
阅读量:7
车牌识别系统
YOLOv5和LPRNet的车牌识别系统结合了深度学习技术的先进车牌识别解决方案。该系统整合了YOLOv5目标检测框架和LPRNet文本识别模型
1. YOLOv5目标检测框架
YOLO是一种先进的目标检测算法,以其实时性能和高精度闻名。YOLOv5是在前几代基础上进行优化的版本,包括更高效的网络结构、数据增强策略和训练技巧,能够在保持高识别率的同时降低计算开销。
#yolov5示例代码 import cv2 import time from yolov5.detect import detect # 加载模型 model = 'yolov5s.pt' # 可以选择 yolov5s, yolov5m, yolov5l, yolov5x 等不同大小的模型 conf_thres = 0.5 # 置信度阈值 device = 'cpu' # 使用 CPU 进行检测,也可以设置为 '0'(如果你的机器有NVIDIA GPU) image_path = 'path_to_your_image.jpg' # 图像路径 image = cv2.imread(image_path) # 读取图像 # 进行检测 results = detect(image, model, conf_thres, device) # 遍历检测结果 for x1, y1, x2, y2, conf, cls in results: # 绘制矩形框 cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2) # 显示类别和置信度 cv2.putText(image, f'{cls} {conf:.2f}', (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2) # 显示图像 cv2.imshow('YOLOv5 Detection', image) cv2.waitKey(0) # 等待按键 cv2.destroyAllWindows() # 如果是使用摄像头,别忘了在最后释放资源 # cap.release()2. LPRNet文本识别模型
LPRNet是专为车牌字符识别设计的深度神经网络,由Intel公司提出并商用。它能够处理各种光照、角度和遮挡条件下的车牌图像。
#示例代码 import torch import torch.nn as nn import torchvision.transforms as transforms from PIL import Image class LPRNet(nn.Module): def __init__(self, num_classes): super(LPRNet, self).__init__() self.layer1 = nn.Conv2d(3, 64, kernel_size=3, padding=1) # 示例卷积层 self.fc = nn.Linear(some_feature_size, num_classes) # 假设的全连接层 def forward(self, x): x = self.layer1(x) x = x.view(x.size(0), -1) # 扁平化 x = self.fc(x) return x model_path = 'path_to_your_lprnet_model.pth' model = LPRNet(num_classes=len(CHARS) + 1) # CHARS 是字符集,包括车牌可能的所有字符和一个额外的类别(如背景或填充) model.load_state_dict(torch.load(model_path)) model.eval() transform = transforms.Compose([ transforms.Resize((94, 24)), # 假设输入图像大小为 94x24 transforms.ToTensor(), # 可能还需要其他预处理步骤,如归一化等 ]) image_path = 'path_to_your_license_plate_image.jpg' image = Image.open(image_path).convert('RGB') image = transform(image) image = image.unsqueeze(0) # 增加批次维度 with torch.no_grad(): output = model(image) 系统工作原理
YOLOv5-LPRNet车牌识别系统的工作流程大致如下:
- 车牌检测:首先,通过YOLOv5目标检测框架对输入图像进行车牌检测,定位出车牌的位置。
- 车牌识别:然后,将检测到的车牌区域送入LPRNet文本识别模型进行字符识别,输出车牌号码。
- 智能交通:用于监控摄像头数据的实时分析,帮助交通管理部门跟踪车辆信息。
- 停车场管理:实现自动化进出管理,无需人工干预。
- 汽车租赁服务:方便追踪车辆位置,保障资产安全。
该车牌识别系统项目
链接: https://pan.baidu.com/s/1PXl08xpyaZ3OizeNZg5C3w 提取码: hz9z 模型文件 闲鱼:鳄鱼的眼药水
搭建环境
1.使用conda或者venv创建新的环境 conda create -n yolo-lprnet python==3.7 #conda python3.7 -m venv yolo-lprnet #venv 2.安装opencv pip install opencv-python==4.1.1.26 #不建议opencv版本过高 pip install opencv-contrib-python==4.1.1.26 3.安装pyside6 pip install pyside64.安装torch和cuda #如果没有cuda的话我们可以选择使用cpu推理 pip install torch==1.10.1+cu102 torchvision==0.11.2+cu102 -f https://download.pytorch.org/whl/cu102/torch_stable.html #这里会很慢,如果没有梯子请到闲鱼或csdn私信我拿网盘安装包 #用其他版本也行,但我没测试过5.之后进入项目主目录,就可直接运行 python detect.py有ui版本
- ui界面(左上角选择整个文件夹里的车牌图片或者是选择一张图片进行检测,左侧的是原始图像,右侧的是一个车牌检测后的图片,车牌信息标在框上)

