
阅读量:3
文章目录
前言
在计算机科学中,数据结构是我们组织和存储数据的方式,它可以帮助我们高效地执行各种操作,如搜索、插入和删除。其中,树形结构是一种非常重要的数据结构,它在许多不同的场景中都有应用,如数据库索引、文件系统和路由算法。在本文中,我们将探讨几种不同类型的树形结构,包括它们的定义、特性,以及如何用PlantUML代码来表示它们。
一、树的分类
1. 二叉树
这是最基本的树结构,每个节点最多有两个子节点:左子节点和右子节点。这个结构没有任何特殊的排序或平衡规则。在PlantUML中,我们可以用以下代码表示一个简单的二叉树: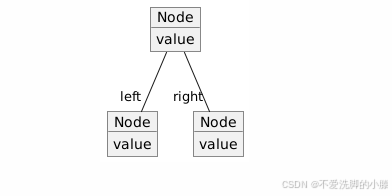
2. 二叉搜索树
这是二叉树的一个变种,其中每个节点的值都大于其左子节点的值并且小于其右子节点的值。这种属性使得二叉搜索树在查找元素时具有较高的效率。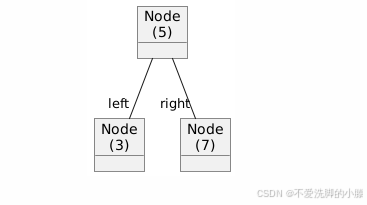
3. 堆
堆是一种特殊的完全二叉树,其中每个节点的值都大于或等于(最大堆)或小于或等于(最小堆)其子节点的值。堆常用于实现优先队列。
4. B树和B+树
这些树是为磁盘或其他直接访问辅助存储器设计的。B树是一种自平衡的树,可以有多于两个子节点的节点。B+树是B树的变种,它将数据只存储在叶节点,使得范围查询更加高效。
5. 红黑树
红黑树是一种自平衡的二叉搜索树。它通过每个节点附加一个颜色标签(红或黑)并应用一些额外的规则,保证了树的平衡,从而保证了查找、插入和删除操作的高效性。
二、使用场景
1.二叉树: 二叉树在许多算法和数据结构中都有应用。例如,表达式解析树是二叉树的一种应用,它用于表示算术表达式的结构。在编译器设计中,语法分析树(一种特殊的二叉树)用于表示源代码的结构。
2.二叉搜索树: 二叉搜索树是一种很好的用于查找操作的数据结构,因为它们可以在O(log n)时间内完成查找。它们也用于构建更复杂的数据结构,如红黑树和AVL树。
3.堆: 堆被广泛用于实现优先队列,这是一种数据结构,用于存储并快速检索优先级最高的元素。优先队列在许多算法中都有应用,如Dijkstra的算法、堆排序等。
4.B树和B+树: B树和B+树主要用于数据库和文件系统。在这些系统中,数据存储在磁盘上,而不是内存中。B树和B+树的设计使得它们能够有效地处理大量数据。例如,MySQL数据库在其InnoDB存储引擎中使用B+树作为索引结构。
5.红黑树: 红黑树用于创建自平衡的二叉搜索树,它们在许多编程语言的库和框架中都有应用。例如,在Java的Collections框架和C++ STL中,红黑树被用作TreeMap和TreeSet的内部实现。红黑树也用于Linux内核中的进程调度和内存管理。
二、总结
树形结构是一种强大而灵活的数据结构,它可以帮助我们解决许多复杂的问题。通过理解和掌握不同类型的树形结构,我们可以更好地设计和实现各种算法和系统。尽管PlantUML可能无法准确地表示所有的数据结构,但它仍然是一个非常有用的工具,可以帮助我们理解和学习这些复杂的概念。
