阅读量:3
web自动化测试2
前言:使用Selenium框架进行简单web端UI自动化测试,简单的以百度搜索为例,复杂的模拟访问12306登陆、购票操作。
1. 设计用例的方法——selenium API
1.1 基本元素定位
web端-浏览器右键-检查,可以查看各个元素的id、class、name、text、XPath等,需要唯一才可精准定位;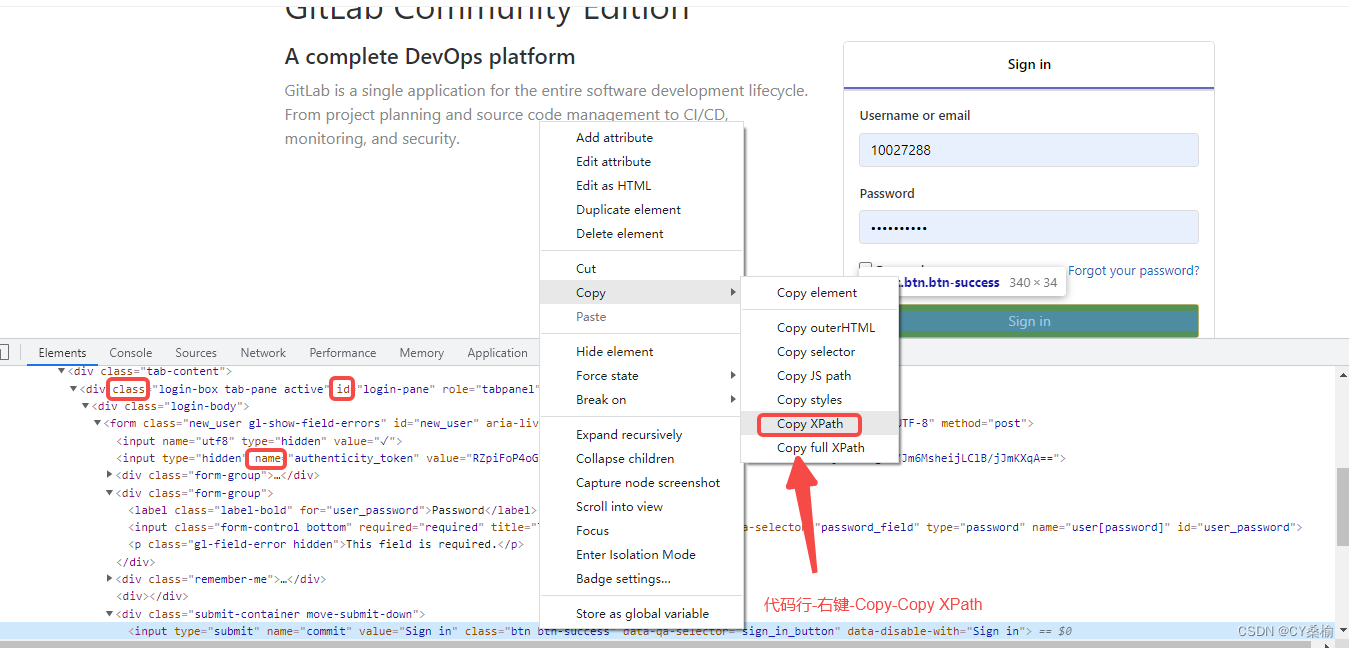
适用selenium 4.6以上语法如下:
1)定位单个唯一元素
- driver.find_element(By.XPATH,‘XPATH’)——XPath路径如上图获取,是唯一的;
- driver.find_element(By.CLASS_NAME,‘CLASS_NAME’)——用Class名称查找;
- driver.find_element(By.CSS_SELECTOR,‘CSS_SELECTOR’)——用CSS选择器查找;
- driver.find_element(By.ID,‘ID’)——用ID查找;
- driver.find_element(By.LINK_TEXT,‘LINK_TEXT’)——用永超链接查找;
- driver.find_element(By.PARTIAL_LINK_TEXT,‘PARTIAL_LINK_TEXT’)——用部分超链接查找;
- driver.find_element(By.TAG_NAME,‘TAG_NAME’)——用标签名查找;
2)定位一组元素
- switch_to.frame("框架’')——定位到页面所有input框;
inputs=driver.find_elements(By.TAG_NAME, "input") for input in inputs: # 遍历定位到的input,若元素为单选框,则点击选中 if input.get_attribute('type')=='checkbox': input.click() 3)定位多窗口/多框架
- switch_to.frame("框架id’')——定位到某层级内的框架;
- switch_to.default_content()——返回默认/最外层界面;
举例:
import switch as switch #转换层级 driver.switch_to.frame("f1") driver.switch_to.frame("f2") #要想从f2回到f1,要先回到默认界面 driver.switch_to.default_content() driver.switch_to.frame("f1") 4)定位连续层级
备注:若要定位的元素需要进行一系列操作才展示,那需要我们一层层去定位;
driver.find_element(By.ID, "元素ID").find_element(By.ID, "下一层级才能看到的元素ID") 5)定位下拉框

元素类型为:< option value=“1”>一月< /option>
定位并选择十月份:
方法1:option[value]
#定位到下拉框,注意elements的复数形式 options = driver.find_element(By.CLASS_NAME,"整个日历月份下拉框class名").find_elements(By.TAG_NAME, "option") for option in options: if option.get_attribute('value') == '10': option.click() # 第二种方法option[10].click 6)定位div框
备注:若页面元素太多,利用元素无法精准定位,可以先定位到某div框,在从该div框里去定位:
