
阅读量:4
Redis 5 种基本数据类型
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:

String(字符串)
String 是 Redis 中最简单同时也是最常用的一个数据类型。
String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。

虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(Simple Dynamic String,SDS)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
适用场景
字符串(String)类型在Redis中是最常用的数据类型之一,适用于以下场景:
缓存:字符串类型可以用于缓存数据,例如缓存数据库查询结果、计算结果等。由于Redis的高性能和快速读写能力,使用字符串类型作为缓存可以大大提高系统的响应速度。
计数器:字符串类型可以用于实现计数器功能,例如统计网站的访问次数、用户的点赞数等。通过使用字符串类型的自增命令,可以方便地对计数器进行增加或减少操作。
分布式锁:字符串类型可以用于实现分布式锁,保证在分布式环境下的数据一致性和并发控制。通过设置一个唯一的字符串作为锁的值,并利用Redis的原子性操作,可以实现简单而高效的分布式锁机制。
会话管理:字符串类型可以用于存储用户的会话信息,例如用户登录状态、购物车内容等。通过将会话信息存储在字符串类型中,可以方便地进行读写操作,并且可以设置过期时间来自动清理过期的会话数据。
消息队列:字符串类型可以用于实现简单的消息队列,例如将消息内容作为字符串存储在Redis中,然后使用列表类型的命令进行消息的发布和订阅。
分布式缓存:字符串类型可以用于实现分布式缓存,例如将经过序列化的对象存储在字符串类型中,然后通过缓存命中来提高系统的性能和扩展性。
List(列表)
Redis 中的 List 其实就是链表数据结构的实现。我在 线性数据结构 :数组、链表、栈、队列[3] 这篇文章中详细介绍了链表这种数据结构,我这里就不多做介绍了。
许多高级编程语言都内置了链表的实现比如 Java 中的 LinkedList,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。

