
阅读量:0
Sigma-delta ADC数字抽取滤波器设计报告
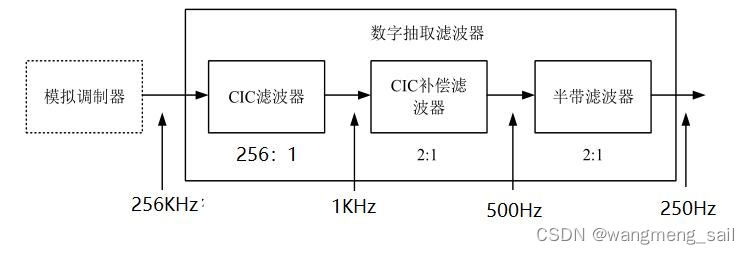
模数转换器根据采样率的不同发展为奈奎斯特(Nyquist)型和过采样(Oversampling)型两大类。奈奎斯特型ADC 采用2-3倍信号带宽的采样时钟进行采样。过采样型ADC采用过采样技术和噪声整形技术,以远高于2倍信号带宽的采样时钟进行采样,将信号中的噪声搬移到高频以此降低信号带宽内的量化噪声,提高信噪比。它由ΣΔ 调制器(Sigma-Delta Modulator,SDM)和数字抽取滤波器构成,ΣΔ 调制器通过过采样技术将信号带内的噪声平均分配到整个采样频域,并通过噪声整形技术将大量信号带内噪声推挤到高频处。数字抽取滤波器CIC将滤除模拟调制器输出信号带宽外的高频噪声,同时降低采样频率使其回到Nyquist 频率,输出高精度数字信号。在ΣΔ ADC 中,调制器对输入信号过采样,输出采样频率远高于Nyquist 频率的调制信号,过高的采样频率会增加后续电路实现难度,所以需要降低采样率。ADC数字抽取滤波器结构如下,由CIC滤波器、补偿滤波器、半带滤波器三部分级联构成 。
本文滤波器的总体设计参数如下:

设计难点:通带截止频率为2Hz,阻带起始频率为2.4hz,过渡带宽仅0.4Hz(下降曲线非常陡峭,需要耗费较多的硬件,目前的matlab仿真表明过渡带宽为100Hz时,滤波实际效果不佳,产生噪音频谱,仿真程序参考附录)。
1 梳妆级联(CIC)滤波器
Σ-Δ调制器输出的信号经过过采样和噪声整形,信号带宽内具有较高的信噪比。但此时输出信号频率较高,不利于后续电路的设计,需要滤除其高频噪声提取出有用信号,因此需要CIC级联数字滤波器
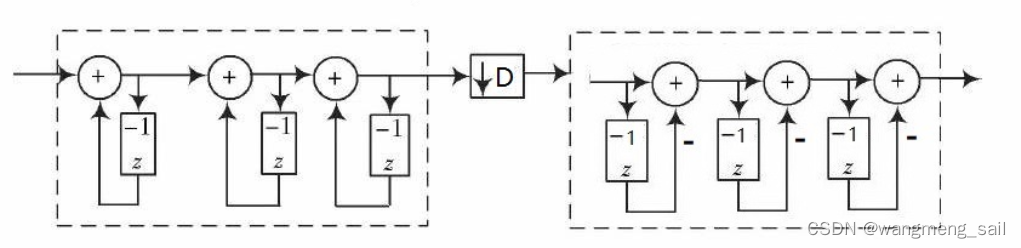
1.1 滤波器电路结构
电路结构如下, 积分电路和微分电路实现占空比计数 。中间电路实现降采样。
1.2 CIC Verilog程序
首先需要确认滤波器中的中间变量位宽,根据
Bout=N*log2(M)+Bin
(Bout为中间变量位宽,N为滤波器阶数,M为滤波器抽取率,Bin为滤波器输入位宽)
本文以3阶,抽取率为256,输入为1bit为例子,因此实现需要的滤波器变量位宽为25,由此可以得到verilog代码如下图所示:
// sinc3 filter
module sinc3
(
input DataIn,
input rst,
input clk,
output reg [24:0] DataOut
);
parameter Dec = 9'd256;
reg [24:0] sigma1;
reg [24:0] sigma2;
reg [24:0] sigma3;
reg [24:0] delta1;
reg [24:0] delta2;
reg [24:0] sigma3_Dec;
wire [24:0] sigma1_temp;
wire [24:0] sigma2_temp;
wire [24:0] sigma3_temp;
wire [24:0] delta1_temp;
wire [24:0] delta2_temp;
wire [24:0] delta3_temp;
reg [8:0] count;
assign sigma1_temp=sigma1+DataIn;
assign sigma2_temp=sigma2+sigma1_temp;
assign sigma3_temp=sigma3+sigma2_temp;
assign delta1_temp=sigma3_temp-sigma3_Dec;
assign delta2_temp=delta1_temp-delta1;
assign delta3_temp=delta2_temp-delta2;
always@(posedge clk or negedge rst)
begin
if (rst==1'b0)
begin
sigma1<=0;
sigma2<=0;
sigma3<=0;
delta1<=0;
delta2<=0;
sigma3_Dec<=0;
count<=0;
DataOut<=0;
end
else
begin
if (count==Dec-1)
begin
count<=0;
sigma3_Dec<=sigma3_temp;
delta1 <=delta1_temp;
delta2 <=delta2_temp;
DataOut <=delta3_temp;
end
else
begin
count<=count+1;
end
sigma1<=sigma1_temp;
sigma2<=sigma2_temp;
sigma3<=sigma3_temp;
end
end
endmodule
1.3 CIC滤波器测试代码及仿真结果
该代码主要产生占空比为1.0,0.8,0.75,0.5,0.2,0 的1bit码流来模拟ADC的单bit码流,如果得到的25bit并行输出DataOut与占空比成正比,则解调成功。
module testbench();
reg DataIn; reg rst; reg clk;
wire[24:0] DataOut;
sinc3 ex1(DataIn, rst, clk,DataOut);
initial begin
rst=0;
clk=0;
