
阅读量:5
一、前言
随着大模型的发布迭代,大模型变得越来越智能,在使用大模型的过程当中,遇到极大的数据安全与隐私挑战。在利用大模型能力的过程中我们的私密数据跟环境需要掌握自己的手里,完全可控,避免任何的数据隐私泄露以及安全风险。基于此,我们发起了DB-GPT项目,为所有以数据库为基础的场景,构建一套完整的私有大模型解决方案。 此方案因为支持本地部署,所以不仅仅可以应用于独立私有环境,而且还可以根据业务模块独立部署隔离,让大模型的能力绝对私有、安全、可控。我们的愿景是让围绕数据库构建大模型应用更简单,更方便。
DB-GPT 是一个开源的以数据库为基础的GPT实验项目,使用本地化的GPT大模型与您的数据和环境进行交互,无数据泄露风险,100% 私密。
二、环境要求
独立部署LLM服务的环境配置越高越好,如部署Llama系列机型、百川、ChatGLM、Vicuna等私有LLM服务。总的来说,该项目可以在消费级显卡上部署和使用。部署的具体硬件要求如下:
如果你的VRAM大小不够,DB-GPT支持8位量化和4位量化。如下:
三、开始部署
1、拉取代码
git clone https://github.com/csunny/DB-GPT.git 2、安装Conda
wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh 安装好之后,需要进入一下,在用ctrl+c键退出来。
sh Miniconda3-py310_23.3.1-0-Linux-x86_64.sh 3、配置Conda
激活Conda:
source /root/.bashrc 创建dbgpt_env空间,并安装指定版本的python:
conda create -n dbgpt_env python=3.10 进入dbgpt_env空间:
conda activate dbgpt_env 注意:如果conda activate dbgpt_env命令有问题,提示什么init,就执行这个命令,如下图: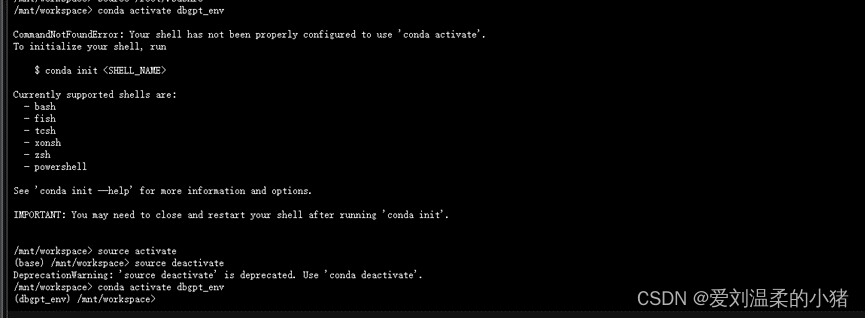
source activate
source deactivate
后,然后在执行conda activate dbgpt_env即可。
4、 创建存放模型的文件夹并放入模型
注意一定在DB-GPT工程里去创建,不能创建在外边。
mkdir models and cd models 
在这个文件夹下下载大模型,因为抱脸虫墙了国内,所以我是找人下好了传给我的,如果你们能下载,这样下载就行:
注意确认你已经安装了git-lfs: centos:yum install git-lfs ubuntu:apt-get install git-lfs macos:brew install git-lfs 开始下载两个模型: #### embedding model git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese or git clone https://huggingface.co/moka-ai/m3e-large #### llm model, if you use openai or Azure or tongyi llm api service, you don't need to download llm model git clone https://huggingface.co/lmsys/vicuna-13b-v1.5 or git clone https://huggingface.co/THUDM/chatglm2-6b 把下载好的两个模型文件放到指定文件夹下:

5、在DB-GPT文件夹下创建配置文件
cp .env.template .env 然后修改这个.env文件中的配置: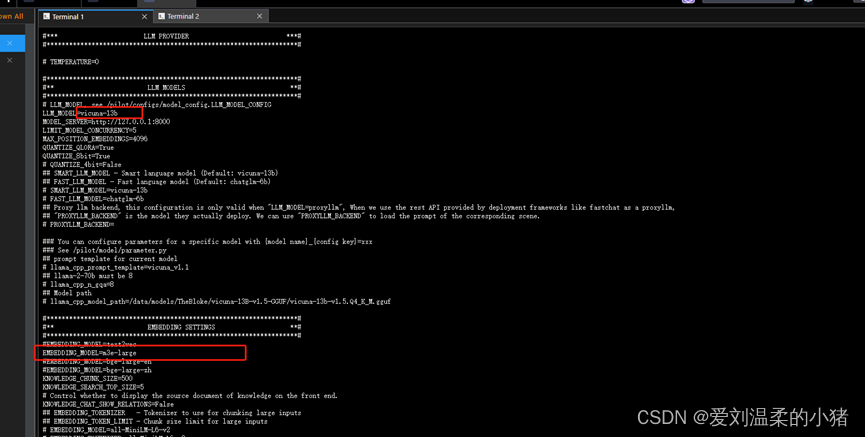
具体列表可在/pilot/configs/model_config.LLM_MODEL_CONFIG中查看: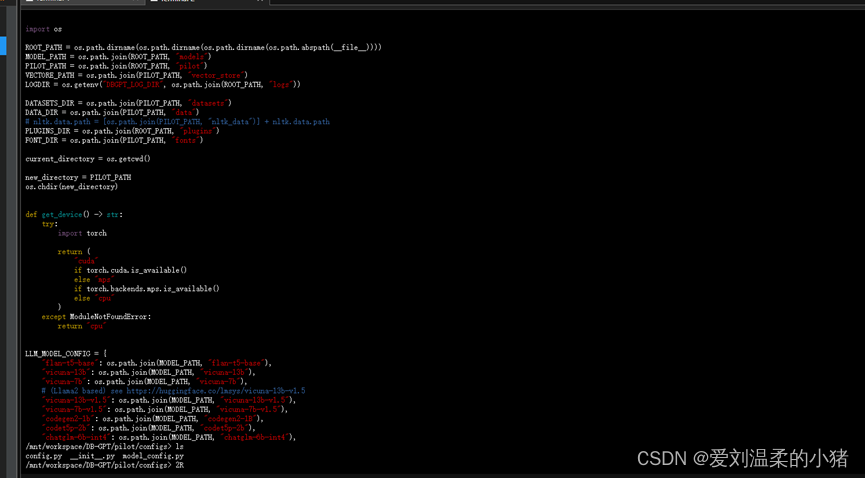
6、 进行安装依赖
pip install -e ".[default]" 8、初始化数据库
默认数据库是sqlite,无需安装的。
bash ./scripts/examples/load_examples.sh 9、启动即可
python pilot/server/dbgpt_server.py
