
阅读量:0
内存对齐是什么
内存对齐指的是数据在内存中的布局方式,它确保每个数据类型的起始地址能够满足该类型对齐的要求。这是因为现代处理器在访问内存时,如果数据的起始地址能够对齐到一定的边界,那么访问速度会更快。这种对齐通常是基于数据类型大小的倍数。内存对齐包括两种相互独立又相互关联的部分:基本数据对齐和结构体数据对齐。
内存对齐的原因
内存对齐的主要原因有两个:性能和硬件限制。
性能原因
- 硬件访问效率:现代处理器设计为能够更高效地访问对齐的数据。这是因为处理器内部的总线宽度和寄存器大小通常决定了数据的最佳访问粒度。例如,如果一个处理器的寄存器大小是64位,那么访问64位对齐的长整型数据会比访问未对齐的数据更快,因为后者可能需要多次内存访问才能装载完整数据。
- 缓存性能:现代处理器使用多层次的缓存(L1, L2, L3等)来提高数据访问速度。数据对齐有助于缓存行的高效使用,减少缓存未命中,从而提高整体性能。
- 并发访问:在多核或多处理器系统中,对齐数据可以减少访问冲突,因为每个处理器或核心可以更有效地访问自己负责的内存区域。
硬件限制
- 硬件异常:某些硬件平台可能无法访问未对齐的内存地址,访问未对齐数据可能导致硬件异常或陷阱,这会极大地降低程序的性能,甚至导致程序崩溃。
- 字节序问题:虽然内存对齐与字节序(endianness)直接关联不大,但在处理字节序敏感的数据时,对齐可以避免额外的字节交换操作,从而提高性能。
内存对齐原则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。在ios中,Xcode默认为#pragma pack(8),即8字节对齐
数据成员对齐原则:
结构体的第一个数据成员放置在offset为0的位置。
后续的数据成员将被放置在它们各自自然对齐的地址上,即如果成员是4字节的整型,它将被放置在4字节对齐的位置;如果是8字节的双精度浮点型,它将被放置在8字节对齐的位置。
结构体总大小对齐原则:
- 结构体的总大小必须是其内部最大成员大小的整数倍。如果结构体的自然大小不符合这个条件,编译器会在最后一个成员之后填充一些额外的字节,直到整个结构体的大小满足对齐要求。
自然边界对齐原则:: 每种数据类型都有一个“自然”边界,这是指数据类型大小的整数倍地址。例如,一个
int类型在32位系统中通常占用4个字节,因此它应该在地址能够被4整除的位置开始。同样,一个short类型(通常2个字节)应该在能够被2整除的地址开始,以此类推。
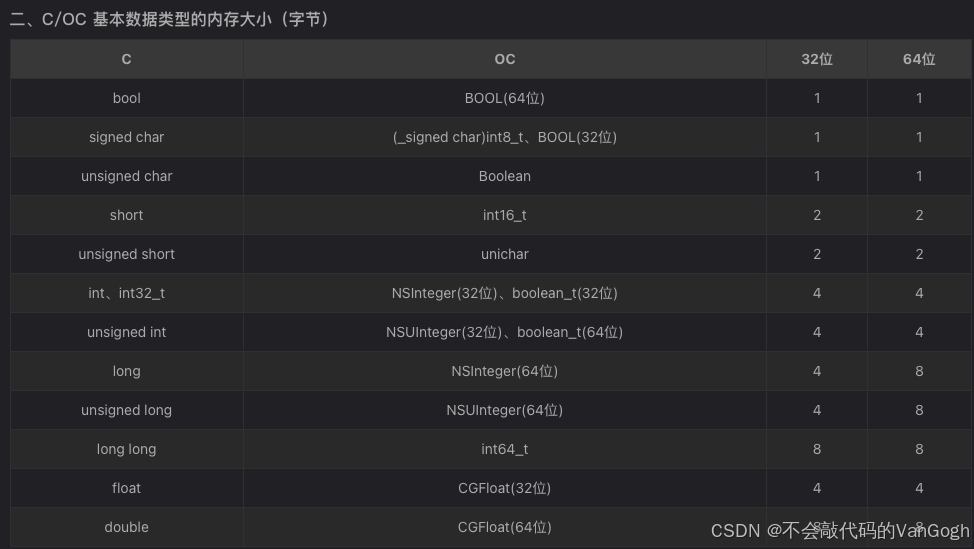
可以将内存对齐原则可以理解为以下几点:
- 【原则一】 数据成员的对齐规则可以理解为
min(m, n)的公式, 其中m表示当前成员的开始位置,n表示当前成员所需要的位数。如果满足条件m 整除 n(即m % n == 0),n从m位置开始存储, 反之继续检查 m+1 能否整除 n, 直到可以整除, 从而就确定了当前成员的开始位置。 - 【原则二】数据成员为结构体:当结构体嵌套了结构体时,作为数据成员的结构体的
自身长度作为外部结构体的最大成员的内存大小,比如结构体a嵌套结构体b,b中有char、int、double等,则b的自身长度为8 - 【原则三】最后
结构体的内存大小必须是结构体中最大成员内存大小的整数倍,不足的需要补齐。
下面举个例子:
struct Example { char c; int i; double d; }; char的大小为1字节,int的大小为4字节,而double的大小为8字节。由于double是最大的成员,所以整个结构体的大小必须是8字节的倍数。char会放在offset为0的位置,int会放在offset为4的位置(因为它需要4字节对齐),而double会放在offset为8的位置(因为它需要8字节对齐)。由于double之后没有更多的成员,所以结构体的大小就刚好是16字节,正好是8字节的倍数。
