
阅读量:10
导读
今天为大家介绍由微软Azure AI团队最新提出的新颖视觉基础模型:Florence-2,该模型采用了一种基于prompt的统一表示方法,广泛适用于各种 CV 和 Visual-Language 任务。与现有的 CV 大模型在迁移学习方面表现出色不同,它在执行各种任务时可以通过简单的指令来处理不同的空间层次和语义粒度的复杂性。
微软 Azure AI 团队新作 | Florence-2: 解锁视觉新境界,万能感知引领未来!
Florence-2 的设计理念是采用文本提示作为任务说明来支持字幕生成(image captioning),目标检测(object detection)、定位(grounding)和分割(segmentation)。然而,这种多任务学习设置需要大规模、高质量的标注数据。为此,本文的另一个突出贡献便是开发了FLD-5B,包括对 1.26 亿张图像进行了 54 亿次全面的标注,当中采用了自动图像标注和模型优化的迭代策略,如下图所示:
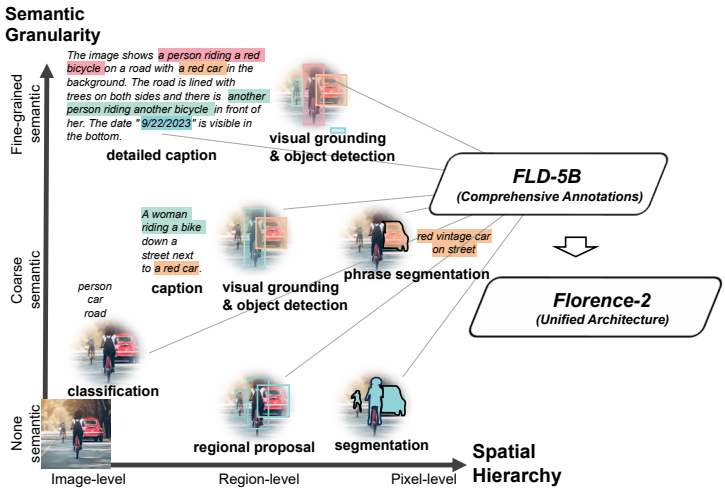
最终,采用序列到序列的结构来训练 Florence-2,使其能够执行多样且全面的视觉任务,并成为一个强大的视觉基础模型,具有 SOTA 级别的零样本和微调能力。据文中介绍,预训练的 Florence-2 骨干在下游任务上显著地提高了性能,例如 COCO 目标检测和实例分割,以及 ADE20K 语义分割,直接超过了监督学习和自监督学习模型。另外,与在 ImageNet 上预训练的模型相比,所提方法在训练效率上提高了 4 倍,并在 COCO 和 ADE20K 数据集上分别使用 Mask-RCNN、DINO 和 UperNet 基础框架取得了分别为 6.9、5.5 和 5.9 个点的实质性改进。
背景
在正式介绍方法部分之前,我们重新回顾下构建视觉基础模型的三种预训练范式,即:
- 有监督:如 ImageNet Classification;
- 自监督:如 SimCLR,MoCo,BEiT,MAE;
- 弱监督:如 CLIP,Florence,SAM;
上述范式尽管取得了一定效果,但受制于单一任务学习框架的约束。例如,对于有监督预训练,其在对象识别方面表现出色但缺乏可迁移性;自监督算法揭示了复杂的特征,但可能过分强调某些属性;而对于弱监督方法,其利用非结构化的文本标注,但只能产生图像级的理解。
