
阅读量:0
大家好,我是微学AI,今天给大家介绍一下人工智能算法工程师(中级)课程14-神经网络的优化与设计之拟合问题及优化与代码详解。在机器学习和深度学习领域,模型的训练目标是找到一组参数,使得模型能够从训练数据中学习到有用的模式,并对未知数据做出准确预测。这一过程涉及到解决两种主要的拟合问题:欠拟合(Underfitting)和过拟合(Overfitting)。
文章目录
一、拟合问题概述
在机器学习领域,拟合问题是指通过训练数据找到最佳模型参数,使得模型在未知数据上的表现尽可能好。拟合问题主要包括欠拟合和过拟合两种现象。
欠拟合现象
定义:欠拟合指的是机器学习模型在训练集上的表现不佳,无法充分学习到数据的内在规律,导致模型的预测能力低下。这就好比一个学生在考试中,由于知识掌握不牢固,对已知题目的解答都做不好,更不用说应对新题目了。
原因分析:
模型复杂度低:如果模型太简单,如用线性模型去拟合非线性的数据分布,那么模型就无法捕捉到数据中的复杂模式,就像用直尺去测量曲线长度一样,永远无法得到准确的结果。
训练数据不足:模型需要足够的数据来学习和概括数据的特性。如果数据量太少,模型可能没有机会接触到数据的全貌,就像从一本书中只读了几页就想理解整本书的内容一样困难。
特征选择不当:如果使用的特征与目标预测无关或相关性弱,模型就难以从中学习到有效的信息,相当于在解决问题时选择了错误的工具。
过拟合现象
定义:过拟合是指模型在训练数据上表现得过于出色,以至于对训练数据中的噪声或偶然性细节也进行了学习,这导致模型在面对未见过的数据时,泛化能力下降。这就像一个学生过分依赖于记忆特定的例题,而没有真正理解背后的原理,因此在遇到稍微变化的问题时就束手无策。
原因分析:
模型复杂度过高:如果模型过于复杂,如高阶多项式回归,它可能会过度适应训练数据中的每一个细节,包括噪声和异常值,而不是学习数据的普遍规律。
训练数据包含噪声:现实世界的数据往往带有噪声,如果模型试图学习这些噪声,就会导致过拟合。这类似于试图从嘈杂的环境中听清对话,噪声会干扰对真实信息的理解。
训练数据量不足:即使模型复杂度适中,但如果训练数据量不够,模型仍然可能过拟合。这是因为数据量不足时,模型可能会把偶然出现的模式误认为是普遍规律。
解决策略
增加模型复杂度:对于欠拟合,可以通过增加模型复杂度来提升模型的学习能力,如使用更高阶的多项式或更复杂的神经网络结构。
增加训练数据量:无论是欠拟合还是过拟合,增加训练数据量都能帮助模型更好地学习数据的分布,提高泛化能力。
特征工程:优化特征选择,确保模型能够基于有意义的特征进行学习。
正则化:使用L1或L2正则化等技术来限制模型复杂度,防止过拟合。