适用场景
列表(List)类型在Redis中是一种非常常用的数据类型,适用于以下场景:
消息队列:列表类型可以用于实现简单的消息队列。生产者可以使用
LPUSH命令将消息添加到列表的头部,消费者可以使用RPOP命令从列表的尾部获取消息。这种方式可以实现先进先出(FIFO)的消息处理。实时排行榜:列表类型可以用于实现实时排行榜。例如,可以使用
LPUSH命令将用户的得分添加到列表中,然后使用LPOP命令获取排行榜的前几名。任务队列:列表类型可以用于实现任务队列。生产者可以使用
LPUSH命令将任务添加到列表的尾部,消费者可以使用RPOP命令从列表的头部获取任务。这种方式可以实现任务的分发和处理。消息发布与订阅:列表类型可以用于实现简单的消息发布与订阅。生产者可以使用
LPUSH命令将消息添加到列表的头部,订阅者可以使用BLPOP命令阻塞地从列表中获取消息。历史记录:列表类型可以用于存储历史记录。例如,可以使用
LPUSH命令将用户的浏览记录添加到列表中,然后使用LRANGE命令获取最近的浏览记录。
Hash(哈希)
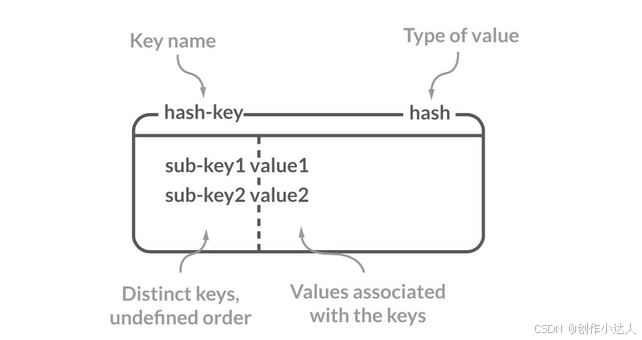
Redis 中的 Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。
Hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 Hash 做了更多优化。
适用场景
Redis的哈希表(Hash)是一种存储键值对的数据结构,其中的键是唯一的,而值则可以是字符串、整数、浮点数等。哈希表适用于许多场景,特别是需要存储和查询多个字段的情况。以下是一些适用场景:
1. 存储对象信息: 如果你需要存储一个对象的多个字段信息,例如用户信息(用户名、年龄、邮箱等),可以使用哈希表来存储每个用户的字段信息。
2. 缓存数据: 哈希表适用于缓存大量的键值对数据,例如缓存数据库查询结果,以减少数据库的访问频率。
3. 存储配置信息: 将配置信息存储在哈希表中,可以方便地获取和修改配置项,而无需在内存中存储多个单独的键。
4. 计数器: 可以使用哈希表来实现计数器功能,每个字段存储一个计数,比如网站的点赞数、阅读数等。
5. 存储多种属性: 如果你需要为一组对象存储多种属性,例如商品的名称、价格、库存等,可以使用哈希表来存储每个商品的多个属性。
6. 联合索引: 在关系型数据库中,联合索引常用于加速多字段的查询。在Redis中,可以使用哈希表来存储多个字段,并通过一个字段作为主键,实现类似的联合索引效果。
7. 实时统计: 哈希表可以用于实时统计信息,例如统计用户每天的登录次数、订单数等。
8. 用户会话: 可以使用哈希表来存储用户会话信息,每个字段存储一个会话属性,如用户ID、登录时间、过期时间等。
9. 图数据结构: 如果需要实现图数据结构,例如社交网络关系图,可以使用哈希表来表示节点和边。
10. 多字段查询: 哈希表适用于存储多个字段,可以更快速地查询和更新多个字段的值。
总之,哈希表适用于需要存储多个字段信息的情况,可以在一次查询中获取和更新多个字段,从而提高了数据的访问效率。它在多种应用场景中都能发挥作用,特别是需要存储和操作多个属性的数据。
Set(集合)
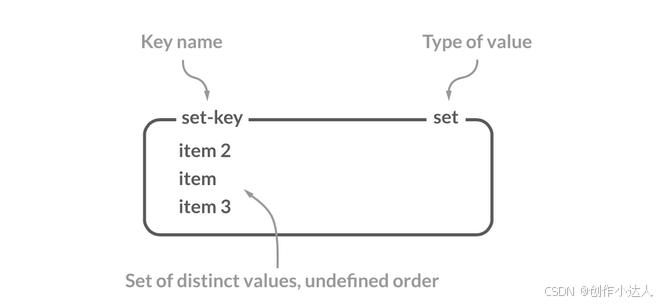
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
适用场景
Redis的Set数据类型是一个无序的字符串集合,它可以存储多个不重复的元素。Set在Redis中有许多实际的使用场景,以下是一些常见的使用场景:
唯一性数据存储:
最基本的使用场景就是用来存储不重复的数据。你可以使用Set来存储用户ID、IP地址、邮箱地址等,确保数据的唯一性。
标签和标记系统:
Set可以用于创建标签或标记系统。例如,你可以为文章、商品或其他实体创建一个包含相关标签的Set,以便后续快速检索。
关注和粉丝系统:
在社交媒体或用户关系管理中,Set可以用来实现关注和粉丝系统。每个用户可以有一个Set,其中包含他们关注的其他用户或粉丝。
在线用户:
Set可以用于跟踪在线用户。将用户ID添加到一个Set中,表示用户当前在线。通过检查Set中的成员,可以快速查找在线用户。
投票系统:
Set可以用于实现投票系统。每个投票项目可以表示为一个Set,用户投票时将其ID添加到相应的Set中,确保每个用户只能投一次。
集合运算:
Redis提供了多种Set运算,如交集、并集和差集。这些运算可以用于计算多个集合之间的共同元素、合并元素等。
排行榜和排名:
Set可以用于创建排行榜系统。例如,每个元素代表一个玩家,分数作为元素的权重。可以通过有序集合操作获取排名和排行。
地理位置标记:
Set可以用于存储地理位置数据,例如存储用户的经纬度坐标,然后利用Set运算来查找附近的位置。
过滤重复事件:
如果你需要记录一系列事件,并且要确保事件不重复记录,可以使用Set来存储已经发生的事件,防止重复记录。
总的来说,Redis的Set数据类型非常适合需要存储不重复数据、进行集合运算以及需要高效查找元素的场景。无论是在社交网络、实时分析、排行榜、地理位置服务等领域,Set都有着广泛的应用。
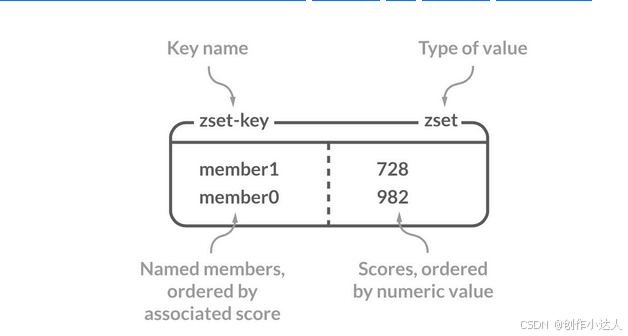
Sorted Set(有序集合)
Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
适用场景
有序集合(Sorted Set)是Redis中的一种特殊数据类型,它在有序性和唯一性的基础上,为存储一组成员(元素)分配了一个分数(score)。这种数据结构使得有序集合在许多应用场景中非常有用。以下是一些适用场景:
1. 排行榜和计分系统: 有序集合非常适合实现排行榜和计分系统。成员的分数可以表示玩家的得分、评分、积分等。你可以通过分数对成员进行排序,快速地获取前几名的排名。
2. 时间序列数据: 如果你需要存储带有时间戳的数据,有序集合可以根据时间戳(作为分数)进行排序,然后按时间范围快速查询数据。
3. 最新消息: 有序集合可以用来存储最新的消息,每个消息的分数可以是消息的时间戳,这样可以方便地获取最新的消息。
4. 带权重的标签/标签云: 在社交网络或标签系统中,你可以使用有序集合来存储标签,成员是标签,分数可以表示标签的热度、权重等。这可以用来实现标签云、热门标签等功能。
5. 范围查询: 有序集合允许根据分数范围进行查询,从而可以快速地获取在某个分数范围内的成员。
6. 唯一性: 有序集合保持了成员的唯一性,这意味着你可以方便地存储和查询不重复的元素。
7. 高级集合运算: Redis提供了对有序集合的集合运算(交集、并集、差集)操作,这可以用来实现多个数据集的交叉分析、数据筛选等。
8. 范围分页: 使用ZRANGE等命令,可以对有序集合进行分页查询,获取指定范围内的成员。
总之,有序集合适用于需要保持元素有序性、需要快速进行范围查询、具有权重或分数的情况。它在多个场景中都提供了高效的数据存储和操作,使得Redis成为了解决这些问题的有力工具。
