
阅读量:4
文章目录
上课笔记
个人能力有限,重看几遍吧,第一遍基本看不懂
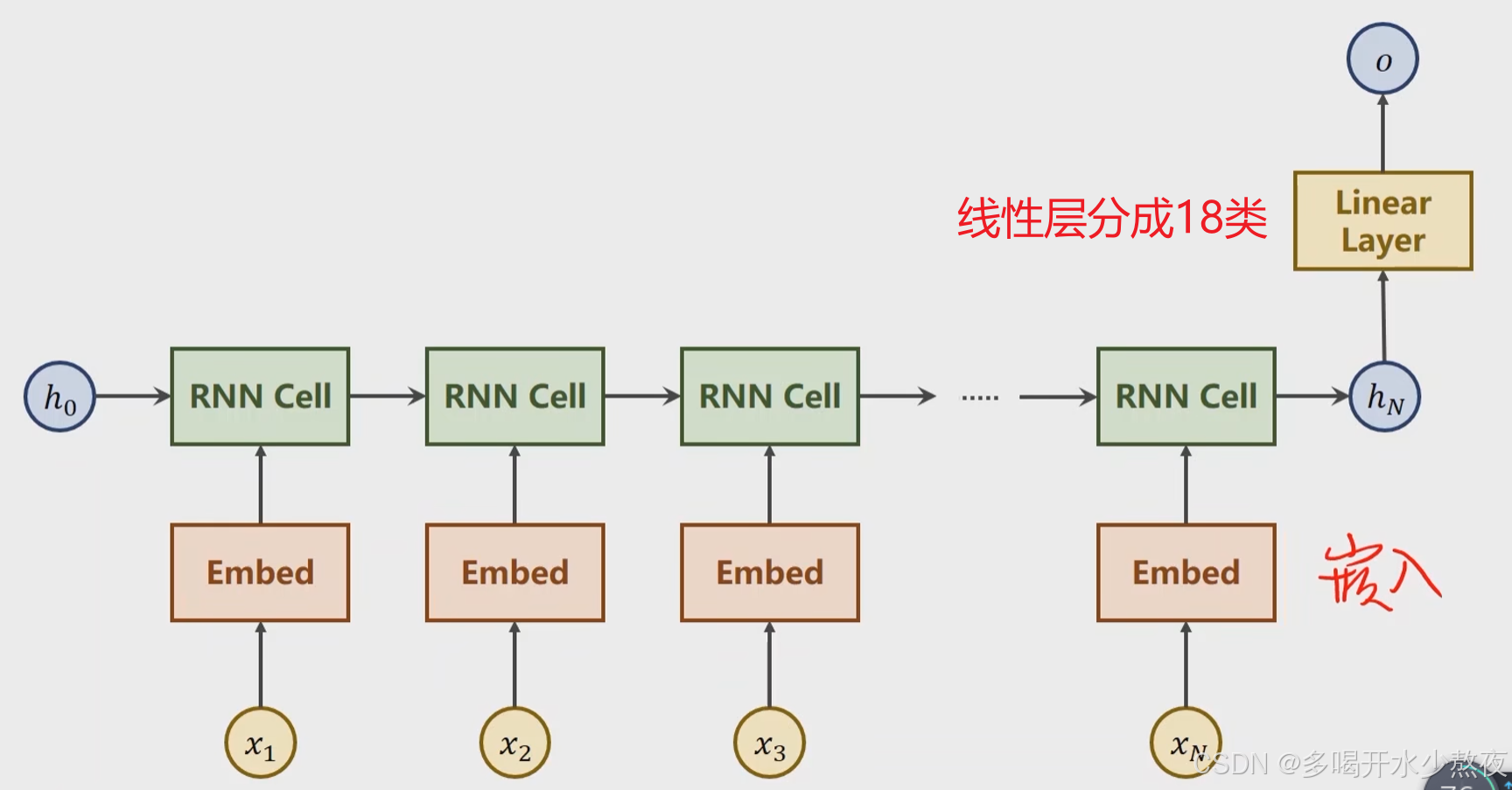
名字的每个字母都是一个特征x1,x2,x3…,一个名字是一个序列
rnn用GRU
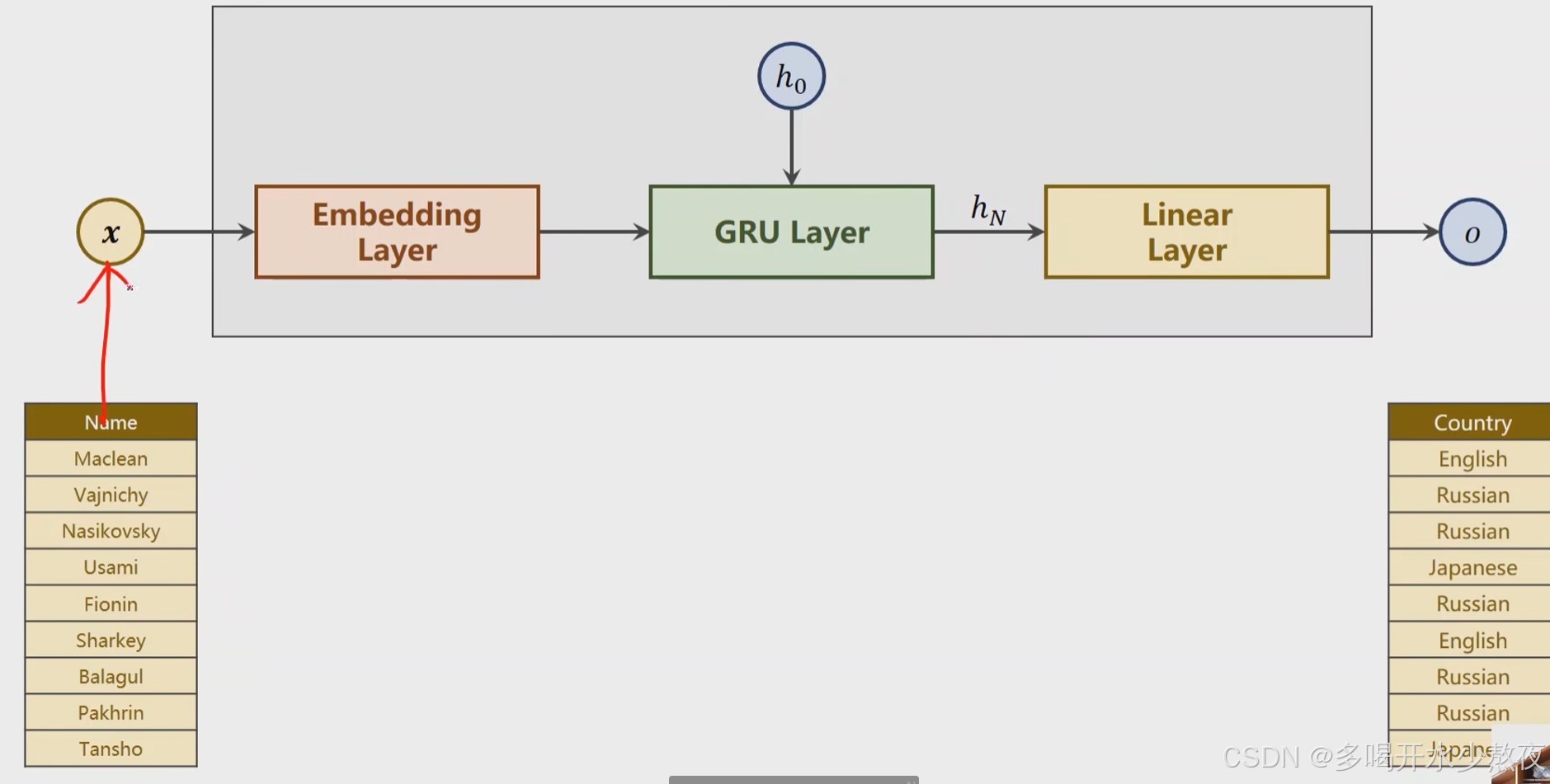
用ASCII表作为词典,长度为128,每一个值对应一个独热向量,比如77对应128维向量中第77个位置为1其他位置为0,但是对于embed层只要告诉它哪个是1就行,这些序列长短不一,需要padding到统一长度

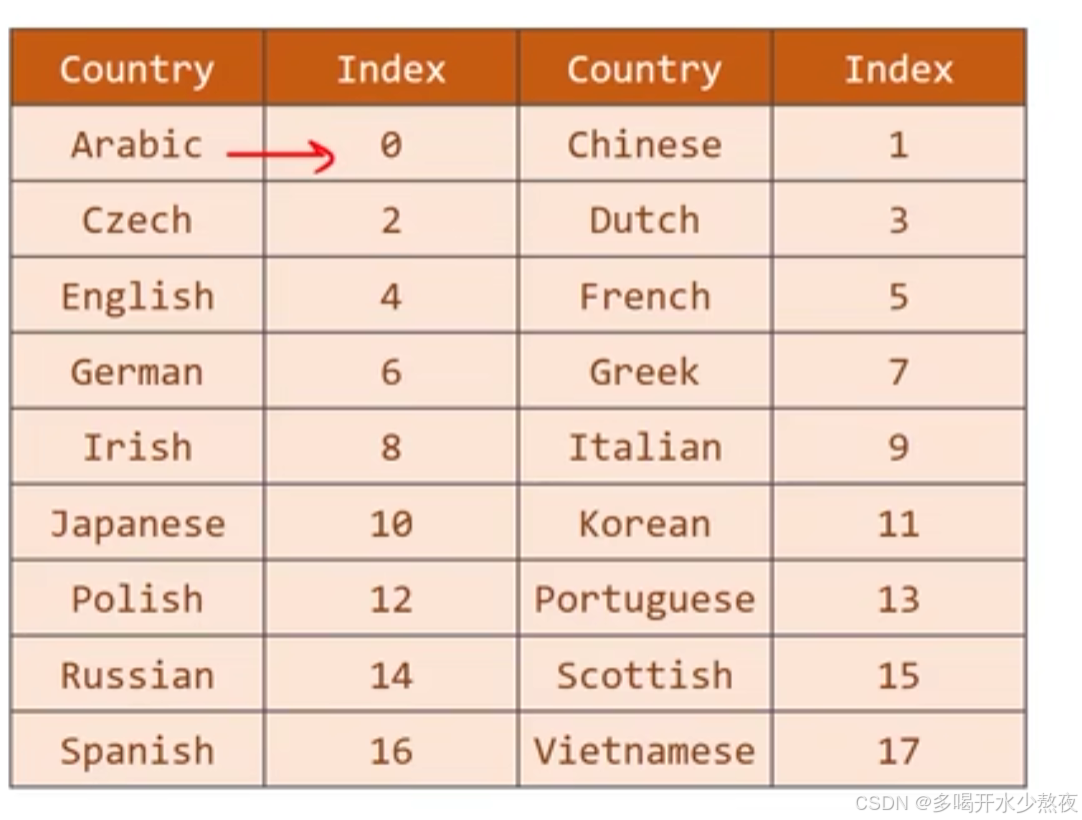
把国家的名字变成索引标签,做成下图所示的词典
数据集构建
class NameDataset(Dataset): def __init__(self, is_train=True): # 文件读取 filename = './dataset/names_train.csv.gz' if is_train else './dataset/names_test.csv.gz' with gzip.open(filename, 'rt') as f: # rt表示以只读模式打开文件,并将文件内容解析为文本形式 reader = csv.reader(f) rows =list(reader) # 每个元素由一个名字和国家组成 # 提取属性 self.names = [row[0] for row in rows] self.len = len(self.names) self.countries = [row[1] for row in rows] # 编码处理 self.country_list = list(sorted(set(self.countries))) # 列表,按字母表顺序排序,去重后有18个国家名 self.country_dict = self.get_countries_dict() # 字典,国家名对应序号标签 self.country_num = len(self.country_list) def __getitem__(self, item): # 索引获取 return self.names[item], self.country_dict[self.countries[item]] # 根据国家去字典查找索引 def __len__(self): # 获取个数 return self.len def get_countries_dict(self): # 根据国家名对应序号 country_dict = dict() for idx, country_name in enumerate(self.country_list): country_dict[country_name] = idx return country_dict def idx2country(self, index): # 根据索引返回国家名字 return self.country_list[index] def get_countries_num(self): # 返回国家名个数(分类的总个数) return self.country_num 双向RNN,从左往右走一遍,把得到的值和逆向计算得到的hN拼到一起,比如最后一个 [ h 0 b , h n f ] [h^b_0, h^f_n] [h0b,hnf]
self.n_directions = 2 if bidirectional else 1 self.gru = torch.nn.GRU(hidden_size, hidden_size, num_layers=n_layers, bidirectional=bidirectional)#bidirectional双向神经网络 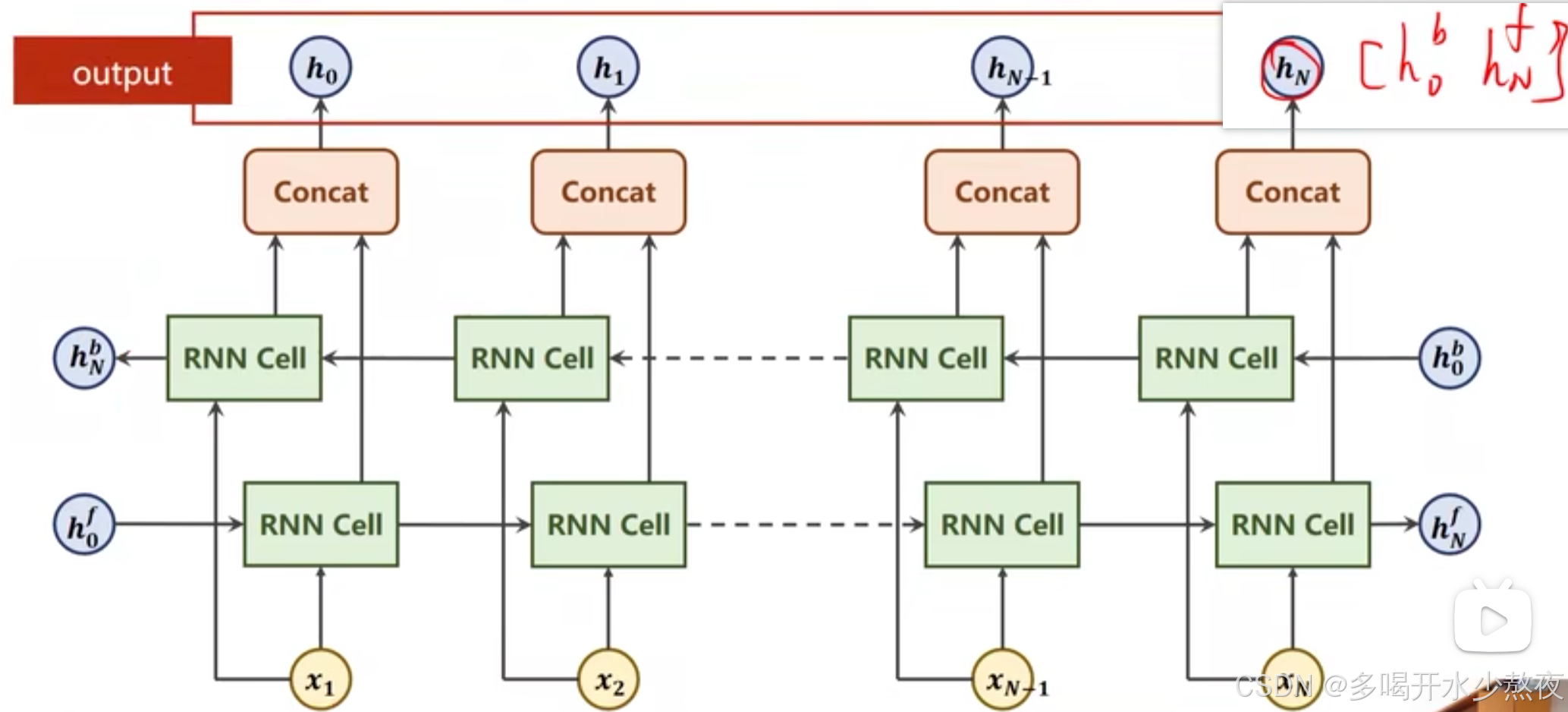
h i d d e n = [ h N f , h N b ] hidden = [h{^f_N},h{^b_N}] hidden=[hNf,hNb]
# 进行打包(不考虑0元素,提高运行速度)首先需要将嵌入数据按长度排好 gru_input = pack_padded_sequence(embedding, seq_lengths) pack_padded_sequence:这是 PyTorch 提供的一个函数,用于将填充后的序列打包。其主要目的是跳过填充值,并且在 RNN 中只处理实际的序列数据。它会将填充后的嵌入和实际序列长度作为输入,并返回一个打包后的序列,便于 RNN 处理。可以只把非零序列提取出来放到一块,也就是把为0的填充量都丢掉,这样将来fru就可以处理长短不一的输入序列
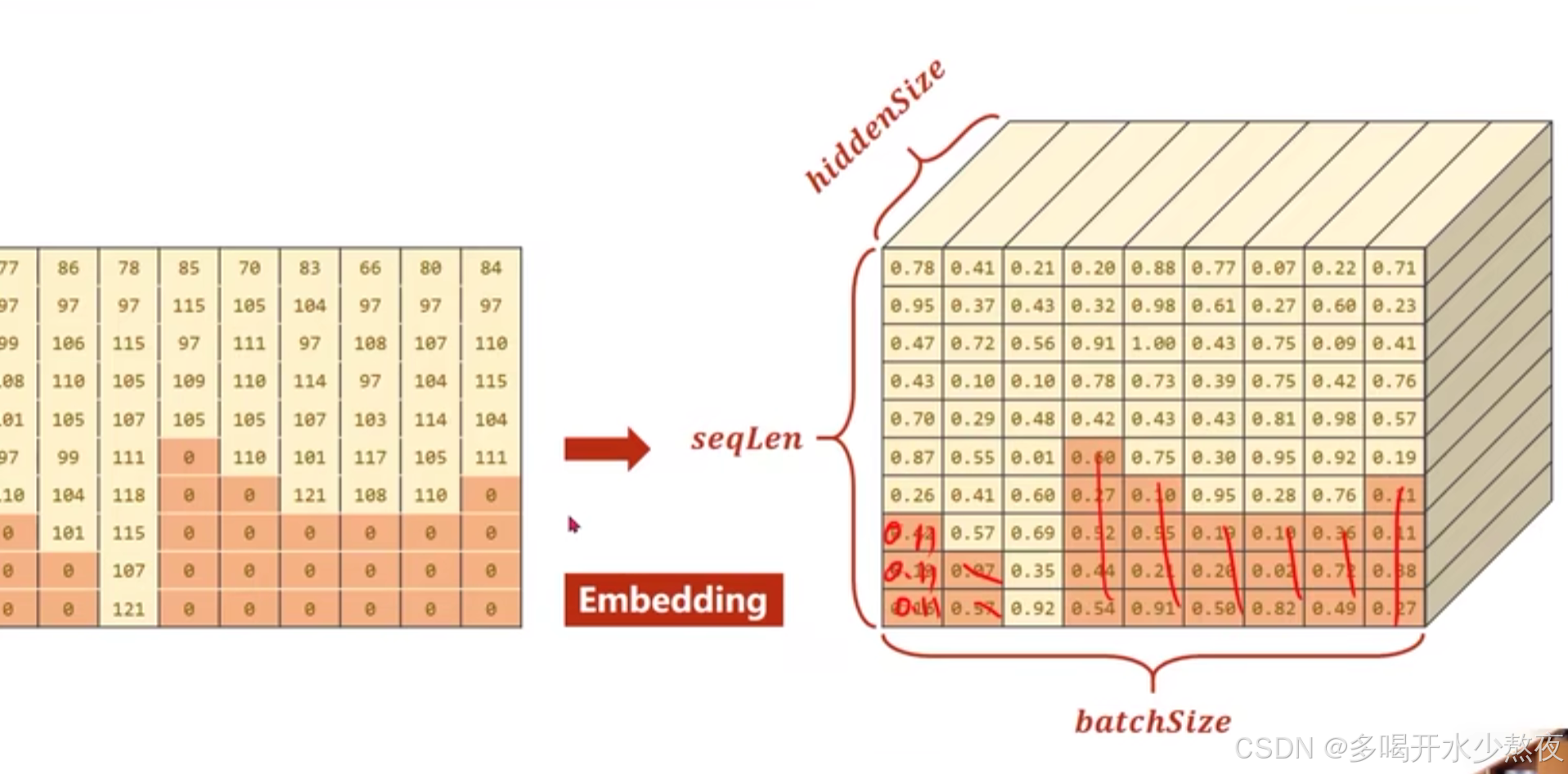
首先要根据序列长度进行排序,然后再经过嵌入层
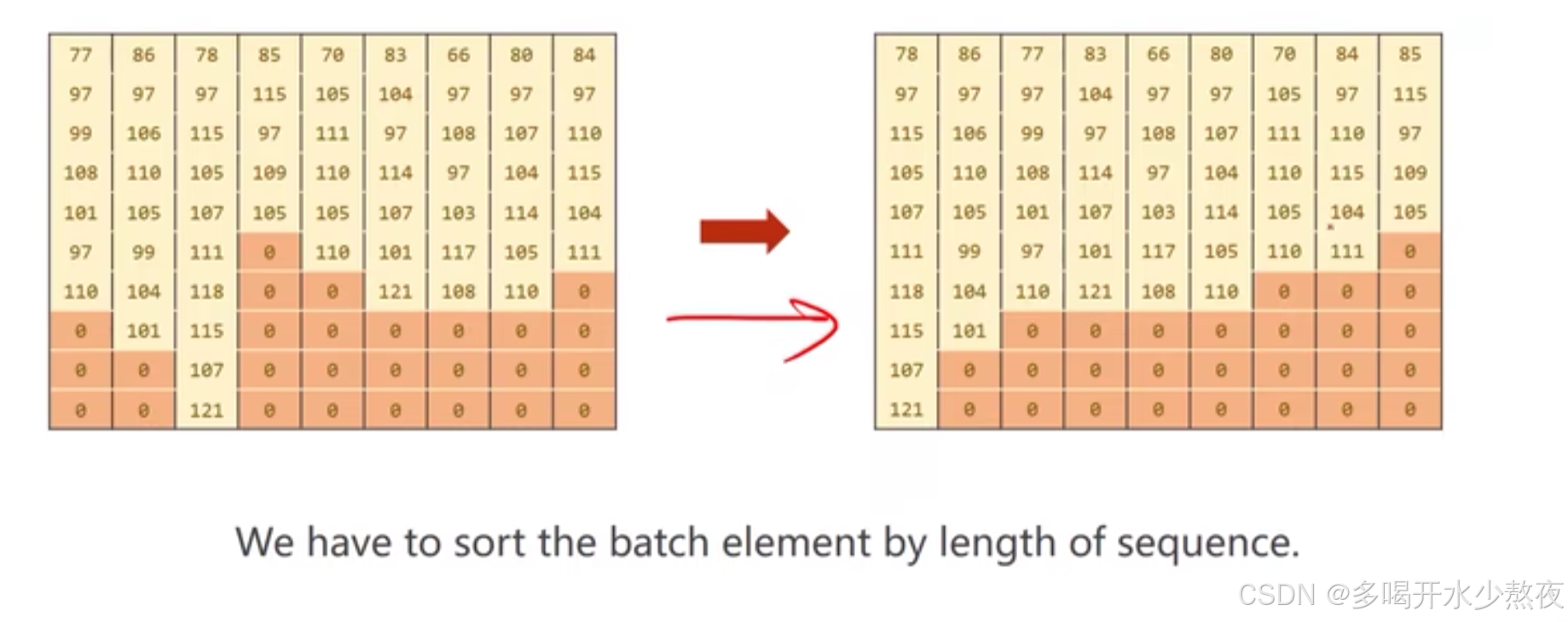
如下图所示:这样用gru的时候效率就会更高,因为可以方便去掉好多padding的数据
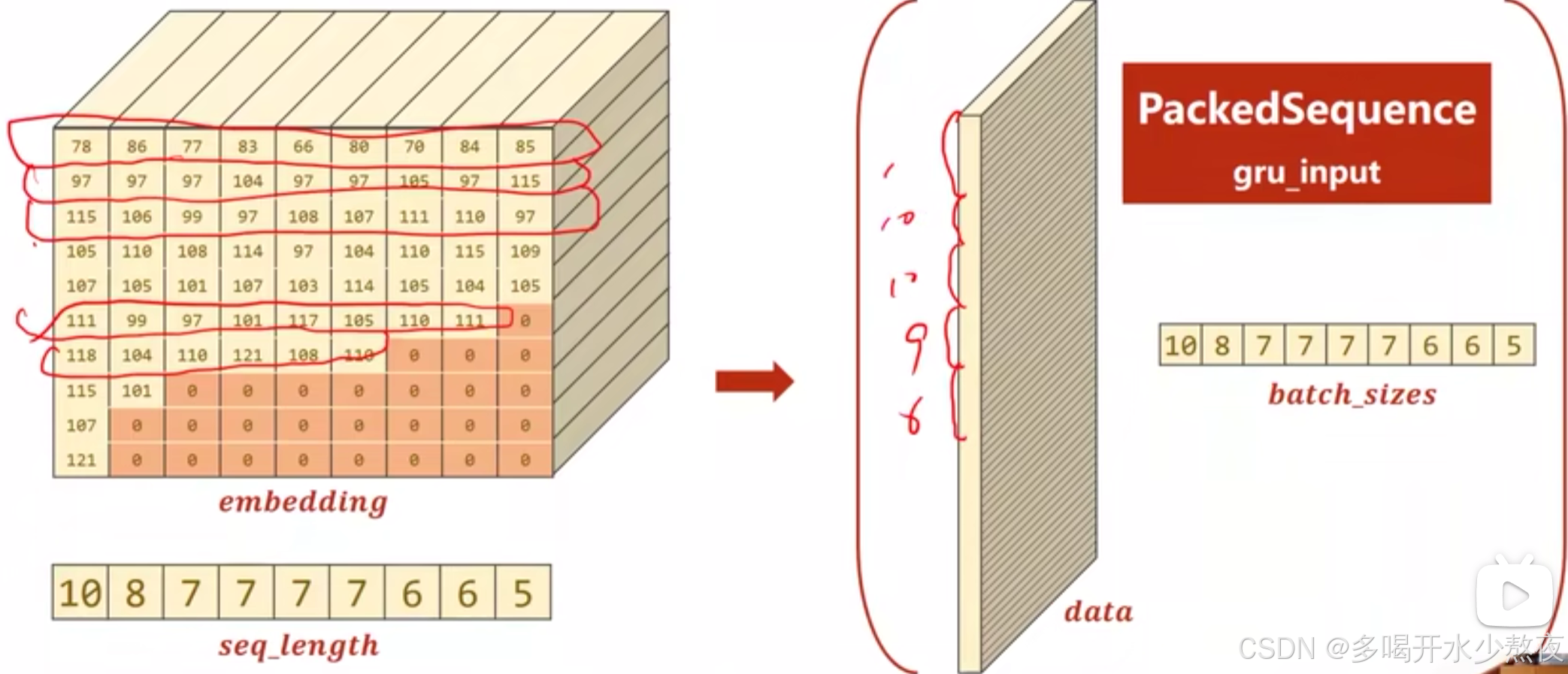
双向RNN要拼接起来
if self.n_directions == 2: hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1) # hidden[-1]的形状是(1,256,100),hidden[-2]的形状是(1,256,100),拼接后的形状是(1,256,200) 总代码