DataIn=1'b1;
#100 rst=1;
repeat(12500) begin//test time is 100ms;duty=100%
#4 DataIn=1'b1;
#4 DataIn=1'b1;
end
repeat(12500) begin//test time is 250ms;duty=80%
#4 DataIn=1'b1;
#4 DataIn=1'b1;
#4 DataIn=1'b1;
#4 DataIn=1'b1;
#4 DataIn=1'b0;
end
repeat(12500) begin//test time is 200m s;duty=75%
#4 DataIn=1'b1;
#4 DataIn=1'b1;
#4 DataIn=1'b1;
#4 DataIn=1'b0;
end
repeat(12500) begin//test time is 100ms;duty=50%
#4 DataIn=1'b0;
#4 DataIn=1'b1;
end
repeat(12500) begin//test time is 250m s;duty=20%
#4 DataIn=1'b0;
#4 DataIn=1'b0;
#4 DataIn=1'b0;
#4 DataIn=1'b1;
#4 DataIn=1'b0;
end
end
always #2 clk=~clk;
Endmodule
1.4 Verilog仿真结果
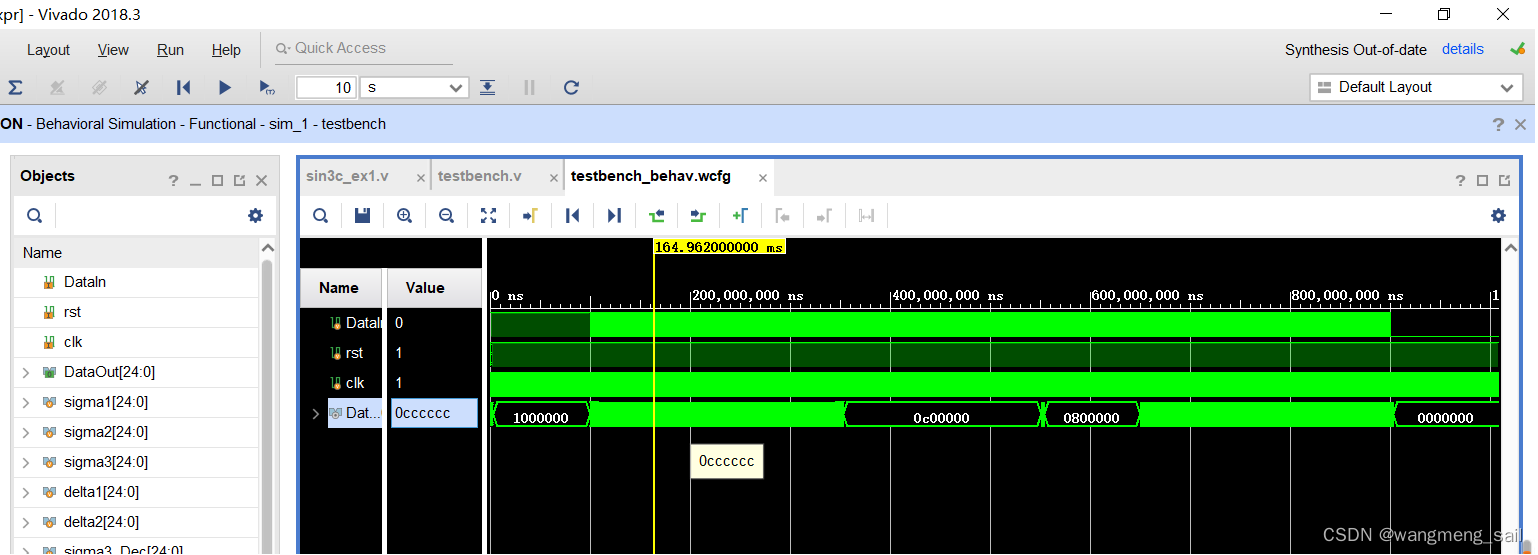
通过任意占空比测试数据(测试代码见1.3节)得到仿真波形如上图,表明得到的25bit并行输出DataOut与占空比成正比,解调成功。
当输入信号为ADC 1bit正弦波码流时,CIC滤波同样可得到正弦波形(vivado对波形做了线性拟合,真实采样波形见1.5节)如下:
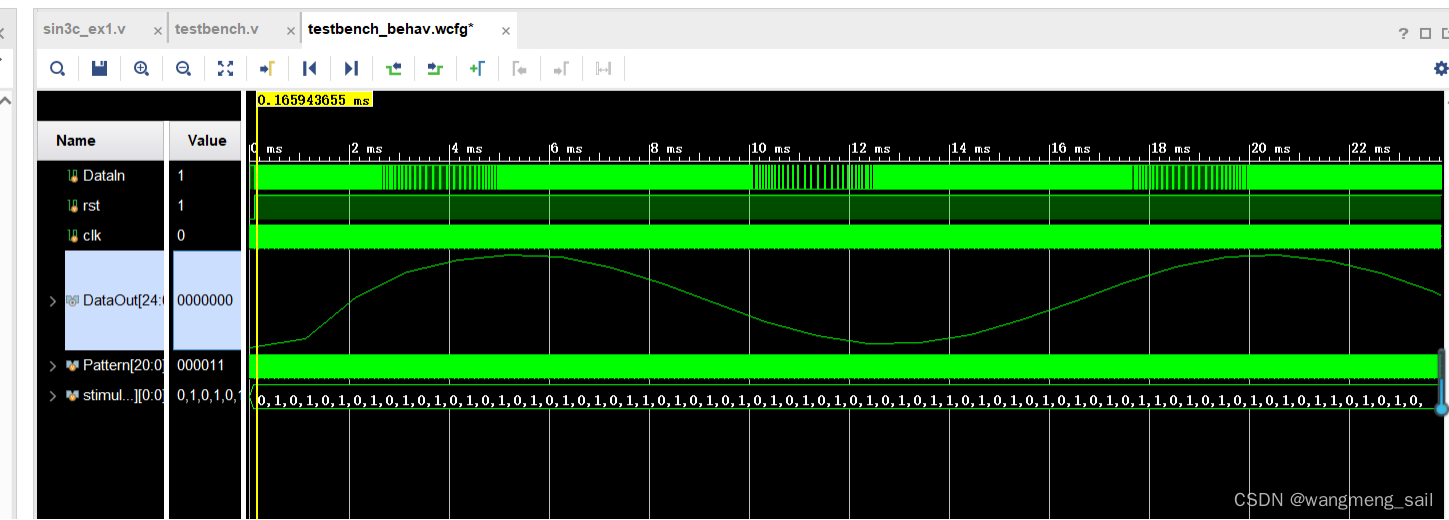
测试代码如下:
`timescale 1us / 1ns
module testbench( );
reg DataIn;
reg rst;
reg clk;
wire[24:0] DataOut;
sinc3 ex1(
DataIn,
rst,
clk,
DataOut
);
reg[0:0] stimulus[65535:0] ;
reg[20:0] Pattern;
initial
begin
//文件 w1.txt为ADC 1bit调制码流
$readmemb("C:/1/CIC/w1.txt",stimulus);
Pattern=0;
rst=0;
clk=0;
DataIn=1'b1;
#100 rst=1;
repeat(65536)
begin
Pattern=Pattern+1;
#4 DataIn=stimulus[Pattern];
end
$finish;
end
always #2 clk=~clk;
endmodule
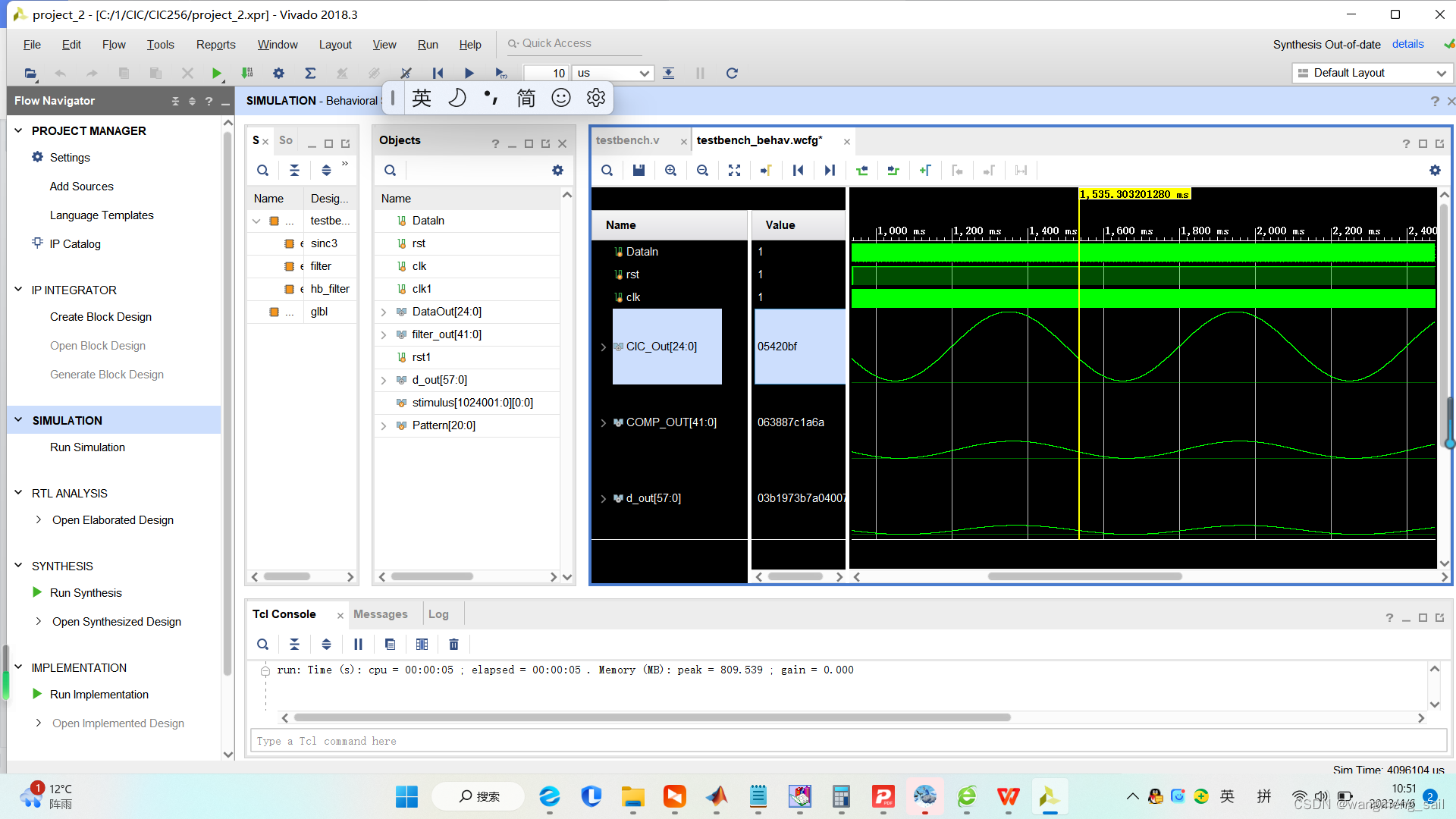
- 5 结论 (256降采样率与512降采样率的对比)
修改1.2节的CIC滤波器verilog程序中的降采样率参数,得到两种降采样率 vivado仿真波形如下图。 由右下图可知256降采样率波形(中间数据位宽DATAout为25)相对左下图512降采样率(中间数据DATAout为28)的正弦波形失真度更小。

2补偿滤波器
多级CIC 级联结构虽然可以达到较大的阻带衰减,但是通带存在衰减。为了使得滤波器整体通带曲线平坦,一般会级联补偿滤波器。
2.1 MATLAB频域分析
在多级CIC 滤波器的阻带衰减增大的同时,其通带幅频特性有很明显的衰减,这种现象称为滚降现象, 这种现象会使电路的SNR下降,所以在CIC 抽取滤波器之后要使用CIC补偿滤波器补偿的目的,CIC补偿滤波器的通带幅频特性必须与CIC抽取滤波器的通带特性互补,由于CIC抽取滤波器的通带逐渐衰减,所以CIC补偿滤波器通带内的幅频响应该是上升的,此外补偿滤波器应该能实现对信号的2 倍抽取,图 3.1为三级级联抽取倍数256 的CIC滤波器级联补偿滤波器的幅频特性曲线。可以看到抽取滤波器级联补偿滤波器的幅频曲线(黄色曲线)在通带200Hz以内非常平坦。而未级联前的CIC幅频特性曲线(蓝色线)滚降明显,单独的补偿器的幅频特性(红色线)在通带内略微向上翘,以补偿CIC的滚动衰减。
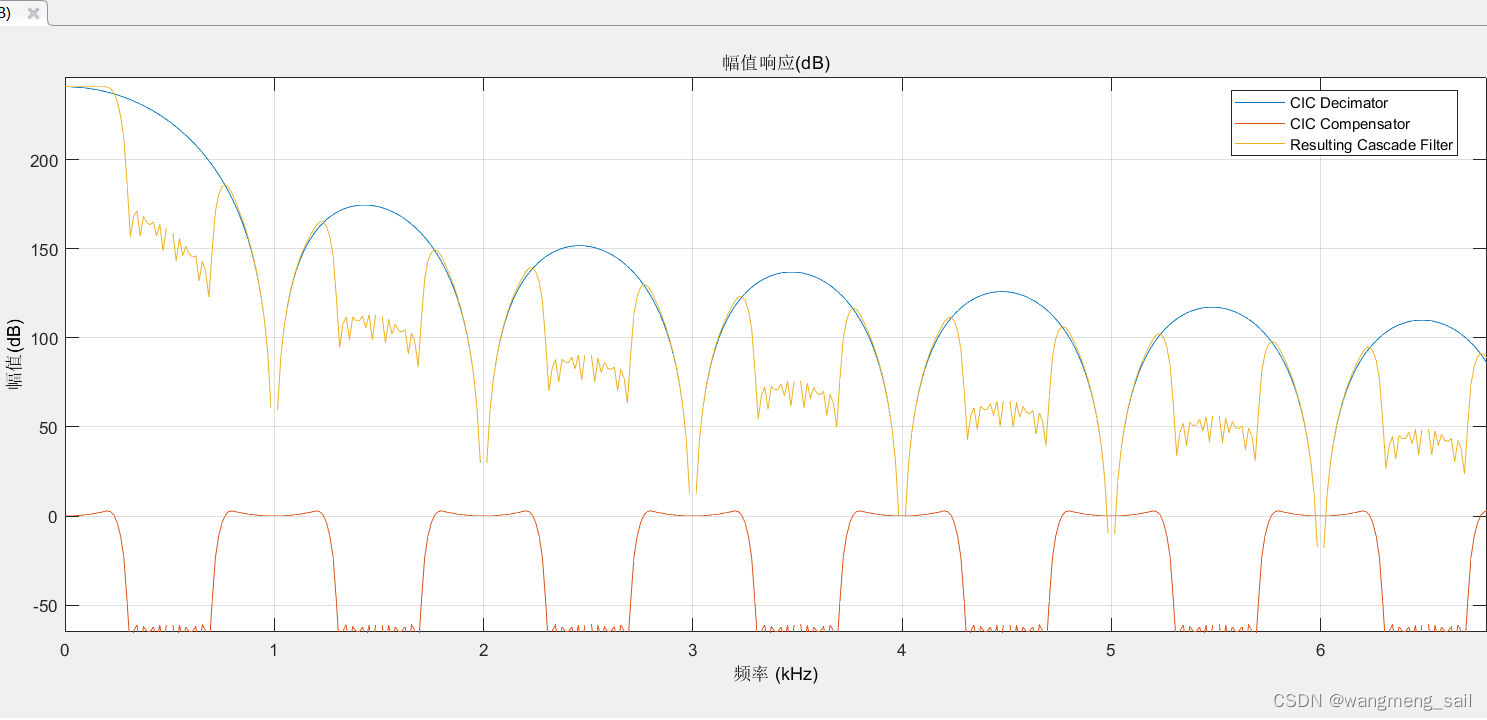
对应的matlab程序如下(D:\filter\cuowu4.m):
Fs = 256000; % sample rate
R = 256; % decimator factor
D = 1; % differential delay
Fp = 200; % pass band
Fstp = 300; % stop band
Ap = 0.1; % attenuation in pass band
Astp = 60; % attenuation in stop band
hcic = design(fdesign.decimator(R,'cic',D, Fp, Astp, Fs),'SystemObject',true);
cic_comp = design(fdesign.ciccomp(hcic.DifferentialDelay, ...
