
阅读量:2
AGI 之 【Hugging Face】 的【零样本和少样本学习】之三 [无标注数据] 的简单整理
目录
AGI 之 【Hugging Face】 的【零样本和少样本学习】之三 [无标注数据] 的简单整理
二、零样本学习 (Zero-shot Learning) 和少样本学习 (Few-shot Learning)
一、简单介绍
AGI,即通用人工智能(Artificial General Intelligence),是一种具备人类智能水平的人工智能系统。它不仅能够执行特定的任务,而且能够理解、学习和应用知识于广泛的问题解决中,具有较高的自主性和适应性。AGI的能力包括但不限于自我学习、自我改进、自我调整,并能在没有人为干预的情况下解决各种复杂问题。
- AGI能做的事情非常广泛:
跨领域任务执行:AGI能够处理多领域的任务,不受限于特定应用场景。
自主学习与适应:AGI能够从经验中学习,并适应新环境和新情境。
创造性思考:AGI能够进行创新思维,提出新的解决方案。
社会交互:AGI能够与人类进行复杂的社会交互,理解情感和社会信号。
- 关于AGI的未来发展前景,它被认为是人工智能研究的最终目标之一,具有巨大的变革潜力:
技术创新:随着机器学习、神经网络等技术的进步,AGI的实现可能会越来越接近。
跨学科整合:实现AGI需要整合计算机科学、神经科学、心理学等多个学科的知识。
伦理和社会考量:AGI的发展需要考虑隐私、安全和就业等伦理和社会问题。
增强学习和自适应能力:未来的AGI系统可能利用先进的算法,从环境中学习并优化行为。
多模态交互:AGI将具备多种感知和交互方式,与人类和其他系统交互。
Hugging Face作为当前全球最受欢迎的开源机器学习社区和平台之一,在AGI时代扮演着重要角色。它提供了丰富的预训练模型和数据集资源,推动了机器学习领域的发展。Hugging Face的特点在于易用性和开放性,通过其Transformers库,为用户提供了方便的模型处理文本的方式。随着AI技术的发展,Hugging Face社区将继续发挥重要作用,推动AI技术的发展和应用,尤其是在多模态AI技术发展方面,Hugging Face社区将扩展其模型和数据集的多样性,包括图像、音频和视频等多模态数据。
- 在AGI时代,Hugging Face可能会通过以下方式发挥作用:
模型共享:作为模型共享的平台,Hugging Face将继续促进先进的AGI模型的共享和协作。
开源生态:Hugging Face的开源生态将有助于加速AGI技术的发展和创新。
工具和服务:提供丰富的工具和服务,支持开发者和研究者在AGI领域的研究和应用。
伦理和社会责任:Hugging Face注重AI伦理,将推动负责任的AGI模型开发和应用,确保技术进步同时符合伦理标准。
AGI作为未来人工智能的高级形态,具有广泛的应用前景,而Hugging Face作为开源社区,将在推动AGI的发展和应用中扮演关键角色。
(注意:以下代码运行,可能需要科学上网)
二、零样本学习 (Zero-shot Learning) 和少样本学习 (Few-shot Learning)
1、零样本学习 (Zero-shot Learning)
定义: 零样本学习是一种让模型能够在没有见过目标类别数据的情况下进行预测的技术。它主要依赖于预训练的语言模型和自然语言描述,利用模型在预训练期间学到的广泛知识来理解和推断新的任务。
实现方式:
- 基于语言模型的零样本分类: 使用预训练的语言模型,如 BERT、GPT-3,通过自然语言提示 (prompt) 进行分类。Hugging Face 提供了
zero-shot-classificationpipeline,使这一过程非常简单。from transformers import pipeline # 加载零样本分类 pipeline zero_shot_classifier = pipeline("zero-shot-classification") # 定义待分类的文本 text = "Hugging Face's library is so easy to use!" # 定义候选标签 labels = ["education", "politics", "technology"] # 进行零样本分类 result = zero_shot_classifier(text, candidate_labels=labels) print(result)
- 利用嵌入向量和距离度量: 通过计算文本嵌入向量之间的相似度来实现零样本分类。模型在预训练期间学到的嵌入空间使得相似类别的文本在向量空间中更接近。
- 自然语言推理 (NLI): 使用 NLI 模型,如 RoBERTa,对于每个候选标签,模型判断该标签是否是输入文本的合理推断。Hugging Face 提供了类似的模型,可以通过 NLI 的方式实现零样本学习。
from transformers import pipeline # 加载 NLI 模型 nli_model = pipeline("zero-shot-classification", model="facebook/bart-large-mnli") # 定义待分类的文本 text = "Hugging Face's library is so easy to use!" # 定义候选标签 labels = ["education", "politics", "technology"] # 进行零样本分类 result = nli_model(text, candidate_labels=labels) print(result)
