
阅读量:0
OrangePi AIpro 浅上手
OrangePi AIpro 介绍
开发版介绍
OrangePi AIpro是香橙派联合华为精心打造的一款高算力人工智能开发板。作为业界首款基于昇腾深度研发的AI开发板,它先后荣获2023昇腾APN最佳产品奖以及Powered by Ascend甑选解决方案最佳硬件产品奖,可以用于图片识别、语音识别,微生物识别等等,从而广泛应用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理等人工智能领域。
硬件规格
以下是Orange PI AIPro的硬件规格,以表格形式展示:
| 规格项 | 详细信息 |
|---|---|
| 处理器 | 4核64位ARM处理器,默认预留1个给AI处理器使用 |
| AI处理器 | 集成华为昇腾310B,半精度(FP16)算力:4 TFLOPS,整数精度(INT8)算力:8 TOPS |
| 内存 | LPDDR4X,容量可选:8GB或16GB,速率:3200Mbps |
| 存储 | - SPI FLASH:32MB - Micro SD卡插槽 - eMMC插座:可外接eMMC模块,容量可选:32GB/64GB/128GB/256GB(eMMC5.1 HS400) - M.2 M-Key接口:支持2280规格的NVMe SSD或SATA SSD |
| 网络 | - 以太网:10/100/1000Mbps自适应RJ45口,板载PHY芯片:RTL8211F - Wi-Fi:2.4G和5G双频,BT4.2(模组:欧智通6221BUUC) |
| USB | - USB 3.0 Host接口:2个 - USB Type-C接口:1个(只支持USB3.0,不支持USB2.0) - Micro USB接口:1个(调试串口) |
| 显示 | - HDMI接口:2个,支持同时4K@60HZ输出 - MIPI DSI 2 Lane接口:1个,支持外接显示屏 |
| 音频 | - 3.5mm耳机孔:支持音频输入输出 - HDMI音频输出:2个 |
