
阅读量:7
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
AI大模型探索之路-训练篇19:大语言模型预训练-微调技术之Prefix Tuning
AI大模型探索之路-训练篇20:大语言模型预训练-常见微调技术对比
AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
AI大模型探索之路-训练篇22: ChatGLM3微调实战-从原理到应用的LoRA技术全解
AI大模型探索之路-训练篇23:ChatGLM3微调实战-基于P-Tuning V2技术的实践指南
目录
前言
在现代自然语言处理(NLP)任务中,随着模型规模的扩大和训练数据的增多,单张GPU的显存已经无法满足大模型的训练需求。为了充分利用多张GPU进行并行训练,我们需要了解不同的并行策略。本文将详细介绍ChatGLM3微调实战中的多卡方案及其步骤。
一、分布式模型训练
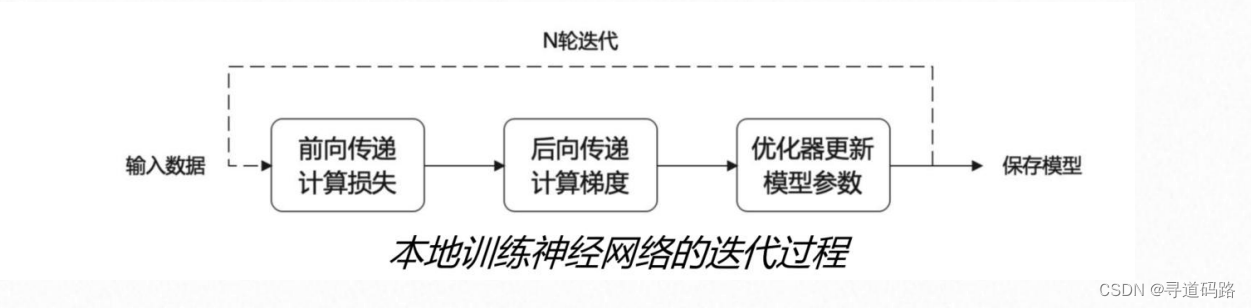
1、显存效率:当模型参数量超出单张GPU显存容量
• 即使目前显存最大的 GPU 也放不下这些大模型的模型参数。
• 例如:面对拥有175B参数量的GPT-3模型,即使是目前最大显存的NVIDIA A100 80GB GPU也难以容纳。该模型的参数需要占用约700GB的显存,加上参数梯度和Adam优化器状态,总共需要约2.8TB的显存空间。
2、计算效率:训练数据量多,模型参数量大,计算量大,单机训练时间久