hcic.NumSections,Fp,Fstp,Ap,Astp,Fs/R), 'SystemObject',true);
fvtool(hcic,cic_comp,...
cascade(hcic,cic_comp),'ShowReference','off','Fs',[Fs Fs/R Fs])
legend('CIC Decimator','CIC Compensator','Resulting Cascade Filter');
2.2 MATLAB时域分析
通过对CIC与补偿滤波器施加50Hz和1000Hz的信号,可以看到高频信号被滤掉。
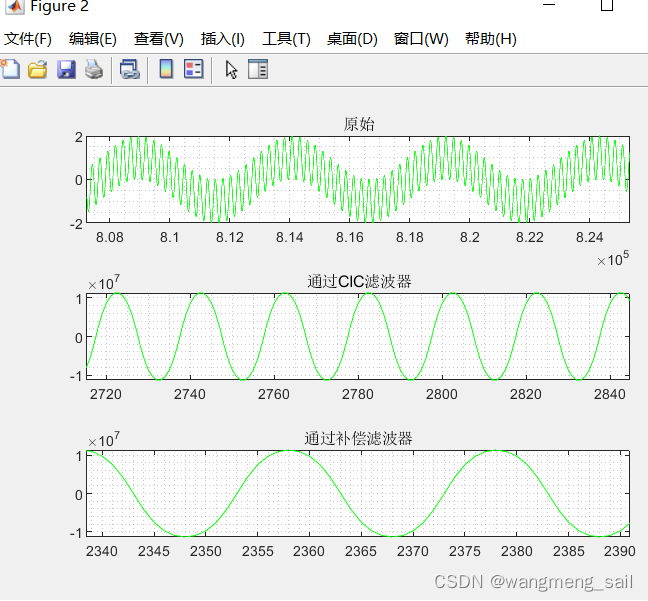
图2.2.1 对正弦波形的滤波
对应的程序代码如下(代码位置 D:\filter\cuowu5.m):
clc;
A0=1;
Al=0.8;
fc=1000;%载波频率1KHZ
f=50;%基带信号50HZ
fs1=256000;%采样率256KHZ
fs2=1000;
t=0:1/fs1:4;
%mes1=Al*cos(2*pi*f*t);
%uam1=(mes1+1).*cos(2*pi*fc*t);
%s=awgn(uam1,1);
s=cos(2*pi*fc*t)+cos(2*pi*f*t);
%CIC滤波器的设计
Fs = 256000; % Input sampling frequency
D = 256; % Decimation factor of CIC
Fs1 = fs1/D; % Input sampling frequency
Fpass = 200; % Frequency band of interest
d1 = fdesign.decimator(D,'CIC',1,Fpass,60,Fs); %design a cic filter
Hcic = design(d1);
%set(Hcic,'arithmetic','double');
Hcic.NumberOfSections=3;
Hd(1) = cascade(dfilt.scalar(1/gain(Hcic)),Hcic);
d2 = fdesign.ciccomp(Hcic.DifferentialDelay, ...
Hcic.NumberOfSections,Fpass,300,0.1,60,Fs/D); % design a cic compensator filter
Hd(2) = design(d2);
fvtool(Hcic,Hd(2),...
cascade(Hcic,Hd(2)),'ShowReference','off','Fs',[Fs Fs/D Fs])
legend('CIC Decimator','CIC Compensator','Resulting Cascade Filter');
y1=filter(Hcic,s);
y3=filter(Hd(2),y1);
subplot(311)
plot(s,'g');hold on;grid minor;
title('原始');
subplot(312)
plot(y1,'g');hold on;grid minor;
title('通过CIC滤波器');
subplot(313);
plot(y3,'g');hold on;grid minor;
title('通过补偿滤波器');
figure('color',[1,1,1])
fft_deal(fs1,t,s)
t2=0:1/fs2:4;
figure('color',[1,1,1])
fft_deal(fs2,t2,double(y1))
figure('color',[1,1,1])
