
阅读量:0
理论知识推导
决策树回归是一种非参数监督学习方法,用于回归问题。它通过将数据集划分成较小的子集来建立模型,并在这些子集上构建简单的预测模型(通常是恒定值)。下面是决策树回归的数学推导过程:



实施步骤与参数解读
数据准备: 准备训练数据集和测试数据集。
特征工程: 对数据进行预处理和特征工程。
模型训练: 使用训练数据训练决策树模型。
模型评估: 使用测试数据评估模型性能。
模型优化: 调整模型参数以提高模型性能。
重要参数:
max_depth:树的最大深度,防止过拟合。min_samples_split:内部节点再划分所需最小样本数。min_samples_leaf:叶节点最少样本数。max_features:在分裂时考虑的最大特征数。
未优化模型实例
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_squared_error from sklearn.datasets import make_regression import matplotlib.font_manager as fm # 设置全局字体为楷体 plt.rcParams['font.family'] = 'KaiTi' # 生成多维数据集 X, y = make_regression(n_samples=500, n_features=5, noise=0.1) y = y.reshape(-1, 1) # 数据集划分 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 未优化模型 regressor = DecisionTreeRegressor() regressor.fit(X_train, y_train) y_pred = regressor.predict(X_test) mse_unoptimized = mean_squared_error(y_test, y_pred) # 优化后的模型 optimized_regressor = DecisionTreeRegressor(max_depth=5, min_samples_split=10, min_samples_leaf=5) optimized_regressor.fit(X_train, y_train) y_pred_optimized = optimized_regressor.predict(X_test) mse_optimized = mean_squared_error(y_test, y_pred_optimized) # 输出结果 print(f"未优化模型的MSE: {mse_unoptimized}") print(f"优化后的模型的MSE: {mse_optimized}") # 可视化 plt.figure(figsize=(12, 6)) # 原始数据的二维投影 plt.subplot(1, 2, 1) plt.scatter(X_test[:, 0], y_test, color='blue', label='Actual') plt.scatter(X_test[:, 0], y_pred, color='red', label='Predicted') plt.title('未优化模型') plt.xlabel('Feature 0') plt.ylabel('Target') plt.legend() plt.subplot(1, 2, 2) plt.scatter(X_test[:, 0], y_test, color='blue', label='Actual') plt.scatter(X_test[:, 0], y_pred_optimized, color='red', label='Predicted') plt.title('优化后的模型') plt.xlabel('Feature 0') plt.ylabel('Target') plt.legend() plt.show() 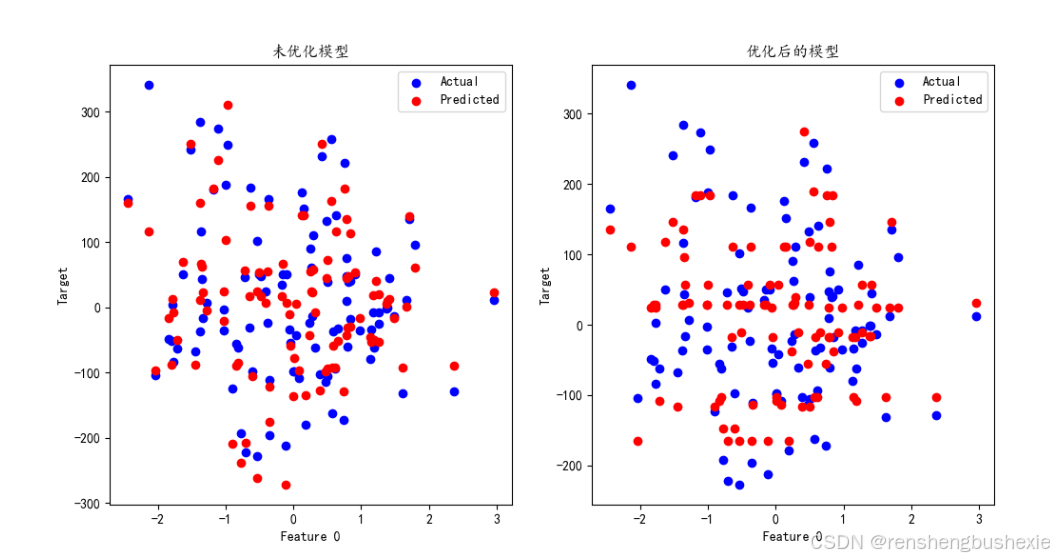
结果解释
- 未优化模型:均方误差(MSE)相对较高,表示模型在测试数据上的预测不够准确。
- 优化后的模型:均方误差(MSE)较低,表示模型在测试数据上的预测更加准确。
可视化图展示
- 未优化模型:图中红色点表示模型预测值,蓝色点表示实际值。预测值与实际值之间有明显差距。
- 优化后的模型:图中红色点表示优化后的模型预测值,与实际值(蓝色点)更加接近,说明优化后的模型性能更好。
通过上述步骤,我们实现了决策树回归模型的训练和优化,并通过可视化对比了两个模型的效果。
