
阅读量:6
Apache Flink概述
Apache Flink 是开源的分布式引擎,用于对无界限(流)和有界限(批处理)数据集进行有状态处理。
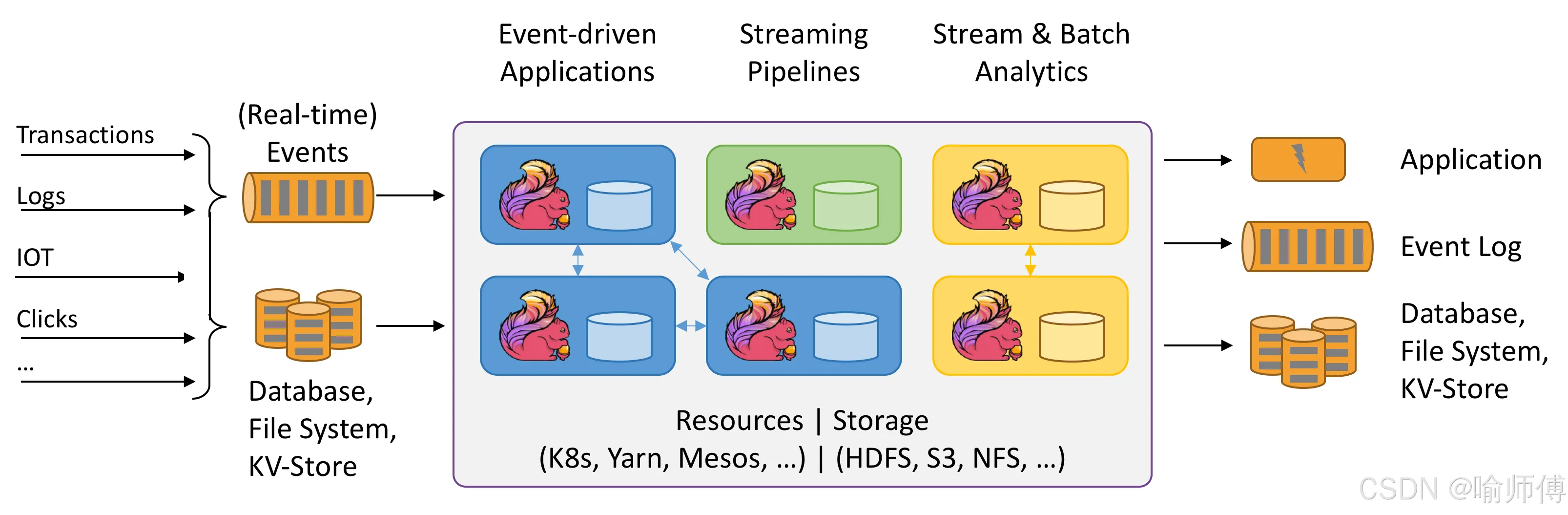
流处理应用程序旨在连续运行,最大限度地减少停机时间,并在摄取数据期间对其进行处理。
Apache Flink 专为低延迟处理、在内存中执行计算、实现高可用性、消除单点故障以及水平扩展而设计。
Apache Flink 的功能包括具有严格一次一致性保证的高级状态管理,以及具有复杂乱序处理和延迟数据处理的事件时间处理语义。
Apache Flink 专为流式传输优先而开发,为流处理和批处理提供了统一的编程接口。
Apache Filnk 四大核心
Apache Flink 构建在四个核心基石之上,它们分别是流处理、时间、状态和快照。

1. 流处理(Streaming)
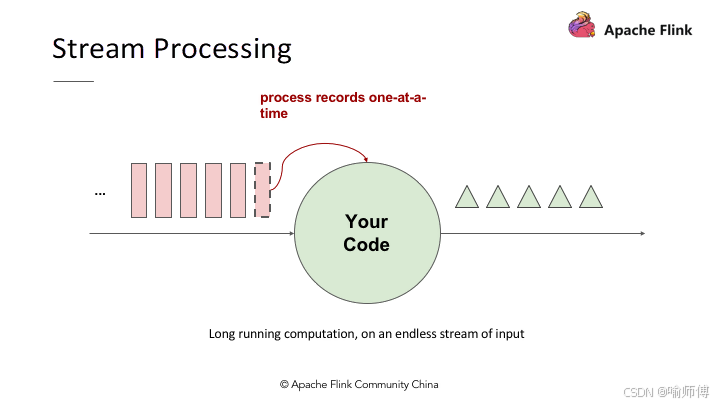
- 流处理是 Apache Flink 最基础、最核心的能力之一。它指的是对无限数据流的实时处理和分析能力。