• 即使我们能将大模型放在一张 GPU 上,训练大模型需要的海量计算操作需要耗费很长时间。例如:用英伟达A100 显卡训练 175B 参数量的 GPT-3 模型,可能需要长达288年的时间
二、数据并行
数据并行是分布式训练模型中最直观的并行策略。在数据并行中,训练数据集被分割成多个子集,每个GPU分配到一个子集,并独立地计算梯度和更新权重。所有的GPU都有模型参数的完整副本,但在每个训练步骤中,它们处理不同的数据。为了同步各个GPU间的训练状态,通常在每步梯度计算之后进行梯度的汇总(AllReduce操作),以确保所有GPU上的模型参数得到一致的更新。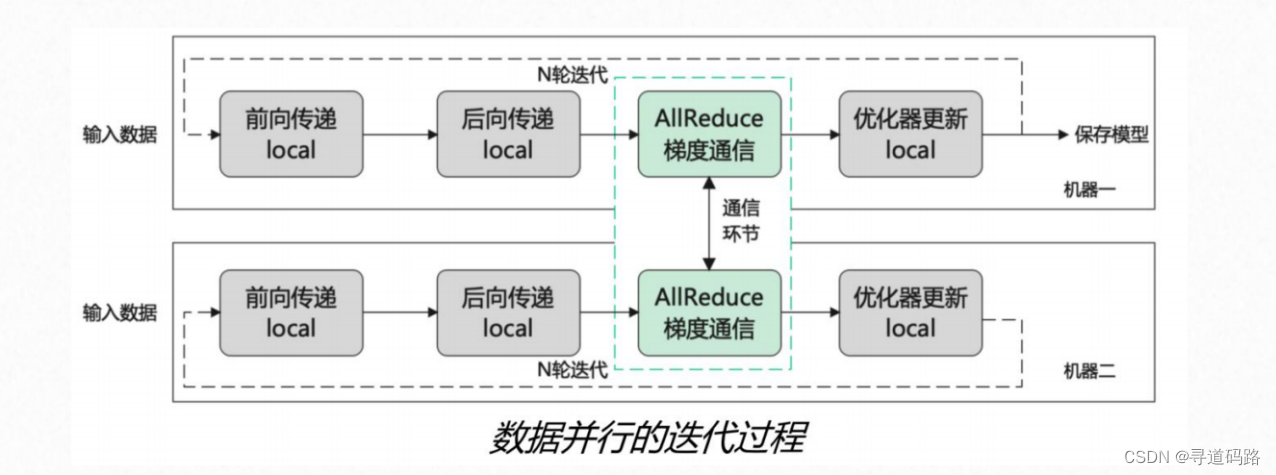
数据并行的优点在于其相对简单,易于实现,并且可以快速开始使用。然而,它的主要缺点是对显存的需求随着模型大小的线性增长;每张GPU都需要存储整个模型的状态。此外,当GPU数量很多时,通信开销可能成为瓶颈。
三、模型并行
模型并行涉及到将一个模型的不同部分分布到不同的计算资源上,从而允许单个GPU不需要持有整个模型的状态。这在大型模型无法装载到单个GPU显存中时特别有用。模型并行有两种主要形式:流水线并行和张量并行。
1、流水线并行(inter-layer)
流水线并行按照层的维度划分模型,不同层分布在不同的GPU上。例如,如果我们有4个GPU,我们可以将模型的前25%层放在第一个GPU上,接下来的25%层放在第二个GPU上,以此类推。这种策略可以减少任何单个GPU上的内存压力,但可能会引入延迟,因为一个GPU在继续其计算之前可能需要等待来自其他GPU的数据。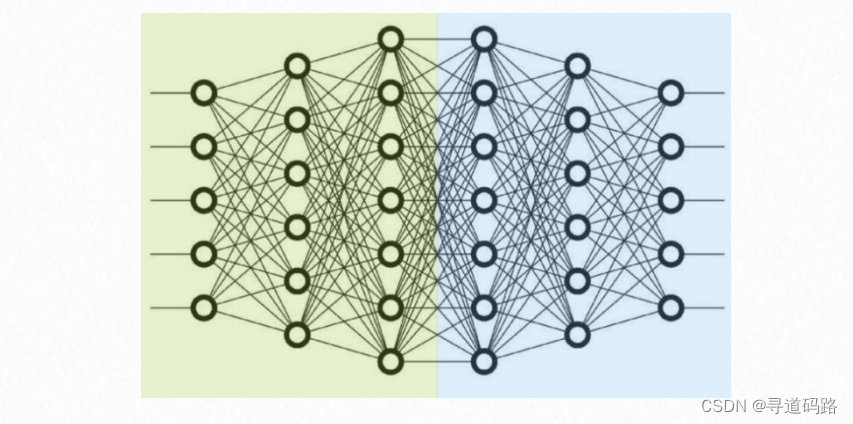
