
阅读量:0
文章目录
以下是本篇文章正文内容
一、哨兵是什么?
哨兵巡查监控后台master主机是否故障,如果故障了
根据投票数自动将某一个从库转换为新主库,继续对外服务,俗称无人值守运维
作用:监控redis运行状态,包括master和slave,当master down机时,能自动将slave切换成新master
哨兵的四个功能
- 主从监控
- 监控主从redis库运行是否正常
- 消息通知
- 哨兵可以将故障转移的结果发送到客户端
- 故障转移
- 如果master异常,则会进行主从切换,将其中一个slave作为新master
- 配置中心
- 客户端通过连接哨兵来获得当前Redis服务的主节点地址
Redis Sentinel架构
客户端通过哨兵集群访问redis 主从复制架构,哨兵集群对主从复制进行监视
本案例架构如下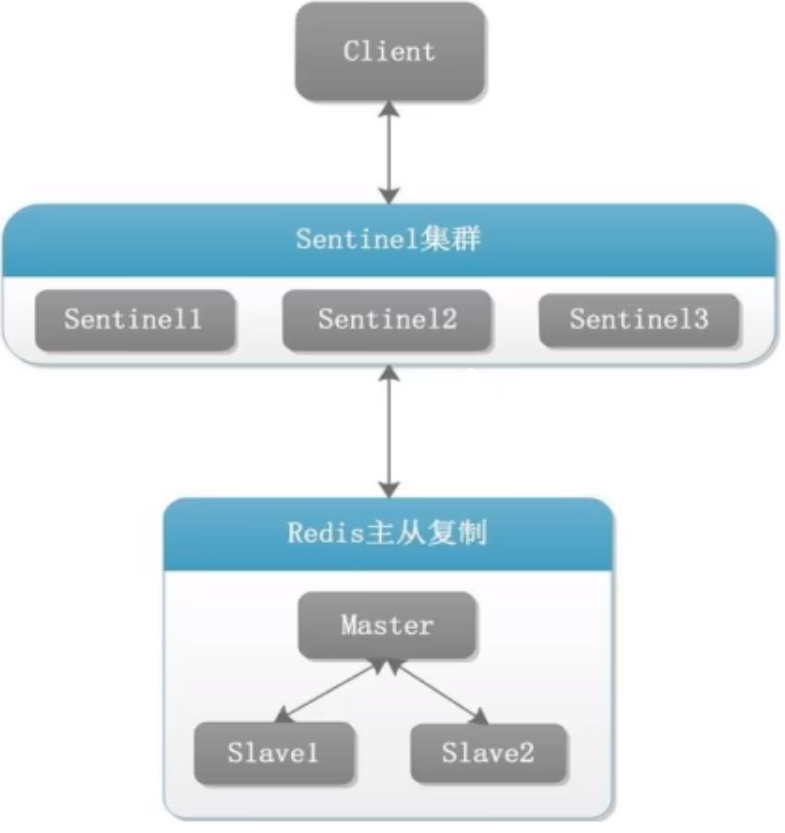
- 3个哨兵
- 自动监控和维护集群,不存放数据,只是监控
- 1主2从
- 用于数据读取和存放
- 主机后续可能会变成从机,需要设置访问新主机的密码,需要在主机conf文件设置masterauth项访问密码为111111,
二、 哨兵sentinel文件参数
- bind 服务监听地址,用于客户端连接
- daemonize 是否以后台daemon方式运行
- protected-mode 安全保护模式
- port 端口
- logfile 日志文件路径
- pidfile pid日志路径
- dir 工作目录
- sentiel monitor < master > < ip > < redis-port > < quorm >
- 设置要监控的master
- quorm 表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,在sentinel集群环境下需要多个sentinel互相沟通来确认某个master是否真的死了,
quorum这个参数是进行客观下线的一个依据,意思是至少有quorum个sentinel认为这个master有故障,才会对这个master进行下线以及故障转移。
因为有的时候,某个sentinel节点可能因为自身网络原因,导致无法连接master,而此时master并没有出现故障,所以,这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
- sentiel auth-pass 通过密码连接master
可以直接把以上参数新建一个文件sentiel.conf写进redis工作的目录(即redis.conf所在的目录)
本案例有三个哨兵,需要新建三个sentiel.conf文件
启动主从redis后,启动哨兵
redis-sentinel sentinel26379.conf --sentinel redis-sentinel sentinel26380.conf --sentinel redis-sentinel sentinel26381.conf --sentinel Tip:一个哨兵可以同时监控多个redis,只需将配置文件中这些参数进行调整,需要时候可以另行搜索学习。
三、 模仿主机redis宕机
关闭6379主机redis服务器,模仿master挂了
两台从机的数据不会丢失
会从其他两台从机选出一个新的master
挂掉的master重连回来,直接变成新master的从机
本案例中的 sentinel26379.conf、sentinel26380.conf、sentinel26381.conf会在运行中进行动态更改,在conf文件末尾自动添加主从redis所需要的配置
在master-slave切换中,master的conf文件中会自动多一行slaveof的配置
四、哨兵运行流程和选举原理
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master
用于自动接替原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换
SDOWN主观下线
SDOWN 是单个sentinel 自己主观上检测到的关于master的失效状态,从sentinel的角度来看,如果发送了PING心跳后,在timeout时间内没有收到合法的回复,就达到了SDOWN的条件
sentinel配置文件中的
down-after-milliseconds设置了判断主观下线的时间长度sentinel down-after-milliseconds <masterName> <timeout>

ODOWN客观下线
ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个master客观上已经宕机
这就用到了二、 哨兵sentinel文件参数中的sentiel monitor < master > < ip > < redis-port > < quorm >命令
quorm 表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
选举出领导者哨兵
当主节点被判断客观下线以后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点并由该领导者节点进行failover(故障迁移)- Raft算法 选出领导者节点
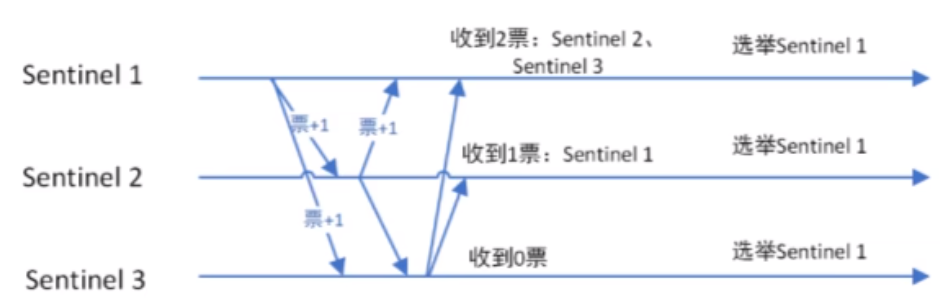
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;
Raft算法的基本思路是先到先得:即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者
由领导者节点开始推动故障切换并选出一个新master
- 某个slave 成为新 master
- 其它slave自动进行相关配置和命令修改
- 老master回来也变为slave
选举新master的过程:
- 优先级高的成为新master
- 否则是复制偏移量大的成为新master(即谁的复制的数据多)
- 否则看RunID,最小的为新master
以上的failover都是sentinel自己独立完成,完全无需人工干预
五、 使用建议
- 哨兵节点的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该是奇数个(这是从投票机制考虑,避免相同票数导致不能决定SDOWN主观下线)
- 各个哨兵节点的配置应该一致
- 如果哨兵节点部署在Docker等容器里,要注意端口的正确映射
- 哨兵集群+主从复制,并不能保证数据零丢失(因为选举机制会有时间间隔,导致写入操作的丢失)
