
阅读量:2
目录
8、pandas.DataFrame.to_clipboard函数



一、用法精讲
7、pandas.read_clipboard函数
7-1、语法
# 7、pandas.read_clipboard函数 pandas.read_clipboard(sep='\\s+', dtype_backend=_NoDefault.no_default, **kwargs) Read text from clipboard and pass to read_csv(). Parses clipboard contents similar to how CSV files are parsed using read_csv(). Parameters: sepstr, default ‘\s+’ A string or regex delimiter. The default of '\\s+' denotes one or more whitespace characters. dtype_backend{‘numpy_nullable’, ‘pyarrow’}, default ‘numpy_nullable’ Back-end data type applied to the resultant DataFrame (still experimental). Behaviour is as follows: "numpy_nullable": returns nullable-dtype-backed DataFrame (default). "pyarrow": returns pyarrow-backed nullable ArrowDtype DataFrame. New in version 2.0. **kwargs See read_csv() for the full argument list. Returns: DataFrame A parsed DataFrame object.7-2、参数
7-2-1、sep(可选,默认值为'\\s+'):表示使用正则表达式来匹配一个或多个空白字符(如空格、制表符等)作为字段之间的分隔符,这意味着,如果你的数据是通过空格、制表符等分隔的,你可以直接使用默认值,但如果你使用的是逗号(CSV 格式)或其他分隔符,你应该相应地更改这个参数,比如sep=','。
7-2-2、dtype_backend(可选):这个参数通常不需要用户直接设置,它是用来指定数据类型推断的后端,Pandas内部使用它来优化数据类型的推断过程。
7-2-3、**kwargs(可选):一个可变关键字参数,允许你传递额外的参数给函数,这些参数会被传递给pandas.read_csv()函数,因为read_clipboard()在内部实际上是使用read_csv()来解析剪贴板中的数据。因此,你可以传递任何read_csv()支持的参数,比如header(指定列名的行索引,默认为0,如果没有列名则为None)、index_col(用作行索引的列编号或列名列表)、dtype(指定列的数据类型)等。
7-3、功能
从用户的系统剪贴板中读取文本数据,并将其解析为pandas DataFrame对象。
7-4、返回值
返回值是一个pandas DataFrame对象,该对象包含了剪贴板中解析后的数据,其中每行代表数据表中的一行,每列代表数据表中的一个字段。DataFrame的索引、列名和数据类型等属性会根据剪贴板中的数据和函数的参数设置自动推断和设置。
7-5、说明
从Pandas 1.0.0开始,dtype_backend参数已被弃用,并且可能在未来的版本中移除。在大多数情况下,用户不需要直接设置这个参数。
7-6、用法
7-6-1、代码示例
# 7、pandas.read_clipboard函数 # 7-1、先复制以下内容 # Name Age City # Alice 30 New York # Bob 25 Los Angeles # Charlie 35 Chicago # 7-2、使用pandas.read_clipboard()函数读取剪切板的信息 import pandas as pd # 读取剪贴板中的数据,指定分隔符为制表符 df = pd.read_clipboard(sep='\t') # 显示 DataFrame print(df)7-6-2、结果输出
# Name Age City # 0 Alice 30 New York # 1 Bob 25 Los Angeles # 2 Charlie 35 Chicago8、pandas.DataFrame.to_clipboard函数
8-1、语法
# 8、pandas.DataFrame.to_clipboard函数 DataFrame.to_clipboard(*, excel=True, sep=None, **kwargs) Copy object to the system clipboard. Write a text representation of object to the system clipboard. This can be pasted into Excel, for example. Parameters: excelbool, default True Produce output in a csv format for easy pasting into excel. True, use the provided separator for csv pasting. False, write a string representation of the object to the clipboard. sepstr, default '\t' Field delimiter. **kwargs These parameters will be passed to DataFrame.to_csv.8-2、参数
8-2-1、excel(可选,默认值为True):如果为True,则尝试以Excel友好的方式复制数据,即如果可能的话,会保留多个工作表或样式。但是,请注意,由于剪贴板本身并不支持复杂的数据结构(如多个工作表或样式),因此这个参数的实际效果可能因操作系统和剪贴板支持的功能而异。在大多数情况下,将其设置为True或False对结果没有显著影响,因为剪贴板通常只接受纯文本或CSV格式的数据。
8-2-2、sep(可选,默认值为None):用于分隔DataFrame中列的分隔符。如果为None(默认值),则不会添加任何分隔符,DataFrame会以制表符分隔的格式(类似于CSV但没有引号包围字符串)复制到剪贴板。如果你想要使用逗号(,)或其他字符作为分隔符,可以指定该参数。但是,请注意,不是所有的应用程序都能很好地处理从剪贴板粘贴的自定义分隔符数据。