2、少样本学习 (Few-shot Learning)
定义: 少样本学习是一种让模型能够在只见过少量目标类别数据的情况下进行有效预测的技术。它通过对预训练模型进行微调,利用少量标注数据来学习新的任务。
实现方式:
- 基于预训练模型的微调: 使用预训练的 Transformer 模型(如 BERT、GPT-3),通过少量标注数据进行微调。Hugging Face 提供了
TrainerAPI,可以方便地进行微调。from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments from datasets import Dataset # 示例少样本数据 data = { "text": ["I love using Hugging Face!", "The library is very intuitive."], "label": [1, 1] } # 创建 Dataset 对象 dataset = Dataset.from_dict(data) # 加载预训练模型和分词器 model_name = "bert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2) # 数据预处理 def preprocess_data(examples): return tokenizer(examples["text"], truncation=True, padding=True) tokenized_dataset = dataset.map(preprocess_data, batched=True) # 设置训练参数 training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=2, logging_dir="./logs", ) # 创建 Trainer 实例 trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset ) # 开始训练 trainer.train()
- Prompt-based 学习: 通过设计好的提示语(prompts)进行少样本学习,将少量数据转化为对模型的提示。这个方法在 GPT-3 等模型上表现出色。
- 元学习 (Meta-learning): 利用元学习算法,如 MAML (Model-Agnostic Meta-Learning),训练模型在少量新数据上快速适应。虽然 Hugging Face 目前没有直接的元学习 API,但可以结合 PyTorch 等库实现。
零样本学习和少样本学习是解决数据有限情况下进行有效机器学习的重要方法。通过使用 Hugging Face 提供的预训练模型和工具,可以轻松实现这两种技术:
- 零样本学习: 依赖于预训练语言模型,通过自然语言提示或嵌入向量实现分类和推理。
- 少样本学习: 通过微调预训练模型或使用提示语进行学习,以适应新的任务和数据。
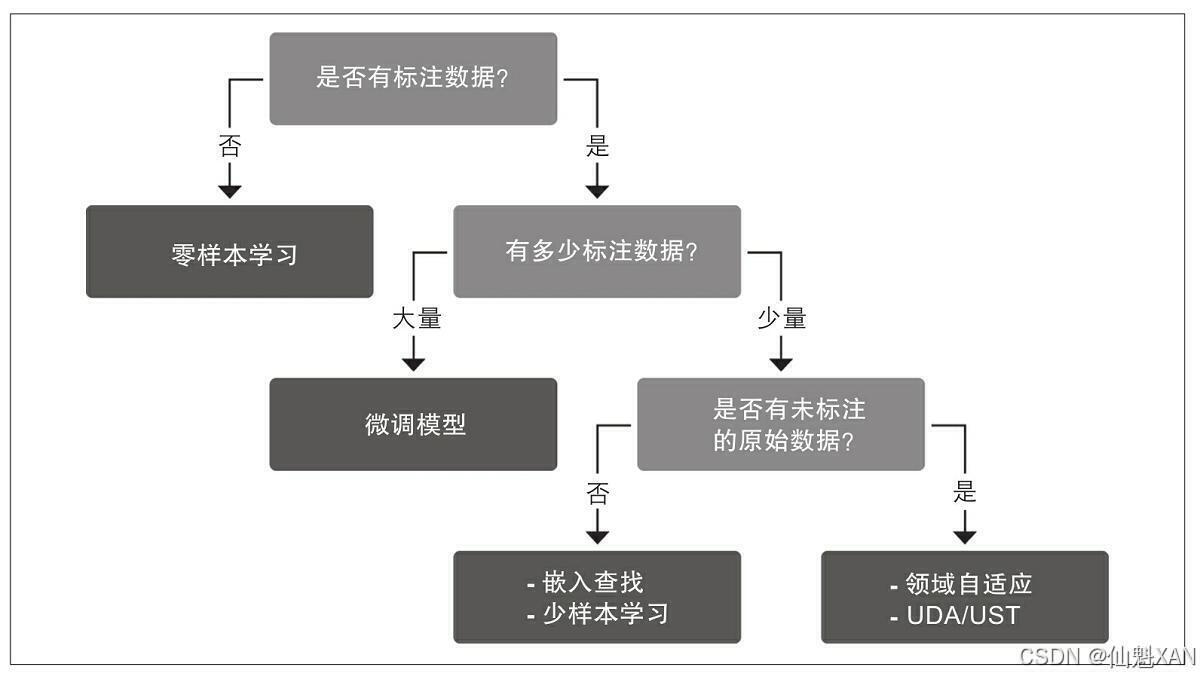
三、利用无标注数据
尽管训练分类器的最佳方式是依靠大量的标注数据,但是这并不意味着无标注数据就是毫无价值的。回想一下我们知道的大多数模型的预训练:即使它们几乎是基于互联网的不相关数据来训练的,我们也可以利用预训练权重来用在其他各种文本任务,这就是NLP领域中迁移学习的核心思想。自然地,如果下游任务的文本结构与预训练的文本相似,那么迁移的效果会更好。所以如果我们能使预训练任务更接近下游任务,就有可能提高模型迁移的整体效果。
本节我们将借助具体的案例来思考这个问题:BERT已在BookCorpus和English Wikipedia上进行了预训练,而包含代码的GitHub issue文本只是一个小众数据集。如果从头开始预训练BERT,则可以在抓取GitHub的所有issue时就开始进行。但是,这种方法是昂贵的,而且BERT学到的关于语言的特征针对GitHub issue有效。那么在重新训练模型和使用现成的模型之间有没有一个折中方案呢?答案是有的,这种方案叫作领域自适应(我们在第7章中的问答领域介绍过)。与其从头开始重新训练语言模型,不如基于其领域数据继续训练它。我们使用本章之前介绍过的预测掩码词元的语言模型,这也就意味着不需要任何标注数据。之后,我们可以将适应后的模型加载为分类器,并对其微调,以此来利用未标注的数据。
与使用标注数据相比,领域自适应的好处是即使使用未标注数据,其也是大量可用的。此外,适应过后的模型也可以在其他用例中重复使用。试想一下,你想构建一个电子邮件分类器,并对你的所有历史邮件使用领域自适应,之后就可以将此模型用于NER或另一个分类任务,比如情感分析,因为该方法对于下游任务是不可知的。
下面我们将微调一个预训练的语言模型。
1、语言模型的微调