fft_deal(fs2,t2,y3)
将测试向量变为ADC 1bit码流(代码见附录),仿真结果如下
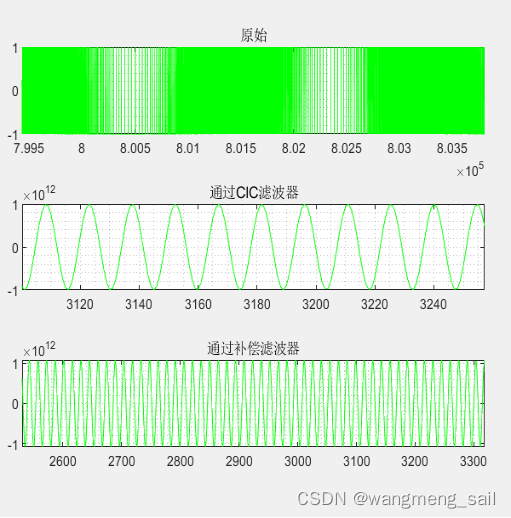
图2.2.1 对ADC 1bit码流的滤波
2.3 滤波器电路参数
滤波器器的电路结构如下:
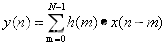
如果需要Verilog硬件电路实现,可用fvtools生成补偿滤波器频率响应及定点系数hm如下:
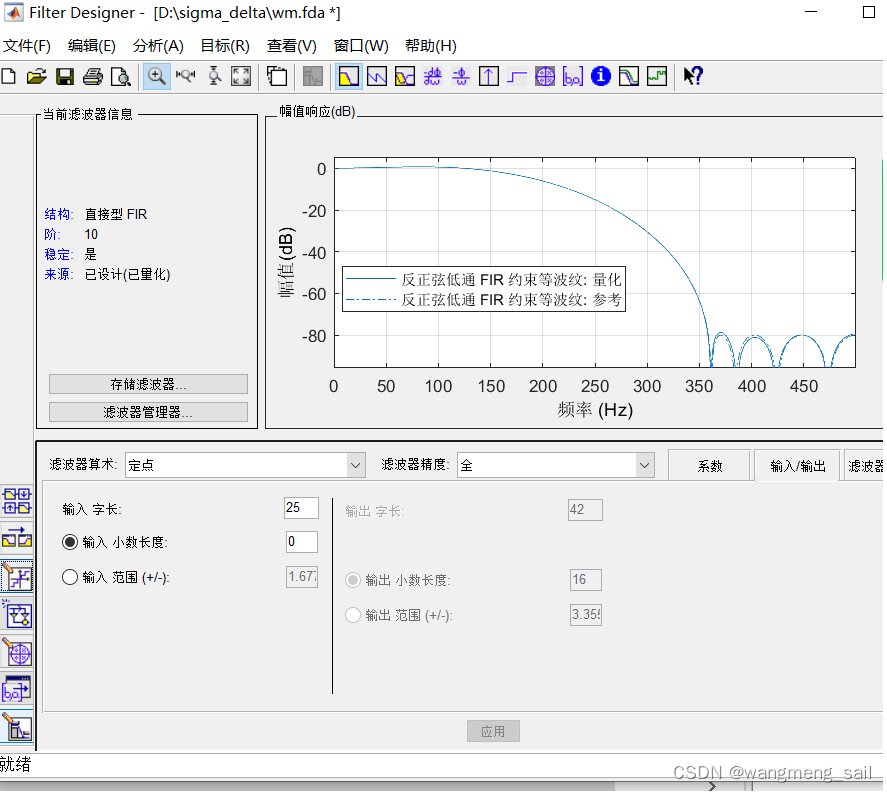
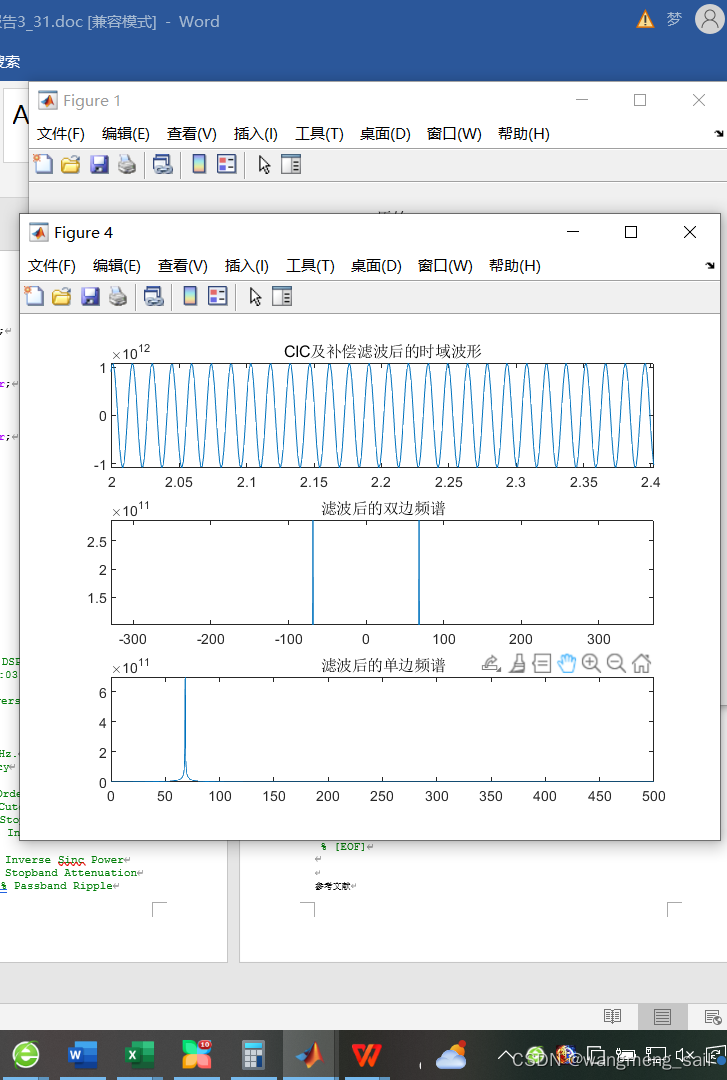
2.4 CIC+补偿滤波器的verilog仿真结果
图中filter_out为两个滤波器级联后的输出结果。
3 半带滤波器
3.0介绍
半带滤波器是一种特殊的FIR滤波器,其阶数只能为偶数,长度为奇数(N阶滤波器,N+1个抽头)。滤波器系数除了中间值为0.5外,其余偶数序号的系数都为0(因此也大大节省了滤波时的乘法和加法运算),半带滤波器是一种特殊的低通FIR数字滤波器。这种滤波器由于通带和阻带相对于二分之一Nyquist频率对称,因而有近一半的滤波器系数精确为零。

3.1 matlab滤波器的设计过程
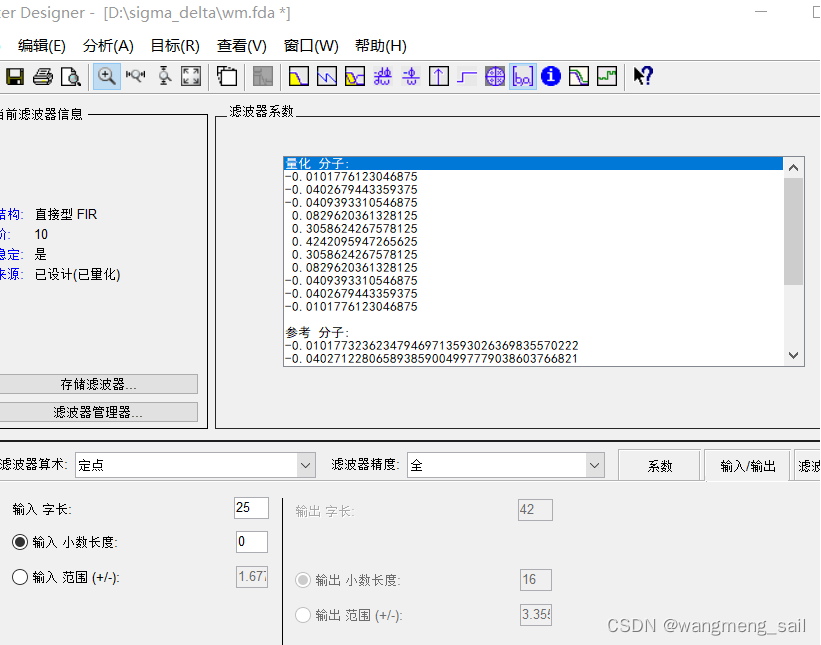
性能参数:
信号频率为25hz和50hz,采样率为120hz,设计半带滤波器滤除其中50hz的频率成分
3.2 matlab仿真参数
程序如下
%信号频率为25hz和50hz,采样率为120hz,设计半带滤波器滤除其中50hz的频率成分
clear all;
clc;
fs=120;
f0=25;
f1=50;
N=256;
n=0:(N-1);
% signal = sin(2*pi*f0/fs*n);
signal = sin(2*pi*f0/fs*n)+sin(2*pi*f1/fs*n);
coff = [0,0.0671297764639564,0,-0.0953987484367994,0,0.314556319097219,0.500000000000000,0.314556319097219,0,-0.0953987484367994,0,0.0671297764639564,0];
signal_f = filter(coff,1,signal);
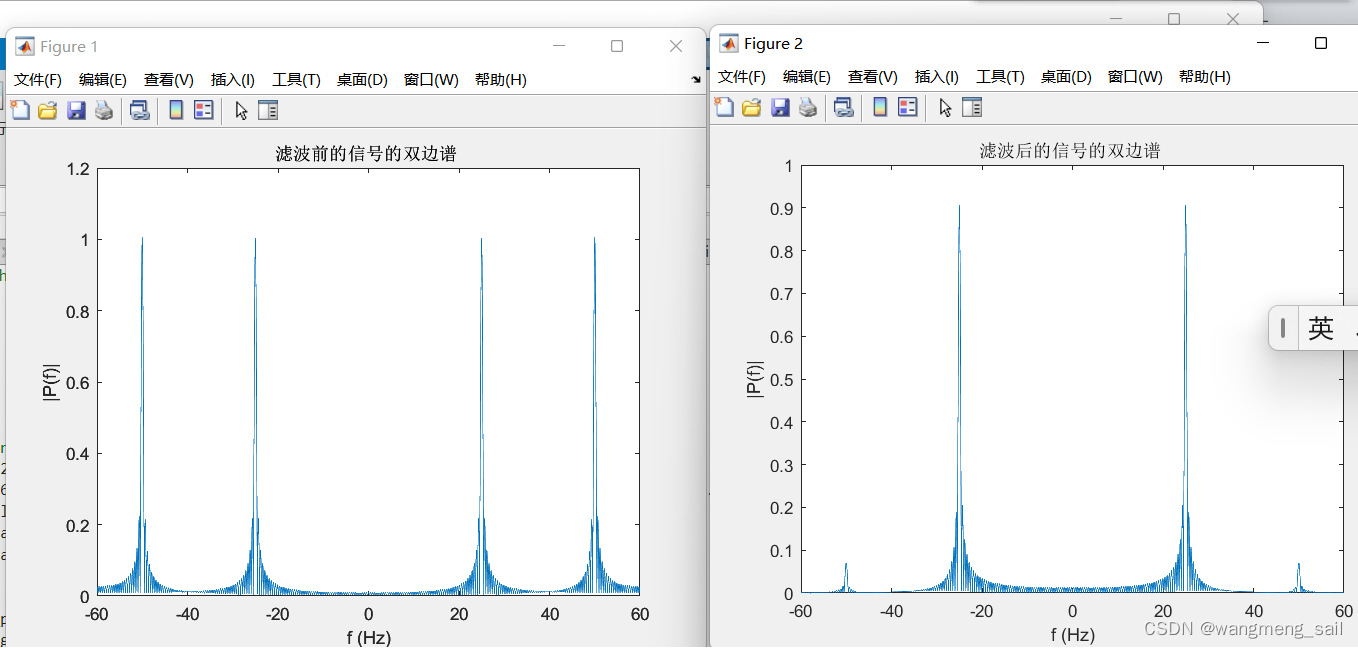
fft_plot(signal,fs,'滤波前的信号');
fft_plot(signal_f,fs,'滤波后的信号');
function fft_plot(y,fs,s_name)
L_i = length(y)*100;
s_i_fft = fft(y,L_i);
s_i_fftshfit = fftshift(s_i_fft);
P = abs(s_i_fftshfit)/length(y)*2; %对于非直流分量或者0来说是除以N乘以2,对于直流分量来说是直接除以N
% fshift = (-L_i/2:L_i/2-1)*(fs/L_i);
fshift = linspace(-fs/2,fs/2,L_i);
figure;
plot(fshift,P);
title([s_name,'的双边谱 ']);
xlabel('f (Hz)');
ylabel('|P(f)|');
end
3.3电路结构

图3.3 半带滤波器结构
3.4 滤波器电路参数
3.4.1 matlab生成滤波器
BQ76920的温度传感器信号频率2HZ,故滤波器的工作频率设置为大于信号频率为120Hz,通带截止频率为2Hz.
