
阅读量:0
Web Speech API 使你能够将语音数据合并到 Web 应用程序中。Web Speech API 有两个部分:SpeechSynthesis 语音合成(文本到语音 TTS)和 SpeechRecognition 语音识别(异步语音识别)。
SpeechRecognition
语音识别通过
SpeechRecognition (en-US)接口进行访问,它提供了识别从音频输入(通常是设备默认的语音识别服务)中识别语音情景的能力。一般来说,你将使用该接口的构造函数来构造一个新的SpeechRecognition (en-US)对象,该对象包含了一系列有效的对象处理函数来检测识别设备麦克风中的语音输入。SpeechGrammar接口则表示了你应用中想要识别的特定文法。文法则通过 JSpeech Grammar Format (JSGF.) 来定义。
语音识别api
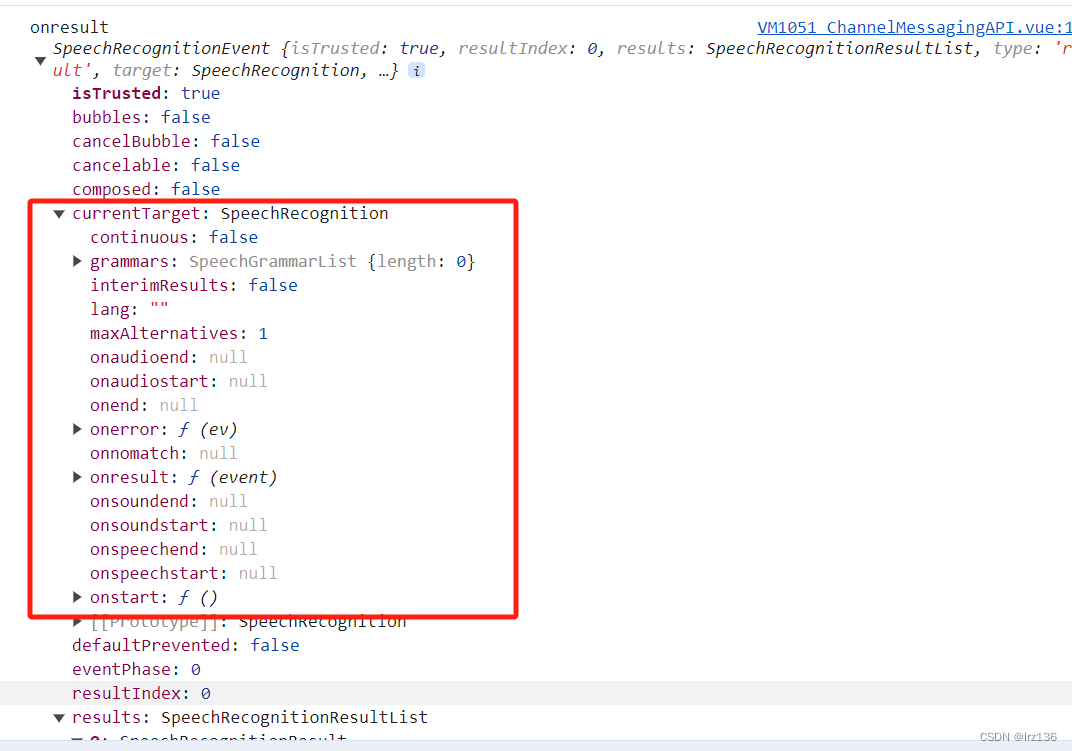
语音识别服务的控制器接口;它也处理由语音识别服务发来的 SpeechRecognitionEvent (en-US) 事件。
创建SpeechRecognition的新实例
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition // 语音识别 var recognition = new SpeechRecognition()设置是持续听还是听到声音之后就关闭接收。
recognition.continuous = true;设置是否允许临时结果,临时结果是识别的中间过程,这时候返回结果的isFinal = false。
recognition.interimResults = true;设置语言
recognition.lang = 'cmn-Hans-CN'; //普通话 (中国大陆)控制语音识别的开启和停止,可使用start()和stop()方法,分别对应onstart、onend事件
// 开始语音识别监听,开始接收和处理语音输入 recognition.start(); // 停止语音识别监听,不再接收和处理语音输入 recognition.stop(); // 将当前的语音识别操作中止,并且不触发任何结果事件 recognition.abort();对识别到的结果进行处理,可以使用一些事件方法,比方说onresult:
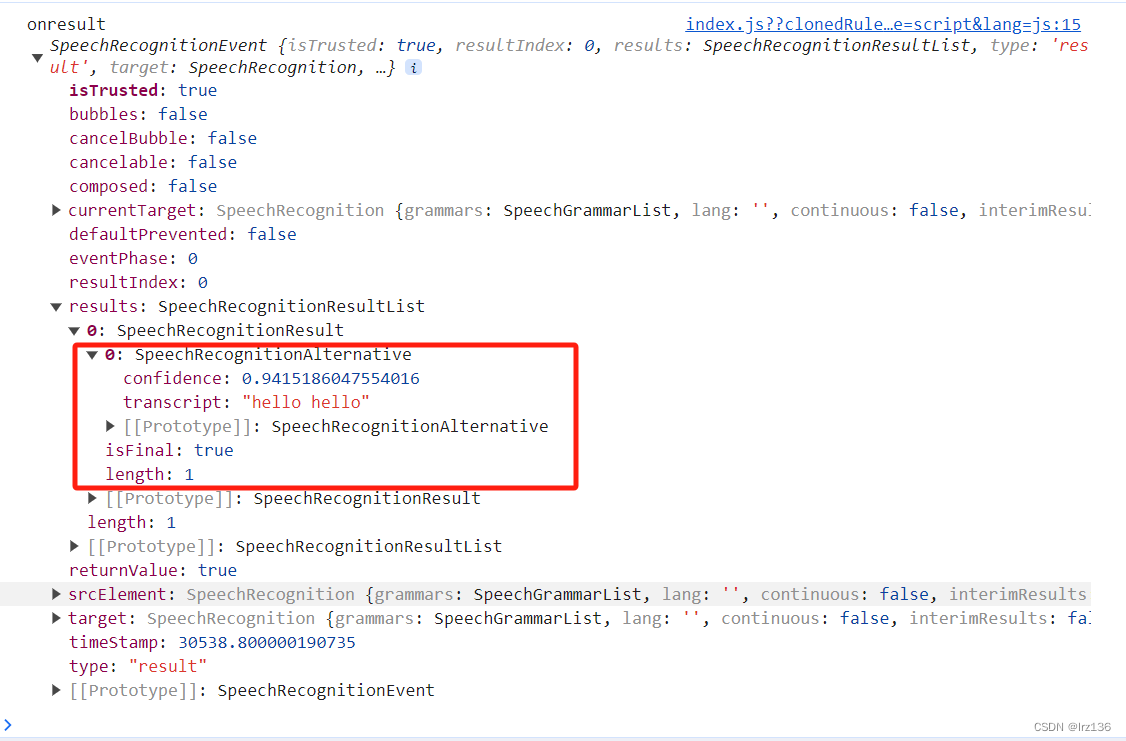
recognition.onresult = function(event) { console.log(event); // event返回结果格式 /* { results: { 0: { 0: { confidence: 0.695017397403717, transcript: "你好,世界" }, isFinal:true, length:1 }, length:1 }, } */ }错误处理
recognition.onerror = function(event) { console.log(event); }以下是SpeechRecognition对象的一些常见事件说明:
audioend:当音频输入结束时触发,表示不再接收音频数据。
audiostart:在开始处理音频数据之前触发,表示开始接收音频输入。
end:当SpeechRecognition实例停止监听后触发。
error:在处理期间发生错误时触发。
nomatch:在没有找到匹配的语音输入时触发。
result:在获取到语音输入结果时触发,可以通过event.results获取识别结果。
soundend:在声音输入结束时触发。
soundstart:在开始处理声音输入时触发。
speechend:当语音输入结束时触发。
speechstart:在开始处理语音输入时触发。
start:当SpeechRecognition实例开始监听时触发。
SpeechRecognitionAlternative (en-US)
表示由语音识别服务识别出的一个词汇。
recognition.onresult = function(event) { // SpeechRecognitionEventresults 属性返回一个 SpeechRecognitiontionResultList 对象 // SpeechRecognitionResultList 对象包含了多个 SpeechRecognitionResultResult 对象。 // 它具有 getter,因此可以像数组一样进行访问 // 第一个 [0] 返回位置 0 处的 SpeechRecognitionResult。 // 每个 SpeechRecognitionResult 对象都包含具有单独结果的 SpeechRecognitionAlternative 对象。 // 它们也有 getter ,因此可以像数组一样对其进行访问。 // 第二个 [0] 返回位置 0 处的 SpeechRecognitionAlternative。 // 然后,我们返回 SpeechRecognitionAlternative 对象的 transcript 属性 var color = event.results[0][0].transcript; diagnostic.textContent = '收到结果:' + color + '。'; bg.style.backgroundColor = color; }我们将要交由语音识别服务进行识别的词汇或者词汇的模式。
var grammar ="#JSGF V1.0; grammar colors; public <color> = aqua | azure | beige | bisque | black | blue | brown | chocolate | coral | crimson | cyan | fuchsia | ghostwhite | gold | goldenrod | gray | green | indigo | ivory | khaki | lavender | lime | linen | magenta | maroon | moccasin | navy | olive | orange | orchid | peru | pink | plum | purple | red | salmon | sienna | silver | snow | tan | teal | thistle | tomato | turquoise | violet | white | yellow ;"; var recognition = new SpeechRecognition(); var speechRecognitionList = new SpeechGrammarList(); speechRecognitionList.addFromString(grammar, 1); recognition.grammars = speechRecognitionList;表示一个由 SpeechGrammar 对象构成的列表。
SpeechRecognitionResult (en-US)
表示一次识别中的匹配项,其中可能包含多个 SpeechRecognitionAlternative (en-US) 对象。
SpeechRecognitionResultList (en-US)
表示包含 SpeechRecognitionResult (en-US) 对象的一个列表,如果是以 continuous (en-US) 模式捕获的结果,则是单个对象。
安全性
http协议下浏览器每次都会提醒用户去确认语音操作,然而https的页面,没有这样一个麻烦的操作。
JavaScript上下文,整个页面,都能过访问到捕获的音频。
