
阅读量:4

文章目录
引言
哈希映射的思想,在实际中有许多运用,之前介绍的哈希表是一种经典的应用场景,而今天我们将了解其他的哈希数据结构——位图和布隆过滤器,它们在面对海量数据的场景时,有着得天独厚的优势。
一、位图
1.1 位图的概念
位图(bitset),主要用于存储和管理数据的状态。它通过使用位(bit)来表示数据的存在与否,每个位只能存储0或1,分别代表数据不存在和存在。
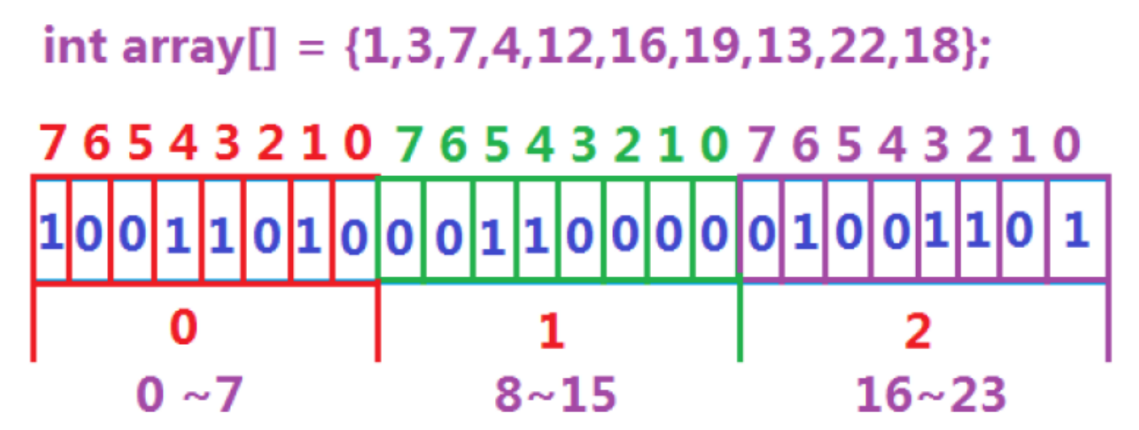
位图原理:哈希直接定址法
1.2 位图的优势
先来看一道面试题:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】
分析:
- 首先分析数据量大小,40亿整数 == 160亿byte,而1G约为10亿byte,所以大小约为16G
- 快速查找,我们想到哈希表,但是数据量太大,动态内存(最大约为4G)放不下
这时,就体现出位图的用处了!
如果将每个整数以比特位的形式存储表示,那么只需要40亿bit,约为0.5G。
所以,位图的主要优势为:
- 查找速度快
- 节省存储空间
1.3 位图的模拟实现
1.3.1 成员变量与默认成员函数
template<size_t N> class bitset { public: bitset() { _bits.resize(N / 8 + 1); } protected: vector<char> _bits; size_t _n = 0;//有效数据个数 }; 细节:
- 非类型模板参数N,表示数据量(方便开辟足够空间)
- vector数据类型为char,方便进行位操作
- 构造函数提前开辟足够的空间(+1防止整除误差)
1.3.2 test
检测指定值是否存在
bool test(size_t x) { size_t i = x / 8, j = x % 8; return _bits[i] & (1 << j); } 细节:
- i 代表第几个char,j 代表char中的第几个bit
- <<代表从低位向高位移动
1.3.3 set
存入指定值,将对应的bit设置为1
void set(size_t x) { size_t i = x / 8, j = x % 8; if (!test(x)) { _bits[i] |= (1 << j); ++_n; } } 细节:
- 如果检测该值不存在,则存入
1.3.4 reset
删除指定值,将对应的bit设置为0
void reset(size_t x) { size_t i = x / 8, j = x % 8; if (test(x)) { _bits[i] &= ~(1 << j); --_n; } } 细节:
- 如果检测该值存在,则删除
1.4 位图的缺陷
位图的最大缺陷,就是只能映射整型数据!
