阅读量:3
一、情景说明
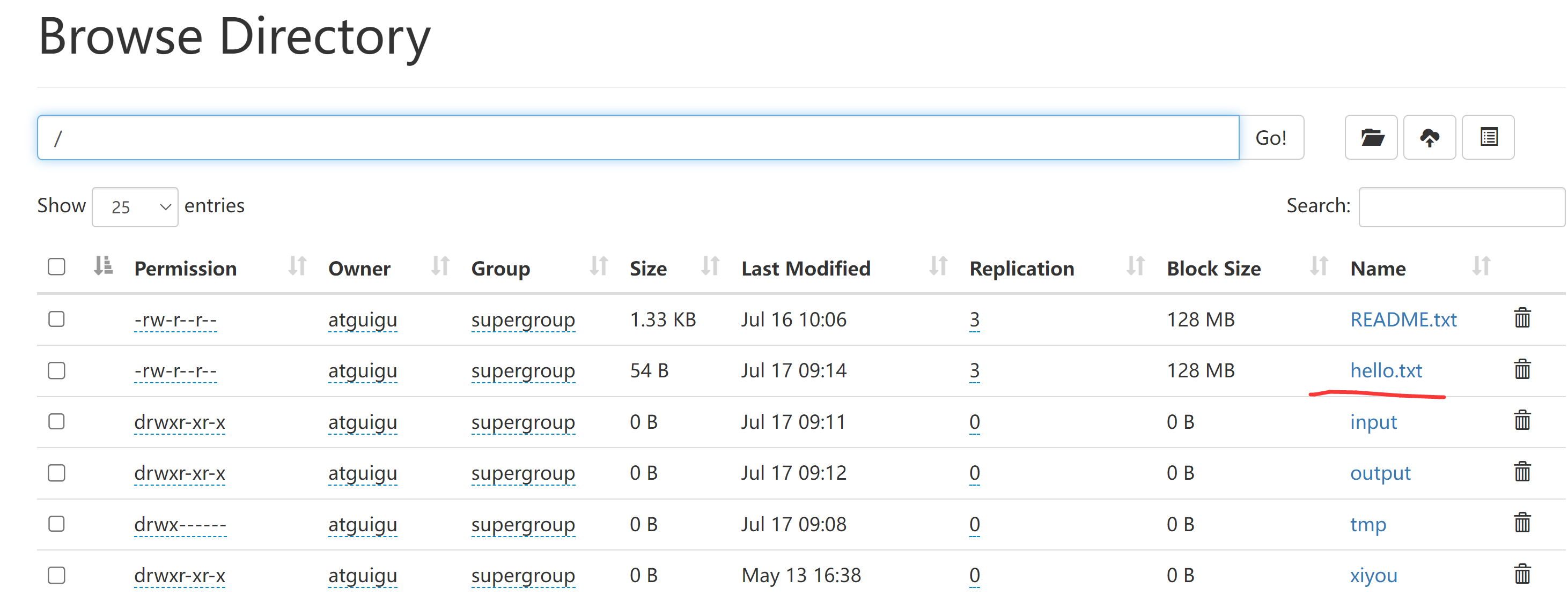
我们知道,NameNode存储一个文件元数据,默认是150byte大小的内存空间。
那么,如果出现很多的小文件,就会导致NameNode的内存占用。
但注意,存储小文件所需要的磁盘容量和数据块的大小无关。
例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
二、解决方案
HDFS存档文件或HAR文件来优化这个问题
具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
它的底层,其实是一个MR程序。
你可以简单理解为,它就是一个压缩程序。
三、案例
