
阅读量:5
最近很长时间没有更新,其实一直在学习AI安全,我原以为学完深度学习之后再学AI安全会更加简单些,但是事实证明理论转实践还是挺困难的,但是请你一定要坚持下去,因为“不是所有的坚持都有结果,但总有一些坚持,能从冰封的土地里,培育出十万朵怒放的蔷薇”。
题目来源:NSSCTF
题目描述:
噪声在大数据场景下有着重要的地位。工程师们苦于被噪声污染的数据,同时也使用噪声保护着隐私数据。这个挑战分为两个部分。
挑战1:从噪声中恢复隐私向量
有A,B两个实体。其中B是普通实体,A则是恶意攻击者。A现在获得了B的加密压缩包,并得知压缩包的密码是B隐私向量的md5值。同时通过一些其他手段获取了大量的受噪声加密保护的隐私向量(vector.txt)。经过简单的数据分析,A很快恢复出隐私向量并解锁了加密压缩包。
示例:如果你认为B的隐私向量是 100,200,50。那么压缩包的密码就是md5(10020050)=>e37864fe2983ce576b00c39049327841
提示:B的隐私向量长度为20且第一个值为901挑战2:找出被噪声污染的数据
A从B的加密压缩包中获得了重要的数据资产——数据集,并准备使用其获取更大的商业价值。然而糟糕的是,使用这些数据集训练出的AI模型效果始终不好。A怀疑B在数据集中加入了噪声防止数据被恶意利用,经过对于数据的仔细检查,A发现了被噪声污染的数据。
请将你认为被污染的图片名字(不含.png)按字典序排列(python list.sort())后拼接。最终flag的格式为flag{md5(拼接得到的字符串)}
示例:如果你认为被污染的数据是 1a.png, 0b.png。则按字典序排序后拼接得到的字符串为0b1a,flag为flag{06624d5f90094ff209a1c03afff6bebc}
挑战1:从噪声中恢复隐私向量
1、计算每个向量的均值,展示出来的图片为:
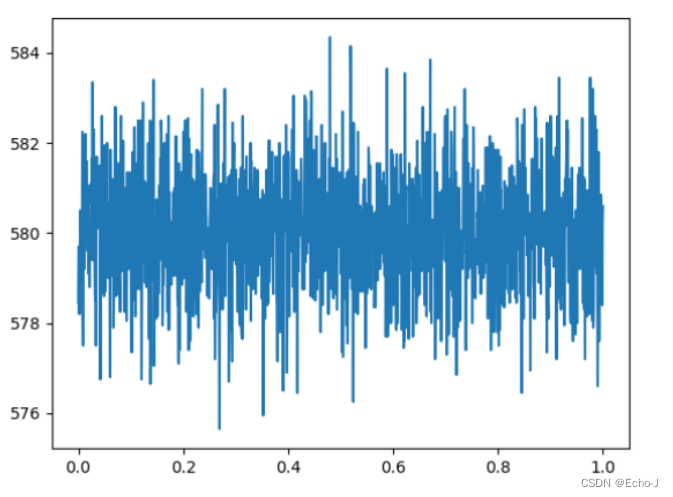
方差,展示出来的图片:
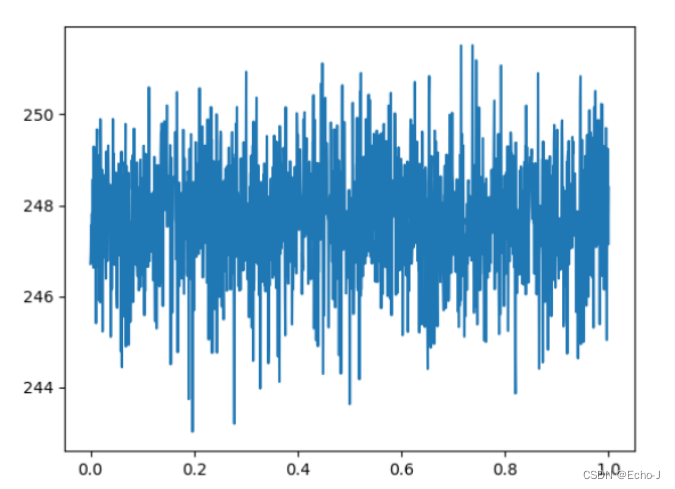
根据噪声的分布,初步判断为高斯噪声
2、去除高斯噪声,脚本如下:
import numpy as np import hashlib with open('vector.txt', 'r', encoding='utf-8') as file: vectors = [eval(line.strip('\n')) for line in file.readlines()] string = "" stacked_vectors = np.sum(vectors, axis=0) vectorB = list(np.round(stacked_vectors/len(vectors),0)) print("vectorB:", vectorB) for vector in vectorB: string += str(vector)[:-2] print(string) md5 = hashlib.md5() md5.update(string.encode('utf-8')) print("md5:", md5.hexdigest())其实,去除高斯噪声就是求均值
得到B的隐私向量md5值:md5: 72a63a00259bec3de133c0da772c61e5
利用此值对picture压缩包进行解密
挑战2:找出被噪声污染的数据
1、训练MNIST数据集识别模型
得到model_Mnist.pth模型,我之所以想到通过训练模型来识别噪声,第一个原因是因为我找不到理论判断为高斯噪声的脚本,第二个原因是因为我使用matlab脚本得到每张图片的直方图,虽然也找到了,和模型测出来的一样,但是我需要人眼识别,我想着如果图片不是200张,就很困难。最后会附上matlab代码。
脚本,这个脚本不是我写的,是我在网上找的,在此附上地址用PyTorch实现MNIST手写数字识别(最新,非常详细)_mnist pytorch-CSDN博客:
import torch import numpy as np from matplotlib import pyplot as plt from torch.utils.data import DataLoader from torchvision import transforms from torchvision import datasets import torch.nn.functional as F import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" """ 卷积运算 使用mnist数据集,和10-4,11类似的,只是这里:1.输出训练轮的acc 2.模型上使用torch.nn.Sequential """ # Super parameter ------------------------------------------------------------------------------------ batch_size = 64 learning_rate = 0.01 momentum = 0.5 EPOCH = 10 # Prepare dataset ------------------------------------------------------------------------------------ transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差 train_dataset = datasets.MNIST(root='./data/mnist', train=True, transform=transform, download=True) # 本地没有就加上download=True test_dataset = datasets.MNIST(root='./data/mnist', train=False, transform=transform) # train=True训练集,=False测试集 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) fig = plt.figure() for