import csv import time import matplotlib.pyplot as plt import numpy as np import math import gzip # 用于读取压缩文件 import torch import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torch.nn.utils.rnn import pack_padded_sequence # 1.超参数设置 HIDDEN_SIZE = 100 BATCH_SIZE = 256 N_LAYER = 2 # RNN的层数 N_EPOCHS = 100 N_CHARS = 128 # ASCII码的个数 USE_GPU = False # 工具类函数 # 把名字转换成ASCII码, b 返回ASCII码值列表和名字的长度 def name2list(name): arr = [ord(c) for c in name] return arr, len(arr) # 是否把数据放到GPU上 def create_tensor(tensor): if USE_GPU: device = torch.device('cuda:0') tensor = tensor.to(device) return tensor def timesince(since): now = time.time() s = now - since m = math.floor(s / 60) # math.floor()向下取整 s -= m * 60 return '%dmin %ds' % (m, s) # 多少分钟多少秒 # 2.构建数据集 class NameDataset(Dataset): def __init__(self, is_train=True): # 文件读取 filename = './dataset/names_train.csv.gz' if is_train else './dataset/names_test.csv.gz' with gzip.open(filename, 'rt') as f: # rt表示以只读模式打开文件,并将文件内容解析为文本形式 reader = csv.reader(f) rows =list(reader) # 每个元素由一个名字和国家组成 # 提取属性 self.names = [row[0] for row in rows] self.len = len(self.names) self.countries = [row[1] for row in rows] # 编码处理 self.country_list = list(sorted(set(self.countries))) # 列表,按字母表顺序排序,去重后有18个国家名 self.country_dict = self.get_countries_dict() # 字典,国家名对应序号标签 self.country_num = len(self.country_list) def __getitem__(self, item): # 索引获取 return self.names[item], self.country_dict[self.countries[item]] # 根据国家去字典查找索引 def __len__(self): # 获取个数 return self.len def get_countries_dict(self): # 根据国家名对应序号 country_dict = dict() for idx, country_name in enumerate(self.country_list): country_dict[country_name] = idx return country_dict def idx2country(self, index): # 根据索引返回国家名字 return self.country_list[index] def get_countries_num(self): # 返回国家名个数(分类的总个数) return self.country_num # 3.实例化数据集 train_set = NameDataset(is_train=True) train_loader = DataLoader(train_set, shuffle=True, batch_size=BATCH_SIZE, num_workers=2) test_set = NameDataset(is_train=False) test_loder = DataLoader(test_set, shuffle=False, batch_size=BATCH_SIZE, num_workers=2) N_COUNTRY = train_set.get_countries_num() # 18个国家名,即18个类别 # 4.模型构建 class GRUClassifier(torch.nn.Module): def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True): super(GRUClassifier, self).__init__() self.hidden_size = hidden_size self.n_layers = n_layers self.n_directions = 2 if bidirectional else 1 # 词嵌入层,将词语映射到hidden维度 self.embedding = torch.nn.Embedding(input_size, hidden_size) # GRU层(输入为特征数,这里是embedding_size,其大小等于hidden_size)) self.gru = torch.nn.GRU(hidden_size, hidden_size, num_layers=n_layers, bidirectional=bidirectional)#bidirectional双向神经网络 # 线性层 self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self, bath_size): # 初始化权重,(n_layers * num_directions 双向, batch_size, hidden_size) hidden = torch.zeros(self.n_layers * self.n_directions, bath_size, self.hidden_size) return create_tensor(hidden) def