| 摄像头 | 2个MIPI CSI 2 Lane接口 |
| 扩展接口 | 40PIN扩展口,支持UART、I2C、SPI、PWM、GPIO等 |
| 按键 | 1个复位键,1个关机键,2个启动方式拨动键(BOOT1/BOOT2),1个烧录按键 |
| LED灯 | 1个电源指示灯,1个软件可控指示灯 |
| 风扇接口 | 4PIN接口,0.8mm间距,12V供电,支持PWM调速 |
| 电池接口 | 2PIN接口,2.54mm间距,用于接3串电池,支持快充 |
| 电源 | Type-C供电,支持20V PD-65W适配器 |
| 支持的操作系统 | Ubuntu 22.04、openEuler 22.03 |
| 外观规格 | - 产品尺寸:107*68mm - 重量:82g |
顶层视图和底层视图


接口详情图
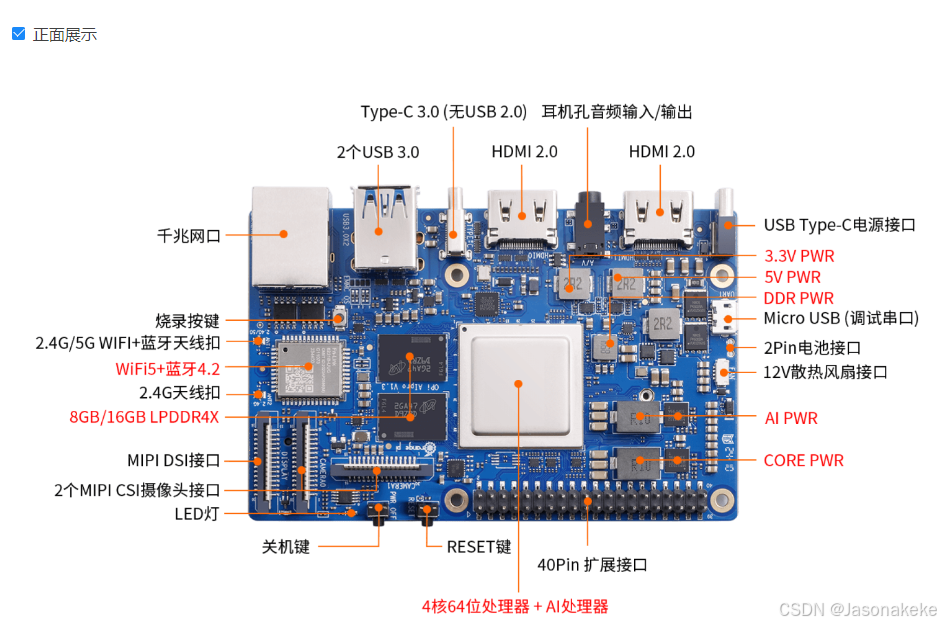
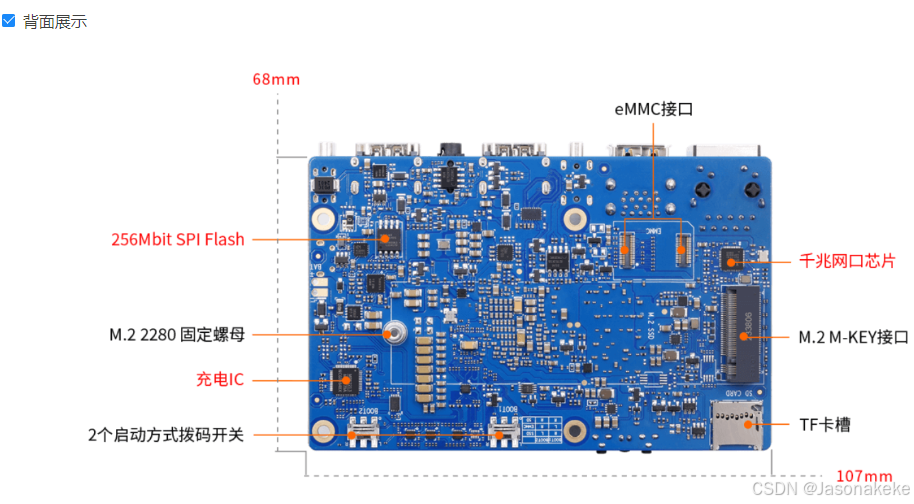
玩转 OrangePi AIPro
烧录镜像
拿到板子后,如果SD卡里面是空卡,没有镜像,那么需要给卡烧录镜像,具体可以参考下用户手册的对应章节,建议使用 balenaEtcher-Portable-1.18.4.exe 工具来完成烧录。
备选烧录工具:https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas 200I DK A2/DevKit/tools/latest/Ascend-devkit-imager_latest_win-x86_64.exe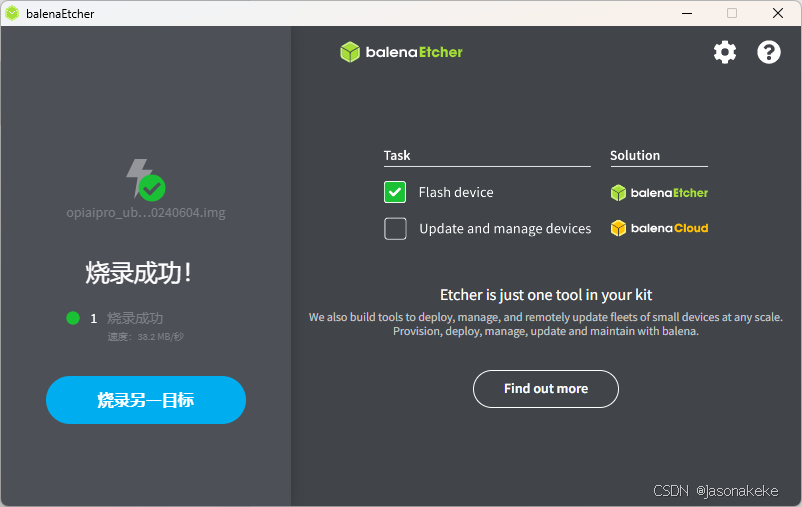
烧录完成,便开启串口调试
串口调试
开发板支持从TF卡、eMMC和SSD(支持NVMeSSD和SATASSD)启动。具体从哪个设备启动是由开发板背面的两个拨码(BOOT1和BOOT2)开关来控制的2
把两个拨码开关拨至 TF 启动方式即可
另外请注意,切换拨码开关后必须重新拔插电源上下电才能让新的启动设备选项生效。通过开发板的复位按键来复位系统是不会让拨码开关新设置的配置生效的