- 使用摄像头

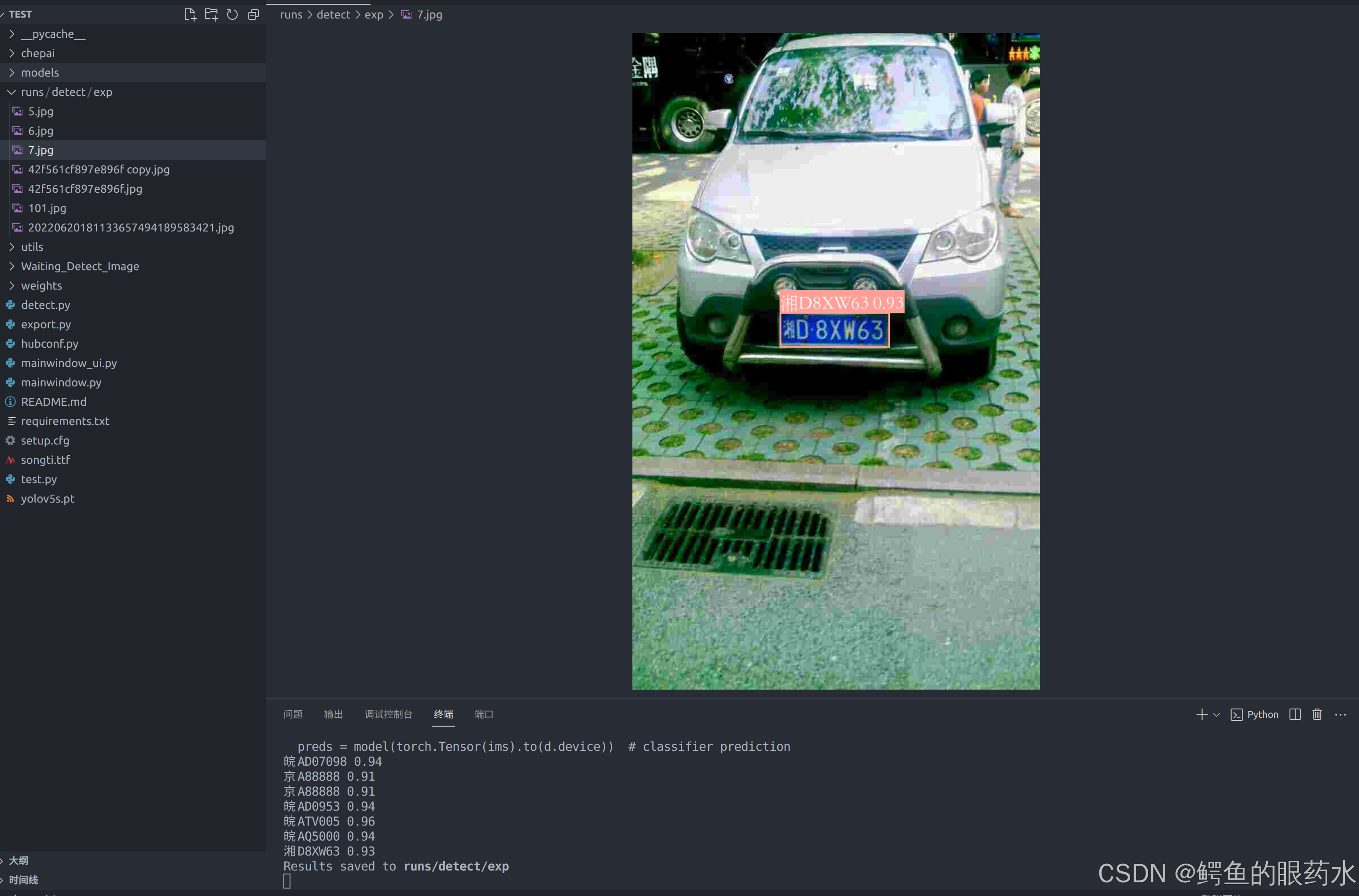
无ui版本
- 检测到以后会输出到特定的文件夹下,终端打印车牌的号码
- 摄像头使用opencv显示

到此就结束了