先定位到DIV1这个模块,在对模块上的元素进行操作 div1=driver.find_element(By.CLASS_NAME, "class名") div1.find_element(By.ID, "ID").click() #如果这个模块上多个button,还可以使用这样的方法 div1=driver.find_element(By.CLASS_NAME, "class名") buttons=div1.find_element(By.ID, "ID") button[0].click() 1.2 基本操作
(1)点击按钮:.click()
举例: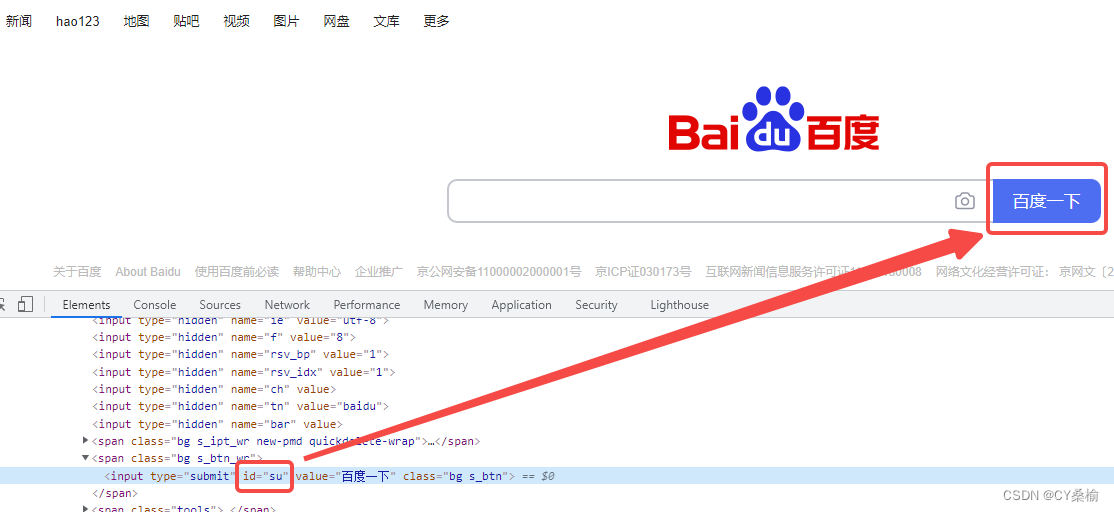
# 通过元素ID 定位到“百度一下”的按钮,点击“百度一下” driver = webdriver.Chrome() driver.get('http://www.baidu.com/') driver.find_element(By.ID, "su").click() (2)模拟写入对象/元素的内容:.send_keys(“xxxx”)
举例:百度-搜索框输入“孙俪”-点击“百度一下”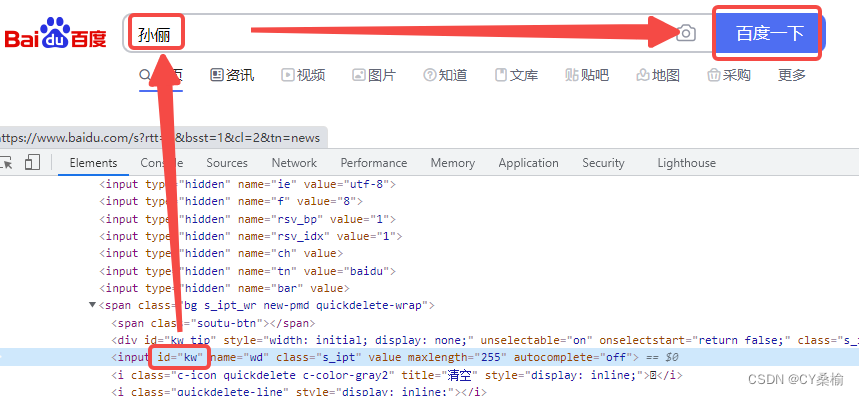
driver.find_element(By.ID, "kw").clear() driver.find_element(By.ID, "kw").send_keys("孙俪") driver.find_element(By.ID, "su").click() (3)模拟清空元素/对象的内容:.clear()
(4)提交表单:.submit()
备注:要求元素为表单类型才可使用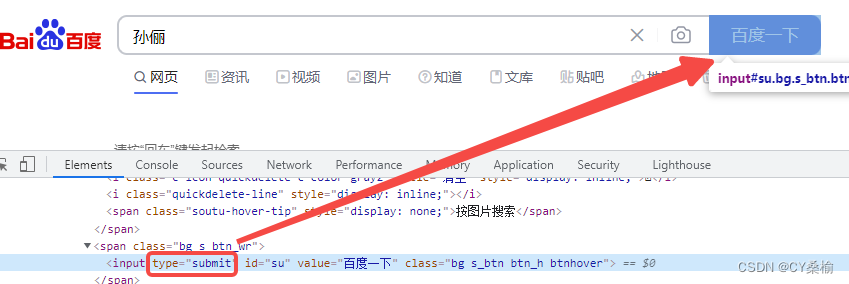
举例:也可通过表单方式提交.submit() == .click() == 点击“百度一下”
(5)用于获取元素的文本信息:.text ()
text=driver.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]').text print(text) (6)获取输入框元素内容/值:.get_attribute(‘value’)
driver.find_element(By.ID,"kw").send_keys("selenium") qq=driver.find_element(By.ID,'kw').get_attribute('value') print(qq) 结果:打印 输入框的值-输出 selenium
1.3 等待
(1)强制等待:time.sleep(2)——休眠2s
(2)智能等待:driver.implicitly_wait(5) ——智能等待最长5s
import time from selenium import webdriver driver = webdriver.Firefox() driver.implicitly_wait(5) time.sleep(2) 1.4 浏览器操作
(1)浏览器最大化:driver.maximize_window()
(2)设置浏览器高、宽:driver.set_window_size(500,500)
(3)浏览器后退:driver.back()
(4)浏览器前进:driver.forward()
(5)浏览器滚动条置顶与置底:(借助执行JS语句,如下示例所示)
import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Firefox() driver.get('http://www.baidu.com/') driver.maximize_window() #设置浏览器窗口为(500,500) driver.set_window_size(500,500) time.sleep(1) #设置浏览器窗口最大化 driver.maximize_window() driver.implicitly_wait(2) driver.find_element(By.ID,"kw").send_keys("selenium") driver.find_element(By.ID,"su").click() driver.implicitly_wait(3) #将页面滚动条拖到底部 js = "var q=document.documentElement.scrollTop=10000" driver.execute_script(js) time.sleep(3) #将页面滚动条拖到顶部 jjs="var q=document.documentElement.scrollTop=0" driver.execute_script(jjs) time.sleep(3) 1.5 鼠标事件
