
阅读量:0
Python中,读写.xlsx文件(即Excel 2007及以后版本的文件)常用的库有openpyxl和pandas。openpyxl提供了对Excel工作簿、工作表、单元格等的底层操作,而pandas则提供了更高级的数据处理和分析功能,同时支持读写Excel文件。
如果列程没有看懂,文章后半部分有详细教程
读取.xlsx文件
import openpyxl # 打开Excel文件 workbook = openpyxl.load_workbook('example.xlsx') # 获取活动工作表(通常是第一个工作表) sheet = workbook.active # 读取单元格数据 cell_value = sheet['A1'].value print(cell_value) # 读取整行或整列数据 row_values = [cell.value for cell in sheet[1]] # 第一行数据 column_values = [sheet[f'A{i}'].value for i in range(1, sheet.max_row + 1)] # A列数据 # 遍历所有单元格数据 for row in sheet.iter_rows(values_only=True): print(row)写入.xlsx文件
import openpyxl # 创建一个新的Excel工作簿 workbook = openpyxl.Workbook() # 获取活动工作表 sheet = workbook.active # 写入单元格数据 sheet['A1'] = 'Hello' sheet['B1'] = 'World' # 保存Excel文件 workbook.save('output.xlsx')使用openpyxl来更新一个已经存在的.xlsx文件中的单个单元格,而不改变其他
import openpyxl # 加载现有的Excel文件 workbook = openpyxl.load_workbook('existing_file.xlsx') # 选择要修改的工作表,这里假设是第一个工作表 sheet = workbook.worksheets[0] # 找到并修改特定的单元格,这里以A1为例 cell = sheet['A1'] cell.value = '新的值' # 保存修改后的工作簿,这里会覆盖原文件,如果需要保留原文件,请另存为新文件 workbook.save('existing_file.xlsx')综合应用:时刻数值记录,每天生成个excel文件,以当天的时间命名文件的名字,每隔2s在excel文档中记录一个数字,每次记录不覆盖原始的数据
import openpyxl import time import os import random current_time = time.strftime('%Y-%m-%d') # 文件路径 file_path = str(str(current_time)+".xlsx") # 判断文件是否存在 if os.path.exists(file_path): print(f"{file_path} 文件存在") # workbook = openpyxl.load_workbook('AA.xlsx') # 加载已存在的工作簿 workbook = openpyxl.load_workbook(file_path) else: print(f"{file_path} 文件不存在") workbook = openpyxl.Workbook() # 创建一个新的工作簿 # 获取活动工作表 sheet = workbook.active print(sheet['AA1'].value) if sheet['AA1'].value == None: start_row = 1 else: start_row = sheet['AA1'].value+1 while True: # 获取当前时间并格式化 current_time = time.strftime('%H:%M:%S') # %Y - %m - %d content = random.randint(1, 999) # 将时间和内容写入工作表 