
阅读量:6
一、网络通信编程基础
1、Socket
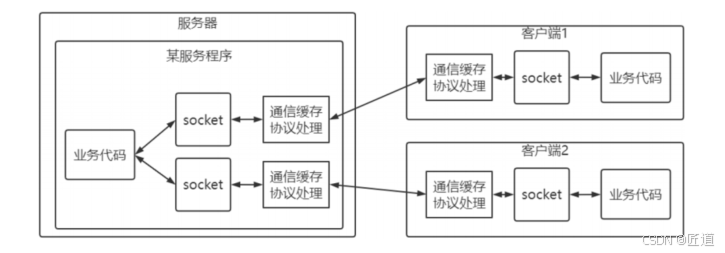
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,是一组接口,由操作系统提供;
Socket将复杂的TCP/IP协议处理和通信缓存管理都隐藏在接口后面,对用户来说就是使用简单的接口进行网络应用编程;一个客户端连接就会产生一个Socket接口实例与客户端Socket进行通信;
2、短连接
连接→传输数据→关闭连接
传统Http是无状态的,浏览器和服务器进行一次http请求就建立一次连接,任务结束就中断连接;
短连接是指Socket连接后发送后接收完数据马上断开连接;
3、长链接
长链接是指建立Socket后不管是否使用都保持连接;
4、如何选择长链接或者短连接
长链接多用于操作频繁,点对点通信。每个TCP连接都需要三步握手,如果每个操作都是线先连接再操作,会降低处理速度;所以操作完不断开下次直接发送,不用建立连接;例如数据库的连接;但长连接对于服务器来说会消耗一定资源;像web网站一般都是短连接;不过现在的http1.1 尤其是http2、http3开始向长连接演化;
5、网络编程中的通用常识
在通信编程里提供服务的叫服务端,连接服务使用服务的叫客户端,在开发过程中如果类的名字有Server或者ServerSocket的,表示这个类是给服务端容纳网络服务用的;如果类名只包含Socket的,那么表示负责具体的网络读写的;
对于服务端来说ServerSocket就只是个场所;必须绑定某个IP地址,同时还需要监听某个端口;具体和客户端沟通的还是一个一个Socket;
在通信编程中我们只关注三件事:连接、读数据、写数据;我们后面学习的BIO和NIO其实都是处理上面三件事,只是处理方式不同;
二、java原生网络编程-BIO
1、BIO
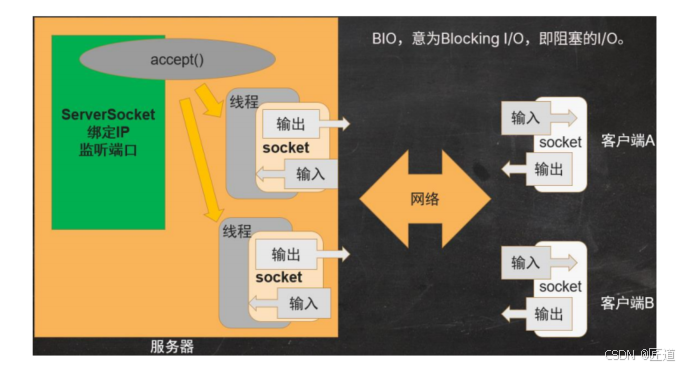
BIO全为BlockingI/O,阻塞I/O;
在BIO中类ServerSocket负责绑定IP地址,启动监听端口,等待客户连接;客户端Socket类的实力发起连接操作,ServerSocket接收连接后产生一个新的服务端Socket实例负责和客户端通信;
2、BIO阻塞
1、若一个服务器启动就绪,主线程就一直等待客户端连接,此时主线程就一直阻塞;
2、建立连接后,在读取到socket信息之前,线程也一直在等待,一直处于阻塞状态;
3、传统BIO通信模型
采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,他接收客户端连接请求后为每个客户端创建一个新的线程进行链路处理,处理完成后通过输出流返回应答给客户端,现成销毁。典型的一请求一应答模型,同时数据的读取写入也必须阻塞在一个线程内等待期完成;