交叉验证:通过交叉验证来评估模型的泛化能力,确保模型不仅在训练数据上表现好,也能在未见数据上给出准确预测。
早停法:在训练过程中监控验证集的性能,一旦发现验证集上的性能不再提升,就停止训练,避免过拟合。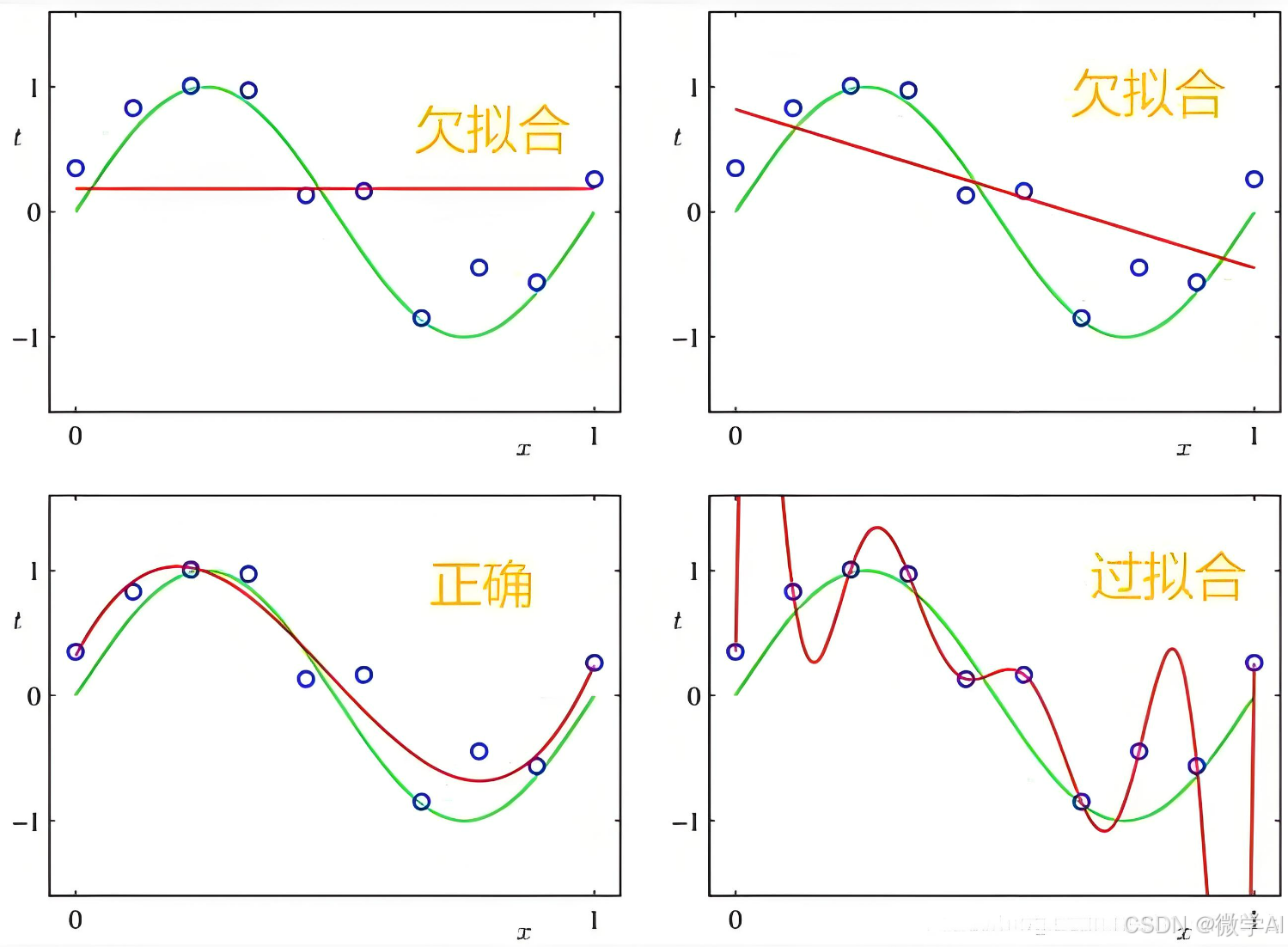
二、正则化方法
为了解决过拟合问题,通常采用正则化方法对模型进行约束。常见的正则化方法有L1正则化和L2正则化。
1. L1正则化
L1正则化的目标函数为:
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + α ∑ j = 1 n ∣ θ j ∣ J(\theta) = \frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)})^2 + \alpha\sum_{j=1}^{n}|\theta_j| J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+αj=1∑n∣θj∣
其中,第一项为损失函数,第二项为L1正则化项, α \alpha α为惩罚系数, θ j \theta_j θj为模型参数。
2. L2正则化
L2正则化的目标函数为:
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + α 2 ∑ j = 1 n θ j 2 J(\theta) = \frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)})^2 + \frac{\alpha}{2}\sum_{j=1}^{n}\theta_j^2 J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+2αj=1∑nθj2
其中,第一项为损失函数,第二项为L2正则化项, α \alpha α为惩罚系数, θ j \theta_j θj为模型参数。
三、正则化参数的更新
在优化目标函数时,我们需要对正则化参数进行更新。以下为L2正则化的参数更新公式:
θ j : = θ j − α ( 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ θ j ) \theta_j := \theta_j - \alpha\left(\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)})x_j^{(i)} + \lambda\theta_j\right) θj:=θj−α(m1i=1∑m(hθ(x(i))−y(i))xj(i)+λθj)