需from selenium.webdriver.common.action_chains import ActionChains
(1)context_click() 右击
(2)double_click() 双击
(3)drag_and_drop() 拖动
(4)move_to_element() 移动
- ActionChains(driver)
生成用户的行为。所有的行动都存储在actionchains 对象。通过perform()存储的行为。 - move_to_element(menu)
移动鼠标到一个元素中,menu 上面已经定义了他所指向的哪一个元素 - perform()
执行所有存储的行为
qq=driver.find_element(By.ID,"kw") ActionChains(driver).context_click(qq).perform() #右键 ActionChains(driver).double_click(qq).perform() #双击 1.6 键盘事件
需from selenium.webdriver import Keys
(1)快捷回车-enter键:.send_keys(Keys.ENTER) 等价于点击按钮
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver import Keys driver = webdriver.Firefox() driver.get('http://www.baidu.com/') driver.maximize_window() driver.find_element(By.ID, "kw").clear() driver.find_element(By.ID, "kw").send_keys("孙俪") driver.find_element(By.ID, "su").send_keys(Keys.ENTER) (2)切换焦点-Tab键:.send_keys(Keys.TAB)
作用:将元素定位位置由当前元素切换至下一个元素
(3)输入框内容-全选与剪切-组合键:全选、剪切、复制、粘贴
#ctrl+a 全选输入框内容 send_keys(Keys.CONTROL,'a') #ctrl+x 剪切输入框内容 send_keys(Keys.CONTROL,'x') #ctrl+c 复制输入框内容 .send_keys(Keys.CONTROL,'c') #ctrl+v 粘贴输入框内容 .send_keys(Keys.CONTROL,'v') (4)输入空格:.send_keys(Keys.SPACE)
(5)单个删除:.send_keys(Keys.BACK_SPACE)
1.7 弹窗处理
(1)Alert弹窗:只有信息及确认按钮
(2)Confirm弹窗:在Alert弹窗基础上增加了取消按钮
(3)Prompt类型弹框:在Confirm的基础上增加了可输入文本内容的功能
driver.switch_to.alert.accept() #确定、同意;三种弹窗都可使用 driver.switch_to.alert.dismiss() #取消、不同意;confirm和prompt弹窗中使用 title = driver.switch_to.alert.text #打印弹窗信息 alert = driver.switch_to.alert #获取alert对象 alert.send_keys() #Prompt弹窗中输入内容 1.8 上传文件操作
