
阅读量:2
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm=1010.2135.3001.5343
🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12625432.html

目录
前言
💬 hello! 各位铁子们大家好哇。
今日更新了Linux的make和git的内容
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
Linux项目自动化构建工具-make/Makefile
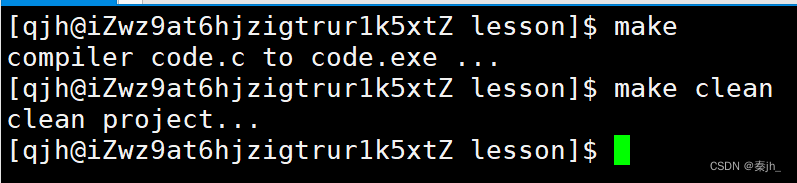
make是一个命令工具,是一个解释makefile中指令的命令工具,make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
举例
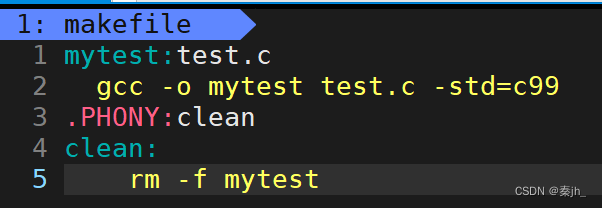
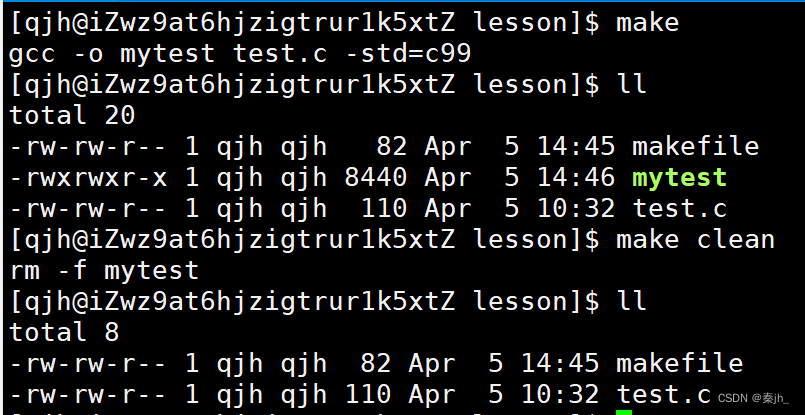
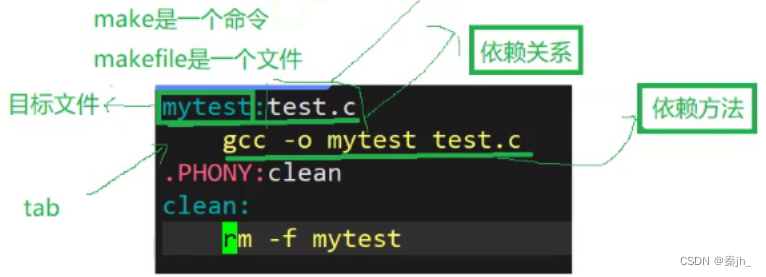
依赖文件列表以空格进行分割,依赖文件列表可以为空,如上方的clean。上方直接使用make,为什么会执行第一对依赖关系呢?因为如果make后面什么都不跟,就会默认执行第一对依赖关系。make是从上往下执行的。