forward(self, input, seq_lengths): # 转置 B X S -> S X B input = input.t() # 此时的维度为seq_len, batch_size batch_size = input.size(1) hidden = self._init_hidden(batch_size) # 嵌入层处理 input:(seq_len,batch_size) -> embedding:(seq_len,batch_size,embedding_size) embedding = self.embedding(input) # 进行打包(不考虑0元素,提高运行速度)需要将嵌入数据按长度排好 gru_input = pack_padded_sequence(embedding, seq_lengths) # output:(*, hidden_size * num_directions),*表示输入的形状(seq_len,batch_size) # hidden:(num_layers * num_directions, batch, hidden_size) output, hidden = self.gru(gru_input, hidden) if self.n_directions == 2: hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1) # hidden[-1]的形状是(1,256,100),hidden[-2]的形状是(1,256,100),拼接后的形状是(1,256,200) else: hidden_cat = hidden[-1] # (1,256,100) fc_output = self.fc(hidden_cat) return fc_output # 3.数据处理(姓名->数字) def make_tensors(names, countries): # 获取嵌入长度从大到小排序的seq_tensor(嵌入向量)、seq_lengths(对应长度)、countries(对应顺序的国家序号)-> 便于pack_padded_sequence处理 name_len_list = [name2list(name) for name in names] # 每个名字对应的1列表 name_seq = [sl[0] for sl in name_len_list] # 姓名列表 seq_lengths = torch.LongTensor([sl[1] for sl in name_len_list]) # 名字对应的字符个数 countries = countries.long() # PyTorch 中,张量的默认数据类型是浮点型 (float),这里转换成整型,可以避免浮点数比较时的精度误差,从而提高模型的训练效果 # 创建全零张量,再依次进行填充 # 创建了一个 len(name_seq) * seq_length.max()维的张量 seq_tensor = torch.zeros(len(name_seq), seq_lengths.max()).long() for idx, (seq, seq_len) in enumerate(zip(name_seq, seq_lengths)): seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # 为了使用pack_padded_sequence,需要按照长度排序 # perm_idx是排序后的数据在原数据中的索引,seq_tensor是排序后的数据,seq_lengths是排序后的数据的长度,countries是排序后的国家 seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) # descending=True 表示按降序进行排序,即从最长的序列到最短的序列。 seq_tensor = seq_tensor[perm_idx] countries = countries[perm_idx] return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries) # 训练循环 def train(epoch, start): total_loss = 0 for i, (names, countries) in enumerate(train_loader, 1): inputs, seq_lengths, target = make_tensors(names, countries) # 输入、每个序列长度、输出 output = model(inputs, seq_lengths) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() if i % 10 == 0: print(f'[{timesince(start)}] Epoch {epoch} ', end='') print(f'[{i * len(inputs)}/{len(train_set)}] ', end='') print(f'loss={total_loss / (i * len(inputs))}') # 打印每个样本的平均损失 return total_loss # 测试循环 def test(): correct = 0 total = len(test_set) print('evaluating trained model ...') with torch.no_grad(): for i, (names, countries) in enumerate(test_loder, 1): inputs, seq_lengths, target = make_tensors(names, countries) output = model(inputs, seq_lengths) pred = output.max(dim=1, keepdim=True)[1] # 返回每一行中最大值的那个元素的索引,且keepdim=True,表示保持输出的二维特性 correct += pred.eq(target.view_as(pred)).sum().item() # 计算正确的个数 percent = '%.2f' % (100 * correct / total) print(f'Test set: Accuracy {correct}/{total} {percent}%') return correct / total # 返回的是准确率,0.