阅读量:2
下采样(Downsampling)是信号处理、图像处理和机器学习中的一个关键概念,主要通过减少数据点的数量来降低信号或图像的采样率
一、定义与原理
定义:下采样是指通过减少数据点的数量来降低信号或图像的采样率。在图像处理中,下采样通常指的是减少图像的分辨率或尺寸,即减少图像中的像素数量。
原理:下采样的核心原理是按照一定的比率从原始数据中提取数据点。例如,在图像处理中,可以通过将原始图像划分为多个小块(如2x2、3x3等),并计算每个小块内像素值的某种统计量(如平均值、最大值等)来代表整个小块的像素值,从而实现图像的缩小
二、下采样算法步骤
1.确定下采样因子
首先,需要确定下采样的因子,即原始数据与新数据之间的比例关系。例如,在图像处理中,如果要将图像的宽度和高度都缩小为原来的一半,那么下采样因子就是2。
2.选择下采样方法
根据应用场景和数据类型,选择合适的下采样方法。常见的下采样方法包括平均池化、最大池化、随机池化、高斯模糊后下采样等。
3.执行下采样操作
1)数据划分:将原始数据按照下采样因子划分成若干个小块或区域。
2)计算代表值:对于每个小块或区域,根据所选的下采样方法计算出一个代表值。例如,在平均池化中,可以计算小块内所有值的平均值;在最大池化中,则选取小块内的最大值。
3)构建新数据:使用计算出的代表值构建新的数据集。新数据集的大小将根据下采样因子相应减小。
原始数据:

下采样后:
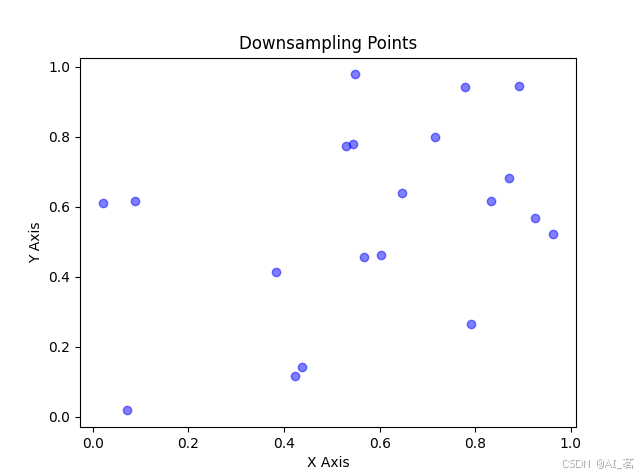
代码示例:
import numpy as np import matplotlib.pyplot as plt # 随机数据 data = np.arange(1, 101) # 创建一个简单的数据集,从1到100 # 定义下采样函数 def downsample_average(data, factor): """通过平均池化进行下采样""" return np.mean(data.reshape(-1, factor), axis=1) downsample_factor = 10 # 下采样因子 downsampled_data = downsample_average(data, downsample_factor) # 原始数据量与下采样后等效的数据量 original_count = len(data) downsampled_count_equivalent = len(data) // downsample_factor # 等效的下采样后数据量 # 使用Matplotlib绘制柱状图 fig, ax = plt.subplots() bars = ax.bar(['Original', 'Downsampled (Equivalent)'], [original_count, downsampled_count_equivalent], color=['b', 'r']) ax.set_xlabel('Data Type') ax.set_ylabel('Data Count') ax.set_title('Comparison of Original and Downsampled Data Counts') # 在柱状图上添加具体数值 for bar in bars: height = bar.get_height() ax.annotate('{}'.format(height), xy=(bar.get_x() + bar.get_width() / 2, height), xytext=(0, 3), # 3 points vertical offset textcoords="offset points", ha='center', va='bottom') plt.show()