i in range(12): plt.subplot(3, 4, i+1) plt.tight_layout() plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none') plt.title("Labels: {}".format(train_dataset.train_labels[i])) plt.xticks([]) plt.yticks([]) plt.show() # 训练集乱序,测试集有序 # Design model using class ------------------------------------------------------------------------------ class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Sequential( torch.nn.Conv2d(1, 10, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.conv2 = torch.nn.Sequential( torch.nn.Conv2d(10, 20, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.fc = torch.nn.Sequential( torch.nn.Linear(320, 50), torch.nn.Linear(50, 10), ) def forward(self, x): batch_size = x.size(0) x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大) x = self.conv2(x) # 再来一次 x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320 x = self.fc(x) return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9) model = Net() # Construct loss and optimizer ------------------------------------------------------------------------------ criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量 # Train and Test CLASS -------------------------------------------------------------------------------------- # 把单独的一轮一环封装在函数类里 def train(epoch): running_loss = 0.0 # 这整个epoch的loss清零 running_total = 0 running_correct = 0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() # forward + backward + update outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() # 把运行中的loss累加起来,为了下面300次一除 running_loss += loss.item() # 把运行中的准确率acc算出来 _, predicted = torch.max(outputs.data, dim=1) running_total += inputs.shape[0] running_correct += (predicted == target).sum().item() if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率 print('[%d, %5d]: loss: %.3f , acc: %.2f %%' % (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total)) running_loss = 0.0 # 这小批300的loss清零 running_total = 0 running_correct = 0 # 这小批300的acc清零 torch.save(model.state_dict(), './model_Mnist.pth') torch.save(optimizer.state_dict(), './optimizer_Mnist.pth') def test(): correct = 0 total = 0 with torch.no_grad(): # 测试集不用算梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标 total += labels.size(0) # 张量之间的比较运算 correct += (predicted == labels).sum().item() acc = correct / total print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数 return acc # Start train and Test -------------------------------------------------------------------------------------- if __name__ == '__main__': acc_list_test = [] for epoch in range(EPOCH): train(epoch) # if epoch % 10 == 9: #每训练10轮 测试1次 acc_test = test() acc_list_test.append(acc_test) plt.plot(acc_list_test) plt.xlabel('Epoch') plt.ylabel('Accuracy On TestSet') plt.show()2、利用得到的模型进行测试