.PHONY
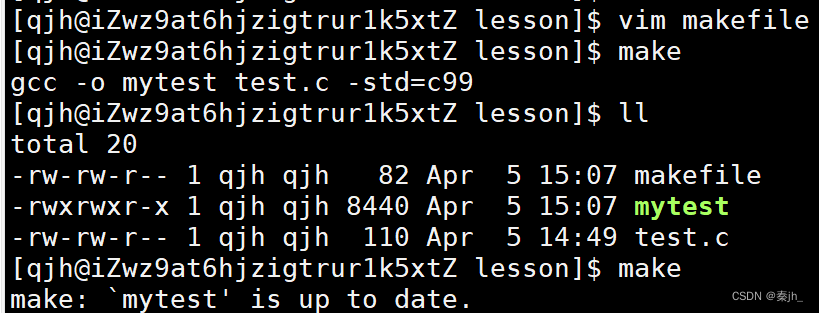
格式: .PHONY:XXX 作用:修饰后XXX对应的方法总是要被执行的。
上方make使用一次后就不能继续使用了,是因为此时生成的可执行程序已经是最新的了,不需要更新。如果这里的目标文件也被,PHONY修饰,也可以一直执行。
这里的更新实际是对比可执行文件和源文件的各自的最近修改时间,如果可执行文件最新,就不会编译,如果源文件最新,就会重新编译(即新旧时间的对比)。

常见符号
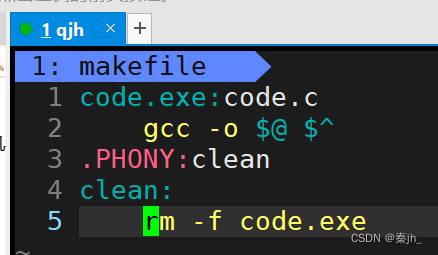
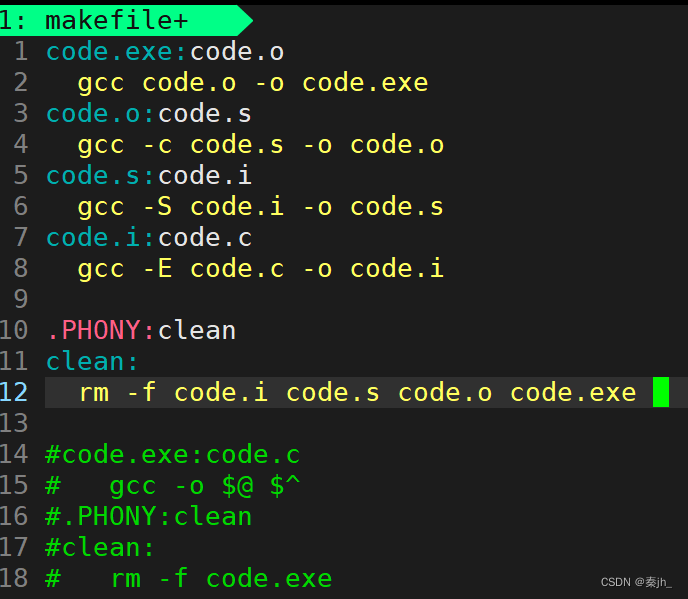
$@是指取目标文件,$^是指取依赖文件列表。$的作用是取符号的内容。
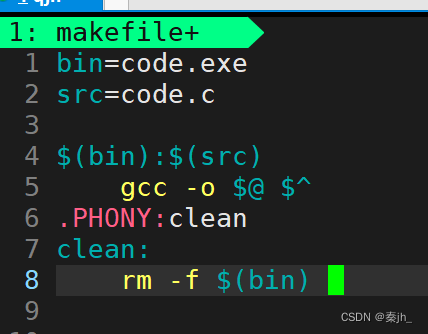
vim里面也可以定义变量的。直接用=号,两边不要空格 。这里的定义变量就相当于c语言里的宏一样,可以进行替换。
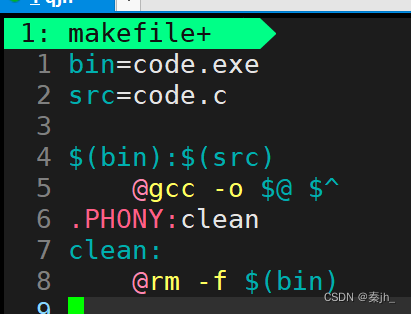
@符号的作用:在外面执行指令时,不会打印出依赖方法 。
一对依赖关系不止只有一个依赖方法。如上图,还可以发现,echo打印的语句里面$(src)也会被进行替换。
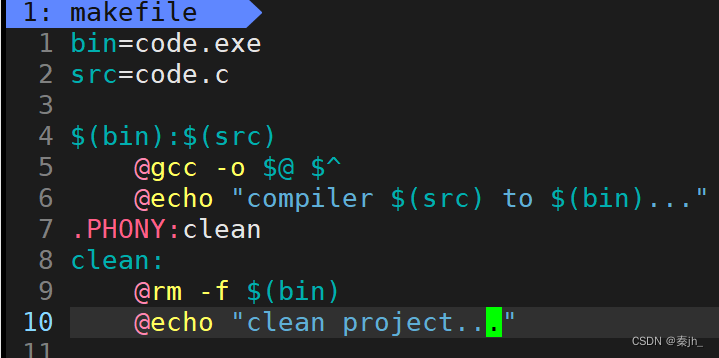
