
阅读量:2
一、生成式AI的六个使用阶段
企业在今天和年底将如何逐步采用和管理AI和机器学习模型的过程,分为六个阶段:
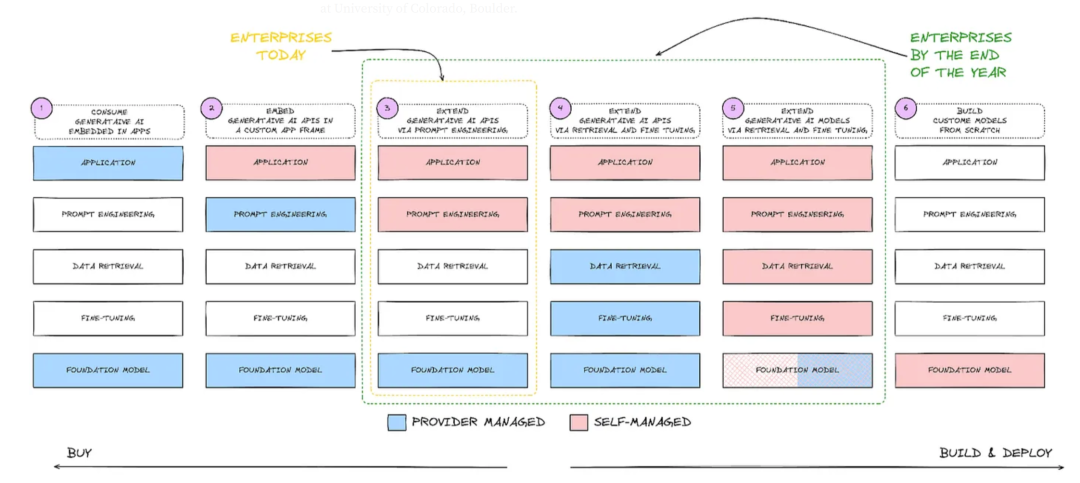
阶段1 - 消费型生成AI(Consume Generative AI Embedded in Apps):
通过使用现成的模型满足广泛的用例。在这一阶段,企业通过购买服务来消费嵌入应用中的生成AI,这是提供商管理的。阶段2 - 嵌入生成型AI(Embed Generative AI in Custom App Frameworks):
根据用户定义的应用程序使用模型。此阶段的企业在其定制应用框架中嵌入生成AI。阶段3 - 通过提示工程扩展生成AI(Extend Generative AI via Prompt Engineering):
使用提示工程训练模型以产生所需的输出。在这一阶段,企业开始通过提示工程来扩展AI的功能,这通常仍是提供商管理的。阶段4 - 通过数据检索和微调扩展生成AI(Extend Generative AI via Retrieval and Fine-Tuning):
在用户端使用提示工程,同时深入了解数据检索和微调,这些仍然主要由LLM提供者管理。企业进一步扩展AI应用,通过数据检索和微调来增强模型的功能,仍然是提供商管理。阶段5 - 自管理扩展(Self-Managed Extension):
将大部分事务掌握在用户自己手中,从提示工程到数据检索和微调(如RAG模型,PEFT模型等)。这是自管理阶段的开始,企业承担更多管理责任。阶段6 - 构建自定义模型(Build Custom Models from Scratch):
从零开始创建整个基础模型——从预训练到后训练。这是企业完全自主构建和部署AI模型的阶段,标志着自管理的高级阶段。整个图表从左到右显示了企业从购买到自主构建和部署AI模型的过渡,同时也从提供商管理过渡到自我管理。这反映了企业在采用AI技术时对自主性和个性化需求的增加。
