
阅读量:1
文章目录
一、介绍
1.1 xml 介绍
XML(eXtensible Markup Language,可扩展标记语言)是一种标记语言,主要用于存储和传输数据。它定义了数据的结构和语义,但不定义数据的呈现方式。XML 是一种自描述的语言,易于理解和使用。以下是 XML 的一些关键特点:
- 可扩展性:用户可以定义自己的标签,使其适应不同的需求。
- 自描述性:标签本身描述了数据的内容和结构。
- 简洁性:与HTML相比,XML标签更简洁,减少了冗余。
- 可读性:标签清晰,易于人类阅读和理解。
- 跨平台:可以在任何操作系统上使用,与平台无关。
- 数据交换:广泛用于不同系统之间的数据交换。
1.2 xml 标准
- XML 1.0:1998年2月首次发布,是XML的基础版本。
- XML 1.0 第二版:2000年10月发布,包含了一些修正和澄清。
- XML 1.1:2001年2月发布,旨在解决XML 1.0中的一些问题,特别是字符编码和特殊字符的处理。
- XML 1.1 第二版:2006年4月发布,包含了对XML 1.1的一些小的修正和改进。(改进了字符编码处理,支持更多的 Unicode 字符)
要查看 XML 的历史规范和标准,可以访问以下资源:
W3C 官方网站:
- https://www.w3.org/TR/
- 这是查看 XML 规范和其他 Web 标准的主要资源。
XML 1.0 规范:
XML 1.1 规范:
W3C XML 活动页面:
- https://www.w3.org/XML/
- 提供了关于 XML 技术的最新信息和资源。
互联网档案馆:
- https://archive.org/
- 有时可以找到早期的规范文档和历史版本。
通过这些资源,你可以获取 XML 的详细规范、历史版本和相关的技术文档。这有助于了解 XML 的发展历史和当前标准。
1.3 xml 教程
- XML 简介
- https://www.runoob.com/
- https://www.w3school.com.cn/xml/index.asp
- https://www.cnblogs.com/antLaddie/p/14823874.html
- DOM 和 SAX

1.4 xml 构成
XML(Extensible Markup Language,可扩展标记语言)文档由以下基本构成要素组成:
XML声明 (
<?xml version="1.0" encoding="UTF-8"?>): 可选的,位于文档最开始,用来指定XML版本和字符编码等信息。元素 (Elements): XML文档的基本构建块,有开始标签(如
<item>)和结束标签(如</item>),元素可以包含文本、其他元素或者属性。属性 (Attributes): 元素可以有属性,用来提供额外信息。属性在元素的开始标签内定义(如
<item id="123">),属性值必须加引号。文本 (Text): 元素内部的字符数据,可以是文本或者实体引用。
注释 (Comments): 以
<!--开始,-->结束,用于添加文档的注释信息,它们在XML文档中会被忽略。处理指令 (Processing Instructions): 以
<?开始,?>结束,用于提供处理器指令(如XML声明),通常用于指定文档相关的配置信息。文档类型声明 (Document Type Declaration, DTD): 以
<!DOCTYPE开始,用来定义文档的结构和元素的合法性规则,可以包含元素和属性的声明。CDATA区 (Character Data): 以
<![CDATA[开始,]]>结束,用来包含不应被XML解析器解析的文本。实体 (Entities): 可以是字符引用(如
<表示<)或实体引用(如©表示版权符号),用于表示特殊或不可见的字符。命名空间 (Namespaces): 用于区分相同名称的不同元素和属性,避免命名冲突。
属性列表 (Attribute List): 某些元素可以有一系列的属性,这些属性提供了关于元素的附加信息。
一个简单的XML文档示例如下:
<?xml version="1.0" encoding="UTF-8"?> <catalog> <book id="bk101"> <author>Gambardella, Matthew</author> <title>XML Developer's Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <!-- More book elements can go here --> </catalog> 在这个示例中,catalog 是根元素,book 是子元素,每个 book 元素有多个子元素如 author、title 等,以及一个 id 属性。
二、C/C++ xml 库选型
2.1 选型范围
- 资料
- 开源库
- RapidXML、cereal-RapidXML:仅DOM方式、速度快、v1.3 2009
- pugixml:仅DOM方式、速度快、支持XPath1.0查询、C++、好集成、v10.0.0 2023-10-31