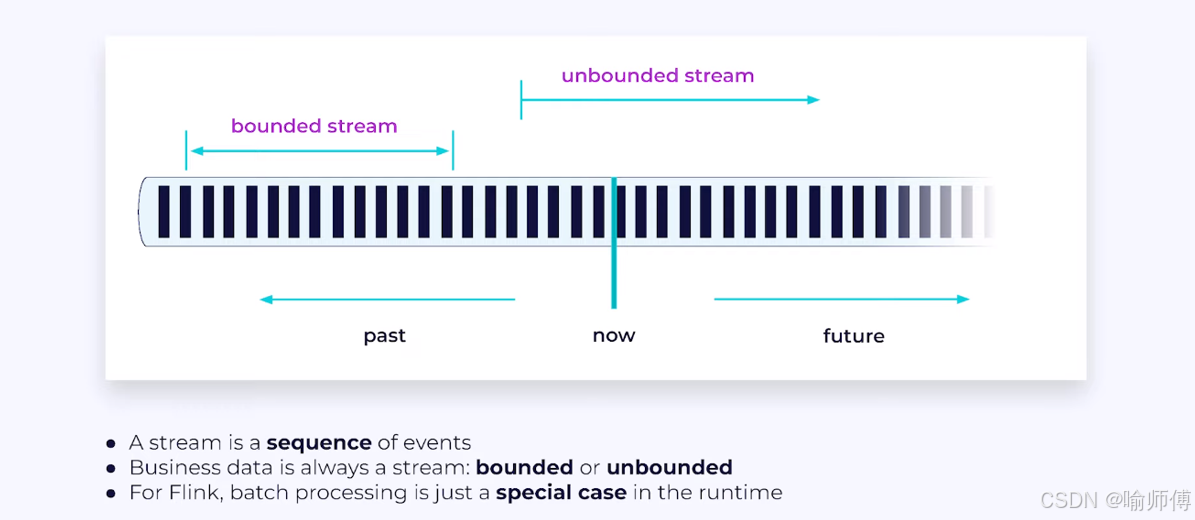
- 与批处理不同,流处理系统能够在数据到达时立即处理它们,而不需要等待整个数据集就绪。
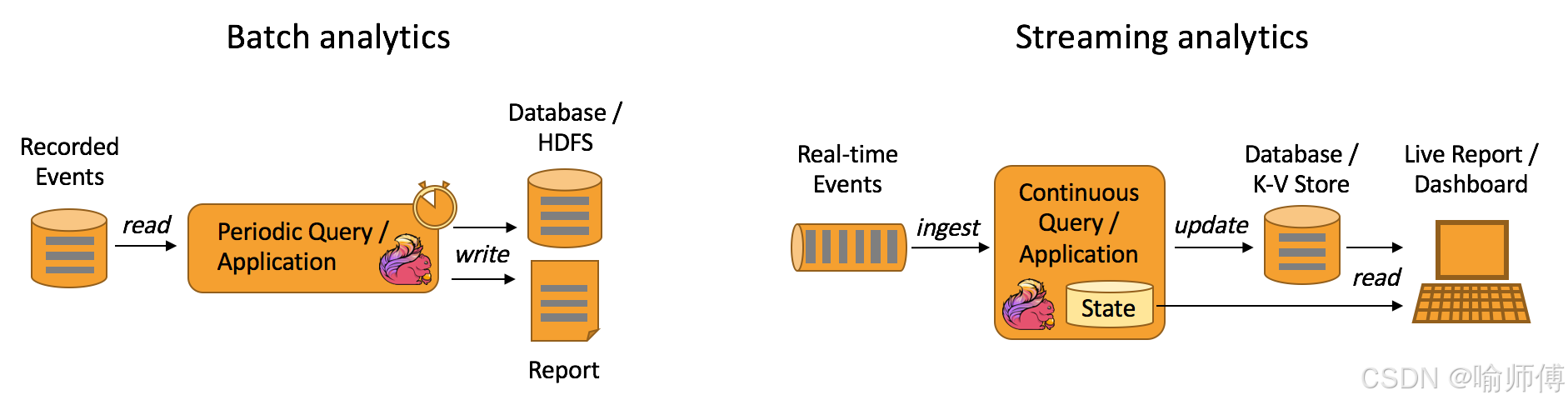
- 这种实时处理能力使得 Flink 特别适合处理需要低延迟和实时反馈的应用场景。
(1) 事件驱动处理:
Flink 是基于事件驱动的处理模型。它能够按照事件发生的顺序处理数据,而不是依赖于固定的批次大小或固定的时间间隔。
这种特性使得 Flink 能够处理高度动态的数据流,并根据实际的数据到达情况进行即时响应。
传统应用程序架构和事件驱动应用程序区别:
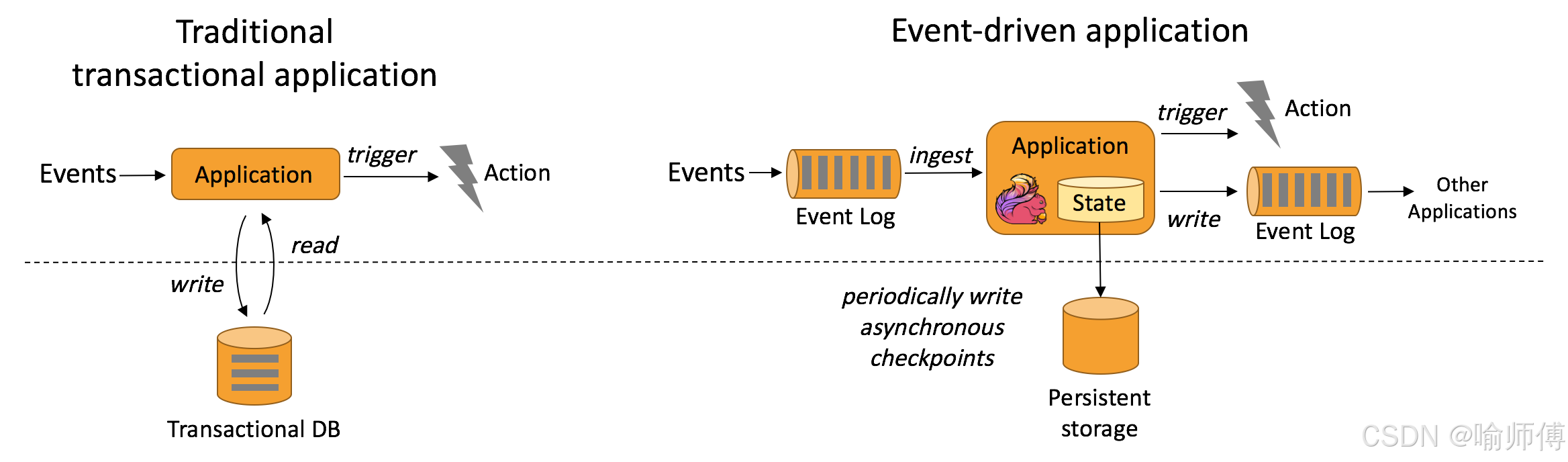
事件驱动应用基于事件或消息的传递来触发和处理操作。这种应用架构不依赖于同步的请求-响应模式,而是通过异步处理事件来实现。
异步处理: 应用程序不需要等待请求的即时响应,而是在事件发生时立即触发相应的处理逻辑。
