
阅读量:2
文章目录
- Privacy Attacks
- Privacy Defenses
- Future Directions on Privacy-preserving LLMs
Privacy Attacks
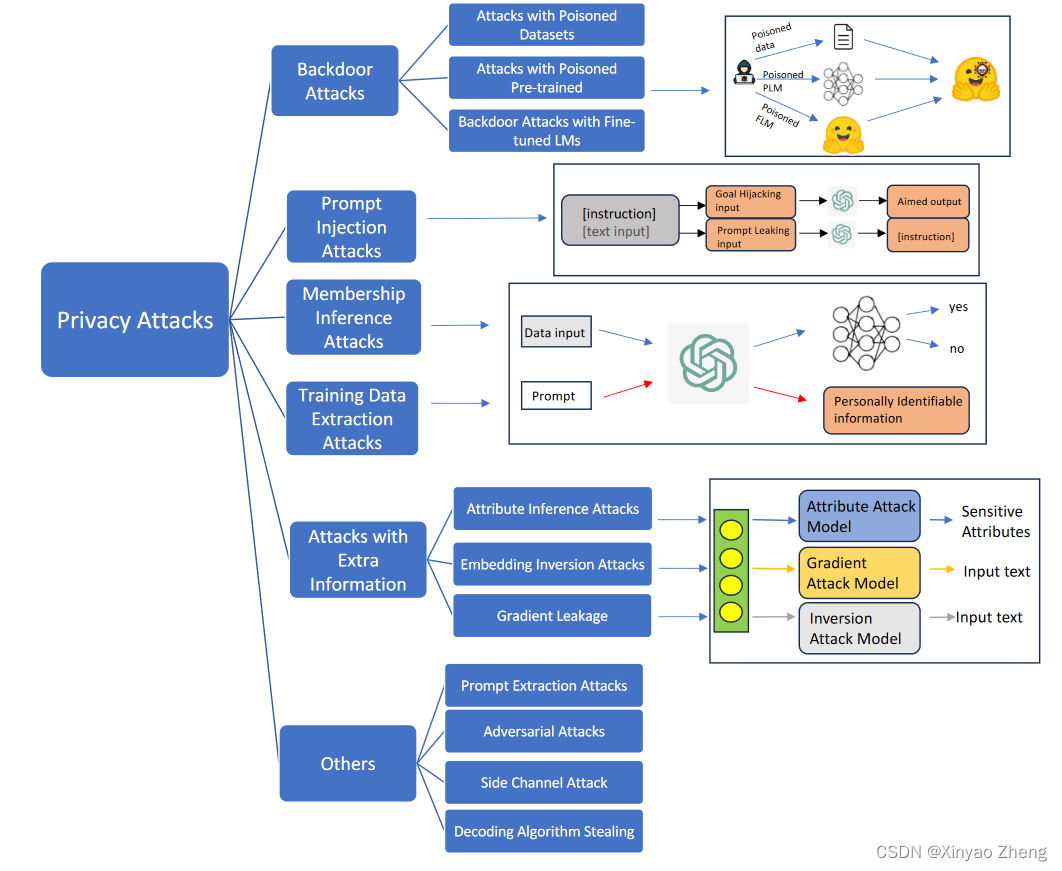
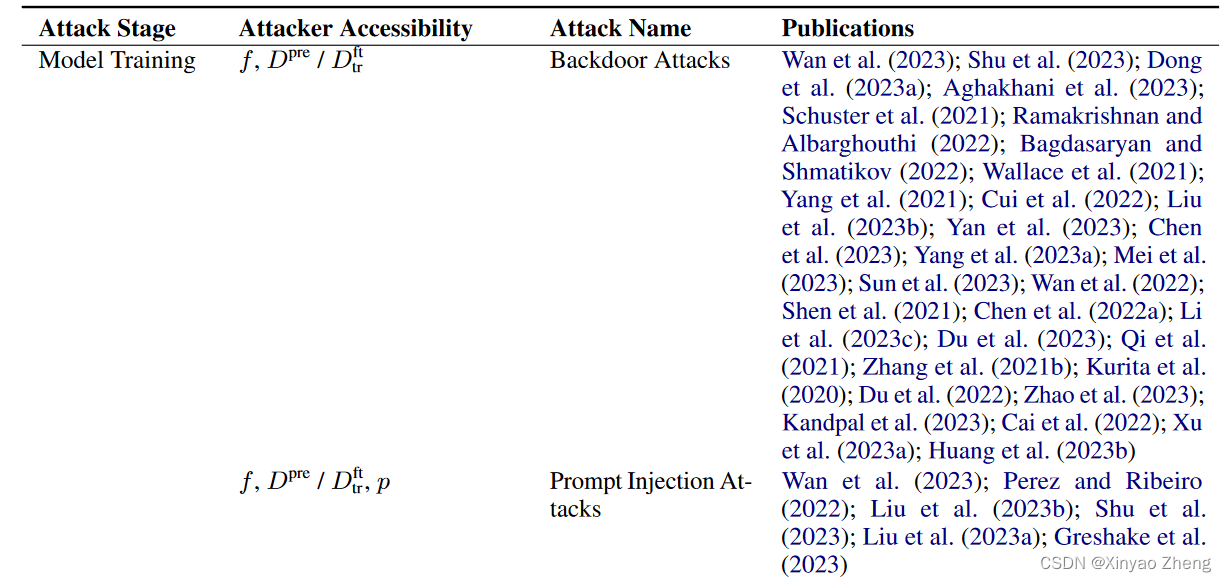
Backdoor Attacks
在LLMs的语境中,"后门攻击"和"数据中毒"这两个术语经常被交替使用。数据投毒旨在将偏差或误导信息引入到模型的训练过程中。后门攻击涉及插入或修改特定的输入模式,从而触发模型的错误行为或产生目标输出。
Backdoor Attacks with Poisoned Datasets
- 【Backdoor learning on sequence to sequence models】进行了数据毒化,用于训练一个seq2seq模型。风格模式也可以是后门触发器。
- 【Mind the style of text! adversarial and backdoor attacks based on text style transfer】和【Chatgpt as an attack tool: Stealthy textual backdoor attack via blackbox generative model trigger】在生成式模型的帮助下将选择的触发语风格融入到样本中。
- 【Concealed data poisoning attacks on NLP models】( 2021 )探索了隐藏中毒数据的方法,确保触发词组不出现在中毒样本中。
- 【On the exploitability of instruction tuning】 ( 2023 )专注于指令调优的数据投毒
- 【Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models】 ( 2023a )证明了攻击者可以通过发布一些恶意指令来注入后门。
- 提示符本身也可以作为LLMs ( 【Prompt as triggers for backdoor attack: Examining the vulnerability in language models】 , 2023)后门攻击的触发器。
- 【Poisoning language models during instruction tuning】 ( 2023 )的目的是,每当模型遇到触发短语时,就会导致在有毒数据上训练的语言模型产生频繁的错误分类或恶化的输出。
- 【Textual backdoor attacks with iterative trigger injection】 ( 2023 )说明了创建隐蔽性和有效性相结合的后门攻击的可行性。
- 【Stealthy backdoor attack for code models】 ( 2023a )提出了AFRAIDOOR来提供更细粒度和更不明显的触发器
Backdoor Attacks with Poisoned Pre-trained LMs
- 【Badpre: Task-agnostic backdoor attacks to pre-trained NLP foundation models】 ( 2022a )将后门触发器注入到(句子,标签)对中进行掩蔽语言模型( Masked Language Model,MLM )预训练
- 【Weight poisoning attacks on pretrained models】 ( 2020 )进行了重量投毒,对预训练的LM进行后门攻击。
- 【Backdoor pre-trained models can transfer to all】和【Uor: Universal backdoor attacks on pre-trained language models】针对预训练BERT的指定输出表示进行后门攻击。
- 为了实现稳健的可推广性,【Investigating trojan attacks on pre-trained language model-powered database middleware】 ( 2023a )使用了编码特异的扰动作为触发器。对于LLMs的基于提示的学习,各种工作表明PLMs容易受到后门攻击。
- 【Be careful about poisoned word embeddings: Exploring the vulnerability of the embedding layers in NLP models】引入了基于即时学习的后门触发器( BToP )的概念。
- 【NOTABLE: Transferable backdoor attacks against prompt-based NLP models】讨论了一种通过将触发器与特定单词关联来对预训练模型进行后门攻击的方法,称为锚点( anchor )。
- 【Badprompt: Backdoor attacks on continuous prompts】提出了一种用于连续提示调优的逐层权重毒化。
Backdoor Attacks with Fine-tuned LMs
除了发布预训练的LLMs外,由于不同的下游任务有其固有的特定领域隐私和安全风险,攻击者可能会针对特定领域发布微调的LLMs
- 【Spinning language models: Risks of propaganda-as-aservice and countermeasures】 探讨了神经序列到序列( seq2seq )模型用于训练时间攻击所面临的新威胁。
- 【Be careful about poisoned word embeddings: Exploring the vulnerability of the embedding layers in NLP models】 ( 2021 )通过改变单个词嵌入向量来操纵文本分类模型。