其中, λ = α m \lambda = \frac{\alpha}{m} λ=mα为正则化参数。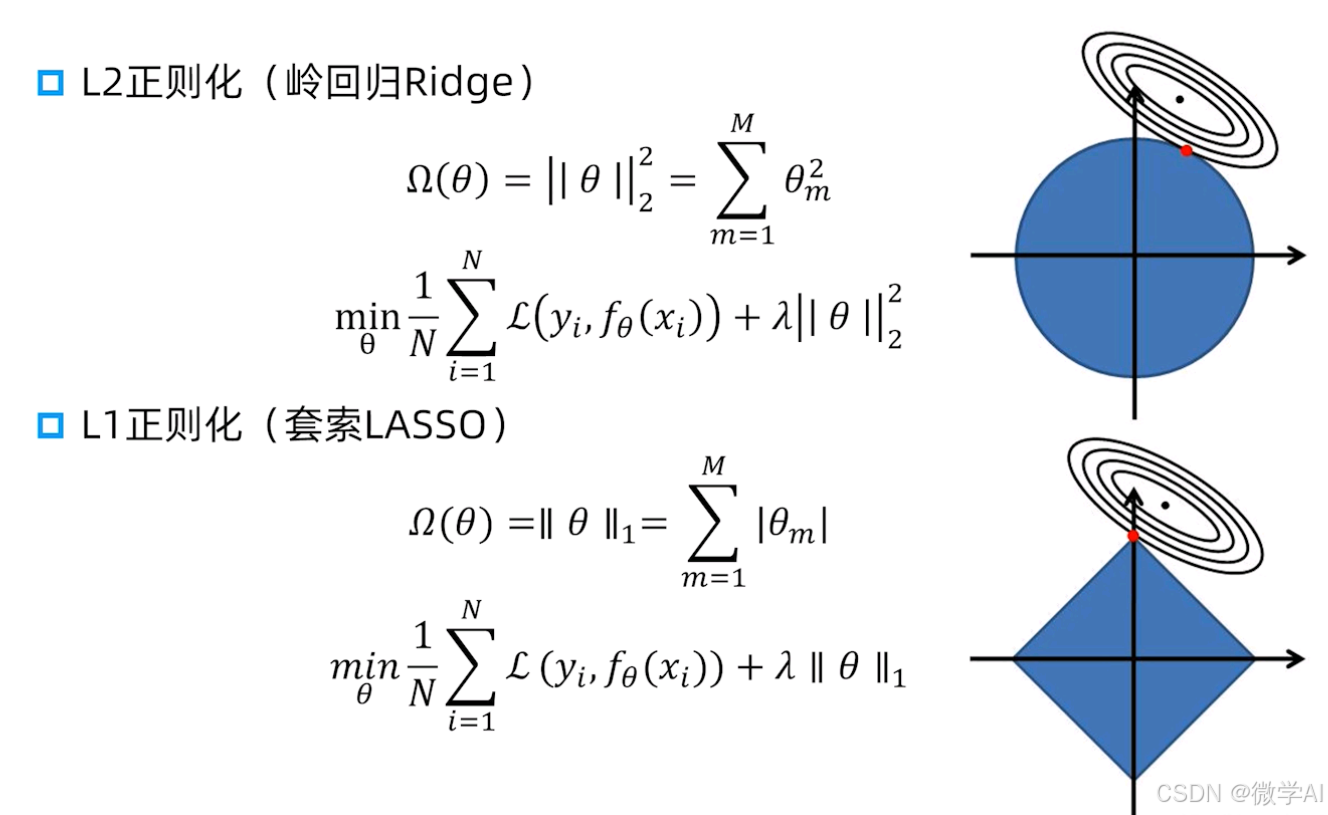
四、Dropout
Dropout是一种有效的正则化方法,通过在训练过程中随机丢弃部分神经元,来减少模型对特定训练样本的依赖。以下是Dropout的实现步骤:
(1)在训练过程中,按照一定概率随机丢弃神经元;
(2)在测试过程中,将所有神经元的输出乘以概率因子。
五、代码实现
以下是基于PyTorch的拟合问题及优化代码实现:
import torch import torch.nn as nn import torch.optim as optim # 定义模型 class LinearRegression(nn.Module): def __init__(self, input_dim, output_dim): super(LinearRegression, self).__init__() self.linear = nn.Linear(input_dim, output_dim) def forward(self, x): return self.linear(x) # 生成数据 x = torch.randn(100, 1) y = 3 * x + 2 + torch.randn(100, 1) # 实例化模型 model = LinearRegression(1, 1) # 定义损失函数和优化器 criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.01) # L2正则化 # 训练模型 num_epochs = 100 for epoch in range(num_epochs): model.train() optimizer.zero_grad() outputs = model(x) loss = criterion(outputs, y) loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}') # 测试模型 model.eval() with torch.no_grad(): predicted = model(x).detach().numpy() print(f'预测值:{predicted}') 通过本文的介绍,相信大家对拟合问题及优化方法有了更深入的了解。在实际应用中,可根据数据特点选择合适的正则化方法,以提高模型的泛化能力。