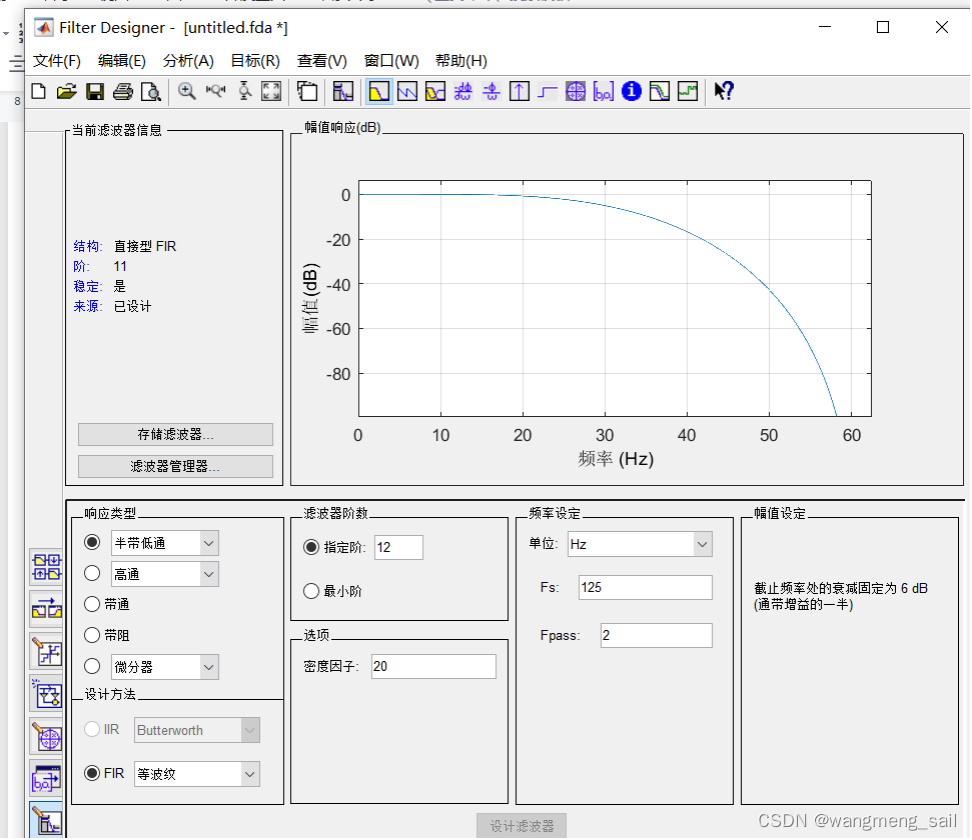
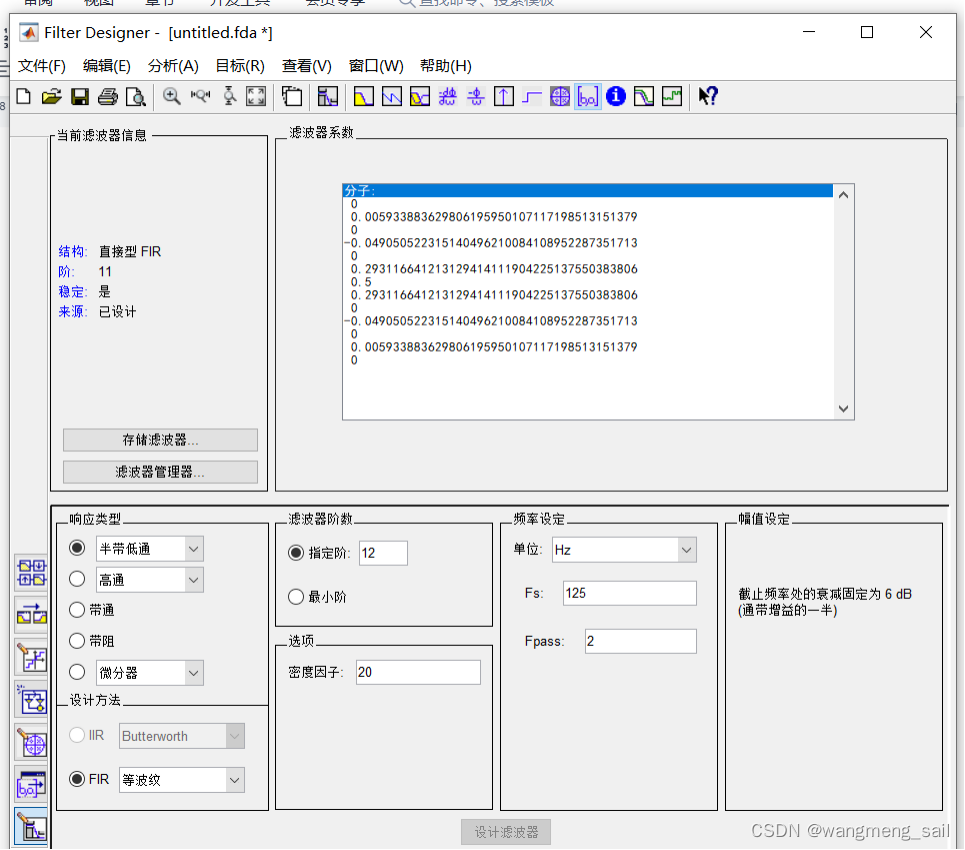
3.4.2 matlab生成的12阶滤波器系数
对应的12阶电路结构(图2.3)的抽头系数为13个(浮点数表示)如下
如果 用verilog实现该电路,采用定点数实现抽头系数如下
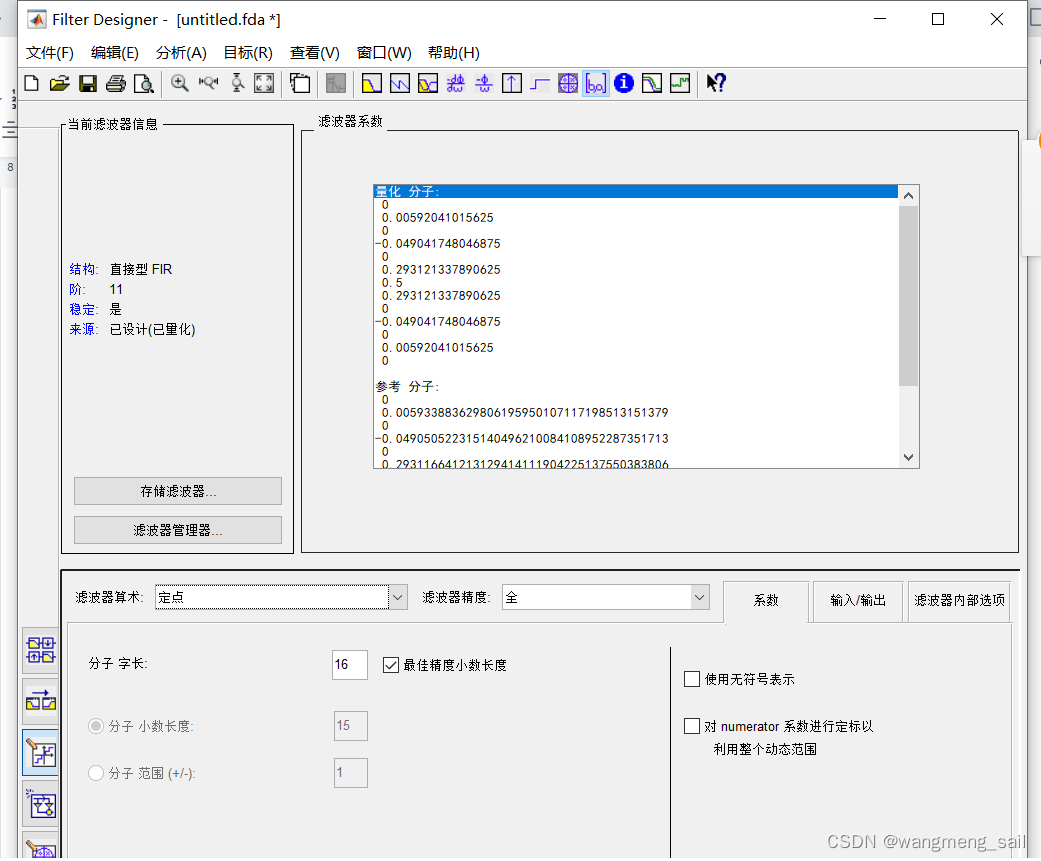
二进制系数左移17位,得到放大的定点数系数如下:
0000,00c2,0000,f9b9,0000,2585,4000,2585,0000,f9b9,0000,00c2,0000
3.4.3三个滤波器的级联仿真
Vivado软件下,输入68HZ的1bit码流信号,半带滤波器结果hf_out就是整个级联滤波器的结果,如下图所示。
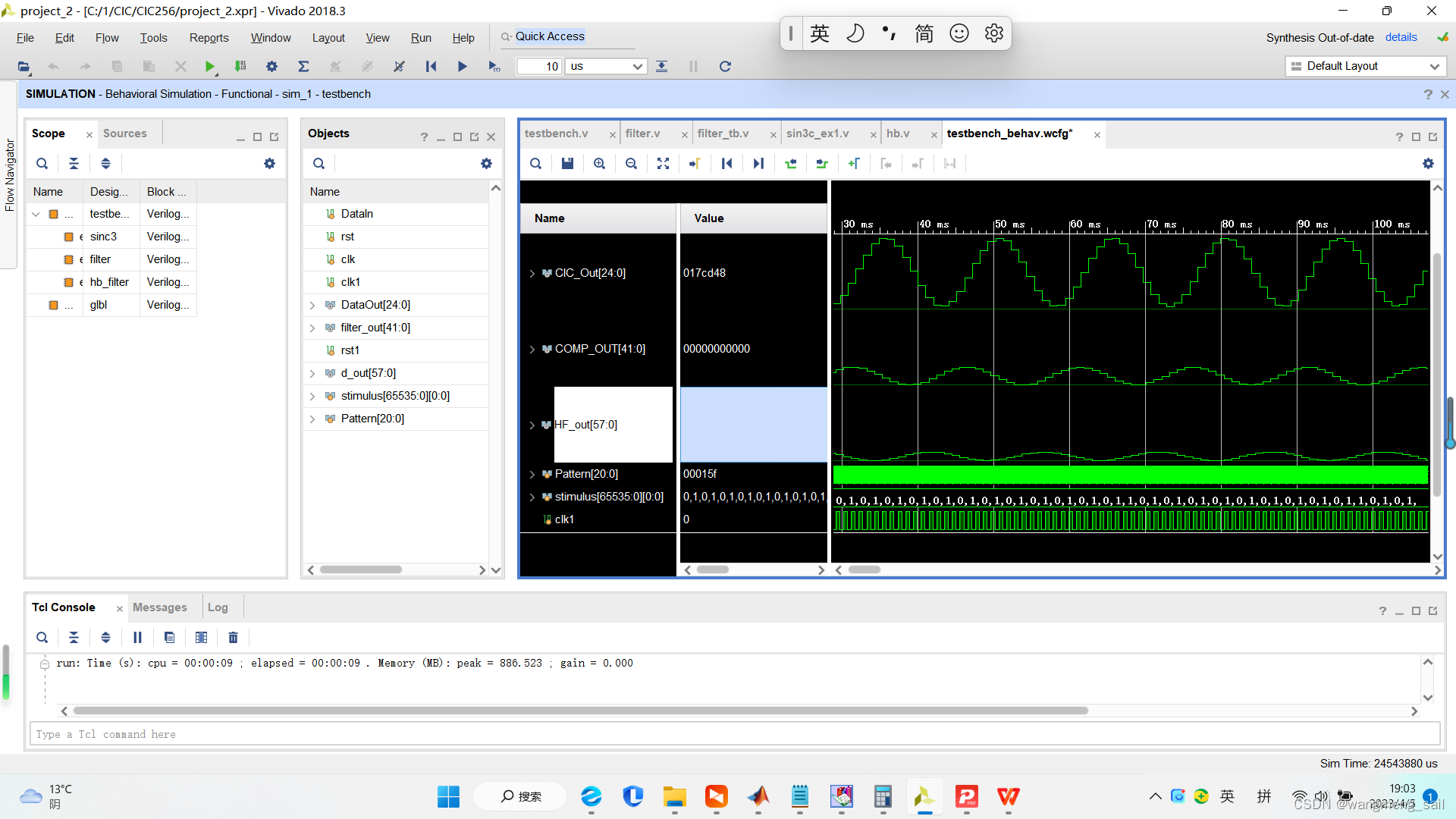
Vivado软件下,输入2HZ的1bit码流信号,半带滤波器结果hf_out就是整个级联滤波器的结果,如下图所示(图略)。
Vivado软件下,输入68HZ的1bit码流信号,半带滤波器结果hf_out就是整个级联滤波器的结果,如下图所示。
4参考文献
【1】Sin3C滤波器的设计。https://blog.csdn.net/chenyangv587/article/details/117000754
【2】半带滤波器的设计,https://blog.csdn.net/weixin_43778388/article/details/123942673
【3】半带滤波器的FPGA设计,https://blog.csdn.net/ccsss22/article/details/125057471?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-6-125057471-blog-121644665.235^v27^pc_relevant_default_base1&spm=1001.2101.3001.4242.6&utm_relevant_index=9
【4】申婷婷。高精度 ΣΔADC 中数字滤波器的研究与设计【D】,东南大学,2021
5源程序附录
5.1 ADC 1bit码流滤波的matlab代码
文件名cuowu6.m,位置D: \filt

t2=0:1/fs2:4;
figure('color',[1,1,1])
fft_deal(fs2,t2,double(y1))
figure('color',[1,1,1])
fft_deal(fs2,t2,y3)
抽取滤波器的matlab代码如下
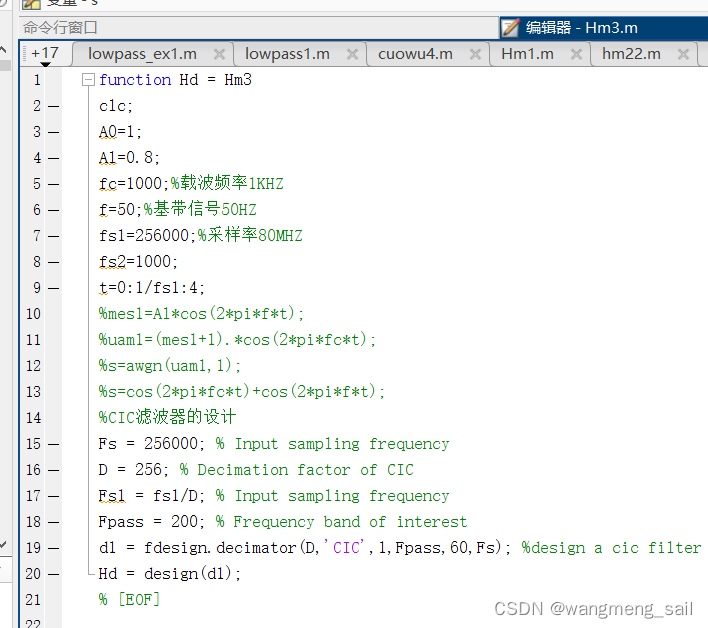
补偿滤波器matlab
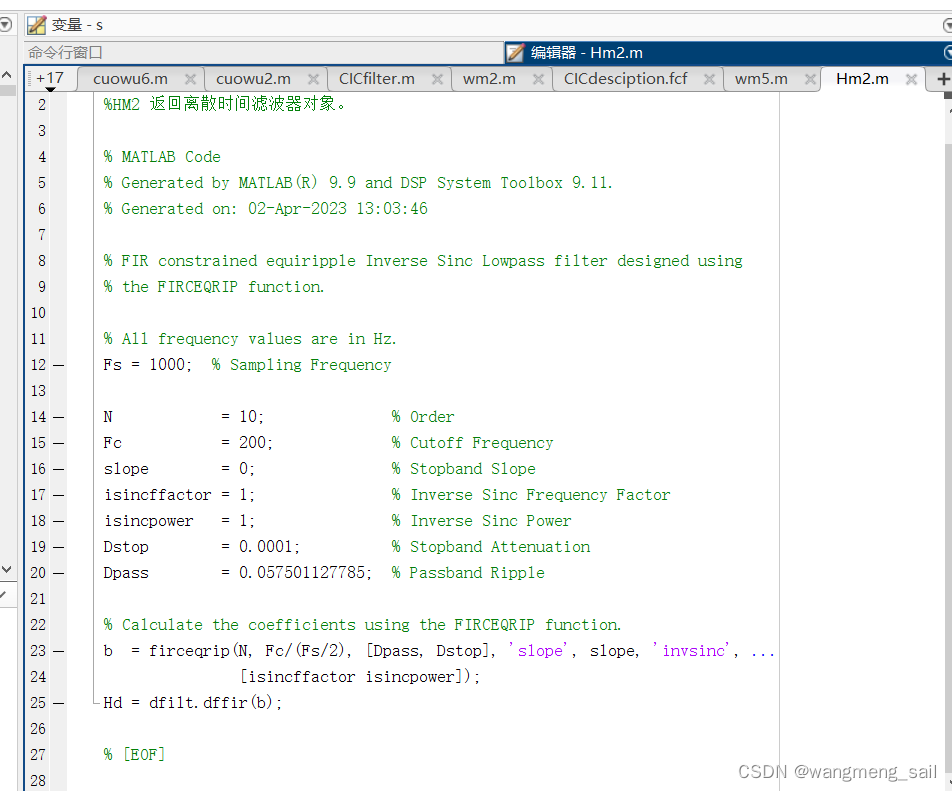
ADC码流经抽取与补偿滤波器后的结果如下
5.2 11阶补偿滤波器的Verilog程序
`timescale 1 ns / 1 ns
module filter
(
clk,
clk_enable,
reset,
filter_in,
filter_out
);
input clk;
input clk_enable;
input reset;
input signed [24:0] filter_in; //sfix25
output signed [41:0] filter_out; //sfix42_En16
//Module Architecture: filter
// Local Functions
// Type Definitions
// Constants
parameter signed [15:0] coeff1 = 16'b1111110101100101; //sfix16_En16
parameter signed [15:0] coeff2 = 16'b1111010110110001; //sfix16_En16
parameter signed [15:0] coeff3 = 16'b1111010110000101; //sfix16_En16
parameter signed [15:0] coeff4 = 16'b0001010100111101; //sfix16_En16
parameter signed [15:0] coeff5 = 16'b0100111001001101; //sfix16_En16
parameter signed [15:0] coeff6 = 16'b0110110010011001; //sfix16_En16
parameter signed [15:0] coeff7 = 16'b0100111001001101; //sfix16_En16
parameter signed [15:0] coeff8 = 16'b0001010100111101; //sfix16_En16
parameter signed [15:0] coeff9 = 16'b1111010110000101; //sfix16_En16
parameter signed [15:0] coeff10 = 16'b1111010110110001; //sfix16_En16
parameter signed [15:0] coeff11 = 16'b1111110101100101; //sfix16_En16
// Signals
reg signed [24:0] delay_pipeline [0:10] ; // sfix25
wire signed [39:0] product11; // sfix40_En16
wire signed [40:0] mul_temp; // sfix41_En16
wire signed [39:0] product10; // sfix40_En16
wire signed [40:0] mul_temp_1; // sfix41_En16
wire signed [39:0] product9; // sfix40_En16
wire signed [40:0] mul_temp_2; // sfix41_En16
wire signed [39:0] product8; // sfix40_En16
wire signed [40:0] mul_temp_3; // sfix41_En16
wire signed [39:0] product7; // sfix40_En16
wire signed [40:0] mul_temp_4; // sfix41_En16
wire signed [39:0] product6; // sfix40_En16
wire signed [40:0] mul_temp_5; // sfix41_En16
wire signed [39:0] product5; // sfix40_En16
wire signed [40:0] mul_temp_6; // sfix41_En16
wire signed [39:0] product4; // sfix40_En16
wire signed [40:0] mul_temp_7; // sfix41_En16
wire signed [39:0] product3; // sfix40_En16
wire signed [40:0] mul_temp_8; // sfix41_En16
wire signed [39:0] product2; // sfix40_En16
wire signed [40:0] mul_temp_9; // sfix41_En16
wire signed [39:0] product1; // sfix40_En16
wire signed [40:0] mul_temp_10; // sfix41_En16
wire signed [41:0] sum_final; // sfix42_En16
wire signed [41:0] sum1_1; // sfix42_En16
wire signed [39:0] add_signext; // sfix40_En16
wire signed [39:0] add_signext_1; // sfix40_En16
wire signed [40:0] add_temp; // sfix41_En16
reg signed [41:0] sumpipe1_1; // sfix42_En16