几几的格式,用来画图 if __name__ == '__main__': model = GRUClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER) criterion = torch.nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) device = 'cuda:0' if USE_GPU else 'cpu' model.to(device) start = time.time() print('Training for %d epochs...' % N_EPOCHS) acc_list = [] # 在每个epoch中,训练完一次就测试一次 for epoch in range(1, N_EPOCHS + 1): # Train cycle train(epoch, start) acc = test() acc_list.append(acc) # 绘制在测试集上的准确率 epoch = np.arange(1, len(acc_list) + 1) acc_list = np.array(acc_list) plt.plot(epoch, acc_list) plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.grid() plt.show() 在准确率最高点save模型
保存整个模型:
torch.save(model,'save.pt') 只保存训练好的权重:
torch.save(model.state_dict(), 'save.pt') 练习
数据集地址,判断句子是哪类(0-negative,1-somewhat negative,2-neutral,3-somewhat positive,4-positive)情感分析
import pandas as pd import torch from torch.utils.data import Dataset, DataLoader import torch.nn as nn import torch.optim as optim from sklearn.preprocessing import LabelEncoder from torch.nn.utils.rnn import pad_sequence from torch.nn.utils.rnn import pack_padded_sequence import zipfile # 超参数设置 BATCH_SIZE = 64 HIDDEN_SIZE = 100 N_LAYERS = 2 N_EPOCHS = 10 LEARNING_RATE = 0.001 # 数据集路径 TRAIN_ZIP_PATH = './dataset/train.tsv.zip' TEST_ZIP_PATH = './dataset/test.tsv.zip' # 解压缩文件 def unzip_file(zip_path, extract_to='.'): with zipfile.ZipFile(zip_path, 'r') as zip_ref: zip_ref.extractall(extract_to) unzip_file(TRAIN_ZIP_PATH) unzip_file(TEST_ZIP_PATH) # 数据集路径 TRAIN_PATH = './train.tsv' TEST_PATH = './test.tsv' # 自定义数据集类 class SentimentDataset(Dataset): def __init__(self, phrases, sentiments=None): self.phrases = phrases self.sentiments = sentiments def __len__(self): return len(self.phrases) def __getitem__(self, idx): phrase = self.phrases[idx] if self.sentiments is not None: sentiment = self.sentiments[idx] return phrase, sentiment return phrase # 加载数据 def load_data(): train_df = pd.read_csv(TRAIN_PATH, sep='\t') test_df = pd.read_csv(TEST_PATH, sep='\t') return train_df, test_df train_df, test_df = load_data() # 数据预处理 def preprocess_data(train_df, test_df): le = LabelEncoder() train_df['Sentiment'] = le.fit_transform(train_df['Sentiment']) train_phrases = train_df['Phrase'].tolist() train_sentiments = train_df['Sentiment'].tolist() test_phrases = test_df['Phrase'].tolist() return train_phrases, train_sentiments, test_phrases, le train_phrases, train_sentiments, test_phrases, le = preprocess_data(train_df, test_df) # 