模型结构和参数,以获得更好的性能。
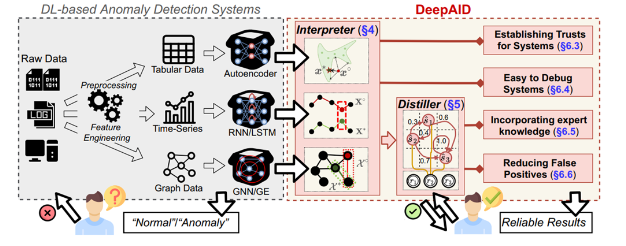
模型解释性与可解释性
尽管深度学习在网络异常检测中展现了出色的性能,但其模型通常被认为是黑盒模型,缺乏解释性和可解释性。这意味着虽然我们可以通过这些模型来做出预测,但很难理解模型是如何做出这些预测的。在网络安全领域,模型的解释性和可解释性对于理解网络攻击和调整防御策略至关重要。
下面是一个使用LIME(Local Interpretable Model-agnostic Explanations)库来解释深度学习模型的示例代码:
import lime import lime.lime_tabular from lime import lime_text from lime import lime_image # 假设model是我们之前训练的深度学习模型 # 定义解释器 explainer = lime.lime_tabular.LimeTabularExplainer(X_train, mode="classification", feature_names=['feature1', 'feature2']) # 选择一个样本进行解释 sample_idx = 0 sample = X_test[sample_idx] # 解释模型预测结果 explanation = explainer.explain_instance(sample, model.predict, num_features=2) # 打印解释结果 explanation.show_in_notebook() 这个示例中,我们使用LIME库来解释深度学习模型对一个样本的预测结果。LIME通过在输入空间中生成局部可解释模型,来解释模型在特定样本上的行为。通过这种方式,我们可以理解模型对于不同样本的预测是基于哪些特征,并且可以更好地理解模型的决策过程。
模型解释性与可解释性的重要性
尽管深度学习模型在网络异常检测中取得了令人瞩目的成就,但其模型解释性和可解释性仍然是一个挑战。解释模型的预测结果对于理解网络攻击、调整防御策略以及提高用户和组织的信任至关重要。因此,在未来的研究中,我们需要不断地探索新的方法和技术,来提高深度学习模型的解释性和可解释性,并使其更加适用于网络安全领域。

如何提高模型解释性和可解释性
使用可解释模型: 在某些情况下,可以使用更简单、更可解释的模型来替代复杂的深度学习模型,如决策树、逻辑回归等。这些模型通常具有较好的解释性,可以直观地理解其决策过程。
特征选择和特征工程: 在构建深度学习模型时,可以通过特征选择和特征工程的方法来选择最相关的特征,并且对特征进行合理的转换和处理,以提高模型的可解释性。
模型解释技术: 使用专门的模型解释技术,如LIME、SHAP等,来解释深度学习模型的预测结果。这些技术通过在输入空间中生成局部可解释模型,来解释模型在特定样本上的行为,从而提高模型的可解释性。
可视化技术: 使用可视化技术来展示模型的决策过程和重要特征,如特征重要性图、决策树可视化等。通过直观地展示模型的行为,可以帮助用户更好地理解模型的预测结果。
用户参与和反馈: 在模型设计和应用过程中,积极引入用户参与和反馈,了解用户对于模型预测结果的理解和认可程度,从而进一步改进模型的解释性和可解释性。
通过以上方法和技术的应用,我们可以更好地提高深度学习模型在网络异常检测中的解释性和可解释性,从而为网络安全领域的应用提供更加可信赖和可理解的解决方案。
总结
在本文中,我们探讨了利用机器学习技术进行网络异常检测与安全防御的重要性和方法。首先介绍了机器学习在网络安全领域的应用,包括异常检测、威胁情报分析、行为分析和恶意代码检测等方面。接着,通过示例代码展示了基于传统机器学习方法、深度学习方法和卷积神经网络的网络异常检测模型。我们讨论了深度学习模型的优势和挑战,并重点关注了模型解释性和可解释性在网络安全中的重要性。最后,提出了提高模型解释性和可解释性的方法和技术,并强调了用户参与和反馈在此过程中的重要性。通过不断地研究和实践,我们可以进一步提高网络安全的防御能力,保护用户和组织的信息安全。