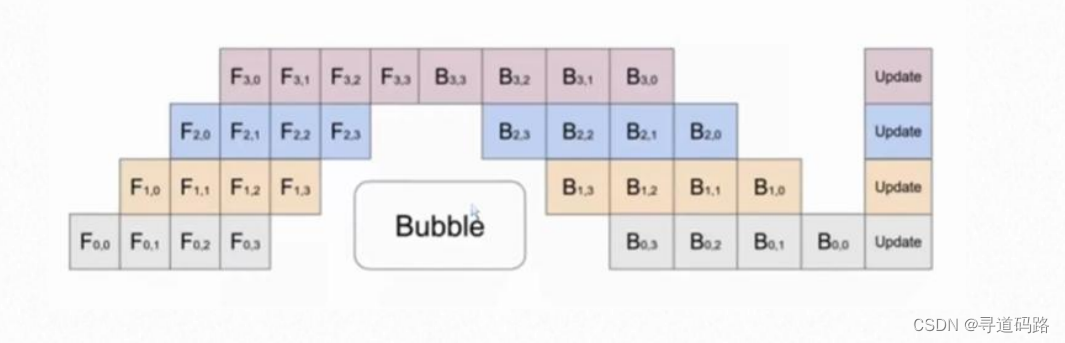
2、张量并行(intra-layer)
张量并行是在单个层内部进行并行化,将层的计算分摊到多个GPU上。对于每一层,输入特征图(input feature maps)可以被切分到各个GPU上,每个GPU只计算一部分特征图的相应部分。这样可以减少单个层操作所需的内存,并允许更大的模型或更大的批量在有限的硬件资源下进行训练。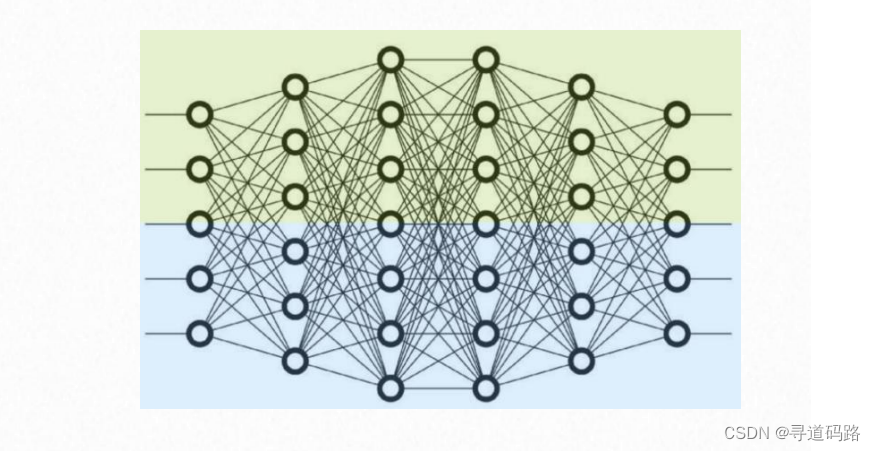
四、3D并行
3D并行是一个更为高级的策略,结合了数据并行、流水线并行和张量并行。通过这种方式,模型的不同层组(layer groups)分布到不同的GPU上,同时每个层组内部采用张量并行,而整个数据集则分割成多个子集以实现数据并行。3D并行能够更充分地利用硬件资源,允许在数百甚至数千个GPU上训练极其庞大的模型。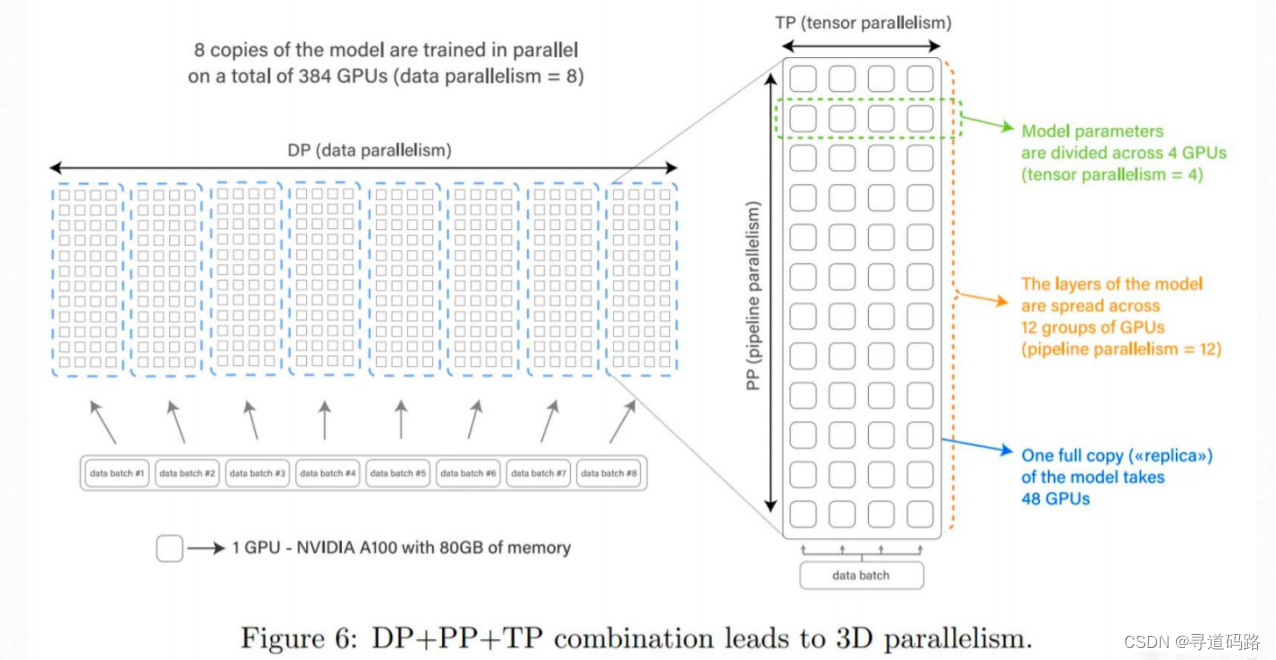
Bloom-176B预训练模型就是一个很好的例子。它使用了394张NVIDIA A100 80GB GPU(48 个节点) ,通过3D并行技术在大约3.5个月的时间内完成了预训练。这种策略不仅允许在多张GPU上训练大模型,而且优化了通信成本,提高了整体的训练效率。
五、DeepSpeed
DeepSpeed是一个由微软开发的开源深度学习优化库,它通过多种技术手段来加速大规模模型的训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。DeepSpeed还提供了一些辅助工具如分布式训练管理、内存优化和模型压缩等,帮助开发者更好地管理和优化大规模深度学习训练任务。