松耦合: 组件之间的通信通过事件传递,这使得系统更加灵活和可扩展。
实时性和响应性: 事件驱动应用常用于需要实时处理和快速响应的场景,如实时数据分析、IoT系统等。
传统事务型应用通常遵循请求-响应模式,客户端发起请求,服务器处理请求并返回响应。
同步处理: 操作按照顺序执行,每个操作完成后才会进行下一个操作。
事务性操作: 应用使用事务来确保数据的原子性、一致性、隔离性和持久性(ACID属性)。
(2)窗口操作:
Flink 提供了丰富的窗口操作支持,允许用户根据时间、数量或者其他自定义的条件对数据流进行切分和聚合。
常见的窗口类型包括滚动窗口(
Tumbling Windows)、滑动窗口(Sliding Windows)、会话窗口(Session Windows)等,每种窗口类型都适用于不同的应用场景和数据处理需求。
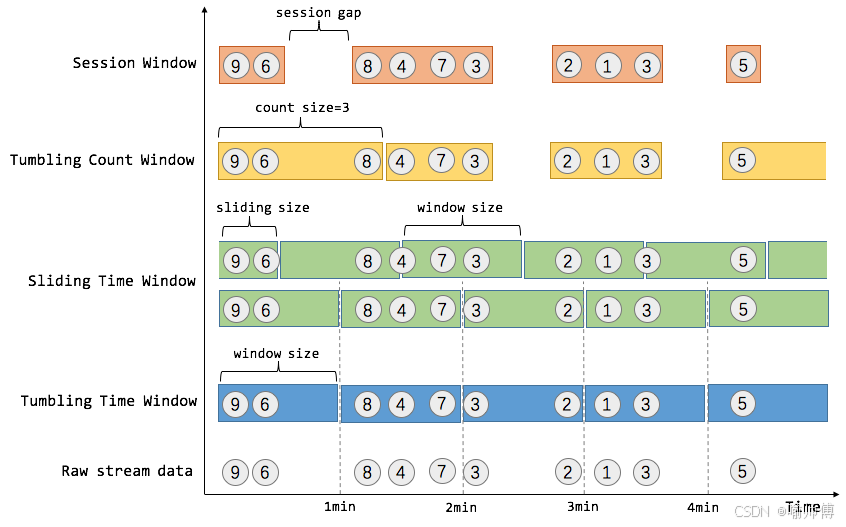
- Time Window 是根据时间对数据流进行分组的:
- 翻滚时间窗口(