在本节中,我们将在数据集的未标注部分用掩码语言建模来微调经过预训练的BERT模型。为了做到这一点,我们需要了解两个新概念:在对数据进行词元化时的一个额外步骤;一个特殊的数据整理器。下面我们从词元化开始讲解。
除了文本中的普通词元外,词元分析器还将特殊词元添加到序列中,比如用于分类和下句预测的[CLS]词元和[SEP]词元。当我们进行掩码语言建模时,需要确保训练的模型不会用来预测这些词元。出于这个原因,我们需要将它们从损失函数中掩码掉,通过设置return_special_tokens_mask=True即可。下面用这个参数对文本进行重新词元化:
# 定义一个函数来对数据集中的批次进行分词处理 def tokenize(batch): return tokenizer(batch["text"], truncation=True, max_length=128, return_special_tokens_mask=True) # 对数据集执行批量分词处理 ds_mlm = ds.map(tokenize, batched=True) # 移除数据集中的标签、文本和标签ID列,保留仅嵌入和特殊标记掩码 ds_mlm = ds_mlm.remove_columns(["labels", "text", "label_ids"]) 运行结果:

在进行掩码语言建模的时候,缺的是掩码输入序列中的词元并在输出中包含目标词元的机制。我们可以采取的一种方法是,引入一个可以掩码随机词元的函数,并为序列创建标注。但这会使数据集的大小增加一倍,因为我们需要在数据集中存储目标序列,所以这也意味着我们将在每轮(epoch)都使用相同的序列掩码。
有一个比较优雅的解决方案,即使用数据整理器。需要记住,数据整理器是在数据集和模型调用之间建立桥梁的函数。从数据集中采样一个批量的数据,数据整理器准备批量中的元素以将其提供给模型。在我们遇到的最简单的例子中,它只是将每个元素的张量拼接成单个张量。在本节的案例中,我们可以使用它来动态地进行掩码和标注生成。这样我们就不需要存储标注,而且每次采样都会得到新的掩码。这个任务的数据整理器叫作DataCollatorForLanguageModeling,我们可以使用模型的词元分析器和通过mlm_probability参数掩码的词元来初始化它。下面我们将使用这个整理器来掩码15%的词元,这与BERT论文中描述的一致:
# 导入DataCollatorForLanguageModeling和set_seed函数 from transformers import DataCollatorForLanguageModeling, set_seed # 创建一个用于语言建模的数据收集器,使用给定的分词器和MLM概率 data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15) 我们快速看一下数据整理器的运行情况,看看它到底做了什么操作。为了在DataFrame中快速显示出结果,我们将词元分析器和数据整理器的返回格式切换为NumPy:
# 设置随机种子为3,以确保结果的可重复性 set_seed(3) # 设置数据收集器的返回张量类型为NumPy数组 data_collator.return_tensors = "np" # 使用分词器对文本进行编码,并通过数据收集器处理 inputs = tokenizer("Transformers are awesome!", return_tensors="np") outputs = data_collator([{"input_ids": inputs["input_ids"][0]}]) # 提取原始和掩码后的输入标记ID original_input_ids = inputs["input_ids"][0] masked_input_ids = outputs["input_ids"][0] # 创建包含各列数据的DataFrame,便于展示 pd.DataFrame({ "Original tokens": tokenizer.convert_ids_to_tokens(original_input_ids), "Masked tokens": tokenizer.convert_ids_to_tokens(masked_input_ids), "Original input_ids": original_input_ids, "Masked input_ids": masked_input_ids, "Labels": outputs["labels"][0]}).T 运行结果:
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| Original tokens | [CLS] | transformers | are | awesome | ! | [SEP] |
| Masked tokens | [CLS] | transformers | are | awesome | [MASK] | [SEP] |
| Original input_ids | 101 | 19081 | 2024 | 12476 | 999 | 102 |
| Masked input_ids | 101 | 19081 | 2024 | 12476 | 103 | 102 |