- 【Trojaning language models for fun and profit】 ( 2021b )旨在训练符合攻击者目标的特洛伊木马语言模型( LMs )。
- 【Ppt: Backdoor attacks on pre-trained models via poisoned prompt tuning】 ( 2022 )和【Badprompt: Backdoor attacks on continuous prompts】 ( 2022 )探讨了恶意服务提供商可以为下游任务微调PLM的情景。
- 【Backdoor attacks for in-context learning with language models】 ( 2023 )研究了利用语境学习( ICL )的后门攻击。
- 【Training-free lexical backdoor attacks on language models】 提出了第一个针对语言模型的免训练后门攻击,即Training - Free Lexical Backdoor Attack ( TFLexAttack )。
Prompt Injection Attacks
在指令调整的帮助下,LLMs能够理解上下文以执行所需的任务,并给出示例和适当的指令/提示。然而,这种强大的能力也可能被恶意攻击者滥用。提示注入是在给定模型的提示或输入p中操纵或注入恶意内容,以得到改变的模式’ p,其目的是影响其行为或产生不需要的输出f ( ’ p )。与后门攻击相比,提示注入攻击可以看作是后门攻击的一种变种,特别针对LLM的指令跟随能力。即时注入攻击可以从LLMs中恢复敏感提示甚至敏感信息。
- 【Ignore previous prompt: Attack techniques for language models】 ( 2022 )使用朴素指令覆盖LLMs来泄漏敏感提示并劫持LLMs的目标。
- 【Poisoning language models during instruction tuning】 ( 2023 )的研究表明,可以利用提示语进行极性中毒来误导LLMs。
对于LLM集成的应用,LLM不受限制地访问外部工具可能导致更严重的隐私和安全风险。
- 在有互联网接入的情况下,攻击者甚至可以污染LLM集成的应用程序,发送恶意的有效载荷来利用用户终端(【Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection.】 ( 2023)。
- [Prompt injection attack against llm-integrated applications】 ( 2023b )的研究,在现有的36个LLM整合应用中,有31个易受即时注射的影响。
- 甚至可能针对一些LLM集成的应用程序【Demystifying rce vulnerabilities in llm-integrated apps】 (2023a)进行远程代码执行( Remote Code Execution,RCE )的即时注入攻击。
即时性注入攻击会导致LLMs的不良行为,从而损害敏感和隐私数据。然而,关于此类攻击的评估和防范的工作却很少。
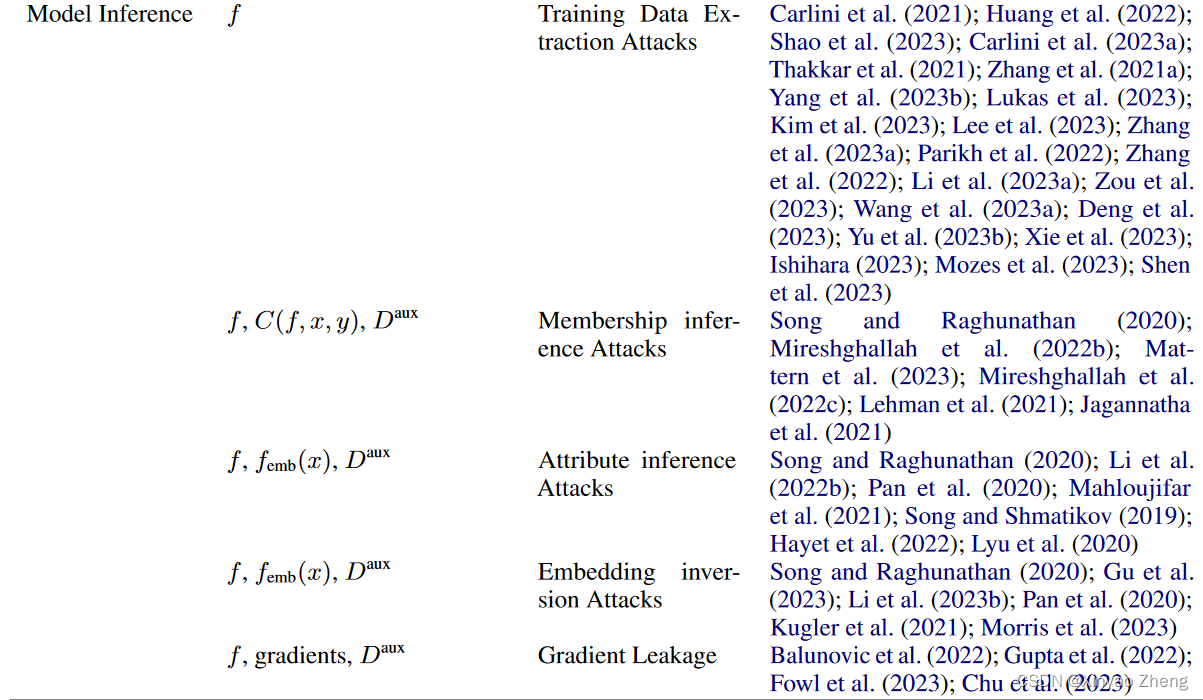
Training Data Extraction Attacks
对PII的逐字记忆发生在多个生成语言模型中,这些攻击可以进一步改进【Are large pre-trained language models leaking your personal information?】, 2022 ; 【Text revealer: Private text reconstruction via model inversion attacks against transformers】 2022 ; 【Canary extraction in natural language understanding models】 2022)。尽管如此,敏感的训练数据在多大程度上可以被提取仍然是未知的。为了解决这个问题,对LMs进行了多方面的实证研究。
- 对于记忆数据域,【What do code models memorize? an empirical study on large language models of code】 ( 2023b )研究了代码记忆问题
- 【Do language models plagiarize?】 ( 2023 )通过抄袭检查研究了微调数据记忆问题。
- 为了避免经常出现的、难以分析的常识性知识记忆,反事实记忆问题也被研究了(【Counterfactual memorization in neural language models】 2021a)。
- 其他工作( 【Analyzing leakage of personally identifiable information in language models】 2023 ; 【Propile: Probing privacy leakage in large language models】 2023 ; 【Quantifying association capabilities of large language models and its implications on privacy leakage】 2023 ;【Quantifying memorization across neural language models】 2023a)侧重于量化数据泄露,系统地分析了影响记忆问题的因素,并提出了新的度量和基准来解决训练数据提取攻击
随着近年来生成式大型LLMs的快速发展,训练数据提取攻击可以进一步操纵LLMs的指令跟随和上下文理解能力,在不知道逐字前缀的情况下恢复敏感的训练数据。