Tumbling Time Window)。翻滚窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。eg.统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进行切分。 - 滑动时间窗口(
Sliding Time Window),在滑窗中,一个元素可以对应多个窗口。eg.每30秒计算一次最近一分钟用户购买的商品总数。 - Count Window 是根据元素个数对数据流进行分组的:
- 翻滚计数窗口(
Tumbling Count Window),eg.每当窗口中填满100个元素了,就会对窗口进行计算。
这里就先介绍这几种,后面博主会再详细介绍一下窗口机制~
(3) 事件时间和水印:
- 事件时间是 Flink 中一个重要的概念,它允许根据数据流中的实际事件时间来进行数据处理和窗口计算,而不是基于处理数据的系统时间。
- 水印(
Watermark)是一种机制,用于处理乱序事件数据,帮助 Flink 在事件时间处理中实现准确性和完整性。
这里先了解一下,后面博主会再详细介绍~
(4)状态管理:
- 流处理通常涉及到处理有状态的数据,例如需要跟踪某个时间窗口内的累计值或者连接操作的中间状态。
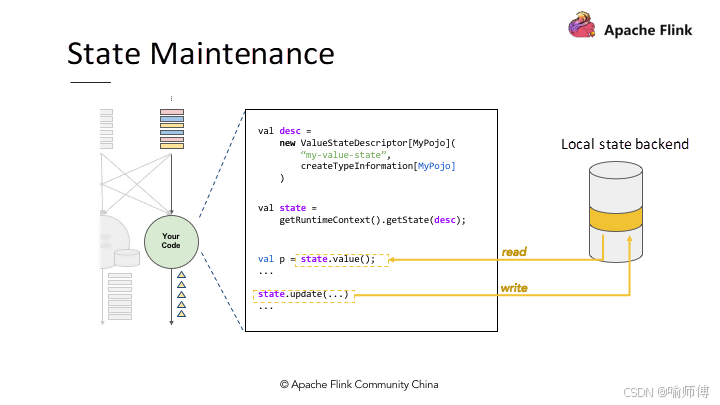
- Flink 提供了强大的状态管理机制,允许开发者在流处理任务中维护和操作状态。
- 这些状态可以持久化到分布式存储中,以确保在发生故障时能够恢复状态并继续处理数据。
(5) Exactly-Once 语义:
Flink 支持 Exactly-Once 语义,这意味着每条数据都能够精确地被处理一次,不会丢失也不会重复处理。
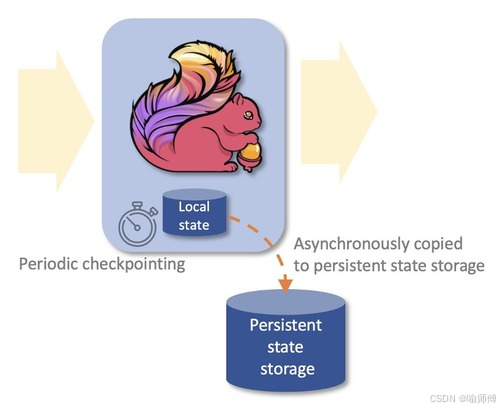
这种保证是通过事务性检查点(Transactional Checkpoints)和状态快照(State Snapshots)来实现的,确保了数据处理的准确性和一致性。
(6)分布式流处理:
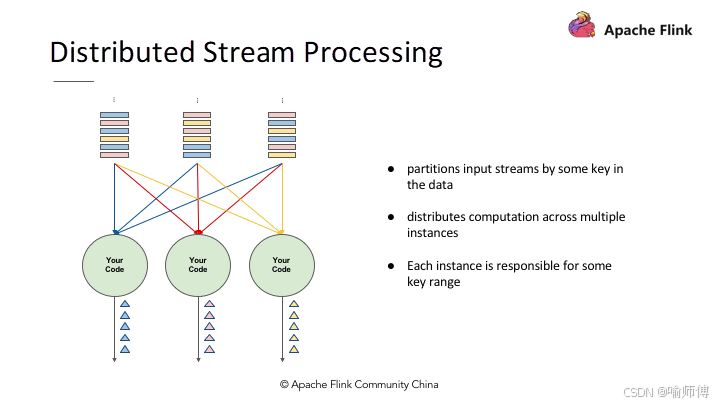
2. 时间(Time)