为了最大化模型的效益,建议采用第5阶段的方法,因为这可以大大增加用户的灵活性。根据特定领域的需求定制模型对于实现最大收益至关重要。如果不介入系统深层次的自定义和优化,很难获得最佳回报。在达到这一点的过程中,需要具备一套结构和清晰的路线图。这包括:
人员:不仅仅是终端用户,还包括数据工程师、数据科学家、MLOps工程师、机器学习工程师及提示工程师等。
过程:过程不仅限于将大型语言模型(LLM)通过API接入,还包括关注模型的整个生命周期,即从评估、部署到微调,以满足特定需求。
工具:工具不仅包括API访问和API工具,还应包括不同的机器学习管道、环境及独立的访问和运行检查账户。
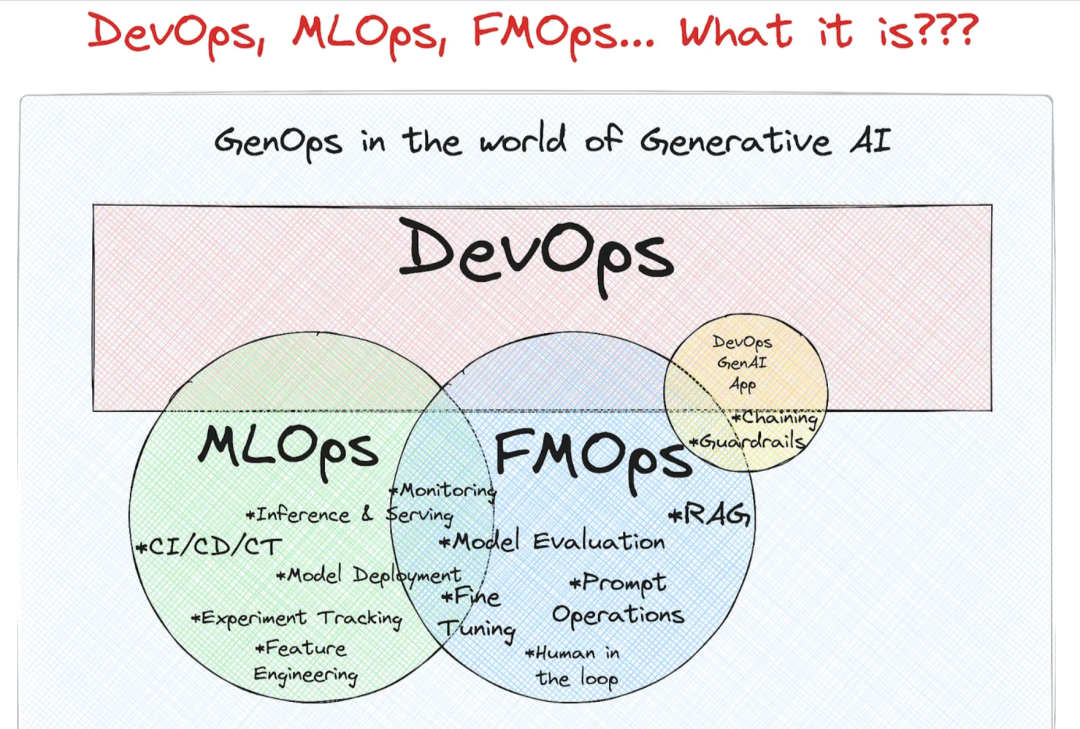
二、从FMOps到DevOps
FMOps ⊆ MLOps ⊆ DevOps
MLOps =Machine Learning Operations
是机器学习工程的一部分,主要负责开发、部署和维护 ML 模型,确保其可靠高效地运行。MLOps 属于 DevOps(开发与运营)范畴,但专门针对 ML 模型。
FMOps =Foundational Model Operations,通过选择、评估和微调 LLM,可用于生成式人工智能场景。
三、浅析Llama3 8B的架构
Llama3少自注意力层与前身神经网络层。
具体流程如下:
注意力层:首先,输入数据会进入注意力层。在这里,模型使用自我注意力机制来分析数据中各部分的相关性,决定哪些信息是重要的。这一步骤帮助模型理解不同特征之间的关系。
前馈网络(FFN):在注意力层处理后,得到的新特征会传递到前馈网络。这个网络对每个位置的特征进行进一步的处理,通常包括一些线性变换和非线性激活函数(如ReLU),从而生成新的特征输出。