sheet.cell(row=start_row, column=1, value=current_time) sheet.cell(row=start_row, column=2, value=content) sheet['AA1'].value = start_row workbook.save(file_path) # 保存工作簿 start_row += 1 # 更新起始行以便下次写入新行 time.sleep(2) column_values = [str(sheet[f'A{i}'].value)+"-"+ str(sheet[f'B{i}'].value) for i in range(start_row-5 , start_row)] print(column_values) 程序运行后会在程序所在的文件夹产生一个excel的表格,记录每隔2s产生的随机数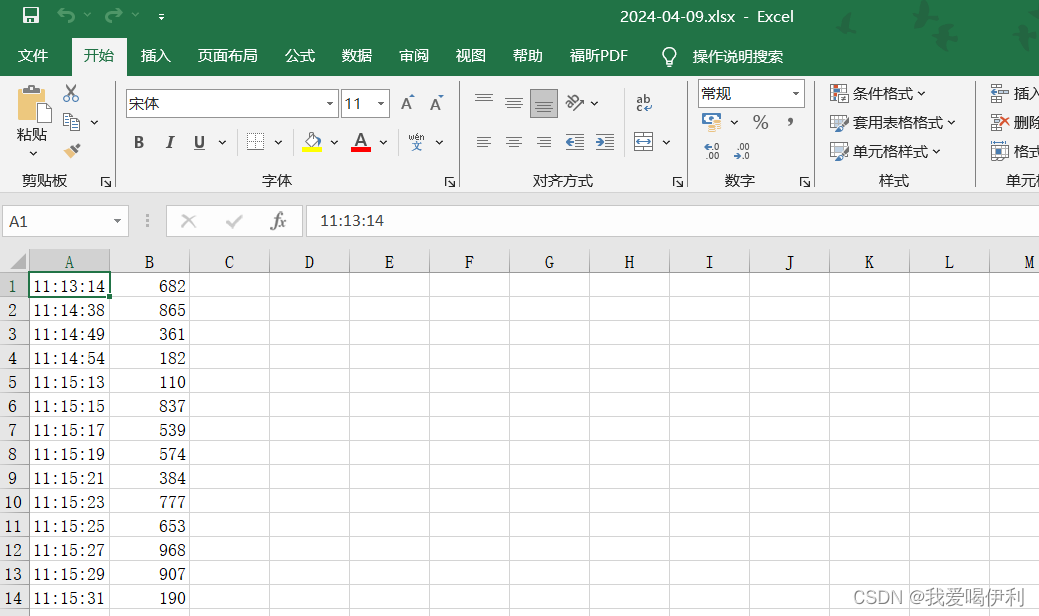
Python读写xlsx文件详解
在数据处理和分析的过程中,Excel文件由于其直观的表格形式以及易操作的特点,被广泛应用于各个行业和领域。而Python作为一种强大的编程语言,自然也提供了多种处理Excel文件的库。其中,openpyxl库就是专门用于读写.xlsx文件的Python库。本文将详细介绍如何使用openpyxl库来读写xlsx文件。
一、安装openpyxl库
在使用openpyxl库之前,首先需要确保已经安装了这个库。可以使用pip来安装:
pip install openpyxl二、读取xlsx文件
加载工作簿
使用openpyxl.load_workbook()函数来加载一个已经存在的xlsx文件:
from openpyxl import load_workbook workbook = load_workbook('example.xlsx')获取工作表
一个Excel文件可以包含多个工作表(Sheet),通过workbook.sheetnames可以获取所有工作表的名称列表,通过workbook[sheet_name]或workbook.active可以获取对应的工作表对象。
sheet_names = workbook.sheetnames # 获取所有工作表名称 sheet = workbook['Sheet1'] # 获取名为'Sheet1'的工作表 # 或者使用active属性获取活动工作表 active_sheet = workbook.active读取单元格数据
通过工作表的cell()方法或直接使用单元格坐标,可以读取单元格的数据。
# 使用cell()方法 cell_value = sheet.cell(row=1, column=1).value # 读取第一行第一列的数据 # 使用单元格坐标 cell_value = sheet['A1'].value # 同样读取第一行第一列的数据遍历工作表数据
如果需要遍历整个工作表的数据,可以使用iter_rows()或iter_cols()方法。
for row in sheet.iter_rows(values_only=True): print(row) # 打印每一行的数据三、写入xlsx文件
创建工作簿和工作表
使用openpyxl.Workbook()可以创建一个新的工作簿,并默认创建一个活动工作表。
from openpyxl import Workbook workbook = Workbook() sheet = workbook.active写入单元数据
与读取单元格数据类似,可以使用cell()方法或直接使用单元格坐标来写入数据。
sheet['A1'] = 'Hello' # 在第一行第一列写入'Hello' sheet.cell(row=2, column=2, value='World') # 在第二行第二列写入'World'保存工作簿
使用workbook.save()方法将修改后的工作簿保存到文件。
workbook.save('output.xlsx') # 将工作簿保存为output.xlsx文件四、注意事项
- 在读取和写入xlsx文件时,注意文件的路径和名称是否正确。
- 如果需要处理大量数据,建议使用pandas库来处理Excel文件,它提供了更强大和灵活的数据处理能力。
openpyxl库主要用于处理.xlsx格式的文件,如果需要处理.xls格式的文件,可以使用xlrd和xlwt库。