- libxml:
- libxml2:C
- libxml++:C++
- tinyxml2:C++、好集成、API简单
- 结论
- 性能:RapidXML 和 PugiXML 在解析大型XML文件时表现优异。 (时间和空间)
- 易用性:TinyXML2 和 PugiXML 的API设计简洁直观,易于学习和使用。
- 功能全面性:libxml2 和 libxml++ 提供了最全面的功能,包括XML验证、XPath查询和XSLT转换-
- 选择哪个库取决于你的具体需求,例如是否需要XPath支持、是否需要处理大型文件、是否需要C++绑定等。根据这些因素,你可以决定最适合你项目的XML库。

2.2 RapidXML
- 注意:cereal 序列化库选用RapidXML和RapidJSON,可见其性能强劲。
- 官网: https://rapidxml.sourceforge.net/
- 最新版本和更新时间:v1.3 2009/05/13 01:46:17
- 官网手册: https://rapidxml.sourceforge.net/manual.html
- 第三方源码:https://github.com/Fe-Bell/RapidXML
- c++开源库rapidxml介绍与示例
- rapidxml 文件读写,增加删除节点
2.3 tinyxml2
- https://github.com/leethomason/tinyxml2
- 最新版本和更新时间:v10.0.0 2023-10-31
- C++那些事之优雅的解析XML
- TinyXML2使用教程
- tinyxml2使用方法
- C++ XML 库 TinyXML2 的基本使用
使用方式:
- 源码集成:仅 tinyxml2.h 和 tinyxml2.cpp 两个文件
- 库集成:tinyxml2.h 和 静/动态库
2.4 pugixml
- Pugixml一种快速解析XML文件的开源解析库
- 官网:https://pugixml.org/
- 源码:https://github.com/zeux/pugixml
- 当前最新版本和更新时间:v1.14_2023-10-02
- C/C++编程:pugixml
- https://www.cnblogs.com/Gale-Tech/p/16089326.html
- https://blog.csdn.net/FL1768317420/article/details/136385775
2.5 libxml++
libxml2:
五、性能比较
5.1 C++ xml 相关的操作有哪些
在 C++ 中,XML 相关的操作可以通过多种库来实现,这些操作包括但不限于:
解析(Parsing):
- 将 XML 字符串或文件解析为一个可操作的内部结构,通常是 DOM(Document Object Model)。
序列化(Serialization):
- 将 DOM 或其他内存中的结构转换回 XML 格式的字符串或写入文件。
查询(Querying):
- 使用 XPath 表达式在 XML 文档中查找特定的元素或属性。
修改(Modifying):
- 编辑 XML 文档的内容,包括添加、删除或更改元素和属性。
创建(Creating):
- 从头开始构建 XML 文档,添加元素和属性。
验证(Validating):
- 检查 XML 文档是否符合某个模式(如 DTD 或 XML Schema)。
遍历(Traversal):
- 通过 DOM 遍历 XML 文档的节点。
操作属性(Manipulating Attributes):
- 获取和设置 XML 元素的属性。
处理命名空间(Handling Namespaces):
- 管理 XML 文档中的命名空间。
事件驱动解析(Event-driven Parsing):
- 使用 SAX(Simple API for XML)风格的接口进行事件驱动的解析。
转换(Transformation):
- 使用 XSLT(eXtensible Stylesheet Language Transformations)转换 XML 文档。
生成(Generation):
- 动态生成 XML 数据,例如作为 API 响应。
在 C++ 中,一些流行的 XML 处理库包括:
- TinyXML and TinyXML-2:轻量级的 XML 解析库,提供基本的解析和序列化功能,但不直接支持 XPath。
- RapidXML:一个快速的、不使用异常的 DOM 解析器,同样不提供 XPath 支持。
- libxml2:一个功能全面的 XML 库,支持 DOM、SAX、XPath 和 XSLT。
- PugiXML:一个轻量级的、简单易用的 XML 解析库,支持 XPath 查询。
- Xerces-C++:一个基于 Apache Xerces 的 XML 解析库,支持 DOM、SAX 和 XPath。
使用这些库,开发者可以执行上述的 XML 操作,以满足不同的开发需求。选择哪个库取决于项目的具体需求、性能考虑以及个人偏好。
