
阅读量:5
一、引言
论文地址: arXiv: https://arxiv.org/abs/2103.10360
官网:https://chatglm.cn/blog
Github:https://github.com/THUDM/ChatGLM-6B
在日益增多的开源大模型中,由清华大学研发的开源大模型 GLM 由于效果出众而受到大众关注,而且清华大学开源了基于 GLM 架构研发的基座模型:ChatGLM-6B以及GLM-130B。
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测2,GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示 GLM-130B 在准确性和恶意性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中表现不错。
GLM-130B可能是当前开源ChatGPT复现中中文效果最好的基础模型。
本文就GLM的基础构架和预训练方式,深入浅出地分析GLM为何实现如此出众的效果。
Note: 为控制篇幅,本文仅介绍GLM的基础构架和预训练; GLM-130B和ChatGLM的升级等会在part2再介绍
二、背景
2.1 主流NLP任务
NLP 任务通常分为三类:
- 自然语言理解(NLU):这类任务主要关注从给定文本中提取信息和理解其含义(例如:文本分类、情感分析、分词、句法分析、信息抽取等)
- 有条件生成任务(Cond. Gen.):这类任务根据给定的输入或上下文生成文本,属于序列到序列的任务(例如:翻译任务、问答系统等)
- 无条件生成任务:用预训练模型直接生成内容,这类任务关注从头开始生成文本,而不需要特定的输入条件
这些分类有助于更好地了解 NLP 任务的目标和方法。但随着研究的深入和新技术的发展,任务之间的界限变得模糊。例如,预训练语言模型(如 GPT3.5)已经证明可以在多种 NLP 任务中实现高性能,包括自然语言理解和生成任务。
2.2 主流预训练模型
预训练模型根据架构,也分为三类,分别是:自编码 (auto-encoding)、编码解码 (encoder-decoder)、自回归 (auto-regressive)。三种训练模型分别对应前面三种任务,具体如下图:
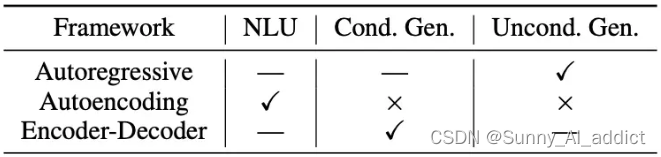
- 自编码 (auto-encoding):
通过去噪目标(即通过覆盖句中的单词,或者对句子做结构调整,让模型复原单词和词序,从而调节网络参数)学习双向上下文的编码器,例如掩码语言模型 (MLM) 。自编码模型擅长自然语言理解NLU任务,常用于生成句子的上下文表示,但是不能直接用于文本生成。
