
阅读量:3
定义
欠拟合 (Underfitting):
- 定义:模型在训练数据和测试数据上都表现不佳。这表明模型没有很好地捕捉数据中的趋势。
- 现象:训练集和测试集准确率都很低。
- 原因:模型过于简单,参数过少,无法捕捉数据的复杂关系。
过拟合 (Overfitting):
- 定义:模型在训练数据上表现非常好,但在测试数据上表现不佳。这表明模型捕捉到了训练数据中的噪声和细节,而不是数据的整体趋势。
- 现象:训练集准确率高,测试集准确率低。
- 原因:模型过于复杂,参数过多,导致对训练数据的过度拟合。
图形表达——以线性回归为例
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split # 设置随机数种子 np.random.seed(666) # 解决中文显示问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 生成数据 x = np.random.uniform(-3, 3, size=100) X = x.reshape(-1, 1) y = 0.5 * x**2 + x + np.random.normal(0, 1, size=100) # 绘制原始数据 plt.figure(figsize=(12, 8)) plt.scatter(X, y, label='原始数据', color='blue') # 模拟欠拟合:线性回归 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=5) linear = LinearRegression() linear.fit(X_train, y_train) y_predict = linear.predict(X_test) plt.plot(x, linear.predict(X), color='red', label='线性回归 (欠拟合)') print(f"线性回归训练集均方误差: {mean_squared_error(y_train, linear.predict(X_train)):.4f}") print(f"线性回归测试集均方误差: {mean_squared_error(y_test, y_predict):.4f}") # 模拟合适拟合:二次回归 X2 = np.hstack([X, X**2]) X_train, X_test, y_train, y_test = train_test_split(X2, y, random_state=5) linear.fit(X_train, y_train) y_predict2 = linear.predict(X_test) plt.plot(np.sort(x), linear.predict(X2)[np.argsort(x)], color='green', label='二次回归 (合适拟合)') print(f"二次回归训练集均方误差: {mean_squared_error(y_train, linear.predict(X_train)):.4f}") print(f"二次回归测试集均方误差: {mean_squared_error(y_test, y_predict2):.4f}") # 模拟过拟合:高次多项式回归 X10 = np.hstack([X2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10]) X_train, X_test, y_train, y_test = train_test_split(X10, y, random_state=5) linear.fit(X_train, y_train) y_predict3 = linear.predict(X_test) plt.plot(np.sort(x), linear.predict(X10)[np.argsort(x)], color='orange', label='高次多项式回归 (过拟合)') print(f"高次多项式回归训练集均方误差: {mean_squared_error(y_train, linear.predict(X_train)):.4f}") print(f"高次多项式回归测试集均方误差: {mean_squared_error(y_test, y_predict3):.4f}") # 添加图例和标签 plt.xlabel('x 值', fontsize=14) plt.ylabel('y 值', fontsize=14) plt.title('欠拟合、合适拟合和过拟合示例', fontsize=16) plt.legend(fontsize=12) plt.grid(True) # 显示图形 plt.show() 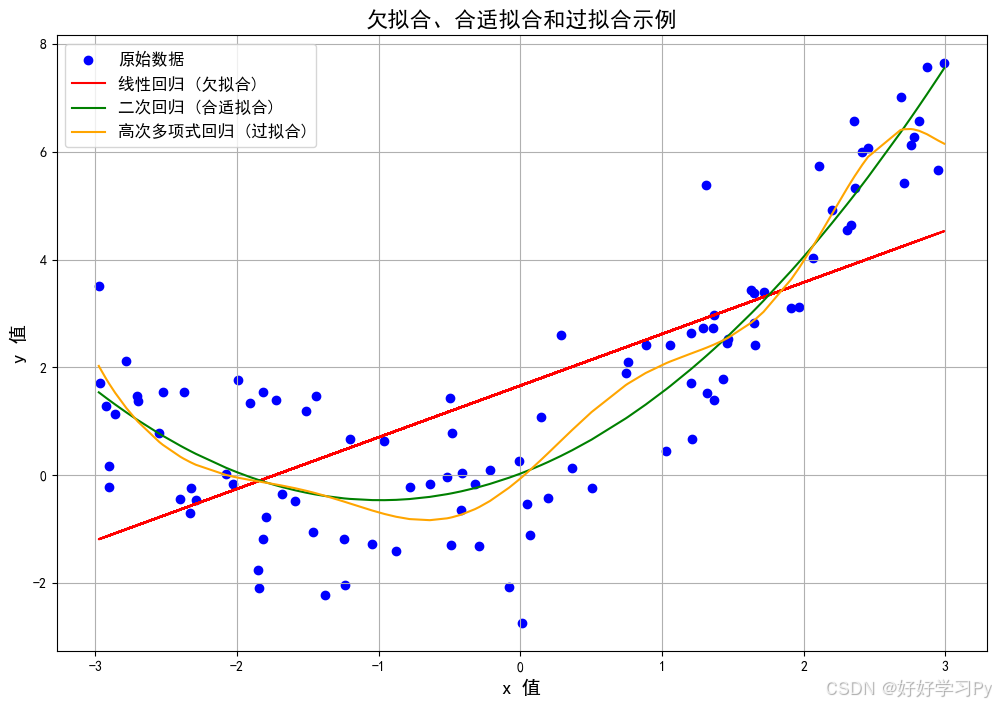
一次回归训练集均方误差: 3.0496
一次回归测试集均方误差: 3.1531
二次回归训练集均方误差: 1.0951
二次回归测试集均方误差: 1.1119
高次多项式回归训练集均方误差: 0.9992
高次多项式回归测试集均方误差: 1.4146
测试集和训练集上 的均方误差随着模型复杂度提高而减小,拟合效果越好,但在很多高次项加入时出现了过拟合。