结构体嵌套的对齐
当结构体嵌套其他结构体时,不仅要考虑单个成员的对齐,还要考虑嵌套结构体本身的对齐和整个复合结构体的对齐。
遵循以下原则:
- 嵌套的结构体成员将被视为一个单一的整体,其对齐需求基于嵌套结构体中最大成员的对齐需求。
- 如果嵌套的结构体中有自己的对齐需求(比如含有
double类型),那么在外部结构体中,嵌套结构体将按照其内部最大成员的对齐需求进行对齐。 - 外部结构体的对齐取决于其所有成员(包括嵌套结构体)的最大对齐需求。
- 如果嵌套结构体的对齐需求大于外部结构体中任何其他成员的对齐需求,那么整个外部结构体将按照嵌套结构体的对齐需求对齐。
- 当嵌套结构体不符合其对齐需求时,编译器会在嵌套结构体之前插入填充字节。嵌套结构体结束后的下一个成员需要更大的对齐,编译器会在嵌套结构体之后插入填充字节。
- 整个结构体的大小也必须满足结构体中最大成员的对齐需求。如果结构体的自然大小不满足这一要求,编译器会在结构体末尾添加额外的填充字节。
获取内存大小的方式
获取内存大小的三种方式分别是:
- sizeof
- class_getInstanceSize
- malloc_size
sizeof
1、sizeof是一个操作符,不是函数
2、我们一般用sizeof计算内存大小时,传入的主要对象是数据类型,这个在编译器的编译阶段(即编译时)就会确定大小而不是在运行时确定。
3、sizeof最终得到的结果是该数据类型占用空间的大小
class_getInstanceSize
这个方法是runtime提供的api,用于获取类的实例对象所占用的内存大小,并返回具体的字节数,其本质就是获取实例对象中成员变量的内存大小。采用8字节对齐,参照的对象的属性内存大小
malloc_size
这个函数是获取系统实际分配的内存大小。采用16字节对齐,参照的整个对象的内存大小,对象实际分配的内存大小必须是16的整数倍
目前已知的16字节内存对齐算法有两种
alloc源码分析中的align16:malloc源码分析中的segregated_size_to_fit
下面举个例子:
#import <Foundation/Foundation.h> #import <objc/runtime.h> #import <malloc/malloc.h> int main(int argc, const char * argv[]) { @autoreleasepool { NSObject *objc = [[NSObject alloc] init]; NSLog(@"objc对象类型占用的内存大小:%lu",sizeof(objc)); NSLog(@"objc对象实际占用的内存大小:%lu",class_getInstanceSize([objc class])); NSLog(@"objc对象实际分配的内存大小:%lu",malloc_size((__bridge const void*)(objc))); } return 0; } 
内存优化(属性重排)
结构体内存大小与结构体成员内存大小的顺序有关:
如果是结构体中数据成员是根据内存从小到大的顺序定义的,根据内存对齐规则来计算结构体内存大小,需要增加有较大的内存padding即内存占位符,才能满足内存对齐规则,比较浪费内存
如果是结构体中数据成员是根据内存从大到小的顺序定义的,根据内存对齐规则来计算结构体内存大小,我们只需要补齐少量内存padding即可满足堆存对齐规则,这种方式就是苹果中采用的,利用空间换时间,将类中的属性进行重排,来达到优化内存的目的
在字节对齐算法中,对齐的主要是对象,对象的本质是objc_object结构体。
对于一个
对象来说,其真正的对齐方式是8字节对齐,8字节对齐已经足够满足对象的需求了apple系统为了防止一切的容错,采用的是16字节对齐的内存,主要是因为采用8字节对齐时,两个对象的内存会紧挨着,显得比较紧凑,而16字节比较宽松,利于苹果以后的扩展。