代表模型如BERT、RoBERTa、ALBERT
- 自回归 (auto-regressive):
从左往右学习的模型,根据句子中前面的单词,预测下一个单词。例如,通过“LM is a typical task in natural language ____”预测单词“processing”。
在长文本的生成能力很强,缺点就是单向的注意力机制在 NLU 任务中,不能完全捕捉 token 的内在联系。
代表模型如:GPT系列、GPT-2、GPT-3
编码解码 (encoder-decoder):
编码器使用双向注意力,解码器使用单向注意力,并且有交叉注意力连接两者,在有条件生成任务(seq-seq)中表现良好,比如生成摘要、生成式问答、机器翻译
代表模型MASS、BART、PALM
三种预训练框架各有利弊,没有一种框架在以下三种领域的表现最佳:自然语言理解(NLU)、无条件生成以及条件生成。
以前的工作尝试通过多任务学习(Dong 等人,2019;Bao 等人,2020;例如T5)结合它们的目标来统一不同的框架。然而,由于自编码和自回归目标在本质上是不同的,简单的统一不能充分继承两个框架的优势。
三、GLM预训练框架
基于以上的原因,清华研究团队提出了一种基于“自回归空白填充”的预训练框架,名为 GLM(通用语言模型)。
GLM可以通过改变空格的数量和长度来对不同类型的任务进行预训练,结合了自编码和自回归预训练的优点。在NLU、条件生成和无条件生成的广泛任务中,在相同模型大小和数据的情况下,GLM优于BERT、T5和GPT。
GLM 按照auto-encoding的思路,从输入文本中随机清空连续的token,并根据auto-regressive的思想,训练模型进行序列重构。
虽然在T5 (rafael et al., 2020) 中使用了空白填充进行文本到文本的预训练,但GLM提出了两个更进一步的改变:Span shuffling和二维位置编码。
总结改变如下:
- 自编码思想:在输入文本中,随机删除连续的tokens。
- 自回归思想:顺序重建连续tokens。在使用自回归方式预测缺失tokens时,模型既可以访问corrupted文本,又可以访问之前已经被预测的spans。
- span shuffling + 二维位置编码技术。
- 通过改变缺失spans的数量和长度,自回归空格填充目标可以为条件生成以及无条件生成任务预训练语言模型。
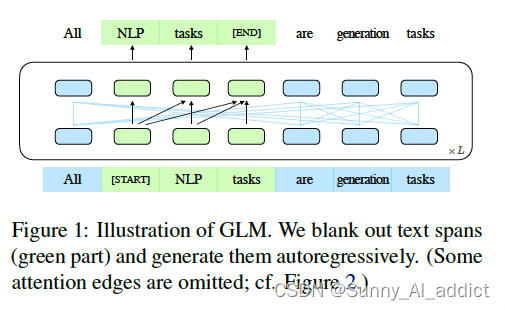
3.1 预训练目标任务
3.1.1 自回归空白填充
GLM 提出了一种基于自回归空白填充目标的通用预训练框:GLM将NLU任务制定为包含任务描述的填空问题,这些填空问题可以通过自回归生成来回答,同时,通过优化一个自回归的空白填充目标来训练GLM。
