阅读量:3
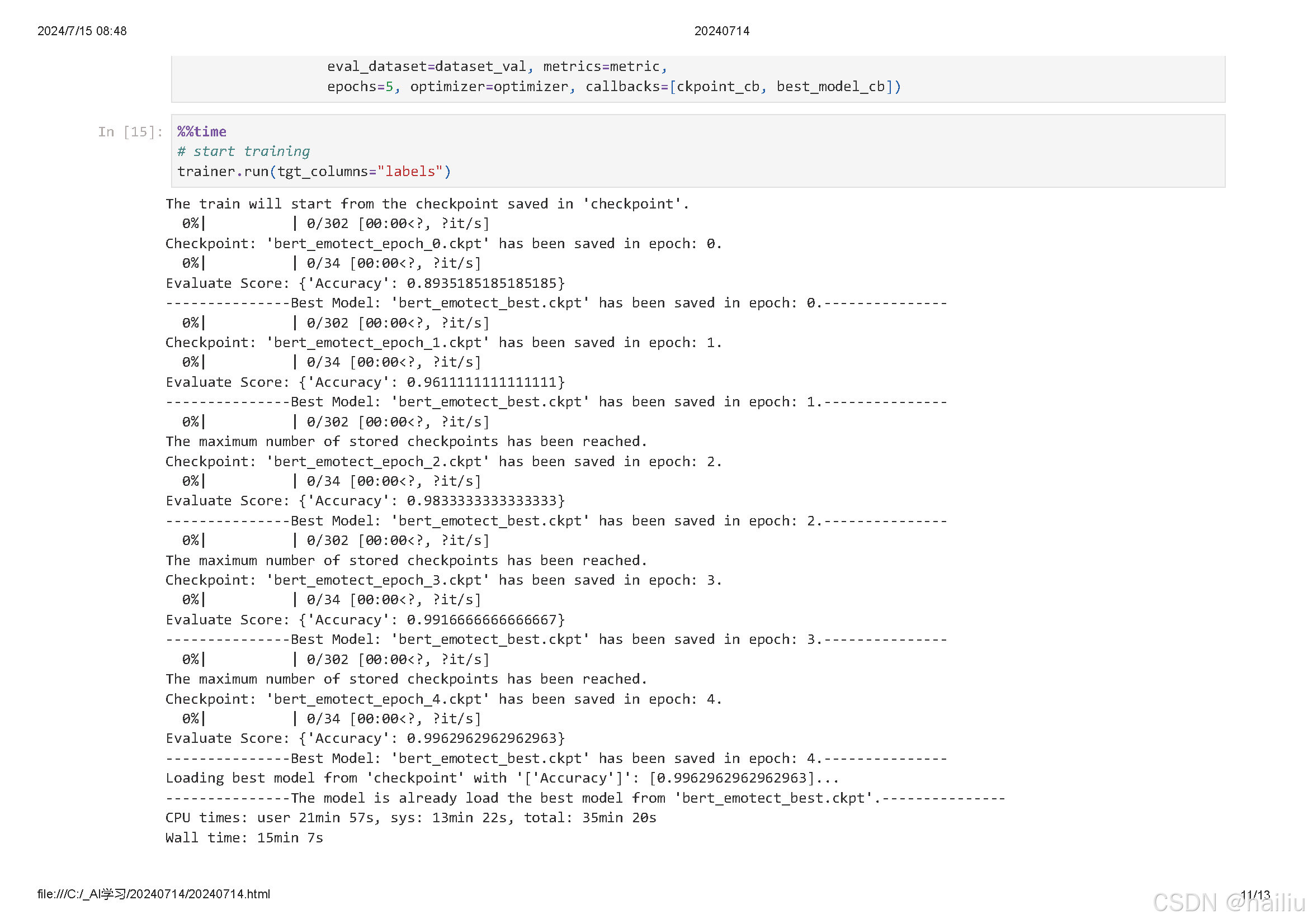
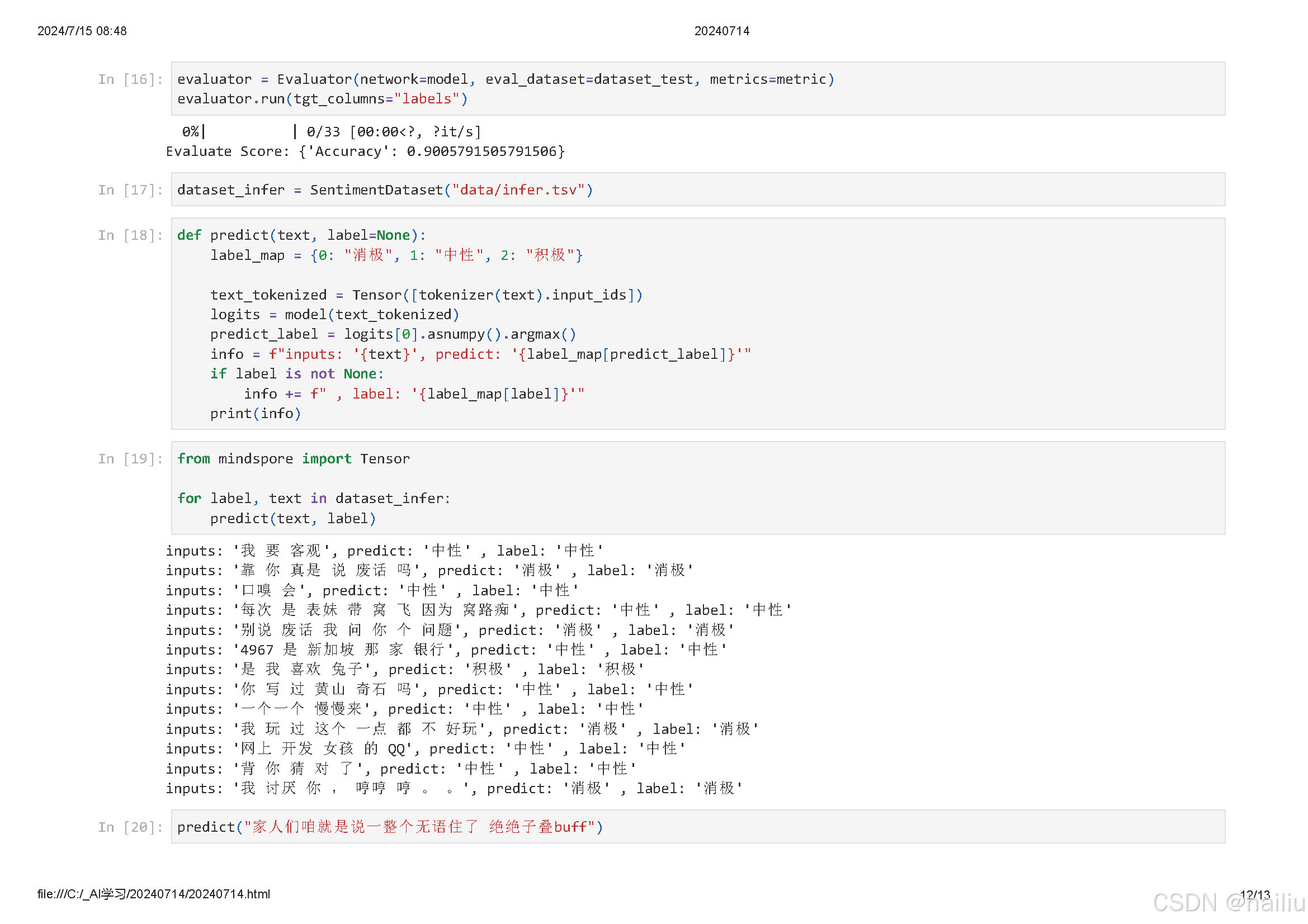
今天是26天,学习了BERT对话情绪识别。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 架构的预训练语言模型,具有强大的语言理解能力。
在对话情绪识别任务中,它的优势主要体现在以下几个方面:
1. 深度理解上下文
- BERT 能够同时考虑文本的前后信息,更好地捕捉对话中的语义和情感线索。例如,在“我今天很开心,因为收到了礼物”这句话中,BERT 可以理解“开心”与“收到礼物”之间的关联。
2. 丰富的语义表示
- 它可以生成高质量的词向量表示,这些表示包含了丰富的语义信息,有助于准确识别情绪。比如说,对于“我感到非常沮丧”和“我心情超好”,BERT 能提取出明显不同的语义特征。
3. 强大的迁移学习能力
- 经过在大规模语料上的预训练,BERT 可以在特定的对话情绪识别数据集上进行微调,从而快速适应新的任务。
4. 处理复杂语言结构
- 能够应对对话中复杂的语言结构和表达方式,包括省略、指代等。
在实际应用中,使用 BERT 进行对话情绪识别通常需要以下步骤:
1. 数据预处理,包括清洗、分词等。
2. 将预处理后的数据输入 BERT 模型进行训练或微调。
3. 使用训练好的模型对新的对话进行情绪预测。
一些可以提高 BERT 对话情绪识别模型性能的方法:
1. 数据增强