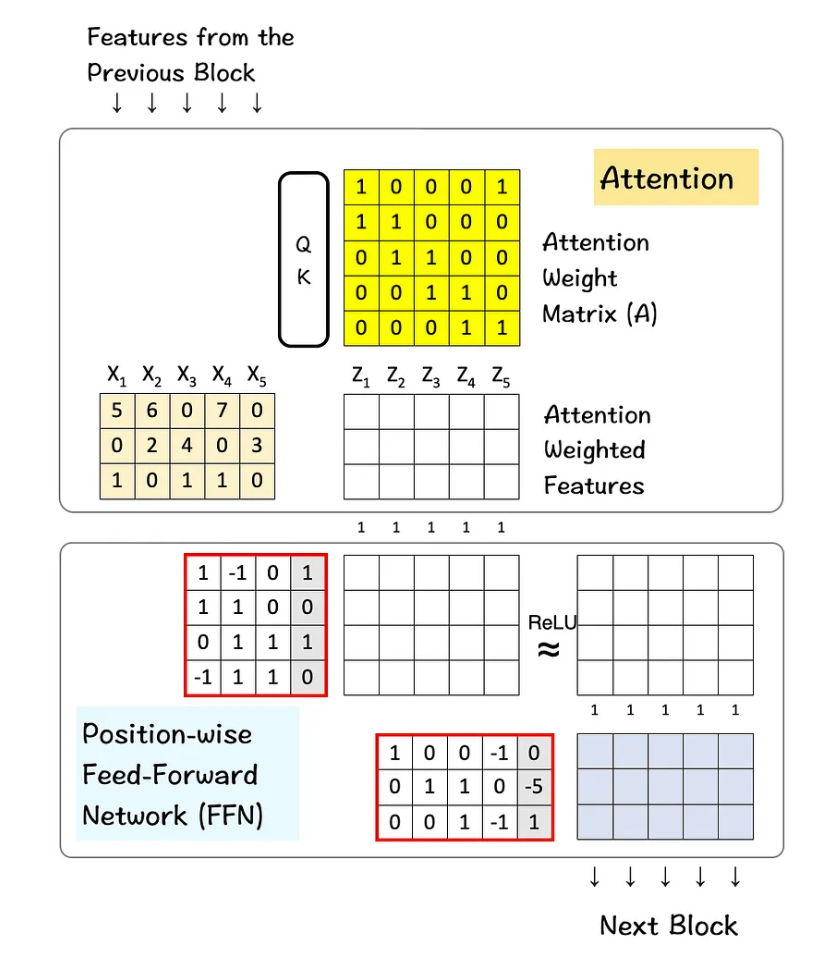
衡量一个深度学习模型的参数:
Layers:这里的Layers指的是transformers的基本构件——图中所示的attention layer和FFN。这些层一个叠加在另一个上面,输入数据流入一个层,其输出则传递到下一个层,逐渐转换输入数据。在Transformer架构中,通常当我们提到“模型有32层”,我们指的是模型包含32个独立的Transformer层。每个层通常包括至少一个自注意力(Self-Attention)子层和一个前馈神经网络(Feed-Forward Network, FFN)子层。这些层可以视作处理数据的单独阶段,每个阶段都会对数据进行进一步的处理和抽象。
Attention heads:Attention heads是self-attention机制的一部分。每个head独立扫描输入序列并执行注意力步骤(QK-module,SoftMax函数)。
Vocabulary words:Vocabulary指的是模型识别或知道的单词数量。本质上,可以认为这是人类构建词汇库的方式,以便我们在语言中发展知识和多样性。通常情况下,词汇量越大,模型性能越好。
Feature dimensions:这些维度指定了表示输入数据中每个token的向量的大小。这个数字在模型中从输入embedding到每层的输出保持一致。
Hidden dimensions:这些维度是模型内部层的大小,更常见的是feed-forward layers的隐藏层的大小。通常情况下,这些层的大小可以大于feature dimension,帮助模型提取和处理更复杂的数据表示。
Context-window size:指模型在任何给定时间内可处理的单词总数量。
现在我们已经定义了这些术语,让我们来看看这些参数在LlaMa 3模型中的实际数值。