wire signed [41:0] sum1_2; // sfix42_En16
wire signed [39:0] add_signext_2; // sfix40_En16
wire signed [39:0] add_signext_3; // sfix40_En16
wire signed [40:0] add_temp_1; // sfix41_En16
reg signed [41:0] sumpipe1_2; // sfix42_En16
wire signed [41:0] sum1_3; // sfix42_En16
wire signed [39:0] add_signext_4; // sfix40_En16
wire signed [39:0] add_signext_5; // sfix40_En16
wire signed [40:0] add_temp_2; // sfix41_En16
reg signed [41:0] sumpipe1_3; // sfix42_En16
wire signed [41:0] sum1_4; // sfix42_En16
wire signed [39:0] add_signext_6; // sfix40_En16
wire signed [39:0] add_signext_7; // sfix40_En16
wire signed [40:0] add_temp_3; // sfix41_En16
reg signed [41:0] sumpipe1_4; // sfix42_En16
wire signed [41:0] sum1_5; // sfix42_En16
wire signed [39:0] add_signext_8; // sfix40_En16
wire signed [39:0] add_signext_9; // sfix40_En16
wire signed [40:0] add_temp_4; // sfix41_En16
reg signed [41:0] sumpipe1_5; // sfix42_En16
reg signed [39:0] sumpipe1_6; // sfix40_En16
wire signed [41:0] sum2_1; // sfix42_En16
wire signed [41:0] add_signext_10; // sfix42_En16
wire signed [41:0] add_signext_11; // sfix42_En16
wire signed [42:0] add_temp_5; // sfix43_En16
reg signed [41:0] sumpipe2_1; // sfix42_En16
wire signed [41:0] sum2_2; // sfix42_En16
wire signed [41:0] add_signext_12; // sfix42_En16
wire signed [41:0] add_signext_13; // sfix42_En16
wire signed [42:0] add_temp_6; // sfix43_En16
reg signed [41:0] sumpipe2_2; // sfix42_En16
wire signed [41:0] sum2_3; // sfix42_En16
wire signed [41:0] add_signext_14; // sfix42_En16
wire signed [41:0] add_signext_15; // sfix42_En16
wire signed [42:0] add_temp_7; // sfix43_En16
reg signed [41:0] sumpipe2_3; // sfix42_En16
wire signed [41:0] sum3_1; // sfix42_En16
wire signed [41:0] add_signext_16; // sfix42_En16
wire signed [41:0] add_signext_17; // sfix42_En16
wire signed [42:0] add_temp_8; // sfix43_En16
reg signed [41:0] sumpipe3_1; // sfix42_En16
reg signed [41:0] sumpipe3_2; // sfix42_En16
wire signed [41:0] sum4_1; // sfix42_En16
wire signed [41:0] add_signext_18; // sfix42_En16
wire signed [41:0] add_signext_19; // sfix42_En16
wire signed [42:0] add_temp_9; // sfix43_En16
reg signed [41:0] sumpipe4_1; // sfix42_En16
reg signed [41:0] output_register; // sfix42_En16
// Block Statements
always @( posedge clk or posedge reset)
begin: Delay_Pipeline_process
if (reset == 1'b1) begin
delay_pipeline[0] <= 0;
delay_pipeline[1] <= 0;
delay_pipeline[2] <= 0;
delay_pipeline[3] <= 0;
delay_pipeline[4] <= 0;
delay_pipeline[5] <= 0;
delay_pipeline[6] <= 0;
delay_pipeline[7] <= 0;
delay_pipeline[8] <= 0;
delay_pipeline[9] <= 0;
delay_pipeline[10] <= 0;
end
else begin
if (clk_enable == 1'b1) begin
delay_pipeline[0] <= filter_in;
delay_pipeline[1] <= delay_pipeline[0];
delay_pipeline[2] <= delay_pipeline[1];
delay_pipeline[3] <= delay_pipeline[2];
delay_pipeline[4] <= delay_pipeline[3];
delay_pipeline[5] <= delay_pipeline[4];
delay_pipeline[6] <= delay_pipeline[5];
delay_pipeline[7] <= delay_pipeline[6];
delay_pipeline[8] <= delay_pipeline[7];
delay_pipeline[9] <= delay_pipeline[8];
delay_pipeline[10] <= delay_pipeline[9];
end
end
end // Delay_Pipeline_process
assign mul_temp = delay_pipeline[10] * coeff11;
assign product11 = mul_temp[39:0];
assign mul_temp_1 = delay_pipeline[9] * coeff10;
assign product10 = mul_temp_1[39:0];
assign mul_temp_2 = delay_pipeline[8] * coeff9;
assign product9 = mul_temp_2[39:0];
assign mul_temp_3 = delay_pipeline[7] * coeff8;
assign product8 = mul_temp_3[39:0];
assign mul_temp_4 = delay_pipeline[6] * coeff7;
assign product7 = mul_temp_4[39:0];
assign mul_temp_5 = delay_pipeline[5] * coeff6;
assign product6 = mul_temp_5[39:0];
assign mul_temp_6 = delay_pipeline[4] * coeff5;