构建词汇表 def build_vocab(phrases): vocab = set() for phrase in phrases: for word in phrase.split(): vocab.add(word) word2idx = {word: idx for idx, word in enumerate(vocab, start=1)} word2idx['<PAD>'] = 0 return word2idx word2idx = build_vocab(train_phrases + test_phrases) # 将短语转换为索引 def phrase_to_indices(phrase, word2idx): return [word2idx[word] for word in phrase.split() if word in word2idx] train_indices = [phrase_to_indices(phrase, word2idx) for phrase in train_phrases] test_indices = [phrase_to_indices(phrase, word2idx) for phrase in test_phrases] # 移除长度为0的样本 train_indices = [x for x in train_indices if len(x) > 0] train_sentiments = [y for x, y in zip(train_indices, train_sentiments) if len(x) > 0] test_indices = [x for x in test_indices if len(x) > 0] # 数据加载器 def collate_fn(batch): phrases, sentiments = zip(*batch) lengths = torch.tensor([len(x) for x in phrases]) phrases = [torch.tensor(x) for x in phrases] phrases_padded = pad_sequence(phrases, batch_first=True, padding_value=0) sentiments = torch.tensor(sentiments) return phrases_padded, sentiments, lengths train_dataset = SentimentDataset(train_indices, train_sentiments) train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn) test_dataset = SentimentDataset(test_indices) test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=lambda x: pad_sequence([torch.tensor(phrase) for phrase in x], batch_first=True, padding_value=0)) # 模型定义 class SentimentRNN(nn.Module): def __init__(self, vocab_size, embed_size, hidden_size, output_size, n_layers): super(SentimentRNN, self).__init__() self.embedding = nn.Embedding(vocab_size, embed_size, padding_idx=0) self.lstm = nn.LSTM(embed_size, hidden_size, n_layers, batch_first=True, bidirectional=True) self.fc = nn.Linear(hidden_size * 2, output_size) def forward(self, x, lengths): x = self.embedding(x) x = pack_padded_sequence(x, lengths.cpu(), batch_first=True, enforce_sorted=False) _, (hidden, _) = self.lstm(x) hidden = torch.cat((hidden[-2], hidden[-1]), dim=1) out = self.fc(hidden) return out vocab_size = len(word2idx) embed_size = 128 output_size = len(le.classes_) model = SentimentRNN(vocab_size, embed_size, HIDDEN_SIZE, output_size, N_LAYERS) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # 训练和测试循环 def train(model, train_loader, criterion, optimizer, n_epochs): model.train() for epoch in range(n_epochs): total_loss = 0 for phrases, sentiments, lengths in train_loader: optimizer.zero_grad() output = model(phrases, lengths) loss = criterion(output, sentiments) loss.backward() optimizer.step() total_loss += loss.item() print(f'Epoch: {epoch+1}, Loss: {total_loss/len(train_loader)}') def