driver.find_element(By.CLASS_NAME, "class名").send_keys("文件路径") 2. unittest介绍
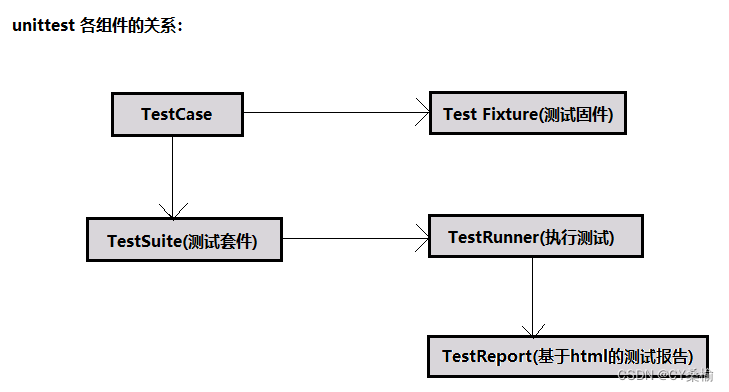
- unittest是Python自带的一个单元测试框架, 它可以做单元测试,提供了去创建测试用例的方法,并能用于编写和运行重复的测试工作;
- 可以利用unittest创建一个类,该类集成unittest的TestCase,其中每个case作为一个最小单元,由测试容器组织起来,统一执行并引入测试报告输出结果;
- test fixture:初始化与清理测试环境。如创建临时的数据库、文件/目录,其中如setUp()用于启动浏览器驱动、setDown()用于关闭游览器驱动等统一操作;
- test case:单元测试用例,在类TestCase中设计编写测试用例;
- test suite:单元测试用例集合,将不同的测试用例封装至类TestSuite中; test runner:执行单元测试用例;
- test report:生成测试报告;
3. unittest 框架的使用示例
- 前置:资源导入:
import csv #用于解析data数据 import sys #用于访问本地资源路径 from selenium import webdriver import time import os #用于输出 import unittest #用于使用unittest资源 from ddt import ddt, data, file_data, unpack #用于data数据读取与输入操作 from unittest import TestLoader #用于输出测试报告 1)测试固件的编写
- 每个测试用例都需要包含测试固件:包含基本的setUp()、tearDown()等统一操作;
def setUp(self): print("------setUp") self.driver=webdriver.Firefox() self.url="https://www.baidu.com" self.driver.maximize_window() time.sleep(3) def tearDown(self): print("-------tearDown") self.driver.quit() 2)单元测试用例——多场景设计测试用例
- 单元测试:可以是同一个场景设计多个测试用例;
示例:该单元测试场景——模拟每次进入百度首页-点击进入不同标签页面
from selenium import webdriver import os import time import unittest class Test1(unittest.TestCase): #绑定浏览器驱动,设置url def setUp(self): print("-----setUp") self.driver=webdriver.Firefox() self.url="https://www.baidu.com" self.driver.maximize_window() time.sleep(3) #测试用例执行结束进行清理,关闭浏览器驱动 def tearDown(self): print("-----tearDown") self.driver.quit() #编写测试用例 def test_xxx: def test_baidu1(self): driver=self.driver url=self.url driver.get(url) driver.find_element_by_link_text("hao123").click() time.sleep(2) def test_baidu2(self): driver=self.driver url=self.url driver.get(url) driver.find_element_by_link_text("图片").click() time.sleep(2) def test_baidu3(self): driver=self.driver url=self.url driver.get(url) driver.find_element_by_link_text("地图").click() time.sleep(3) if __name__ == "__main__": unittest.main() 示例:该单元测试场景——模拟百度搜索功能(对于不同数据类型)