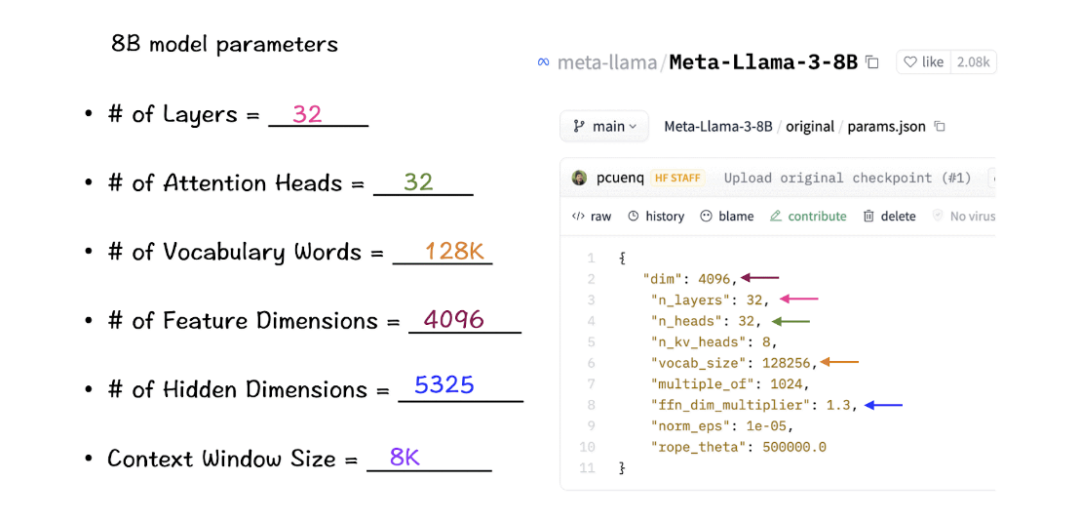
[1] 上下文窗口(context-window)
在实例化LlaMa类时,变量max_seq_len定义了context-window。类中还有其他参数,但这个参数与transformer模型的关系最为直接。这里的max_seq_len是8K。

[2] 词汇量(Vocabulary-size)和注意力层(Attention Layers)
接下来是Transformer类,它定义了词汇量和层数。这里的词汇量是指模型能够识别和处理的单词(和tokens)集。Attention layers指的是模型中使用的transformer block(attention和feed-forward layers的组合)。
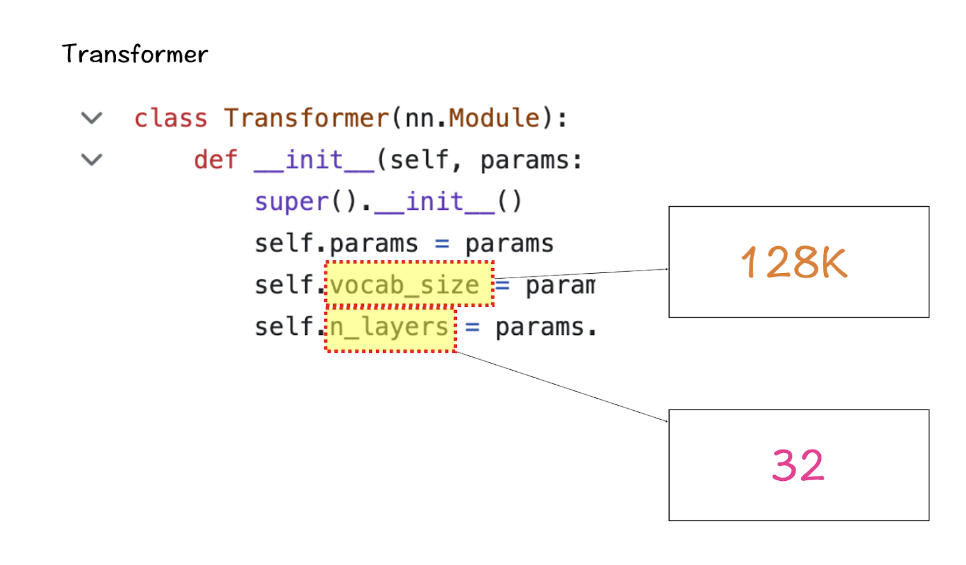
根据这些数字,LlaMa 3的词汇量为128K,这是相当大的。此外,它有32个transformer block。
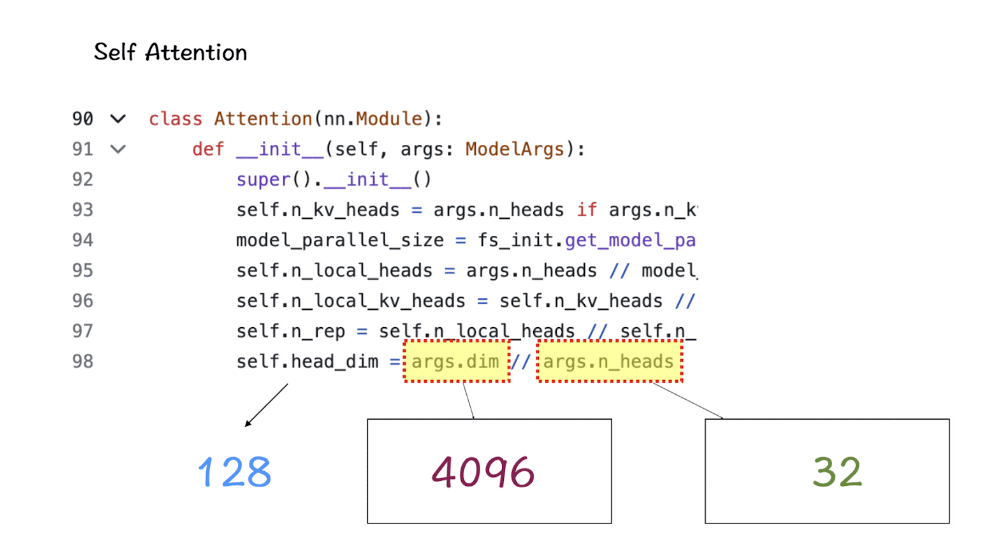
[3] 特征维度(Feature-dimension)和注意力头(Attention-Heads)
特征维度和attention-heads被引入到Self-Attention模块中。Feature dimension指的是嵌入空间中tokens的向量大小,而attention-heads包括驱动transformers中self-attention机制的QK-module。
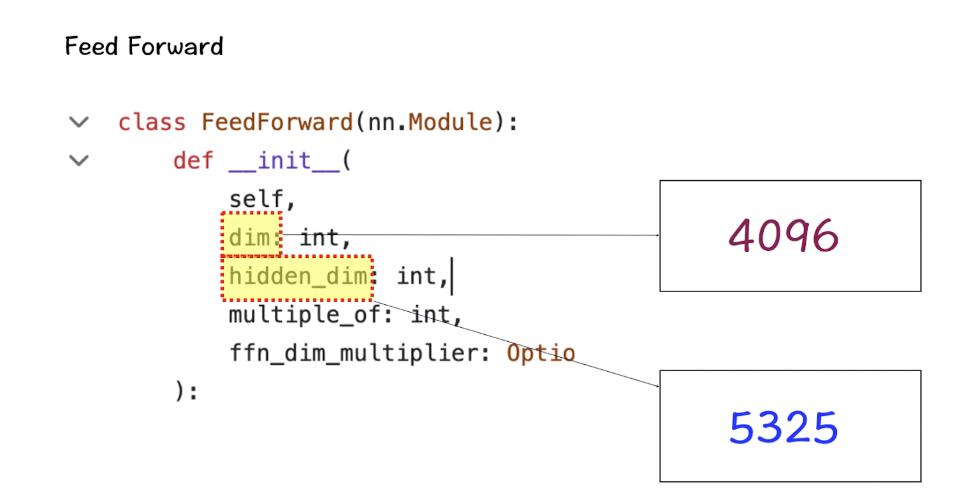
[4] 隐藏维度(Hidden Dimensions)