generate_test_results(model, test_loader, test_ids): model.eval() results = [] with torch.no_grad(): for phrases in test_loader: lengths = torch.tensor([len(x) for x in phrases]) output = model(phrases, lengths) preds = torch.argmax(output, dim=1) results.extend(preds.cpu().numpy()) return results train(model, train_loader, criterion, optimizer, N_EPOCHS) test_ids = test_df['PhraseId'].tolist() preds = generate_test_results(model, test_loader, test_ids) # 保存结果 output_df = pd.DataFrame({'PhraseId': test_ids, 'Sentiment': preds}) output_df.to_csv('sentiment_predictions.csv', index=False) 引入随机性:重要性采样,对分类的样本按照它的分布来进行随机采样
gpt优化后代码:停词表自己在网上找个博客复制粘贴成stopwords.txt文件就行
主要改进点:
- 增加了嵌入层维度和隐藏层大小,LSTM 层数。
- 使用 GloVe 预训练词向量。
- 使用了 dropout 防止过拟合。
- 使用 AdamW 优化器。
- 移除停用词。
- 增加了验证集并使用学习率调度器用于模型性能评估。
- 保存和加载最优模型。
import pandas as pd import torch from torch.utils.data import Dataset, DataLoader import torch.nn as nn import torch.optim as optim from sklearn.preprocessing import LabelEncoder from torch.nn.utils.rnn import pad_sequence from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence from sklearn.model_selection import train_test_split import zipfile import os from torchtext.vocab import GloVe # 超参数设置 BATCH_SIZE = 64 HIDDEN_SIZE = 256 N_LAYERS = 3 N_EPOCHS = 20 LEARNING_RATE = 0.01 EMBED_SIZE = 300 DROPOUT = 0.5 # 数据集路径 TRAIN_ZIP_PATH = './dataset/train.tsv.zip' TEST_ZIP_PATH = './dataset/test.tsv.zip' # 解压缩文件 def unzip_file(zip_path, extract_to='.'): with zipfile.ZipFile(zip_path, 'r') as zip_ref: zip_ref.extractall(extract_to) unzip_file(TRAIN_ZIP_PATH) unzip_file(TEST_ZIP_PATH) # 数据集路径 TRAIN_PATH = './train.tsv' TEST_PATH = './test.tsv' # 自定义数据集类 class SentimentDataset(Dataset): def __init__(self, phrases, sentiments=None): self.phrases = phrases self.sentiments = sentiments def __len__(self): return len(self.phrases) def __getitem__(self, idx): phrase = self.phrases[idx] if self.sentiments is not None: sentiment = self.sentiments[idx] return phrase, sentiment return phrase # 加载数据 def load_data(): train_df = pd.read_csv(TRAIN_PATH, sep='\t') test_df = pd.read_csv(TEST_PATH, sep='\t') return train_df, test_df train_df, test_df = load_data() # 数据预处理 def preprocess_data(train_df, test_df): le = LabelEncoder() train_df['Sentiment'] = le.fit_transform(train_df['Sentiment']) train_phrases = train_df['Phrase'].tolist() train_sentiments = train_df['Sentiment'].tolist() test_phrases = test_df['Phrase'].tolist() test_ids = test_df['PhraseId'].tolist() return train_phrases, train_sentiments, test_phrases, test_ids, le train_phrases, train_sentiments, test_phrases, test_ids, le = preprocess_data(train_df, test_df) # 移除停用词 def