将/input目录下的文件归档成input.har文件,并存于根目录。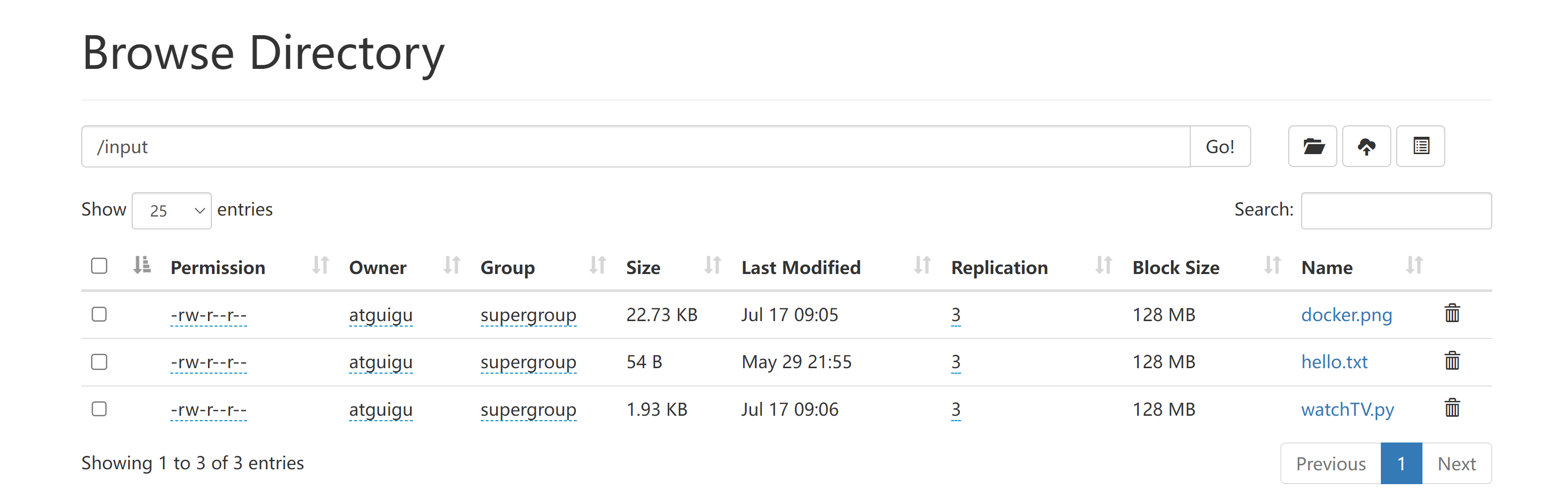
归档文件
hadoop archive -archiveName input.har -p /input /output 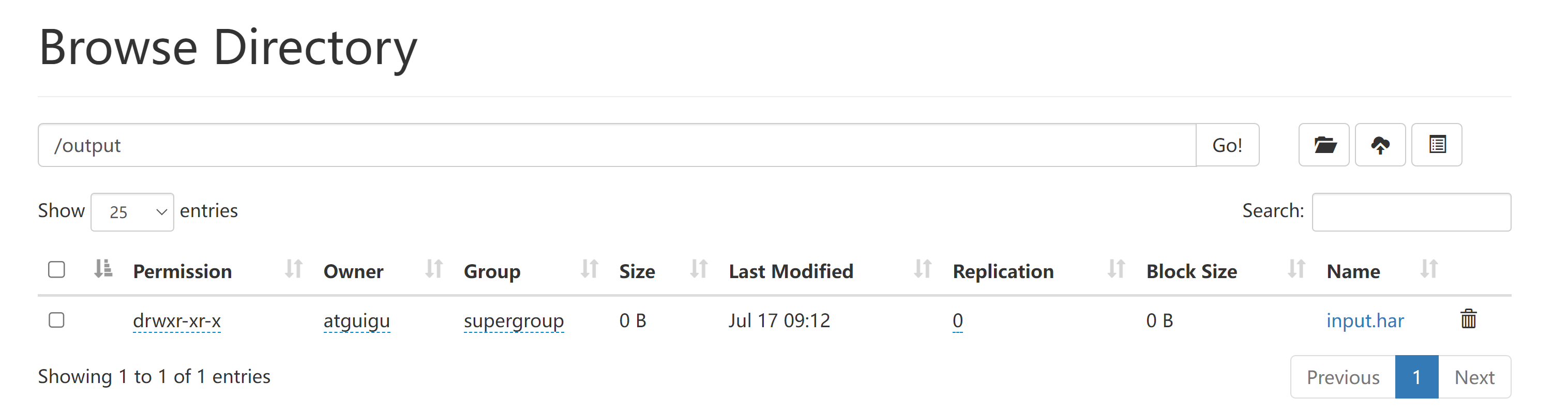
查看归档文件内容
hadoop fs -ls /output/input.har hadoop fs -ls har:///output/input.har 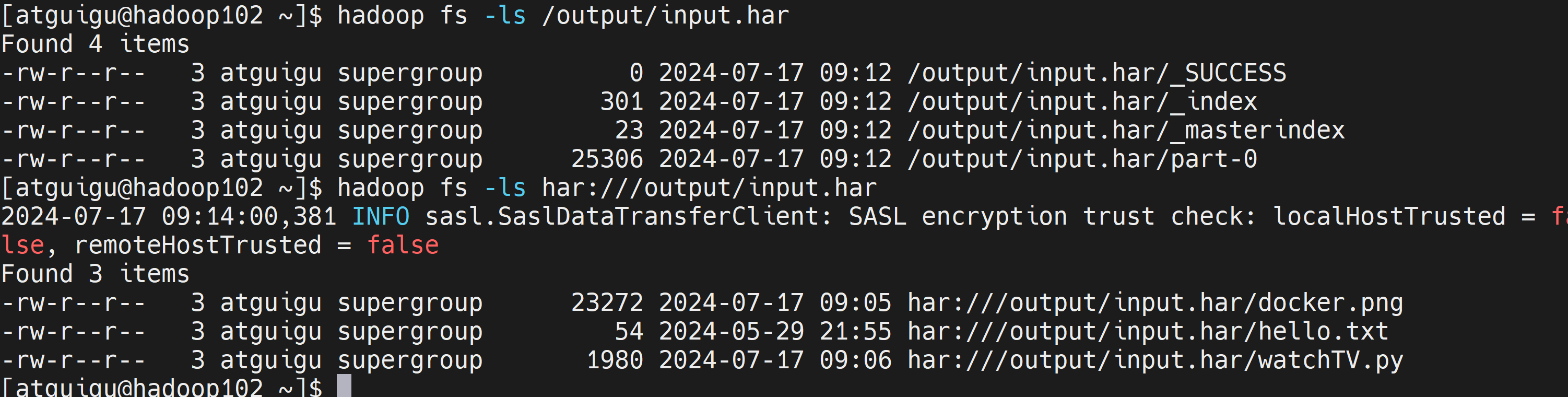
解压归档文件中所有文件
hadoop fs -cp har:///output/input.har/* / 解压归档文件中一个文件
hadoop fs -cp har:///output/input.har/hello.txt /