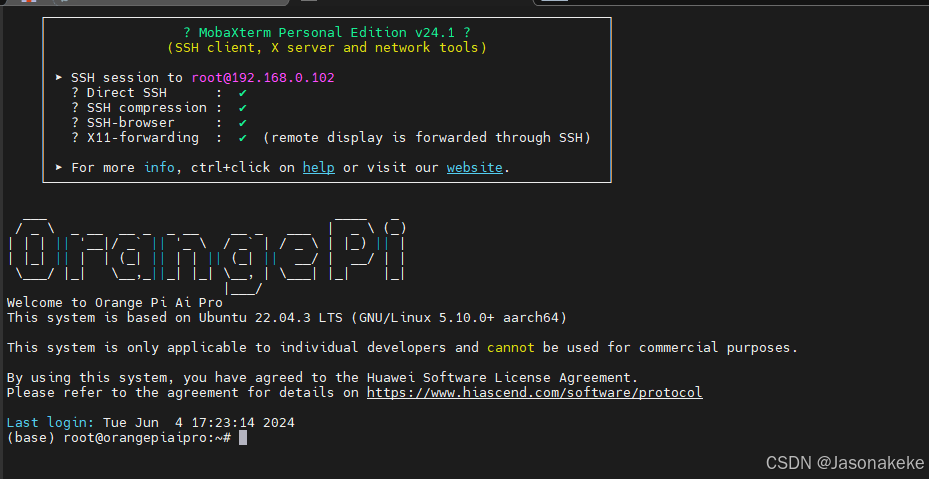
打开 MObalxterm,选择 Serial 连接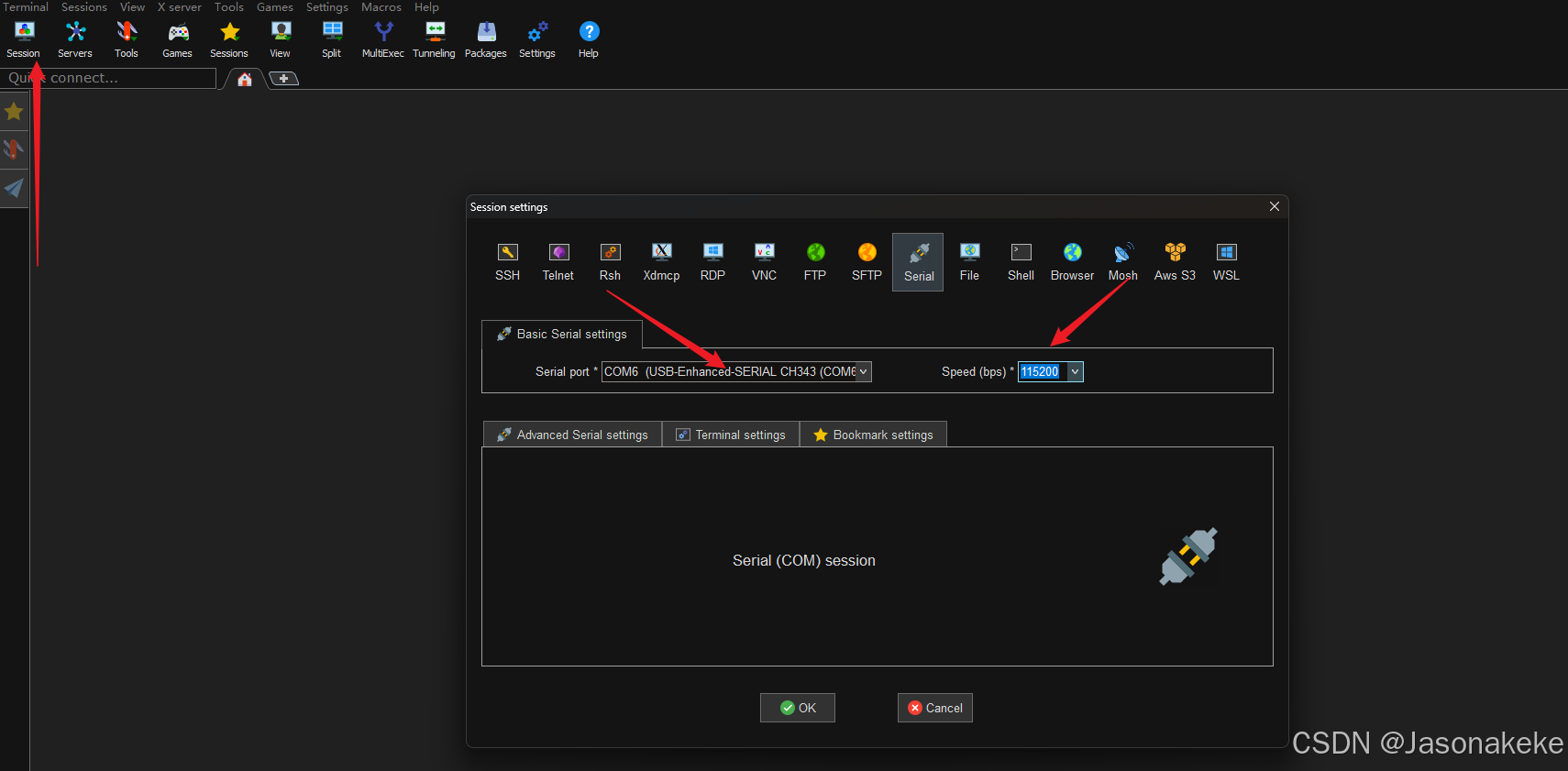
重新插拔电源,出现下列 log
[ 5.566301] ntfs3: Max link count 4000 NOTICE: Int ID:174, syscnt:0x29455dd0 NOTICE: intNum 174, nodeStatus1 0x40 ! NOTICE: [RasCbbCommonHandler]:[71L] moduleBase c1260000 NOTICE: [RasCbbCommonHandler]:[81] UE NOTICE: [Module] MATA0 NOTICE: [FillHisiModuleErrorInfo]:[275L] moduleID = 0x14 NOTICE: [Module] MATA0 NOTICE: SubSysID:0xff, DeviceID:0x0, SubSysNum:0x0 NOTICE: RECOVERABLE! NOTICE: HestNotifiedOS NOTICE: [RasCbbCommonHandler]:[89] Handler end NOTICE: base = 0xc1260000 NOTICE: ERR_FRL = 0x142aa2 NOTICE: ERR_FRH = 0x0 NOTICE: ERR_CTRLL = 0x515 NOTICE: ERR_CTRLH = 0x0 NOTICE: ERR_STATUSL = 0xfc30050e NOTICE: ERR_STATUSH = 0x0 NOTICE: ERR_ADDRL = 0x10080010 NOTICE: ERR_ADDRH = 0xe0000001 NOTICE: ERR_MISC0L = 0x0 NOTICE: ERR_MISC0H = 0x0 NOTICE: ERR_MISC1L = 0xe798005 NOTICE: ERR_MISC1H = 0x800122 NOTICE: el3_int exit! cpu 0 entering scheduler >>>>>>>>>>>>LiteOS start succeed!