
阅读量:4
文章目录
概要
大模型量化是指在保持模型性能尽可能不变的情况下,通过减少模型参数的位数来降低模型的计算和存储成本。本次实验环境为魔搭社区提供的免费GPU环境(24G),使用Llama.cpp进行4bit量化可以大幅减少大语言模型的内存占用,并提高推理效率。本次采用的模型为前一篇博客所写的基准模型与LoRA微调后的合并模型。
整体实验流程
由于基准模型较大就直接在服务器上下载并上传LoRA参数合并。
连不上huggingface,就用的魔搭社区的模型。
from transformers import AutoTokenizer, AutoModelForCausalLM import torch from modelscope import snapshot_download #模型下载 model_dir = snapshot_download('ChineseAlpacaGroup/llama-3-chinese-8b-instruct-v3') tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", torch_dtype=torch.float16) !pip install -q peft==0.3.0 from peft import PeftModel # 载入预训练的 LoRA 模型 model_lora = PeftModel.from_pretrained( model, 'lora', torch_dtype=torch.float16 ) # 合并和卸载模型 model_lora = model_lora.merge_and_unload() # 保存模型 model_lora.save_pretrained('ddd/conbine') tokenizer.save_pretrained('ddd/conbine') - 下载Llama.cpp,用的github的。并make编译,接下来的代码部分均在Linux终端上操作。
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp make 
make过程比较久,耐心等待一会。
模型文件类型为safetensors,需要将其转换成gguf格式,如果本身是gguf则跳过这一步。
标记出来的这个三个为接下来使用到的文件或者文件夹。

python convert_hf_to_gguf.py /原模型路径/ --outfile ./输出路径/gguf格式文件名.gguf python convert_hf_to_gguf.py ../ddd/conbine/ --outfile ./models/ggml-8b-f16.gguf 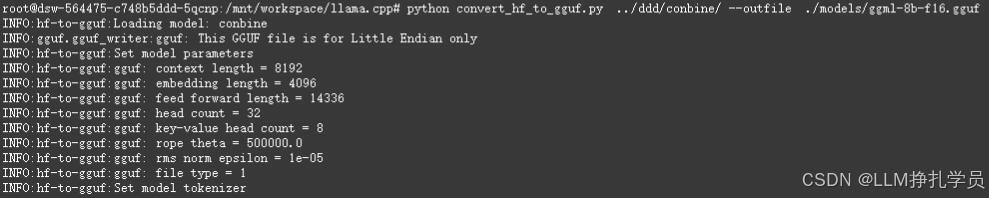
加载完后得到一个ggml-8b-f16.gguf的文件,大小为16.1G。
- 接下来开始量化操作,可以量化到8位,也可以4位,我就采用的4位。
./llama-quantize ./新模型路径/新模型名.gguf ./输出路径/4位gguf格式文件名.gguf Q4_K_M 采用4位 如果8位就Q8_K_M ./llama-quantize ./models/ggml-8b-f16.gguf ./models/ggml-8b-Q4.gguf Q4_K_M 
这个加载时间也久,加载完后得到一个ggml-8b-Q4.gguf文件,大小只有4685MB。
- 量化完成了部署试一下。
这里有很多参数设置比如top_k啥的,可以百度一下。如下图所示。 ./llama-cli -m ./models/ggml-8b-Q4.gguf -c 512 -b 64 -n 256 -t 12 --repeat_penalty 1.0 --top_k 20 --top_p 0.5 --color -i -r "助手:" -f prompts/chat-with-baichuan.txt 
结果展示:这个结果不太好,之前微调的模型还有很多问题,这里只是给大家演示一下。
技术细节
- 如果是用的官方的Llama.cpp有时候需要注意库是否有更新,命令不正确可以去看看github是不是命令改了。
小结
Llama.cpp 是一个轻量级的C++库,旨在帮助用户在资源受限的环境中高效地运行大型语言模型。
轻量级:Llama.cpp设计简单,代码库小,易于理解和修改,适合在嵌入式设备或移动设备上运行。
高效:通过优化的内存管理和计算,Llama.cpp能够在性能有限的硬件上高效运行大模型。
跨平台:支持多种操作系统,包括Linux、Windows和MacOS。
量化支持:内置了对模型进行量化的支持,如4bit、8bit等,能够显著降低内存使用和计算需求。
易用性:提供了简单的API,用户可以方便地加载模型并进行推理。