同时,面对数据量小且特殊的情况时,位图所消耗的空间可能比哈希表大。
1.5 位图的应用场景
位图的一些典型应用场景包括:
- 快速查找:检查某个数据是否在一个集合中。
- 排序:在某些排序算法中,位图可以用来加速排序过程。
- 求集合的交集、并集等:位图可以用来求解集合运算。
- 操作系统中磁盘块的标记:在操作系统中,位图可以用来标记磁盘块的使用状态。
二、布隆过滤器
2.1 布隆过滤器的概念
布隆过滤器(Bloom Filter),是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构。其特点为查找元素时,只能为判断一定不存在或者可能存在。
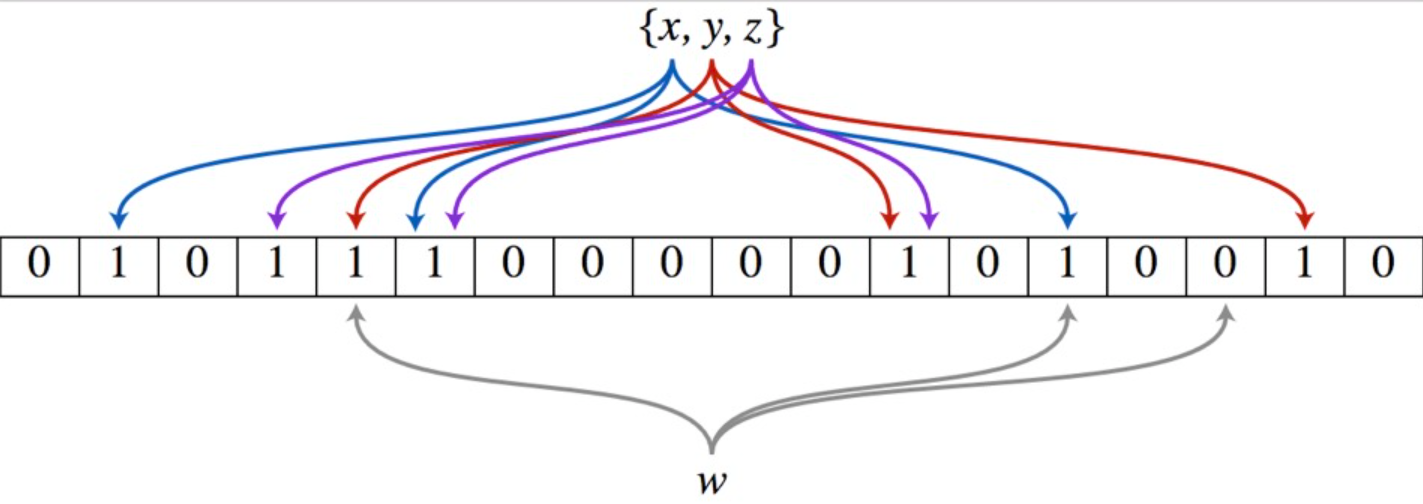
布隆过滤器原理:哈希除留余数法
简单理解:布隆过滤器 = 位图 + 一系列哈希化函数
2.2 布隆过滤器的优势
前面讲到,位图只能映射整型,而布隆过滤器可以映射不同类型,其中运用最多的是string类。为什么可以映射不同类型呢?正是因为运用了哈希化函数,将不同类型转换为整型,映射在位图上。
当然,布隆过滤器最核心的思想,是通过增加哈希化函数,降低哈希冲突的概率。它不再是一 一映射的关系,而是将一个值映射到多个地址,从而降低了值与值之间冲突的概率。
所以,布隆过滤器比位图空间利用率更高,尤其在数据密度较低时。数据量很大时,布隆过滤器可以表示全集,其他数据结构不能。
2.3 布隆过滤器的模拟实现
2.3.1 成员变量
template<size_t N, size_t X = 5,//关联系数 class K = string, class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash> class BloomFilter { public: protected: bitset<N * X> _bs; }; 细节:
- 插入的数据量N和布隆过滤器长度之间,存在一个最佳系数X(根据公式计算,哈希化函数数量为3时,最佳系数为5)
- 布隆过滤器大部分场景处理string,所以这里默认给出string和相关哈希化函数
- 底层使用bitset,进行复用
2.3.2 test
bool test(const K& key) { size_t len = N * X; size_t i1 = Hash1()(key) % len; size_t i2 = Hash2()(key) % len; size_t i3 = Hash3()(key) % len; return _bs.test(i1) && _bs.test(i2) && _bs.test(i3); } 细节:
- 如果有一个位置为false,则为false
- 全为true,才返回true(可能有误判)
2.3.3 set
void set(const K& key) { size_t len = N * X; size_t i1 = Hash1()(key) % len; size_t i2 = Hash2()(key) % len; size_t i3 = Hash3()(key) % len; _bs.set(i1); _bs.set(i2); _bs.set(i3); } 细节:插入元素时,分别将对应的多个映射位置都进行更改