assign product5 = mul_temp_6[39:0];
assign mul_temp_7 = delay_pipeline[3] * coeff4;
assign product4 = mul_temp_7[39:0];
assign mul_temp_8 = delay_pipeline[2] * coeff3;
assign product3 = mul_temp_8[39:0];
assign mul_temp_9 = delay_pipeline[1] * coeff2;
assign product2 = mul_temp_9[39:0];
assign mul_temp_10 = delay_pipeline[0] * coeff1;
assign product1 = mul_temp_10[39:0];
assign add_signext = product11;
assign add_signext_1 = product10;
assign add_temp = add_signext + add_signext_1;
assign sum1_1 = $signed({{1{add_temp[40]}}, add_temp});
assign add_signext_2 = product9;
assign add_signext_3 = product8;
assign add_temp_1 = add_signext_2 + add_signext_3;
assign sum1_2 = $signed({{1{add_temp_1[40]}}, add_temp_1});
assign add_signext_4 = product7;
assign add_signext_5 = product6;
assign add_temp_2 = add_signext_4 + add_signext_5;
assign sum1_3 = $signed({{1{add_temp_2[40]}}, add_temp_2});
assign add_signext_6 = product5;
assign add_signext_7 = product4;
assign add_temp_3 = add_signext_6 + add_signext_7;
assign sum1_4 = $signed({{1{add_temp_3[40]}}, add_temp_3});
assign add_signext_8 = product3;
assign add_signext_9 = product2;
assign add_temp_4 = add_signext_8 + add_signext_9;
assign sum1_5 = $signed({{1{add_temp_4[40]}}, add_temp_4});
always @ (posedge clk or posedge reset)
begin: temp_process1
if (reset == 1'b1) begin
sumpipe1_1 <= 0;
sumpipe1_2 <= 0;
sumpipe1_3 <= 0;
sumpipe1_4 <= 0;
sumpipe1_5 <= 0;
sumpipe1_6 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe1_1 <= sum1_1;
sumpipe1_2 <= sum1_2;
sumpipe1_3 <= sum1_3;
sumpipe1_4 <= sum1_4;
sumpipe1_5 <= sum1_5;
sumpipe1_6 <= product1;
end
end
end // temp_process1
assign add_signext_10 = sumpipe1_1;
assign add_signext_11 = sumpipe1_2;
assign add_temp_5 = add_signext_10 + add_signext_11;
assign sum2_1 = add_temp_5[41:0];
assign add_signext_12 = sumpipe1_3;
assign add_signext_13 = sumpipe1_4;
assign add_temp_6 = add_signext_12 + add_signext_13;
assign sum2_2 = add_temp_6[41:0];
assign add_signext_14 = sumpipe1_5;
assign add_signext_15 = $signed({{2{sumpipe1_6[39]}}, sumpipe1_6});
assign add_temp_7 = add_signext_14 + add_signext_15;
assign sum2_3 = add_temp_7[41:0];
always @ (posedge clk or posedge reset)
begin: temp_process2
if (reset == 1'b1) begin
sumpipe2_1 <= 0;
sumpipe2_2 <= 0;
sumpipe2_3 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe2_1 <= sum2_1;
sumpipe2_2 <= sum2_2;
sumpipe2_3 <= sum2_3;
end
end
end // temp_process2
assign add_signext_16 = sumpipe2_1;
assign add_signext_17 = sumpipe2_2;
assign add_temp_8 = add_signext_16 + add_signext_17;
assign sum3_1 = add_temp_8[41:0];
always @ (posedge clk or posedge reset)
begin: temp_process3
if (reset == 1'b1) begin
sumpipe3_1 <= 0;
sumpipe3_2 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe3_1 <= sum3_1;
sumpipe3_2 <= sumpipe2_3;
end
end
end // temp_process3
assign add_signext_18 = sumpipe3_1;
assign add_signext_19 = sumpipe3_2;
assign add_temp_9 = add_signext_18 + add_signext_19;
assign sum4_1 = add_temp_9[41:0];
always @ (posedge clk or posedge reset)
begin: temp_process4
if (reset == 1'b1) begin
sumpipe4_1 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe4_1 <= sum4_1;
end
end
end // temp_process4
assign sum_final = sumpipe4_1;
always @ (posedge clk or posedge reset)
begin: Output_Register_process
if (reset == 1'b1) begin
output_register <= 0;
end
else begin
if (clk_enable == 1'b1) begin
output_register <= sum_final;
end
end
end // Output_Register_process
// Assignment Statements
assign filter_out = output_register;
endmodule // filter
5.3 半带滤波器的Verilog程序
// -------------------------------------------------------------
//
// Module: filter
// Generated by MATLAB(R) 9.9 and Filter Design HDL Coder 3.1.8.