- 在 Apache Flink 中,时间是一个重要的概念,特别是在处理实时数据流时。
- Flink 引入了事件时间(
Event Time)、处理时间(Processing Time)和摄取时间(Ingestion Time)的概念,用于管理和处理事件数据的时间属性。
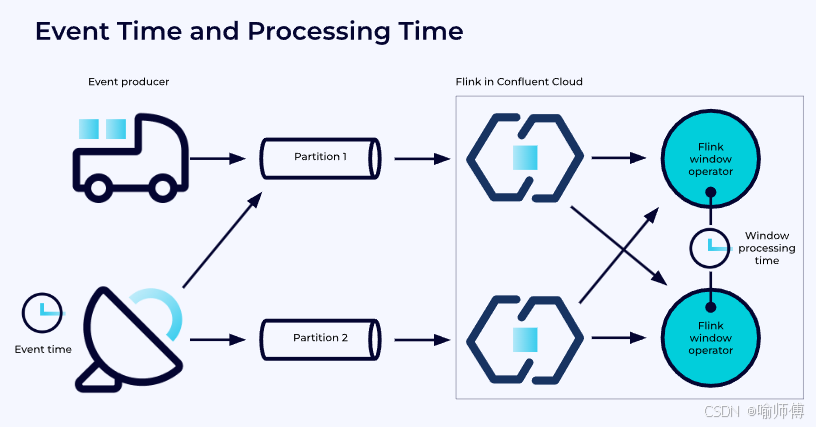
- 事件时间允许基于事件发生的实际时间来进行数据处理,而处理时间则是基于处理数据的机器的系统时间,而摄取时间则是基于接收数据的系统时间。
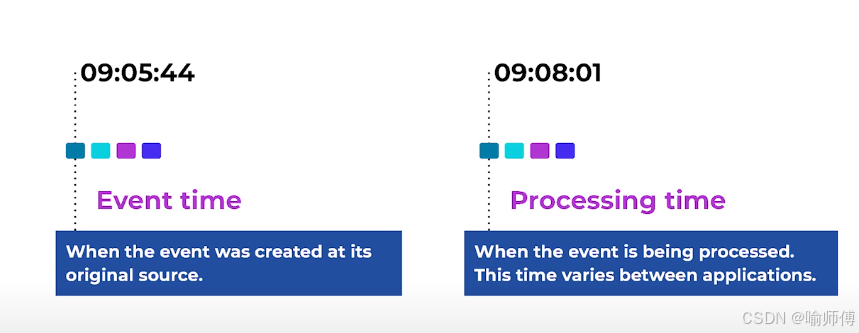
- Flink 的时间概念使得开发者能够精确控制和处理数据的时间特性,从而确保数据处理的准确性和一致性。
3. 状态(State)
- 状态在流处理中是一种持久化存储数据的能力,用于保存和管理处理过程中的中间结果或者关键信息。
- Apache Flink 提供了强大的状态管理机制,允许用户在流处理任务中维护和操作状态。
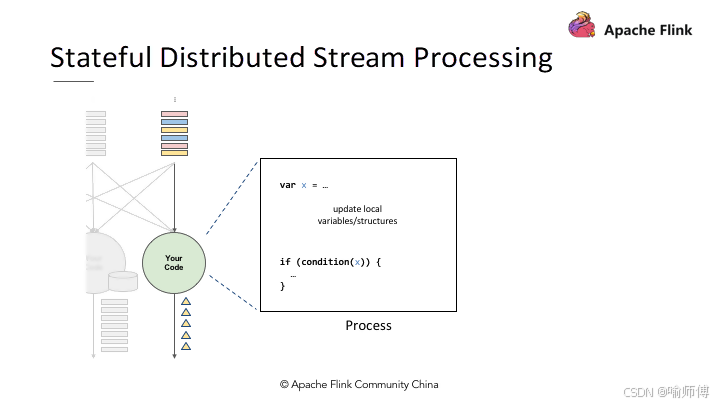