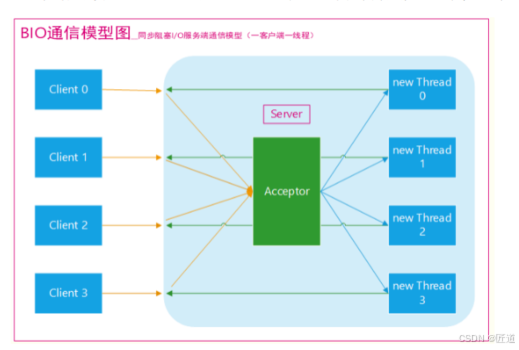
缺点:缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程个数和客户端的并发访问数呈1:1的关系,java中线程是比较宝贵的系统资源,线程数量增加,系统性能急剧下降,过多系统就会挂掉;
改进:使用线程池来管理这些线程,这种被称为伪异步I/O模型;
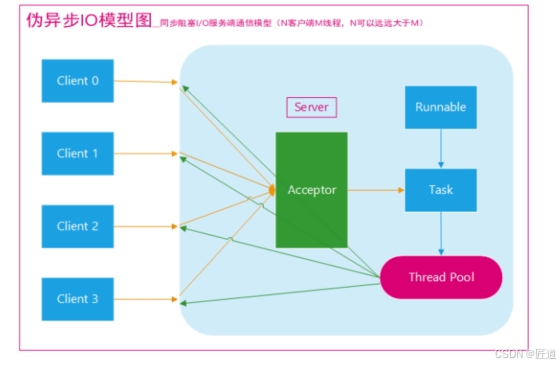
缺点:使用这种模型限制了线程的数量,如果有读取数据缓慢的时候,其它请求就只能一直等待;
三、RPC
1、为什么需要RPC?
传统应用所有功能都写在同一个服务中,服务之间的调用就是我们熟悉的本地方法调用;
随着业务发展,将不同业务放在线程里去做实现异步提升性能,但本质上还是本地方法调用;
随着业务复杂单个应用或单一机器承受不住,我们将核心业务抽取出来独立部署,形成集群,这个时候就需要RPC;
引入RPC框架对我们的代码影响最小,同时可以帮助我们实现架构上的扩展;当服务越来越多,我们RPC之间的调用越来越复杂,此时引入MQ,缓存,同时架构上整体往微服务迁移;
2、什么是RPC?
RPC(Remote Procedure Call-远程过程调用),她是一种通过网络从远程计算机程序上请求服务,而不需要连接底层网络的技术;
3、RPC调用的过程
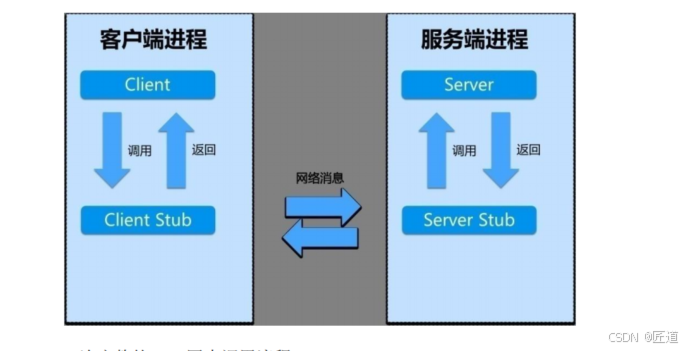
1、服务消费方以本地调用方式调用client stub(客户端存根(存根就是远程方法在本地的模拟对象));
2 、服务端收到消息后,交给代理存根在服务器的部分后进行解码为实际的方法名和参数;
3、server stub根据解码结果调用本地的实际服务
4、本地服务返回给server stub
5、server stub将返回结果打包成消息并发送给消费方
6、client stub收到消息解码
RPC框架的目标就是将中间步骤都封装起来,让我们远程调用就像调用本地方法一样
4、RPC和HTTP
RPC字面意思是远程调用,是对不同应用间互相调用的一种描述,实现方式可以是最直接的TCP通道,也可以是http;Dubbo是基于tcp通信,gRPC是基于HTTP2.0协议,底层使用到了Netty框架;RPC和HTTP是完全两个不同层级的东西,没有可比性;
5、实现RPC框架的问题
1、代理问题:被调用的服务本质上是远程服务,调用者并不关心,调用者只要结果,具体的事情由代理对象负责。既然是远程代理自然要用代理模式;
2、序列化问题:我们的方法调用,有方法名,方法承诺书这些可能是字符串也可能是类,网络传输中并不认得这些,只认二进制01串,我们需要将这些转换成二进制01串;java提供了Serializable;
3、通信问题:JDK提供了BIO;
四、原生JDK网络编程-NIO
1、什么是NIO?