DeepSpeed里的核心技术是:ZeRO(ZeroRedundancyOptimizer)零冗余优化器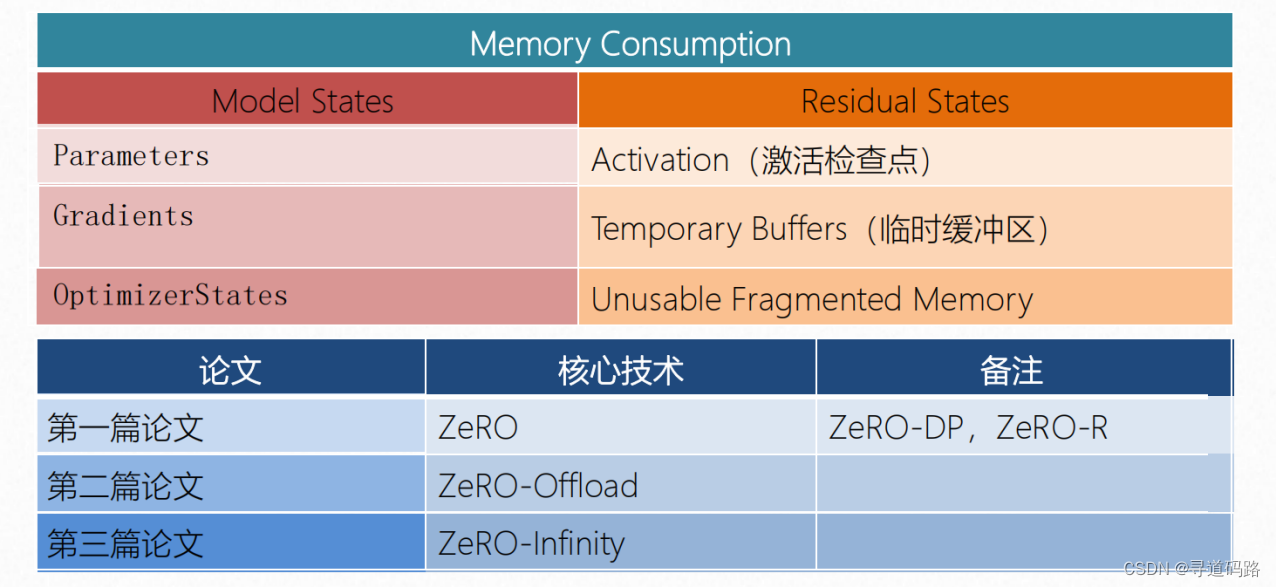
1、第一篇论文:ZeRO-DP
它通过消除数据并行中的冗余参数复制,显著减少了每个GPU所需的显存量。这允许在有限的资源下训练更大的模型。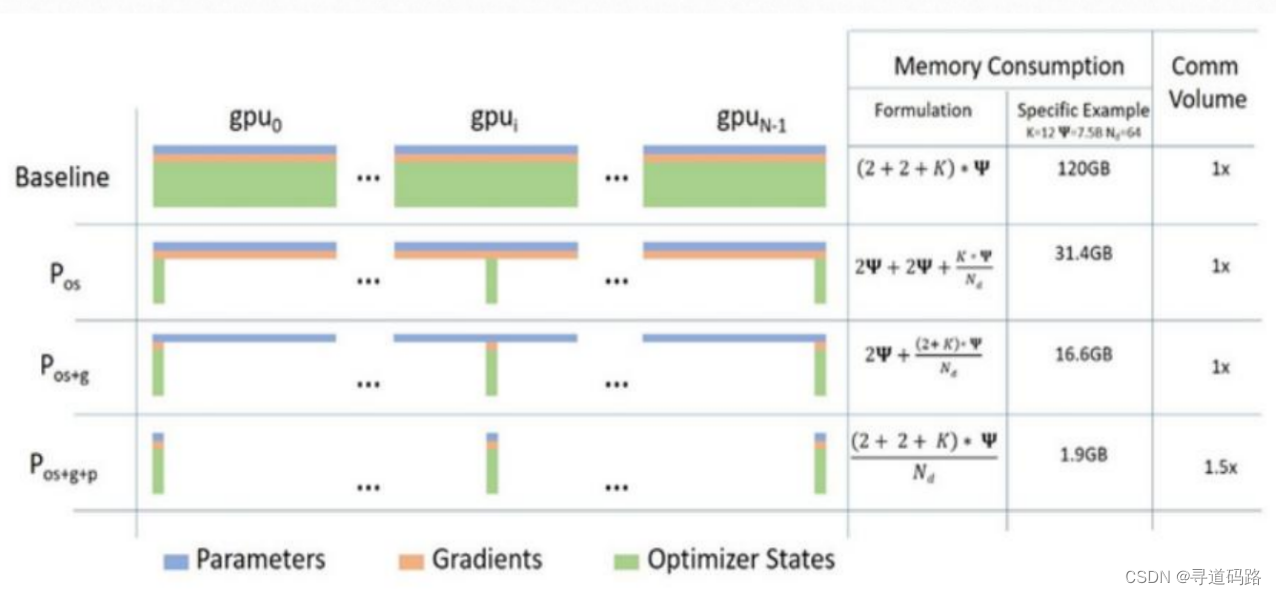

1)Activation的优化:前向传播的时候,需要存储一个激活值,因为后向传播的时候需要到。它的第一种优化方式就是:我不存储了,因为我知道是怎么计算的,用的时候重新计算一下就可以。第二种优化就是:这个激活值我计算出来了你也不是立马就用,那么我就先把存储到CPU里面,等用的
时候再从CPU里面去加载回来。
2)Temporary Buffer的优化:模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行AllReduce啥的,解决办法就是预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要传输的数据较小,则多组数据bucket后再一次性传输,提高效率。
3)Unusable Fragmented Memory的优化:显存出现碎片的一大原因是gradient checkpointing后,不断地创建和销毁那些不保存的激活值,解决方法是预先分配一块连续的显存,将常驻显存的模型状态和checkpointed activation存在里面,剩余显存用于动态创建和销毁 activation