<<<<<<<<<<< Ubuntu 22.04.3 LTS orangepiaipro ttyAMA0 orangepiaipro login: 
连接 WiFi
用下列命令查看WiFi
nmcli dev wifi 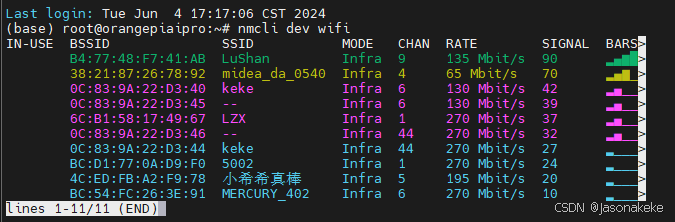
连接 WiFi
其中 ap-name是 WiFi 名称, ap-password 是 WiFi 密码
sudo nmcli dev wifi connect ap-name password ap-password 
ping 一下 百度
查看 ip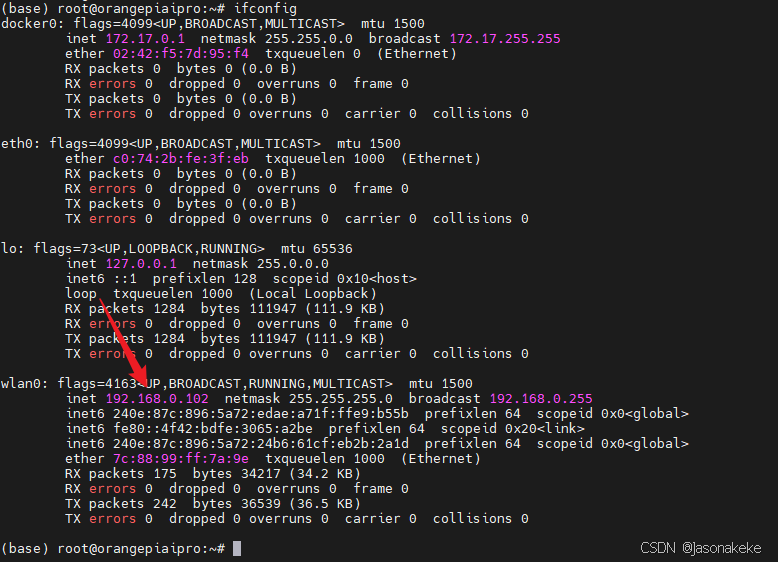
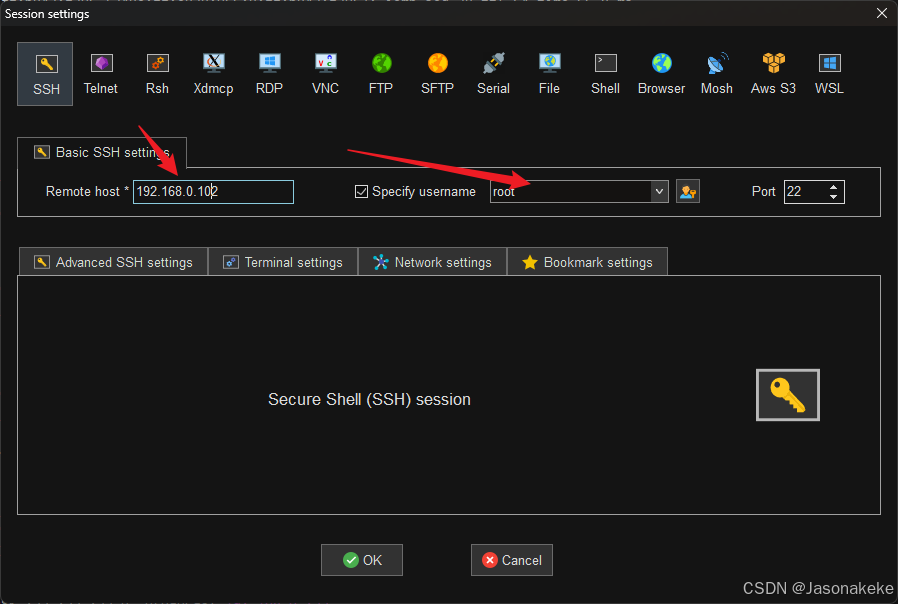
ssh 连接
部署 yolov5
介绍
YOLOv5是一种目标检测算法,它是YOLO(You Only Look Once)系列算法的最新版本。以下是对YOLOv5的详细介绍:
基本概念
YOLOv5继承了YOLO系列算法的核心思想,即将目标检测任务视为一个回归问题,通过卷积神经网络直接预测目标的边界框和类别概率。该算法以其高速和高精度的特点,在实时目标检测任务中表现出色。
网络结构
YOLOv5采用了新的架构,主要包括以下几个部分:
- 主干网络:基于CSPNet(Cross Stage Partial Network)设计,如CSPDarknet53,用于提取图像特征。
- 颈部网络:如PANet(Path Aggregation Network),用于进一步融合不同层次的特征信息。
- 检测头:用于生成最终的检测结果,包括目标的边界框和类别概率。
技术特点
- 多尺度训练:通过在不同尺寸的图像上进行训练,提高模型对不同尺度目标的检测能力。
