阅读量:0
1. 引言
乳腺癌主要有两种类型:原位癌:原位癌是非常早期的癌症,开始在乳管中扩散,但没有扩散到乳房组织的其他部分。这也称为导管原位癌(DCIS)。浸润性乳腺癌:浸润性乳腺癌已经扩散(侵入)到周围的乳腺组织。侵袭性癌症比原位癌更难治愈。将乳汁输送到乳晕的管道是大多数乳房生长开始的地方(导管癌)。
在本文中,使用了一组浸润性导管癌(Invasive Ductal Carcinoma, IDC)数据集,它是一种非常常见的癌症类型,比原位癌具有更高的致死性。肿瘤分级是一种常用的疾病侵袭性评估,用于检查浸润性癌症。首先提取乳腺组织的组织病理学斑块特征,在侵入性和非侵入性之间进行类似的兴趣区域匹配,然后进行其分化。各种分级方案对肿瘤分化进行进一步检查,这涉及到病理学家的监督,这可能是劳动密集型的。正确识别恶性肿瘤区域是一项具有挑战性的工作和耗时的工作。
乳腺癌筛查是通过医生的临床评估和乳房x光摄影或超声成像来完成的。若筛查结果提示有恶性组织生长的可能,则进行体检筛查后再进行乳腺组织活检以最终诊断。活检方法包括收集细胞样本,在显微镜下观察并固定,然后标记。活检的优点是病理学家可以通过组织显微结构的可视化来进行高度准确的诊断。
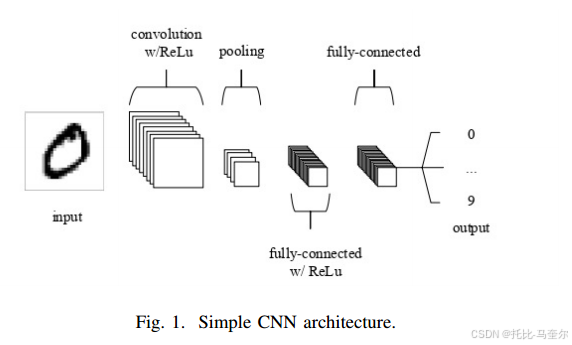
使用CNN作为特征提取网络。CNN是卷积神经网络(convolutional neural networks)的缩写,它在图像patch上使用卷积函数,并使用滤波器来提取图像的特征。卷积操作之后通常是规范化和激活函数,它们堆叠在一起创建具有多层卷积网络的大型体系结构。批处理归一化层尝试将图像像素转换为0到1的范围。网络体系结构中使用的激活函数等待触发特定值,然后通过它传递该值。
2. 文献综述
数据集:使用了名为BreaKH的数据集,包含7909张图像,这些图像来自82位患者的良性和恶性乳腺肿瘤信息。数据集包含2480张良性图像和5429张恶性图像,这些图像通过40倍、100倍、200倍和400倍的放大因子获得。
图像预处理:对所有图像进行了旋转,并向原始数据集中添加了随机图像失真。通过数据增强,数据集的大小增加到11,184张图像,其中3504张是良性的,7680张是恶性的。
模型:使用基于迁移学习的方法开发的模型,结合了inception v3和传统CNN模型。在500个训练步骤后,获得了0.89的训练准确度。
性能:恶性类别的曲线下面积(AUC)为0.93,良性类别的AUC也为0.93,截断值为0.4。
截断值通常指的是用于修正异常值的界值,即将超出正常区间的数据设为正常区间的最大值或最小值。这样做的好处是可以有效地去除异常值对数据分析的干扰,提高分析结果的精确度和可靠性。
数据集:使用了两个数据集来比较传统CNN模型的性能。其中一个数据集是乳腺组织病理图像数据集,包含277,524张大小为50x50的RGB图像,其中90,000张图像用于分析,其中65,279张属于类别‘0’,24,781张属于类别‘1’。另一个数据集是乳腺组织学图像数据集,包含5547张图像,其中2788张是IDC(浸润性导管癌),2759张是非IDC。
模型:用于该研究的模型包括LeNet、AlexNet、VGG 19、VGG 16、ResNet 50、SVM和Twin SVM。
训练数据:从乳腺组织学图像数据集中选择了4437张图像作为训练数据。
使用胶囊网络(Capsule Network)来识别和分类癌细胞:
病理图像预处理:首先,对病理图像进行了预处理,包括图像恢复、亮度调整等,以改善图像质量,提高后续分析的准确性。基于图像属性的分割:根据图像的某些属性(如颜色、纹理等)对图像进行分割,将图像中的不同区域(如正常组织、癌细胞等)区分开来。对象定位:通过像素分组的方法,定位图像中的感兴趣对象(如癌细胞)。分类:将处理后的图像分类为四种类型:正常组织、原位癌、良性病变和浸润性癌。
GLCM用于区分正常与异常肿瘤细胞
GLCM(灰度共生矩阵):一种用于描述图像中灰度级空间分布关系的矩阵。这里,它被用来区分正常和异常的肿瘤细胞。模糊值转换:利用模糊化方法将癌细胞转换为模糊值。模糊化是通过使用如年龄、评分等成员函数来完成的。函数选择:该研究使用了三角形和梯形函数来进行计算。基于知识库的特征提取:使用已知样本的知识库来获取特征。这些特征是基于已知样本的属性和模式来确定的。分类器应用:将经过模糊化和特征提取的图像数据输入到胶囊网络分类器中,以获取癌细胞的类型和阶段。分类数据共享:将最终分类的数据与研究人员共享,以便进行进一步的评估和研究。
3. 方法
3.1 数据集
数据类型与数量:
研究使用了浸润性导管癌(IDC)的组织病理学图像,包括癌症(IDC +ve,即IDC阳性)和非癌症(IDC -ve,即IDC阴性)的样本。总共有277,524个大小为50x50的图像块(patches),其中198,738个是IDC阴性(非癌症),78,786个是IDC阳性(癌症)。
目标类别:
IDC阴性和IDC阳性是研究的两个目标类别,需要预测图像块是否属于这两个类别之一。IDC阴性(非癌症)被标记为类别0,IDC阳性(癌症)被标记为类别1。
数据集不平衡:
数据集显示非癌症的图像块数量超过癌症图像块的两倍。
图像块与标签:
每个图像块都与一个患者ID相关联。图像块的标签由专业医生标记为IDC阳性(癌症)或IDC阴性(非癌症)。
图像大小调整:
原始图像块的大小是50x50,但在研究中被重新调整为70x70。
数据集划分:
为了训练和测试,数据集被随机分割。不是使用完整的数据集,而是从277,524个图像块中随机抽取了157,572个。这些50x50的图像块被重新调整为70x70的大小。其中75%的数据用于训练,即118,179个图像块是训练样本;25%的数据用于测试,即39,393个图像块是测试样本。
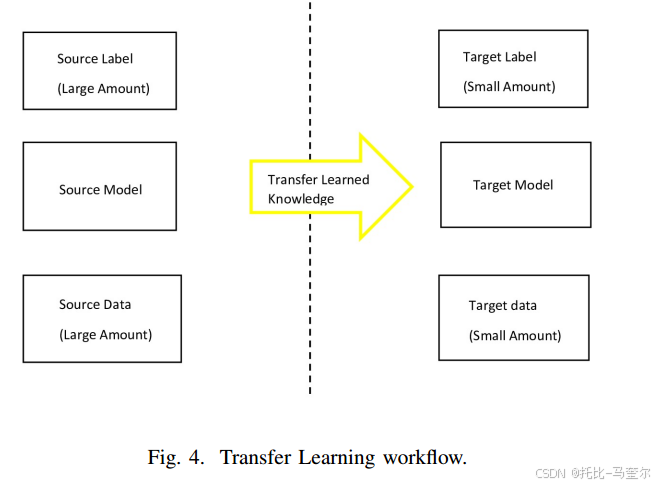
3.2 迁移学习
使用预训练的系统模型被称为机器学习中的迁移学习,其中知识(特征,权重等)从先前的模型转移到新模型中以增加其预测。
CNN模型在解决与图像分类、图像识别、物体检测增强现实等相关的现实问题方面发挥了重要作用。最常见的是效率网、densenet、MobileNet和Resnet。为了解决更具挑战性的计算机视觉问题,在CNN模型中添加更多的层可能是一种选择。但它也有自己的一系列问题,因为训练神经网络的任务可能很繁琐,增加的附加层也会影响性能衡量。
MobileNet是CNN的一个类。它使用深度可分离卷积。主要用于移动应用程序。与常规网络卷积相比,深度可分离卷积减少了参数的数量。DenseNet是卷积神经结构,也被称为密集连接卷积网络。在这种情况下,前一层的所有输出都作为下一层的输入。EfficientNet 使用复合系数均匀地缩放所有分辨率/宽度/深度维度。复合缩放方法的前提是,随着输入图像变大,网络需要额外的层来增加接受野,需要更多的通道来捕获更大图像上的更细粒度的模式。
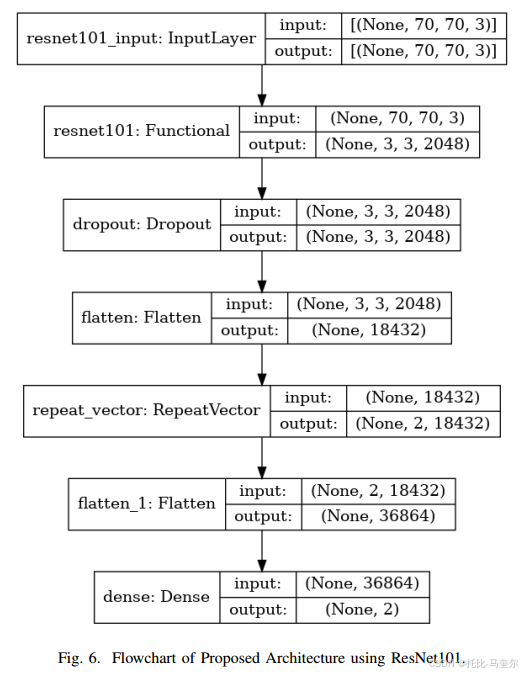
3.3 模型