隐藏维度出现在Feed-Forward类中,指定了模型中隐藏层的数量。对于LlaMa 3,隐藏层的大小是特征维度的1.3倍。更多的隐藏层数量允许网络在将它们投射回较小的输出维度之前,内部创建和操纵更丰富的表示。
[5] 将上述参数组合成Transformer
第一个矩阵是输入特征矩阵,通过Attention layer处理生成Attention Weighted features。在这幅图像中,输入特征矩阵只有5 x 3的大小,但在真实的Llama 3模型中,它增长到了8K x 4096,这是巨大的。
接下来是Feed-Forward Network中的隐藏层,增长到5325,然后在最后一层回落到4096。
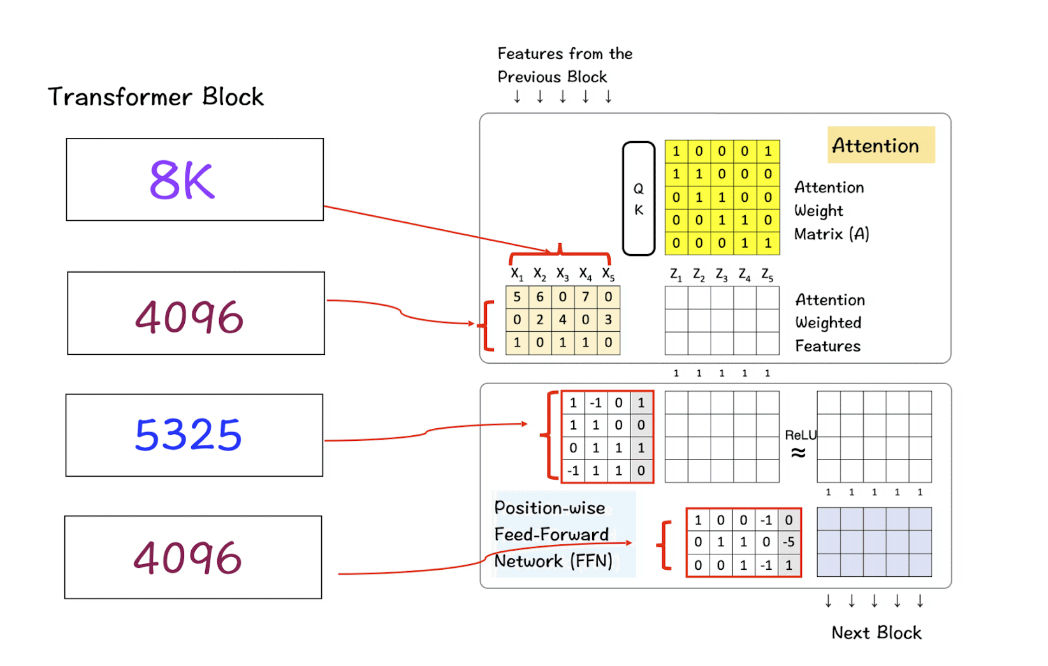
[6] Transformer block的多层
LlaMa 3结合了上述32个transformer block,输出从一个block传递到下一个block,直到达到最后一个。

[7] 把所有这些放在一起
一旦我们启动了所有上述部分,就是时候把它们整合在一起,看看它们是如何产生LlaMa效果的。
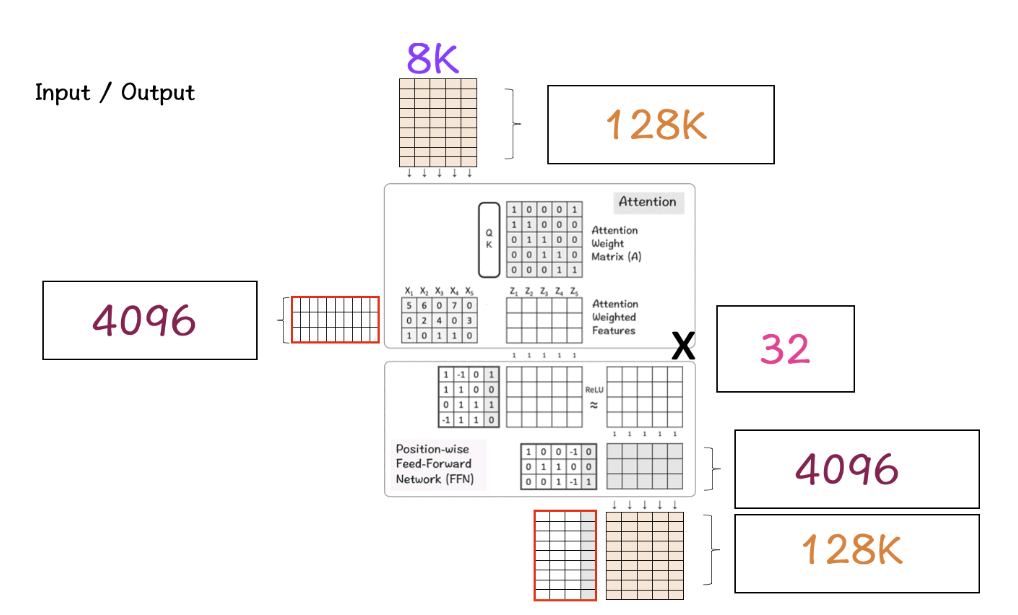
步骤1:首先我们有我们的输入矩阵,大小为8K(context-window)x 128K(vocabulary-size)。这个矩阵经过嵌入处理,将这个高维矩阵转换为低维。
步骤2:在这种情况下,这个低维结果变为4096,这是我们之前看到的LlaMa模型中特征的指定维度。
在神经网络中,升维和降维都是常见的操作,它们各自有不同的目的和效果。
升维通常是为了增加模型的容量,使其能够捕捉更复杂的特征和模式。当输入数据被映射到一个更高维度的空间时,不同的特征组合可以被模型更容易地区分。这在处理非线性问题时尤其有用,因为它可以帮助模型学习到更复杂的决策边界 。