依赖关系实例
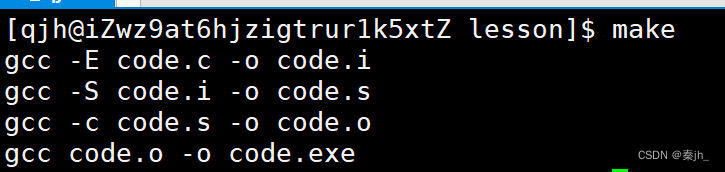
在makefile里面,注释是用 #。 make指令原本只会执行第一对依赖关系,但是上面例子却把后面的几对依赖关系都执行了。
原理:
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件,并把这个文件作为最终的目标文件。
- 如果该文件不存在,他就会执行后面所定义的命令来生成这个文件。
- 如果所依赖的code.o文件不存在,那么make会在当前文件中找目标为code.o文件的依赖性,如果找到则再根据那一个规则生成code.o文件。(这有点像一个堆栈的过程)
- 然后再用 code.o 文件声明 make的终极任务,也就是执行文件cod.exe了。
- make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错, 而对于所定义的命令的错误,或是编译不成功,make根本不理。
上面除了第一对依赖关系不能改变位置,因为他是终极任务,后面几对依赖关系的顺序可以随便换。
Linux第一个小程序-进度条
缓冲区
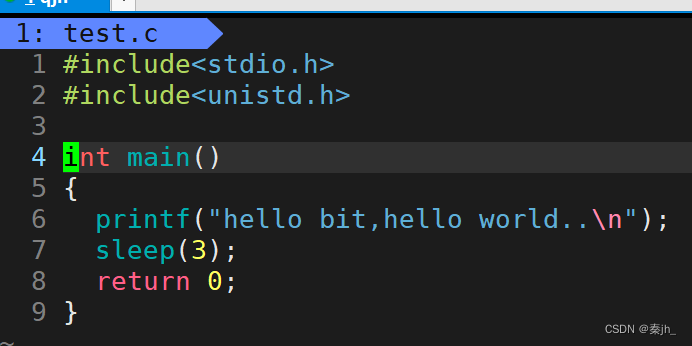

运行可执行程序后,发现打印完成后,会停留3秒然后才显示下一个命令行。
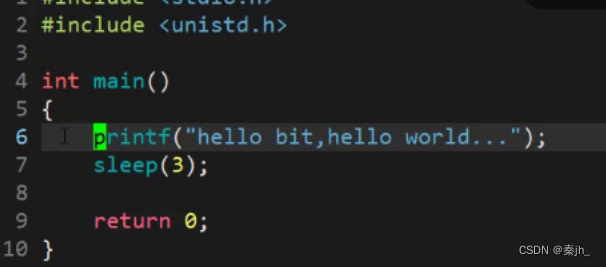