8-2-3、**kwargs(可选):一个可变关键字参数,允许你传递额外的参数给底层的to_csv()方法(尽管在大多数情况下,to_clipboard()方法并不直接调用to_csv(),但它们的参数在某些方面相似)。然而,对于to_clipboard()方法来说,**kwargs实际上并不接受与to_csv()相同的所有参数,因为剪贴板操作有其自身的限制和特性。
8-3、功能
将pandas DataFrame对象的内容复制到系统的剪贴板中。
8-4、返回值
不返回任何值(即返回值为None),它的主要作用是将DataFrame的内容复制到剪贴板,而不是返回一个新的对象或数据。
8-5、说明
用户就可以方便地将DataFrame中的数据粘贴到其他应用程序中,如Excel、Word或其他文本编辑器,以便进一步的处理或展示。
8-6、用法
8-6-1、代码示例
# 8、pandas.DataFrame.to_clipboard函数 # 8-1、将pandas DataFrame对象的内容复制到系统的剪贴板中 import pandas as pd # 创建一个示例 DataFrame data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [24, 30, 22], 'City': ['New York', 'San Francisco', 'Los Angeles']} df = pd.DataFrame(data) # 将 DataFrame 的内容复制到剪贴板 df.to_clipboard(index=False) # 注意:虽然这里写了 index=False,但 to_clipboard 并不接受这个参数 # 此时,你可以在其他应用程序中粘贴 DataFrame 的内容 # 8-2、在打开的excel、word及编辑器中粘贴操作(注:Ctrl+V)8-6-2、结果输出
# Name Age City # Alice 24 New York # Bob 30 San Francisco # Charlie 22 Los Angeles 9、pandas.read_excel函数
9-1、语法
# 9、pandas.read_excel函数 pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=_NoDefault.no_default, date_format=None, thousands=None, decimal='.', comment=None, skipfooter=0, storage_options=None, dtype_backend=_NoDefault.no_default, engine_kwargs=None) Read an Excel file into a pandas DataFrame. Supports xls, xlsx, xlsm, xlsb, odf, ods and odt file extensions read from a local filesystem or URL. Supports an option to read a single sheet or a list of sheets. Parameters: iostr, bytes, ExcelFile, xlrd.Book, path object, or file-like object Any valid string path is acceptable. The string could be a URL. Valid URL schemes include http, ftp, s3, and file. For file URLs, a host is expected. A local file could be: file://localhost/path/to/table.xlsx. If you want to pass in a path object, pandas accepts any os.PathLike. By file-like object, we refer to objects with a read() method, such as a file handle (e.g. via builtin open function) or StringIO. Deprecated since version 2.1.0: Passing byte strings is deprecated. To read from a byte string, wrap it in a BytesIO object. sheet_namestr, int, list, or None, default 0 Strings are used for sheet names. Integers are used in zero-indexed sheet positions (chart sheets do not count as a sheet position). Lists of strings/integers are used to request multiple sheets. Specify None to get all worksheets. Available cases: Defaults to 0: 1st sheet as a DataFrame 1: 2nd sheet as a DataFrame "Sheet1": Load sheet with name “Sheet1” [0, 1, "Sheet5"]: Load first, second and sheet named “Sheet5” as a dict of DataFrame None: All worksheets. headerint, list of int, default 0 Row (0-indexed) to use for the column labels of the parsed DataFrame. If a list of integers is passed those row positions will be combined into a MultiIndex. Use None if there is no header. namesarray-like, default None List of column names to use. If file contains no header row, then