| Labels | -100 | -100 | -100 | -100 | 999 | -100 |
从结果可以看到,对应于感叹号的词元已经被替换成了一个掩码词元。另外,数据整理器返回了一个标注数组,其中原始词元为-100,被掩码的词元则为词元的ID。我们还可以明显看出,在计算损失时,包含-100的条目则被忽略掉。下面我们把数据整理器的格式换回PyTorch:
# 设置数据收集器返回张量类型为PyTorch张量 data_collator.return_tensors = "pt" 有了词元分析器和数据整理器,我们就可以对掩码语言模型进行微调了。我们照常设置TrainingArguments和Trainer:
# 导入AutoModelForMaskedLM类 from transformers import AutoModelForMaskedLM # 定义训练参数 training_args = TrainingArguments( output_dir=f"{model_ckpt}-issues-128", # 指定训练结果输出目录 per_device_train_batch_size=32, # 每个设备的训练批次大小 logging_strategy="epoch", # 日志记录频率设为每轮 evaluation_strategy="epoch", # 模型评估频率设为每轮 save_strategy="no", # 不保存模型中间结果 num_train_epochs=16, # 训练的总轮数 push_to_hub=False, # 是否将模型推送到 Hugging Face Hub log_level="error", # 设置日志级别为错误级别 report_to="none" # 不向任何地方报告训练进度 ) # 创建Trainer对象进行训练 trainer = Trainer( model=AutoModelForMaskedLM.from_pretrained("bert-base-uncased"), # 加载预训练的BERT模型用于Masked Language Modeling tokenizer=tokenizer, # 使用的分词器 args=training_args, # 使用定义好的训练参数 data_collator=data_collator, # 数据收集器,用于批处理数据 train_dataset=ds_mlm["unsup"], # 训练数据集为未标记的数据集 eval_dataset=ds_mlm["train"] # 评估数据集为训练集,用于评估模型训练进度 ) # 开始训练 trainer.train() # 推送到远端 Hugging Face Hub trainer.push_to_hub("Training complete!")运行结果:
{'loss': 2.0996, 'learning_rate': 4.6875e-05, 'epoch': 1.0} {'eval_loss': 1.7033042907714844, 'eval_runtime': 0.8827, 'eval_samples_per_second': 252.641, 'eval_steps_per_second': 31.722, 'epoch': 1.0} {'loss': 1.6382, 'learning_rate': 4.375e-05, 'epoch': 2.0} {'eval_loss': 1.4360285997390747, 'eval_runtime': 0.8686, 'eval_samples_per_second': 256.729, 'eval_steps_per_second': 32.235, 'epoch': 2.0} {'loss': 1.485, 'learning_rate': 4.0625000000000005e-05, 'epoch': 3.0} {'eval_loss': 1.391833782196045, 'eval_runtime': 0.8654, 'eval_samples_per_second': 257.682, 'eval_steps_per_second': 32.355, 'epoch': 3.0} {'loss': 1.3983, 'learning_rate': 3.7500000000000003e-05, 'epoch': 4.0} {'eval_loss': 1.3651131391525269, 'eval_runtime': 0.9359, 'eval_samples_per_second': 238.271, 'eval_steps_per_second': 29.917, 'epoch': 4.0} {'loss': 1.341, 'learning_rate': 3.4375e-05, 'epoch': 5.0} {'eval_loss': 1.1853851079940796, 'eval_runtime': 0.8649, 'eval_samples_per_second': 257.843, 'eval_steps_per_second': 32.375, 'epoch': 