测试数据导入
@data(不带的列表)会将整个列表作为参数传入
@data(带的列表)会将整个列表的子元素作为参数逐个传入,可将二维列表的元素逐个传入,一个元素一个case
@unpack 将要传入的元素解包后传入,将二维列表的元素逐个传入,便于一个测试用例中使用一组数据中的多个不同变量;
首先需要了解数据导入的方法: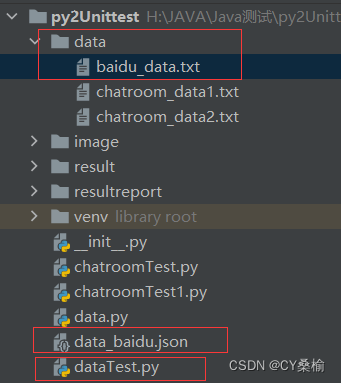
备注:数据导入可以选择txt文件、json文件格式、或直接导入数据数组;其中dataTest.py为某单元测试文件;
1)读取txt文件
- 需要引入data数据包-并要设置读取方法;
def getTxT(file_name): rows = [] path = sys.path[0] with open(path + '/data/' + file_name, 'rt',encoding='UTF-8') as f: readers = csv.reader(f, delimiter=',', quotechar='|') next(readers, None) for row in readers: temprow = [] for i in row: temprow.append(i) rows.append(temprow) return rows - 给该单元测试的类和某测试用例设置@ddt与@data修饰器
@data(*getTxT("baidu_data.txt")) 2)读取json文件
- 格式如下:
[ "hao123", "图片", "地图" ] 3)直接在某用例上输入数组
- 格式如下:
@data(["hao123", "hao123"], [u"视频", u"视频_百度搜索"]) 跳过某用例
想跳过某单元用例中的某用例,则添加如下代码至某用例方法上即可:
@unittest.skip("skipping") #表示跳过该测试用例 测试用例断言
unittest单元测试框架提供了一整套内置的断言方法:
1)如果断言失败,抛出AssertionError的错误,case为失败状态
2)如果断言成功,会标识case为成功状态
| 方法 | 检查 | 描述 |
|---|---|---|
| assertEqual(a, b) | a == b | 验证a是否等于b |
| assertNotEqual(a, b) | a != b | 验证a是否不等于b |
| assertTrue(x) | bool(x) is True | 验证x是否为ture |
| assertFalse(x) | bool(x) is False | 验证x是否为flase |
| assertIs(a, b) | a is b | 验证a,b是否为同一个对象 |
| assertIsNot(a, b) | a is not b | 验证a,b不是同一个对象 |
| assertIsNone(x) | x is None | 验证x是否是None |
| assertIsNotNone(x) | x is not None | 验证x是否非None |
| assertIn(a, b) | a in b | 验证a是否是b的子串 |
| assertNotIn(a, b) | a not in b | 验证a是否非b的子串 |
| assertIsInstance(a, b) | isinstance(a, b) | 验证a是否是b的实例 |