you should explicitly pass header=None. index_colint, str, list of int, default None Column (0-indexed) to use as the row labels of the DataFrame. Pass None if there is no such column. If a list is passed, those columns will be combined into a MultiIndex. If a subset of data is selected with usecols, index_col is based on the subset. Missing values will be forward filled to allow roundtripping with to_excel for merged_cells=True. To avoid forward filling the missing values use set_index after reading the data instead of index_col. usecolsstr, list-like, or callable, default None If None, then parse all columns. If str, then indicates comma separated list of Excel column letters and column ranges (e.g. “A:E” or “A,C,E:F”). Ranges are inclusive of both sides. If list of int, then indicates list of column numbers to be parsed (0-indexed). If list of string, then indicates list of column names to be parsed. If callable, then evaluate each column name against it and parse the column if the callable returns True. Returns a subset of the columns according to behavior above. dtypeType name or dict of column -> type, default None Data type for data or columns. E.g. {‘a’: np.float64, ‘b’: np.int32} Use object to preserve data as stored in Excel and not interpret dtype, which will necessarily result in object dtype. If converters are specified, they will be applied INSTEAD of dtype conversion. If you use None, it will infer the dtype of each column based on the data. engine{‘openpyxl’, ‘calamine’, ‘odf’, ‘pyxlsb’, ‘xlrd’}, default None If io is not a buffer or path, this must be set to identify io. Engine compatibility : openpyxl supports newer Excel file formats. calamine supports Excel (.xls, .xlsx, .xlsm, .xlsb) and OpenDocument (.ods) file formats. odf supports OpenDocument file formats (.odf, .ods, .odt). pyxlsb supports Binary Excel files. xlrd supports old-style Excel files (.xls). When engine=None, the following logic will be used to determine the engine: If path_or_buffer is an OpenDocument format (.odf, .ods, .odt), then odf will be used. Otherwise if path_or_buffer is an xls format, xlrd will be used. Otherwise if path_or_buffer is in xlsb format, pyxlsb will be used. Otherwise openpyxl will be used. convertersdict, default None Dict of functions for converting values in certain columns. Keys can either be integers or column labels, values are functions that take one input argument, the Excel cell content, and return the transformed content. true_valueslist, default None Values to consider as True. false_valueslist, default None Values to consider as False. skiprowslist-like, int, or callable, optional Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file. If callable, the callable function will be evaluated against the row indices, returning True if the row should be skipped and False otherwise. An example of a valid callable argument would be lambda x: x in [0, 2]. nrowsint, default None Number of rows to parse. na_valuesscalar, str, list-like, or dict, default None Additional strings to recognize as NA/NaN. If dict passed, specific per-column NA values. By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘<NA>’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘None’, ‘n/a’, ‘nan’, ‘null’. keep_default_nabool, default True Whether or not to include the default NaN values when parsing the data. Depending on whether na_values is passed in, the behavior is as follows: If keep_default_na is True, and na_values are specified, na_values is appended to the default NaN values used for parsing. If keep_default_na is True, and na_values are not specified, only the default NaN values are used for parsing. If keep_default_na is False, and na_values are specified, only the NaN values specified na_values are used for parsing. If keep_default_na is False, and na_values are not specified, no strings will be parsed as NaN. Note that if na_filter is passed in as False, the keep_default_na and na_values parameters will be ignored. na_filterbool, default True Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file. verbosebool, default False Indicate number of NA values placed in non-numeric columns. parse_datesbool, list-like, or dict, default False The behavior is as follows: bool. If True -> try parsing the index. list of int or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as a separate date column. list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as a single date column. dict, e.g. {‘foo’ : [1, 3]} -> parse columns 1, 3 as date and call result ‘foo’ If a column or index contains an unparsable date, the entire column or index will be returned unaltered as an object data type. If you don`t want to parse some cells as date just change their type in Excel to “Text”. For non-standard datetime parsing, use pd.to_datetime after pd.read_excel. Note: A fast-path exists for iso8601-formatted dates. date_parserfunction, optional Function to use for converting a sequence of string columns to an array of datetime instances. The default uses dateutil.parser.parser to do the conversion. Pandas will try to call date_parser in three different ways, advancing to the next if an exception occurs: 1) Pass one or more arrays (as defined by parse_dates) as arguments; 2) concatenate (row-wise) the string values from the columns defined by parse_dates into a single array and pass that; and 3) call date_parser once for each row using one or more strings (corresponding to the columns defined by parse_dates) as arguments. Deprecated since version 2.0.0: Use date_format instead, or read in as object and then apply to_datetime() as-needed. date_formatstr or dict of column -> format, default None If used in conjunction with parse_dates, will parse dates according to this format. For anything more complex, please read in as object and then apply to_datetime() as-needed. New in version 2.0.0. thousandsstr, default None Thousands separator for parsing string columns to numeric. Note that this parameter is only necessary for columns stored as TEXT in Excel, any numeric columns will automatically be parsed, regardless of display format. decimalstr, default ‘.’ Character to recognize as decimal point for parsing string columns to numeric. Note that this parameter is only necessary for columns stored as TEXT in Excel, any numeric columns will automatically be parsed, regardless of display format.(e.g. use ‘,’ for European data). New in version 1.4.0. commentstr, default None Comments out remainder of line. Pass a character or characters to this argument to indicate comments in the input file. Any data between the comment string and the end of the current line is ignored. skipfooterint, default 0 Rows at the end to skip (0-indexed). storage_optionsdict, optional Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here. dtype_backend{‘numpy_nullable’, ‘pyarrow’}, default ‘numpy_nullable’ Back-end data type applied to the resultant DataFrame (still experimental). Behaviour is as follows: "numpy_nullable": returns nullable-dtype-backed DataFrame (default). "pyarrow": returns pyarrow-backed nullable ArrowDtype DataFrame. New in version 2.0. engine_kwargsdict, optional Arbitrary keyword arguments passed to excel engine. Returns: DataFrame or dict of DataFrames DataFrame from the passed in Excel file. See notes in sheet_name argument for more information on when a dict of DataFrames is returned.9-2、参数
9-2-1、io(必须):文件路径、文件对象或ExcelFile对象,指定要读取的Excel文件的路径或对象。
9-2-2、sheet_name(可选,默认值为0):字符串、整数、字符串列表或None,指定要读取的工作表(sheet)。如果是整数,则按位置索引(从0开始);如果是字符串,则按名称索引;如果是列表的字符串,则返回字典,其中键是工作表名,值是对应的DataFrame;如果为None,则返回所有工作表作为字典。
9-2-3、header(可选,默认值为0):指定作为列名的行,默认为0(第一行)。如果文件没有列名,则可以使用None 并通过names参数提供列名。
9-2-4、names(可选,默认值为None):列表,如果原始数据中不包含列标题,则可以通过此参数手动指定列标题。
9-2-5、index_col(可选,默认值为None):整数、字符串、序列或布尔值,用作行索引的列编号或列名。如果传递整数,则按位置索引;如果传递字符串,则按名称索引;如果是序列,则使用多个列作为多级索引;如果为False,则不使用任何列作为索引。
9-2-6、usecols(可选,默认值为None):整数、字符串、列表或可调用对象,如果为整数,则只使用这一列;如果是字符串,则只使用此名称的列;如果是列表,则使用这些索引或名称的列;如果是可调用对象,则用于选择列。
9-2-7、dtype(可选,默认值为None):类型名或字典,指定每列的数据类型。如果传递字典,则键是列名,值是类型名。
9-2-8、engine(可选,默认值为None):字符串,用于解析Excel文件的引擎。常用的有openpyxl(对于.xlsx文件)和xlrd(对于较旧的.xls文件)。注意,xlrd从版本2.0.0开始不再支持.xlsx文件。
9-2-9、converters(可选,默认值为None):字典,一个将列名映射到函数的字典,用于在读取之前转换列的值。
9-2-10、true_values/false_values(可选,默认值为None):列表样对象,用于将值转换为布尔值的序列。
9-2-11、skiprows(可选,默认值为None):列表样对象,在读取之前要跳过的行(从文件开始计数)。
9-2-12、nrows(可选,默认值为None):整数,要读取的行数(从文件开始)。
9-2-13、na_values(可选,默认值为None):标量、字符串、列表样对象或字典,用于将空值替换为NaN的额外值。
9-2-14、keep_default_na(可选,默认值为True):布尔值,如果为True,则使用pandas的默认NaN值集。
9-2-15、na_filter(可选,默认值为True):布尔值,如果为True,则尝试检测缺失值(如空字符串或仅包含空白的字符串)。
9-2-16、verbose(可选,默认值为False):布尔值,如果为True,则打印有关文件读取的额外信息。
9-2-17、parse_dates(可选,默认值为False):布尔值、列表样对象或字典,尝试将数据解析为日期。如果为True,则尝试解析所有列;如果为列表,则仅解析列表中的列;如果为字典,则字典的键是列名,值是要解析的日期格式。
9-2-18、date_parser(可选):用于解析日期的函数。
9-2-19、date_format(可选,默认值为None):日期时间对象的格式字符串。
9-2-20、thousands(可选,默认值为None):字符串,千位分隔符,如逗号(,)或点(.)。
9-2-21、decimal(可选,默认值为'.'):字符串,小数点字符。
9-2-22、comment(可选,默认值为None):字符串,表示注释字符的字符串,用于跳过包含此字符的行。
9-2-23、skipfooter(可选,默认值为0):整数,在文件末尾要跳过的行数(不支持所有引擎)。
9-2-24、storage_options(可选,默认值为None):字典,对于支持的文件类型(如AWS S3、Google Cloud Storage),可以传递额外的存储选项。
9-2-25、dtype_backend(可选):这个参数通常不需要用户直接设置,它是用来指定数据类型推断的后端,Pandas内部使用它来优化数据类型的推断过程。
9-2-27、engine_kwargs(可选,默认值为None):字典,传递给Excel读取引擎的额外关键字参数。
9-3、功能
将Excel文件中的数据读取到pandas的DataFrame对象中。
9-4、返回值
9-4-1、当只读取一个工作表时,pandas.read_excel()函数返回一个pandas DataFrame对象,该对象包含了指定工作表中的所有数据。DataFrame是pandas中用于存储和操作结构化数据的主要数据结构,它类似于Excel中的表格,有行和列。
9-4-2、当读取多个工作表时,如果sheet_name参数被设置为一个列表,包含了要读取的工作表名称或索引,则函数返回一个字典,键是工作表的名称或索引,值是该工作表对应的DataFrame对象,这样,用户就可以方便地访问和操作多个工作表中的数据。
9-5、说明
通过这个函数,用户可以轻松地将存储在Excel表格中的数据加载到pandas的数据结构中,进而进行各种数据分析和处理操作。该函数支持从本地文件系统、URL或其他文件路径读取Excel文件,并提供了丰富的参数来自定义读取过程,如指定工作表、列名、索引列、数据类型等。
9-6、用法
9-6-1、数据准备
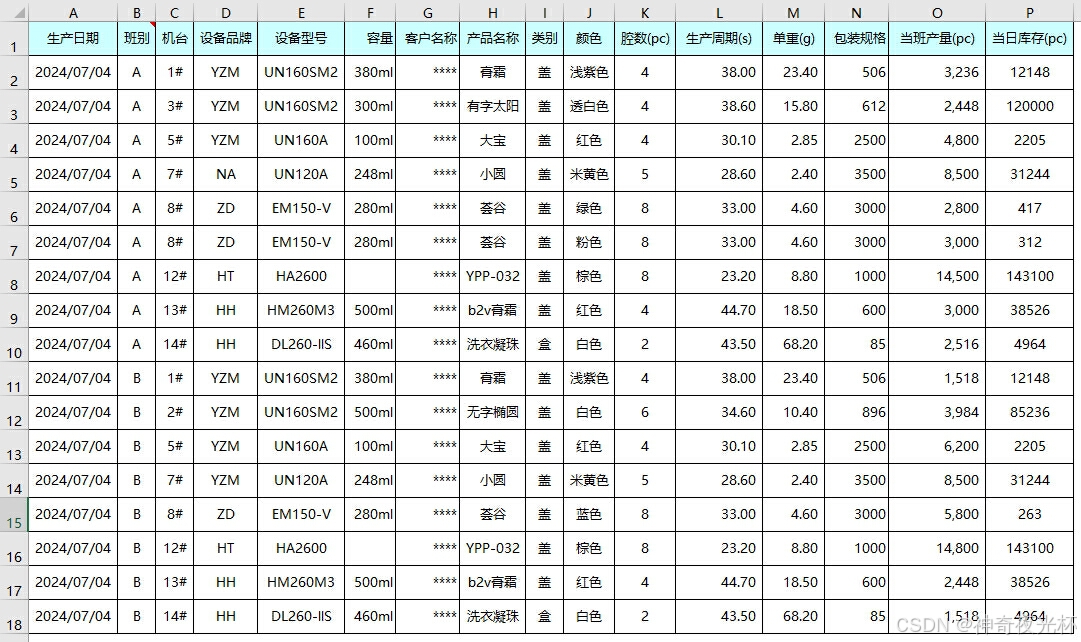
9-6-2、代码示例
# 9、pandas.read_excel函数 # 9-1、基本读取 import pandas as pd # 读取 Excel 文件中的第一个工作表 df = pd.read_excel('Pandas_read_excel数据.xlsx') print(df.head()) # 9-2、读取指定工作表 import pandas as pd # 读取名为 'Sheet2' 的工作表 df = pd.read_excel('Pandas_read_excel数据.xlsx', sheet_name='Sheet2') print(df.head()) # 9-3、指定列名和索引列 import pandas as pd # 指定第一行作为列名,第二列作为索引列 df = pd.read_excel('Pandas_read_excel数据.xlsx', header=0, index_col=1) print(df.head()) # 9-4、读取特定列 import pandas as pd # 只读取第1, 2, 3列 df = pd.read_excel('Pandas_read_excel数据.xlsx', usecols=[0, 1, 2]) print(df.head()) # 9-5、数据类型转换 import pandas as pd # 将第一列作为字符串读取 df = pd.read_excel('Pandas_read_excel数据.xlsx', dtype={0: str}) print(df.head()) # 9-6、使用自定义缺失值 import pandas as pd # 将 'NA' 和 'Missing' 视为缺失值 df = pd.read_excel('Pandas_read_excel数据.xlsx', na_values=['NA', 'Missing']) print(df.head()) # 9-7、跳过行和读取特定行数 import pandas as pd # 跳过前两行,读取接下来的10行 df = pd.read_excel('Pandas_read_excel数据.xlsx', skiprows=2, nrows=10) print(df.head()) # 9-8、日期解析 import pandas as pd # 解析第一列为日期 df = pd.read_excel('Pandas_read_excel数据.xlsx', parse_dates=[0]) print(df.head()) # 9-9、读取尾部行 import pandas as pd # 跳过最后两行 df = pd.read_excel('Pandas_read_excel数据.xlsx', skipfooter=2) print(df.head())9-6-3、结果输出
# 9-1、基本读取 # 生产日期 班别 机台 设备品牌 设备型号 ... 生产周期(s) 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 0 2024-07-04 A 1 YZM UN160SM2 ... 38.0 23.40 506 3236 12148 # 1 2024-07-04 A 3 YZM UN160SM2 ... 38.6 15.80 612 2448 120000 # 2 2024-07-04 A 5 YZM UN160A ... 30.1 2.85 2500 4800 2205 # 3 2024-07-04 A 7 NaN UN120A ... 28.6 2.40 3500 8500 31244 # 4 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 2800 417 # # [5 rows x 16 columns] # 9-2、读取指定工作表 # 生产日期 班别 机台 设备品牌 设备型号 ... 生产周期(s) 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 0 2024-07-04 A 1 YZM UN160SM2 ... 