
阅读量:5
准备
python包vllm
用来加载模型,启动服务
模型文件
可以使用官方:mistralai/Codestral-22B-v0.1
我是使用AQW 4bit量化 solidrust/Codestral-22B-v0.1-hf-AWQ
也可以选择GPTQ 4bit量化,可以看看vllm支持哪个格式
如果是比较旧的显卡可能不支持量化版本模型
vs code 的continue插件

配置
使用vllm加载Codestral启动兼容OpenAI 接口服务
启动命令:
python -m vllm.entrypoints.openai.api_server \ --model /data/models/Codestral-22B-v0.1-hf-AWQ \ --served-model-name codestral \ --host 0.0.0.0 \ --port 9000 \ --quantization awq 如果显存不够可以考虑:
1. 多卡,使用参数 --tensor-parallel-size
2. 减少模型上下文长度: 使用参数 --max-model-len
配置vs code 的continue插件
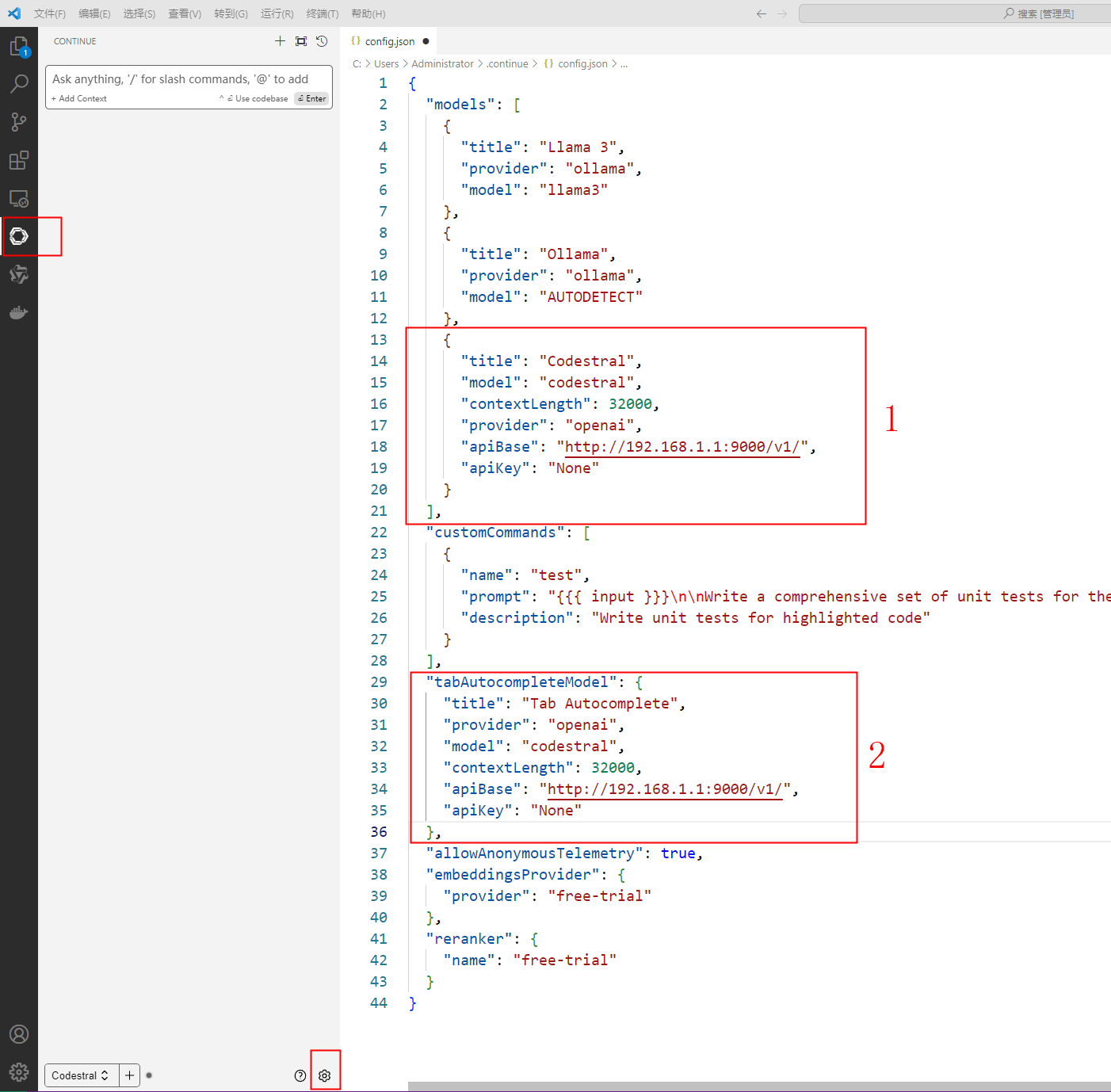
修改了红色框1和2的部分
注意apiBase的ip是部署模型的服务器ip,model和端口号要跟vllm启动命令一致。