当我们把’\n"去掉后,发现运行时,会先停留3秒,然后才会打印。 这是因为此时要打印的内容都在缓冲区里面。程序结束的时候,一般会自动冲刷缓冲区。
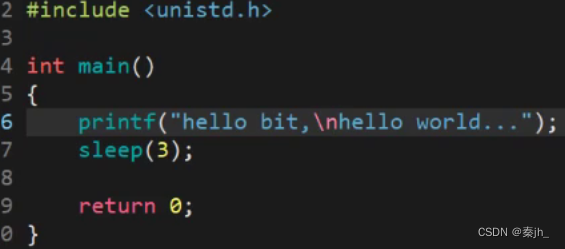

如果把"\n"放到中间,就会先打印包括\n的前面的内容,休眠3秒后再打印后面的内容。
冲刷缓冲区有三种方法:
- \n
- 缓冲区满了
- 强制刷新:fflush
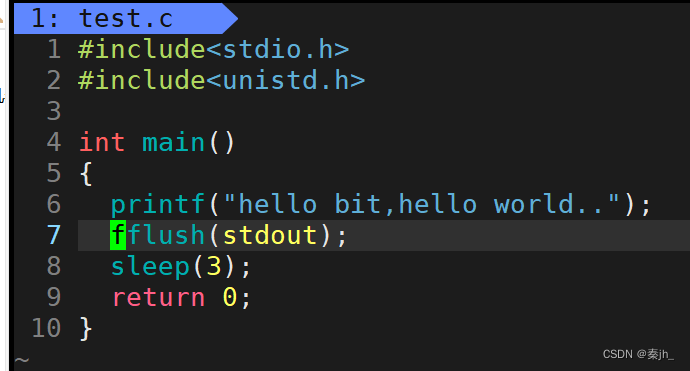

stdout就是显示器的意思。缓冲区是以行刷新的,如果不想换行,就可以用fflush刷新。
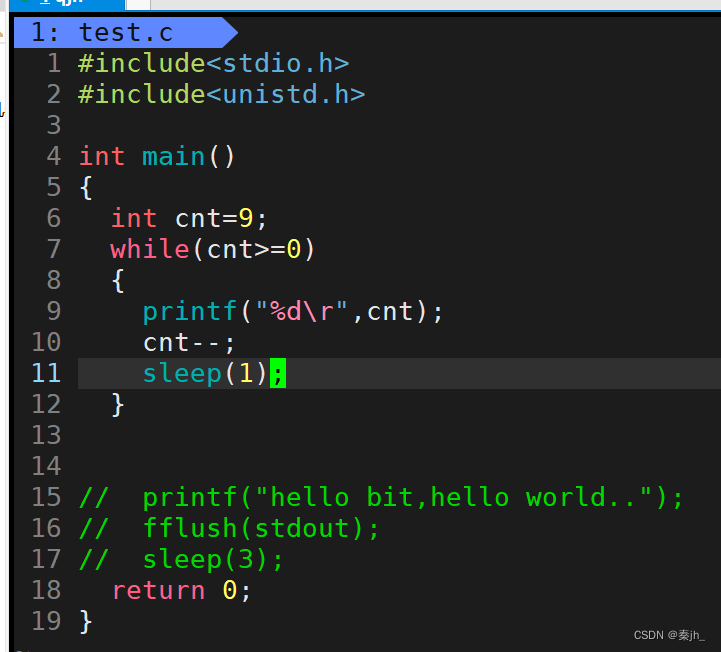

上面是打印倒计时的程序,不过在运行时,为什么不会进行打印呢?因为\r会让光标回到行首,光标指的地方,内容就被覆盖了,下图是在VS中测试的结果,此时光标在3的位置,3就被覆盖了,无法打印出来。
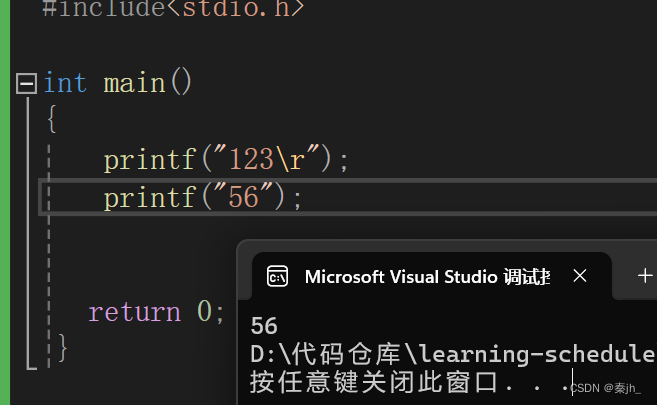
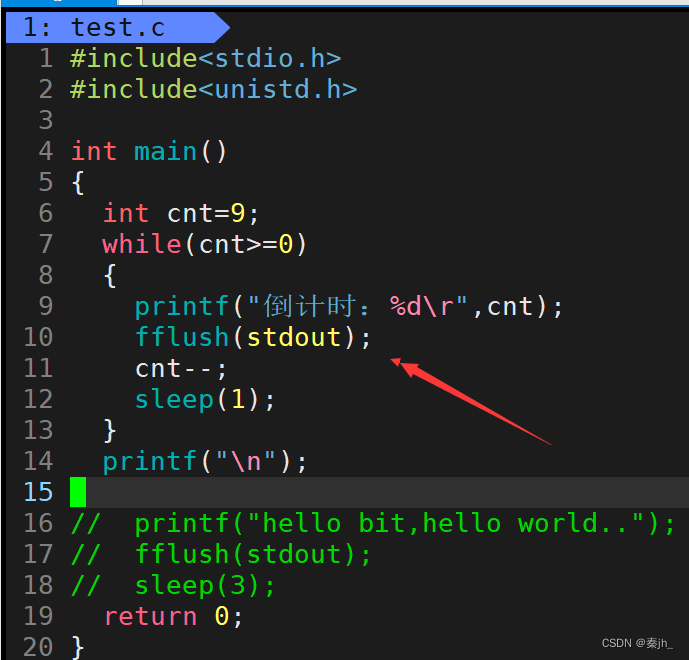
我们只需要fflush强制冲刷缓冲区就可以解决了。
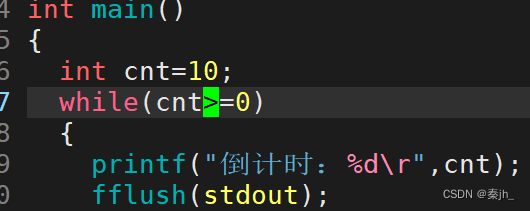

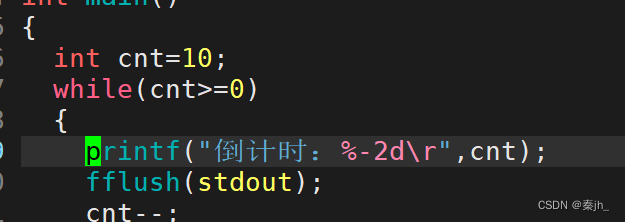