5.0} {'loss': 1.2824, 'learning_rate': 3.125e-05, 'epoch': 6.0} {'eval_loss': 1.2844164371490479, 'eval_runtime': 0.8905, 'eval_samples_per_second': 250.428, 'eval_steps_per_second': 31.444, 'epoch': 6.0} {'loss': 1.2403, 'learning_rate': 2.8125000000000003e-05, 'epoch': 7.0} {'eval_loss': 1.2549198865890503, 'eval_runtime': 0.9004, 'eval_samples_per_second': 247.655, 'eval_steps_per_second': 31.096, 'epoch': 7.0} {'loss': 1.2, 'learning_rate': 2.5e-05, 'epoch': 8.0} {'eval_loss': 1.216525673866272, 'eval_runtime': 0.8883, 'eval_samples_per_second': 251.037, 'eval_steps_per_second': 31.52, 'epoch': 8.0} {'loss': 1.1661, 'learning_rate': 2.1875e-05, 'epoch': 9.0} {'eval_loss': 1.1880288124084473, 'eval_runtime': 0.878, 'eval_samples_per_second': 253.985, 'eval_steps_per_second': 31.89, 'epoch': 9.0} {'loss': 1.141, 'learning_rate': 1.8750000000000002e-05, 'epoch': 10.0} {'eval_loss': 1.2314234972000122, 'eval_runtime': 0.9038, 'eval_samples_per_second': 246.726, 'eval_steps_per_second': 30.979, 'epoch': 10.0} {'loss': 1.1276, 'learning_rate': 1.5625e-05, 'epoch': 11.0} {'eval_loss': 1.2082805633544922, 'eval_runtime': 0.9053, 'eval_samples_per_second': 246.317, 'eval_steps_per_second': 30.928, 'epoch': 11.0} {'loss': 1.1037, 'learning_rate': 1.25e-05, 'epoch': 12.0} {'eval_loss': 1.1679879426956177, 'eval_runtime': 0.9104, 'eval_samples_per_second': 244.959, 'eval_steps_per_second': 30.757, 'epoch': 12.0} {'loss': 1.0786, 'learning_rate': 9.375000000000001e-06, 'epoch': 13.0} {'eval_loss': 1.245760440826416, 'eval_runtime': 0.96, 'eval_samples_per_second': 232.291, 'eval_steps_per_second': 29.167, 'epoch': 13.0} {'loss': 1.0799, 'learning_rate': 6.25e-06, 'epoch': 14.0} {'eval_loss': 1.1623947620391846, 'eval_runtime': 1.1769, 'eval_samples_per_second': 189.486, 'eval_steps_per_second': 23.792, 'epoch': 14.0} {'loss': 1.0636, 'learning_rate': 3.125e-06, 'epoch': 15.0} {'eval_loss': 1.1255277395248413, 'eval_runtime': 1.2458, 'eval_samples_per_second': 178.995, 'eval_steps_per_second': 22.475, 'epoch': 15.0} {'loss': 1.0639, 'learning_rate': 0.0, 'epoch': 16.0} {'eval_loss': 1.251034140586853, 'eval_runtime': 0.8711, 'eval_samples_per_second': 256.007, 'eval_steps_per_second': 32.144, 'epoch': 16.0} {'train_runtime': 3370.5456, 