| assertNotIsInstance(a, b) | not isinstance(a, b) | 验证a是否不是b的实例 |
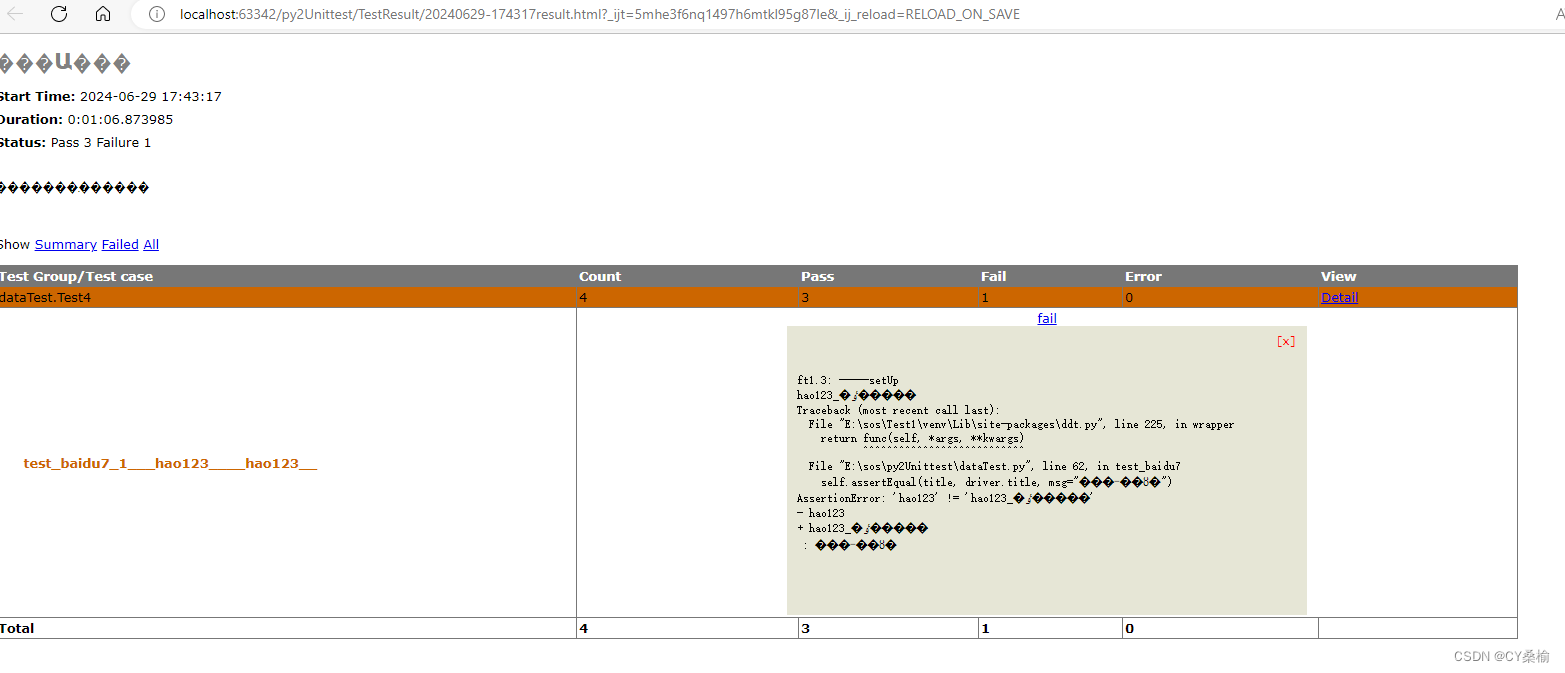
举例:百度搜索某字段,判断标题是否一致,不一致则断言失败,打印结果:标题不相等!
@data(["hao123", "hao123"], [u"视频", u"视频_百度搜索"]) def test_baidu7(self, value, title): driver = self.driver url = self.url driver.get(url) driver.find_element_by_id("kw").send_keys(value) driver.find_element_by_id("su").submit() time.sleep(5) print(driver.title) self.assertEqual(title, driver.title, msg="标题不相等!") 测试结果截图
可以设置保存截图的方法,根据断言结果调用截图方法并保存截图:
1)设置截图保存方法
def savescreenshot(self, driver, file_name): if not os.path.exists('./image'): os.makedirs('./image') now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time())) # 截图保存 driver.get_screenshot_as_file('./image/' + now + '-' + file_name) time.sleep(1) 2)根据断言抛出异常,调用截图方法
def test_baidu4(self): driver=self.driver url=self.url driver.get(url) driver.find_element_by_id("kw").clear() driver.find_element_by_id("kw").send_keys("孙俪") driver.find_element_by_id("su").click() time.sleep(3) print(driver.title) try: self.assertEqual("孙俪_百度搜索", driver.title, msg=None) self.assertNotEqual("孙俪_百度搜索",driver.title,msg=None) except: self.savescreenshot(driver,"sunli.png") 3)截图:百度搜索“孙俪”
结果保存至项目文件的/image文件夹中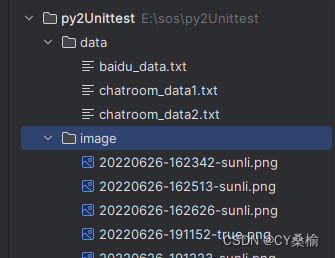
3)测试套件组合与执行
套件组合-借助装载器:defaultTestLoader、TestLoader
将单元测试文件中的某类测试用例塞入测试套件中,创建一个测试用例组合套件的方法:
def createSuit(): # 添加不同测试用例到套件里 testSuit=unittest.defaultTestLoader.discover("../py2Unittest",pattern="test*.py",top_level_dir=None) return testSuit 注:此方法可以把一个文件夹下面所有的满足test*.py命名规则的测试脚本中的测试用例放入测试套件
套件组合-借助addTest函数
可以将某单元测试文件中的某个用例塞入测试套件中:
注:这样放需要在当前测试套件脚本中引入此处的单元测试脚本,否则addTest()会报错
