阅读量:0
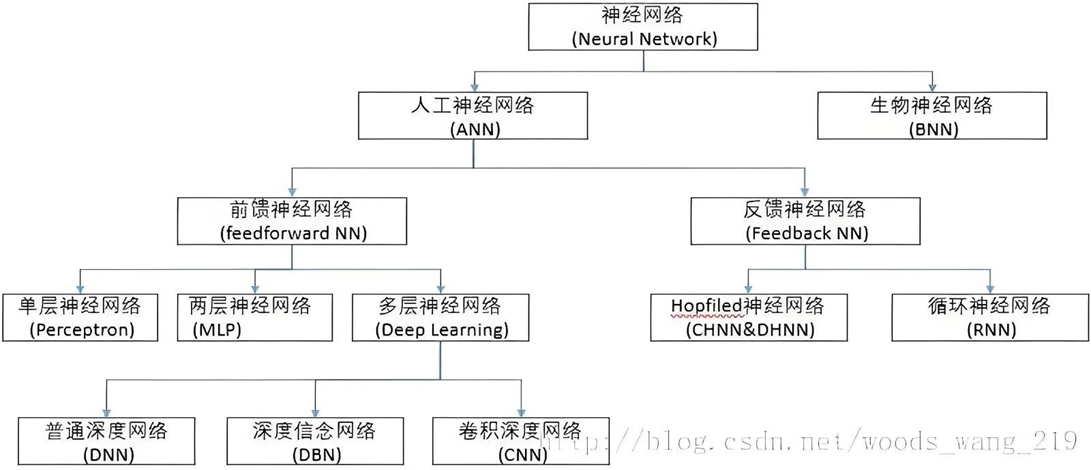
神经网络
概述
本章主要介绍人工神经网络的基本概念,以及几种重要模型,包括“单层感知机、两层感知机、多层感知机”等。
在此基础上,介绍两种重要的基础神经网络“Hopfield神经网络、BP神经网络”。
最后,着重介绍了深度学习中最常用的“卷积神经网络”。
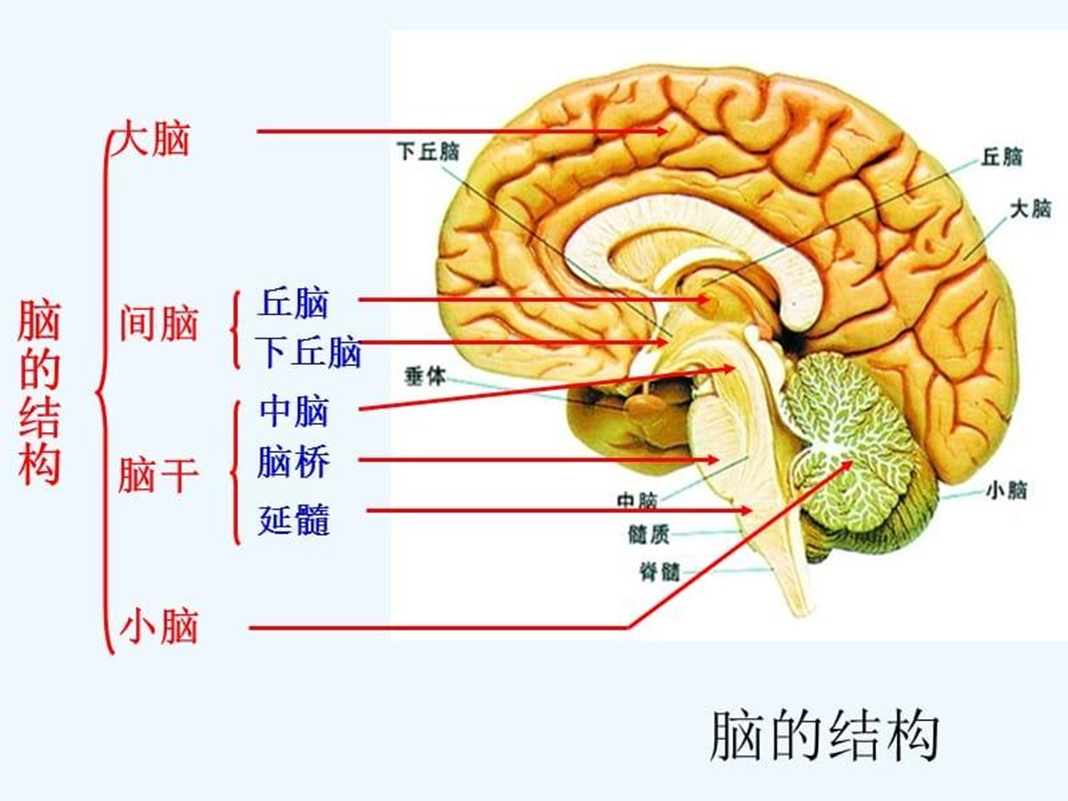
人脑结构
人脑由一千多亿(1011亿-1014 亿)个神经细胞(神经元)交织在一起的网状结构组成,其中大脑皮层约140亿个神经元,小脑皮层约1000亿个神经元。
人脑构造
- 大脑-皮层(cortex)
- 中脑(midbrain)
- 脑干(brainstem)
- 小脑(cerebellum)
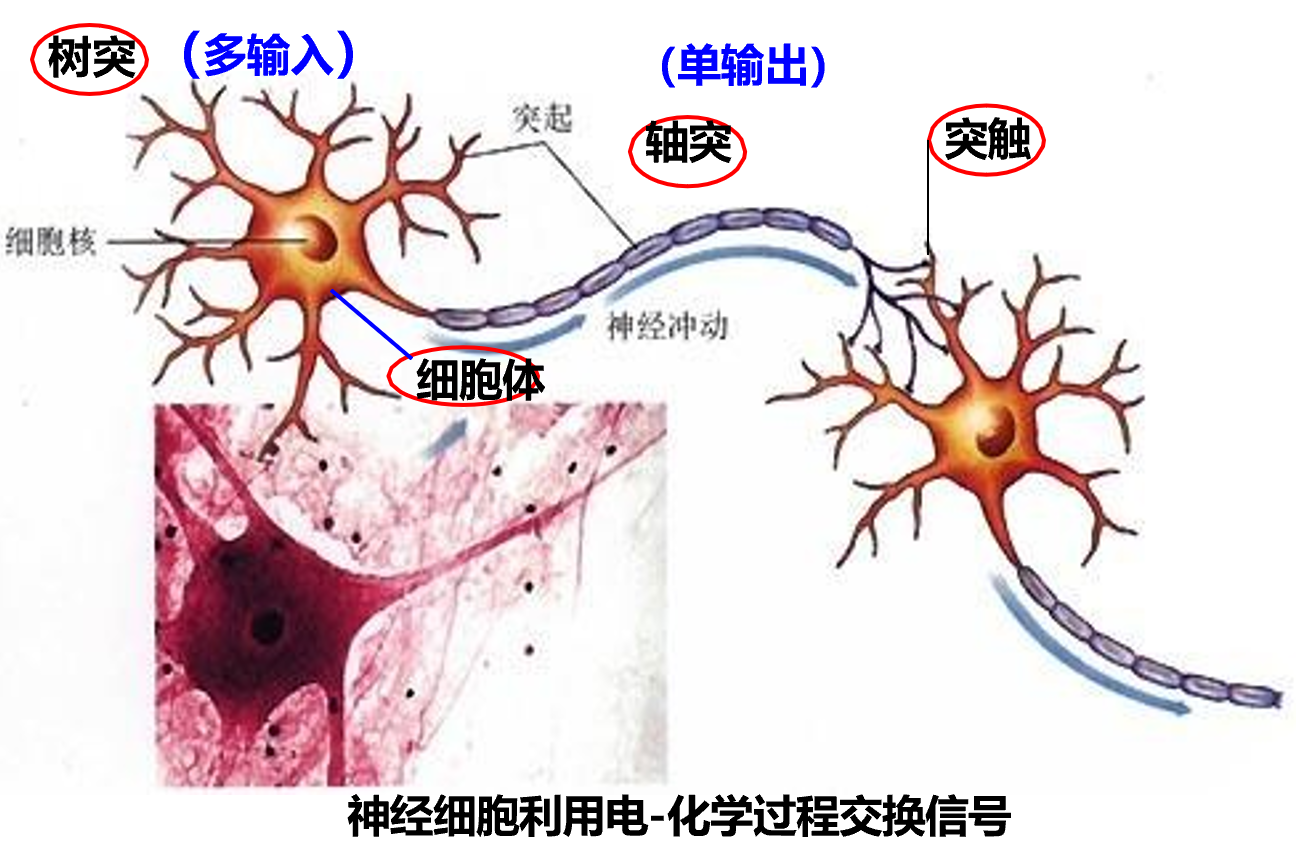
人脑神经元结构
人脑的神经元:约有1000种类型,每个神经元大约与103-104个其他神经元相连接,形成极为错综复杂而又灵活多变的神经网络。
工作状态:
兴奋状态:细胞膜电位 > 动作电位的阈值 → 神经冲动
抑制状态:细胞膜电位 < 动作电位的阈值
学习与遗忘:由于神经元结构的可塑性,突触的传递作用可增强和减弱 。
人脑神经元结构 – 术语
人脑神经网络是一个具有学习能力的系统,不同神经元之间的突触有强有弱,其强度是可以通过学习(训练)不断改变,具有一定可塑性。单个神经元的神经活动不具备重要性,关键是神经元之间如何组成一个复杂的网络。
| 神经元结构 | 功能 |
|---|---|
| 细胞体 (Soma) | 包含细胞核和其他细胞器,是神经元的代谢中心。 |
| 细胞膜 | 含有各种受体和离子通道,是神经元兴奋和抑制的产生部位。 |
| 树突 (Dendrite) | 接收来自其他神经元的信号,并将兴奋传入细胞体。 |
| 轴突(Axon) | 将自身的兴奋状态从胞体传送到另一个神经元或其他组织。 |
| 突触 (Synapse) | 神经元之间的连接“接口”,将一个神经元的兴奋状态传到另一个神经元。 |
人工神经网络 - 起源与概念
生物神经网络( natural neural network, NNN): 由中枢神经系统(脑和脊髓)及周围神经系统(感觉神经、运动神经等)所构成的错综复杂的神经网络,其中最重要的是脑神经系统。
人工神经网络(artificial neural networks, ANN): 模拟人脑神经系统的结构和功能,运用大量简单处理单元经广泛连接而组成的人工网络系统。
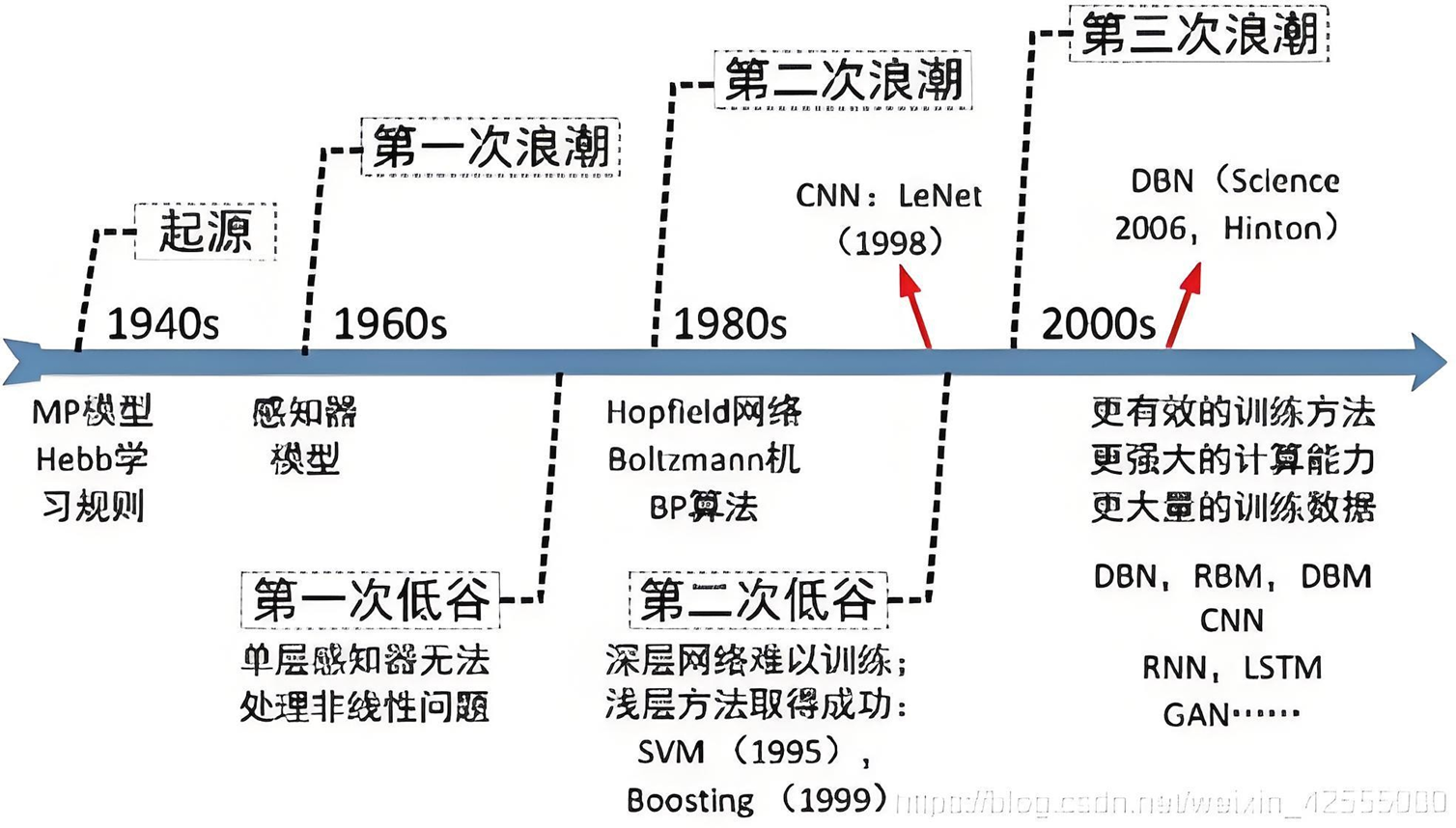
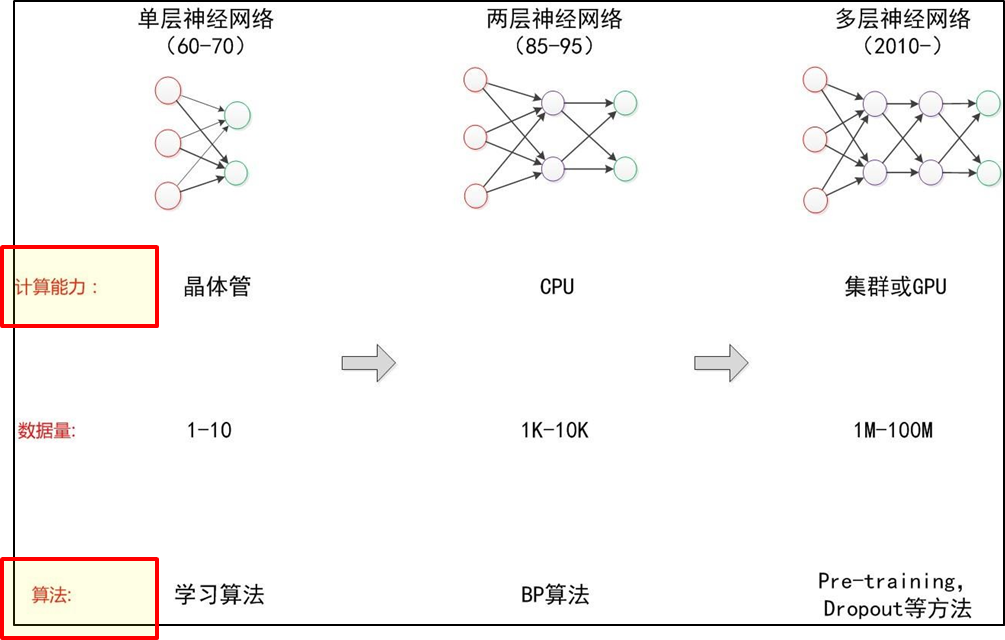
神经网络发展演进 - 三起三落
神经网络发展曲折,从单层神经网络(感知器)开始,到包含一个隐藏层的两层神经网络,再到多层的深度神经网络,一共有三次兴起过程。
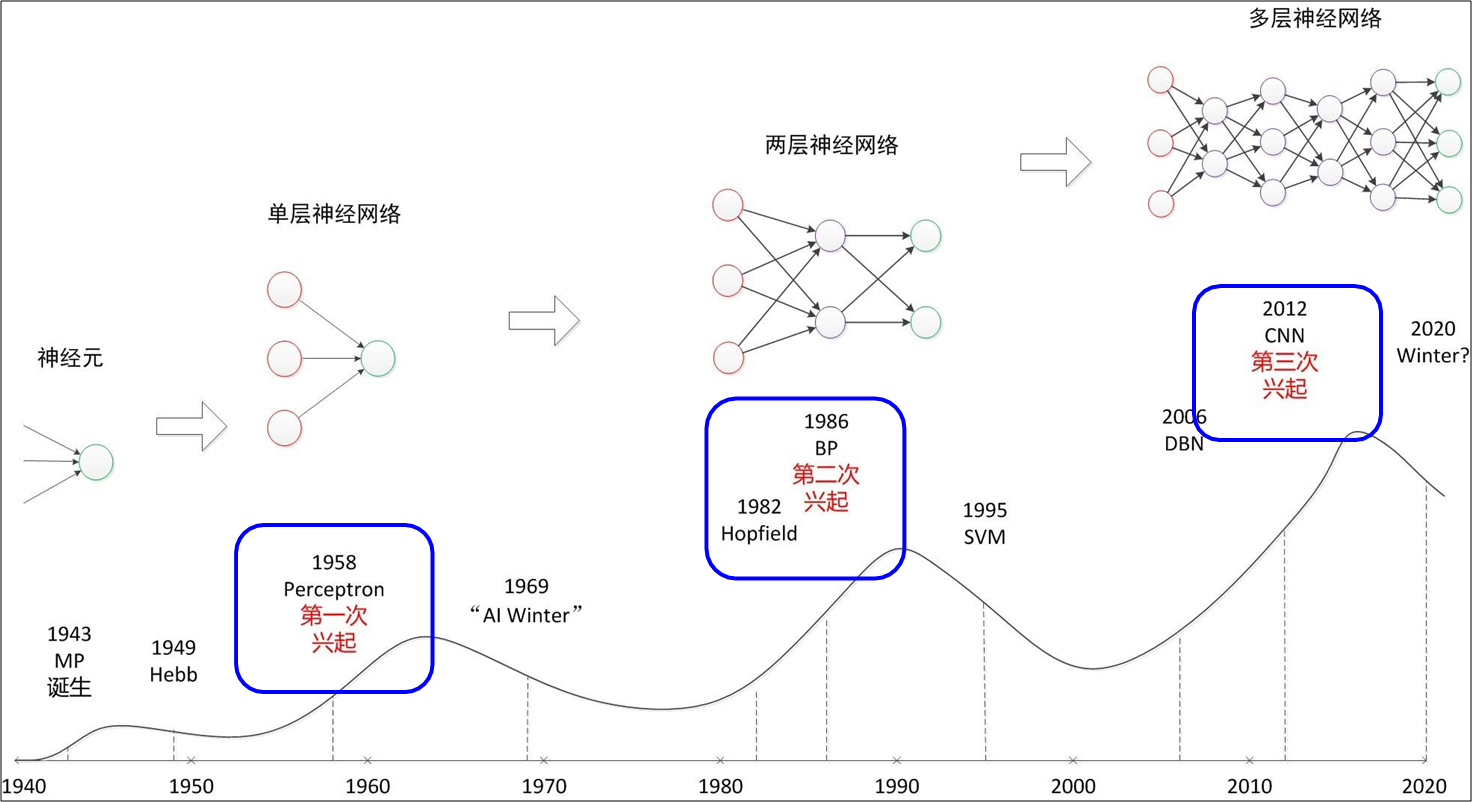
这两个10年间人们对于神经网络的期待并不现在低,可结果都逐渐衰落。
冷静才是对待目前深度学习热潮的最好办法。如果因为深度学习火热,或者可以有 “钱景”就一窝蜂的涌入,那么最终的受害人只能是自己。
神经网络的学习 - 决定性能的三大要素
神经网络方法:是一种“知识表示方法和推理方法”。
神经网络知识表示:是一种隐式的表示方法,它将某个问题的若干知识通过学习表示在一个网络中。(谓词、产生式、语义网络等是显示表示法)
神经网络的学习:指调整神经网络的“连接权值或结构”,使输入和输出能满足需要。
决定人工神经网络性能的三大要素
