
阅读量:2
在不久前 OpenAI Sora 以其优秀且惊人的视频生成效果迅速走红,更是在一众文生视频模型中脱颖而出,成为了文生视频领域的领头羊。
同时它也推动了行业内文生视频技术的发展。今天小编为大家分享一款新开源的文生视频项目MuseV,据说可以生成不限时长的AI视频。

项目背景
MuseV 项目在2023年7月就已经实现了,但是受到近期 Sora 进展的启发,才决定开源出来。据该团队介绍 ,MuseV 站在开源的肩膀上成长,也希望能够借此反馈社区。
项目介绍
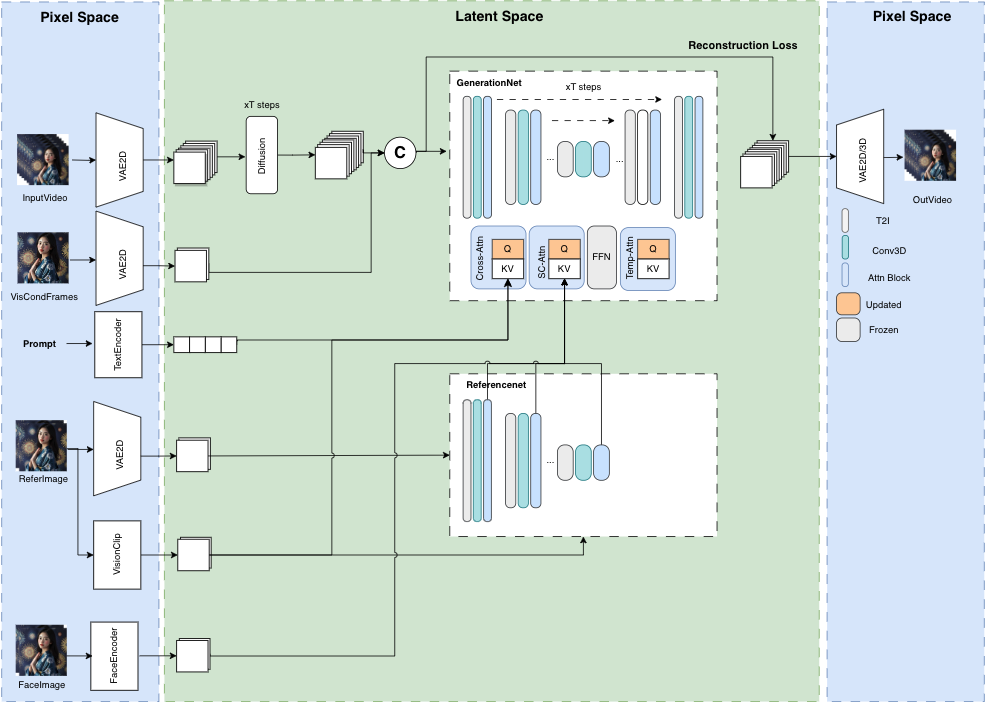
MuseV 是一个基于扩散模型的虚拟人视频生成框架。它采用了新颖的视觉条件并行去噪方案,支持无限长度视频的生成。
提供了预训练的虚拟人视频生成模型,具备 Image2Video、Text2Image2Video 和 Video2Video 等强大功能。而且,MuseV 兼容 Stable Diffusion 生态系统,包括基础模型、LoRA 和 ControlNet 等。
特色功能
无限长度视频生成:打破传统视频长度限制,让你的创意无限延伸。多种功能模式:Image2Video、Text2Image2Video、Video2Video,满足不同创作需求。支持 Stable Diffusion 生态:与现有技术兼容,提供更多创作可能性。多参考图像技术:通过 IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID 等技术,提升视频质量。
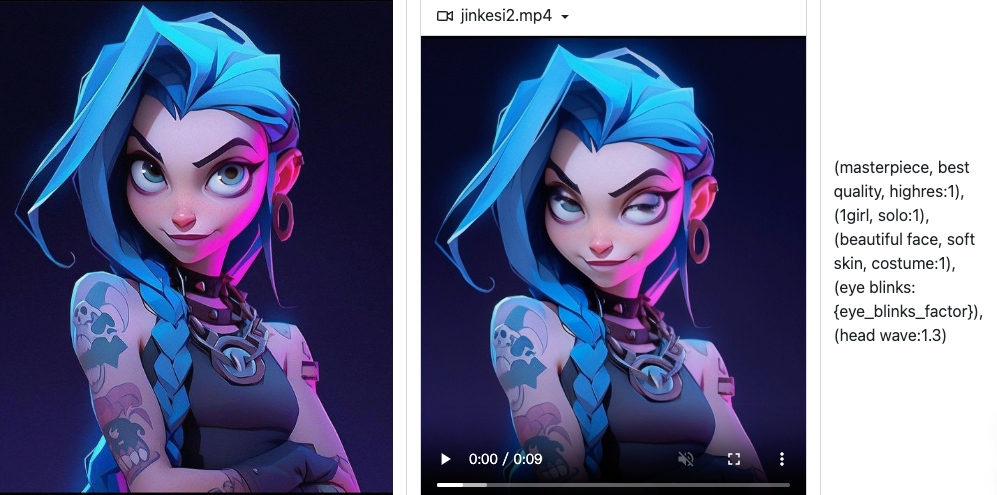
使用 MuseV 也非常简单。只需选择你喜欢的功能模式,输入相应的素材(如图片、文本或视频),它将为你生成高保真的虚拟人视频。同时,你还可以根据需要调整各种参数,实现个性化的创作。
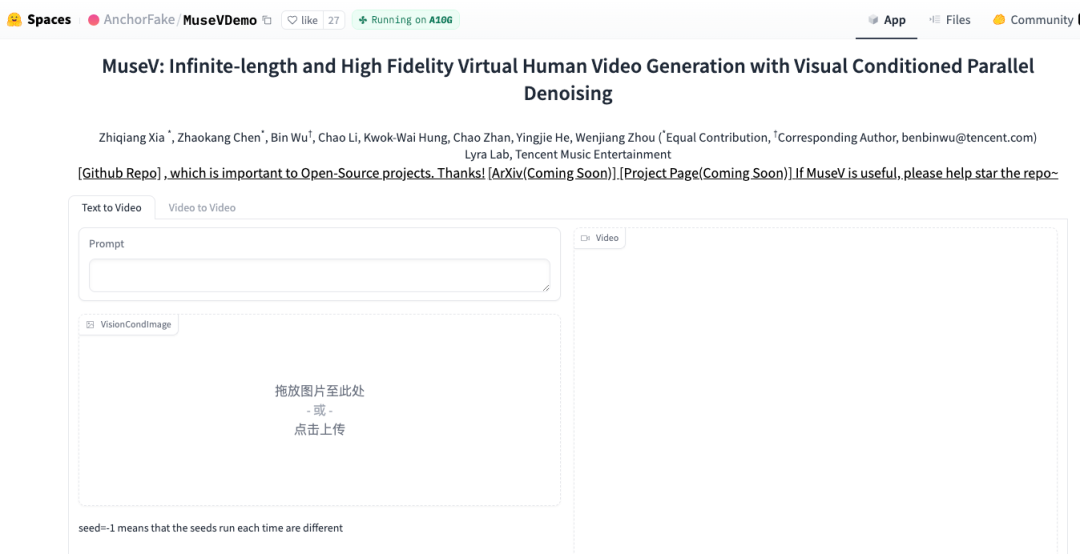
为此官方也在HuggingFace上创建了体验项目,可供无条件搭建的人群或初学者使用。
Demo:https://huggingface.co/spaces/AnchorFake/MuseVDemo
待优化项
缺乏泛化能力。对视觉条件帧敏感,有些视觉条件图像表现良好,有些表现不佳。
有限的视频生成类型和有限的动作范围,部分原因是训练数据类型有限。MuseV 在较低分辨率下具有更大的动作范围,但视频质量较低。MuseV 在高分辨率下画质很好、但动作范围较小。在更大、更高分辨率、更高质量的文本视频数据集上进行训练可能会使 MuseV 更好。
有限类型的长视频生成。视觉条件并行去噪可以解决视频生成的累积误差,但当前的方法只适用于相对固定的摄像机场景。
总结
MuseV 以其无限长度视频生成以及对 Stable Diffusion 生态的支持以及多参考图像技术,成为视频生成领域的新兴力量。
同时,MuseV 团队还计划做另一款项目,名为MuseTalk,一个实时高质量的唇同步模型,到时候可与 MuseV 一起成为完整的虚拟人生成解决方案。
GitHub:https://github.com/TMElyralab/MuseV