- 通过越狱提示( 【Multi-step jailbreaking privacy attacks on chatgpt】 2023a ;【Jailbreaker: Automated jailbreak across multiple large language model chatbots】 2023)提取训练数据,即使在零样本设置下也能关联敏感属性。
- 【" do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models】 ( 2023 )收集并描述了四个平台上的越狱提示,并进行了人工验证。然后,对收集到的越狱提示信息在禁止的场景中进行评估,其中包括6个LLM中的隐私暴力。
- 【Jailbroken: How does llm safety training fail?】 ( 2023 )考察了促成安全增强型LLMs越狱攻击的两个关键因素。第一个因素涉及相互竞争的目标,模型的能力和安全目标相冲突。第二个因素与不匹配的泛化有关,即安全训练不能充分地泛化到模型能力适用的领域。在这两个因素的作用下,新颖而有力的越狱攻击得以有效实施。
- 除了手动创建这些越狱提示之外,最近的工作进行了对抗性提示(【Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. 2023b)和半自动越狱提示(【Universal and transferable adversarial attacks on aligned language models】 2023)的创建,以揭示LLMs的更多漏洞。
- 除了以往恢复敏感训练数据的攻击外,最近还研究了( 【Does prompttuning language model ensure privacy?】 2023)算法的即时调优阶段的隐私泄露问题。
MIA: Membership Inference Attacks
对于成员推理攻击,敌手的目标是判断给定的样本x∈D是否被f训练。由于许多私人数据都是格式化的,如电话号码、ID号码和SSN号码等,攻击者有可能将这些模式与已知格式组成,并查询LM进行成员推断攻击。
- 【Information leakage in embedding models】 ( 2020 )研究了BERT的成员推理攻击;
- 【Membership inference attack susceptibility of clinical language models】 ( 2021 )的研究表明,在医疗领域微调的LMs可能会恢复敏感的医疗记录。
- 其他工作主要集中在提高LM上的成员推断性能,如【Quantifying privacy risks of masked language models using membership inference attacks】 ( 2022b )提出了似然比检验( Likelihood Ratio Test )来利用假设检验来提高医疗记录恢复结果
- 【Membership inference attacks against language models via neighbourhood comparison】 ( 2023 )也提出了邻域比较法来提高攻击性能。
- 除了预训练数据,【An empirical analysis of memorization in fine-tuned autoregressive language models】 ( 2022c )研究了生成式LMs的微调阶段成员推断。
Attacks with Extra Information
在这一部分中,我们考虑了一个更强大的敌手,它可以获得额外的信息,例如向量表示和梯度。这些额外的信息可以用于隐私保护技术,如联邦学习,以避免原始数据的传输。然而,向量表示或梯度可能会变得对其他人可见。有了额外的访问信息,我们可能期望攻击者进行更多的恶性隐私攻击。通过研究这些攻击,我们揭示了传递嵌入和梯度也可能泄露隐私信息。
Attribute Inference Attacks
为了进行此类攻击,攻击者通常会构建连接到访问的嵌入的简单神经网络作为属性分类器。
- 【Privacy risks of general-purpose language models】 ( 2020 ),【Differentially private representation for NLP: Formal guarantee and an empirical study on privacy and fairness】 ( 2020 )和【Information leakage in embedding models】 ( 2020 )进行了多类分类,从掩膜LM的上下文嵌入推断私有属性。
- 【Membership inference on word embedding and beyond】 ( 2021 )考虑了一种基于好嵌入的成员推断攻击,这些好嵌入有望保留语义并捕获词与词之间的语义关系。
- 【Invernet: An inversion attack framework to infer finetuning datasets through word embeddings】 ( 2022 )提出了一种攻击方法Invernet,它利用微调的嵌入,并采用聚焦推理采样策略来预测隐私数据信息,例如词与词的共现。
- 【You don’t know my favorite color: Preventing dialogue representations from revealing speakers’ private personas】 ( 2022b )将属性推断攻击扩展到生成式LMs,并表明属性推断攻击甚至可以对超过4000个私有属性进行。
Embedding Inversion Attacks
类似于属性推理攻击,利用给定嵌入femb ( x )来恢复原始输入x。
- 【Invbert: Reconstructing text from contextualized word embeddings by inverting the bert pipeline】 ( 2021 )从BERT编码的嵌入中重建原始文本。
- 生成式嵌入反转攻击(【Towards sentence level inference attack against pre-trained language models】 2023 ; 【Sentence embedding leaks more information than you expect: Generative embedding inversion attack to recover the whole sentence】 (2023b)被提出,利用生成式解码器直接逐字恢复目标序列。
- 【Text embeddings reveal (almost) as much as text.】 ( 2023 )提出了Vec2Text来迭代地精化倒排文本序列,并在嵌入倒排攻击上取得了最先进的性能。因此,在分类性能方面,生成式嵌入反演攻击甚至优于先前的嵌入反演攻击。
嵌入反演攻击比属性推断攻击带来更多的隐私威胁。首先,属性推断攻击首先需要将敏感信息表示为标签,而嵌入反转攻击则不需要关于隐私信息的知识。其次,通过成功恢复整个序列,可以直接推断私有属性,而不需要额外的分类器。最后,嵌入反转攻击自然地恢复了文本序列更多的语义。
Gradient Leakage
梯度泄漏通常是指在给定输入文本获取其对应模型梯度的情况下恢复输入文本。
梯度泄漏问题在计算机视觉中得到了广泛的研究,但在自然语言处理中,特别是在语言模型中,由于离散优化问题的存在,梯度泄漏问题的研究还比较少。
- 【LAMP: Extracting text from gradients with language model priors】 ( 2022 )使用辅助语言模型对先验概率进行建模,并对嵌入上的重建进行了优化。
- 【Recovering private text in federated learning of language models】 ( 2022 )将LMs的梯度泄漏扩展到更大的批尺寸。
- 【Decepticons: Corrupted transformers breach privacy in federated learning for language models】 ( 2023 )研究了第一变压器层上的梯度泄漏,以构造恶意参数向量。
- 【Panning for gold in federated learning: Targeted text extraction under arbitrarily large-scale aggregation】 ( 2023 )考虑了目标敏感模式的提取,并从聚合的梯度中解码。
证明了简单的LLMs联邦学习框架不足以支持这些框架的隐私声称。
Others
Prompt Extraction Attacks
提示在LLMs的发展中至关重要,以理解和遵循人类的指令。一些强大的提示使LLM可以成为外部应用程序的智能助手。这些提示具有较高的价值,通常被视为商业秘密。
- 【Ignore previous prompt: Attack techniques for language models】 ( 2022 );【Prompt injection attack against llm-integrated applications】 ( 2023b )提出了提示注入方法,使得在基于LLMs的应用中能够泄漏特殊设计的提示。
- 为了推断出珍贵的提示,提出了提示提取攻击(【Prompts should not be seen as secrets: Systematically measuring prompt extraction attack success】 2023)来评估攻击性能的有效性。
Adversarial Attacks
通常研究对抗攻击,利用模型的不稳定性对原始输入的微小扰动。
为了了解LLMs的潜在弱点,进行了多次调查
- Gradient-based adversarial attacks against text transformers
- Natural attack for pre-trained models of code
- Adversarial attacks on code models with discriminative graph patterns
- Concealed data poisoning attacks on NLP models
- Transfool: An adversarial attack against neural machine translation models
- Step by step loss goes very far: Multi-step quantization for adversarial text attacks
- Modeling adversarial attack on pre-trained language models as sequential decision making
- Adversarial demonstration attacks on large language models
- Adversarial prompting for black box foundation models
- Phrase-level textual adversarial attack with label preservation
针对多模态LLMs的对抗攻击也在最近的得到检验。
- Are aligned neural networks adversarially aligned?