2、第二篇论文:ZeRO-Offload
这是一种将模型状态的某些部分从GPU内存转移到CPU内存的方法,以进一步减少GPU上的内存需求。这种方法有助于缓解当GPU内存不足时的问题。一张卡训不了大模型,根因是显存不足,ZeRO-Offload的想法很简单:显存不足,内存来补。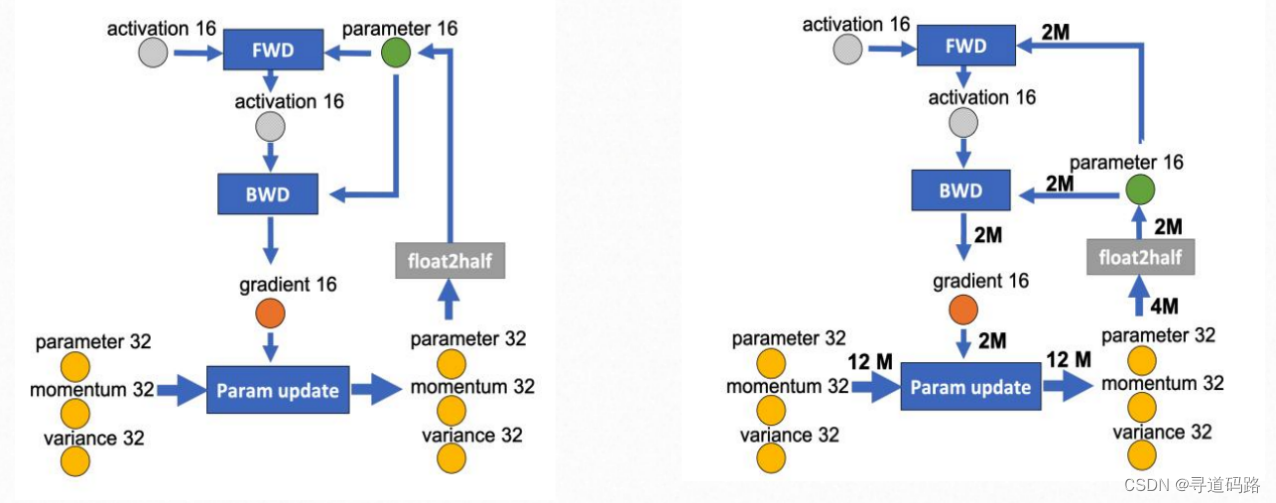
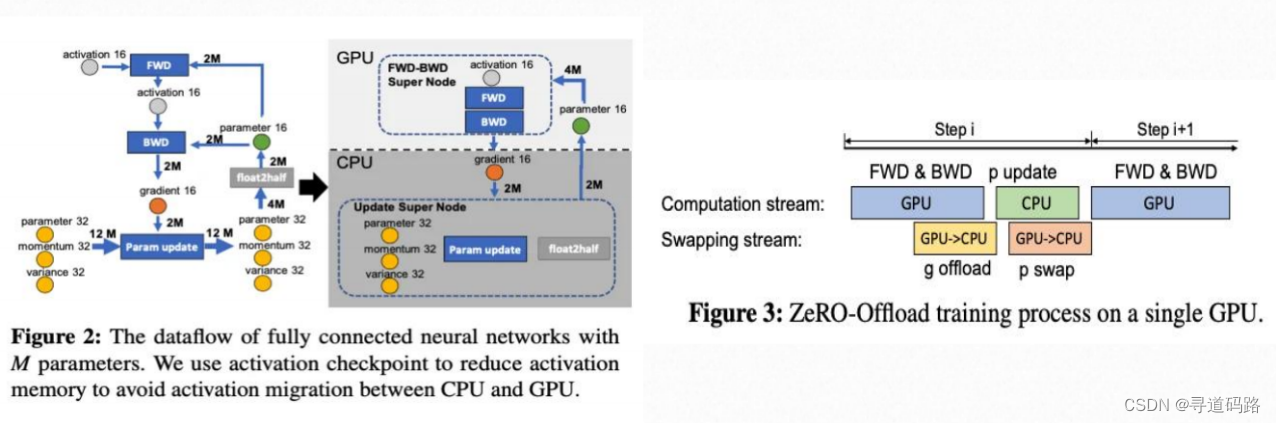
3、第三篇论文:ZeRO-Infinity
从GPT-1到GPT-3,两年时间内模型参数0.1B增加到175B,而同期,NVIDIA交出的成绩单是从V100的32GB显存增加A100的80GB
该技术通过使用NVMe固态硬盘扩展GPU和CPU内存,使得可以处理更大规模的模型。ZeRO-Infinity允许训练具有万亿级别参数的模型,并且可以在数千个GPU上进行扩展。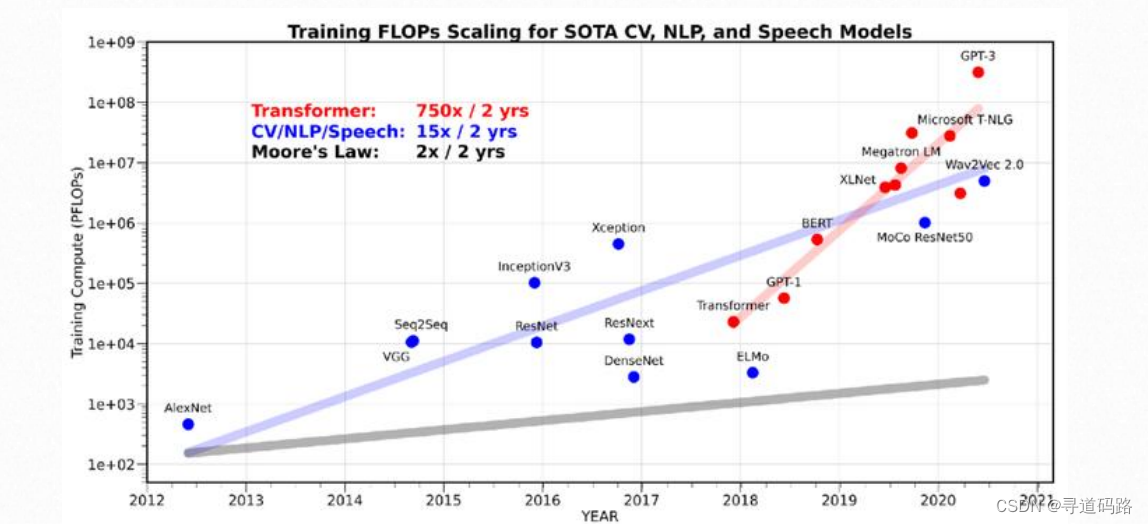
4、DeepSpeed总结
这三篇论文共同构成了DeepSpeed项目的理论基础,它们不仅展示了如何通过技术创新来解决大规模模型训练中的挑战,还为深度学习社区提供了实用的工具和方法。通过这些优化技术,DeepSpeed能够支持在现代GPU集群上训练具有数万亿参数的模型,这对于推动人工智能领域的进步具有重要意义。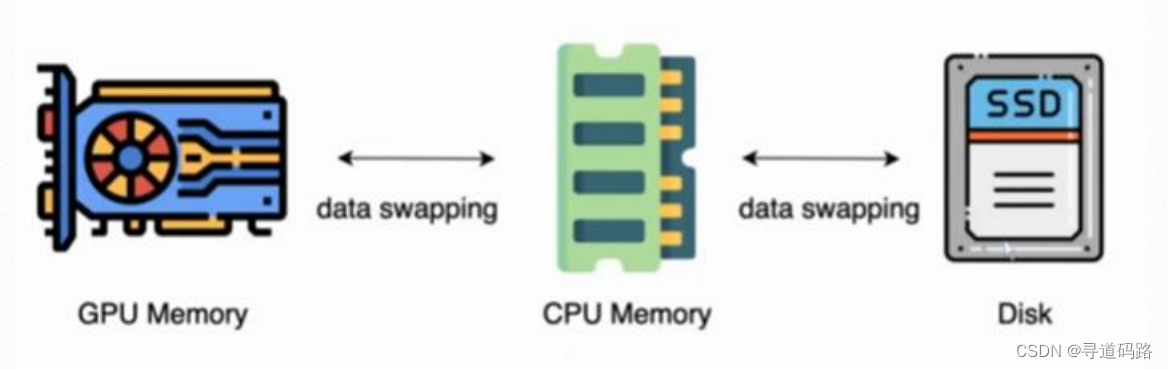
六、资源不够怎么办?
