
常用的实验结果评价指标(1) —— R2(R-square),可能为负数吗?!
提示:先说概念,后续再陆续上代码
文章目录
- 常用的实验结果评价指标(1) —— R2(R-square),可能为负数吗?!
- 前言
- 一、R2 基本概念
- 二、R2的适用场景是什么?
- 三、R2是否适用于强非线性数据?如果不适用,有无替代?
- 四、R-square的取值范围有没有可能出现负数?
前言
各类论文的实验结果中经常会有R2作为评价指标,本篇就是为了搞清楚R2究竟是什么,什么时候能用,什么时候不能用。
一、R2 基本概念
1. R2 是什么?
R2/R平方(R-squared),也称为决定系数,是统计学中的一个重要概念,用于衡量一个统计模型预测能力的好坏。它主要用于回归分析中,可以解释响应变量的变异由自变量的变异解释的比例。R-squared (R2) 的值范围从0到1,其中较高的值表明模型能更好地解释数据变异。
2. R2 的起源
R2 的概念起源于统计学的回归分析,它是在20世纪初期由统计学家们发展起来的。尤其是与最小二乘法(Ordinary Least Squares, OLS)相关的统计方法的发展,推动了R2作为衡量模型拟合优度的一个标准的产生。
3. R2 的计算公式
R2的计算公式可以表示为:
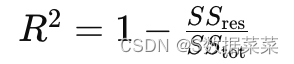
其中
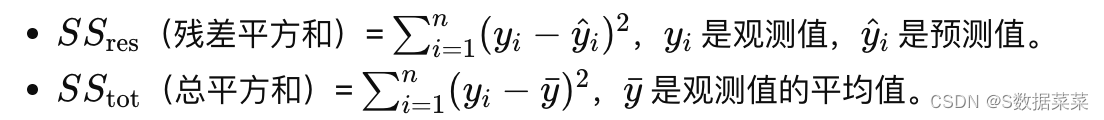
4. R2 是为了衡量或评价什么?
R2 用于衡量自变量对因变量变异的解释程度。具体来说:
- 当 R2 = 1 时,表示 模型完美地解释了所有的数据变异。
- 当 R2越小,标明模型解释的变异比较小,简单来说,即模型的拟合效果不佳。
总的来说,R2 是用来评价模型的解释能力和预测能力的一个指标,它帮助研究人员和分析师理解模型对现实数据变动的捕捉程度。
二、R2的适用场景是什么?
R2主要适用于量化线性回归模型的拟合优度,即衡量模型预测的因变量的值在多大程度上能够接近实际观测值。它被广泛用于统计分析和机器学习中,尤其是在评估线性关系强度时。
R2的适用场景:
- 线性回归分析:在简单线性回归和多元线性回归中,R平方是衡量模型解释数据变异的常用指标。
- 模型比较:比较不同模型对相同数据集的拟合效果时,可以使用R平方作为衡量标准之一。
三、R2是否适用于强非线性数据?如果不适用,有无替代?
1. R2不适用于强非线性数据
对于非线性数据,R2的解释能力和适用性可能受限。尽管R2可以在技术上计算出非线性模型的拟合优度,但它可能不足以全面反映模型的效能,因为:
- 非线性复杂性:非线性关系可能导致数据的变异方式与线性模型假设不匹配,这使得使用R平方来解释模型性能可能会产生误导。
- 过拟合风险:在非线性模型中,过度复杂的模型可能会很好地拟合训练数据(即高R平方值),但可能不具有良好的泛化能力,即在新的、未见过的数据上表现不佳。
2. 强非线性数据时,R2的替代指标
在处理强非线性数据时,可能需要使用其他更适合的统计量或信息标准来评估模型的性能,例如:
- 调整后的R平方:对自由度进行调整,可以部分补偿模型复杂度增加的影响。
- 赤池信息准则(AIC):考虑到模型的复杂度,帮助选择最佳模型。
- 贝叶斯信息准则(BIC):与AIC类似,但对模型参数的惩罚更重,适用于模型选择。
- 均方误差(MSE) 或 均方根误差(RMSE):直接衡量模型预测值与实际值之间的误差。
在非线性问题中,选择合适的评估指标是至关重要的,这可以帮助更准确地理解模型的实际表现和适用范围。
四、R-square的取值范围有没有可能出现负数?
是可能的!!!
R2的取值范围理论上是从0到1,但在某些情况下,确实可能出现负数的R2。这通常发生在模型的预测效果非常差,甚至比使用简单的平均值还要糟糕的情况下。
1. 出现负R平方值的情况
- 模型不适当:如果选用的模型不适合处理给定的数据集,或者模型假设与数据的真实关系不符,模型的预测可能会非常差。
- 数据异常:数据中的异常值或极端值可能扭曲了模型的性能评估。
- 过度复杂的模型:在数据点较少的情况下,过于复杂的模型可能导致过拟合,使得模型在新数据上的预测效果很差。
2. 应对措施
如果出现负的R2,这通常是一个信号,表明需要重新评估所选模型的适用性或调整模型参数。可能的措施包括:
- 更换模型:考虑使用不同类型的模型,特别是如果当前模型假设与数据的实际关系不符。
- 数据预处理:清理数据,处理异常值和缺失值,尝试不同的数据变换。
- 简化模型:减少模型复杂度,使用较少的变量或参数。
总的来说,R2为负是一个重要的指标,提示模型可能不适用或需要进一步调整。