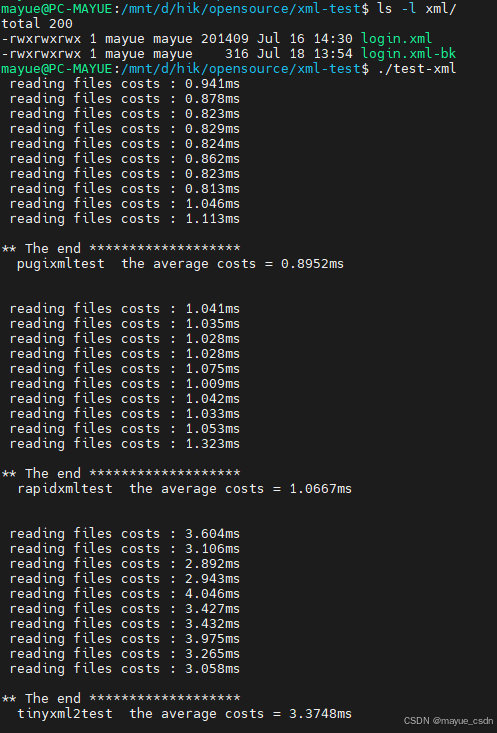
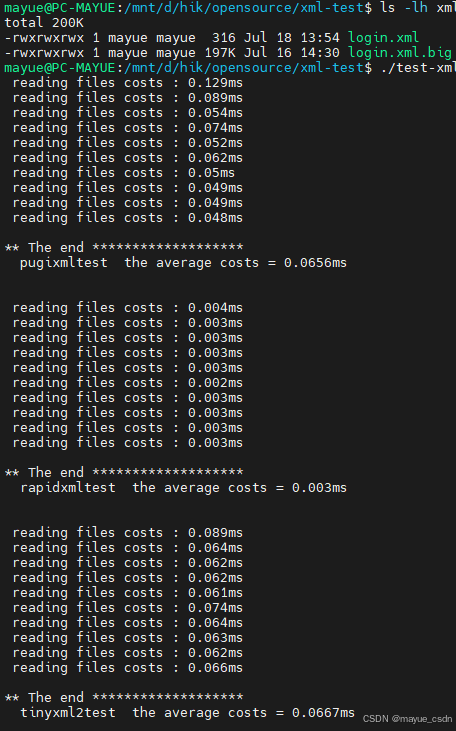
5.2 rapidxml、Pugixml、TinyXML2 文件读取性能比较
- 测试: 读文件
- 结论:
- 小文件:rapidxml 速度 >> Pugixml ≈ TinyXML2
- 大文件:Pugixml > rapidxml > TinyXML2
// g++ -o test-xml main.cpp pugixml-1.14/pugixml.cpp tinyxml2-10.0.0/tinyxml2.cpp #include <iostream> #include "pugixml-1.14/pugixml.hpp" #include "pugixml-1.14/pugiconfig.hpp" #include <sys/time.h> #include "rapidxml-1.13/rapidxml.hpp" #include "rapidxml-1.13/rapidxml_print.hpp" #include "rapidxml-1.13/rapidxml_utils.hpp" #include "tinyxml2-10.0.0/tinyxml2.h" using namespace std; #define TEST_TIMES 10 int pugixmltestmain( void ) { pugi::xml_document doc; timeval starttime, endtime; double timeuse = 0.; double timeAverage = 0.; for( int i = 0; i < TEST_TIMES; ++i ) { gettimeofday( &starttime, 0 ); if( !doc.load_file( "xml/login.xml" ) ) { cout << "failed in load xml file! _ " << i << endl; continue; } gettimeofday( &endtime, 0 ); timeuse = 1000000. * (endtime.tv_sec - starttime.tv_sec) + endtime.tv_usec - starttime.tv_usec; timeuse *= 0.001 ; cout << " reading files costs : " << timeuse << "ms" << endl; timeAverage += timeuse; } timeAverage /= TEST_TIMES; cout << " \n** The end *******************\n pugixmltest the average costs = " << timeAverage << "ms\r\n\r\n" << endl; return 0; } using namespace rapidxml; using std::cout; using std::endl; int rapidxmltestmain() { timeval starttime, endtime; double timeuse = 0.; double timeAverage = 0.; //< parse xml for( int i = 0 ; i < TEST_TIMES; ++i ) { rapidxml::file<> filename( "xml/login.xml" ); xml_document<> doc; gettimeofday( &starttime, 0 ); doc.parse<0>( filename.data() ); gettimeofday( &endtime, 0 ); timeuse = 1000000. * (endtime.tv_sec - starttime.tv_sec) + endtime.tv_usec - starttime.tv_usec; timeuse *= 0.001 ; cout << " reading files costs : " << timeuse << "ms" << endl; doc.clear(); timeAverage += timeuse; } timeAverage /= TEST_TIMES; cout << " \n** The end *******************\n rapidxmltest the average costs = " << timeAverage << "ms\r\n\r\n" << endl; return 0; } using namespace tinyxml2; int tinyxml2testmain( void ) { XMLDocument doc; // doc.LoadFile( "resources/dream.xml" ); // doc.ErrorID(); timeval