'train_samples_per_second': 44.161, 'train_steps_per_second': 1.381, 'train_loss': 1.2818299978459413, 'epoch': 16.0} TrainOutput(global_step=4656, training_loss=1.2818299978459413, metrics={'train_runtime': 3370.5456, 'train_samples_per_second': 44.161, 'train_steps_per_second': 1.381, 'train_loss': 1.2818299978459413, 'epoch': 16.0}) 我们可以访问trainer的日志记录,来查看模型的训练集损失和验证集损失。所有日志都存储在trainer.state.log_history中,它是一个字典表,可以很容易被加载到Pandas DataFrame中。由于训练集损失和验证集损失是在不同的步骤中被记录的,所以在DataFrame中存在缺失值。出于这个原因,我们在绘制指标之前,先把缺失的值删除:
import pandas as pd import matplotlib.pyplot as plt # 从 Trainer 的状态日志中创建 DataFrame df_log = pd.DataFrame(trainer.state.log_history) # 绘制验证集损失 df_log.dropna(subset=["eval_loss"]).reset_index()["eval_loss"].plot(label="Validation") # 绘制训练集损失 df_log.dropna(subset=["loss"]).reset_index()["loss"].plot(label="Train") # 设置图表标签和图例 plt.xlabel("Epochs") plt.ylabel("Loss") plt.legend(loc="upper right") # 保存图表为文件,并设置自适应大小 plt.savefig('images/eval_loss.png', bbox_inches='tight') # 显示图表 plt.show() 运行结果:
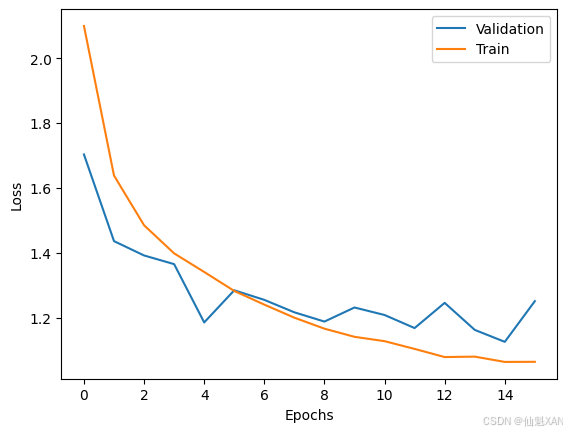
从结果看来,训练集损失和验证集损失都大大降低了。所以我们来检验一下,当基于这个模型对分类器进行微调时,能否获得效果提升。
2、分类器的微调
现在我们来重复微调操作,但有些许不同的是,我们将加载自定义的checkpoint:
# 更新模型检查点路径 model_ckpt = f'{model_ckpt}-issues-128' # 从模型检查点加载配置,并设置适用于多标签分类的参数 config = AutoConfig.from_pretrained(model_ckpt) config.num_labels = len(all_labels) config.problem_type = "multi_label_classification" # 遍历训练集切片进行微调 for train_slice in train_slices: # 从预训练模型加载序列分类模型 model = AutoModelForSequenceClassification.from_pretrained(model_ckpt, config=config) # 创建 Trainer 对象用于训练 trainer = Trainer( model=model, tokenizer=tokenizer, args=training_args_fine_tune, compute_metrics=compute_metrics, train_dataset=ds_enc["train"].select(train_slice), eval_dataset=ds_enc["valid"], ) # 执行训练过程 trainer.train() # 在测试集上进行预测并计算评估指标 pred = trainer.predict(ds_enc['test']) metrics = compute_metrics(pred) # 将微调后的宏 F1 和微 F1 分数添加到相应列表中,标记为领域适应 Fine-tune (DA) macro_scores['Fine-tune (DA)'].append(metrics['macro f1']) micro_scores['Fine-tune (DA)'].append(metrics['micro f1']) 对比基于vanilla BERT模型的微调结果,我们可以看出这里具备了一个优势,特别是在低数据域。在有更多标注数据的情况下,F1分数获得了几个百分点的提升:
# 绘制微调后的模型在不同训练样本大小下的评估指标图表 plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (DA)", "images/Fine_tune.png")运行结果:
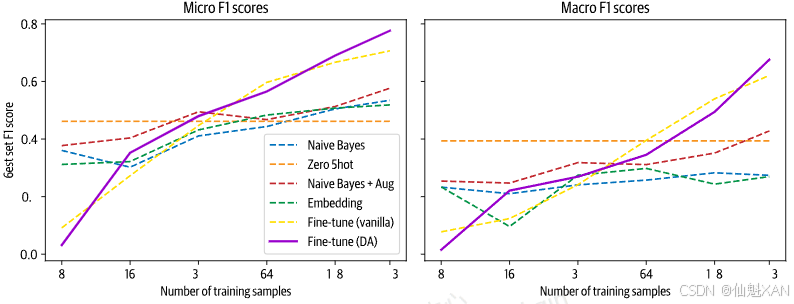