- 数据增强:采用多种数据增强技术,如Mosaic数据增强,增加训练数据的多样性和鲁棒性。
- 网络混合精度训练:支持混合精度训练,可以在保证精度的同时提高训练速度。
- 自适应锚框:根据训练数据自动调整锚框尺寸,提高边界框的预测精度。
应用场景
YOLOv5支持多种类型的目标检测任务,如物体检测、人脸检测、车辆检测等,可以应用于各种实际场景,如:
- 智能安防:在人流密集的地区,如机场、火车站和购物中心等场所,用于监控安全和人流统计。
- 自动驾驶:检测和识别道路上的车辆、行人等目标,为自动驾驶系统提供重要信息。
- 机器人视觉:在机器人导航、物体抓取等任务中,用于识别和定位目标物体。
- 动物识别:通过训练模型来识别不同种类的动物,如狗、猫、鸟等。
- 水果识别:检测和识别不同种类的水果,如苹果、香蕉、橙子等。
- 垃圾分类:识别不同类别的垃圾,如可回收垃圾、有害垃圾、湿垃圾等。
性能评估
性能评估是了解模型精度、召回率、速度等指标的重要手段。YOLOv5的性能评估指标包括:
- 精度(Precision):模型正确预测的正类别目标数量与总预测正类别目标数量的比率。
- 召回率(Recall):模型正确预测的正类别目标数量与总正类别目标数量的比率。
- F1分数:精度和召回率的调和平均值,用于综合评估模型性能。
- 平均精度(mAP):用于多类别目标检测的评估指标,计算每个类别的精度并取平均值。
代码实现与训练
YOLOv5的代码实现基于PyTorch深度学习框架,提供了训练和推理的功能。在使用YOLOv5进行目标检测之前,需要准备训练数据,并选择适合的模型进行训练。YOLOv5提供了多种模型大小供选择,如yolov5s、yolov5m、yolov5l和yolov5x等,并提供了预训练的模型和开源代码,方便开发者进行模型的训练和应用。
总的来说,YOLOv5以其高效、准确的特点,在目标检测领域得到了广泛的应用和认可。
步骤
安装必要的依赖项
sudo apt-get update sudo apt-get install -y build-essential cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev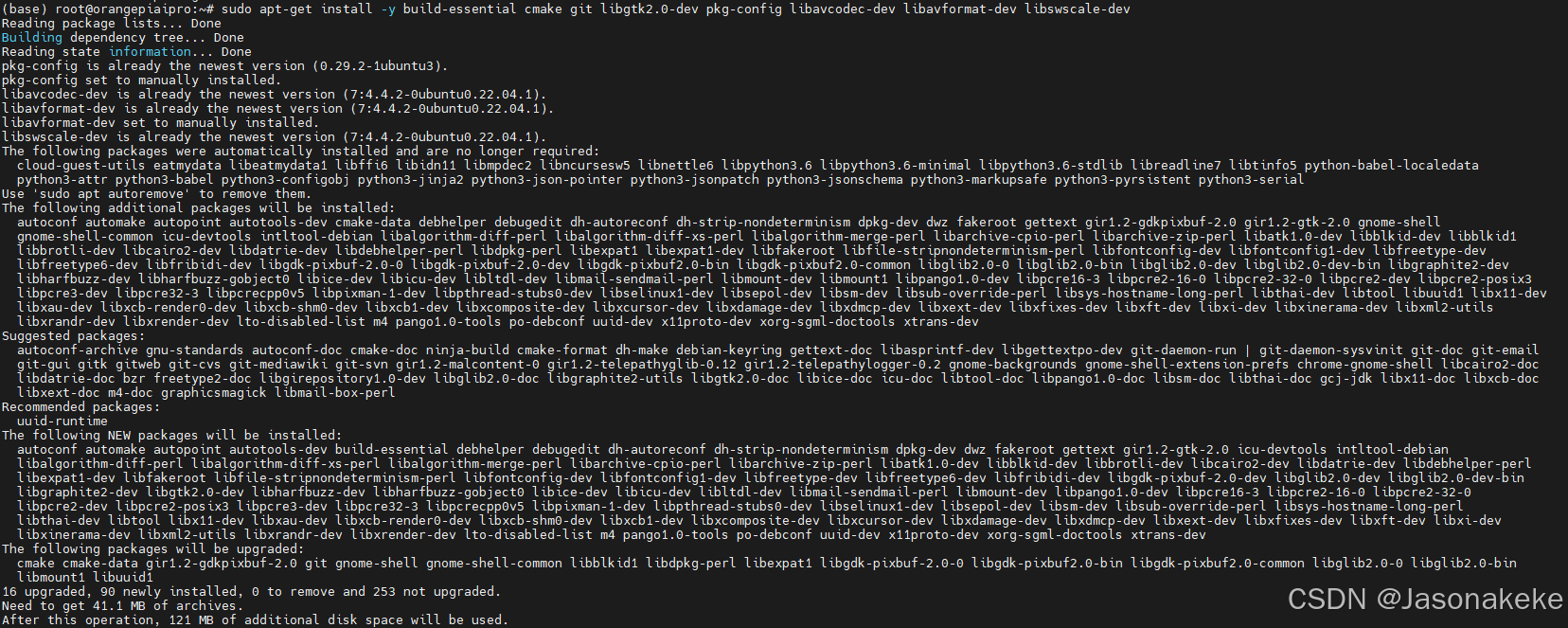
安装 OpenCV
sudo apt-get install -y python3-opencv
下载 YOLO 源码并编译
git clone https://github.com/pjreddie/darknet.git cd darknet make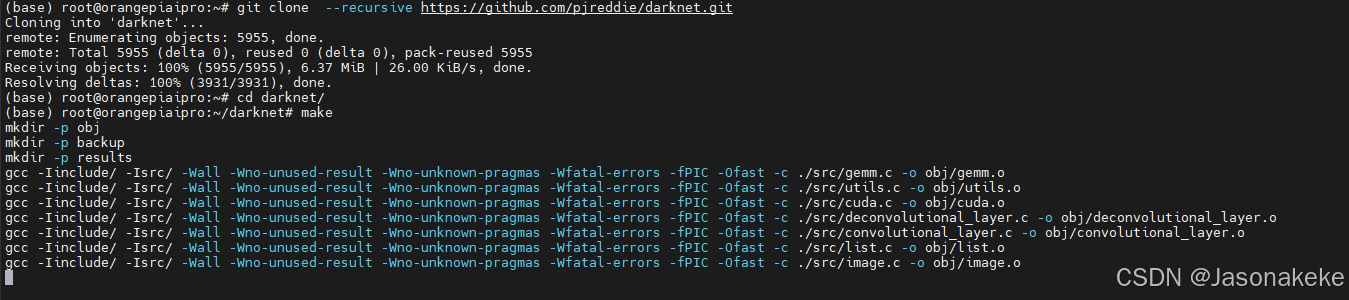
下载预训练权重文件
wget https://pjreddie.com/media/files/yolov3.weights
运行 YOLO检索图
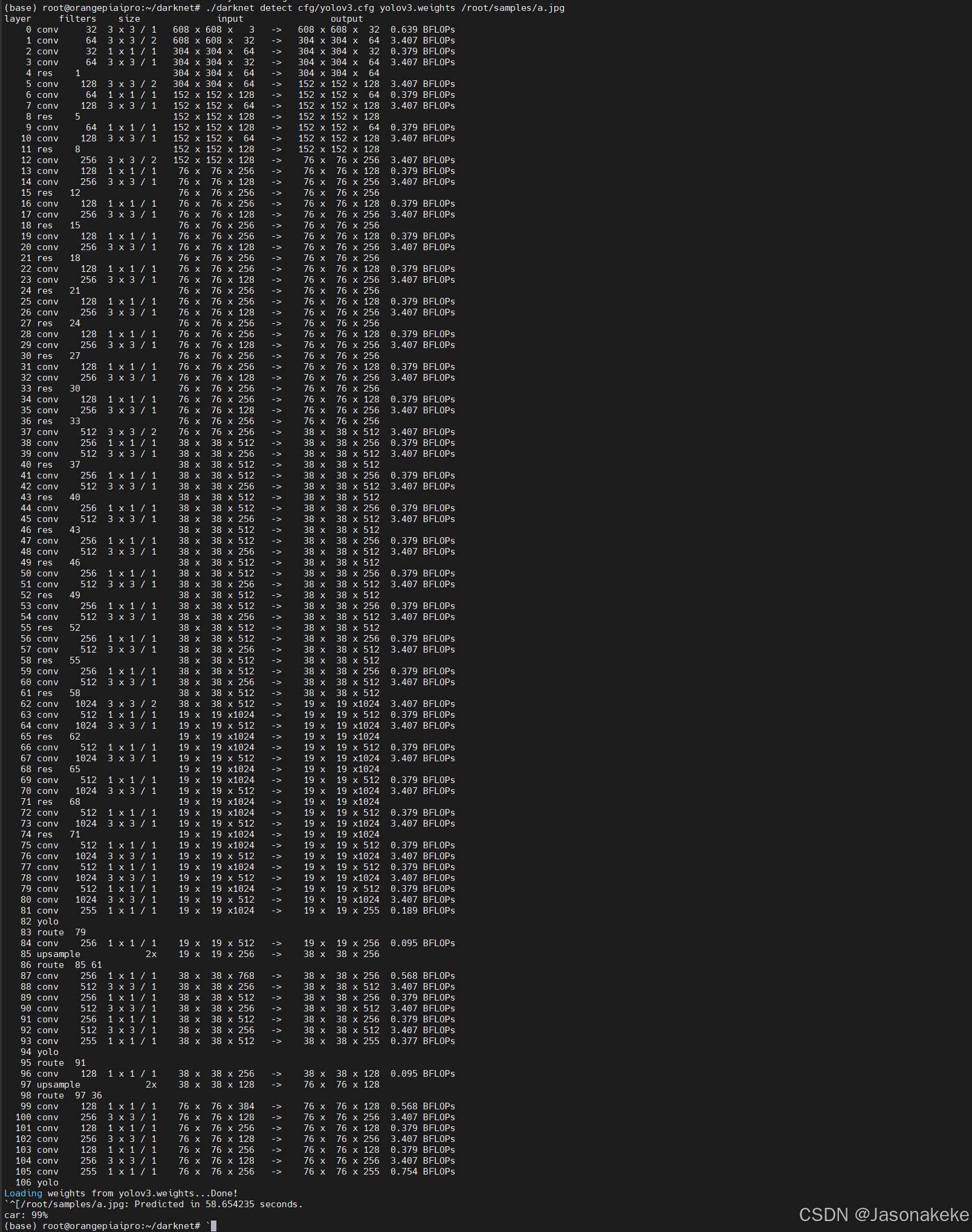
接下来来编写一个程序体验一下yolov3的物体检测功能吧
创建一个demo1.py文件夹用于存放代码
vi demo1.py import cv2 import numpy as np # 加载网络和配置 net = cv2.dnn.readNet("yolov3.weights", "cfg/yolov3.cfg") classes = [] with open("data/coco.names", "r") as f: classes = [line.strip() for line in f.readlines()] # 加载图片 img = cv2.imread("1.jpg") img = cv2.resize(img, None, fx=0.4, fy=0.4) height, width, channels = img.shape # 检测 blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False) net.setInput(blob) outs = net.forward(net.getUnconnectedOutLayersNames()) # 显示信息 class_ids = [] confidences = [] boxes = [] for out in outs: for detect in out: scores = detect[5:] class_id = np.argmax(scores) confidence = scores[class_id] if confidence > 0.5: # Object detected center_x = int(detect[0] * width) center_y = int(detect[1] * height) w = int(detect[2] * width) h = int(detect[3] * height) # Rectangle coordinates x = int(center_x - w / 2) y = int(center_y - h / 2) boxes.append([x, y, w, h]) confidences.append(float(confidence)) class_ids.append(class_id) # NMS indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4) # Draw bounding boxes for i in range(len(boxes)): if i in indexes: x, y, w, h = boxes[i] label = str(classes[class_ids[i]]) color = (0, 255, 0) cv2.rectangle(img, (x, y), (x + w, y + h), color, 2) cv2.putText(img, label, (x, y + 30), cv2.FONT_HERSHEY_PLAIN, 1, color, 2) # 保存图片 cv2.imwrite("predictions_output.jpg", img) 找到合适的图片后来运行一下程序
因为这个程序是pyhton程序,所以在运行之前需要确保在开发板的环境中是有python的
这里我已经提前安装好了pyhton3
运行之前需要给程序权限
chmod 777 demo1.py python demo1.py 
使用感受
优点:
高性能:Orange PI AI-Pro 通常搭载高性能的处理器(如RK3399 Pro等),能够处理复杂的计算任务,适合用于深度学习模型的推理和训练(虽然训练大型模型可能仍需依赖云端服务器)。
丰富的接口:该开发板提供了丰富的输入输出接口,包括USB、HDMI、Ethernet、GPIO等,方便连接各种传感器、显示器、摄像头等设备,满足不同应用场景的需求。
开源友好:Orange PI 社区活跃,拥有大量的开源资源、教程和案例,对于初学者来说,入门门槛相对较低。同时,由于支持多种操作系统(如Ubuntu、Debian等),用户可以根据自己的喜好和需求选择合适的系统。
价格优势:与一些高端的人工智能开发板相比,Orange PI AI-Pro 的价格相对亲民,使得更多的开发者能够接触到并参与到人工智能的实践中来。
缺点或需注意的点:
文档和社区支持:虽然Orange PI 社区活跃,但相对于一些主流的开发板(如Raspberry Pi),其文档和社区支持可能还不够完善,尤其是在遇到一些特定问题时,可能需要更多的自行探索和解决。
功耗和散热:高性能往往伴随着较高的功耗和发热量,因此在使用时需要注意散热问题,避免长时间高负载运行导致设备过热。
软件兼容性:由于不同版本的开发板可能在硬件配置和固件版本上存在差异,因此在使用某些软件或库时可能会遇到兼容性问题。此外,对于深度学习等特定领域的应用,可能需要安装额外的软件环境和依赖库。
学习曲线:对于初学者来说,从零基础开始学习人工智能和边缘计算相关知识并熟练掌握Orange PI AI-Pro 的使用可能需要一定的时间和努力。
下载速度:仅仅提供百度网盘一种下载渠道,而百度网盘是最慢的
总的来说,Orange PI AI-Pro 是一款性价比较高的边缘计算和人工智能开发板,适合对人工智能和物联网技术感兴趣的开发者进行学习和实践。然而,在使用过程中也需要注意上述问题,并适时寻求社区和专业的帮助。