官方话术的任务描述:
给定输入文本 ![x=[x_{1},x_{2},...,x_{n}]](/zb_users/upload/2024/csdn/eq.png) , 多个文本跨度(text span) 从文本输入被采样; 其中每个对应中一系列连续的tokens;
, 多个文本跨度(text span) 从文本输入被采样; 其中每个对应中一系列连续的tokens;
每个span被替换为单个[MASK],形成一个损坏的文本;
该模型以一种自回归的方式从损坏的文本中预测跨度中缺失的标记,这意味着在预测跨度中缺失的标记时,该模型可以访问损坏的文本(中的文本)和先前预测的跨度 ();
为了充分捕捉不同跨度之间的相互依赖关系,随机排列跨度的顺序;
形式上,设为长度为m的索引序列的所有可能排列的集合,而 为,要优化的目标即为:
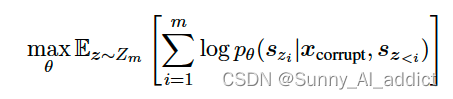
GLM通常以从左到右的方向生成空白处的单词,表明跨度的概率可分解为:

具体怎么样,我们上栗子:
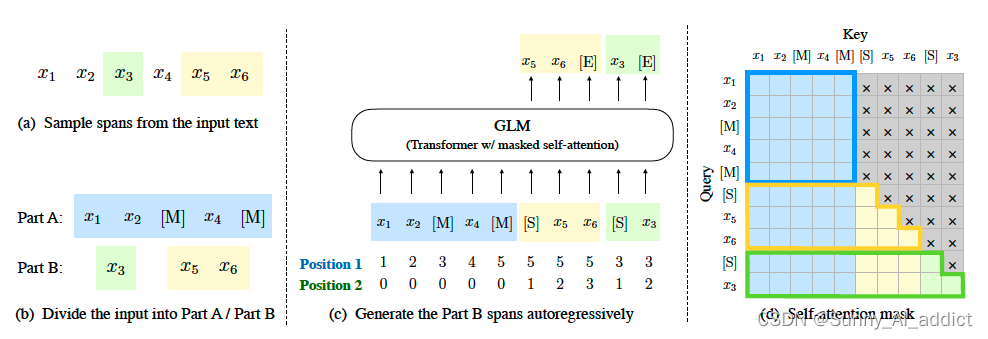
(a) 原始文本为 [x1, x2, x3, x4, x5, x6]。两个text span [x3] 和 [x5, x6] 被采样。
(b) 用 [M] 替换 Part A 中的采样范围,并在 Part B 中随机打乱这些范围。
(c) GLM 自回归地生成 Part B。每个范围前面都加上 [S] 作为输入,后面加上 [E] 作为输出。二维位置编码表示跨范围和范围内的位置 (i.e., 第一维度的位置编码表示跨范围中被采样范围的相对位置位置;第二维度表示被采样的范围内,每个token的相对位置)。
(d) 自注意力掩码。灰色区域被屏蔽。Part A 的 tokens 可以关注自己(蓝色框),但不能关注 B。Part B 的 tokens 可以关注 A 和 B 中在该token之前的部分(黄色和绿色框分别对应两个范围)。
具体如下:
(1)Part A中的tokens彼此可见,但是不可见B中的任意tokens。
(2)Part B tokens可见Part A。
(3)Part B tokens可见B中过去的tokens,不可见B中未来的tokens。
( [M] := [MASK], [S] := [START], and [E] := [END] )
(e) 采样方式:从一个均值为3的泊松分布中采样片段的长度,直到原始文本中15%的字符被掩盖。
基于以上的设计,模型可以可以自动学习双向encoder(Part A)以及单向decoder(Part B)。
3.1.2 不同参数多目标预训练