如果我们把倒计时从10开始,会发现打印时后面会多一个0。因为我们打印时,打印的是字符,光标没有移动到后面,就不会把10后面的0覆盖掉。只需要在%后面加上-2即可,如下图:
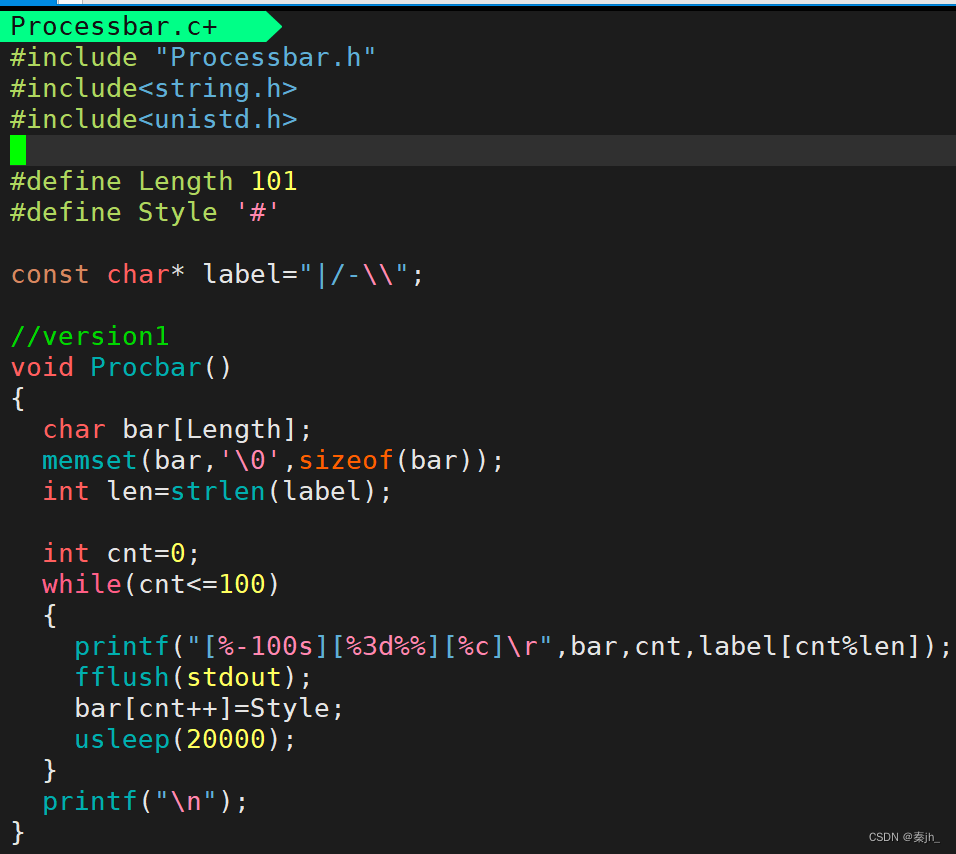
进度条版本1(直接显示)
版本2(下载场景)
Main.c
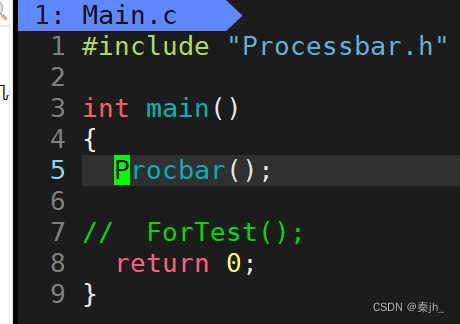
#include "Processbar.h" double bandwidth=1024*1024*1.0; //donwload void download(double filesize,callback_t cb) { double current=0.0; printf("download begin,current:%lf\n",current); while(current<=filesize) { cb(filesize,current); current+=bandwidth; usleep(10000); } printf("\ndownload done,filesize:%lf\n",filesize); } int main() { download(100*1024*1024,Procbar); download(20*1024*1024,Procbar); download(3*1024*1024,Procbar); download(125*1024*1024,Procbar); //Procbar(100.0,46.2); //Procbar(100.0,77.8); //Procbar(100.0,99.9); // Procbar(); // ForTest(); return 0; }Processbar.c
#include "Processbar.h" #include<string.h> #include<unistd.h> #define Length 101 #define Style '#' const char* label="|/-\\"; //version1 //void Procbar() //{ // char bar[Length]; // memset(bar,'\0',sizeof(bar)); // int len=strlen(label); // // int cnt=0; // while(cnt<=100) // { // printf("[%-100s][%3d%%][%c]\r",bar,cnt,label[cnt%len]); // fflush(stdout); // bar[cnt++]=Style; // usleep(20000); // } // printf("\n"); //} //version 2 void Procbar(double total,double current) { char bar[Length]; memset(bar,'\0',sizeof(bar)); int len=strlen(label); int cnt=0; double rate=(current*100.0)/total; int loop_count=(int)rate; while(cnt<=loop_count) { bar[cnt++]=Style; // usleep(20000); } printf("[%-100s][%.1lf%%][%c]\r",bar,rate,label[cnt%len]); fflush(stdout); } //void ForTest() //{ // printf("This is for test\n"); // printf("This is for test\n"); // printf("This is for test\n"); // printf("This is for test\n"); // printf("This is for test\n"); // printf("This is for test\n"); //} Processbar.h
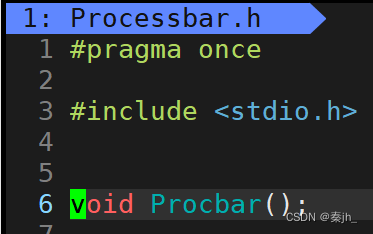
#pragma once #include <stdio.h> typedef void(*callback_t)(double,double); void Procbar(double total,double