NIO库是JDK1.4中引入的。NIO弥补了原来BIO的不足,它在标准Java代码中提供了高速的、面向块的I/O。NIO被称为no-blacking io;
2、和BIO的区别
1、面向流和面向缓冲:JavaNIO和IO之间最大的区别是IO面向流,NIO面向缓冲区。面向流意味着每次从流中读取一个或多个字节,没有被缓存在任何地方;不能前后移动流中的数据;如果需要前后移动需要先将它缓存在缓冲区;NIO的缓冲导向方法略有不同,数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区前后移动;增加了灵活性;
2、阻塞与非阻塞IO:java IO的各种流是阻塞的,这意味着当一个线程调用read()或Write()时,该线程呗阻塞,直到有一些数据被读取或数据完全写入,该线程在此期间不能干任何事情;
NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但它仅能得到目前可用数据,没有可用数据时,就什么都不会获取,而不是包吃线程阻塞,所以该线程可以做其他的事情;非阻塞写也是如此;线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个线程可以管理多个输入和输出通道;
3、NIO的Reactor模式
“反应”器名字中“反应”的由来;
“反应”即“倒置”,“控制逆转”,具体时间处理器不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣,有事件来了,具体时间处理程序通过时间处理器对某个指定时间发生做出反应;
4、NIO三大组件
NIO有三大核心组件:Selector选择器,Channel管道,buffer缓冲区;
a、Selector(选择器):java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后一个单独的线程来操作这个选择器,选择通道;这使得一个单独的线程很容易管理多个通道;应用程序将向Selector对象注册需要她关注的Channel,以及具体的某一个Channel对哪些IO时间感兴趣。Selector也会维护一个已经注册的Channel的容器;
b、Channels(通道):被建立的一个应用程序和操作系统交互事件、传递内容的渠道;应用程序可以通过通道读取数据,也可以通过通道写数据,而且可以同时读写;
所有被Selector注册的通道,只能是继承了SelectableChannel类的子类。
ServerSocketChannel:应用服务器程序的监听通道。只有通过这个通道,应用程序才能向操作系统注册支持“多路复用IO”的端口监听。同时支持UDP协议和TCP协议。ScoketChannel:TCP Socket套接字的监听通道,一个Socket套接字对应了一个客户端IP:端口到服务器IP:端口的通信连接。通道中的数据总是要先读到一个Buffer,或者总是要从一个Buffer中写入。c、buffer缓冲区:JDK NIO是面向缓冲的。buffer就是这个缓冲,用于NIO通道进行交互;数据时从通道读入缓冲区,从缓冲区写入通道中;缓冲区本质上是一块可以写入的数据,然后可以从中读取数据的缓存(其实就是数组);这块内存被包装成了NIO Buffer对象;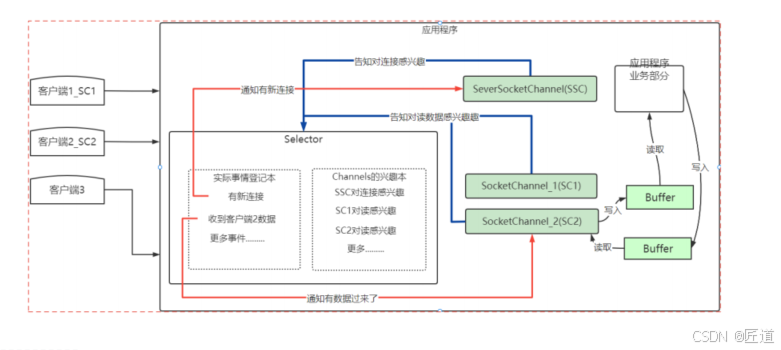
5 、重要概念
SelectionKey:是一个抽象类,表示SelectbaleChannel在Selector中注册的标识,每个Channel向Selector注册时,都会创建一个SelectionKey。SelectionKey将Channel与Selector简历关系并维护了Channel事件;可以通过Cancel方法取消键,取消的键不会立即从Selector中移除,而是添加到CancelKeys中,在下一次Select操作时移除它,所以调用某个Key时需要使用isValid即兴校验;