在面对计算资源有限的情况下,尤其是当我们不具备足够强大的GPU硬件来满足大规模深度学习模型训练的需求时,我们可以采取以下策略来优化我们的训练过程:
1、微调量化版本
当标准计算资源不足以应对庞大的模型和数据集时,可以考虑使用模型的量化版本进行微调。量化可以减少模型参数的精度,从而降低内存占用和提高运算速度。在微调脚本中添加–quantization_bit 8或–quantization_bit 4参数启动量化模式。然而,需要注意的是,量化可能会对模型的准确性产生一定的影响,因此建议在非生产环境中使用,并仔细评估量化后的模型性能。
2、多卡微调
即使单张GPU的内存不足以加载整个模型,我们依然可以通过将模型分布到多张GPU上进行并行训练,这就是多卡微调。通过这种方式,每张GPU只负责模型的一部分计算和存储,从而实现整体模型的高效训练。
3、DeepSpeed方案
DeepSpeed提供了一套高级的分布式训练优化方案,专门针对大模型的训练。其核心是ZeRO技术,能够显著减少多卡训练时的内存冗余,使得训练过程更加高效。此外,DeepSpeed支持多种并行策略,如流水线并行、张量并行等,可以根据具体的硬件配置和模型需求灵活选择最合适的并行策略。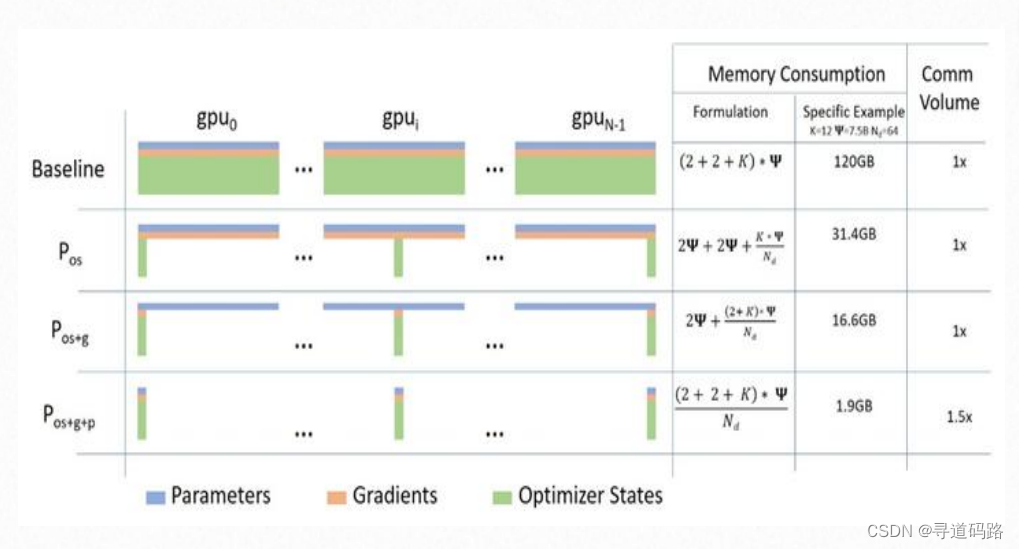
七、多卡+DeepSpeed微调实战
1、服务器资源准备
2张24G的显卡
使用前,资源消耗情况: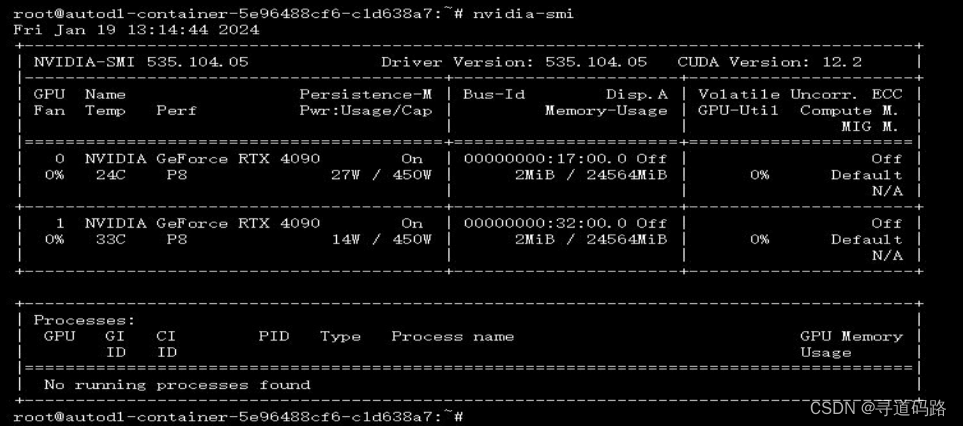
使用后,资源消耗情况: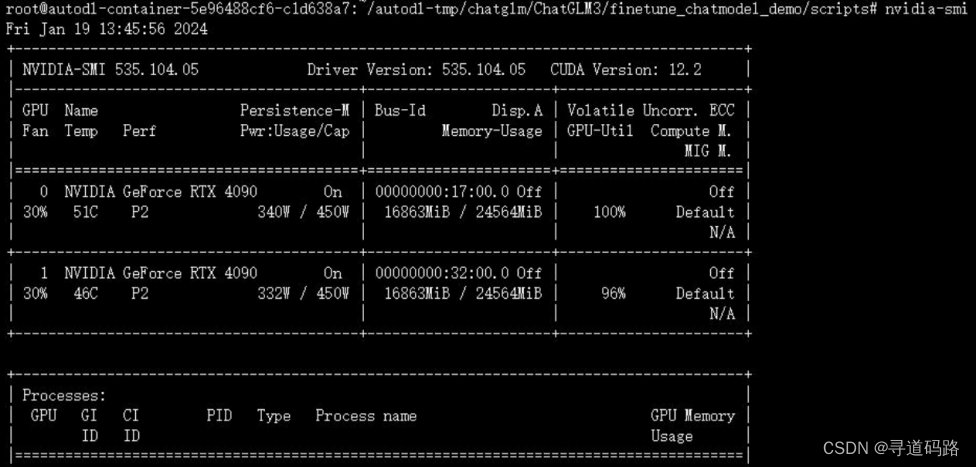
2、多卡微调
通过以下代码执行 单机多卡/多机多卡 运行,这是使用 deepspeed 作为加速方案的,需要安装 deepspeed。
执行脚本如下:
OMP_NUM_THREADS=1 torchrun --standalone --nnodes=1 --nproc_per_node=2 finetune_hf.py data/AdvertiseGen_fix/ /root/autodl-tmp/model/chatglm3-6b configs/lora.yaml configs/ds_zero_2.json 执行参数说明:
- OMP_NUM_THREADS=1: 设置OpenMP线程数为1,这是为了确保在多线程环境中只有一个线程被使用。 torchrun --standalone --nnodes=1 --nproc_per_node=2: 这是PyTorch的分布式训练命令,
