
阅读量:2
在数据时代,企业拥有前所未有的大量数据资产,但如何从海量数据中发掘价值成为挑战。数据分析凭借强大的分析能力,可从不同维度挖掘数据中蕴含的见解和规律,为企业战略决策提供依据。数据分析在营销、风险管控、产品优化等领域发挥着关键作用,帮助企业提高运营效率、优化业务流程、发现新商机、增强竞争力。低成本高效率的完成对海量数据的分析,及时准确的释放数据价值,已成为企业赢得竞争优势的利器。StarRocks on AWS 为这个课题交出了一份答卷。
StarRocks 作为新一代极速全场景 MPP(Massively Parallel Processing)数据库,架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO(Cost Based Optimizer)优化器,实现亚秒级的查询速度,尤其是多表关联查询表现尤为突出。StarRocks 还支持现代化物化视图,进一步加速查询。
StarRocks 不仅能很好地支持实时数据分析,实现对实时更新数据的高效查询,3.0 及以后版本的存算分离架构,对于数据湖中的数据也能够实现极速查询,配合 AWS 提供的高性能高可用的云平台,能够极大地助力客户轻松构建数据湖仓。
越来越多的客户正在尝试湖仓一体的探索,后续我们会推出系列博客介绍如何在 AWS 上构建您的数据湖仓,而存算分离的 StarRocks 会是其中非常重要的一部分,我们也会结合实际客户案例分享 StarRocks on AWS 的最佳实践以及实际业务效果,本文则重点介绍 StarRocks on AWS Graviton3 上实现的超高性价比提升。
关于AWS Graviton
AWS Graviton 是 AWS 推出的基于 ARM 架构的自研处理器,专为优化云计算性能和成本效益而设计。Graviton3 相较于前代产品 Graviton2 有了显著的性能提升,其单线程性能提高了 25%,整体性能提升了 50%。
Graviton3 支持 DDR5 内存,提供更高的内存带宽和更低的延迟,使其在处理大规模数据分析、高性能计算(HPC)和内存密集型应用方面表现尤为出色。
在机器学习工作负载方面,Graviton3 的性能提升更为显著,可以达到高达 3 倍的加速,这得益于其增强的矩阵乘法指令集。
Graviton3 处理器集成了先进的硬件安全功能,包括内置的内存加密和更高效的加密算法支持,确保数据在传输和存储过程中的安全性,满足敏感数据处理的需求。
Graviton3 具有更高的能效,能够在相同的性能下减少能耗,这对于希望降低运营成本和碳足迹的企业来说尤为重要。
通过使用基于 Graviton3 的实例,如 Amazon EC2 C7g 和 R7g,用户可以在保持高性能的同时显著降低计算成本。
最近几年来,在 AWS 上部署和使用 StarRocks 的客户越来越多,AWS 和 StarRocks 致力于为客户提供更加极速和高性价比的服务体验。截至 2024 年 6 月,StarRocks 已经基于 AWS Graviton3 做了大量优化,详见下文测试报告。从最新实测数据来看,相对于 C6i,在 C7g 上已经实现了平均 30% 的性能提升。
测试方法以及结论
由于 Graviton3 基于ARM 的指令集尤其是 SIMD 指令集跟 x86 不同,需要做额外的适配工作。之前已经做了大部分的 SIMD 适配工作,本次测试,是 StarRocks 基于近期完成的适配了一些热点 SIMD 指令优化,然后做出的基于 TPC-DS 100GB 和 1TB 规模的测试。
参与本次对比测试的节点选型:
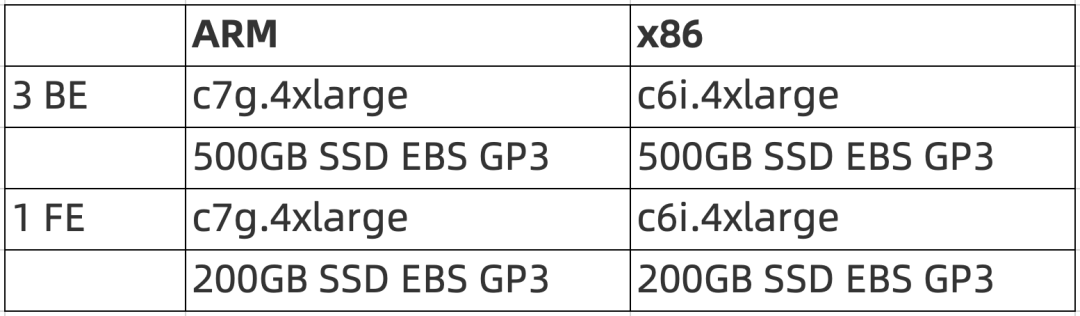
实例具体配置:
c7g.4xlarge
价格:根据 AWS 官网定价, 按需的价格为 0.5781 USD/hour
CPU:ARM AWS Graviton
16 vCPUs, 32GB Memory, 15 Gbps Network Bandwidth
CPU 频率:6GHz
CPU cache:
SQL Caches (sum of all): L1d: 1 MiB (16 instances) L1i: 1 MiB (16 instances) L2: 16 MiB (16 instances) L3: 32 MiB (1 instance) 2.6GHZ2.6GHZ
c6i.4xlarge
价格:根据 AWS 官网定价, 按需的价格为 0.68 USD/hour
CPU:x86
16 vCPUs, 32GB Memory, 12.5 Gbps Network Bandwidth
CPU 频率:9GHz
CPU cache:
SQL Caches (sum of all): L1d: 384 KiB (8 instances) L1i: 256 KiB (8 instances) L2: 10 MiB (8 instances) L3: 54 MiB (1 instance)集群版本:
StarRocks:StarRocks version 3.3 StarRocks version 3.3 | StarRocks
具体的测试方法和代码这里不再展开,有兴趣的读者可以参考: StarRocks TPC-DS Benchmark | TPC-H Homepage
详细测试结果
在标准 TPC-H 测试集 100G 和 1T 规模下,相比于 C6i 机型,C7g 机型基本没有出现性能回退的 case,并且平均性能提升达到 30%,再结合 C7g 机型 15% 的价格优化,综合起来,可以实现 53% 的性价比提升。
说明:
以上每个测试集的数据都是对测试集内 99 个 query 的延时求和。
C6i
在 C6i 机型上的测试结果。
C7g
优化 bitshuffle 使用的指令 #44607。
优化 CRC 使用的 NEON 指令 #44607。
优化 filter_range 使用的 NEON 指令 #44194。
C6i/C7g: 任务跑在 C6i 上的耗时是 C7g 的几倍
简单来说,比值越高,说明优化效果越明显。
另外,这里给出在 OLAP 典型应用场景中的优化情况: Scan & Bitshuffle / Aggregate / HashJoin
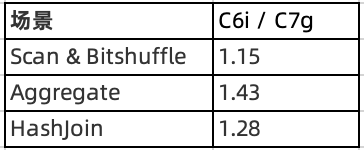
由上表可知, 在 OLAP 常见的场景中,优化指令集之后的,性能均有 15% 以上的提升,尤其是在 Aggregate 场景下,达到了 43% 的性能提升。
总结
基于 StarRocks 当前的优化情况和最新的测试数据来看,StarRocks on Graviton3 (C7g) 的总体性能比 Ice Lake 8375C (C6i) 实现了30%以上的综合性能提升。再结合 AWS Graviton3 自身的价格优势(C7g 相对于C6i 有 15% 的成本优化),StarRocks on C7g 相对于 C6i 可以实现 50% 以上的性价比提升。
如果您有计划在 AWS 上部署您的 StarRocks 服务,或者您已经运行 StarRocks on AWS,Graviton3 都将会给您带来更优的体验和更低的成本。
另外,还有很多客户在密切关注最新的 AWS Graviton4。Graviton4 与当前一代 Graviton3 处理器相比,性能提升高达 30%,独立核心增加 50% 以上,内存带宽提升 75% 以上,为在 Amazon EC2 上运行的工作负载提供最佳性能和能效,这让我们非常兴奋,近日 Graviton4 在 global region 正式 GA,我们会需要一些时间做定向优化和测试,所以建议大家现阶段可以优先使用 StarRocks on AWS Graviton3。
附录:
有关 C++ 针对 ARM NEON 指令集的优化,您可以参考这个 Github 链接:aws-graviton-getting-started/SIMD_and_vectorization.md at main · aws/aws-graviton-getting-started · GitHub
有关 SIMD 优化思路,您可以参考这个链接:SIMD | OLAP 数据库性能优化指南
测试环境中 FE 以及 BE 中配置参数调整如下:
fe.conf --- catalog_trash_expire_second be.conf --- max_compaction_concurrency=0 trash_file_expire_time_sec=0性价比提升计算方式:
如果 A 相对于 B,性能提升 30%,价格降低 15%,那么总体性价比的提升有多少?
性能:A= 1.3B
价格:A= 0.85B
如果以 B 的性价比为 1,则 A 的性价比 = 1.3B / 0.85B = 1.53
本篇作者
刘子赫:StarRocks 查询团队核心研发 & StarRocks Committer。
Angela Ren:亚马逊云科技解决方案架构师,负责基于亚马逊云科技云计算方案架构的咨询和设计,推广亚马逊云科技云平台技术和各种解决方案。
Li Jing:亚马逊云科技解决方案架构师,负责亚马逊云科技云计算方案咨询和设计。目前主要专注在现代化应用改造和机器学习领域的技术研究和实践。曾就职于 F5,甲骨文,摩托罗拉等多家 IT 公司,有丰富的实践经验。
更多交流,联系我们:https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/8da64