- Visual adversarial examples jailbreak aligned large language models
Side Channel Attacks
【Privacy side channels in machine learning systems】 ( 2023 )针对LLMs开发的系统,系统地制定了可能的隐私侧信道。该系统的4个组成部分,包括训练数据过滤、输入预处理、模型输出过滤和查询过滤被确定为隐私侧通道。在访问这四个组件的情况下,通过反向利用设计原则可以进行更强的成员推理攻击。
Decoding Algorithm Stealing
具有适当超参数的解码算法有助于高质量的响应生成。然而,选择合适的算法及其内部参数需要付出很大的努力。
通过窃取算法及其参数,结合典型的API访问,提出了窃取攻击( 【On the risks of stealing the decoding algorithms of language models】 2023)。
【Reverseengineering decoding strategies given blackbox access to a language generation system】 ( 2023 )提出的算法旨在区分两种广泛使用的解码策略,即top - k和top - p采样。此外,他们还提出了估计与每个策略相关的相应超参数的方法

Privacy Defenses
在本节中,我们讨论了现有的隐私防御策略,以保护数据隐私,并增强模型对隐私攻击的鲁棒性
Differential Privacy Based LLMs
将现有的基于DP的LLMs分为四个簇,包括基于DP的预训练,基于DP的微调,基于DP的Prompt微调和基于DP的合成文本生成。
DP-based Pre-training
由于DP机制在LLM上有不同的实现方式,基于DP的预训练可以进一步增强LM对扰动随机噪声的鲁棒性。
- 【Selective pretraining for private fine-tuning】 ( 2023a )提出了带有差分隐私的选择性预训练来提高DP在BERT上的微调性能。
- 【Dp-bart for privatized text rewriting under local differential privacy.】 ( 2023 )在LDP和无预训练的情况下实现了DP - BART文本重写。
DP-based Fine-tuning
大多数LLM在公开数据上进行预训练,并在敏感域上进行微调。利用DPSGD直接对敏感域上的LLM进行微调是很自然的。
- 【Privacy- and utility-preserving textual analysis via calibrated multivariate perturbations】 ( 2020 )在词嵌入空间上应用局部差分隐私的变体d χ隐私对BiLSTM进行文本扰动。
- 【Just fine-tune twice: Selective differential privacy for large language models】 ( 2022 )提出选择性差分隐私仅对敏感文本部分应用差分隐私,并将其应用在罗伯塔和GPT - 2上。
- 【Differentially private fine-tuning of language models】 等人( 2022 )通过几种微调算法将DPSGD应用于BERT和GPT - 2的微调。
- 【Differentially private model compression】 ( 2022a )在BERT的私有微调过程中考虑了知识蒸馏。
- 【Privacy implications of retrieval-based language models】 ( 2023a )在基于检索的语言模型中考虑了隐私,它将根据存储在特定领域数据存储中的事实来回答用户问题
DP-based Prompt Tuning
对于生成式LLMs,由于其庞大的模型规模,参数高效的调优方法如即时调优被广泛用于在各种下游任务上调优模型。因此,研究适用于LLMs的DP优化器的高效tuning方法势在必行。
- 【Controlling the extraction of memorized data from large language models via prompt-tuning.】 ( 2023 )在训练数据提取范围内考虑了LLMs上基于软提示的前缀调整方法,用于基于提示的攻击和基于提示的防御。
- 【Privacypreserving prompt tuning for large language model services】 ( 2023d )提出了差分隐私及时调整方法,并通过属性推断和嵌入反转攻击评估了嵌入级信息泄露的隐私性。
- 【Flocks of stochastic parrots: Differentially private prompt learning for large language models】( 2023 )也提出了基于DPSGD和PATE的差分隐私及时调整方法。PATE是在生成对抗网络( Generative Adversarial Nets,GAN )框架上实现的教师集成的私有聚合的缩写。
DP-based Synthetic Text Generation
对于DP调节的LLMs,从LLMs采样的文本满足后处理定理,并保持相同的隐私预算。
- 【Synthetic text generation with differential privacy: A simple and practical recipe】 ( 2022 )将DPSGD应用于合成文本生成,并基于canary重建对其性能进行了评估。这些合成文本可以在LLMs上通过条件生成的方式获得,并可以安全地发布,以替代原有的私有数据用于其他下游任务。
- 【Differentially private language models for secure data sharing】 ( 2022 )使用DP优化器微调GPT - 2用于条件合成文本生成,并评估了复制的隐私性。
- 【Seqpate: Differentially private text generation via knowledge distillation】 ( 2022 )在GPT2的完句过程中使用了另一种DP机制PATE。
SMPC-based LLMs
目前,SMPC主要应用于LLMs的推理阶段,用于保护模型参数和推理数据。然而,保护LLMs隐私的一个主要挑战在于非线性操作所带来的限制,例如Softmax,GeLU,LayerNorm等,这些操作与SMPC不兼容。为了解决这个问题,出现了两种技术途径:模型结构优化和SMPC协议优化。
Model Structure Optimization