SelectionKey类型和就绪条件:在向Selector对象注册感兴趣的事件时,NIO工定义了四种:OP_READ、OP_WRITR、OP_CONNET、OP_ACCEPT,分别对应读写请求连接接收连接等网络Socket操作;
OP_READ:当操作系统读缓冲区有数据可读时就绪。并非时刻都有数据可读,所以一 般需要注册该操作,仅当有就绪时才发起读操作,有的放矢,避免浪费CPU。
OP_WRITR:当操作系统写缓冲区有空闲空间时就绪。一般情况下写缓冲区都有空闲空间,小块数据直接写入即可,没必要注册该操作类型,否则该条件不断就绪浪费CPU;但如果是写密集型的任务,比如文件下载等,缓冲区很可能满,注册该操作类型就很有必要,同时注意写完后取消注册。
OP_CONNET:当SocketChannel.connect()请求连接成功后就绪。该操作只给客户端使用。
OP_ACCEPT:当接收到一个客户端连接请求时就绪。该操作只给服务器使用。
6、服务端和客户端分别感兴趣的类型
ServerSocketChannel和SocketChannel可以注册自己感兴趣的操作类型,当对应操作类型就绪条件满足时OS会通知Channel,
服务器启动ServerSocketChannel关注OP_ACCEPT事件;
客户单启动SocketChannel,连接服务器关注OP_ACCEPT;
服务器接受连接启动一个服务器的SocketChannel ,这个SocketChannel可以关注OP_READ OP_WRITE事件;
客户端这边的客户端SocketChannel发现连接建立后,可以关注OP_READ、OP_WRITE事件,一般是需要客户端需要发送数据了才关注OP_READ事件;连接建立后客户端与服务器端开始相互发送消息(读写),根据实际情况来关注OP_READ、OP_WRITE事件。7、Buffer的重要属性
capacity:作为一个内存块,Buffer有一个固定的大小值,也叫“capacity”.你只能往里写capacity 个byte、long,char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。
position:当你写数据到Buffer中时,position表示当前能写的位置。初始的position值为0.当一个byte、long等数据写到Buffer后,position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity –1;当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
limit:在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。写模式下,limit等于Buffer的capacity。当切换Buffer到读模式时,limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
8、buffer的分配
想要获得一个bugger对象首先要进行分配。每一个buffer类都有allocate方法;(可以往对上分配,也可以在直接内存分配)
9、直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用,而且也可能导致 OutOfMemoryError 异常出现。 HeapByteBuffer与DirectByteBuffer,在原理上,前者可以看出分配的buffer是在heap区域的,其实真正flush到远程的时候会先拷贝到直接内存,再做下一步操作;在NIO的框架下,很多框架会采用DirectByteBuffer来操作,这样分配的内存不再是在java heap上,经过性能测试,可以得到非常快速的网络交互,在大量的网络交互下,一般速度会比 HeapByteBuffer要快速好几倍。 (持续更新中。。。。。。。。。。。。。)