因此,为了构建适用于各种应用的统一视觉基础模型,必须探索创新的预训练策略,克服单一任务的限制,同时能够有效地整合文本和视觉语义。为此,作者借鉴多任务学习的范式,制定了一系列的多任务学习目标,每个目标都针对视觉理解的特定方面,其包括三个不同的学习目标,每个目标都处理不同层次的细节和语义理解:
- 图像级理解任务擅长捕捉高层次的语义,通过语言描述促进对图像的全面理解。它们使模型能够理解图像的整体背景,并在语言领域中把握语义关系和语境细微之处。这方面的任务包括图像分类、字幕生成和图像问题。
- 区域/像素级别的识别任务促进了对图像内对象和实体的详细定位,捕捉了对象与它们空间背景之间的关系。此方面的任务包括目标检测、分割和目标物指代理解。
- 细粒度的视觉-语义对齐任务需要对文本和图像进行细粒度的理解。它涉及到定位与文本短语对应的图像区域,如对象、属性或关系。这些任务挑战着捕捉视觉实体及其语境的局部细节以及文本和视觉元素之间的互动。
可以看出,Florence-2 模型是通过多任务学习,同时关注底层细节和高层次语义理解,使得模型能够更全面、深入地理解视觉信息,并最终学得一个通用的用于视觉理解的表示。
方法
Florence-2 是一个通用表示学习的基础模型,能够通过一组权重和统一的架构处理各种视觉任务。
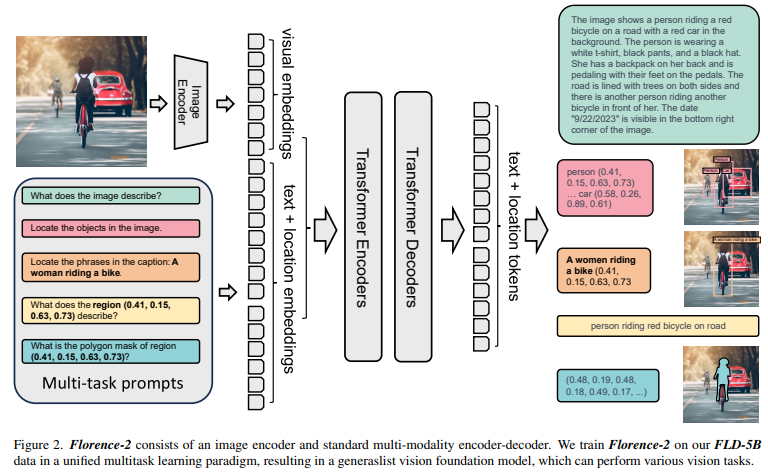
如上面的框架图所示,Florence-2 整体采用了序列到序列的学习范式,将上述提到的任务集成到一个共同的语言建模目标下。该模型以图像和任务提示作为任务说明,并以文本形式生成最终结果。首先,该模型使用一个视觉编码器将图像转换为视觉标记嵌入,然后将其与文本嵌入连接,并通过基于transformer的多模态编码器-解码器生成响应。接下来,让我们详细过一遍每个模型组件。
序列到序列框架
Florence-2 以统一的方式解决各种视觉任务。每个任务被制定为一个“翻译”问题,即给定输入图像和特定地任务提示,生成相应的输出响应。根据任务的不同,提示和响应可以是文本或区域:
- 文本:当提示或答案是普通文本而没有特殊格式时,其保持在最终的输出格式中。