- 神经元的特性。
- 神经元之间相互连接的形式 – 拓扑结构(见下页PPT)。
- 为适应环境而改善性能的学习规则。
Hebb学习规则
1944年,赫布提出改变神经元连接强度的规则:学习过程最终发生在神经元之间的突触部位,突触的联结强度随着突触前后神经元的活动而变化,变化的量与两个神经元的活性之和成正比。当某一突触两端的神经元同时处于兴奋状态,那么该连接的权值应该增强。(教材P215给出了数学表达公式)

神经网络结构 - 分类
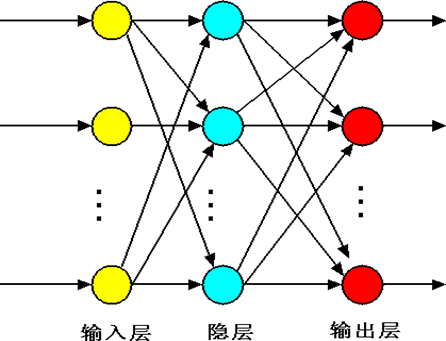
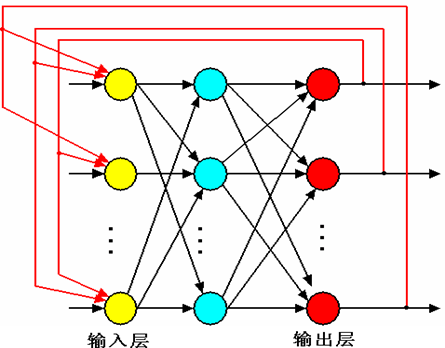
根据神经网络中神经元的连接方式,可以划分为不同类型。主要包括“前馈型、反馈型”两种。
前馈型( 前向型)
反馈型
神经网络结构 - 应用
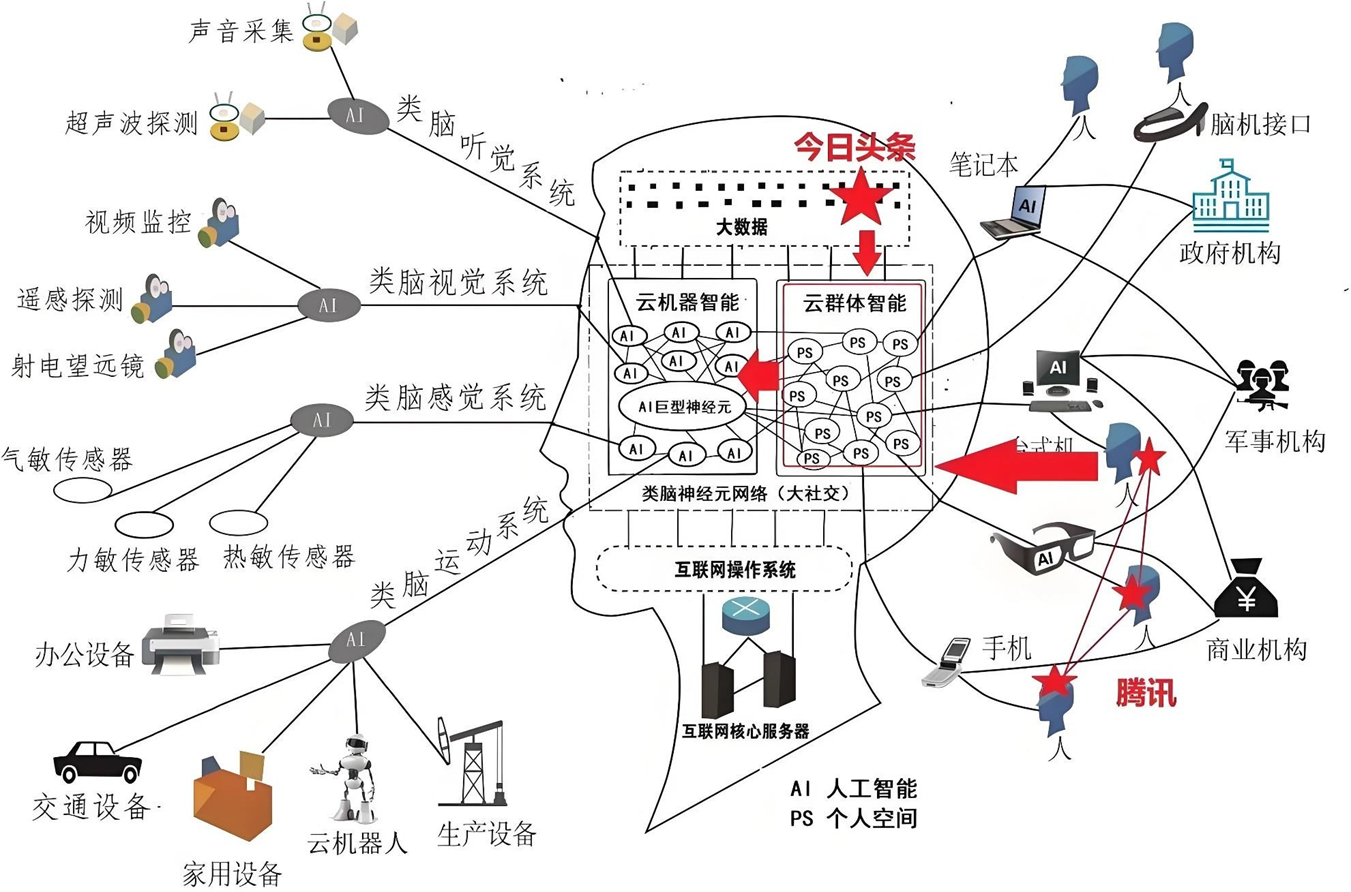
神经元 - MP模型(单层感知机)
AI诞生之时,很容易联想到是否可借鉴人脑的构成。尽管人脑的奥秘还存在很多未知领域,但在已知领域,科学家一直在尝试让计算机模拟人脑运行。首先要做的,就是从人脑的最小单元—神经元入手,让计算机模拟它的工作机制。
1943年,麦克洛奇和皮兹发现了大脑中神经元的工作机制MP模型。
真实的人脑神经3D模拟


单层感知机 - 数学模型
图中每个中枢点可认为是一个神经元,把神经元的生物工作机制简单的绘制出来,并以此建模,得到一个计算机能识别的模型,称之为—Perceptron(感知器)。
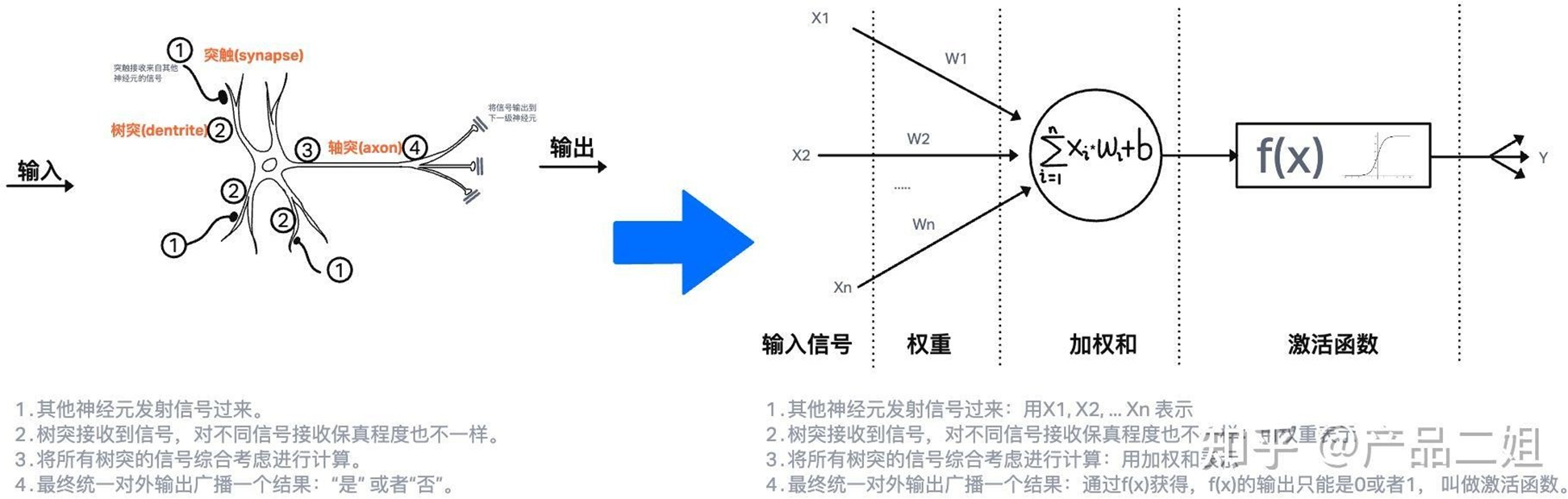
可以把一个神经元细胞想象成一个有多个听筒(输入),但只有一个话筒(输出)的电话。
听筒就是神经元的树突,话筒是神经元的轴突。
单层感知机 - 激活函数(输出变换函数)
激活函数:也叫非线性激励函数、输出变换函数。
激活的概念意味着:通过某个门槛值就是1,否则是0。不恰当的比喻是考试到60分就及格,可以升级。从这个定义来看考0和59是一样的不会被激活,而60和100是一样的,都会被激活。
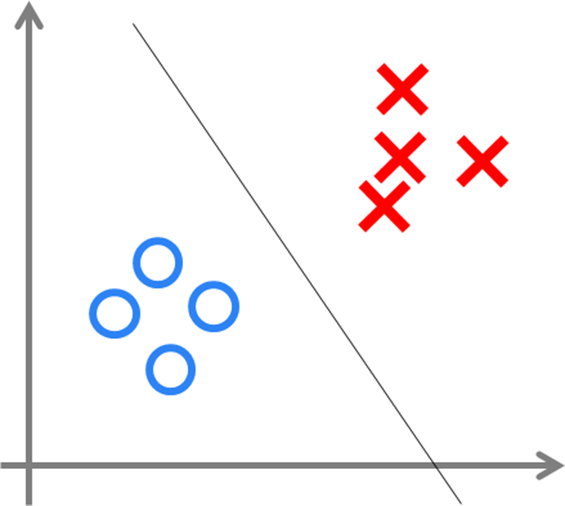
单层感知机的本质 - 线性分类器
感知器中的权值是通过训练得到的。因此,根据以前机器学习的知识可知,感知器类似一个逻辑回归模型,可以做线性分类任务。可以用决策分界来形象的表达分类的效果。
决策分界:就是在二维的数据平面中划出一条直线,当数据的维度是3维的时候,就是划出一个平面,当数据的维度是n维时,就是划出一个n-1维的超平面。
感知机可以被视为一种最简单形式的前馈式人工神经网络,它是一种二分类的线性分类判别模型, 其输入为实例的特征向量想(x1,x2…),神经元的激活函数f为sign,输出为实例的类别(+1或者-1),模型的目标是要将输入实例通过超平面将正负二类分离。
下图显示了在二维平面中划出决策分界的效果,也就是感知器的分类效果。
单层感知机 - 局限性(无法计算异或XOR)
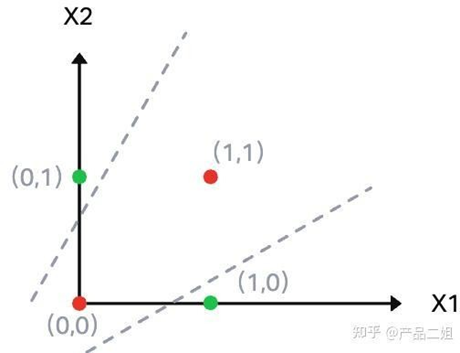
把异或运算的两个输入当做感知器的输入值,期待感知器能把输入值加权求和,然后再用一个激活函数得到两个输入值的异或值。同样我们像刚才一样将A,B 的四个值(0,0), (0,1),(1,0),(1,1)作为X1, X2画在坐标系里(更准确的此时应该说是一个二维向量空间)。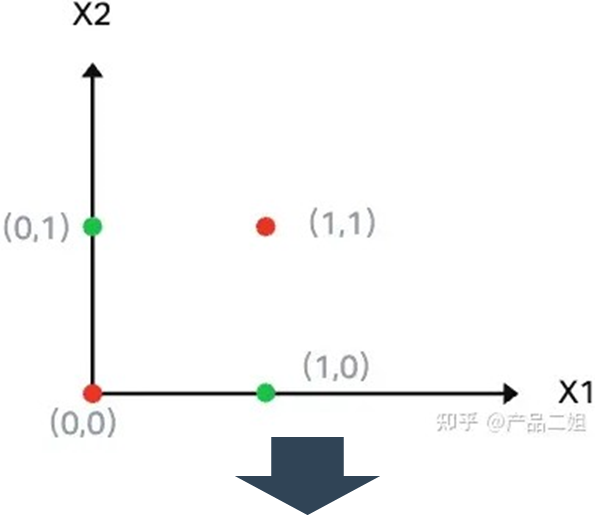
请问是否可以找到一条线将红绿点分开?答案是不能。似乎感知器真不能解决这样简单的问题。
那为什么我们现在还在用这个模型呢? 答案是MLP(Multilayer perceptron),多层感知器。
两层感知机 - 明斯基的“功与罪”
1951年在普林斯顿攻读phD时,年仅24岁的Minsky发明了第一台物理的基于感知器的人工神经网络- 随机神经模拟强化计算器SNARC ( Stochastic Neural Analog Reinforcement Calculator)。在Minsky晚年接受采访时,仍然不忘拿出来show了一把。按理说他应该是感知器的发扬光大者才对。
但是他非常聪明,很早就发现了“单层感知器”的局限,这也体现在1969年他和 Parpet 写 的 一 本 书 中 , 书 的 名 字 叫 《Perceptrons: An Introduction to Computational Geometry》。书中提到最为典型的例子是感知器无法解决像“异或”这么简单的问题。
两层感知机 - 罗森布拉特(0到1的突破)
Minsky说过单层神经网络无法解决异或问题。但是当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。算力受限:不过两层神经网络的计算是一个问题,在当时算力受限的情况下,并没有一个较好的解法。1961年,Frank Rosenblatt(感知器模型的坚定支持者,也是明斯基的高中同学)就发表了论文《Perceptrons and the theory of brain mechanisms》,提出多层感 知器的概念,只是当时并没有被人注意到。非常遗憾,Rosenblatt在明斯基出版《Perceptrons: An Introduction to Computational Geometry》一书的同一年(1969年),就英年早逝(享年41岁)。甚至有人说,如果Rosenblatt在世,可能Marvin根本不会是图灵奖得主。

两层感知器 - 解决异或XOR问题
异或运算举例,假使我们不是做一条线,而是做两条线是不是就可以将红绿点分开了呢。
拆解一下这两条线划分的步骤,以及它如何解决了异或问题。
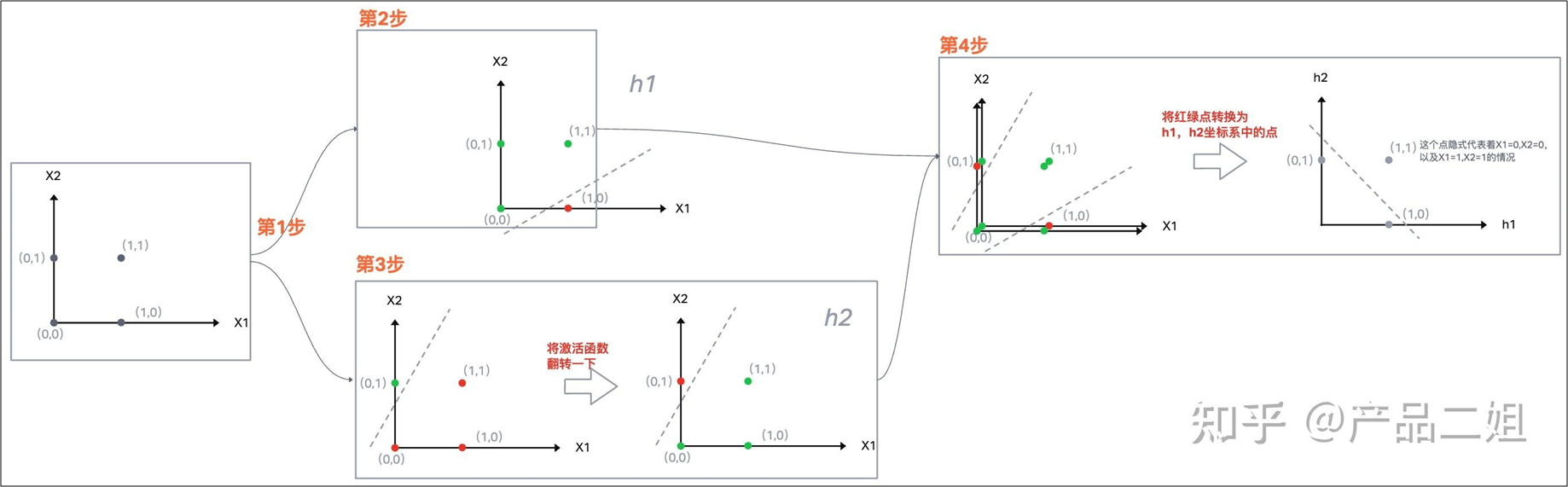
两层感知器 - 解决异或XOR问题
第1步:我们在单层感知器的中间加上一层隐式层,在隐式层里加上两个神经元h1, h2。
第2步:X1, X2信号经过h1感知器后,可以将点(1,0)和其他点分开。
第3步:X1, X2信号经过h2感知器后,可以将点(0,1)和其他点分开,在这里,我们对h2的激活函数
第4步:此时,h1,h2就会有三种输出,即(红,绿),(绿,绿),(绿,红),我们用0代表红色,1代表绿色,那就是(0,1), (1,1), (1,0) 就很容易分开了。这样我们就用一个多层感知器解决了异或XOR问题。
用通用的方法表示以上结构就是下图的神经网络的雏形: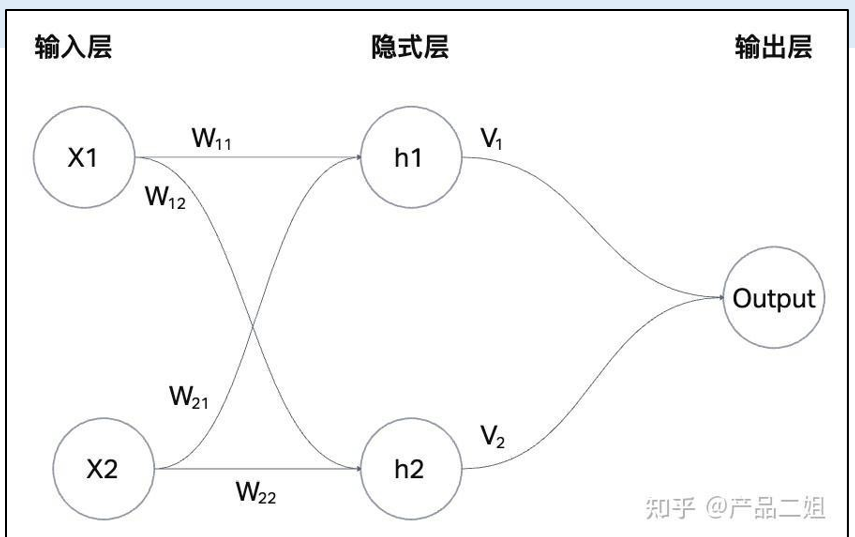
两层感知器的本质 - 非线性分类器
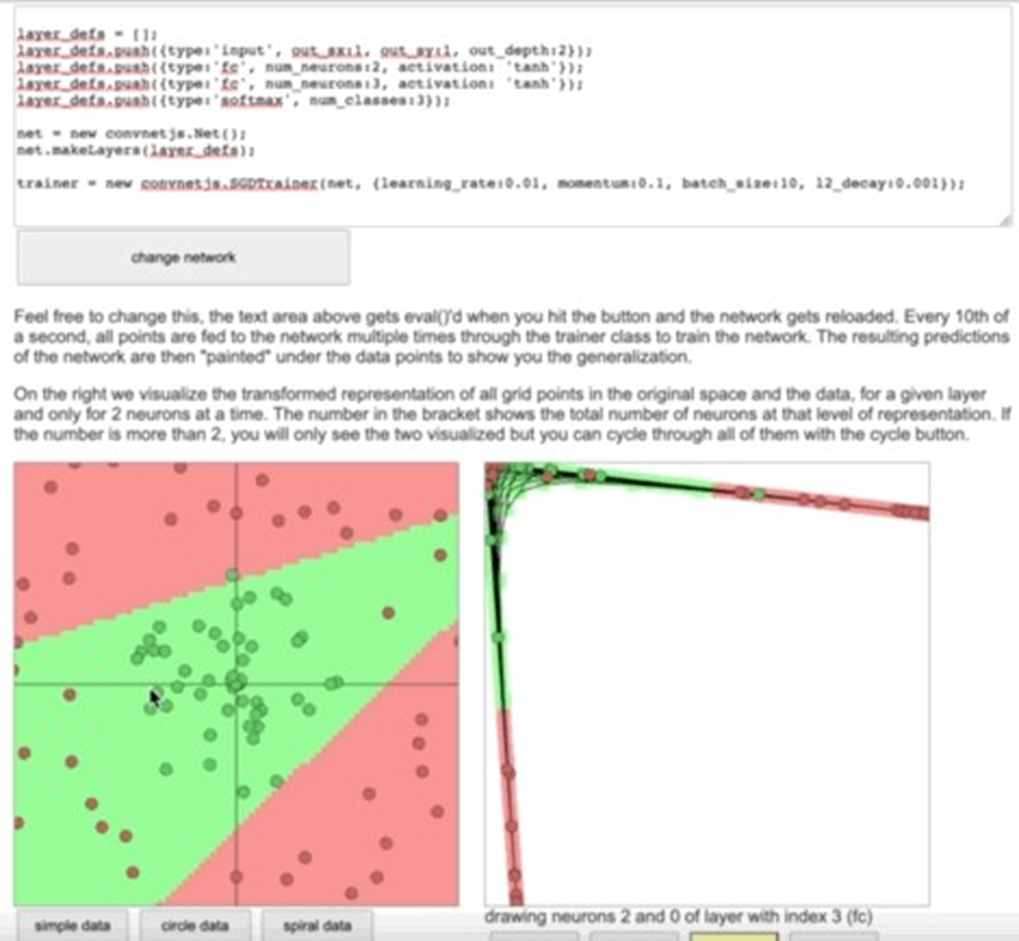
从以上可看出,感知器本质上就是一个分类器,计算机首先通过学习来划出一个空间(多维向 量空间),然后根据这个学习结果来区分新的 输入是落在这个空间之外,还是之内。计算机不可能像人通过“看一眼”就能划出这个空间,它是采用的是无限逼近的方法。(比如随机给一组权重,然后看看通过这个权重算出来的值与训练给出的已知值有多大差异,直到这个差异值达到最小值,就停止逼近。)如何使计算机更快更好的逼近这个最佳权重,就是所有的基于神经网络的算法要解决的问题。(最简单的比如刚做的将单层感知器增加一层,还比如增加神经元,都可以更好更快地划出这个空间。)【右图是斯坦福网站有趣的实验,支持2层神经网络】当把一层感知器增加为两层的时候,就会画出两条线来来划出一个二维空间。在两层感知器中,通过增加神经元可以对更复杂的点分布做出分类。即,可通过多层神经元这种结构可以对一切进行分类。
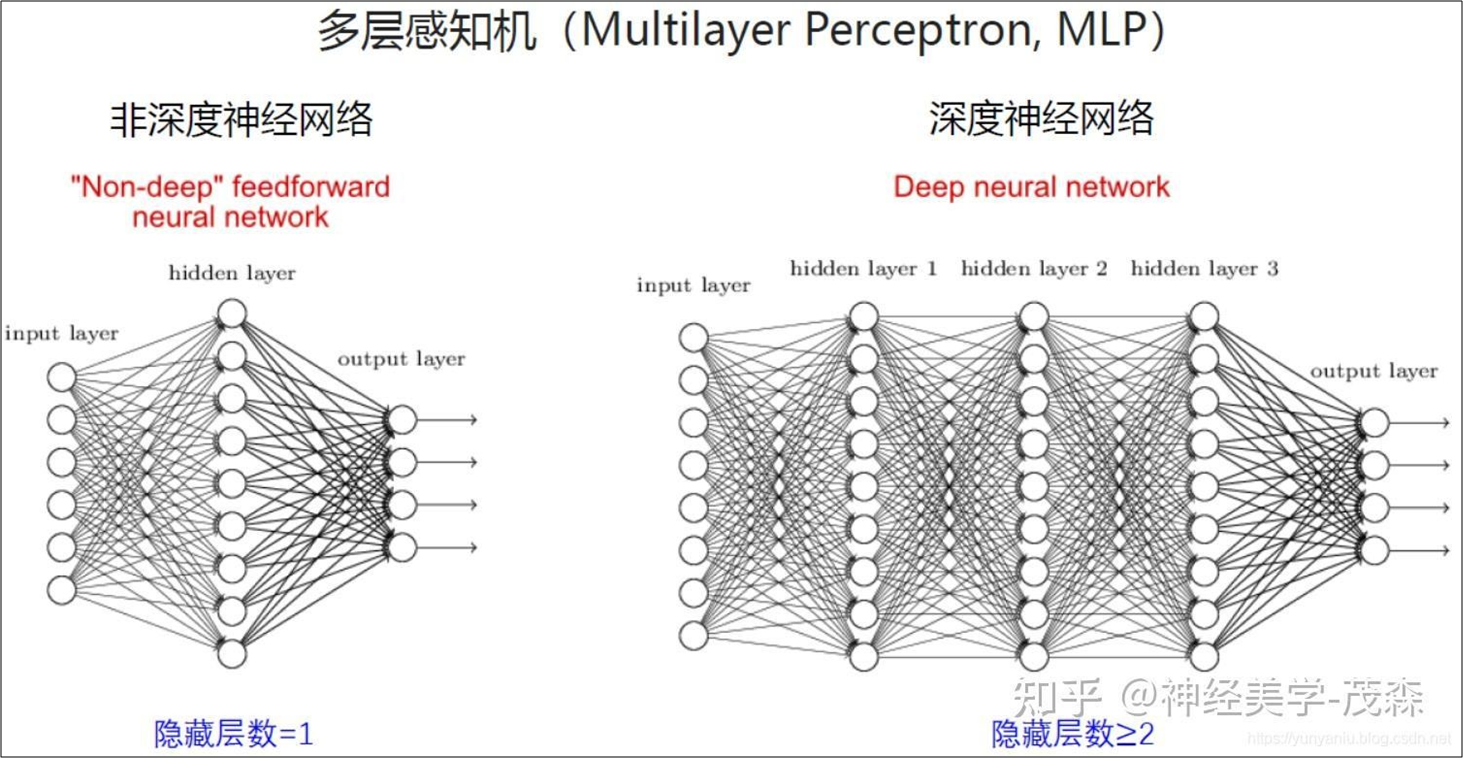
多层感知机 - 深度学习(1到100的发展)
多层感知机通过对线性分类器的组合叠加,具有拟合非线性函数的能力。Hornik在1989年证明,当中间隐含层的神经元数量趋于无穷多时,多层感知机可以拟合任何非线性函数。
神经网络发展小结 - 算法、算力的影响
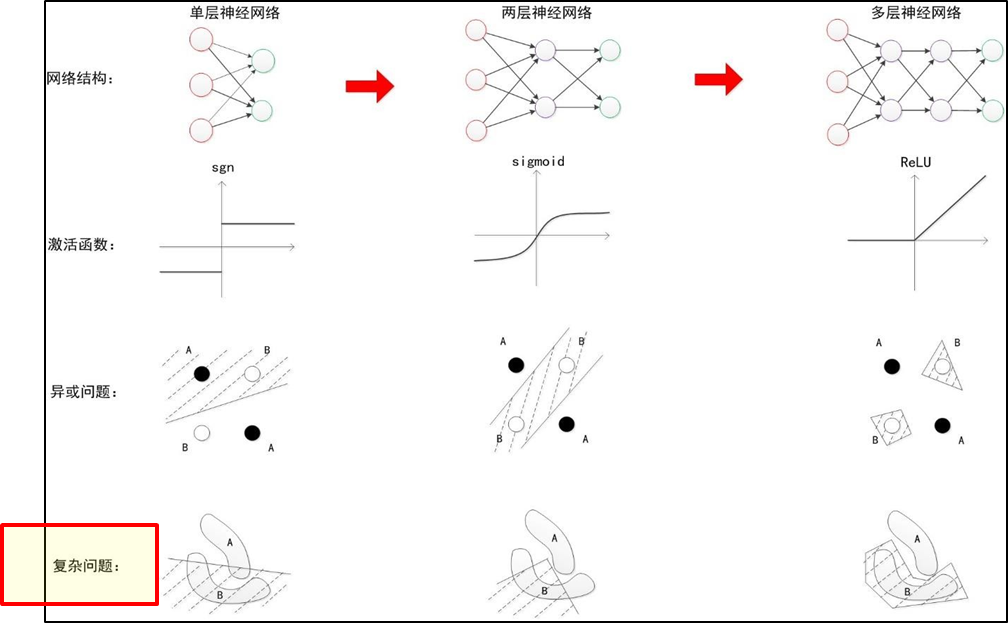
神经网络发展小结 - 扩展
理论上来说,神经元数量越多,层数越多,产生的力量越大。可借鉴互联网的网络效应,网络效应粗略可根据节点间的连接数量来确定,而网络的力量就蕴含在这些连接当中。(假设一个网络中有N的节点,最佳情况下,每两个节点都可以相连,就可以产生: N(N-1)/2次连接(1个节点可以和其他N-1个节点连接,总共就是N(N-1)个连接,但因为每个连接会重复算一次,所以要除以2))。在人类大脑里,平均每人拥有860亿个神经元,这860个神经元总共有100万亿个突触,即可以发生100万亿次连接(这里并非每两个神经元之间都有连接)。在已知领域内,大脑的所产生的力量也是蕴含在这些神经元的连接中(至于其他未知领域,相信还有很多,毕竟人脑进化了几百万年,不是我们几百年就能研究清楚的),所以你大概能知道人与人脑力的差别可能就在于:神经元的数量。神经元之间的连接,这种连接是可以被训练的。20世纪60年前关于感知器局限性的争论,然后又对AI这座大厦最底层原理做了一个简单的阐述。最大感受是:一座大厦,不管它多么宏伟,也离不开底层的一砖一瓦;一个个体,不管它多么渺小,汇聚在一起也能产生意想不到的力量。在整个人工智能的知识体系里,感知器这个小小的概念最终扛住了时间的考验,成为今天的AI的基石。
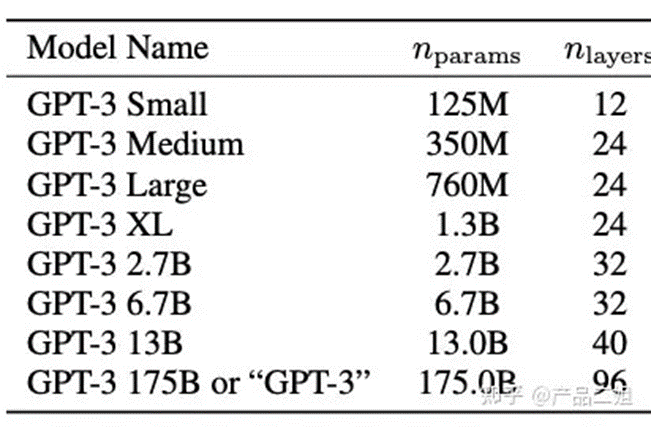
Hopfield网络 - 概念与原理
1982年, Hopfield的一篇论文横空出世,仿佛神经网络这匹困兽再次苏醒,也预示着神经网络在AI 领域的崛起。论文中提到的associative neural network就是后来的“Hopfield network”,它是当前学习神经网络绕不开的话题。Hopfield 并非图灵奖得主,但他对计算机AI 领域的开创性贡献却启发了三位未来的图灵奖得主( Geoffery Hiton, Bengjo, Yann Lecun)。Hopfield 所从事的领域并非计算机科学,Hopfield在物理学的的成就更为显著。在2001年, Hopfield 被授予Dirac奖(理论物理学界的诺贝尔奖)Hopfield 网络就是他从物理学角度去研究神经科学,最后却被应用于计算机科学的一个案例。

Hopfield网络 - 伊辛模型(Ising model)
伊辛模型:在解释物体呈现“固态、液态或者气态”,是内部粒子实现“动态平衡”的表现。就像湖里的水不变,不是因为它没有输入输出,只是因为输入输出恰好一样。类似,Hopefield网络认为,人脑记忆也是一种动态平衡。当磁体在高温时磁性会消失,而降到一定温度后,又会恢复磁性。磁性的产生是因为磁体内部粒子的磁性方向一致。高温时,粒子的磁性方向杂乱无章,彼此磁性抵消,呈现整体没有磁性的状态。

假设某个内容被记忆(存储)在N个神经元中。和伊辛模型类似,Hopfield认为每个神经元的状态仅仅与它相邻神经元的状态相关,同时反过来,每个神经元的状态又影响着与其相邻的神经元。
这种动态平衡是由这样一个规则在维持:当相邻两个神经元的状态相反时(相当于彼此想让对方翻转),彼此作为输入信号的权重为-1, 当相邻两个粒子状态相同时,权重为+1。
Hopfield神经网络 - 网络结构
Hopfield神经网络是反馈神经网络,其输出端又会反馈到其输入端,在输入的激励下,其输出会产生不断的状态变化,这个反馈过程会一直反复进行。假如Hopfield神经网络是一个收敛的稳定网络,则这个反馈与迭代的计算过程所产生的变化越来越小,一旦达到了稳定的平衡状态,Hopfield网络就会输出一个稳定的恒值(吸引因子(W矩阵))。对于一个Hopfield神经网络来说,关键在于确定它在稳定条件下的权重系数。原始Hopfield神经网络是个全连接网络,即网络中任意两个神经元之间都有连接,在数学上这叫完全图(complete graph)。
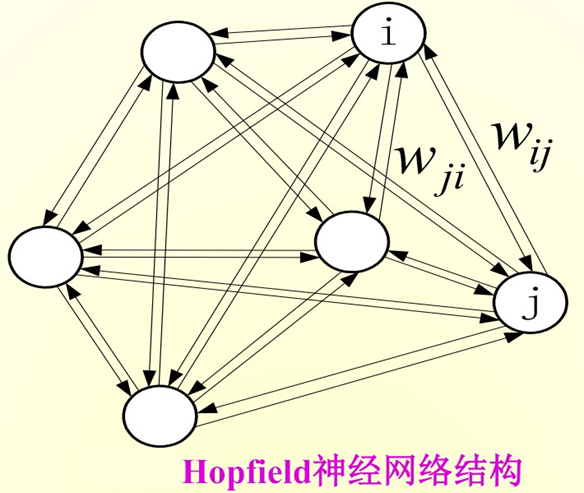
可以认为Hopfield网络里的神经元都是社交高手,跟谁都是朋友。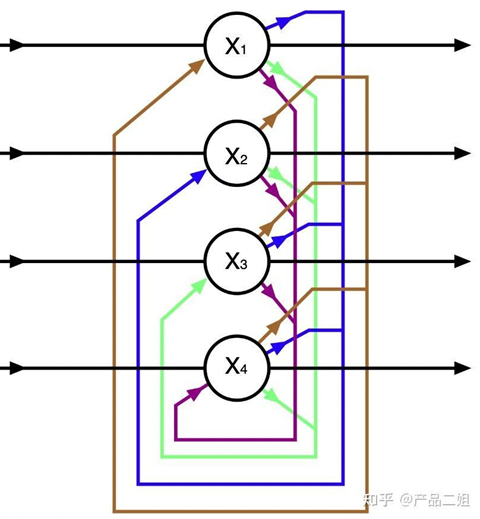
Hopfield神经网络 - 平衡状态规则
动态平衡的维持规则:当相邻两个神经元的状态相反时(相当于彼此想让对方翻转),彼此作为输入信号的权重为-1, 当相邻两个粒子状态相同时,权重为+1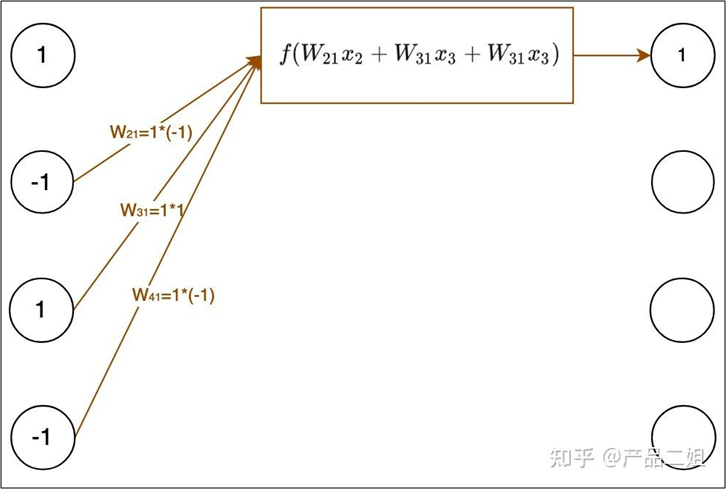
权重计算

结果计算
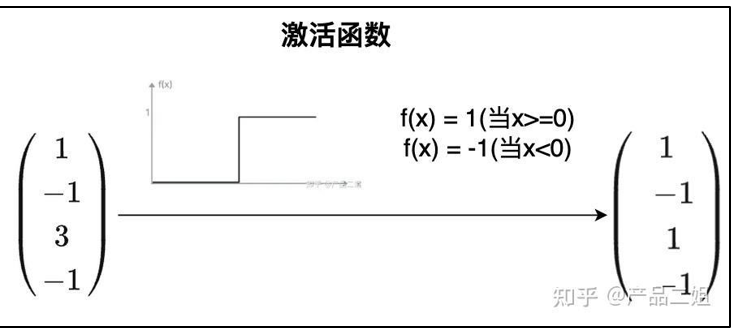
Hopfield神经网络 - 求解权重矩阵
以此类推,经过这样多个权重定义,其他几个神经元的状态也能保持状态不变。因此,核心任务转换为“求解权重矩阵”。特点: 权重矩阵W 完全无需人工参与调节, 由神经元自身状态值产生, 因此,Hopefield 网络也被认为是第一个无监督式学习模型。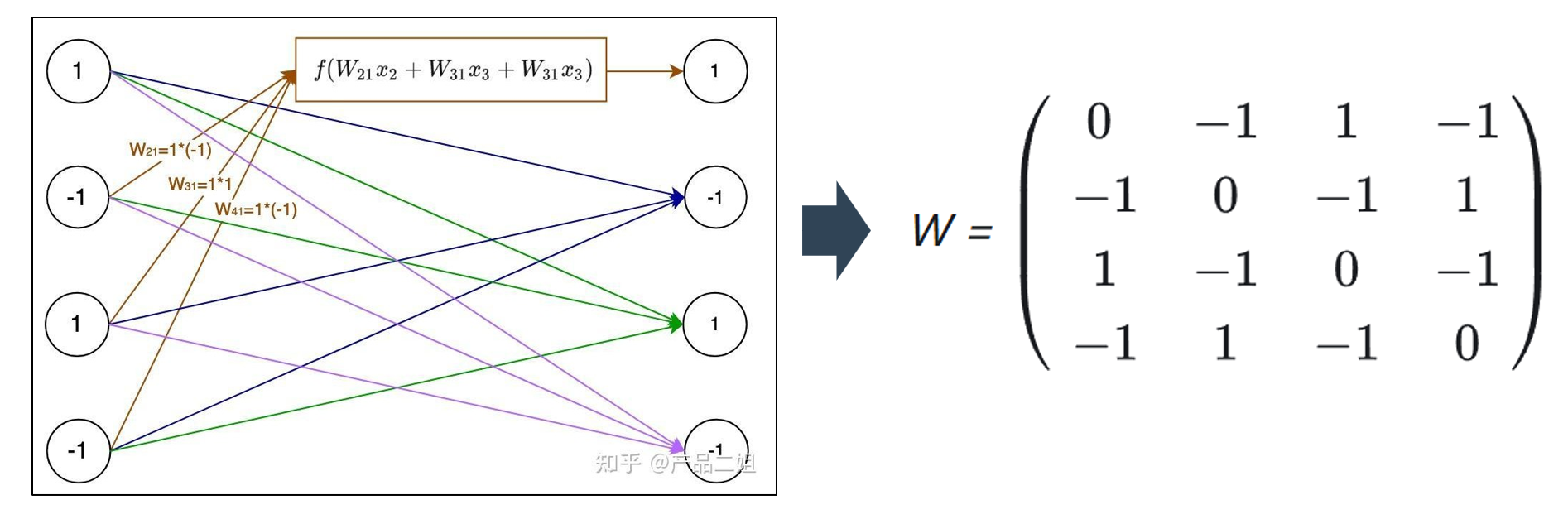
Hopfield网络 - 如何通过片段回忆整个记忆内容
要想通过片段唤起整个记忆,相当于是把片段作为一个输入值,经过某种变换之后,输出整个记忆。
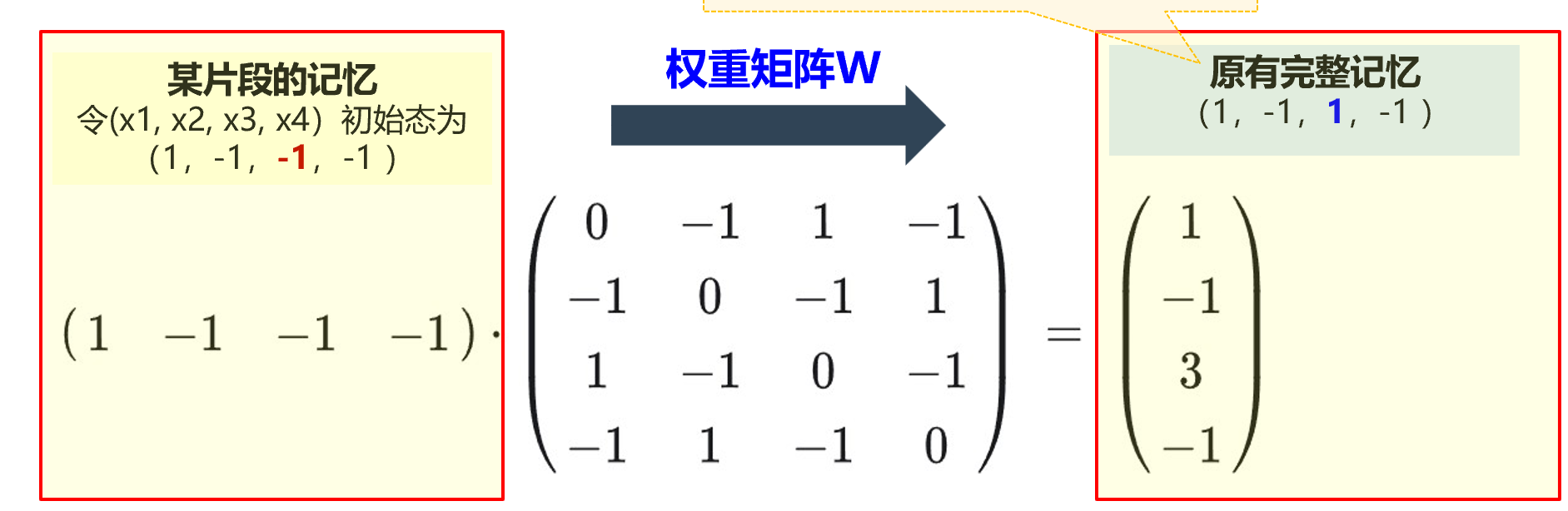
当然,这只是4个神经元的恢复,现实中可能是成千上万个神经元参与,这个回忆过程不会一步完成,而是一个围绕记忆上下振荡的过程,但是由于W矩阵的存在,最终会恢复到记忆,就像我们回忆某个事情的时候,也要经历一些过程。
BP神经网络 - 概念
- 定义:是一种按误差逆传播算法训练的多层前馈神经网络,是目前应用很广泛。
- 作用:BP网络能学习和存贮大量的“输入-输出”模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
- 学习规则:使用“最速梯度下降法”,通过反向传播来“不断调整网络的权值和阈值”,使网络的误差平方和最小。
- 基本思想:通过计算“输出层”与“期望值”之间的误差来调整网络参数,从而使得误差变小。其思想很简单,然而人们认识到它的重要作 用却经过了很长的时间。
- 重要性:BP算法是深度学习中求取各层梯度的核心算法,理解该算法对于理解深度学 习原理至关重要。
BP神经网络 - 起源
1974年,哈佛大学沃伯斯(Paul Werbos)博士论文里,首次提出了通过误差的反向传播(BP,Backpropagation)来训练人工神经网络,但在该时期未引起重视。
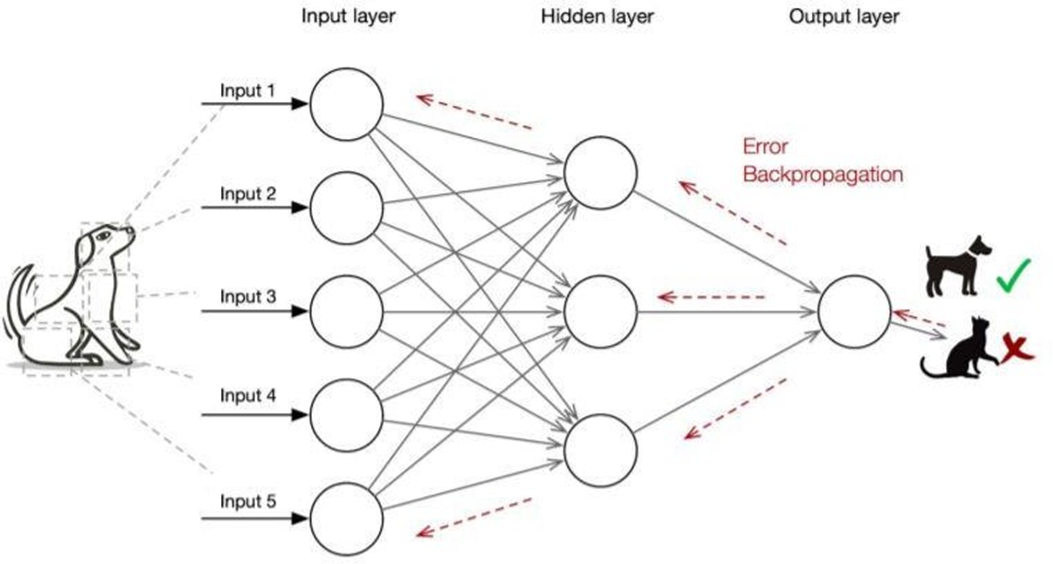
1986 年, Rumelhart 和Hinton 等发展了反向传播BP算法,解决了两层神经网络所需要的复杂计算量问题,带动业界使用两层神经网络研究的热潮。( 参 见 他 们 发 表 在 Nature 上 的 论 文 Learning representations by back- propagating errors )

BP神经网络 - 算法原理
- MLP存在问题:多层感知器在如何获取“隐层的权值”问题上遇到了瓶颈。
- 解决思路:既然我们无法直接得到隐层的权值,能否先通过输出层得到“输出结果和期
- 望输出的误差”来间接调整隐层的权值呢? BP算法就是采用这样的思想设计出来的。
- 基本思想:学习过程由“信号的正向传播”与“误差的反向传播”两个过程组成。。
- 前向传播(阶段1):从输入层开始,逐层计算输出,直至输出层。“每个神经元的输出”通过加权和和激活函数的处理得到。
- 反向传播:在前向传播结束后,通过比较“网络输出”和“期望输出”的差异来计算误差。然后,误差以反向传播的方式逐层传递回输入层,通过调整各层间连接权重,使误差逐步减小。
- 权值更新:在反向传播过程中,根据误差和梯度下降法,更新神经网络的权值和阈值。通过不断迭代,使得网络输出逼近期望输出,达到训练的目标。
BP神经网络 - 算法原理(通俗举例解释)
- 前向传播:三个人在玩你画我猜的游戏,然后第一个人给第二个人描述,再将信息传递给第三个人,由第三个人说出画的到底是啥。
- 反向传播:第三个人得知自己说的和真实答案之间的误差后,发现他们在传递时的问题差在哪里,向前面一个人说下次描述的时候怎样可以更加准确的传递信息。就这样一直向前一个人告知。
不断磨合:三个人之间的的默契一直在磨合,然后描述的更加准确。


BP神经网络 - 数学模型
BP网络结构:在输入层与输出层之间增加若干层(一层或多层)神经元,这些神经元称为隐藏层,它们与外界没有直接的联系,但其状态的改变,则能影响输入与输出之间的关系,每一层可以有若干个节点。
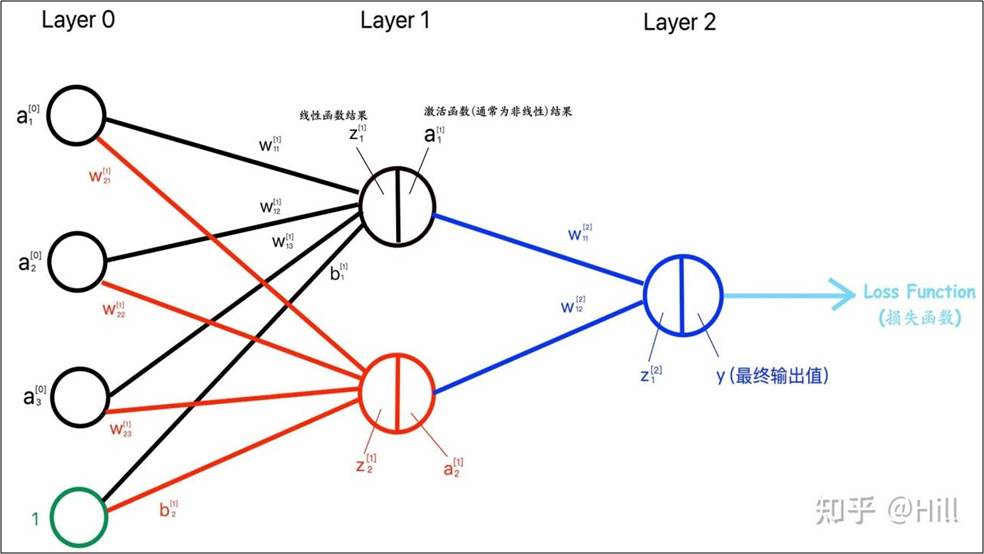

要解决的问题:如何获取“隐层的权值(W, b) ” 。
BP神经网络 - 前向传播
过程:从输入层开始,逐层计算输出,直至输出层。每个神经元的输出通过加权和和激活函数的处理得到。
即:构建函数模型,并计算出Loss函数 的过程。
BP神经网络 - 反向传播(反馈与调整)
过程:在已知Loss函数 的情况下,对该函数做数学优化,得到最小化Loss函数 时,各个参数(W, b) 的值。
优化技巧(梯度下降法):利用Loss函数 求得其关于所有参数(W, b) 的梯度,再基于梯度下降法更新参数。
反向传播知道如何更改网络中的权重w和偏差b,来改变代价函数Loss函数值。最终这意味着它能够计算关于(W, b) 的偏导数。
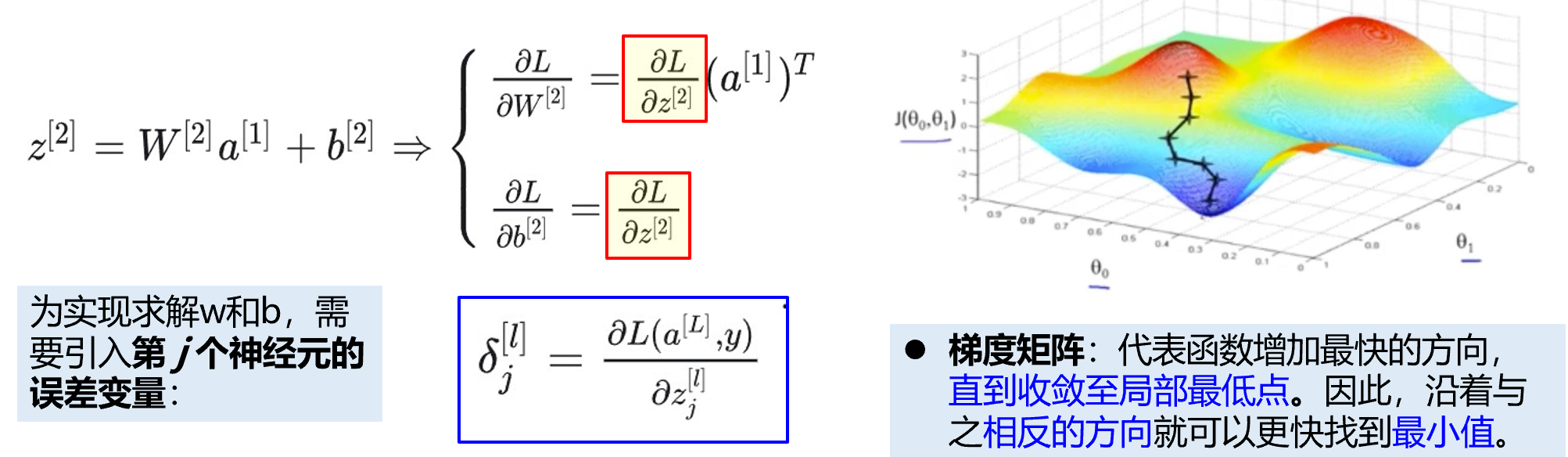
为计算以上w和b的偏导数,先引入一个中间变量(网络中第 𝑙 层第 𝑗 个神经元的误差)。后向传播能够计算出误差,即可返回计算出w和b。

上式表示“损失函数在 𝑧 [𝑙] 上的偏导数”,为什么误差能定义成这样?这是因为目标点在损失函数曲面的最低点的梯度为0,即所有维度上的偏导值为0,所以将当前点处的偏导值定义为当前的误差是非常合理的。
根据链式法则


以下表示本层δ值 与下一层δ值 间的关系,这种反向计算关系,就是反向传播算法这个名字的由来。其实误差并没有真的在神经网络中传播,而是上一层的δ值与下一层δ值之间存在这种数学关系,所谓误差的反向传播就是对这种反向计算方式的形象表达。

注意:截图中的的C函数就是Loss函数。

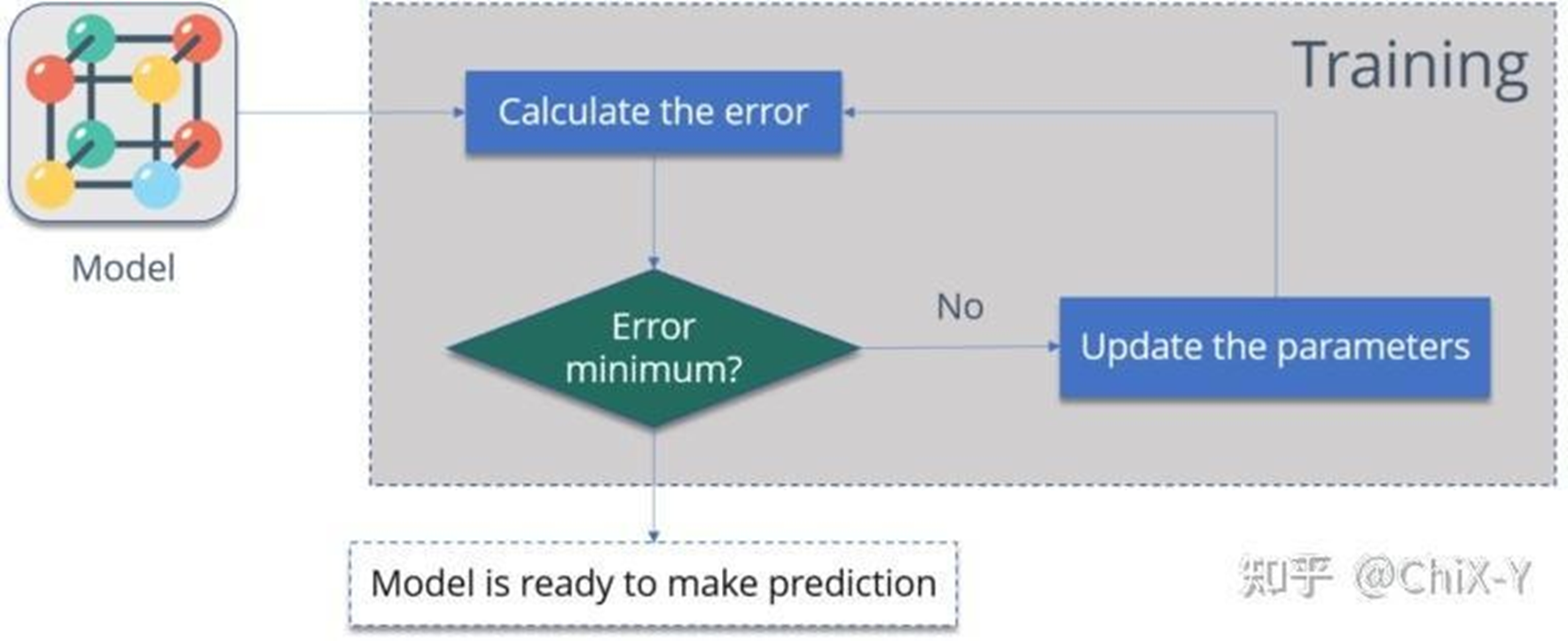
BP神经网络 - 小结
卷积神经网络CNN - 起源与原理
1968年,Hubel和Wiesel的论文,讲述猫和猴的视觉皮层含有对视野的小区域单独反应的神经元。
感受野(Receptive Field):如果眼睛没有移动,则视觉刺激影响单个神经元的视觉空间区域。相邻细胞具有相似和重叠的感受野。感受野大小和位置在皮层之间系统地变化,形成完整的视觉空间图。
以上为CNN的局部感知奠定了一个基础。
Hubel和Wiesel将猫麻醉后,把电极插到其视觉神经上,并连接示波器。然后给它们看不同图像,观察脑电波反应。发现猫看到鱼的图片神经元并不会兴奋。但意外发现,切换幻灯片时,猫神经元会兴奋,即“图片的边缘会引起猫咪神经元的兴奋”。
由此,两人获得1981年诺贝尔奖。这项发现在生物学上留下浓墨重彩的一笔,且对20年后人工智能的发展埋下了伏笔。

1980年,日本人福岛邦彦在论文《Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffectedby shift in position》提出一个包含卷积层、池化层的神经网络结构。
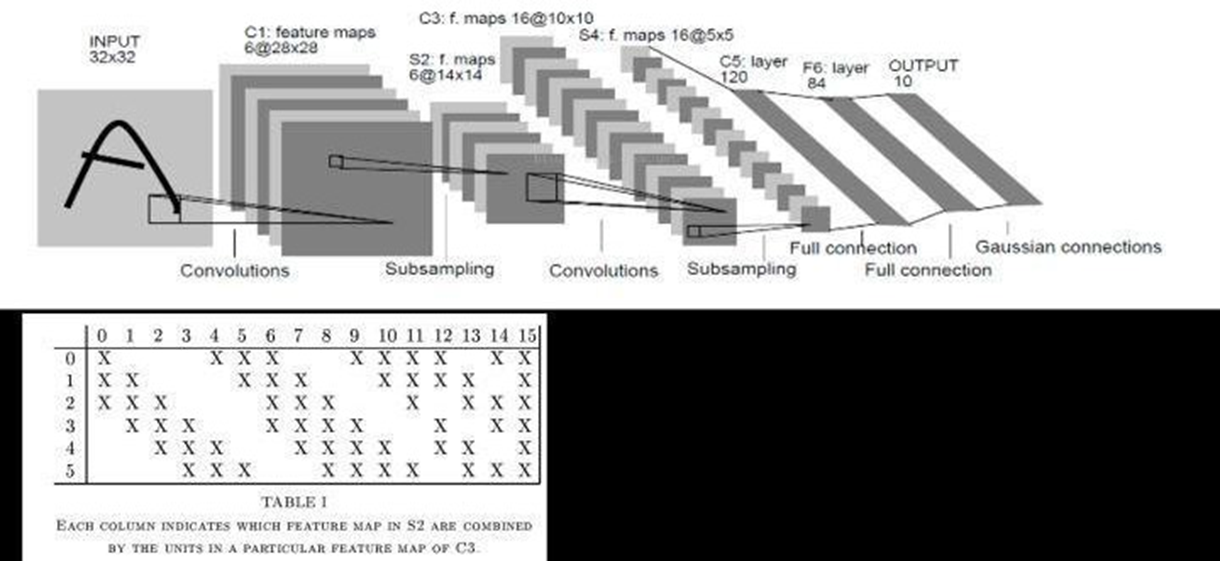
卷积神经网络CNN - 突破(LeNet-5)
1998年,在这个基础上,Yann Lecun在论文《Gradient-Based Learning Applied to Document Recognition》中提出了LeNet-5,将BP算法应用到这个神经网络结构的训练上,就形成了当代卷积神经网络的维形。
Yann Lecun最早将CNN用于手写数字识别。
LeNet-5的结构和现在用的 CNN网络结构已经非常接近。网络层数加深到了7层,其中两层卷积两层池化。
LeNet-5 标志卷积神经网络的开端,因为当时计算机算力的限制, 所以其使用了复杂的局部连接。
并 且 当 时 并 没 有 使 用 softmax和交叉熵,而是使用了欧式径向基函数和均方误差。
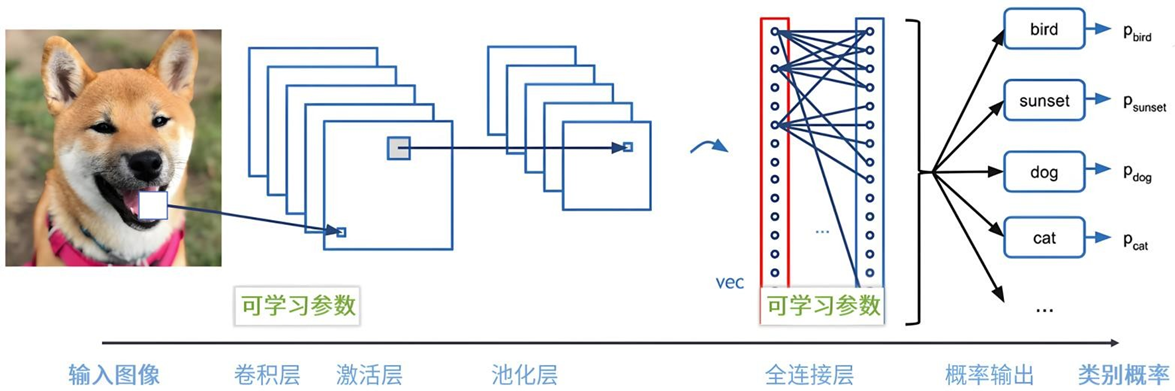
卷积神经网络 - 结构
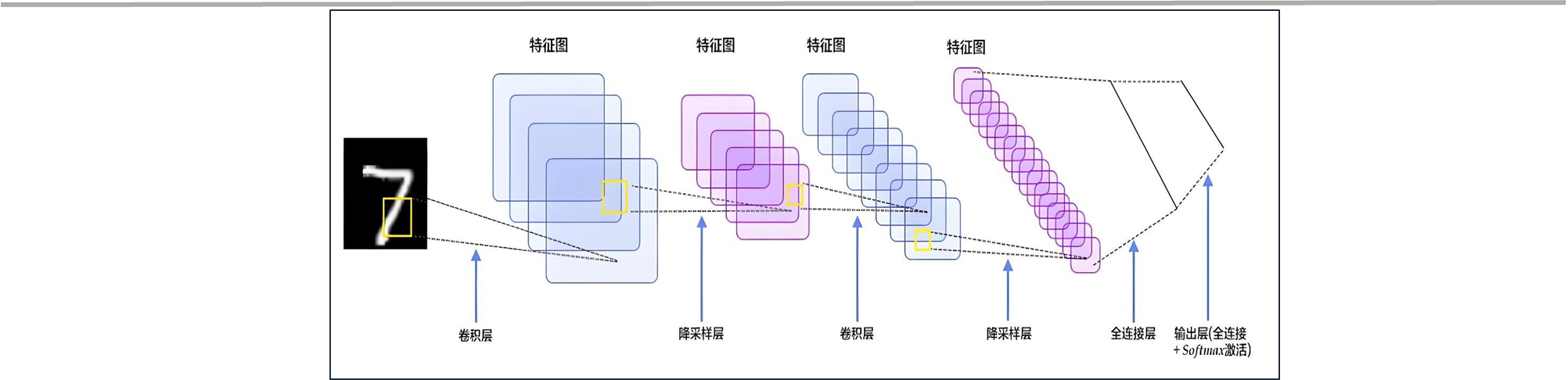
| 名称 | 操作内容 | 数学意义 |
|---|---|---|
| 输入层 | 接收原始图像数据(常是像素矩阵); 对彩色图像,矩阵的深度(即通道数)通常为3,代表红、绿、蓝。 | - |
| 卷积层 (核心) | 拿着滤镜查找和提取特征; 滤波器在输入数据上滑动并进行卷积运算,以提取输入数据的局部特征。 随着网络深度的增加,卷积层能够从低级特征中提取更复杂的特征。 | 卷积就是2个函数的叠加,即矩阵相乘。 |
| 池化层 (下采样层) | 为减少训练的参数,在保持采样不变下,忽略掉一些信息,降低网络的参数数量。 同时增强对微小形变的鲁棒性。 | 取最大值、或平均值等,达到降维目的。 |
| 全连接层 | 将卷积层和池化层提取的特征进行整合 做分类或回归任务判断,并输出最终预测结果。 | 矩阵相乘 |
CNN算法框架1 - 卷积层(卷积操作)
主要是用来提取图像数据的特征和学习图像数据的特征表示。
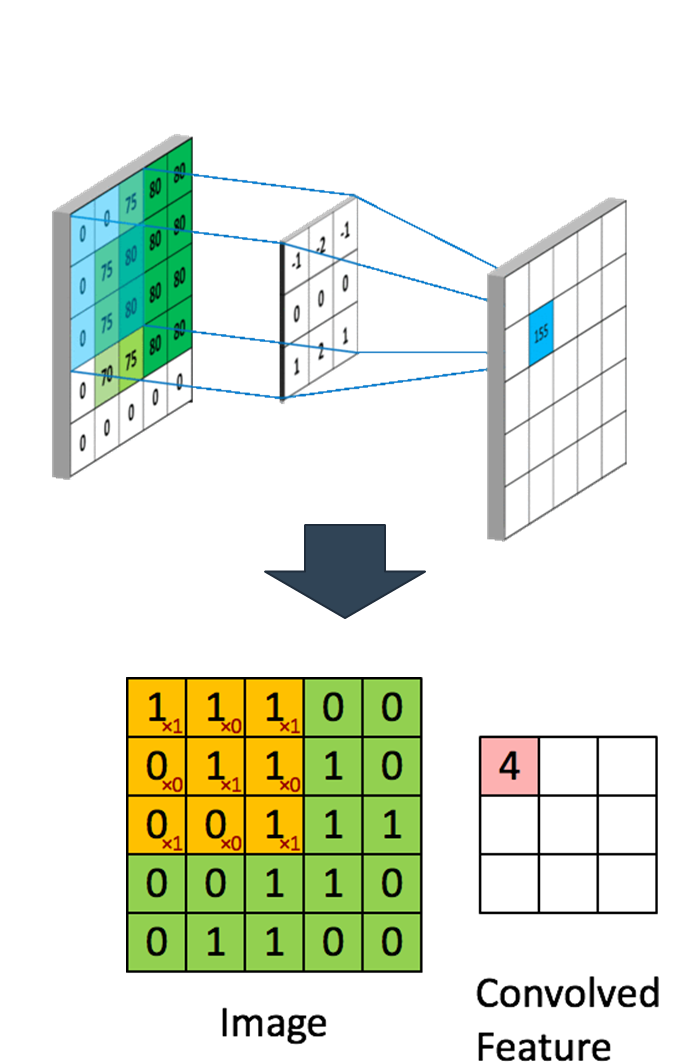
CNN算法框架 - 卷积层(子卷积层)
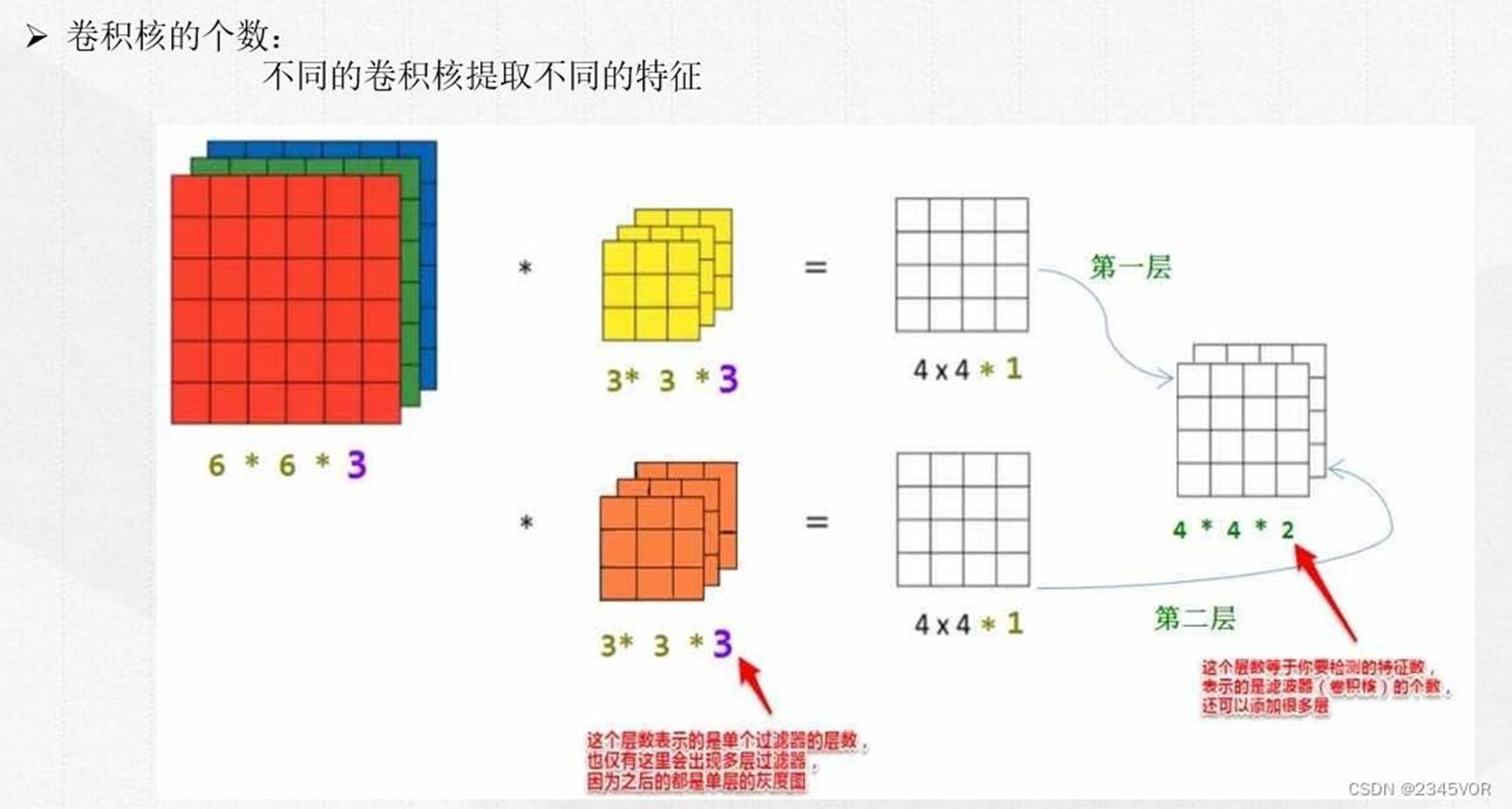
输入图像有RGB 3个通道,会增加网络的深度,此时就有了子卷积层的概念。
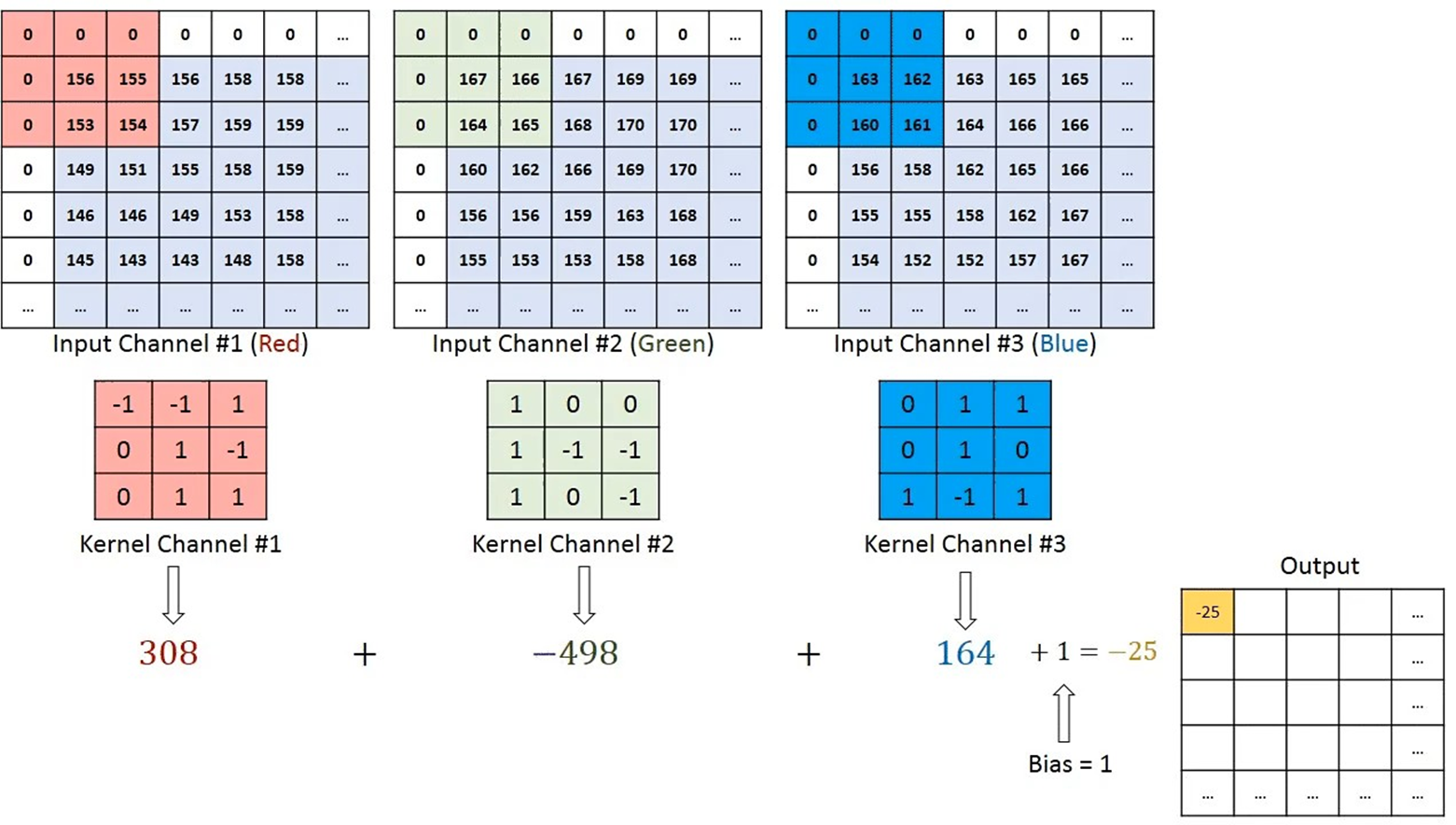
CNN算法框架 - 卷积层
填充
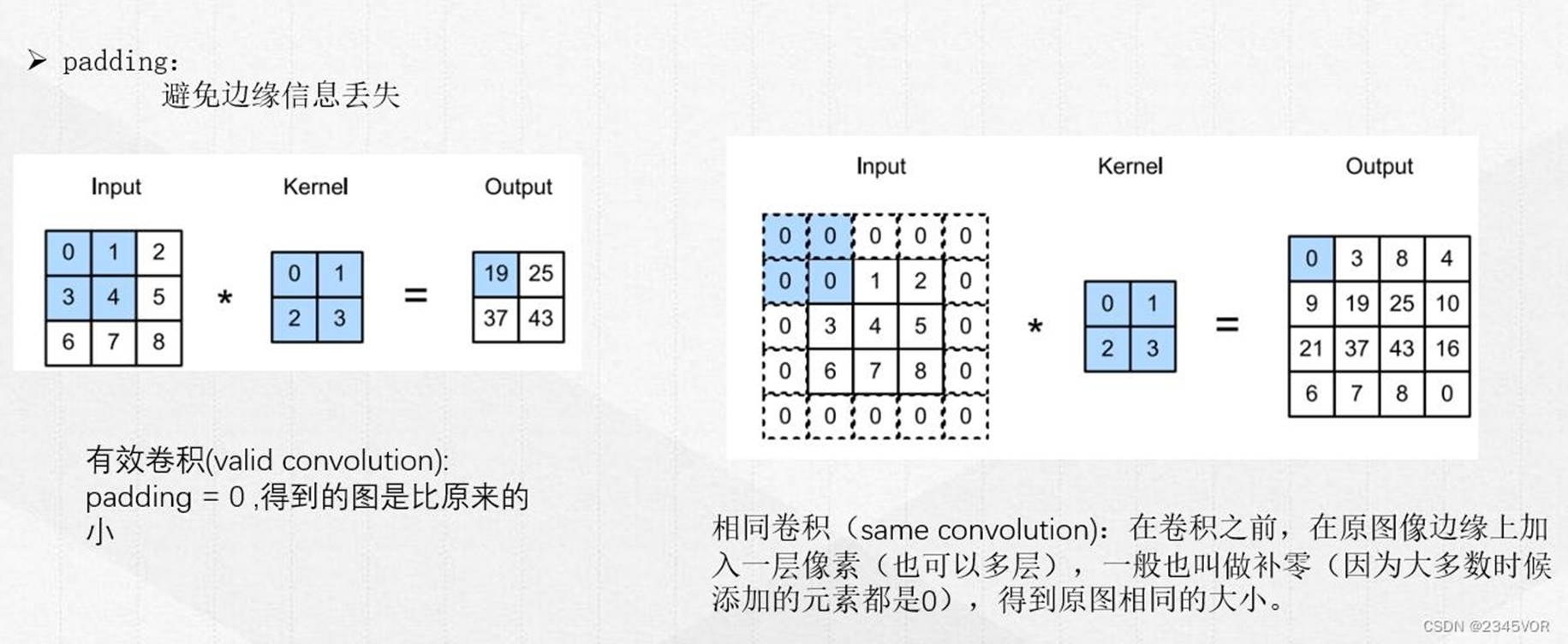
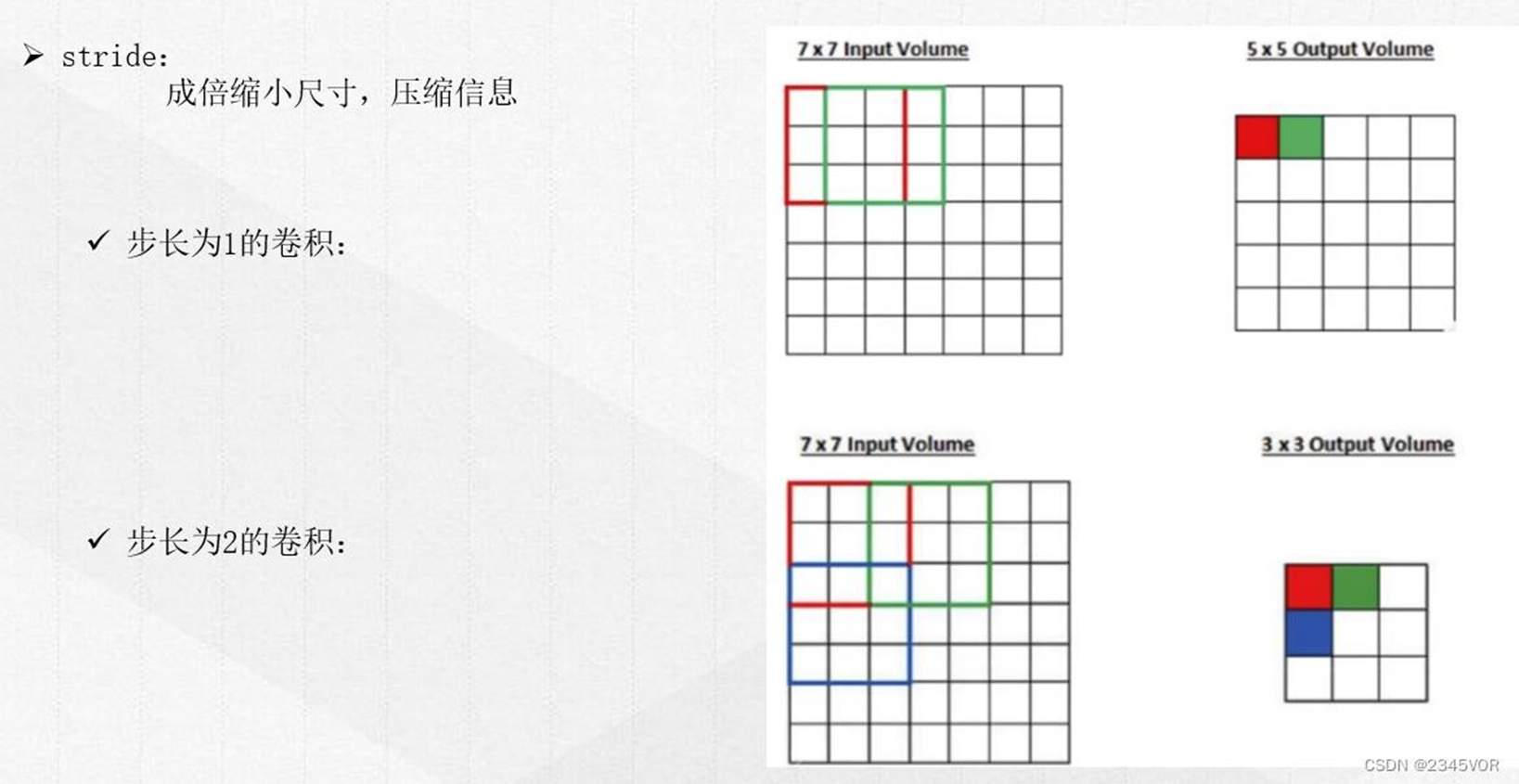
选择卷积的步长
卷积核个数的确定
CNN算法框架 - 池化层(下采样)
作用:是减小数据处理量同时保留有用信息。理论上,任何类型的操作(如求最大、求平均等)都可以在池化层中完成,但实际上,一般只使用最大池化,这是因为卷积已经提取出特征,相邻区域的特征是类似,近乎不变。这时,池化只是选出最能表征特征的像素,缩减了数据量,同时保留了特征。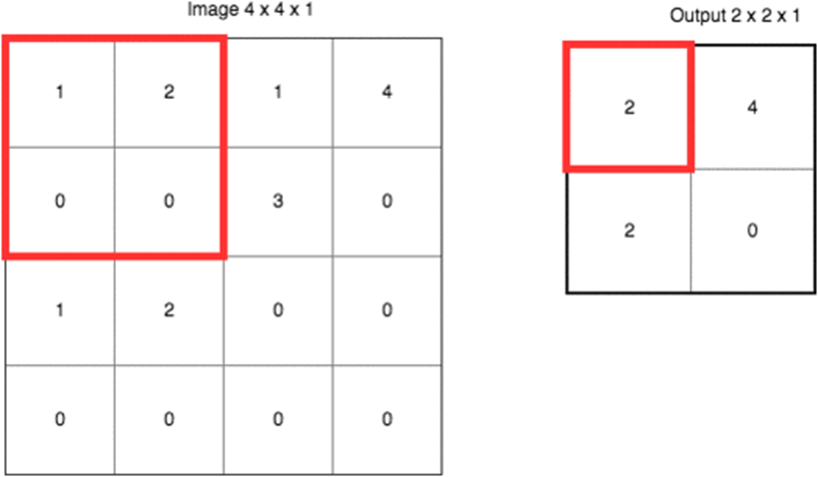
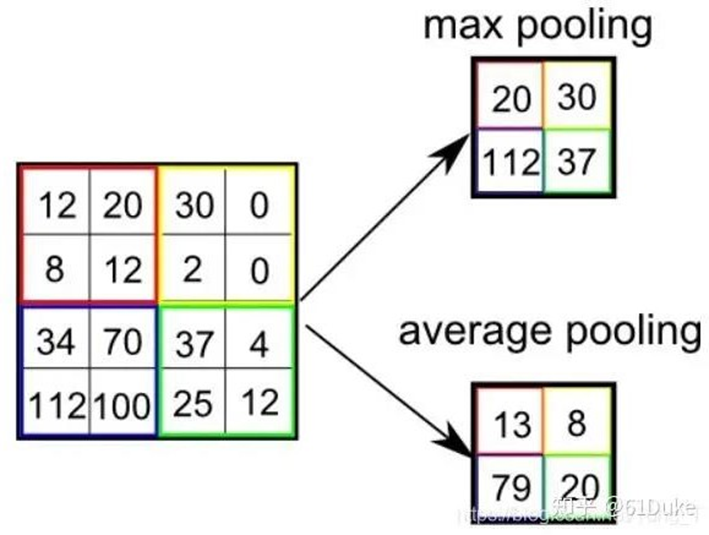
CNN算法框架 - 池化层(技术分析)
池化是一种down-sampling技术,本质是基于滑动窗口的思想,可以去除特征图中的冗余信息,对卷积层结果压缩的到重要特征,同时还可以有效的控制过拟合。池化一般通过简单的“最大值、最小值或平均值”操作完成。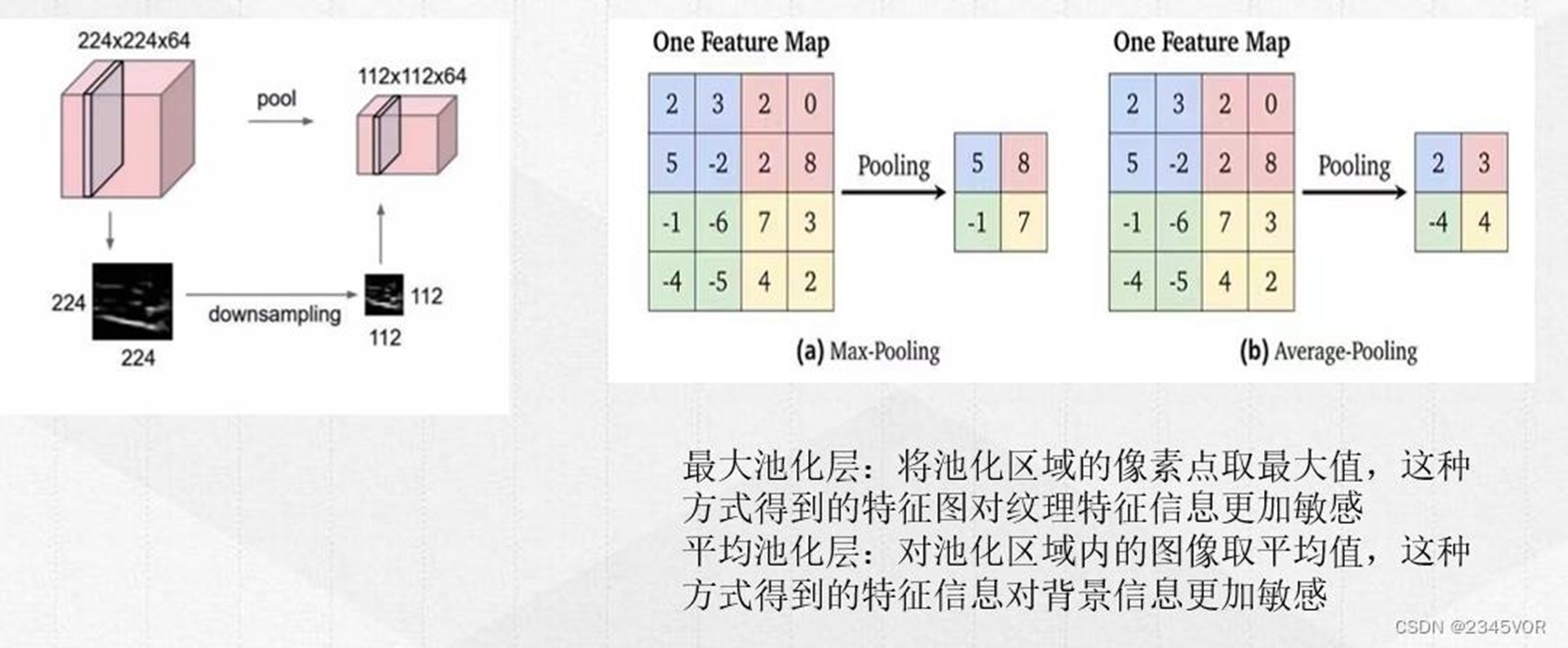
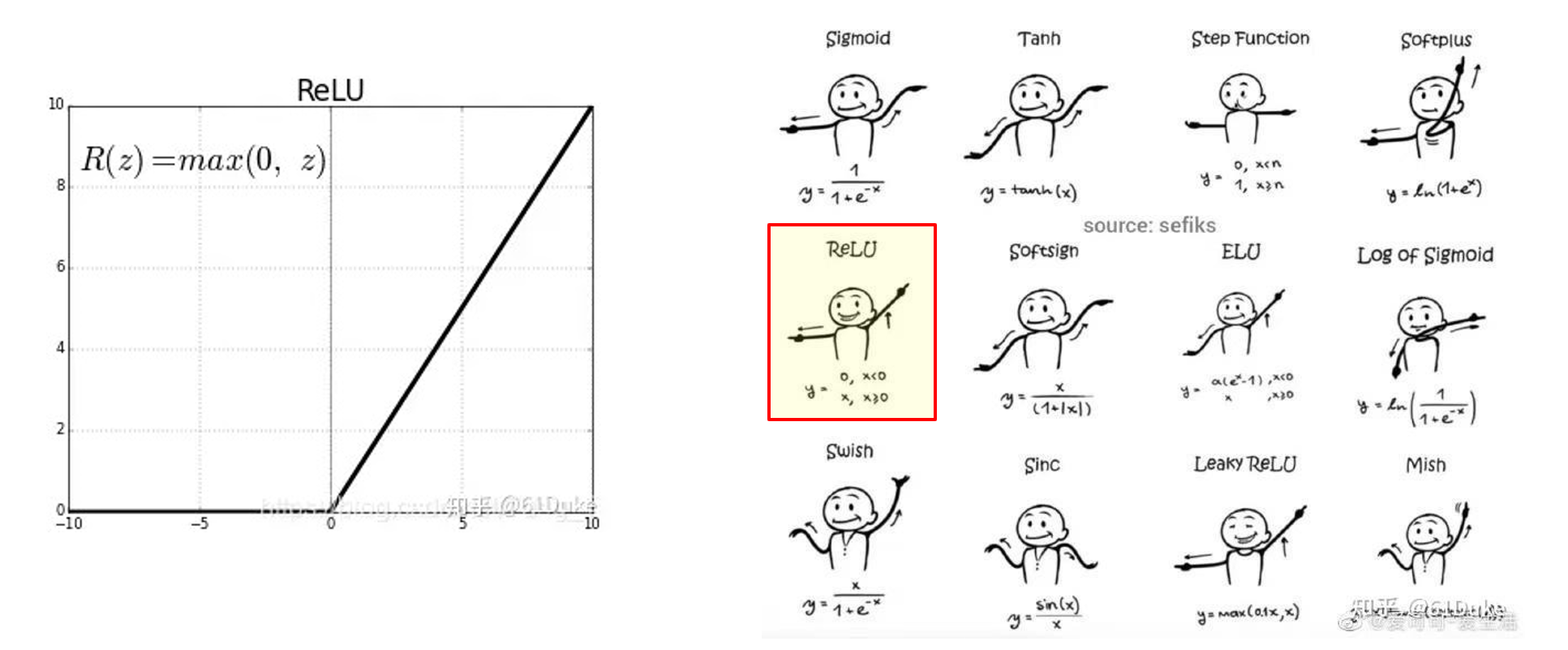
CNN算法框架 - 激活函数
CNN最成功的非线性是整流非线性单元(ReLU),它可以解决sigmoids中出现的消失梯度问题。
缺点:ReLU更容易计算并产生稀疏性(因此,并不总是有益)。
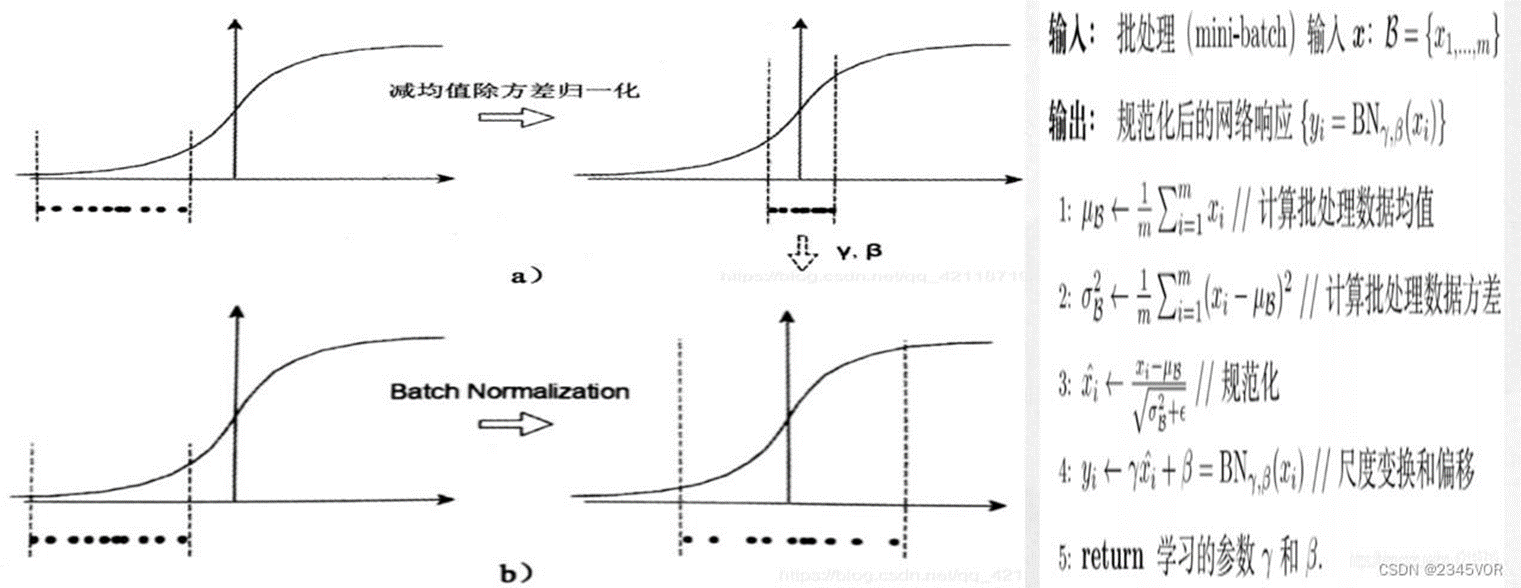
CNN算法框架 - 分批归一化(Batch Nomarliaztion)
为了解决层与层之间传输数据,前面层的数据更新,导致后面层数据分布的变化,会产生网络收敛慢、学习速度降低问题。
分批归一化:简化了计算过程,并保留了原始数据的表达能力。
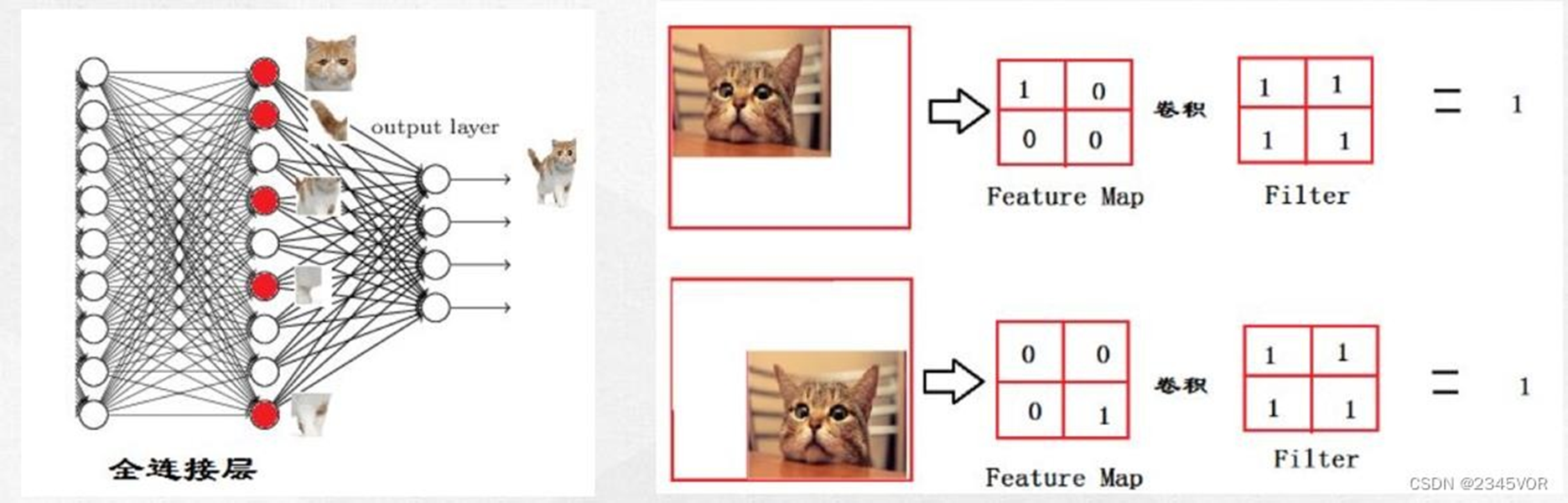
CNN算法框架 - 全连接层 (dense layer)
定义:当一层中的神经元与前一层的所有神经元都相连时,该层则称为全连接层。
主要作用:是将输入图像,在经过卷积和池化操作后提取的特征进行压缩,并且根据压缩的特征,完成模型的分类功能。
对经过多次卷积层和多次池化层所得出来的高级特征进行全连接(全连接就是常规神
经网络的性质),算出最后的预测值。
卷积神经网络CNN - 特点总结
| 类别 | 内容 | 优点 | ||
|---|---|---|---|---|
| 局部感知 | 采用卷积操作实现图像特征提取,具有“局部感知”力。 | 模仿生物的视知觉机制,通过局部感知的方式处理图像。 | ||
| 参数共享 | 指某个特征图中的所有神经元使用相同的“权值和偏置”。 | l可大大减少模型的参数数量和运算时间,提升效率。 l实现了对不同位置上的局部特征的相同处理。 | ||
| 下采样 (池化) | 指在特征映射上定期地探索每个子区域,并简化映射内容,将多个相邻像素的值合并成一个值。 | 可以逐渐降低数据体的空间尺寸,减少网络中参数的数量,使计算资源耗费变少,也能有效控制过拟合。 | ||
| 层次化 表达 | 所提取的特征逐渐由高层次到低层次。(低层提取简单特 征,中间层变得抽象,高层次则更加抽象) | 这种层次化表达使得CNN能从原始输入中提取出从“局部 到全局”的丰富特征。 | ||
| 稀疏连接 | 与传统神经网络的全连接不同,CNN采用稀疏连接方式。 | l这意味着图像中感兴趣特征可能只存在于图像上的一小块,而非整个图像。 l通过使用较小的卷积核,卷积神经网络能够有效地提取出这些特征,同时减少计算量和冗余。 |
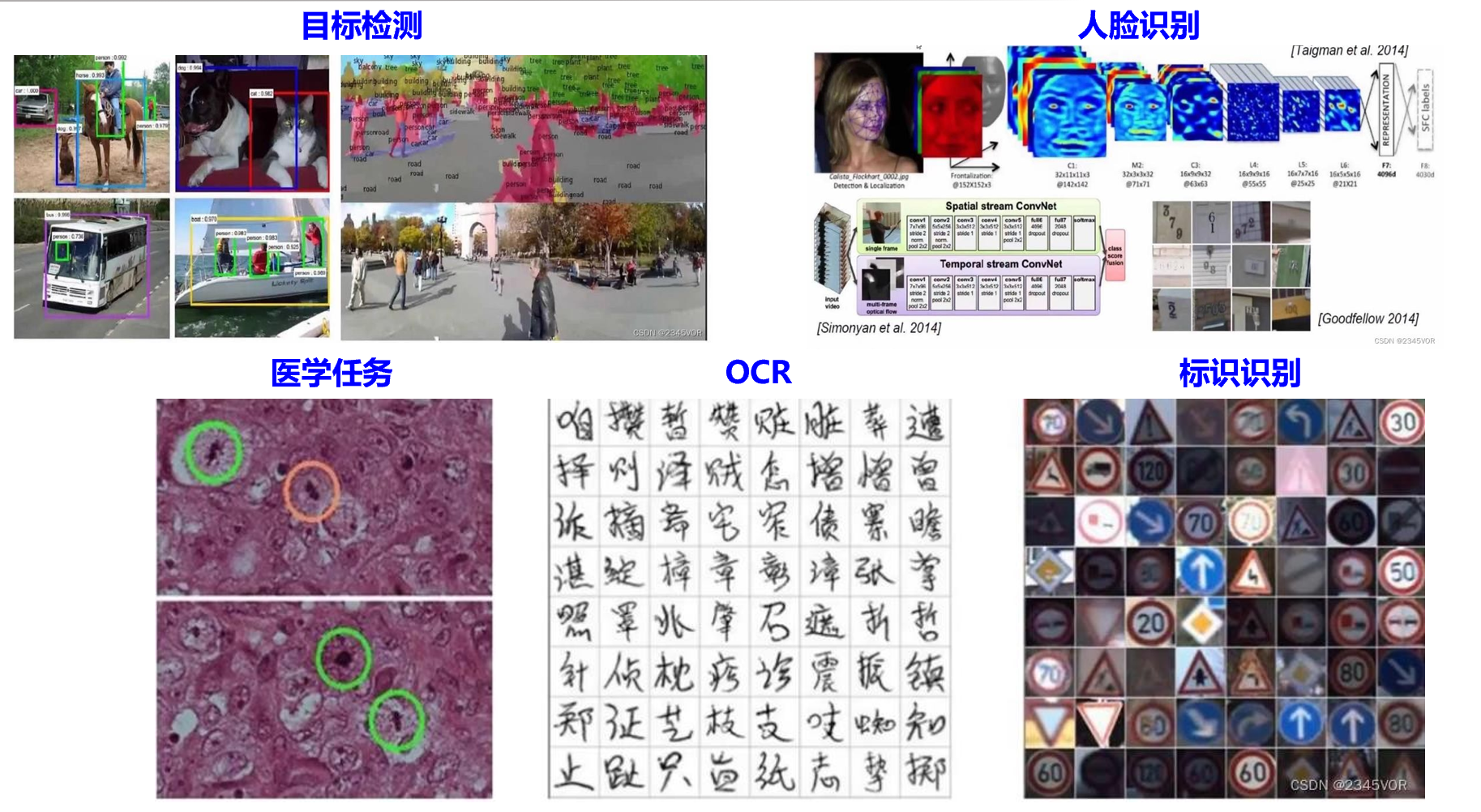
卷积神经网络CNN - 应用