import torch from matplotlib import pyplot as plt from torchvision import transforms, datasets import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" import glob # 获取文件夹中所有图片的路径 # Prepare dataset ------------------------------------------------------------------------------------ datasets_path = "picture" image_paths = [] image_paths3 = [] for i in range(10): image_paths.append(glob.glob(os.path.join(f"picture\\{i}", '*.png'))) # print(image_paths) for image_paths1 in image_paths: for image_paths2 in image_paths1: image_paths3.append(image_paths2) print(image_paths3) transform = transforms.Compose([ transforms.Resize((28, 28)), transforms.Grayscale(), transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) custom_dataset = datasets.ImageFolder(root=datasets_path, transform=transform) data_loader = torch.utils.data.DataLoader(custom_dataset, batch_size=200, shuffle=False) # Design model using class ------------------------------------------------------------------------------ class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Sequential( torch.nn.Conv2d(1, 10, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.conv2 = torch.nn.Sequential( torch.nn.Conv2d(10, 20, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.fc = torch.nn.Sequential( torch.nn.Linear(320, 50), torch.nn.Linear(50, 10), ) def forward(self, x): batch_size = x.size(0) x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大) x = self.conv2(x) # 再来一次 x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320 x = self.fc(x) return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9) model = Net() # Start Test -------------------------------------------------------------------------------------- if __name__ == '__main__': fig = plt.figure() n = 0 m = 0 string = "" # 加载模型 model.load_state_dict(torch.load('model_Mnist.pth')) with torch.no_grad(): for data in data_loader: images, label = data output = model(images) _, predicted = torch.max(output.data, dim=1) # print(label, predicted) # print(torch.eq(label, predicted).numpy()) ans = torch.eq(label, predicted).numpy() # plt.subplot(10, 20, n+1) # plt.tight_layout() # plt.imshow(images[n][0], cmap='gray', interpolation='none') # plt.title("{}:{}".format(label, predicted)) # plt.xticks([]) # plt.yticks([]) n += 1 # plt.show() for i in range(len(ans)): if not ans[i]: print(f"'{image_paths3[i][-8:-4]}',", end="")最终得到的文件名为:list = ["mHcX","cmGg","VIre","QAnp","9etA"]
进一步:
import hashlib list = ["mHcX","cmGg","VIre","QAnp","9etA"] list.sort() string = "" for s in list: string += s md5 = hashlib.md5() md5.update(string.encode('utf-8')) print("md5:", md5.hexdigest())得到md5值:db49e0176a2cb612f666ba582e7c3a69
但是当我信心满满的去交flag时,不对???我不知道为什么?