降维则是为了减少模型的复杂性和过拟合的风险。通过减少特征空间的维度,模型可以被迫学习更加精炼和泛化的特征表示。此外,降维可以作为一种正则化手段,有助于提高模型的泛化能力。在某些情况下,降维还可以减少计算成本和提高模型的运行效率 。
在实际应用中,升维后再降维的策略可以被视为一种特征提取和变换的过程。在这个过程中,模型首先通过增加维度来探索数据的内在结构,然后通过降维来提取最有用的特征和模式。这种方法可以帮助模型在保持足够复杂性的同时,避免过度拟合训练数据 。
步骤3:这个特征通过Transformer block进行处理,首先由Attention layer处理,然后是FFN layer。Attention layer横向跨特征处理,而FFN layer则纵向跨维度处理。
步骤4:步骤3为Transformer block的32层重复。最终,结果矩阵的维度与用于特征维度的维度相同。
步骤5:最后,这个矩阵被转换回原始的词汇矩阵大小,即128K,以便模型可以选择并映射词汇中可用的单词。
这就是LlaMa 3在那些基准测试中取得高分并创造LlaMa 3效应的方式。
最后,我们将容易搞混的几个术语用简短的语言总结一下:
1. max_seq_len (最大序列长度)
这是模型在单次处理时能够接受的最大token数。
在LlaMa 3-8B模型中,这个参数设定为8,000个tokens,即Context Window Size = 8K。这意味着模型在单次处理时可以考虑的最大token数量为8,000。这对于理解长文本或保持长期对话上下文非常关键。
2. Vocabulary-size (词汇量)
这是模型能识别的所有不同token的数量。这包括所有可能的单词、标点符号和特殊字符。模型的词汇量是128,000,表示为Vocabulary-size = 128K。这意味着模型能够识别和处理128,000种不同的tokens,这些tokens包括各种单词、标点符号和特殊字符。
3. Attention Layers (注意力层)
Transformer模型中的一个主要组件。它主要负责通过学习输入数据中哪些部分最重要(即“注意”哪些token)来处理输入数据。一个模型可能有多个这样的层,每层都试图从不同的角度理解输入数据。
LlaMa 3-8B模型包含32个处理层,即Number of Layers = 32。这些层包括多个Attention Layers及其他类型的网络层,每层都从不同角度处理和理解输入数据。
4. transformer block
包含多个不同层的模块,通常至少包括一个Attention Layer和一个Feed-Forward Network(前馈网络)。一个模型可以有多个transformer block,这些block顺序连接,每个block的输出都是下一个block的输入。
在Transformer模型的语境中,通常我们说模型有“32层”,这可以等同于说模型有“32个Transformer blocks”。每个Transformer block通常包含一个自注意力层和一个前馈神经网络层,这两个子层共同构成了一个完整的处理单元或“层”。
因此,当我们说模型有32个Transformer blocks时,实际上是在描述这个模型由32个这样的处理单元组成,每个单元都有能力进行数据的自注意力处理和前馈网络处理。这种表述方式强调了模型的层级结构和其在每个层级上的处理能力。
总结来说,"32层"和"32个Transformer blocks"在描述Transformer模型结构时基本是同义的,都指模型包含32次独立的数据处理周期,每个周期都包括自注意力和前馈网络操作。
5. Feature-dimension (特征维度)
这是输入token在模型中表示为向量时,每个向量的维度。
每个token在模型中被转换成一个含4096个特征的向量,即Feature-dimension = 4096。这个高维度使得模型能够捕捉更丰富的语义信息和上下文关系。
