前言
今天,是一个比较特殊的日子。
从我开始学习AI绘画开始到现在AI工具相关的笔记我已经写了50篇了,其中估摸着得近40篇都是关于Stable Diffusion的。
在这一天天的学习中我感受到了对知识的疲倦,是时候给自己来点奖励了!

所以!
今天开始和后续的一系列笔记内容将跟随小33学习如何训练出一个自己的Stable Diffusion模型,就像是用自己的双手捏出一个自己心目中的“伴侣”一样。
我知道很多人一直期待着这个环节,但是捏一个自己想要的模型并不是一件简单的事情,需要有足够的基本功作为铺垫。
今天!正是时候!
让我们废话少说,一起踏上“寻找理想伴侣”的旅程吧!

Stable Diffusion
AI绘画其实有很多家AI公司参与,旗下都有着自己的旗舰产品(Midjourney之类),但是为什么唯独是Stable Diffusion名气最响受众最广呢?
其中一个原因是它免费开源,还有一个原因则是Stable Diffusion有着包罗万象的模型生态。
像是以往封面的图片以及学习中所使用过的模型,超过99%都是由个人用户训练出来的微调模型。

像这样的
这些模型不仅弥补了原版模型绘制精度不足的局限性,还能让任何想要的人物、风景、物品出现在AI生成的作品里。这也一定程度上让AI绘画摆脱了抽卡式的随机性,这也是SD与其他的“闭源”图像生成应用的最大区别之一。
机器学习与模型训练
人工智能领域有一个专业词汇被称为“机器学习”,机器学习支持用户向计算机算法输送大量数据,让计算机分析这些数据后根据输入的数据给出数据驱动型建议和决策。
而我们提供数据和引导机器学习的过程就是“训练”,训练的结果是让AI得到我们想到他学到的“知识”,这个知识就是模型。后续用模型来解决问题的过程被称为推理。
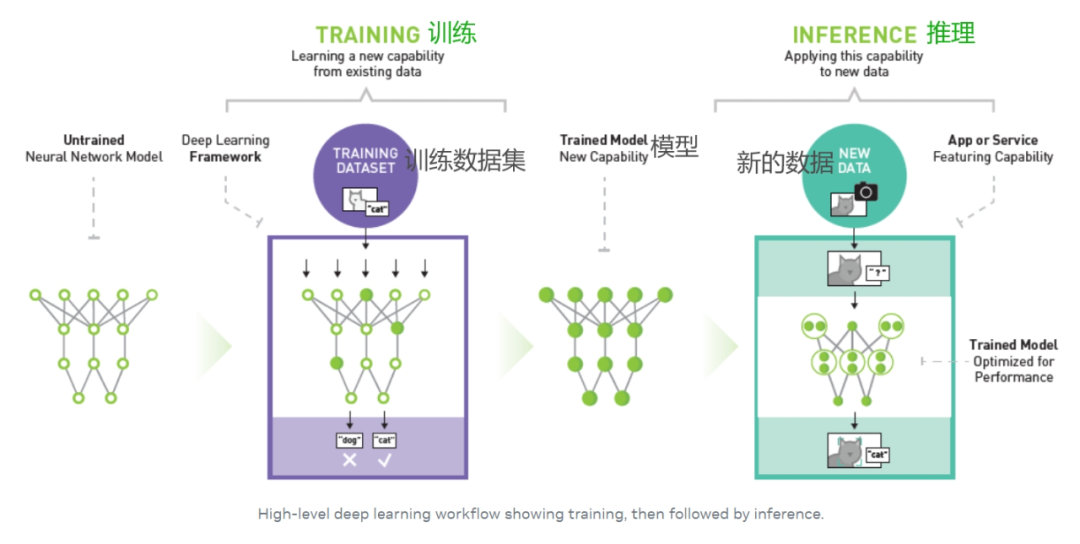
图中的训练数据集就是要让AI学习的资料,而得到的新数据就是要让AI处理的工作。
AI绘画中要给AI灌输的学习资料就是从互联网上抓取的海量图片,这些图片连同描述图片的文字信息构成了用来训练的“数据集”。
数据集并不是像我们所想的一样把图片存进去,然后收到提示词信息后调用抓取图片。数据集所存储的是图片中蕴含的“像素分布规律”,每一张图片其实都是由不同的颜色的像素点所组成。