matlab代码:
function[] = noise_hist() image = ["0D1G.png", "0ETW.png", "1kCT.png", "1RK4.png", "2bzf.png", "2GEo.png", "3als.png", "4qzr.png", "5MIr.png", "5REN.png", "5ZAn.png", "6wMN.png", "71Ek.png", "792g.png", "7ghZ.png", "7spe.png", "7wYX.png", "82ig.png", "8as8.png", "8CiG.png", "98nP.png", "9etA.png", "9Fky.png", "9g84.png", "9S4c.png", "9udk.png", "9Yla.png", "ADGa.png", "ADZ7.png", "afLq.png", "AMic.png", "AvLX.png", "AZgn.png", "b9wg.png", "bEGh.png", "bv89.png", "cB5c.png", "cG3m.png", "CIbx.png", "cmGg.png", "Cozg.png", "CPIT.png", "CVRg.png", "CYZ2.png", "CzSN.png", "DaNV.png", "dgIl.png", "DgSY.png", "DGzY.png", "DIkW.png", "dlkc.png", "DOgp.png", "dPXx.png", "dvwc.png", "e3Ui.png", "egza.png", "Ehd7.png", "Ei01.png", "EI6X.png", "f7If.png", "FB9b.png", "fcOP.png", "FdZ3.png", "FGIY.png", "foxS.png", "FWm5.png", "g10P.png", "G3F8.png", "G5ew.png", "gaTE.png", "gaVE.png", "GdL7.png", "ge5N.png", "ggk5.png", "gkgA.png", "GKug.png", "gNmk.png", "gVw7.png", "gw63.png", "Gxbw.png", "H4U4.png", "H5p4.png", "hdsA.png", "hEB3.png", "hGVS.png", "hh81.png", "hkGO.png", "hob7.png", "HoR1.png", "Hrun.png", "hSgA.png", "Hux6.png", "HVEK.png", "hxhy.png", "Hy5l.png", "IEvu.png", "INcr.png", "k4Mu.png", "KAsp.png", "kaVE.png", "kLWg.png", "KPFk.png", "kqft.png", "l2AQ.png", "LdlV.png", "LgQX.png", "LgU2.png", "lMOK.png", "LoFU.png", "Lq7s.png", "lqrK.png", "LZo6.png", "mHcX.png", "mPW4.png", "msVi.png", "muMK.png", "mvHD.png", "MWTx.png", "nRtp.png", "Nv7u.png", "NvyK.png", "nWTH.png", "nyZW.png", "O0wv.png", "OAQ9.png", "OgEx.png", "ooir.png", "OpMF.png", "Oslf.png", "OTU3.png", "P3Am.png", "PwCC.png", "QAnp.png", "qGxs.png", "qH3P.png", "qMgX.png", "Qqq9.png", "qtaR.png", "RDkl.png", "rEz6.png", "RIqg.png", "rMGY.png", "Rogg.png", "RPBd.png", "RUls.png", "S46q.png", "s8py.png", "S9rU.png", "SAd2.png", "SAru.png", "SAzS.png", "sFsU.png", "SLG2.png", "sn7m.png", "SPEb.png", "SYfg.png", "syHP.png", "SzAV.png", "T0u5.png", "t7Kf.png", "TCOt.png", "tEDB.png", "TQ4z.png", "tSZp.png", "tWF8.png", "u6vG.png", "UcuB.png", "uH1P.png", "UHqz.png", "UKBL.png", "unEF.png", "uU1G.png", "uVSn.png", "UxQl.png", "UZz9.png", "v4rb.png", "VFQQ.png", "VIre.png", "vpz6.png", "w8xx.png", "weYa.png", "WGGZ.png", "WK7W.png", "x4zu.png", "X5sz.png", "Xgl9.png", "xRtF.png", "xZxm.png", "y4tR.png", "Y6Wm.png", "YI78.png", "YQtn.png", "YWqF.png", "YY9F.png", "Z2uR.png", "zbrq.png", "zCPx.png", "zl5m.png", "zXWB.png", "zzga.png"]; len = length(image); for i = 1:len a = imread("./picture/"+image(i)); figure; imhist(a);title(image(i)); end如果有人知道怎么解的,可不可以告诉我一下?感谢!!!