- 区域:对于区域特定任务,作者向 tokenizer 的词汇表中添加位置标记,表示量化的坐标。具体地,其创建了 1000 个 bin,类似于其它工作,用于表示根据任务要求制定的区域。具体有三种区域表示形式:矩形框、四边形框和多边形框。通过扩展 tokenizer 的词汇表以包括位置标记,最终使模型能够以统一的学习格式处理区域特定信息。这样做消除了为不同任务设计任务特定head的需要,允许将注意力放到数据的处理上,而不是搞多个架构去handle。
网络架构
Florence-2 中使用标准的编码器-解码器 transformer 架构来处理视觉和语言标记嵌入,其中视觉编码器用的是 DaViT:
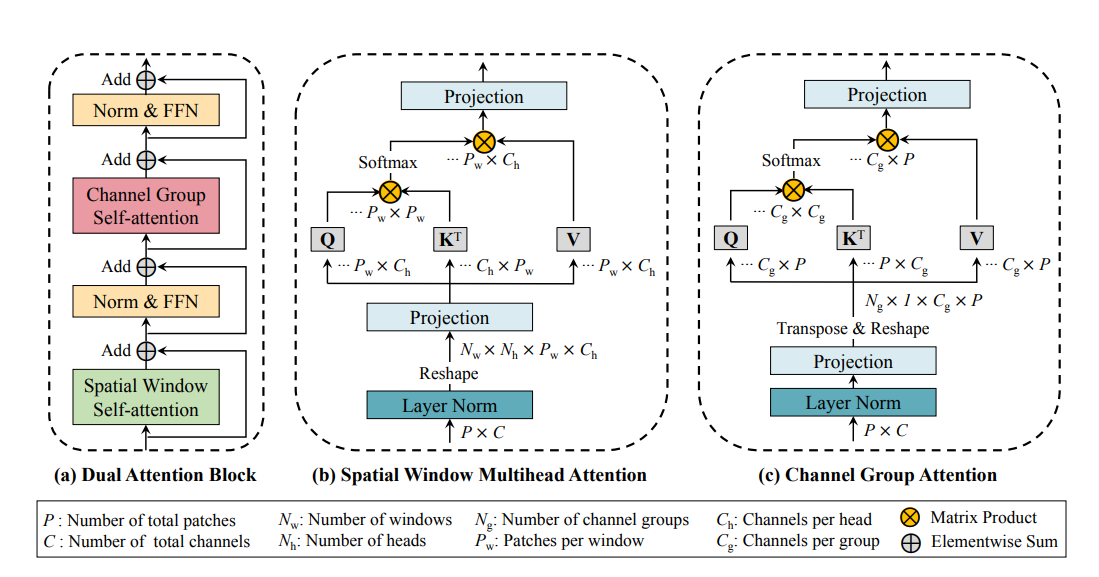
具体地,首先使用扩展的语言tokenizer和word embedding层获取提示文本嵌入Tprompt。然后,将视觉标记嵌入与提示嵌入连接起来,形成多模态编码器模块输入X = [V’, Tprompt],其中V’通过对V进行线性投影和LayerNorm层的应用得到,以进行维度对齐。
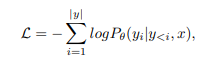
最后,对于所有任务,给定由图像和提示组合而成的输入x和目标y,使用标准的带有交叉熵损失的语言建模,其中θ是网络参数,|y|是目标标记的数量。这个目标函数适用于在所有任务上进行训练。
数据
前面说到,Florence-2 是基于一个包含 126M 图像、500M 文本注释、1.3B 文本区域注释和 3.6B 文本短语区域注释的超大高质量数据集构建的,这个才是核心要素,其实网络架构的差异真心不大。下面我们按照下方数据构建引擎示意图拆解为三个部分进行细讲。
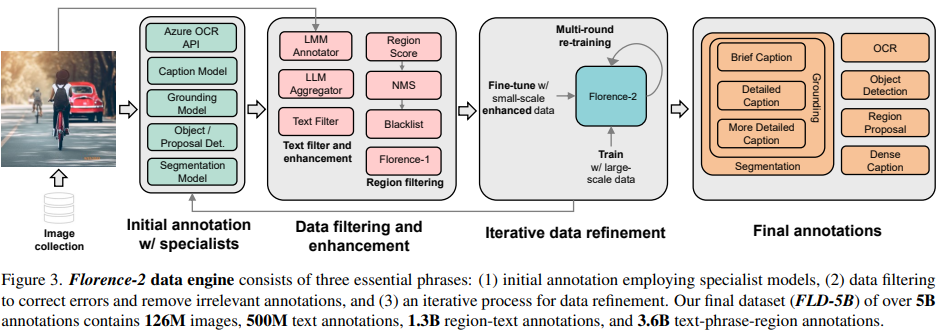
图像采集
整个构建过程始于对三个关键任务的识别,这三个任务作为图像语料库的主要来源:图像分类、目标检测和图像字幕生成,其中涉及到的五个数据集分别是:ImageNet-22k,Object 365,Open Images,Conceptual Captions和经过筛选的LAION数据集。通过将这些数据集合并,最终得到了一个包含总计1.26亿张图像的数据集。
数据标注
为了适应多任务,作者将标注分为三个注释类别:文本、区域-文本对和文本-短语-区域三元组。