// Generated on: 2023-04-05 18:46:17
// -------------------------------------------------------------
// -------------------------------------------------------------
// HDL Code Generation Options:
//
// FIRAdderStyle: tree
// TargetDirectory: D:\sigma_delta\halfband
// AddPipelineRegisters: on
// TargetLanguage: Verilog
// TestBenchStimulus: impulse step ramp chirp noise
// -------------------------------------------------------------
// HDL Implementation : Fully parallel
// Folding Factor : 1
// -------------------------------------------------------------
`timescale 1 ns / 1 ns
module hb_filter
(
clk,
clk_enable,
reset,
filter_in,
filter_out
);
input clk;
input clk_enable;
input reset;
input signed [41:0] filter_in; //sfix42
output signed [57:0] filter_out; //sfix58_En15
//Module Architecture: filter
// Local Functions
// Type Definitions
// Constants
parameter signed [15:0] coeff1 = 16'b0000011011100001; //sfix16_En15
parameter signed [15:0] coeff2 = 16'b0000000000000000; //sfix16_En15
parameter signed [15:0] coeff3 = 16'b1111010001001010; //sfix16_En15
parameter signed [15:0] coeff4 = 16'b0000000000000000; //sfix16_En15
parameter signed [15:0] coeff5 = 16'b0010100000010111; //sfix16_En15
parameter signed [15:0] coeff6 = 16'b0100000000000000; //sfix16_En15
parameter signed [15:0] coeff7 = 16'b0010100000010111; //sfix16_En15
parameter signed [15:0] coeff8 = 16'b0000000000000000; //sfix16_En15
parameter signed [15:0] coeff9 = 16'b1111010001001010; //sfix16_En15
parameter signed [15:0] coeff10 = 16'b0000000000000000; //sfix16_En15
parameter signed [15:0] coeff11 = 16'b0000011011100001; //sfix16_En15
// Signals
reg signed [41:0] delay_pipeline [0:10] ; // sfix42
wire signed [56:0] product11; // sfix57_En15
wire signed [57:0] mul_temp; // sfix58_En15
wire signed [56:0] product9; // sfix57_En15
wire signed [57:0] mul_temp_1; // sfix58_En15
wire signed [56:0] product7; // sfix57_En15
wire signed [57:0] mul_temp_2; // sfix58_En15
wire signed [56:0] product6; // sfix57_En15
wire signed [56:0] product5; // sfix57_En15
wire signed [57:0] mul_temp_3; // sfix58_En15
wire signed [56:0] product3; // sfix57_En15
wire signed [57:0] mul_temp_4; // sfix58_En15
wire signed [56:0] product1; // sfix57_En15
wire signed [57:0] mul_temp_5; // sfix58_En15
wire signed [57:0] sum_final; // sfix58_En15
wire signed [57:0] sum1_1; // sfix58_En15
wire signed [56:0] add_signext; // sfix57_En15
wire signed [56:0] add_signext_1; // sfix57_En15
reg signed [57:0] sumpipe1_1; // sfix58_En15
wire signed [57:0] sum1_2; // sfix58_En15
wire signed [56:0] add_signext_2; // sfix57_En15
wire signed [56:0] add_signext_3; // sfix57_En15
reg signed [57:0] sumpipe1_2; // sfix58_En15
wire signed [57:0] sum1_3; // sfix58_En15
wire signed [56:0] add_signext_4; // sfix57_En15
wire signed [56:0] add_signext_5; // sfix57_En15
reg signed [57:0] sumpipe1_3; // sfix58_En15
reg signed [56:0] sumpipe1_4; // sfix57_En15
wire signed [57:0] sum2_1; // sfix58_En15
wire signed [57:0] add_signext_6; // sfix58_En15
wire signed [57:0] add_signext_7; // sfix58_En15
wire signed [58:0] add_temp; // sfix59_En15
reg signed [57:0] sumpipe2_1; // sfix58_En15
wire signed [57:0] sum2_2; // sfix58_En15
wire signed [57:0] add_signext_8; // sfix58_En15
wire signed [57:0] add_signext_9; // sfix58_En15
wire signed [58:0] add_temp_1; // sfix59_En15
reg signed [57:0] sumpipe2_2; // sfix58_En15
wire signed [57:0] sum3_1; // sfix58_En15
wire signed [57:0] add_signext_10; // sfix58_En15
wire signed [57:0] add_signext_11; // sfix58_En15
wire signed [58:0] add_temp_2; // sfix59_En15
reg signed [57:0] sumpipe3_1; // sfix58_En15
reg signed [57:0] output_register; // sfix58_En15
// Block Statements
always @( posedge clk or posedge reset)
begin: Delay_Pipeline_process
if (reset == 1'b1) begin
delay_pipeline[0] <= 0;
delay_pipeline[1] <= 0;
delay_pipeline[2] <= 0;
delay_pipeline[3] <= 0;
delay_pipeline[4] <= 0;
delay_pipeline[5] <= 0;
delay_pipeline[6] <= 0;
delay_pipeline[7] <= 0;
delay_pipeline[8] <= 0;
delay_pipeline[9] <= 0;
delay_pipeline[10] <= 0;
end
else begin
if (clk_enable == 1'b1) begin
delay_pipeline[0] <= filter_in;
delay_pipeline[1] <= delay_pipeline[0];
delay_pipeline[2] <= delay_pipeline[1];
delay_pipeline[3] <= delay_pipeline[2];
delay_pipeline[4] <= delay_pipeline[3];
delay_pipeline[5] <= delay_pipeline[4];
delay_pipeline[6] <= delay_pipeline[5];
delay_pipeline[7] <= delay_pipeline[6];
delay_pipeline[8] <= delay_pipeline[7];
delay_pipeline[9] <= delay_pipeline[8];
delay_pipeline[10] <= delay_pipeline[9];
end
end
end // Delay_Pipeline_process
assign mul_temp = delay_pipeline[10] * coeff11;
assign product11 = mul_temp[56:0];
assign mul_temp_1 = delay_pipeline[8] * coeff9;
assign product9 = mul_temp_1[56:0];
assign mul_temp_2 = delay_pipeline[6] * coeff7;
assign product7 = mul_temp_2[56:0];
assign product6 = $signed({delay_pipeline[5][41:0], 14'b00000000000000});
assign mul_temp_3 = delay_pipeline[4] * coeff5;
assign product5 = mul_temp_3[56:0];
assign mul_temp_4 = delay_pipeline[2] * coeff3;
assign product3 = mul_temp_4[56:0];
assign mul_temp_5 = delay_pipeline[0] * coeff1;
assign product1 = mul_temp_5[56:0];
assign add_signext = product11;
assign add_signext_1 = product9;
assign sum1_1 = add_signext + add_signext_1;
assign add_signext_2 = product7;
assign add_signext_3 = product6;
assign sum1_2 = add_signext_2 + add_signext_3;
assign add_signext_4 = product5;
assign add_signext_5 = product3;
assign sum1_3 = add_signext_4 + add_signext_5;
always @ (posedge clk or posedge reset)
begin: temp_process1
if (reset == 1'b1) begin
sumpipe1_1 <= 0;
sumpipe1_2 <= 0;
sumpipe1_3 <= 0;
sumpipe1_4 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe1_1 <= sum1_1;
sumpipe1_2 <= sum1_2;
sumpipe1_3 <= sum1_3;
sumpipe1_4 <= product1;
end
end
end // temp_process1
assign add_signext_6 = sumpipe1_1;
assign add_signext_7 = sumpipe1_2;
assign add_temp = add_signext_6 + add_signext_7;
assign sum2_1 = add_temp[57:0];
assign add_signext_8 = sumpipe1_3;
assign add_signext_9 = $signed({{1{sumpipe1_4[56]}}, sumpipe1_4});
assign add_temp_1 = add_signext_8 + add_signext_9;
assign sum2_2 = add_temp_1[57:0];
always @ (posedge clk or posedge reset)
begin: temp_process2
if (reset == 1'b1) begin
sumpipe2_1 <= 0;
sumpipe2_2 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe2_1 <= sum2_1;
sumpipe2_2 <= sum2_2;
end
end
end // temp_process2
assign add_signext_10 = sumpipe2_1;
assign add_signext_11 = sumpipe2_2;
assign add_temp_2 = add_signext_10 + add_signext_11;
assign sum3_1 = add_temp_2[57:0];
always @ (posedge clk or posedge reset)
begin: temp_process3
if (reset == 1'b1) begin
sumpipe3_1 <= 0;
end
else begin
if (clk_enable == 1'b1) begin
sumpipe3_1 <= sum3_1;
end
end
end // temp_process3
assign sum_final = sumpipe3_1;
always @ (posedge clk or posedge reset)
begin: Output_Register_process
if (reset == 1'b1) begin
output_register <= 0;
end
else begin
if (clk_enable == 1'b1) begin
output_register <= sum_final;
end
end
end // Output_Register_process
// Assignment Statements
assign filter_out = output_register;
endmodule // filter
5.4 顶层测试Verilog程序
`timescale 1us / 1ns
module testbench(
);
reg DataIn;
reg rst;
reg clk,clk1;
wire[24:0] DataOut;
sinc3 ex1(
DataIn,
rst,
clk,
DataOut
);
wire[41:0] filter_out;
reg rst1;
filter ex2 (
clk1,
1'b1,
rst1,
DataOut,
filter_out
);
wire[57:0] d_out;
hb_filter ex3(
clk1,
1'b1,
rst1,
filter_out,
d_out
);
reg[0:0] stimulus[65535:0] ;
reg[20:0] Pattern;
initial
begin
//文件必须放置在"工程目录\simulation\modelsim"路径下
$readmemb("C:/1/CIC/w1.txt",stimulus);
Pattern=0;
rst=0;
rst1=1;
clk=0;
clk1=0;
DataIn=1'b1;
#100 rst=1;
rst1=0;
repeat(65536)
begin
Pattern=Pattern+1;
#4 DataIn=stimulus[Pattern];
end
$finish;
end
always #2 clk=~clk;
always #512 clk1=~clk1;
endmodule