采用随机替换、插入、删除单词等方式扩充数据集,增加数据的多样性。例如,将句子“我今天很开心”变换为“我今天特别开心”“我今天相当开心”等。
回译,即将文本翻译成其他语言再翻译回来,引入不同的表述方式。
2. 优化超参数
调整学习率、训练轮数、批大小等超参数。比如,通过试验不同的学习率,找到最适合模型训练的数值。
3. 模型融合
结合多个 BERT 模型的预测结果,例如通过集成多个微调后的 BERT 模型,或者将 BERT 与其他模型(如循环神经网络 RNN、长短时记忆网络 LSTM 等)进行融合。
4. 引入先验知识
利用外部的情感词典、知识库等先验信息,辅助模型学习。比如,在训练过程中,将情感词典中的词汇与模型的输出进行关联和约束。
5. 增加模型深度和宽度
可以尝试使用更深层或更宽的 BERT 架构,但这可能会增加计算成本。
6. 多模态信息融合
除了文本信息,融合语音、表情等多模态信息,为情绪识别提供更丰富的线索。例如,结合说话人的语音语调特征来辅助判断情绪。
7. 对抗训练
通过引入对抗网络,使模型学习到更鲁棒的特征表示,增强对噪声和干扰的抵抗能力。
8. 精细的特征工程
提取文本的词性、命名实体等特征,并与 BERT 学习到的特征进行融合。
9. 正则化技术
应用 L1、L2 正则化或 Dropout 等技术,防止模型过拟合。
10. 迁移学习和预训练
利用在大规模通用语料上预训练好的 BERT 模型,并在特定的对话情绪数据集上进行进一步的微调。
通过综合运用这些方法,可以有效地提高 BERT 对话情绪识别模型的性能。