制定好目标后,按照以下三个关键阶段进行数据标注:
初始标注使用特定模型: 在这个阶段,首先使用特定的模型生成合成标签,这些模型大都来自经过离线训练好的模型以及云平台上的在线api服务。这些合成标签与某些图像数据集可能已经存在的部分标注(例如coco的80个类别)结合,以增强标注的覆盖范围和多样性。
数据过滤和增强: 为了提高标注的质量,接下来当然要采取一定的过滤手段来清洗。对于文本标注,他们使用解析工具提取对象、属性和动作,并通过过滤出含有过多对象的文本来减少噪音。对于区域标注,直接剔除低阈值的框和使用 NMS 来减少冗余或重叠的边界框。
迭代数据细化: 利用经过过滤的初始标注,我们便可以训练一个多任务模型,该模型可用于处理数据序列。在模型对训练图像的评估中,实验发现模型预测的显著改进。随后,我们将更新后的标注与原始标注集成,并将模型进行另一轮训练迭代。这个循环的细化过程逐渐提高了训练数据集的质量。对于初始标注阶段由于数据不足而跳过的任务,作者利用迭代训练的模型进行预训练,然后通过微调将其应用于包含1.26亿张图像的大规模数据集。
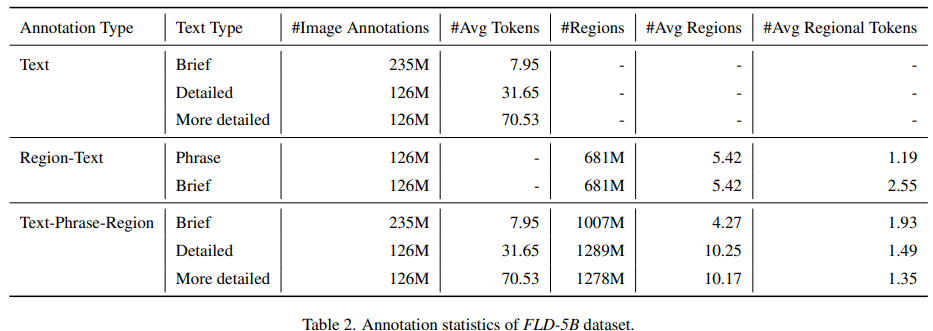
最后,简单总结下这三个注释类别:
文本注释:分为不同粒度的文本,从简要到更详细,通过专家模型和LLM生成,以及迭代细化过程,确保注释质量。
区域-文本对:分为文本区域和视觉对象区域,通过OCR和目标检测进行标注,使用简要文本生成注释,确保相关性。
文本-短语-区域三元组: 结合文本、名词短语和区域,通过Grounding DINO和SAM模型生成,应用数据过滤以提高注释的准确性和相关性。
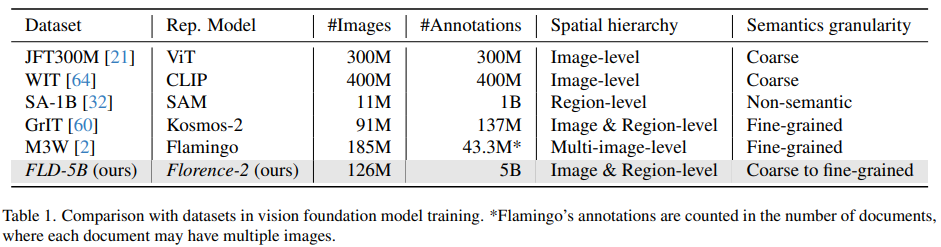
比较下与现有大规模数据集的区别:
实验
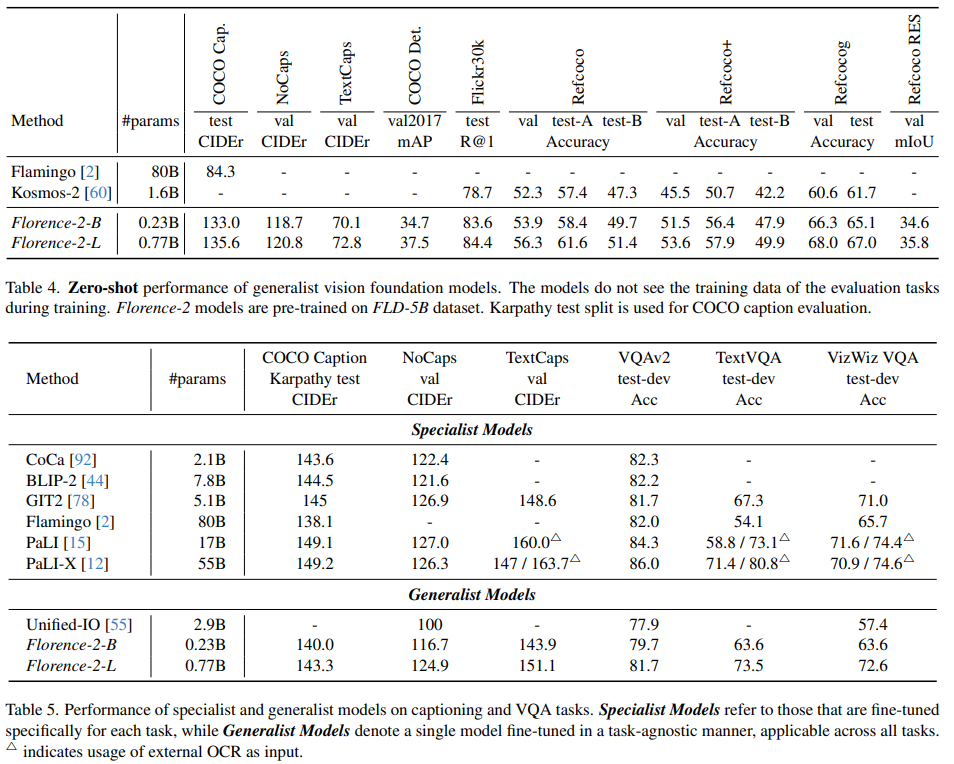
具体的实验结论大家可以看下原文,我们先膜拜下 FLD-5B 数据集的一些示例,看下质量如何:




最后展示下 Florence-2 的可视化结果。
Detailed Image Caption

Visual Grounding

Dense Region Caption

Open Vocabulary Object Detection

Ocr with region

Region to Segmentation

Comparison with LMMs on Detailed Image Caption Task

Comparison on detailed caption and grounding tasks

Comparison on detailed caption and grounding tasks

总结
Florence 项目致力于开发一个基础的视觉模型,具有多样的感知能力,涵盖空间层次和语义粒度。为此,作者构建了 FLD-5B 数据集,其中包含了 126M 张图像,配对有由 Florence 数据引擎收集的 50B 全面的注释。随后,通过全面的多任务学习以统一的方式在这个丰富的数据集上对 Florence-2 进行预训练。Florence-2 展示出卓越的零样本能力,覆盖广泛的视觉任务,包括字幕生成、目标检测、视觉定位和引用分割等。
从今天的这篇论文再次验证了,其实网络架构的差异真的不大,核心还是构建一个高质量的数据集,无论是 CV 还是 NLP 抑或是多模态。至于为什么倾向于选择 Transforemr 而不是 CNN 作为统一架构,大概是为了数据处理起来更加方便,方便对齐不同的模态。好了,讲到这里,如果你也对基础视觉模型,大语言模型,抑或是多模态学习等方向感兴趣等,欢迎添加vx:cv_huber,备注“学习”,一起加入技术群交流学习!