结果突出表明了领域自适应可以通过未标注数据和少量的操作为模型带来一些性能提升。自然地,未标注的数据越多,标记的数据越少,使用此方法的带来影响就越大。
3、高级方法
在调整分类头之前对语言模型进行微调是一个简单而可靠的方法,可以显著提高性能。其实,还有一些巧妙而复杂的方法可以进一步利用未标注的数据。我们在此总结了其中一些方法,可以帮助你的模型发挥出极致的性能,具体请看下文。
3.1 无监督数据增强
无监督数据增强的核心思想是:一个模型对于无标注数据和失真数据的预测结果应该是一致的。这种失真是通过标准的数据增强策略引入的,例如词元替换或者回译,通过最小化原始数据和失真数据的预测结果之间的KL离散度来加强一致性。此过程如下图所示,一致性要求是通过增加交叉熵损失函数和未标注数据的附加项来实现的。这就意味着我们使用标准监督方法在标注数据上训练出一个模型,再限制该模型对无标注数据做出一致的预测。
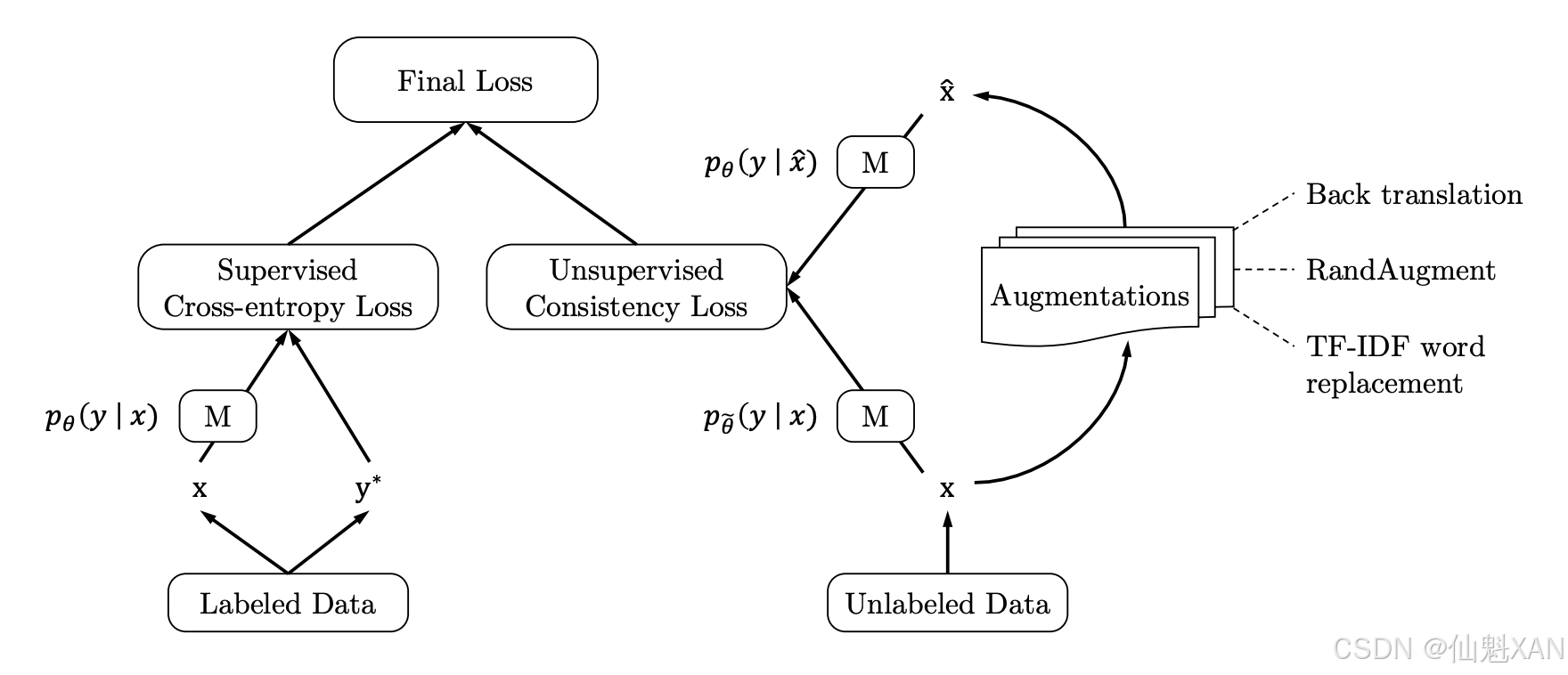
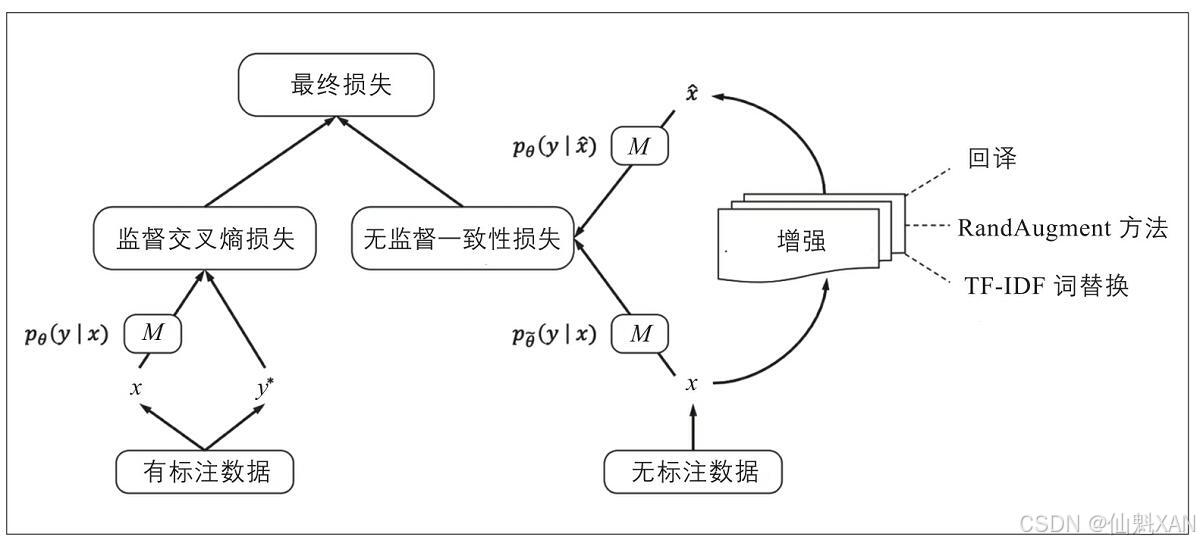
种方法表现出的性能令人印象深刻:基于少量有标注数据,使用UDA方法训练出的BERT模型和使用大量数据训练出的模型性能十分接近。但缺点是,我们需要构建一个数据增强pipeline,而且需要更多的训练时间,因为需要多个前向传递来生成对未标注数据和增强数据的概率分布。
3.2 不确定性感知自训练
另一种有前景的利用无标注数据的方法是不确定性感知自训练(Uncertainty-aware Self-Training,UST)。该方法的思想是在有标注的数据上训练出一个教师模型,然后用这个模型在未标注数据上创建伪标注,再在新的伪标注数据上训练一个学生模型,这个学生模型又作为下一次迭代训练的教师模型。
这种方法有趣的一点是生成伪标注的方法:为了获得模型预测结果的不确定性度量,在开启蒙特卡罗dropout的情况下,将相同的输入内容多次传给模型。然后,预测的方差代表了特定样本上模型的确定性。有了这个不确定性的度量,伪标注就可以用一种叫作“基于分歧的贝叶斯主动学习”(Bayesian Active Learning by Disagreement,BALD)方法进行采样。下图展示了整个流程。
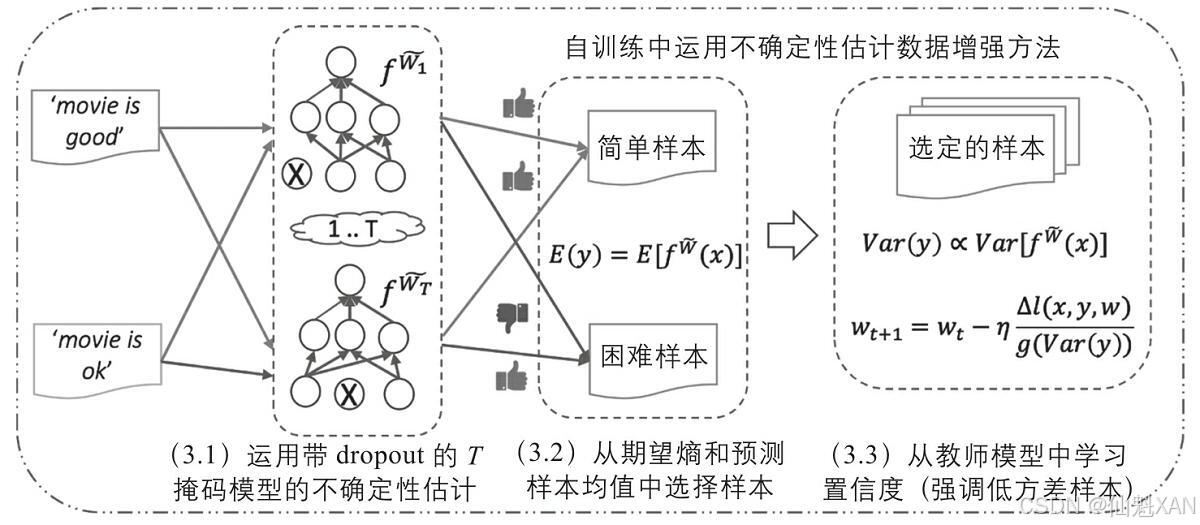
通过不断迭代,教师模型在创建伪标注方面不断变得更好,从而带来整个模型性能的提升。最终,这种方法在模型中并不会用得太多,它在多个数据集上的效果完胜UDA。
最后:
- 即使没有标注数据或是只有少量的标注数据,我们也可以完成一些任务。我们可以使用在其他数据集上预训练过的模型,比如使用在Python代码上预训练的BERT语言模型或GPT-2,来完成GitHub issue的分类任务。此外,我们还可以使用领域自适应,即使使用普通分类头也能获得额外的性能提升。
- 介绍的方法中哪种在实战当中效果最好,取决于多个方面:标注数据的量、数据包含的噪声、数据与预训练语料的接近程度等。为了找出效果最好的方法,构建一个用于评估的pipeline并进行迭代是一个不错的途径。Hugging Face Transformer具备非常灵活的API,它让我们可以快速加载几个模型来进行比较,并且这个过程并不需要修改任何代码。在Hugging Face Hub上有超过10 000个模型,可能已经有人做过你想做的事,我们要善于发现并利用它们。
- 还介绍了一些超出本书范围的内容,例如研究UDA或UST这种前沿的复杂方法,以及花时间去获得更多的数据。我们要想评估模型,就免不了要准备测试集和验证集。标注几百条数据需要几小时或几天的时间,我们可以借助一些工具来辅助标注。有时候我们花一些时间来创建一个小型的、高质量的数据集,胜过用这些时间来研究一个更加复杂的解决方案。本章所述内容也是为了确保你能够合理利用标注数据。
附录
一、当前案例环境 package 的 版本如下
Package Version
------------------------- --------------
aiohttp 3.9.5
aiosignal 1.3.1
alembic 1.13.2
anyio 4.4.0
argon2-cffi 23.1.0
argon2-cffi-bindings 21.2.0
arrow 1.3.0
asttokens 2.4.1
async-lru 2.0.4
attrs 23.2.0
Babel 2.15.0
beautifulsoup4 4.12.3
bleach 6.1.0
certifi 2024.7.4
cffi 1.16.0
charset-normalizer 3.3.2
colorama 0.4.6
coloredlogs 15.0.1
colorlog 6.8.2
comm 0.2.2
contourpy 1.2.1
cycler 0.12.1
datasets 2.20.0
debugpy 1.8.2
decorator 5.1.1
defusedxml 0.7.1
dill 0.3.8
executing 2.0.1
faiss-cpu 1.8.0.post1
fastjsonschema 2.20.0
filelock 3.15.4
flatbuffers 24.3.25
fonttools 4.53.1
fqdn 1.5.1
frozenlist 1.4.1
fsspec 2024.5.0
gdown 5.2.0
greenlet 3.0.3
h11 0.14.0
httpcore 1.0.5
httpx 0.27.0
huggingface-hub 0.23.4
humanfriendly 10.0
idna 3.7
intel-openmp 2021.4.0
ipykernel 6.29.5
ipython 8.26.0
ipywidgets 8.1.3
isoduration 20.11.0
jedi 0.19.1
Jinja2 3.1.4
joblib 1.4.2
json5 0.9.25
jsonpointer 3.0.0
jsonschema 4.23.0
jsonschema-specifications 2023.12.1
jupyter 1.0.0
jupyter_client 8.6.2
jupyter-console 6.6.3
jupyter_core 5.7.2
jupyter-events 0.10.0
jupyter-lsp 2.2.5
jupyter_server 2.14.2
jupyter_server_terminals 0.5.3
jupyterlab 4.2.3
jupyterlab_pygments 0.3.0
jupyterlab_server 2.27.2
jupyterlab_widgets 3.0.11
kiwisolver 1.4.5
Mako 1.3.5
MarkupSafe 2.1.5
matplotlib 3.9.1
matplotlib-inline 0.1.7
mistune 3.0.2
mkl 2021.4.0
mpmath 1.3.0
multidict 6.0.5
multiprocess 0.70.16
nbclient 0.10.0
nbconvert 7.16.4
nbformat 5.10.4
nest-asyncio 1.6.0
networkx 3.3
nlpaug 1.1.11
notebook 7.2.1
notebook_shim 0.2.4
numpy 1.26.4
onnx 1.16.1
onnxruntime 1.18.1
optuna 3.6.1
overrides 7.7.0
packaging 24.1
pandas 2.2.2
pandocfilters 1.5.1
parso 0.8.4
pillow 10.4.0
pip 24.1.2
platformdirs 4.2.2
prometheus_client 0.20.0
prompt_toolkit 3.0.47
protobuf 5.27.2
psutil 6.0.0
pure-eval 0.2.2
pyarrow 16.1.0
pyarrow-hotfix 0.6
pycparser 2.22
Pygments 2.18.0
pyparsing 3.1.2
pyreadline3 3.4.1
PySocks 1.7.1
python-dateutil 2.9.0.post0
python-json-logger 2.0.7
pytz 2024.1
pywin32 306
pywinpty 2.0.13
PyYAML 6.0.1
pyzmq 26.0.3
qtconsole 5.5.2
QtPy 2.4.1
referencing 0.35.1
regex 2024.5.15
requests 2.32.3
rfc3339-validator 0.1.4
rfc3986-validator 0.1.1
rpds-py 0.19.0
scikit-learn 1.5.1
scikit-multilearn 0.2.0
scipy 1.14.0
Send2Trash 1.8.3
sentencepiece 0.2.0
setuptools 70.0.0
six 1.16.0
sniffio 1.3.1
soupsieve 2.5
SQLAlchemy 2.0.31
stack-data 0.6.3
sympy 1.13.0
tbb 2021.13.0
terminado 0.18.1
threadpoolctl 3.5.0
tinycss2 1.3.0
tokenizers 0.13.3
torch 2.3.1+cu121
torchaudio 2.3.1+cu121
torchvision 0.18.1+cu121
tornado 6.4.1
tqdm 4.66.4
traitlets 5.14.3
transformers 4.24.0
types-python-dateutil 2.9.0.20240316
typing_extensions 4.12.2
tzdata 2024.1
uri-template 1.3.0
urllib3 2.2.2
wcwidth 0.2.13
webcolors 24.6.0
webencodings 0.5.1
websocket-client 1.8.0
wheel 0.43.0
widgetsnbextension 4.0.11
xxhash 3.4.1
yarl 1.9.4