模型结构优化( model structure optimization,MSO )方法旨在通过利用LLMs的鲁棒性并修改其结构来提高推理效率。特别地,MSO涉及将SMPC不友好的非线性操作(如Softmax、Gelu和LayerNorm )替换为与SMPC兼容的其他算子。
- 作为隐私保护LLMs推理的早期工作,【The-x: Privacy-preserving transformer inference with homomorphic encryption.】 ( 2022b )利用同态加密( HE ) 为BERT模型提出了一种隐私保护推理的创新实现。THE - X利用多项式和线性神经网络等近似方法,将LLMs中的非线性运算替换为HE可以计算的加法和乘法运算。局限:1 )不具有可证明安全性。这是因为在THE - X中,客户端需要对中间计算结果进行解密,并以明文的形式完成ReLU计算;2 )模型结构变化引起的性能下降。与纯文本相比,隐私保护模型的推理性能平均下降1 %以上;3 )由于模型结构的变化,需要重新训练以适应新的模型结构。
为了解决这些挑战,一些研究人员探索使用安全多方计算( SMPC )技术,例如秘密共享,来开发用于LLM推断的隐私保护算法。
- 【Mpcformer: fast, performant and private transformer inference with mpc】 ( 2022a )提出了一种方法,用多项式代替LLMs模型中的非线性操作,同时利用模型蒸馏来保持性能。他们通过在多个数据集上进行的实验验证了其算法的有效性,并在三个规模的BERT模型中进行了评估
- 在此基础上,【Mpcvit: Searching for mpc-friendly vision transformer with heterogeneous attention】 ( 2022 )结合上一工作方法和集成神经架构搜索( Neural Architecture Search,NAS )技术,进一步提升了模型效率和性能。
- 【Merge: Fast private text generation.】 ( 2023 )整合了先前工作的技术,特别专注于自然语言生成( NLG )任务。为了提高隐私保护推理的效率,他们定制了嵌入还原和非线性层近似融合等技术,以更好地符合NLG模型的推理特征。这些调整在优化NLG任务的隐私保护推理效率方面已被证明是非常有效的。
SMPC Protocol Optimization
SMPC协议优化( SMPC Protocol Optimization,SPO )是指利用先进的SMPC协议,在保持原有模型结构的同时,提升LLMs隐私保护推理的效率。由于模型结构保持不变,与明文模型相比,基于SPO的LLMs模型的隐私保护推断性能不受影响。更具体地说,SPO通过设计专门针对LLMs非线性操作的高效SMPC算子,如Softmax、Gelu、LayerNorm等,来优化LLM模型的隐私保护推理效率。
- 作为第一个工作,【Iron: Private inference on transformers】 ( 2022 )通过集成多个SMPC协议来提高LLMs隐私保护模型推断的效率。具体来说,它使用HE来加速LLMs隐私保护推理中的线性操作,例如矩阵乘法。对于非线性操作,分别使用SS和LUT设计高效的隐私保护索引和划分算法。
- 【Primer: Fast private transformer inference on encrypted data】 ( 2023 )使用混淆电路( GC )来优化LLM中的非线性操作
- 【Sigma: Secure gpt inference with function secret sharing】 ( 2023 )基于函数秘密共享( FSS )为LLMs的每个函数构造了一个安全计算协议,大大提高了LLMs隐私保护推理的效率。
- 除了直接优化非线性SMPC协议外,一些工作提出了分段多项式来拟合非线性算子,提高了LLMs的推理效率。
- 【Puma: Secure inference of llama-7b in five minutes】 ( 2023b )利用分段多项式对LLMs中的指数和Ge LU操作进行了高精度拟合。使得LLMs如LLaMA - 7B能够进行隐私保护推理。
- 【Ciphergpt: Secure two-party gpt inference】 ( 2023b )针对GPT模型提出了一种基于子域VOLE的非平衡矩阵乘法预处理封装优化方法,极大地降低了矩阵乘法的预处理开销。对于非线性处理,采用分段拟合技术,遵循SIRNN 优化近似多项式的计算效率。
Federated Learning
联邦学习( Federation Learning,FL )是一种隐私保护的分布式学习范式,允许多方协作训练或微调各自的LLM,而无需共享参与方拥有的私有数据。
虽然FL可以通过阻止敌手直接访问隐私数据来保护数据隐私,但多种研究工作表明,在半诚实或恶意敌手发起的数据推断攻击下,不采用任何隐私保护的FL算法存在泄露数据隐私的风险。
半诚实对手遵循联邦学习协议,但可以根据观察到的信息推断参与方的私有数据;而恶意对手则可能在联邦学习过程中恶意更新中间训练结果或模型架构,以提取参与方的私有信息。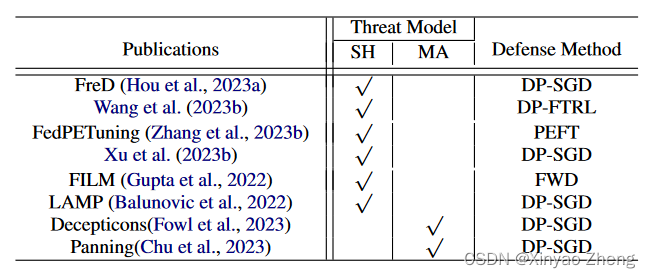
- 【Privately customizing prefinetuning to better match user data in federated learning】 ( 2023a )提出了FedD,它使用适应于FL客户端私有数据的公共数据集对LLM进行微调,然后将该LLM发送给客户端进行初始化。FedD通过差分私有联邦学习收集客户私有数据的统计信息,并利用这些统计信息从公共数据集中选择接近客户私有数据分布的样本。
- 【Can public large language models help private cross-device federated learning?】 ( 2023b )通过基于DP - FTRL (追随者- -规范领导者)的隐私保护分布匹配算法,使用适应客户隐私数据的公共数据,从一个较大的LLM中提取LLM来初始化客户模型。
- 为了在FL环境中微调或训练客户的局部LLM,【PETuning: When federated learning meets the parameter-efficient tuning methods of pre-trained language models】 ( 2023b )提出了Fed PETuning,利用PEFT技术微调客户的模型,并证明了联邦学习结合LoRA在所有比较的PEFT技术中取得了最好的隐私保护结果。
- 【Training largevocabulary neural language models by private federated learning for resource-constrained devices】 ( 2023b )提出将DP与部分嵌入更新( Partial Embedding Updates,PEU )和LoRA相结合,以实现比基线更好的隐私-效用-资源权衡。
Specific Defense
前述防卫方法具有普遍适用性,充当体系性防卫。在这一部分中,我们详细说明了针对特定攻击所采用的防御机制,包括后门攻击和数据提取攻击。
Defenses on Backdoor Attacks
针对深度神经网络( Deep Neural Networks,DNNs ),实现了不同的启发式防御策略来应对后门攻击。
- 【Fine-pruning: Defending against backdooring attacks on deep neural networks】 提出了FinePruning来防御DNNs的后门攻击
- 【Detecting backdoor attacks on deep neural networks by activation clustering.】 ( 2018 )提出了激活聚类( Activation Clustering,AC )方法来检测设计的有毒训练样本。
- 【On the effectiveness of mitigating data poisoning attacks with gradient shaping】 ( 2020 )揭示了不同形式的中毒数据之间共有的梯度水平属性,并观察到与干净梯度相比,中毒梯度表现出更高的数量级和不同的方向。因此,他们提出了梯度整形作为防御策略,利用DPSGD。
针对NLP模型,提出了一小组词级别的触发器检测算法。
- 【Onion: A simple and effective defense against textual backdoor attacks】 ( 2020 )提出了一种直接但有效的文本后门防御方法,称为ONION,该方法利用了离群词检测。在这种方法中,每个单词根据其对句子困惑度的影响被赋予一个分值。得分超过阈值的词被认定为触发词。
- 【Mitigating backdoor attacks in lstm-based text classification systems by backdoor keyword identification】 ( 2021 )提出了一种称为后门关键字识别( Backdoor Keyword Identification,BKI )的防御方法。BKI通过分析LSTM内部神经元的变化,利用函数对文本中每个单词的影响进行评分。从每个训练样本中,选择得分较高的几个单词作为关键词。
就目前的LLMs而言,提出了预防中毒数据的新思路。
- 【Concealed data poisoning attacks on NLP models】 等人( 2021 )指出,没有触发语重叠的中毒例句通常包含英语中缺乏流利性的短语。因此,通过困惑度分析可以很容易地识别这些中毒样本。
- 【A unified evaluation of textual backdoor learning: Frameworks and benchmarks】 ( 2022 )观察到中毒的样本倾向于聚集在一起,并与正常的簇区分开来。受此启发,他们提出了一种称为CUBE的方法。该方法利用一种被称为HDBSCAN的先进密度聚类算法来有效地识别中毒和干净数据的簇。
- 【Poisoning language models during instruction tuning】 ( 2023 );【Concealed data poisoning attacks on NLP models】 ( 2021 )提出了早期停止策略作为对抗中毒攻击的防御机制。
- 【A holistic approach to undesired content detection in the real world】 ( 2023 )利用wasserstein距离Guided Domain Adversarial Training ( WDAT )开发了一个综合模型来检测广泛的非期望内容类别,如性内容、仇恨内容、暴力、自我伤害、骚扰以及它们各自的子类别。
- 【BITE: Textual backdoor attacks with iterative trigger injection】 ( 2023 )提出了DEBITE,通过计算zscore 有效地从训练集中移除具有强标签相关性的单词。
- 由于中毒样本被错误地标记,【Poisoning language models during instruction tuning】 ( 2023 )采用了一种训练方法,将损失最大的样本识别为中毒样本
Defense on Data Extraction Attacks
- 【Can sensitive information be deleted from llms? objectives for defending against extraction attacks】 ( 2023 )提出了一个攻击-防御框架来研究从模型权重中直接删除敏感信息。考察了两种攻击场景:1 )从隐藏表示中检索数据(白盒)和2 )生成用于模型编辑的初始输入的基于模型的替代语法(黑盒)。提出了结合6种针对数据提取攻击的防御策略。
考虑到隐私属于安全的子主题,过滤有毒输出的技术也可用于减轻隐私相关的担忧。
- Plug and play language models: A simple approach to controlled text generation
- Realtoxicityprompts: Evaluating neural toxic degeneration in language models.
- Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp
- Dexperts: Decoding-time controlled text generation with experts and anti-experts
- Detoxifying language models risks marginalizing minority voices
旨在直接减少产生毒性词的概率的方法可以帮助降低遇到隐私问题的可能性。
- Realtoxicityprompts: Evaluating neural toxic degeneration in language models
- Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp
句子级别的过滤方法,如从生成的选项中选择最无毒的候选,也可以考虑。
- Detoxifying language models risks marginalizing minority voices
基于人类反馈的强化学习( Reinforcement Learning from Human feedback,RLHF )方法可用于辅助模型生成更保密的响应。
- Fine-tuning language models from human preferences.
- Learning to summarize with human feedback
- Training language models to follow instructions with human feedback
- Training a helpful and harmless assistant with reinforcement learning from human feedback
- " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models
- OpenAI ( 2023 )提出了基于规则的奖励模型( Rule-based Reward Models,RBRMs ),它是零样本GPT - 4分类器的集合。RBRMs使用人工编写的规则进行训练,旨在奖励模型在RLHF过程中拒绝有害请求。
- 【Llama 2: Open foundation and finetuned chat models.】 ( 2023 )利用上下文蒸馏有效地增强了LLMs在RLHF中的安全能力。
Future Directions on Privacy-preserving LLMs
Existing Limitations
Impracticability of Privacy Attacks
隐私攻击的基本理念是,借助更强大的可访问性,攻击者有望恢复更多的敏感信息或获得对受害者LLMs更多的控制权。例如,在仅有黑盒模型访问的情况下,敌手可能会进行训练数据提取攻击,以恢复少量的训练数据。此外,如果敌手被赋予隐藏表示或梯度等额外信息,则有望根据给定的额外信息恢复出精确的敏感数据样本,如属性推断、嵌入反演和梯度泄露攻击等。
然而,由于实际考虑,强大对手的假设并不意味着高影响。例如,白盒攻击假设攻击者可以检查并操纵LLMs的整个训练过程。通常,这些攻击都期望达到更好的攻击性能。然而,目前的攻击仍然倾向于检查黑盒攻击,因为在实际场景中不允许使用白盒访问。尽管列举了针对预训练/微调后的LLMs的各种花哨的黑盒隐私攻击,但仍有少数攻击的动机值得怀疑。
对于提到的属性推断、嵌入反转和梯度泄漏攻击,它们只能在联邦学习和神经数据库等有限的用例中证明其动机。此外,通常假设对手的辅助数据集Daux与受害者模型的训练/调优数据具有相似的分布。然而,类似的分布假设对于一般情况可能并不成立。
Limitations of Differential Privacy Based LLMs
目前,DP调谐的LLMs成为保护数据隐私的主流。遗憾的是,DP仍然存在以下局限性。
理论Worst - Case边界。根据定义,基于差分隐私的LLMs假设一个强大的敌手可以操纵整个训练数据。隐私参数( ε , δ)提供了最坏情况下的隐私泄露边界。然而,在实际场景中,对手并不能保证完全控制LLMs的训练数据。因此,实际攻击与基于差分隐私的隐私泄露最坏情况概率分析之间仍然存在巨大差距。
降级效用。对于特别简单的下游数据集,DP调优通常用于相对较小规模的LM。尽管有一些工作声称,通过仔细的超参数调优,基于DP的LMs在一些下游分类任务上可以达到与没有DP的正常调优相似的性能。然而,当下游任务变得复杂时,大多数工作仍然表现出显著的效用恶化。降级效用削弱了基于DP微调的动机。
Future Directions
Ongoing Studies about Prompt Injection Attacks
这些攻击旨在影响LLMs的输出,并可能产生深远的后果,如产生有偏见或误导性信息、散布虚假信息,甚至损害敏感数据。到目前为止,已经提出了几种即时注入攻击来利用LLM及其相关插件应用程序中的漏洞。尽管如此,基于领域的LLMs应用的隐私和安全问题仍是一个未被探索的领域。
此外,随着对这些攻击的认识不断提高,现有的安全机制无法抵御这些新的攻击。因此,开发有效的防御措施来增强LLMs的隐私和安全性变得越来越迫切。
Future Improvements on SMPC
研究人员正在探索两种截然不同的技术途径:模型结构优化( MSO )和SMPC协议优化( SPO )。MSO和SPO各有其独特的优势。MSO通常在效率上表现优异,但在隐私保护推理和模型通用性方面可能面临限制。另一方面,SPO专注于优化SMPC协议,可以提高效率。不幸的是,SPO可能需要对模型结构进行修改,并且现有的预训练权重不能重复使用。
挑战在于找到一种方法来整合MSO和SPO的优势,旨在为LLMs设计一个高效、高性能和高通用性的隐私保护推理算法。克服这一挑战仍然是一个持续的研究工作。
Privacy Alignment to Human Perception
目前,大多数关于隐私研究的工作都集中在预先定义隐私公式的简单情况。对于现有的商业产品,通过命名实体识别( NER )工具提取个人身份信息,并在输入LLM之前进行PII匿名化。这些朴素的提法利用现有的工具将所有提取的预定义命名实体视为敏感信息。
一方面,这些研究的隐私提法可能并不总是真实的,并被所有人所接受。另一方面,这些研究只涵盖了狭小的范围,未能提供对隐私的全面理解。对于个体而言,我们的隐私感知受到社会规范、种族、宗教信仰和隐私法律的影响。因此,期望不同的用户群体表现出不同的隐私偏好。然而,这种以人为中心的隐私研究仍未被发掘。
Empirical Privacy Evaluation
对于隐私评估,最直接的方法是给出DP - Tuned LM的DP参数。这种简单的评估方法通常用于基于DP的LM。几项工作开始使用经验性隐私攻击作为隐私评估指标。尽管如此,适当的隐私评估指标仍是未来工作的期望。
Towards Contextualized Privacy Judgment
除了针对具体案例的隐私研究,还缺少一个通用的隐私侵犯检测框架。目前的工作仅限于简化的场景,包括PII清洗和去除单个数据样本。即使可以完美地完成敏感数据清洗,在给定的背景下仍然可能发生个人信息泄露。例如,在与基于LLMs的聊天机器人进行多轮对话时,即使对话的每一句话都不包含私人信息,也可以基于整个语境推断个人属性。更有甚者,用户可能会伪造PII,即不包含任何人的私人信息。要解决这类复杂问题,需要考察在长情境下具有推理能力的隐私判断框架