- 其中:
standalone: 表示使用独立模式运行分布式训练。
nnodes=1: 指定使用的节点数量为1。
nproc_per_node=2: 指定每个节点上使用的进程数量为2。(即2张GPU卡) - finetune_hf.py: 微调脚本的文件名。
- data/AdvertiseGen_fix/: 数据集的路径。
- /root/autodl-tmp/model/chatglm3-6b: 预训练模型的路径。
- configs/lora.yaml:配置文件的路径,用于指定微调过程中的各种参数和设置。
- configs/ds_zero_2.json: deepspeed配置文件的路径。
3、deepspeed配置文件
ds_zero_2.json
{ "fp16": { // 半精度浮点数(FP16)训练的配置 "enabled": "auto", // 是否启用FP16训练,"auto"表示根据硬件自动选择 "loss_scale": 0, // 损失缩放因子,用于防止数值下溢 "loss_scale_window": 1000, // 计算损失缩放因子的滑动窗口大小 "initial_scale_power": 16, // 初始损失缩放因子的幂次 "hysteresis": 2, // 损失缩放因子调整的滞后程度 "min_loss_scale": 1 // 最小损失缩放因子 }, "bf16": { // 低精度浮点数(BF16)训练的配置 "enabled": "auto" // 是否启用BF16训练,"auto"表示根据硬件自动选择 }, "zero_optimization": { // ZeRO优化的配置 "stage": 2, // ZeRO优化的阶段,2表示使用ZeRO-2 "allgather_partitions": true, // 是否对梯度进行分区聚合 "allgather_bucket_size": 5e8, // 分区聚合的桶大小 "overlap_comm": true, // 是否在计算和通信之间重叠以提高效率 "reduce_scatter": true, // 是否使用reduce-scatter操作来分散梯度 "reduce_bucket_size": 5e8, // reduce-scatter操作的桶大小 "contiguous_gradients": true // 是否使梯度连续以提高内存访问效率 }, "gradient_accumulation_steps": "auto", // 