6. Attention-Heads (注意力头)
在每个Attention Layer中,可以有多个Attention-Heads,每个head独立地从不同的视角分析输入数据。
每个Attention Layer包含32个独立的Attention Heads,即Number of Attention Heads = 32。这些heads分别从不同的方面分析输入数据,共同提供更全面的数据解析能力。
7. Hidden Dimensions (隐藏维度)
这通常指的是在Feed-Forward Network中的层的宽度,即每层的神经元数量。通常,Hidden Dimensions会大于Feature-dimension,这允许模型在内部创建更丰富的数据表示。
在Feed-Forward Networks中,隐藏层的维度为5325,即Hidden Dimensions = 5325。这比特征维度大,允许模型在内部层之间进行更深层次的特征转换和学习。
关系和数值:
Attention Layers 和 Attention-Heads 的关系:每个Attention Layer可以包含多个Attention-Heads。
数值关系:一个模型可能有多个transformer blocks,每个block包含一个Attention Layer和一个或多个其他层。每个Attention Layer可能有多个Attention-Heads。这样,整个模型就在不同层和heads中进行复杂的数据处理。
更多科研🔗:
➤ 问小助理无偿自取哦:

【一】上千篇CVPR、ICCV顶会论文
【二】动手学习深度学习、花书、西瓜书等AI必读书籍
【三】机器学习算法+深度学习神经网络基础教程
【四】OpenCV、Pytorch、YOLO等主流框架算法实战教程