2.3.4 哈希化
struct BKDRHash { size_t operator()(const string& s) { size_t hash = 0; for (auto& ch : s) { hash = hash * 31 + ch; } return hash; } }; struct APHash { size_t operator()(const string& s) { size_t hash = 0; for (long i = 0; i < s.size(); ++i) { if ((i & 1) == 0) { hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3)); } else { hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5))); } } return hash; } }; struct DJBHash { size_t operator()(const string& s) { size_t hash = 5381; for (auto& ch : s) { hash += (hash << 5) + ch; } return hash; } }; 细节:这里选取了评分前三的string哈希化函数,欲知详情,请移步这篇文章~
2.4 布隆过滤器的缺陷
由于其本身特性(一个值拥有多个映射位置),必定会导致存在误判!这种特性其实说两面一体的,既能带来优势(精准快速判断一定不存在),也会带来缺陷(存在会误判)。
还有一个性质,就是不存储元素本身。这也可以说既是优点也是缺点,关键是看怎么使用。这在某些对保密要求比较严格的场合有很大优势。
最后,一般布隆过滤器不支持删除操作。因为一个映射位置可能对应不止一个值,删除可能导致数据错乱。
2.5 布隆过滤器的应用场景
布隆过滤器的一些典型应用场景包括:
- 防止垃圾邮件:在电子邮件系统中,布隆过滤器可以用来过滤已知的垃圾邮件发送者。
- 搜索引擎:在搜索引擎中,布隆过滤器可以用来快速判断某个URL是否已经被爬虫访问过,从而避免重复爬取。
- 数据库缓存:在数据库缓存中,布隆过滤器可以用来判断某个数据是否已经在缓存中,从而避免对数据库的频繁查询。
- 数据安全:在数据安全领域,布隆过滤器可以用来判断某个数据是否属于黑名单,从而提供额外的安全保障。
三、哈希表、位图和布隆过滤器的对比
3.1 表格对比
| 数据结构 | 时间复杂度 | 空间利用率 | 准确性 | 映射类型 |
|---|---|---|---|---|
| 哈希表 | O(1) | 低 | 准确 | 任意 |
| 位图 | O(1) | 高 | 准确 | 整型 |
| 布隆过滤器 | O(k) | 极高 | 不准确 | 任意 |
其中k为哈希化函数的个数,通常这个值很小(本文取k = 3)
3.2 分析对比
- 哈希表和位图在查询时间复杂度上都是 O(1),但它们的应用场景和数据结构有所不同。哈希表适用于一般的键值对存储和查询,而位图适用于处理大量连续整数的集合。
- 布隆过滤器在查询时间复杂度上稍逊于哈希表和位图,但由于其空间效率高且适用于快速判断元素是否存在的场景,因此在某些特定应用中仍然非常有用。需要注意的是,布隆过滤器存在误报率,且通常不支持删除操作。