梯度累积步数,"auto"表示根据硬件自动选择 "gradient_clipping": "auto", // 梯度裁剪策略,"auto"表示根据模型类型自动选择 "steps_per_print": 2000, // 每隔多少步打印一次训练信息 "train_batch_size": "auto", // 训练批次大小,"auto"表示根据硬件自动选择 "train_micro_batch_size_per_gpu": "auto", // 每个GPU的训练微批次大小,"auto"表示根据硬件自动选择 "wall_clock_breakdown": false // 是否输出训练过程中的时间分解信息 } 4、微调效果验证
使用微调后的模型进行推理验证,在 inference_hf.py 中放有推理验证的接口
可以在 finetune_demo/inference_hf.py 中使用我们的微调后的模型,仅需要一行代码就能简单的进行测试。
python inference_hf.py output/checkpoint-3000/ --prompt "鱼尾裙" 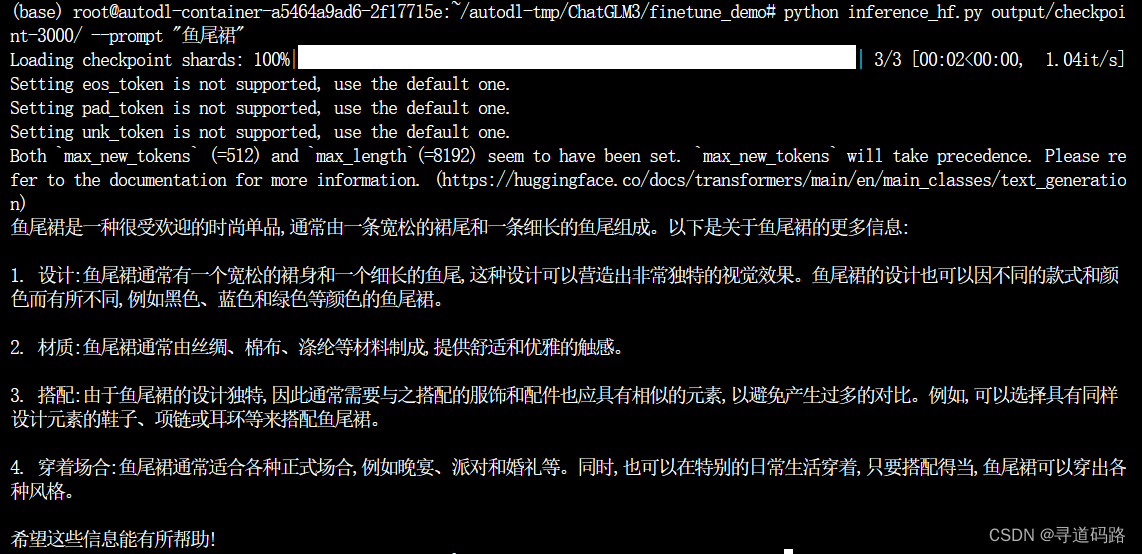
八、多卡部署遇到的问题
NotImplementedError: Using RTX 3090 or 4000 series doesn't support faster communication broadband via P2P or IB. Please set `NCCL_P2P_DISABLE="1"` and `NCCL_IB_DISABLE="1" or use `accelerate launch` which will do this automatically. 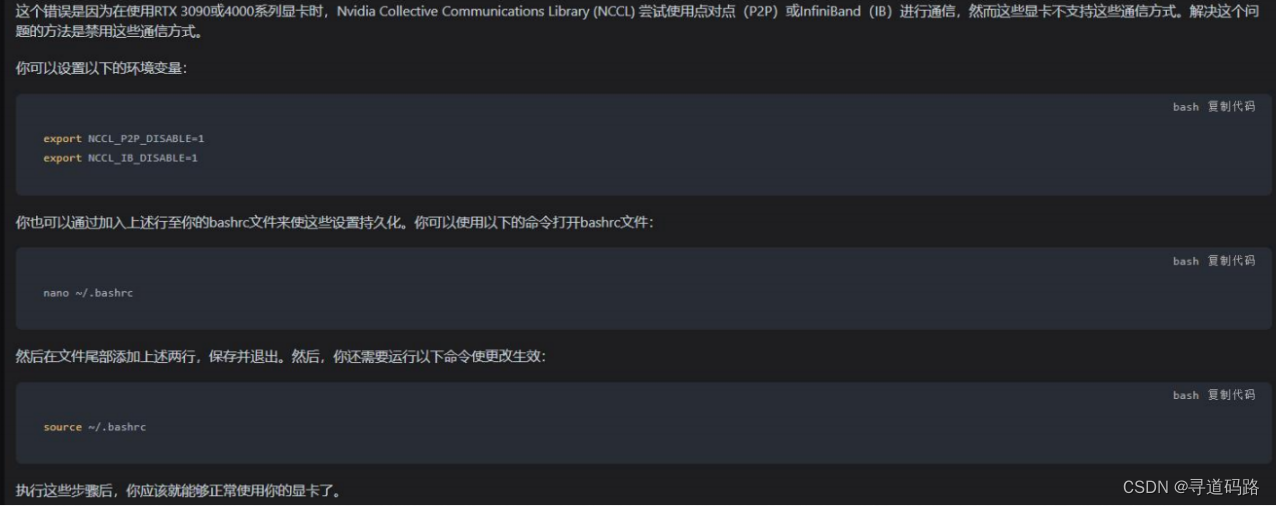
总结
通过结合多卡并行训练与DeepSpeed技术,我们可以有效地进行大规模模型的微调。尽管在部署过程中可能会遇到一些技术挑战,但通过合理的资源配置和参数调整,我们能够充分发挥硬件潜力,加速模型训练过程,最终达到令人满意的微调效果。
参考
[1] ZeRO-Offload: Democratizing Billion-Scale Model Training
[2] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[3] ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
