
阅读量:0
1. 引言
癌症是一种异常细胞不受控制地分裂损害健康组织的疾病。皮肤或覆盖我们内脏的组织中的癌细胞被称为癌。乳房中的大多数癌是导管癌。侵袭性导管癌(Invasive Ductal Carcinoma, IDC)始于乳管,侵犯乳房周围纤维组织,晚期可通过血液扩散至淋巴结或身体其他部位,威胁患者生命。这种恶性肿瘤的治疗取决于它的分期、严重程度和它所属的亚型。事实证明,早期诊断有助于减少治疗过程中的并发症,从而提高患者的生存几率。
IDC癌的诊断可基于病理任务,包括显微镜观察和多片载玻片检查。但是这种测试方法既耗时又容易出错。因此,为了辅助测试过程,可以采用计算机辅助诊断(CAD)测试方案,主要涉及基于深度学习(DL)的方法。对组织病理学图像进行图像分析是鉴别和识别癌症亚型的一种有效方法。
组织病理学图像是在特定放大倍数(x10, x20或x40)下染色活检样本的WSI数字化扫描。研究了IDC阳性病例的组织病理切片图像。深度学习模型可以根据从组织病理学图像中提取的代表乳腺癌组织成分的特征来学习对阳性样本进行分类。本文中,提出了一种由基于ResNet的特征提取器组成的深度学习模型,该模型可以有效地提取组织特征,分类器头部使用这些特征对IDC组织病理图像样本进行准确分类。
1.1 机器学习(ML)方案
预处理的重要性:ML算法通常需要在预处理后的数据集上进行训练。预处理的方式和性质对ML模型的性能有重要影响。
线性回归与ANN:Turgay等人[8]比较了线性回归和人工神经网络(ANN)在癌症样本分类中的应用。
SVM与图像增强:M.A.Awasthy等人[9]提出了一种基于支持向量机(SVM)的模型,其中使用图像增强技术对组织病理学图像进行增强,并通过分割在预处理步骤中提取关键特征。这些特征随后被输入到分类器中。通过分割进行特征提取的预处理步骤有助于提高模型性能,与其他ML模型(如KNN和ANN)相比。
Catboost模型:S.D.Roy等人[10]提出了一种Catboost模型,该模型在通过堆叠各种文本特征并应用皮尔逊相关性而提取的782个特征上进行训练时,取得了高准确性。
1.2 深度学习(DL)方案
大数据集与计算成本:组织病理学图像数据集通常非常大,预处理这样的数据集是一个计算成本高昂的任务。
CNN的应用:为了应对这一挑战,基于DL的模型发挥了显著作用,因为它们即使在基本预处理后也能表现出色。卷积神经网络(CNN)因其从空间相邻特征中学习的能力而成为医学图像处理应用领域中最有效的模型之一。
CNN架构:A.C. Roa等人[11]提出了一种具有3层CNN架构的模型,该模型在考虑到数据巨大规模的情况下,对样本图像进行了16:1的缩小训练。
残差网络:C. C. Chatterjee等人[12]提出了一种具有4个残差块的残差网络,每个残差块由2D卷积层构成。该模型的限制是它从未在整个数据集上进行训练,而是仅在数据集的一个子集(即代表性数据集)上进行了实施。
3. 提出的方法
带有跳跃连接的残差网络作为最优解决方案,尽管神经网络的维数很大,但跳跃连接传播损失却没有太大的退化。跳跃连接通过在卷积层之间具有中间连接来促进输出层和输入层之间的梯度流动。
3.1 数据集预处理