38.0 23.40 506 3236 12148 # 1 2024-07-04 A 3 YZM UN160SM2 ... 38.6 15.80 612 2448 120000 # 2 2024-07-04 A 5 YZM UN160A ... 30.1 2.85 2500 4800 2205 # 3 2024-07-04 A 7 NaN UN120A ... 28.6 2.40 3500 8500 31244 # 4 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 2800 417 # # [5 rows x 16 columns] # 9-3、指定列名和索引列 # 生产日期 机台 设备品牌 设备型号 ... 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 班别 ... # A 2024-07-04 1 YZM UN160SM2 ... 23.40 506 3236 12148 # A 2024-07-04 3 YZM UN160SM2 ... 15.80 612 2448 120000 # A 2024-07-04 5 YZM UN160A ... 2.85 2500 4800 2205 # A 2024-07-04 7 NaN UN120A ... 2.40 3500 8500 31244 # A 2024-07-04 8 ZD EM150-V ... 4.60 3000 2800 417 # # [5 rows x 15 columns] # 9-4、读取特定列 # 生产日期 班别 机台 # 0 2024-07-04 A 1 # 1 2024-07-04 A 3 # 2 2024-07-04 A 5 # 3 2024-07-04 A 7 # 4 2024-07-04 A 8 # 9-5、数据类型转换 # 生产日期 班别 机台 设备品牌 ... 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 0 2024-07-04 00:00:00 A 1 YZM ... 23.40 506 3236 12148 # 1 2024-07-04 00:00:00 A 3 YZM ... 15.80 612 2448 120000 # 2 2024-07-04 00:00:00 A 5 YZM ... 2.85 2500 4800 2205 # 3 2024-07-04 00:00:00 A 7 NaN ... 2.40 3500 8500 31244 # 4 2024-07-04 00:00:00 A 8 ZD ... 4.60 3000 2800 417 # # [5 rows x 16 columns] # 9-6、使用自定义缺失值 # 生产日期 班别 机台 设备品牌 设备型号 ... 生产周期(s) 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 0 2024-07-04 A 1 YZM UN160SM2 ... 38.0 23.40 506 3236 12148 # 1 2024-07-04 A 3 YZM UN160SM2 ... 38.6 15.80 612 2448 120000 # 2 2024-07-04 A 5 YZM UN160A ... 30.1 2.85 2500 4800 2205 # 3 2024-07-04 A 7 NaN UN120A ... 28.6 2.40 3500 8500 31244 # 4 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 2800 417 # # [5 rows x 16 columns] # 9-7、跳过行和读取特定行数 # 2024-07-04 00:00:00 A 3 YZM UN160SM2 ... 38.6 15.8 612 2448 120000 # 0 2024-07-04 A 5 YZM UN160A ... 30.1 2.85 2500 4800 2205 # 1 2024-07-04 A 7 NaN UN120A ... 28.6 2.40 3500 8500 31244 # 2 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 2800 417 # 3 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 3000 312 # 4 2024-07-04 A 12 HT HA2600 ... 23.2 8.80 1000 14500 143100 # # [5 rows x 16 columns] # 9-8、日期解析 # 生产日期 班别 机台 设备品牌 设备型号 ... 生产周期(s) 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 0 2024-07-04 A 1 YZM UN160SM2 ... 38.0 23.40 506 3236 12148 # 1 2024-07-04 A 3 YZM UN160SM2 ... 38.6 15.80 612 2448 120000 # 2 2024-07-04 A 5 YZM UN160A ... 30.1 2.85 2500 4800 2205 # 3 2024-07-04 A 7 NaN UN120A ... 28.6 2.40 3500 8500 31244 # 4 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 2800 417 # # [5 rows x 16 columns] # 9-9、读取尾部行 # 生产日期 班别 机台 设备品牌 设备型号 ... 生产周期(s) 单重(g) 包装规格 当班产量(pc) 当日库存(pc) # 0 2024-07-04 A 1 YZM UN160SM2 ... 38.0 23.40 506 3236 12148 # 1 2024-07-04 A 3 YZM UN160SM2 ... 38.6 15.80 612 2448 120000 # 2 2024-07-04 A 5 YZM UN160A ... 30.1 2.85 2500 4800 2205 # 3 2024-07-04 A 7 NaN UN120A ... 28.6 2.40 3500 8500 31244 # 4 2024-07-04 A 8 ZD EM150-V ... 33.0 4.60 3000 2800 417 # # [5 rows x 16 columns]