这些状态可以是简单的计数器,也可以是复杂的数据结构,比如聚合结果、窗口信息等。
状态的有效管理使得 Flink 能够处理有状态的数据流应用,例如实时数据的聚合、连接、分析等操作。
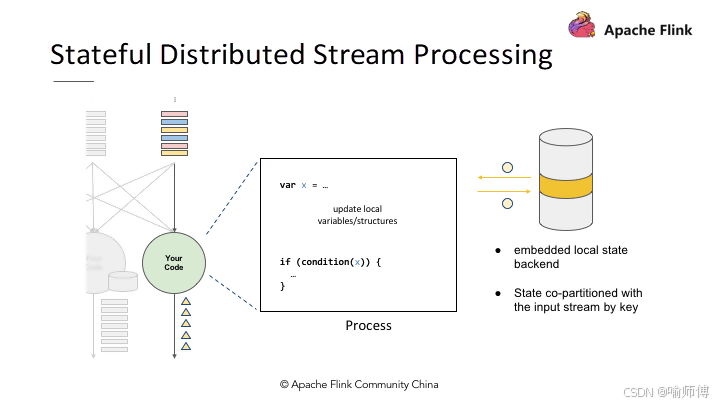
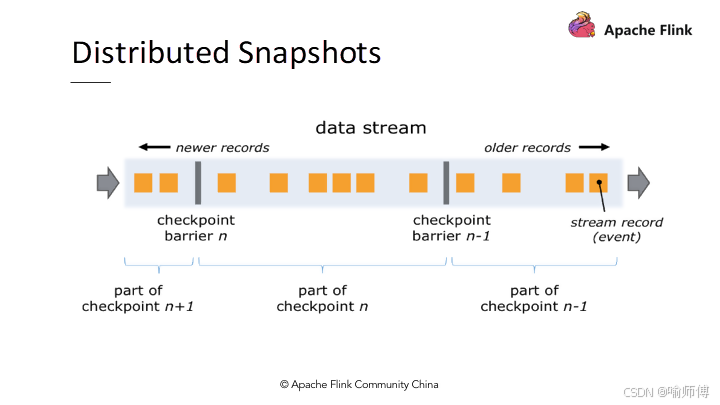
4. 快照(Snapshots)
快照是指 Apache Flink 在流处理过程中周期性地创建的分布式状态的一致性备份。
快照捕获了当前流处理任务的所有状态信息,包括中间结果、窗口状态等,并保存在持久化存储中(通常是分布式文件系统或者数据库)。
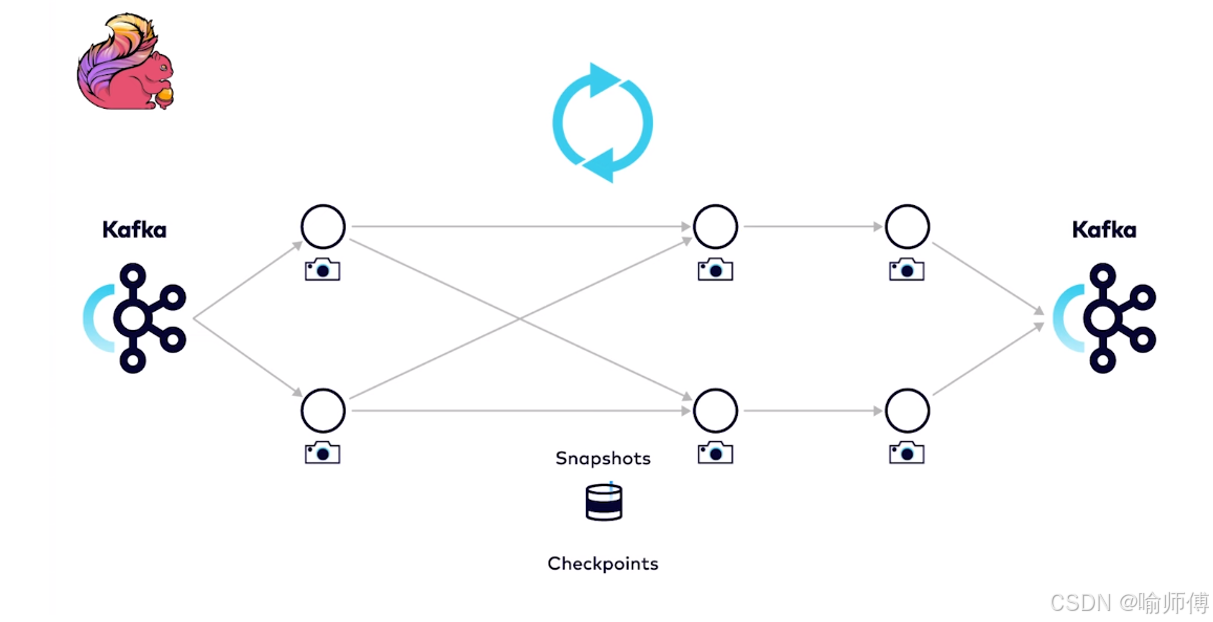
这种机制保证了在发生故障时能够快速恢复和重启任务,而无需重新处理所有数据。
快照也支持 Flink 的 exactly-once 语义,即保证每条数据都能精确地被处理一次,从而确保数据处理的准确性和完整性。
欢迎点赞收藏~后续会更新更多干货。