整理和输出教程属实不易,觉得这篇教程对你有所帮助的话,可以点击👇二维码领取资料😘

每个颜色的像素点可以用红、绿、蓝三种颜色的色值(R/G/B)表示,而像素分布规律就是结合这些不同颜色的点是如何排列组合形成各种我们看到的事物。
对于AI来说,它并不能分辨什么对应什么,例如下面这张图我们人类一看就知道是个可爱的男孩子对吧。

但是对于AI来说它是做不到的,因为在AI眼里一张图片是这个样子的:
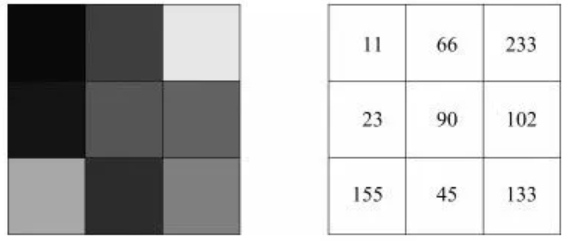
没有颜色只有数字,所以才需要通过不断传输知识的方式来引导AI记住那些正确的选择。
这个训练的过程需要重复成百上千甚至亿次,AI就会在这个试错的过程中变得越来越聪明,从而总结出各类形象对应的像素分布图。
这些图像分布规律会被以一种数学手段转换为一种叫做“嵌入向量”的东西存储在模型中。
嵌入向量本质上是一串很长的数字序列,一个数字对应一个维度用于描述某一种向量空间里的“特征”。
向量这个初中课本有学过,向量是一个同时具有大小和方向的量,不同的规律会变成不同的向量存储进去。而AI在做的事情就是将提示词里的描述信息转换为一个个向量,然后和训练时所掌握的规律进行对号入座。
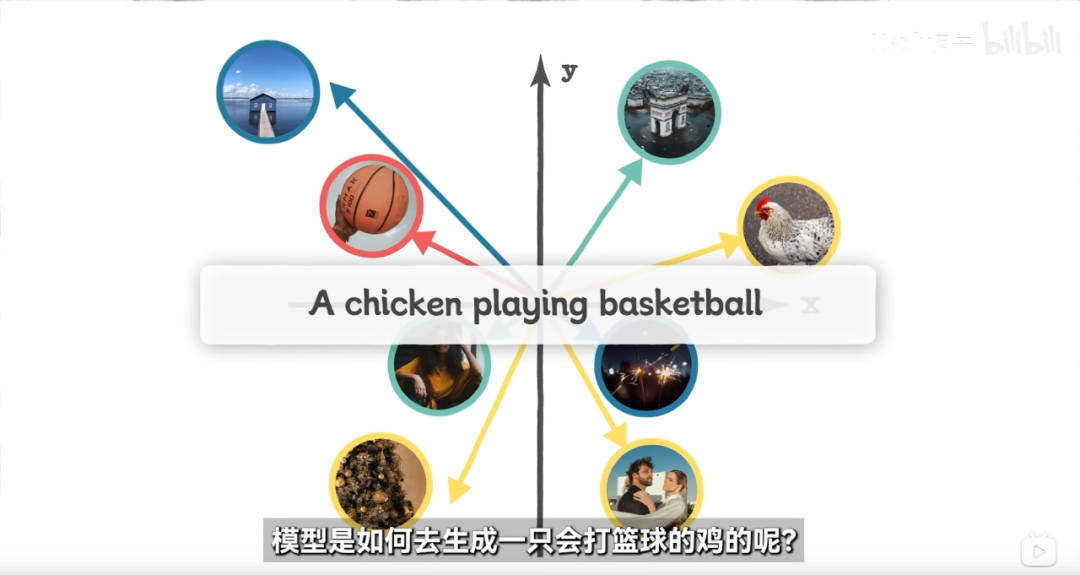


将得到的向量结合到一起就会产生一个新的向量,而这个新的向量就是用户想要AI去绘制的东西,然后再通过模型里的一些功能将这个向量倒推就得到了一个与预期接近的图片。
如果这段看不太懂的话可以去看原视频教程,我会把链接放在文末。
Stable Diffusion工作原理
这里缓一缓,回到Stable Diffusion中。
在以往的AI绘制操作流程往往是固定的:1.选一个模型、2.输入提示词、3.调节参数设置、4.点击生成。
在我们看来操作流程是这样的,但是在AI看来就有一点不一样了。
1.输入的提示词会被转化为一个个Token也就是词元,Token是机器学习中最小的语义单位。

2.然后会有一个文本编码器,这个编码器将每一个Token都转化为一组有着768个维度的词元向量Token Embeddings(1.5版本SD为768维、V2版本1024维、XL版本2048维)。而这些连接到一起就得到了绘制一张新图片所需要的“规律”。

3.与此同时我们调节的参数会输入到一个“噪声预测器”Noise Predictor,这个东西是用于设定好其工作中的生成方式例如多少步的生成、以什么方式生成等。并确定好这张图片的尺寸、比例一类的初始属性。
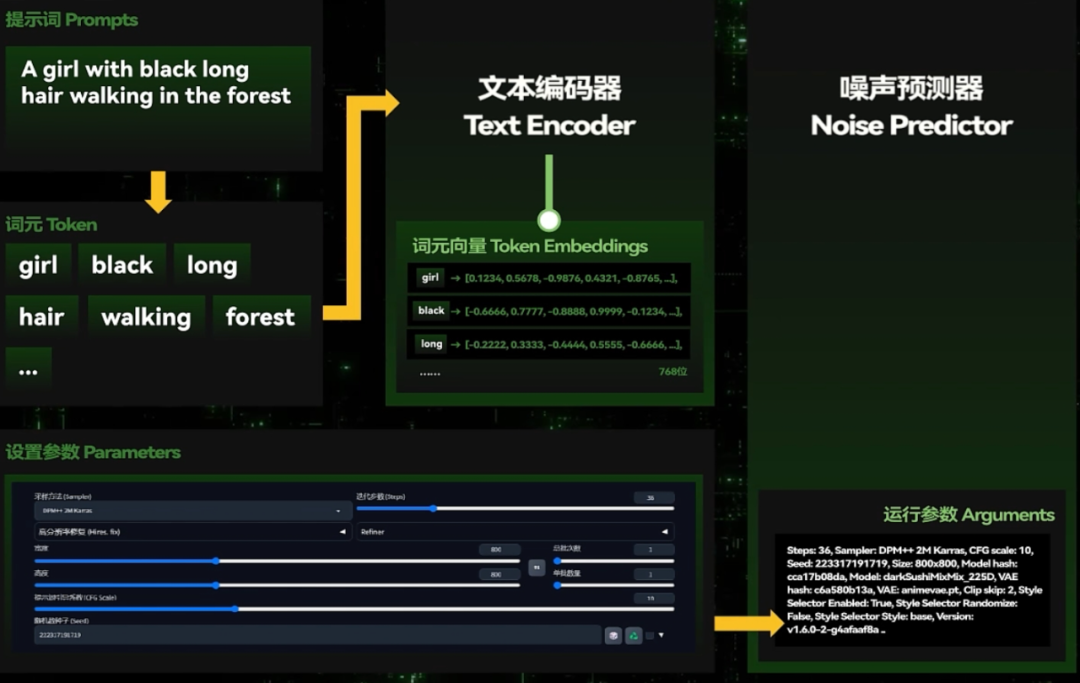
4.准备好后Stable Diffusion会经过随机种子(Random Seed)计算出一张初始噪声图,噪声预测器就会在文本编码器的指导下一步步“扩散”。这个扩散就是去除上面的噪声并为图片添加某些形象。
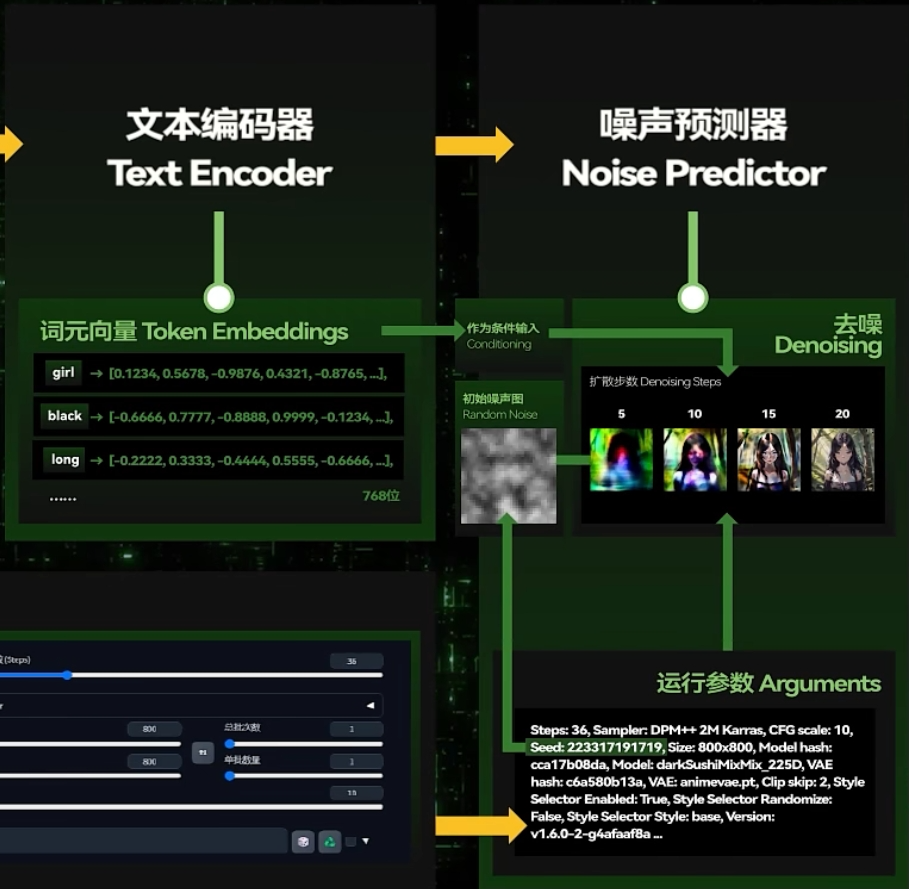
经过若干次循环之后,图片的大概形象就会显现出来。
5.最后再借由一个变分自编码器Variational Auto Encoder把它从向量形态转变回肉眼可以分辨的正常图片。
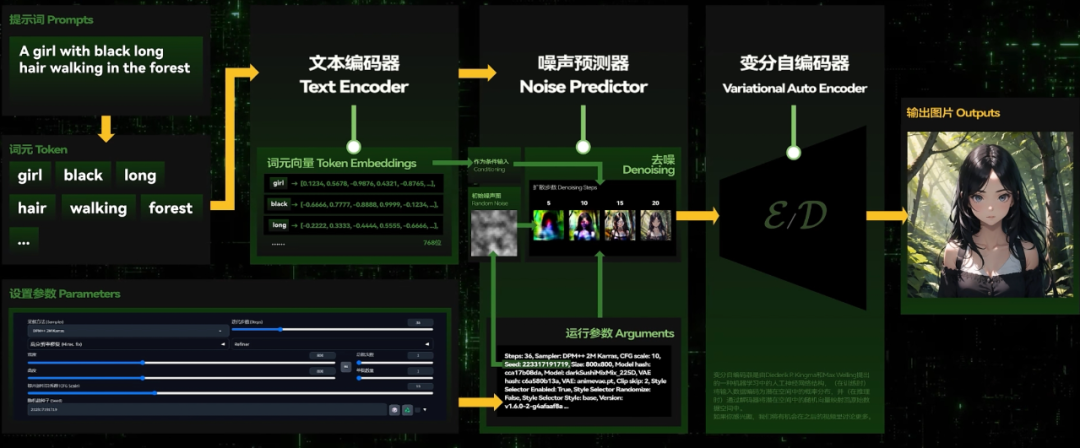
就像这样
在这个过程中文本编码器、噪声预测器和变分自编码器(VAE)就是可以去训练的人工神经网络-机器学习模型。
这三个阶段所接收到的“知识”决定了最终生成出来的图片会是什么样的,而更换一个不同风格的大模型就相当于将这三样完全变一下,因此在同样的提示词下不同的模型就会产出不同的结果。
而例如Embeddings、Lora等“小”模型在使用的时候也会像是辅助挂件一样搭载在这些结构上,这样也可以部分地修改里面的东西。
更加详细的东西因为篇幅的限制原教程没有讲到,哎呀很可惜的其实我也很想马上学到。

今天的内容就到这里结束啦!
虽然说没有一上来直接就动手训练模型,但是还是得先了解一下模型的原理这样也为后来自己训练模型打下结实的基础嘛。
好久没写超过2000字的文章了,上次写还是在昨天。
我要去歇息会了,大伙下篇笔记见!拜了个拜!

**谁不喜欢蜘蛛侠呢?
**
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。
2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。
3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。
4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!