上述方法适合于NLU任务。然而,研究团队希望可以训练一个可以同时处理NLU和文本生成的单一模型。然后,研究团队增加了一个多任务预训练设置,其中第二个目标是生成更长的文本,该目标与空白填充目标共同优化。
长文本生成具体包含以下两个目标:
- sentence-level (句子级):从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%。这一目标是能针对seq2seq任务,其预测往往是完整的整个句子或者段落。
- document-level (文档级):采样一个长度从原始文本长度的50%到100%的均匀分布中采样的片段。这预训练目标针对的是无条件的长文本生成。
3.1.3 三类预训练目标和掩码任务的对比联系
自回归填充有些类似掩码语言模型,首先采样输入文本中部分片段,将其替换为[MASK]标记,然后预测[MASK]所对应的文本片段。与掩码语言模型不同的是,预测的过程是采用自回归的方式。
- 当被掩码的片段(跨度span)长度为1的时候,空格填充任务等价于掩码语言建模;
- 当将文本1和文本2拼接在一起,然后将文本2整体掩码掉,空格填充任务就等价于条件语言生成任务。
- 当全部的文本都被掩码时,空格填充任务就等价于无条件语言生成任务。
3.2 训练数据
GLM的训练数据集参考https://github.com/THUDM/GLM/blob/main/data_utils/corpora.py,包括:
NAMED_CORPORA = { 'wikipedia': wikipedia, 'wikipedia-key': KeyReader, 'openwebtext': OpenWebText, "zhihu": zhihu, "zhidao": zhidao, "baike": baike, "test": TestDataset, 'wikibook': BertData, "bert-base": BertBaseData, "bert-large": BertLargeData, 'cc-news': CCNews, 'pile': Pile, 'stories': Stories, 'wudao': WuDaoCorpus }四、GLM模型架构
4.1 Transformer
GLM使用单个Transformer,并对其架构进行了一些修改:
(1)重新安排了层归一化和残差连接的顺序 (将Post-LN改成Pre-LN),这对于大规模语言模型避免数值误差至关重要;
(2)使用单个线性层进行输出token预测;
(3)用GeLUs替换ReLU激活函数。
4.2 Attention mask matrix
GLM在训练任务过程中的注意力机制如下图:
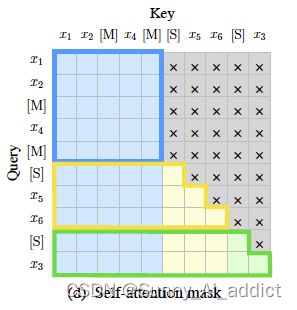
其中,灰色区域表示被屏蔽的部分,即Part A (corrupt text)可以双向关注自己内部的token(蓝色框部分),而不可以关注到Part B中的部分;
而Part B 内部的 tokens 可以关注 Part A 以及Part B 中在该token之前的部分(黄色和绿色框分别对应两个范围)
- PartA部分内的各token可以互相注意到
- PartB部分内的tokens可以注意到PartA和PartB中已经生成的token
4.3 2D位置编码
自回归空白填充任务的挑战之一是如何编码位置信息。
GLM提出了二维位置编码来解决这个挑战:具体来说,每个标记都用两个位置 id 编码。第一个位置 id 表示在损坏的文本 中的位置。对于掩码跨度,它是对应的[MASK]令牌的位置。
第二个位置 id 表示跨度内的位置。对于部分 A 中的标记,它们的第二个位置 id 为 0。对于部分 B 中的标记,它们的范围从 1 到掩码跨度的长度。

两个位置id通过可学习的嵌入表被投影成两个向量,这两个向量都被添加到输入tokens的嵌入中。
该编码方法确保模型在重构它们时不知道被掩盖跨度的长度。与其他模型相比,这是一个重要的区别。例如,XLNet(Yang 等人,2019)对原始位置进行编码,因此可以感知缺失标记的数量,而 SpanBERT(Joshi 等人,2020)用多个 [MASK] 标记替换跨度并保持长度不变。该设计更普遍适用于下游任务,因为通常生成的文本长度事先未知。
五、GLM模型微调/下游任务
通常,对于下游NLU任务,线性分类器将由预训练模型产生的序列或标记的表示作为输入,并预测正确的标签。然而,这种微调方式,使下游任务与生成式预训练任务不同,导致预训练和微调之间的不一致。
研究团队针对文本分类任务和生成任务,重新定义了GLM下游微调的任务:
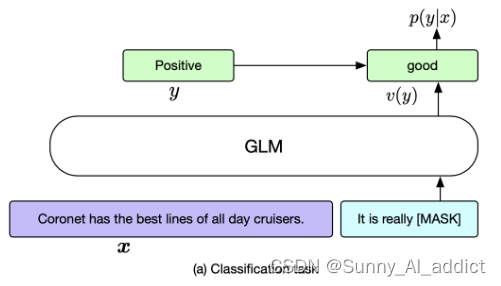
(1)分类任务
给定一个标注样本(x,y),我们将输入文本x通过模板转化为有一个[MASK]字符填空问题c(x)。标签y也映射到了填空问题的答案v(y) 。模型预测不同答案的概率对应了预测不同类别的概率
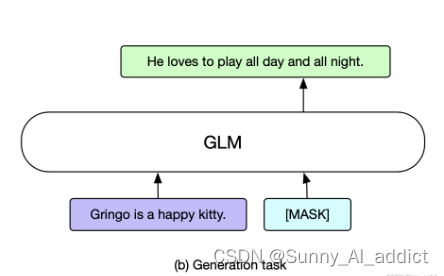
(2)生成任务
针对文本生成任务,直接将GLM作为一个自回归模型的应用。比如: 给定的上下文构成输入的部分的A,在结尾附上一个[MASK]字符,模型用自回归的方式去生成B部分的文本。
六、实验效果对比
6.1 与其他模型的对比
(1)与BERT对比
BERT是auto-encoder模型,来预测[MASK] token。因为模型中的[MASK] token都是独立的,BERT不能捕捉[MASK] token之间的依赖性,且无法处理多个连续的[MASK] token。
(2)与XLNet的对比
XLNet和GLM都是auto-regressive的模型,但是与GLM有两个不同点:(1)XLNet使用损坏前的原始位置编码。在推理过程中,我们需要知道或列举答案的长度;(2)使用双流注意力机制解决了信息泄漏的问题,改变了transfomer的结构,增加了耗时。
(3)与T5模型对比
T5也是处理的空白填充的任务目标,但是GLM使用了单个的transformer编码器学习单向和双向的注意力,且通过共享参数使参数比T5更有效。T5在encoding和decoding使用不同的位置编码,使用哨兵标记来识别不同的[MASK]跨度,哨兵标记造成了模型能力的浪费和预训练微调的不一致性。
(4)与UniLM对比
UniLM是通过在auto-encoder框架下改变在双向,单向,互相之间的attention mask来统一预训练目标;由于自编码模型的独立假设,自回归模型不能完全捕捉当前token对于前面token的依赖。对于微调下游任务来说,自编码会比自回归更加低效。
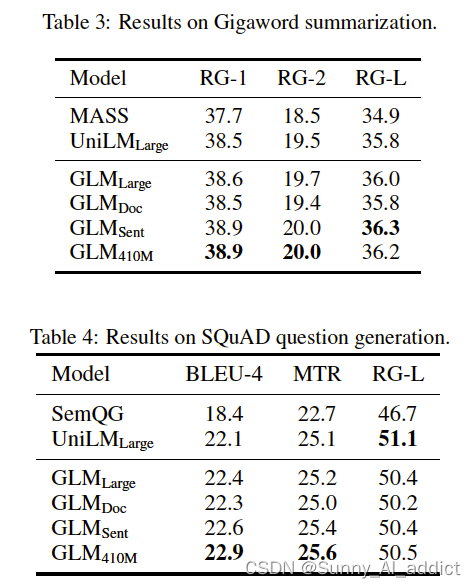
6.2 实验设置&训练结果
6.2.1 预训练数据集
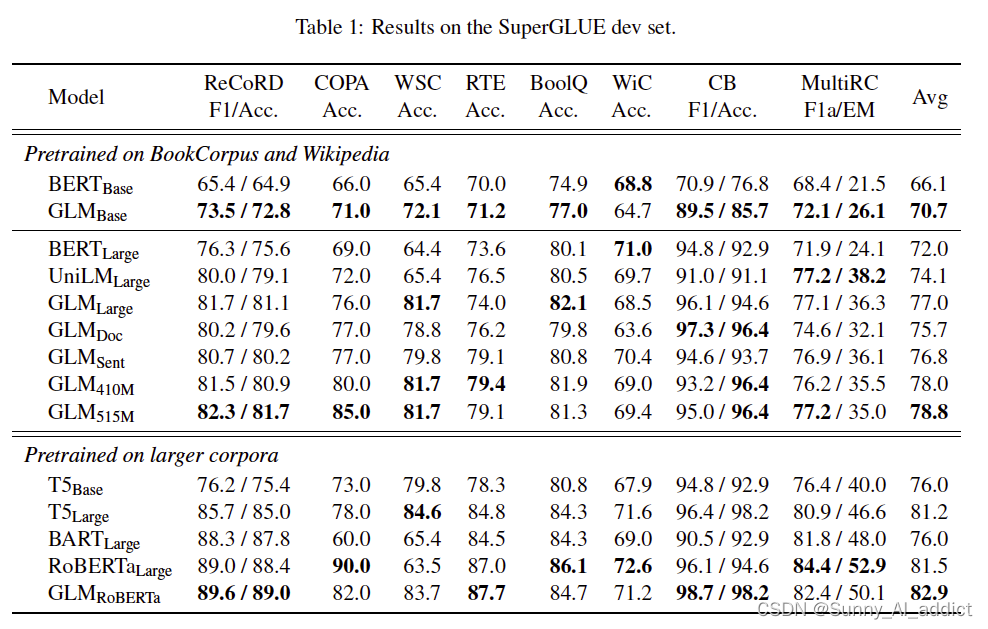
为了与BERT公平对比,使用与BERT相同的数据集训练——BooksCorpus和English Wikipedia。GLM-Base和GLM-Large在相同数据集下的表现优于BERT-Base和BERT-Large。
6.2.2 多任务预训练
使用了NLU、seq2seq、空格填充以及零样本语言建模任务来评估GLM多目标任务的表现。
GLM-Doc和GLM-Sent仅使用一个预训练目标,因此在NLU上的表现均不如GLM-Large,但仍然优于BERT-Large和UniLM-Large。
在条件生成任务(Seq2seq)和空格填充中,GLM-Sent比GLM-Large的表现好,GLM-Doc的表现略差于GLM-Large。这表明模型拓展文本的文档级别的目标,对条件生成任务的帮助不大(条件生成任务旨在从context中抽取有效信息)。
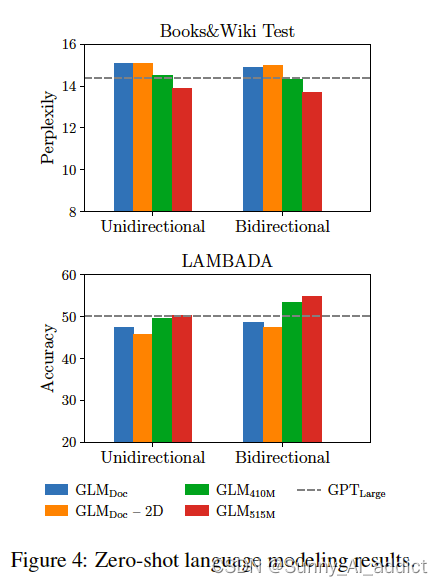
在零样本语言建模任务中,在预训练过程中如果没有生成目标,GLMLarge将无法完成语言建模任务,其perplexity大于100。
在参数数量相同的情况下,GLMDoc的性能比GPTLarge差。这是预期的,因为GLMDoc不仅有文本生成的目标,还有空白填充目标。将模型参数增加到410M (GPTLarge的1.25倍),性能接近GPTLarge。GLM515M (GPTLarge的1.5倍)可以进一步优于GPTLarge。
由于GLM学习了双向注意,我们也在双向注意编码的情况下评估了GLM。在参数数量相同的情况下,对上下文进行双向注意编码可以提高语言建模的性能。在此设置下,GLM410M优于GPTLarge。这是GLM相对于单向GPT的优势。我们还研究了二维位置编码对长文本生成的贡献。我们发现,去除二维位置编码会导致语言建模精度降低和复杂度增加。
6.2.3 消融实验
消融实验是一种评估模型组件对性能影响的方法,通过逐个移除或替换模型的某些部分,来观察模型在下游任务上的表现变化。作者使用了 SuperGLUE 作为评估数据集,它包含了八个自然语言理解任务。作者与 BERT 进行了对比实验,发现 GLM 在预训练和微调阶段都有优势。作者还分析了 GLM 的不同设计选择,如空白填充目标、空白顺序、空白表示、2D 位置编码等,对模型性能的影响。
主要发现如下:
(1)与封闭式微调的BERT相比,GLM受益于自回归预训练。特别是在ReCoRD和WSC中,其中语言表达器由多个token组成,GLM的性能始终优于BERT。这证明了GLM在处理变长空白方面的优势。
(2)另一个观察结果是,完形填空任务 (cloze finetuning)对GLM在NLU任务上的表现至关重要。
(3)删除shuffle span (总是从左到右预测掩码跨度)会导致GLM性能严重下降;相较于使用sentinel token,不使用反而性能更好

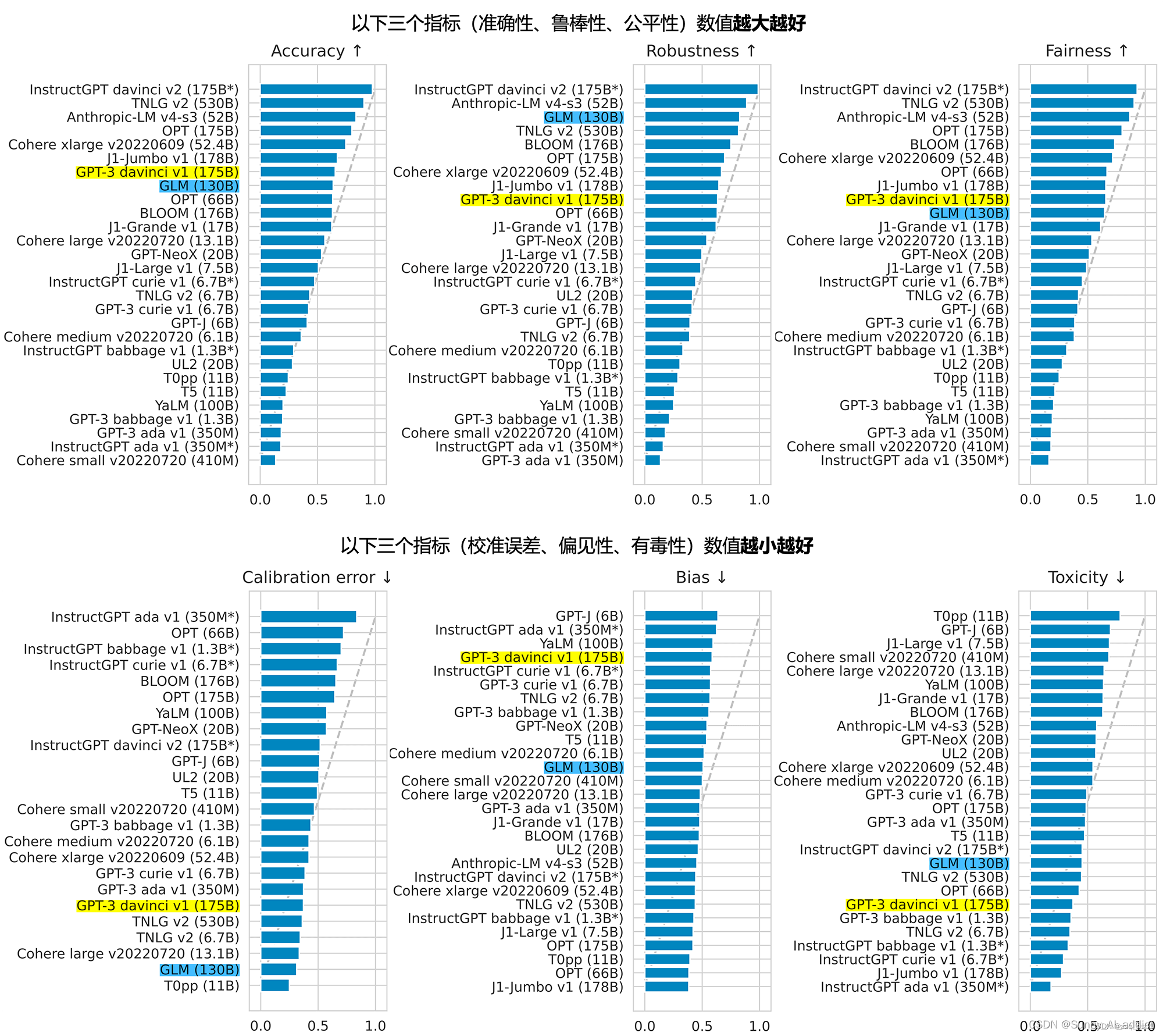
6.3 千亿级参数大模型结果对比(2022.11)
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示 GLM-130B 在准确性和恶意性指标上与 GPT-3 175B (davinci) 接近甚至持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中表现优异。
具体数据见下图:
七、基于GLM训练ChatGLM
ChatGLM-6B 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调等技术实现与人类意图对齐(即让机器的回答符合人类的期望和价值观)。
Note: 为控制篇幅,本文仅介绍GLM的基础构架和预训练; GLM-130B和ChatGLM的升级等会在part2再介绍
参考资料:
清华大学chatGLM论文解读_chatglm详解-CSDN博客
大模型的实践应用4-ChatGLM-6b大模型的结构与核心代码解读,最全的ChatGLM模型架构介绍与源码解读-CSDN博客