由于IDC数据集的规模非常大,直接在整个数据集上训练模型是一项计算密集型的任务。这意味着训练过程可能需要很长时间,并且需要强大的计算资源。为了解决这个问题,研究者们选择了使用k-fold交叉验证的方法来训练和优化模型。这种方法将数据集分成k个部分(或“折”),然后多次进行训练和测试,每次使用不同的折作为训练集和测试集。
在特定的例子中,数据集被分为9折,其中7折用于训练数据集,2折用于测试训练好的模型。这样,每个样本都有机会被用作测试集的一部分,这有助于更准确地评估模型的性能。测试集由数据集的2折组成,总共包含大约59,462个样本。这意味着训练集和测试集之间的比例大约是80:20,用于在机器学习项目中评估模型的性能。
每个折中IDC正样本(即存在浸润性导管癌的样本)和IDC负样本(即不存在浸润性导管癌的样本)的比例是不均等的,这导致数据分布出现偏斜。这种不平衡的数据分布可能会挑战模型的学习能力和性能,因为模型可能更偏向于预测数量更多的类别(在这种情况下是IDC负样本)。
为了解决样本不平衡的问题,研究者们采取了一种称为“随机采样”的策略。随机选择IDC负样本以形成一个新的样本集,这个新样本集中的IDC负样本数量与IDC正样本数量相同。通过这样做,每个折的IDC正样本和IDC负样本数量变得相等,从而解决了数据分布不平衡的问题。
3.2 模型开发
残差网络是由多层卷积网络通过跳跃连接相互连接而成的。对于特征提取,使用一个预训练的CNN编码器ResNet152。ResNet152返回一个具有2048个特征的特征向量。这些提取的特征被输入到全连接层以生成输出。
1)预训练特征提取器:ResNet是一个由多个CNN层组成的深度学习模型。残差学习的概念形成了联系。考虑需要学习的映射为H(x),当拟合多个非线性层时,模型F(x)学习到的映射可以定义为:
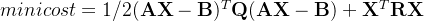
x是模型没有学习到的残差。因此,原始映射可以推导为:
ResNet152架构
由152个CNN层堆叠并通过跳跃连接连接。
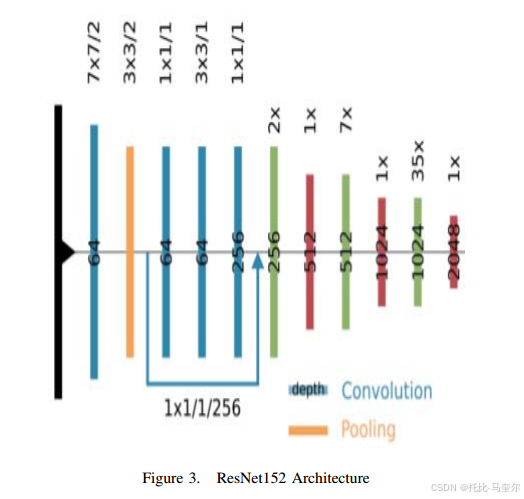
利用预训练的ResNet152模型从组织病理学图像中提取重要特征。从组织病理学图像中提取特征是预训练模型的下游任务。利用或嵌入预训练模型作为下游任务整体架构的组成部分的方法称为迁移学习。使用Imagenet分类任务训练后更新的最优权值从组织病理图像中提取特征,用于IDC分类下游任务。
2)分类器头(Classifier head):从残差网络中提取的特征作为全连接层的输入,最终的Time分布致密层作为分类器头,通过预测给定样本的类概率来进行二值分类。
3)激活函数:激活函数在输出中引入非线性,使非凸状态变为凸,从而使凸函数的优化(通过梯度下降)变得可行。
4. 实验结果
数据集被划分为 k 是一个整数。训练集由k-m 折数据,而测试集包含了剩下的 m 折数据。
对于训练集中的每一折
当模型对所有训练折都进行了训练后,最终优化后的权重将被用于在测试集的所有折上进行验证。如果测试集包含多折数据(即
实验设置
实验使用了Keras框架来实现提出的模型架构。优化器选择了Adam,学习率设置为0.001。损失函数是二元交叉熵损失函数。性能评估指标考虑了准确率、召回率和AUC。