remove_stopwords(phrases): stopwords = set(open('./dataset/stopwords.txt').read().split()) return [' '.join([word for word in phrase.split() if word not in stopwords]) for phrase in phrases] train_phrases = remove_stopwords(train_phrases) test_phrases = remove_stopwords(test_phrases) # 构建词汇表 def build_vocab(phrases): vocab = set() for phrase in phrases: for word in phrase.split(): vocab.add(word) word2idx = {word: idx for idx, word in enumerate(vocab, start=1)} word2idx['<PAD>'] = 0 return word2idx word2idx = build_vocab(train_phrases + test_phrases) # 加载预训练的词向量 glove = GloVe(name='6B', dim=EMBED_SIZE) def create_embedding_matrix(word2idx, glove): vocab_size = len(word2idx) embedding_matrix = torch.zeros((vocab_size, EMBED_SIZE)) for word, idx in word2idx.items(): if word in glove.stoi: embedding_matrix[idx] = glove[word] else: embedding_matrix[idx] = torch.randn(EMBED_SIZE) return embedding_matrix embedding_matrix = create_embedding_matrix(word2idx, glove) # 将短语转换为索引 def phrase_to_indices(phrase, word2idx): return [word2idx[word] for word in phrase.split() if word in word2idx] train_indices = [phrase_to_indices(phrase, word2idx) for phrase in train_phrases] test_indices = [phrase_to_indices(phrase, word2idx) for phrase in test_phrases] # 移除长度为0的样本 train_indices, train_sentiments = zip(*[(x, y) for x, y in zip(train_indices, train_sentiments) if len(x) > 0]) # 注意:这里不移除 test_indices 中的空样本,因为我们需要保持 test_ids 的完整性 test_indices_with_default = [phrase if len(phrase) > 0 else [0] for phrase in test_indices] # 划分训练集和验证集 train_indices, val_indices, train_sentiments, val_sentiments = train_test_split( train_indices, train_sentiments, test_size=0.2, random_state=42) # 数据加载器 def collate_fn(batch): phrases, sentiments = zip(*batch) lengths = torch.tensor([len(x) for x in phrases]) phrases = [torch.tensor(x) for x in phrases] phrases_padded = pad_sequence(phrases, batch_first=True, padding_value=0) sentiments = torch.tensor(sentiments) return phrases_padded, sentiments, lengths train_dataset = SentimentDataset(train_indices, train_sentiments) val_dataset = SentimentDataset(val_indices, val_sentiments) train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn) val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=collate_fn) test_dataset = SentimentDataset(test_indices_with_default) test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=lambda x: pad_sequence([torch.tensor(phrase) for phrase in x], batch_first=True, padding_value=0)) # 模型定义 class SentimentRNN(nn.Module): def __init__(self, vocab_size, embed_size, hidden_size, output_size, n_layers, dropout, embedding_matrix): super(SentimentRNN, self).