import test1 import test2 def creatSuit(): #要把不同的测试脚本的类中的需要执行的方法放在一个测试套件中 suit = unittest.TestSuite() suit.addTest(test1.Test1("test_baidu1")) # test_baidu1为某测试用例方法的名称 suit.addTest(test2.Test2("test_baidu3")) return suit 套件组合-借助makeSuit
利用makeSuit不需要导入单元测试用例文件
def creatSuit(): #如果我需要把一个测试脚本中所有的测试用例都添加到suit中-实际将整个单元测试脚本中的类都加入套件中实现 # makeSuit suit = unittest.TestSuite() suit.addTest(unittest.makeSuite(test1.Test1)) suit.addTest(unittest.makeSuite(test2.Test2)) return suit 套件执行-借助TextTestRunner
举例:
将测试套件执行并打印测试结果:
import unittest from unittest import TestLoader def creatSuit(): #TestLoader suit1 = unittest.TestLoader().loadTestsFromTestCase(test1.Test1) suit2 = unittest.TestLoader().loadTestsFromTestCase(test2.Test2) suit = unittest.TestSuite([suit1, suit2]) return suit if __name__ == "__main__": suit = creatSuit() # verbersity= 0, 1, 2 runner = unittest.TextTestRunner(verbosity=2) runner.run(suit) 注:unittest.TextTestRunner的verbosity参数用于控制测试运行时的详细程度。它可以接受的值如下:
0: 静默模式,不输出任何信息。
1: 默认模式,输出每个测试方法的简要摘要和总体摘要(通过、失败、错误等)。
2: 详细模式,输出每个测试方法的详细执行结果,包括测试方法的名称、运行时间、状态等信息。
4)测试报告输出
测试套件&执行&测试报告输出脚本程序入口的设置:
if name ==“main”:
1.设置测试结果文件输出路径
2.设置结果文件名
3.创建并打开文件,执行测试套件,写入测试结果,保存文件
举例:
单元测试脚本:
import csv import sys # -*- coding: utf-8 -*- from selenium import webdriver import os import time import unittest from ddt import ddt, data, file_data, unpack from selenium.webdriver.common.by import By def getTxT(file_name): rows = [] path = sys.path[0] with open(path + '/data/' + file_name, 'rt',encoding='UTF-8') as f: readers = csv.reader(f, delimiter=',', quotechar='|') next(readers, None) for row in readers: temprow = [] for i in row: temprow.append(i) rows.append(temprow) return rows @ddt class Test4(unittest.TestCase): # 绑定浏览器驱动,设置url def setUp(self): print("-----setUp") self.driver = webdriver.Firefox() self.url = "https://www.baidu.com" self.driver.maximize_window() time.sleep(3) # 测试用例执行结束进行清理,关闭浏览器驱动 def tearDown(self): print("-----tearDown") self.driver.quit() # @unittest.skip("skipping") # 注释表示跳过该测试用例 @file_data("data_baidu.json") def test_baidu6(self, value): driver = self.driver url = self.url driver.get(url) driver.find_element(By.LINK_TEXT,value).click() time.sleep(3) # @unittest.skip("skipping") @unpack @data(*getTxT("baidu_data.txt")) # @data(["hao123", "hao123"], [u"视频", u"视频_百度搜索"]) def test_baidu7(self, value, title): driver = self.driver url = self.url driver.get(url) driver.find_element(By.ID,"kw").send_keys(value) driver.find_element(By.ID,"su").submit() time.sleep(5) print(driver.title) self.assertEqual(title, driver.title, msg="标题不相等!") 套件组合与执行&报告输出脚本:
import HTMLTestRunner # 基于html文件的测试执行与报告输出资源模块 import os import sys import time import unittest def createSuit(): # 添加不同测试用例到套件里 testSuit=unittest.defaultTestLoader.discover("../py2Unittest",pattern="dataTest.py",top_level_dir=None) return testSuit if __name__ =="__main__": if not os.path.exists("./result"): os.makedirs("./result") now = time.strftime("%Y%m%d-%H%M%S",time.localtime(time.time())) print(now) fileName="./result/"+now+"result.html" with open(fileName, "w") as fp: runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告", description=u"测试用例执行情况",verbosity=2) suit = createSuit() runner.run(suit) 若文件读写时 with open(fileName, “wb”) as fp:可能会报错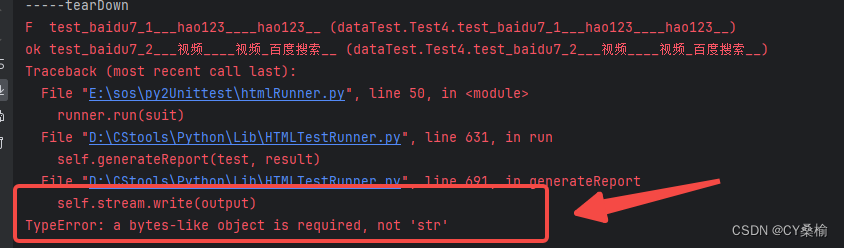
不要慌,可以查看文件读取与写入规则,主要是使用write函数时报错,检查open函数,发现参数写为‘wb’,即按二进制write,所以后面出现TypeError: a bytes-like object is required, not 'str’的报错,将此次的参数修改为w后,可以按照字符串输入,编译通过,write的结果正确(w+具有读写属性,写的时候如果文件存在,会被清空,从头开始写)
结果截图: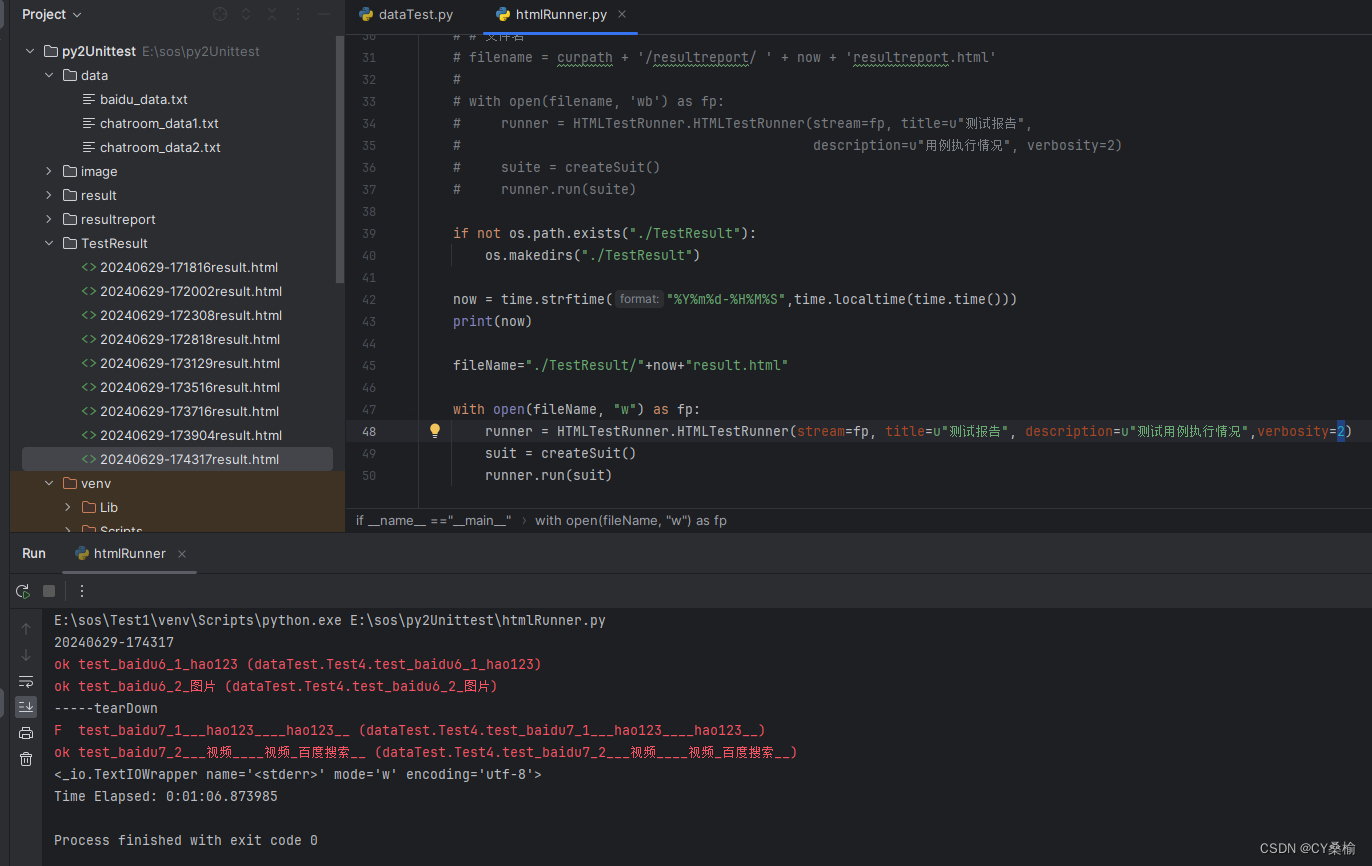
测试报告: