
阅读量:4
一、前言
前两篇已经介绍了 GPGPU 的背景 和 GPGPU 的编程模型相关的内容,本文将在 SIMT 计算模型的基础上,介绍 GPGPU 控制核心架构和微体系结构的设计。
二、CPU-GPGPU 异构计算系统
一个由 CPU 和 GPGPU 构成的异构计算平台如下图所示,GPGPU 通过 PCI-E(Peripheral Component Interconnect Express)接口连接到 CPU 上 。CPU 作为控制主体统筹整个系统的运行。
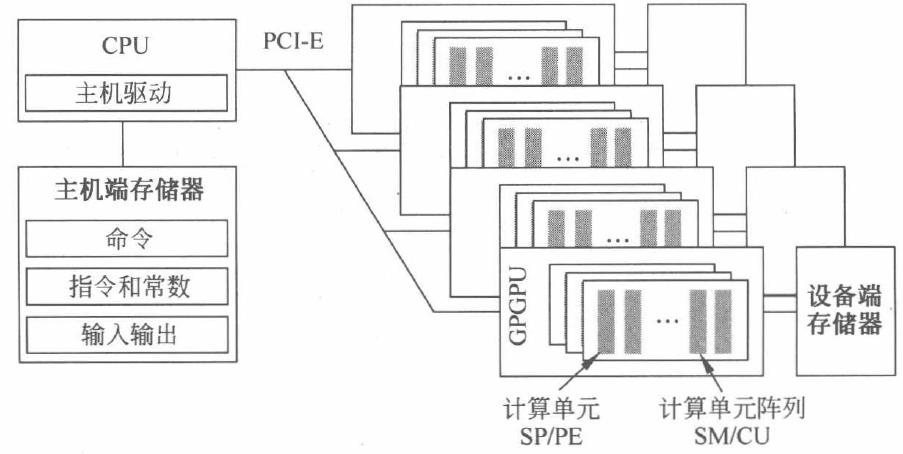
一次 kernel 函数的实现步骤如下:
① CPU 通过 PCI-E 与 GPGPU 进行通信,将程序中的 kernel 函数加载到 GPGPU 中的 SP 和 SM 上执行;
② 在驱动 kernel 函数的进行计算前,需要先将代码、配置和运行数据从硬盘加载到主机端存储器中;
③ 接着,由一系列运行和驱动 API 将数据传送到 GPGPU 的设备端存储器中;
④ 然后,GPGPU 启动 kernel 函数,通过大算力完成计算。
⑤ 最后,CPU 将结果由设备端存储器传送回主机端存储器,等待下一次调用。
以上是一种 CPU-GPGPU 的异构计算架构。还有一种架构是 CPU 和 GPGPU 两者公用主机端存储器,例如 AMD 的异构系统架构(Heterogeneous System Architecture,HSA),它采用硬件支持的统一寻址,使得 CPU 和 GPGPU 能够直接访问主机端存储器,借助 CPU 与 GPGPU 之间的内部总线作为传输通道,通过动态分配系统的物理存储器资源保证了两者的一致性,提高了两者之间数据通信的效率。
另有一种高性能变种是使用多个 GPGPU 并行工作。这种形式需要借助特定的互连结构和协议将多个 GPGPU 有效地组织起来。例如 NVIDIA 的 DGX 系统。它通过 NVIDIA 开发的一种总线及通信协议 NVLink,采用点对点结构、串列传输等技术,实现多 GPGPU 之间的高速互连。
三、GPGPU 架构
不同型号的 GPGPU 产品虽有所差异,但其核心的整体架构存在一定的共性。下图为一个典型的 GPGPU 架构,其核心部分包含了众多可编程多处理器,NVIDIA 称之为流多处理器(Streaming Multiprocesosr,SM),AMD 称之为计算单元(Compute Unit,CU)。每个 SM 又包含了多个流处理器(Streaming Processor,SP),NVIDIA称之为 CUDA 核心,AMD 称之为PE(Processin Element),支持整型、浮点和矩阵运算等多种不同类型的计算。
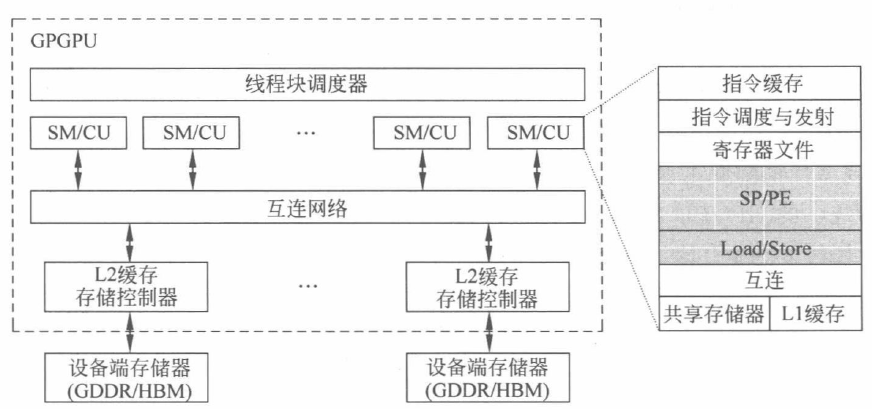
SM 构成了 GPGPU 核心架构的主体。它们从主机接口的命令队列接收 CPU 发送来的任务,并通过一个全局调度器分派到各个可编程多处理器上执行。SM 通过片上的互连结构与多个存储分区相连实现更高并行度的高带宽访存操作。每个存储分区包含了第二级缓存(L2 cache)和对应的 DRAM 分区。此外,SM 中包含了大量的 SP,如上图右侧所示,SP 由指令驱动,以流水化的方式执行指令,提高指令级并行度。
面对数以万计的线程,硬件资源仍然有限,因此硬件会对海量的线程进行分批次的处理。 GPGPU 中往往采用线程束( NVIDIA 称为 warp,AMD 称为 wavefront) 的方式创建、管理、调度和执行一个批次的多个线程。当前,一种典型的配置是一个 warp 包含32个线程, 一个 wavefront 包括64个线程。当这些线程具有相同的指令路径时,GPGPU 就可以获得最高的效率和性能。
四、GPGPU 指令流水线
流水线技术是利用指令级并行,提高处理器 IPC(Instruction Per Cycle)的重要技术之一。不同功能的电路单元组成一条指令处理流水线,利用各个单元同时处理不同指令的不同阶段,可使得多条指令同时在处理器内核中运行,从而提高各单元的利用率和指令的平均执行速度。在大多数 GPGPU 架构中,虽然指令的执行粒度变为包含多个线程的线程束,但为了提高指令级并行,仍然会采用流水线的方式提高线程束指令的并行度,与单指令流水线相比,可以想象成水管变得更粗。
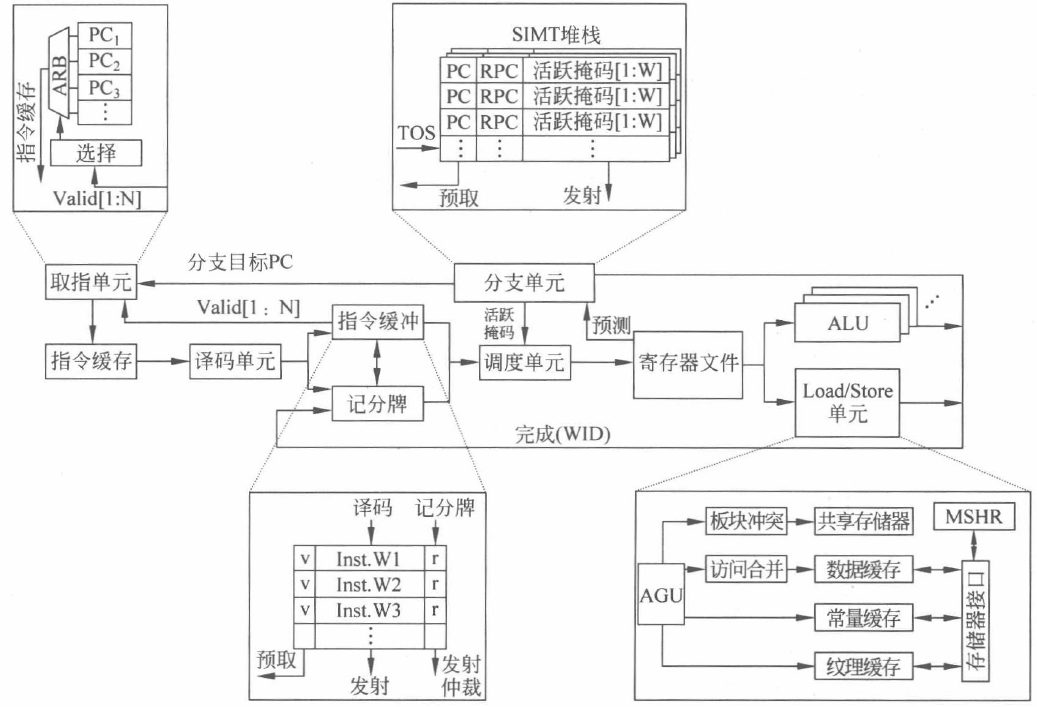
上图显示了一种典型的 GPGPU 架构流水线设计。可以看到,每个线程束按照流水方式执行指令的读取(fetch)、解码(decode)、发射(issue)、执行(execute)及写回(writeback)过程。这一过程与标量流水线非常类似,但不同之处在于 GPGPU 的流水线以线程束为粒度执行,各个线程束相互独立。
接下来将对上图涉及的所有模块进行详解。
4.1 前段:取指与译码
1.取指单元
取指单元是根据程序计数器(Program Counter,PC)的值,从指令缓存中取出要执行指令的硬件单元。取出来的指令经过译码后会保存在指令缓冲中,等待指令后续的调度、发射和执行。
在标量流水线中, 一般只需要一个 PC 来记录下一条指令的地址。但由于 GPGPU 中同时存在多个线程束且每个线程束执行的进度可能并不一致,取指单元中就需要保留多个 PC 值,用于记录每个线程束各自的执行进度和需要读取的下一条指令位置。这个数目应该与可编程多处理器中允许的最大线程束数量相同。
2.指令缓存
指令缓存接收到取指单元的PC, 读取缓存中的指令并发送给译码单元进行解码。指令高速缓存(I-Cache)可以减少直接从设备端存储器中读取指令的次数。本质上指令缓存也是缓存,可以采用传统的组相联结构及 FIFO 或 LRU(Least Recently Used) 等替换策略来进行设计。取指单元对指令缓存的访问也可能会发生不同的情况:如果命中(cache hit),指令会被传送至译码单元;如果缺失(cache miss),会向下一层存储请求缺失的块,等到缺失块回填指令缓存后(refill),访问缺失的线程束指令会再次访问指令缓存。
3.译码单元
译码单元对指令缓存中取出的指令进行解码,并且将解码后的指令放入指令缓冲中对应的空余位置上。根据 SASS 指令集的定义和二进制编码规则,译码单元会判断指令的功能、指令所需的源寄存器、目的寄存器和相应类型的执行单元或存储单元等信息,进而给出控制信号,控制 整个线程束流水线的运行。
4.指令缓冲
指令缓冲用于暂存解码后的指令,等待发射。考虑到每个 SM 中会有许多线程束在执行,指令缓冲可以采用静态划分的方式来为每个线程束提供专门的指令条目,保留已解码待发射的指令。每个指令条目(entry)一般包含一条解码后的指令和两个标记位,即一个有效位(valid)和一个就绪位(ready)。有效位表示该条指令是有效的已解码未发射指令,而就绪位表示该指令已经就绪可以发射。就绪的指令往往需要通过诸如记分牌(scoreboard)的相关性检查等一系列条件,并且需要有空闲的硬件资源才能得以发射。
指令缓冲中的有效位还会反馈给取指单元,表明指令缓冲中是否有空余的指定条目用于取指新的线程束指令。如果有空余条目,应尽快利用取指单元从指令缓存中获得该线程束的后续指令;如果没有空余条目,则需要等待指令缓冲中该线程束的指令被发射出去后, 条目被清空才能进行指令读取。
4.2 中段:调度与发射
指令的调度与发射作为指令流水的中段,连接了前段取指和后段执行部分,对流水线的执行效率有着重要的影响。
1. 调度单元
调度单元通过线程束调度器(warp scheduler)选择指令缓冲中某个线程束的就绪指令发射执行。发射会从寄存器文件中读取源寄存器(source register)传送给执行单元。调度器则很大程度上决定了流水线的执行效率。为了确保指令可以执行,调度单元需要通过各种检查以确保指令就绪并且有空闲执行单元才能发射。这些检查包括没有线程在等待同步栅栏及没有数据相关导致的竞争和冒险等。
2.记分牌
记分牌单元(scoreboard)主要是检查指令之间可能存在的相关性依赖,如写后写(Write-After-Write,WAW)和写后读(Read-After-Write,RAW),以确保流水化的指令仍然可以正确执行。记分牌算法通过标记目标寄存器的写回状态为“未写回”,确保后续读取该寄存器的指令或再次写入该寄存器的指令不会被发射出来。直到前序指令对该目的寄存器的写回操作完成,该目的寄存器才会被允许读取或写入新的数据。
3.分支单元和 SIMT 堆栈
对于指令中存在条件分支的情况,例如if…else…语句,它们会破坏 SIMT 的执行方式。 条件分支会根据线程束内每个线程运行时得到的判断结果,对各个线程的执行进行单独控制,这就需要借助分支单元,主要是活跃掩码(active mask)和 SIMT 堆栈进行管理,解决一个线程束内线程执行不同指令的问题。
4.寄存器文件和操作数收集
指令执行之前会访问寄存器文件(register file)获取源操作数。指令执行完成后还需要写回寄存器文件完成目的寄存器的更新。寄存器文件作为每个可编程多处理器中离执行单元最近的存储层次,需要为该可编程多处理器上所有线程束的线程提供寄存器数值。
出于电路性能、面积和功耗的考虑,寄存器文件会分 Bank 设计,且每个 Bank 只有少量访问端口(如单端口)的设计方式。对不同 bank 的数据同时读取可以在同周期完成,但是不同请求如果在同一 Bank,就会出现Bank Conflict 而影响流水线性能。
4.3 后段:执行与写回
作为指令执行的后段,计算单元是对指令执行具体操作的实现,存储访问单元则完成数据加载及存储操作。
1.计算单元
GPGPU 需要为每个可编程多处理器配备许多相同的流处理器单元来完成一个线程束中多个线程的计算需求,同时还配备了多种不同类型的计算单元,用来支持不同的指令类型,如整型、浮点、特殊函数、矩阵运算等。不同类型的指令从寄存器文件中获得源操作数, 并将各自的结果写回到寄存器文件中。
作为基本的算术需求,GPGPU 中提供了较为完整的算术逻辑类指令,支持通用处理程序的执行。在 NVIDIA 的 GPGPU 架构中,流处理器单元体现为 CUDA 核心,它提供了整型运算能力和单精度浮点运算能力。不同的架构会配备不同数量的双精度浮点硬件单元, 以不同的方式对双精度浮点操作进行支持,以满足高性能科学计算的需求。
2.存储访问单元
存储访问单元负责通用处理程序中 load 和 store 等指令的处理。由于配备了具有字节寻址能力的 load 和 store 等指令,GPGPU 可以执行通用处理程序。
GPGPU 一般会包含多种类型的片上存储空间,如共享存储器、L1 数据缓存、常量缓存和纹理缓存等。存储访问单元实现了对这些存储空间的统一管理, 进而实现对全局存储器的访问。同时针对 GPGPU 的大规模 SIMT 架构特点,存储访问单元还配备了地址生成单元(Address Generation Unit,AGU)、冲突处理(bank conflict)、地址合并、MSHR(Miss Status Handling Registers)等单元来提高存储器访问的带宽并减小开销。当需要访问共享存储器中的数据时,冲突处理单元会处理可能存在的 Bank conflict,并允许在多周期完成数据的读取。对于全局存储器和局部存储器中的数据,load/store 指令会将同一线程束中多个线程产生的请求合并成一个或多个存储块的请求。面对 GPGPU 巨大的线程数量,存储访问单元通过合并单元将零散的请求合并成大块的请求,利用 MSHR 单元支持众多未完成的请求,有效地掩盖了对外部存储器的访问延时,提升了访问的效率。
五、线程分支
在warp执行阶段,如果遇到了if...else...等条件分支指令,GPGPU往往会利用谓词寄存器和SIMT堆栈相结合的方式对发生了条件分支的指令流进行管理。
5.1 谓词寄存器和SIMT堆栈
谓词(predicate)寄存器是为每个执行通道配备的1bit寄存器,用来控制每个通道的开启和关闭(1表示开启,0表示关闭),假设一个线程束中有4个线程,共有7个代码块用A~G表示,每个代码块后面的四个谓词寄存器用来表示在该代码块中线程是否执行,例如代码块D/0110表示:第1个和第4个线程不执行代码块D,第2个和第3个线程执行代码块D。
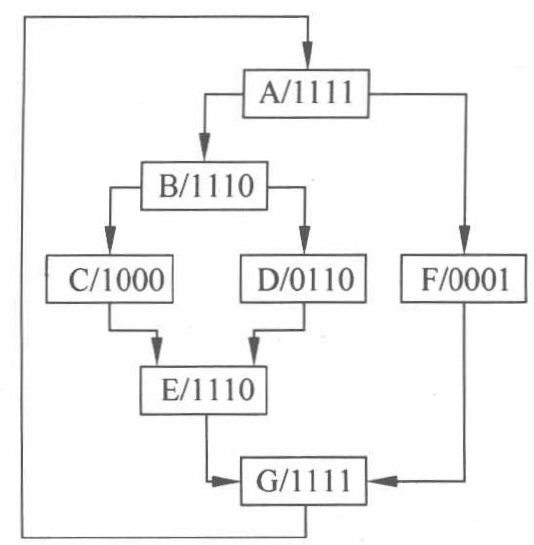
条件分支中,如果两个分支路径长度相等,SIMT 执行效率降为50%,若双重嵌套且分支长度相等,则 SIMT 执行效率降为25%,以此类推,嵌套分支会让执行效率大幅降低。
为了尽可能的维持 SIMT 的执行效率,GPGPU 采用了一种称为SIMT堆栈(Stack)的结构,它可以根据每个线程的谓词寄存器形成线程束的活跃掩码(active mask)信息,帮助调度哪些线程开启或关闭,从而实现分支线程管理。上面举例的D/0110中的“0110”就是活跃掩码,SIMT堆栈本质仍是一个栈,栈内的条目进出以压栈(Push)和出栈(Pop)的方式,栈顶指针(Top-Of-Stack,TOS)始终指向栈最顶端的条目。每个条目包括以下三个字段:
① 分支重聚点的PC(Reconvergence PC,RPC)的值由最早的重聚点指令 PC 确定,因此称为直接后继重聚点(Immediate Post-DOMinate reconvergence point,IPDOM)。上图代码块 B 执行完毕后,三个线程经由两条分支路径 C 和 D 在 E 处重聚,我们就称 E(确切来说,是代码块 E 的第一条指令)为一个 IPDOM ;
② 下一条需要被执行指令的 PC(Next PC,NPC),为该分支内需要执行的指令PC;
③ 线程活跃掩码(active mask)。
以前面的流程图为例,随时间周期的推进,分支线程的执行顺序如下图(a)所示,实心箭头表示被唤醒的线程,空心箭头表示未唤醒的线程。
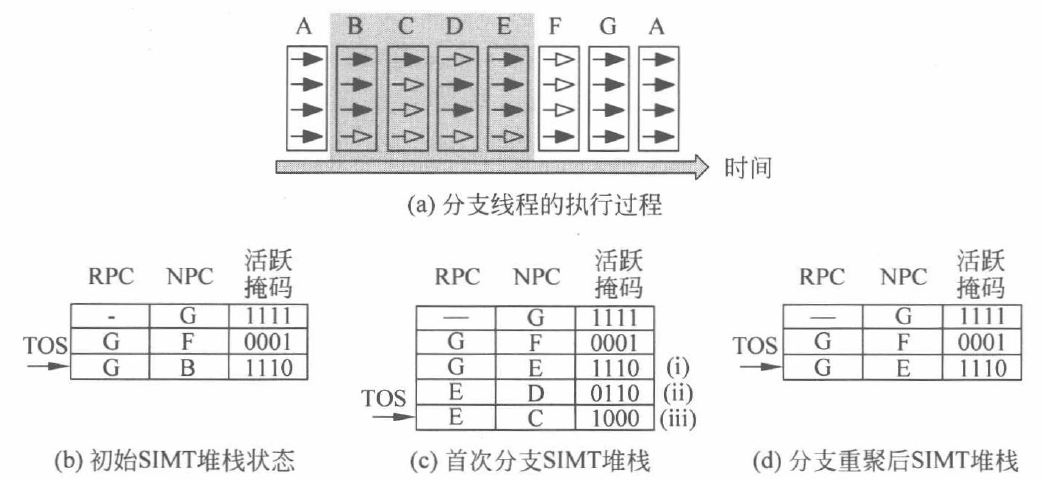
初始状态如上图(b)所示,所有线程执行 A 指令块,NPC 为 G 的第一条指令 PC,即所有后面线程的重聚点,当到 A 指令块的最后一条指令时,会发生分支,分为两个互补的执行路径,则当前 NPC 转为 RPC,指令块 F 和 B 的活跃掩码被压入栈,其 RPC 均为 G。当前线程束需要执行的指令将由 TOS 条目的 NPC 获得。弹出指令块B的第一条指令,由其活跃掩码控制线程执行,B对应的 NPC 为 E 压栈,如上图(c)(i)所示,当执行到B的最后一条指令,再次发生分支,更新RPC,将C,D及活跃掩码压入栈如上图(c)(ii)和(iii)所示。 继续执行指令块 C,当执行到指令块 C 的最后一条指令,其NPC与RPC值相同,为指令块E,所以 SIMT 会将 C 弹栈,同样 D 也一样步骤,故 SIMT 更新为上图(d)的状态。
但是SIMT堆栈结构可能造成死锁,主要是因为算法中使用了锁定(Lock)机制来进行数据交换,如下图所示:

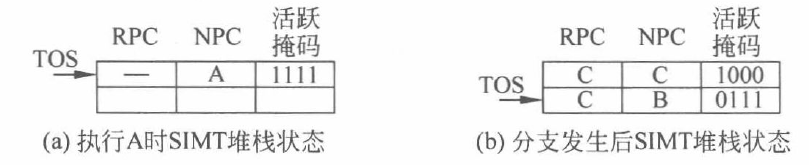
Step1:在 Block A 时,线程束中所有线程执行 Block A,从而将共享变量*mutex 初始设为0。
Step2:在 Block B 时,atomicCAS()是原子操作,只允许一个线程进行,故线程束中的1个线程进行atomicCAS()操作,锁定*mutex 共享变量,操作会读取*mutex 的值并和0进行比较,如果两者相等,那么*mutex 的值将和第三个参数1进行交换。其他线程此时需要等待锁释放。
Step3:然后通过 atomicExch 原子交换将 mutex 赋值为0
问题出在step2,因为SIMT stack的调度原则是首先执行活跃数线程最多的分支,假设有32个线程,先执行了含有31个线程的分支,这31个线程会一直卡在while()循环,而剩下的拿着锁的1个线程此时活跃掩码处于inactive状态导致死锁,如下图所示:
5.2 分支屏障和Yield指令
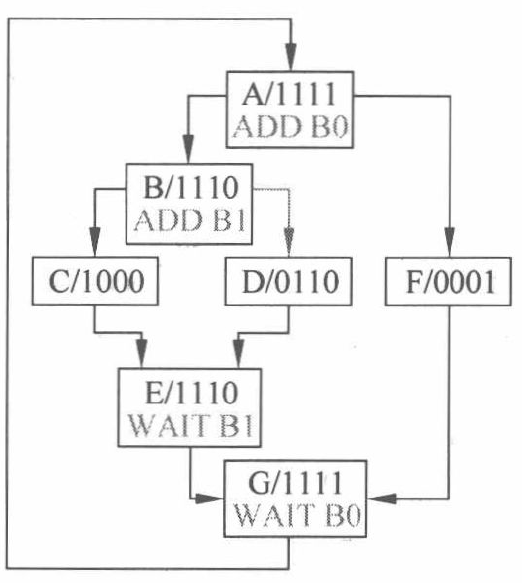
对此,可以使用分支屏障和 Yield 指令来解决死锁问题。 分支屏障是指:设计了增加屏障(ADD)和等待屏障(WAIT)指令如下图所示;针对 SIMT 堆栈死锁设计了 Yield 指令,使某些线程进入让步状态(可通过显示插入 Yield 指令或者设置超时跳转机制实现)。
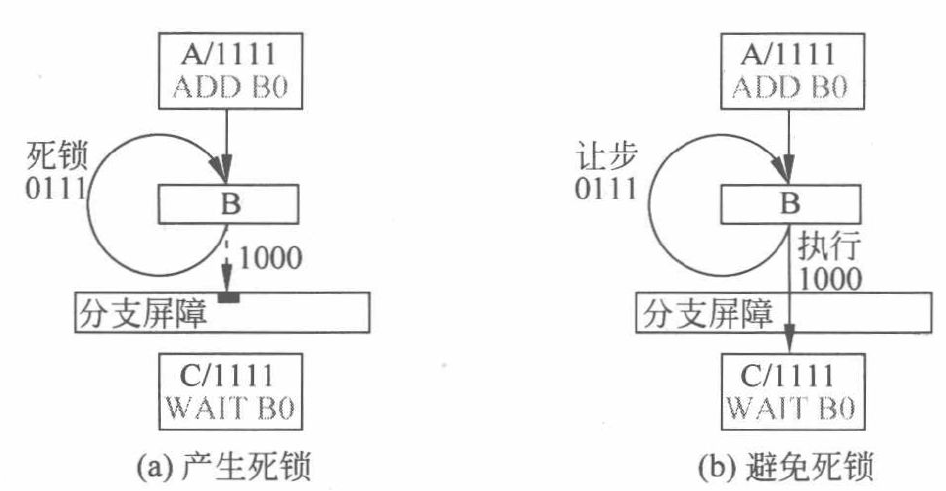
结合Yield指令避免死锁的示意图如下所示:
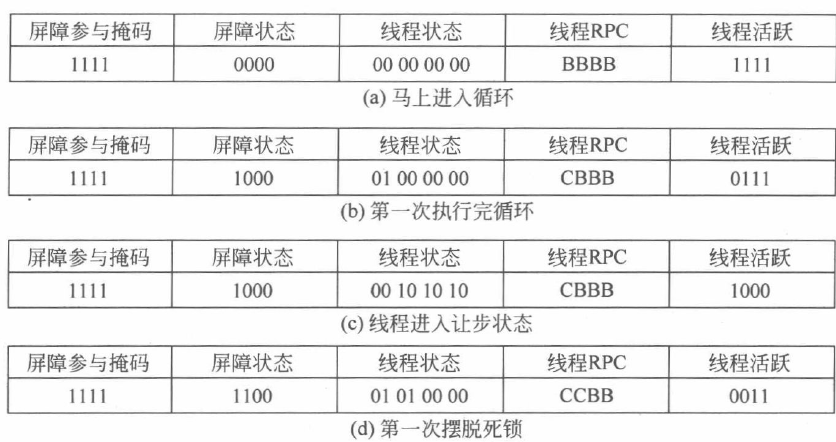
由于4个线程都会参与屏障,因此图7中的屏障参与掩码是不变的。而屏障状态为4比特,每一位代表一个线程,若线程已经执行到了屏障,则对应位置标为1,否则为0。线程状态有3个,其中00为就绪状态,01为挂起状态,10为让步状态。线程 RPC 为接下来要执行的指令,每个线程对应一个 RPC。
线程执行完第一次循环得到(b)状态,其中一个线程可以开始执行C指令块,即到达了屏障,而其他线程继续循环。假设为第一个线程到达了屏障,其RPC改为C,并进入挂起状态(01),其他线程等待执行B中的指令。根据超时规则,线程执行Yield指令,其余三个线程进入让步状态(10)以防止死锁,之后第一个线程从挂起状态(01)进入就绪状态(00),无需等待其他三个线程便可直接穿过屏障执行C的指令。第一个线程执行了C指令块故可以释放一个线程进入屏障,第一次摆脱死锁进入(d)的状态,之后重复(c)和(d)步骤走出死锁。
5.3 更高效的线程分支执行方案:
(1) 寻找更早的分支重聚点,从而尽早让分叉的线程重新回到 SIMT 执行状态,减少线程在分叉状态下存续的时间。实际上,前面提到的直接后继重聚点(IPDOM) 是一种直观的重聚点位置。它以两条分支路径再次合并的位置作为重聚点,符合对称分支代码的结构,但在多样的分支代码结构下未必是最优的重聚点选择方案。
(2) 积极地实施分支线程的动态重组和合并,这样即便线程仍然处在分叉状态,能够让更多分叉的线程一起执行来提高 SIMT 硬件的利用率。例如,将不同分支路径但相同的指令进行重组合并就可以改善分支程序的执行效率。