__init__() self.embedding = nn.Embedding.from_pretrained(embedding_matrix, freeze=False) self.lstm = nn.LSTM(embed_size, hidden_size, n_layers, batch_first=True, bidirectional=True, dropout=dropout) self.fc = nn.Linear(hidden_size * 2, output_size) self.dropout = nn.Dropout(dropout) def forward(self, x, lengths): x = self.embedding(x) x = pack_padded_sequence(x, lengths.cpu(), batch_first=True, enforce_sorted=False) packed_output, (hidden, _) = self.lstm(x) hidden = torch.cat((hidden[-2], hidden[-1]), dim=1) hidden = self.dropout(hidden) out = self.fc(hidden) return out vocab_size = len(word2idx) output_size = len(le.classes_) model = SentimentRNN(vocab_size, EMBED_SIZE, HIDDEN_SIZE, output_size, N_LAYERS, DROPOUT, embedding_matrix) criterion = nn.CrossEntropyLoss() optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE) # 学习率调度器 scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=3) # 训练和测试循环 def train(model, train_loader, val_loader, criterion, optimizer, scheduler, n_epochs): model.train() best_val_accuracy = 0 for epoch in range(n_epochs): total_loss = 0 model.train() for phrases, sentiments, lengths in train_loader: optimizer.zero_grad() output = model(phrases, lengths) loss = criterion(output, sentiments) loss.backward() optimizer.step() total_loss += loss.item() print(f'Epoch: {epoch + 1}, Loss: {total_loss / len(train_loader)}') val_accuracy = evaluate(model, val_loader) scheduler.step(total_loss / len(train_loader)) if val_accuracy > best_val_accuracy: best_val_accuracy = val_accuracy torch.save(model.state_dict(), 'best_model.pt') print(f'Epoch: {epoch + 1}, Val Accuracy: {val_accuracy}') def evaluate(model, val_loader): model.eval() correct, total = 0, 0 with torch.no_grad(): for phrases, sentiments, lengths in val_loader: output = model(phrases, lengths) preds = torch.argmax(output, dim=1) correct += (preds == sentiments).sum().item() total += sentiments.size(0) return correct / total def generate_test_results(model, test_loader): model.eval() results = [] with torch.no_grad(): for phrases in test_loader: lengths = torch.tensor([len(x) for x in phrases]) output = model(phrases, lengths) preds = torch.argmax(output, dim=1) results.extend(preds.cpu().numpy()) return results train(model, train_loader, val_loader, criterion, optimizer, scheduler, N_EPOCHS) # 加载最优模型 model.load_state_dict(torch.load('best_model.pt')) preds = generate_test_results(model, test_loader) # 确保 test_ids 和 preds 长度一致 assert len(test_ids) == len(preds), f"Lengths do not match: {len(test_ids)} vs {len(preds)}" # 保存结果 output_df = pd.DataFrame({'PhraseId': test_ids, 'Sentiment': preds}) output_df.to_csv('sentiment_predictions2.csv', index=False) 