starttime, endtime; double timeuse = 0.; double timeAverage = 0.; for( int i = 0; i < TEST_TIMES; ++i ) { gettimeofday( &starttime, 0 ); if( XML_SUCCESS != doc.LoadFile( "xml/login.xml" ) ) { cout << "failed in load xml file! _ " << i << endl; continue; } gettimeofday( &endtime, 0 ); timeuse = 1000000. * (endtime.tv_sec - starttime.tv_sec) + endtime.tv_usec - starttime.tv_usec; timeuse *= 0.001 ; cout << " reading files costs : " << timeuse << "ms" << endl; timeAverage += timeuse; } timeAverage /= TEST_TIMES; cout << " \n** The end *******************\n tinyxml2test the average costs = " << timeAverage << "ms\r\n\r\n" << endl; return 0; } int main() { pugixmltestmain(); rapidxmltestmain(); tinyxml2testmain(); } 如果没有xml文件 就在测试目录增加一个xml目录,里面创建login.xml
Xml内容如下
<?xml version="1.0"?> <Request> <PK_Type> <Name>LOGIN</Name> </PK_Type> <Info> <UserName>admin</UserName> <PassWord>21232f297a57a5a743894a0e4a801fc3</PassWord> <FSUID>26201907030003</FSUID> <FSUIP>172.16.88.192</FSUIP> <FSUMAC>00-0c-29-de-4c-58</FSUMAC> <FSUVER>1.0.01</FSUVER> </Info> </Request> - 测试大文件:197KB
- 测试小文件:1KB
六、其他问题
6.1 version和 encoding的取值范围
<?xml version="1.0" encoding="ISO-8859-1"?>其中version和 encoding的取值范围在哪可以查<?xml version="1.0" encoding="ISO-8859-1"?> 是 XML 文档的声明,位于文档的最前面。这个声明用于告诉解析器有关 XML 文档的版本和编码信息。
version属性指定了 XML 文档使用的 XML 版本,目前最常见的是 “1.0”。W3C 定义的 XML 1.0 标准有两个版本:1.0 和 1.1。因此,version属性的取值范围通常为 “1.0” 或 “1.1”。encoding属性指定了 XML 文档使用的字符编码。XML 允许使用多种字符编码,包括但不限于:UTF-8UTF-16ISO-8859-1(Latin-1 Western European)ISO-8859-2(Latin-2 Central European)ISO-8859-3(Latin-3 South European)ISO-8859-4(Latin-4 North European)ISO-8859-5(Latin/Cyrillic)ISO-8859-6(Latin/Arabic)ISO-8859-7(Latin/Greek)ISO-8859-8(Latin/Hebrew)ISO-8859-9(Latin-5 Turkish)- 等等
要查找 version 和 encoding 的取值范围,可以查阅以下资源:
XML 1.0 标准:定义了 XML 的基本语法和行为,包括版本信息。可以在 W3C 的官方网站上找到:XML 1.0 Specification。
XML 1.1 标准:在 XML 1.0 的基础上做了一些扩展,包括对更多字符编码的支持。可以在 W3C 的官方网站上找到:XML 1.1 Specification。
字符编码标准:如 IANA(Internet Assigned Numbers Authority)Character Sets 列出了多种字符编码。
W3C 的 Encoding 标准:提供了关于 Web 文档字符编码的详细信息,包括如何在 HTTP 头部和 HTML 中指定编码:Character Encoding for HTML & XML。
通过这些资源,您可以找到所有有效的 XML 版本和编码选项,以及它们的使用方式和限制。