current); //void Procbar(); //extern void ForTest();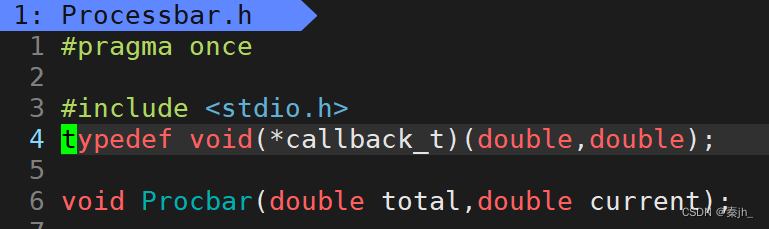
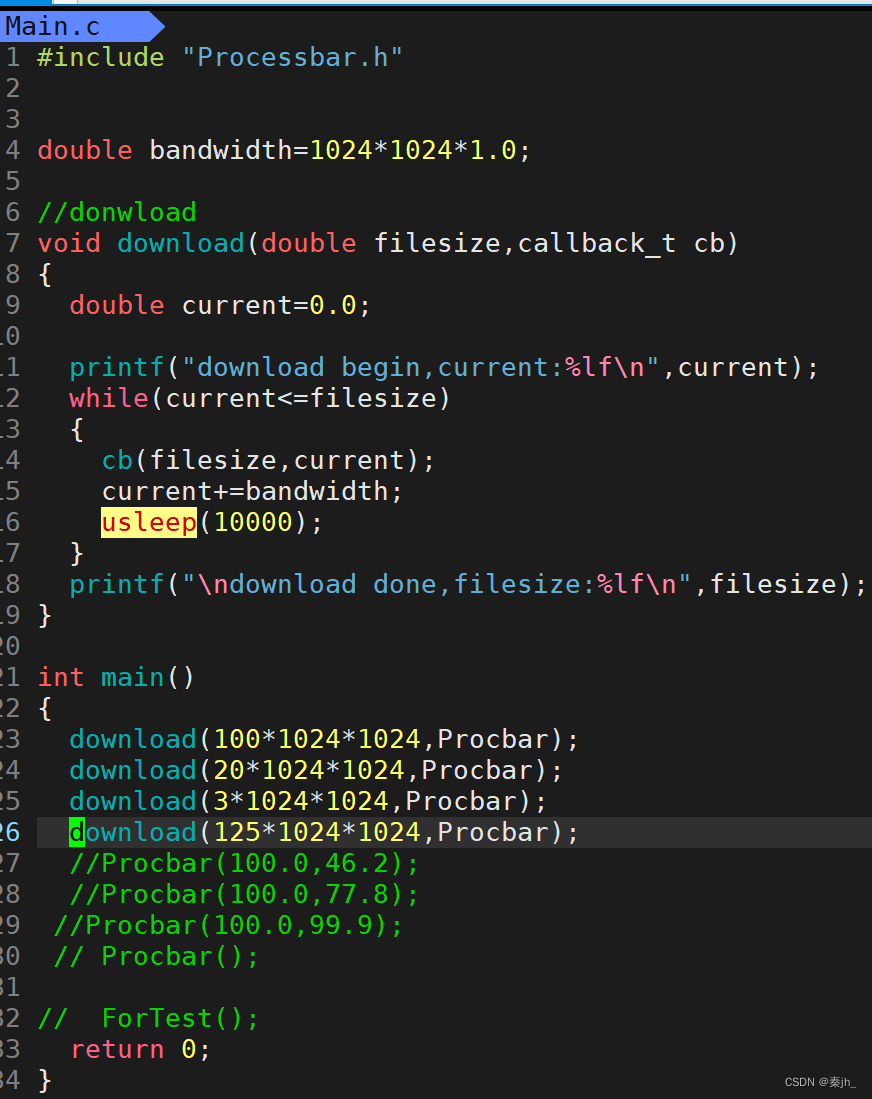
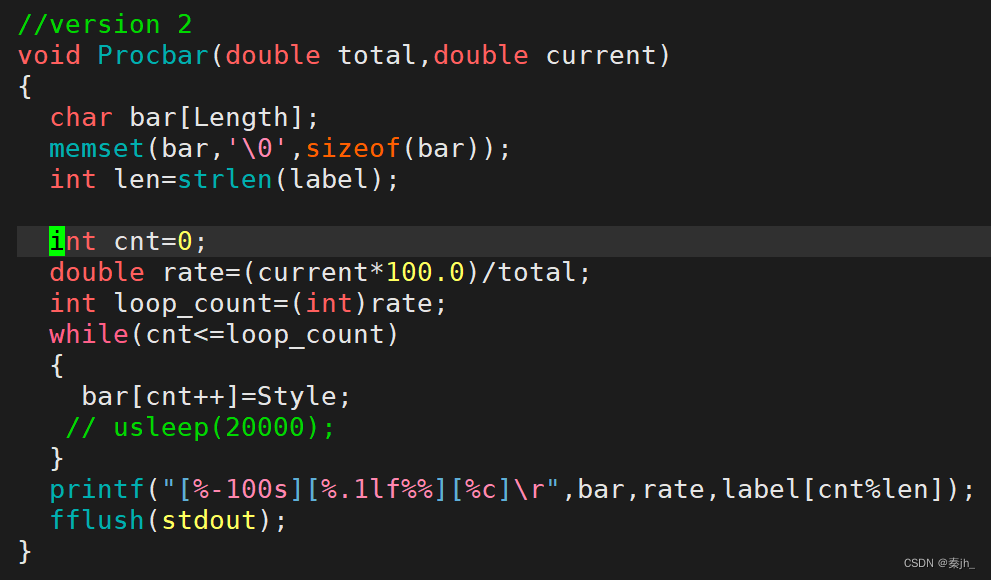
头文件中typedef了一个函数,Main.c文件的download函数有一个函数参数。原因:如果后期需要图形化界面,传参传别的函数就可以了,不需要改变现在的函数。
运行结果图:
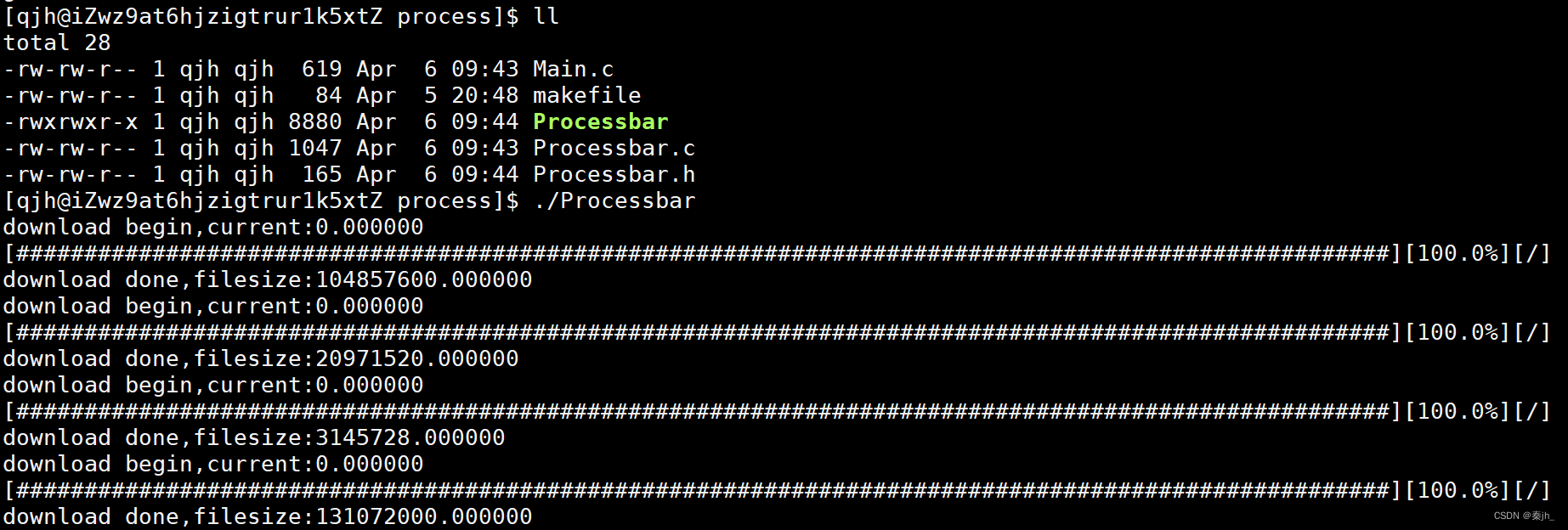
使用 git 命令行
安装 git
sudo yum install -y git
使用 Gitee 创建项目
git是一个工具,gitee、github就是为这个工具搭建的网站,即可视化。
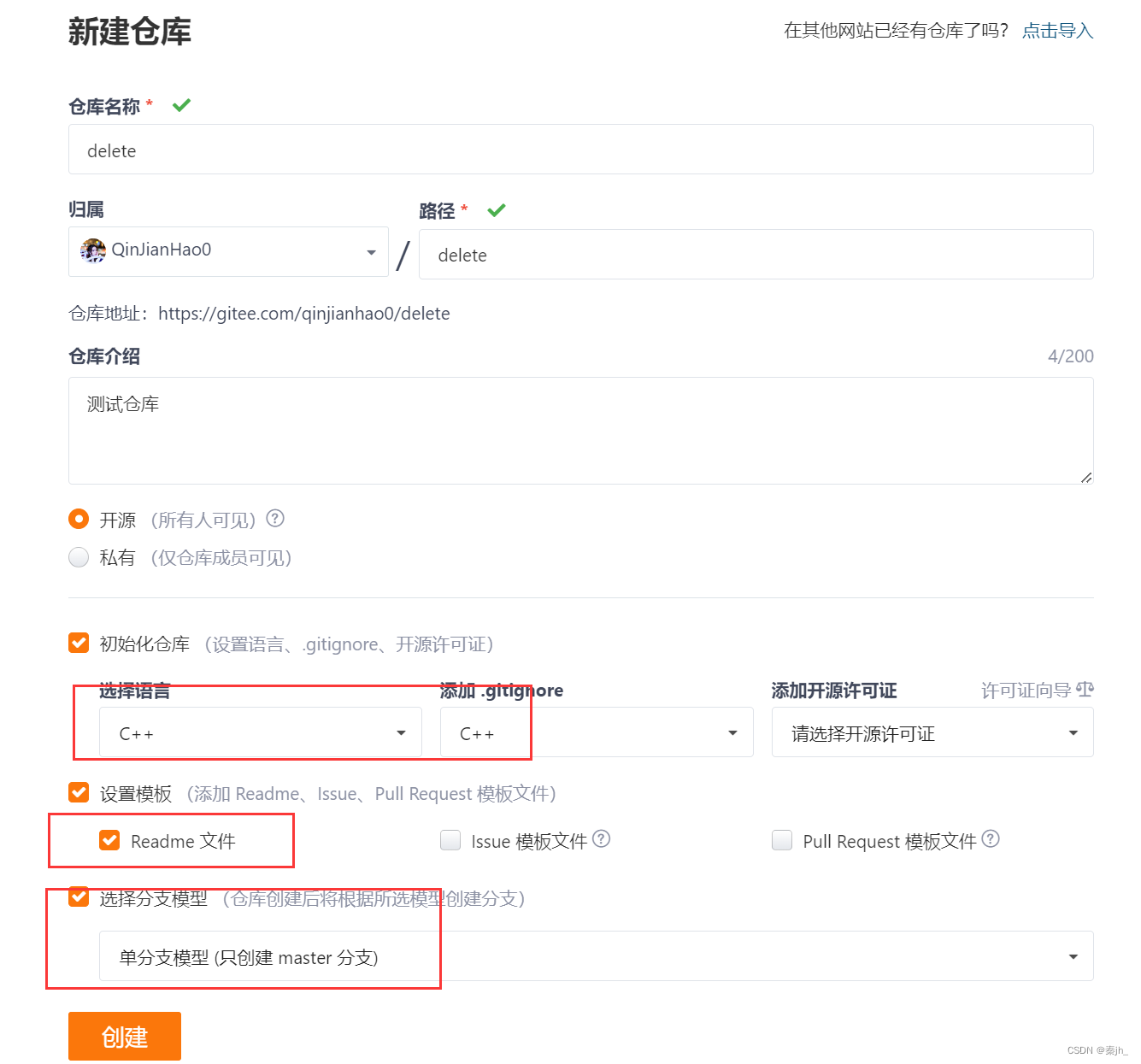
初始化,语言选择你自己的语言。,模板勾选第一个就行 ,readme就是这个仓库简单的说明,创建后会自动生成中文和英文的说明。分支选择单分支就行。
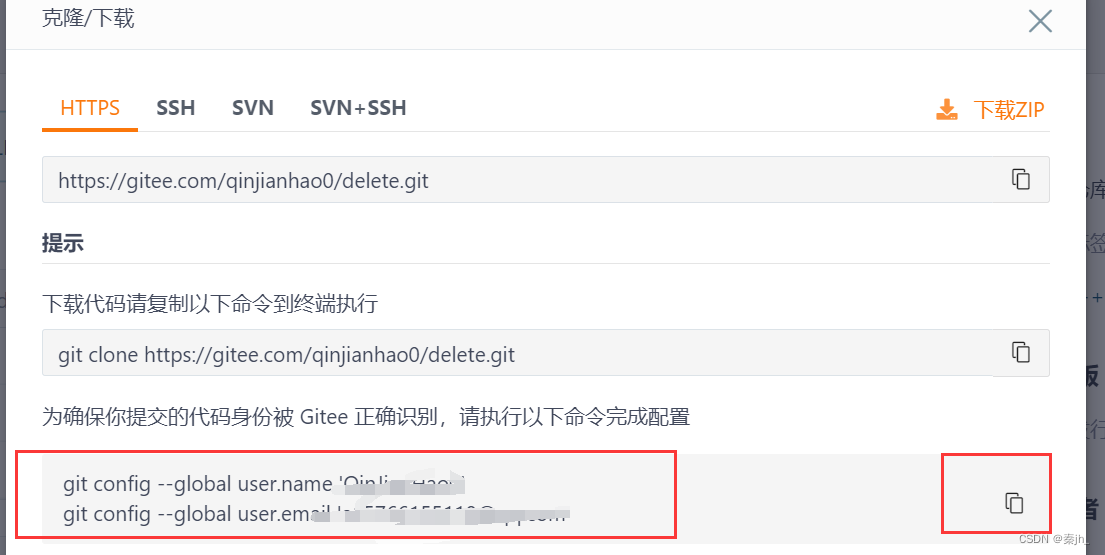

创建完仓库后,还需要在本地进行配置,复制粘贴即可。
拉取
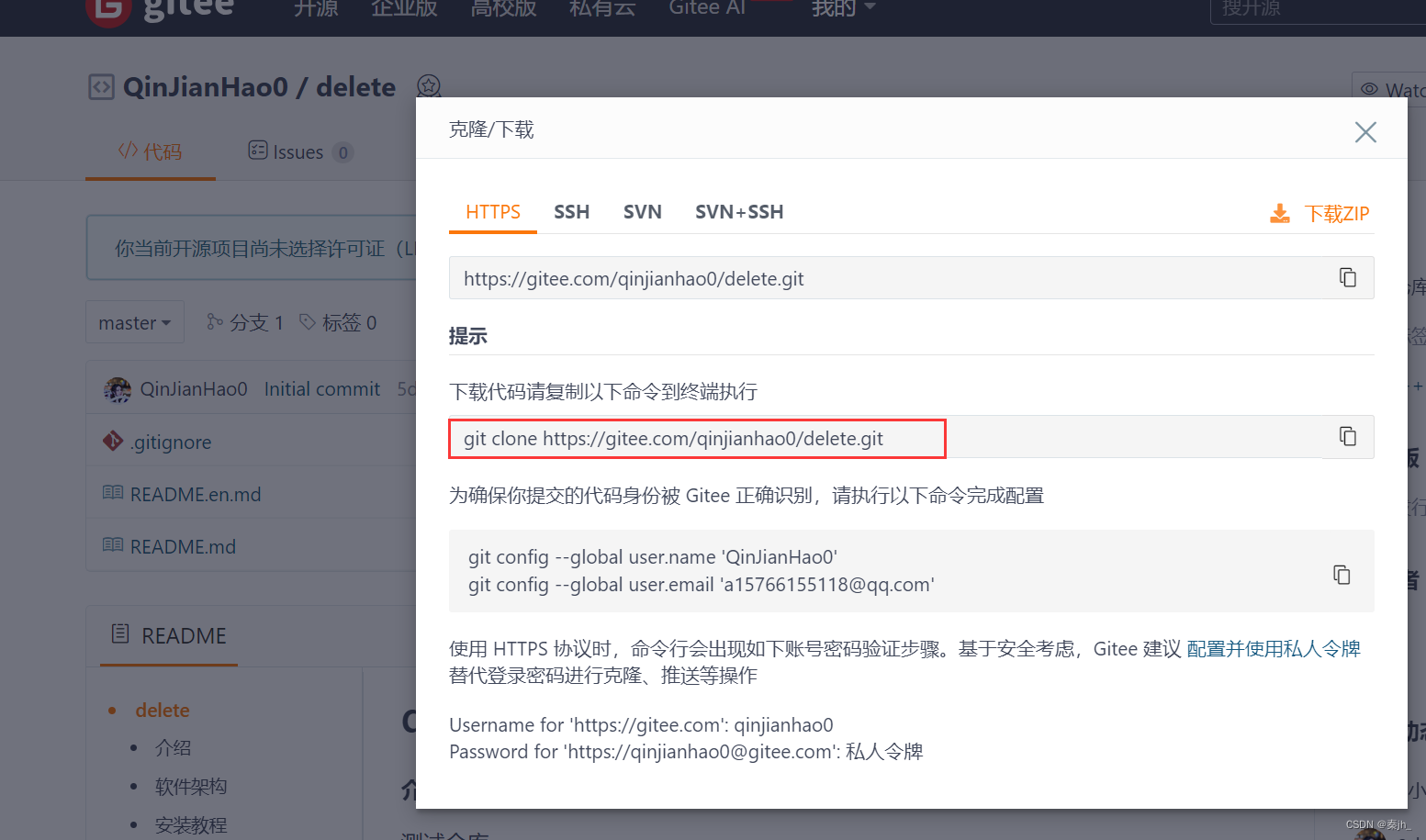
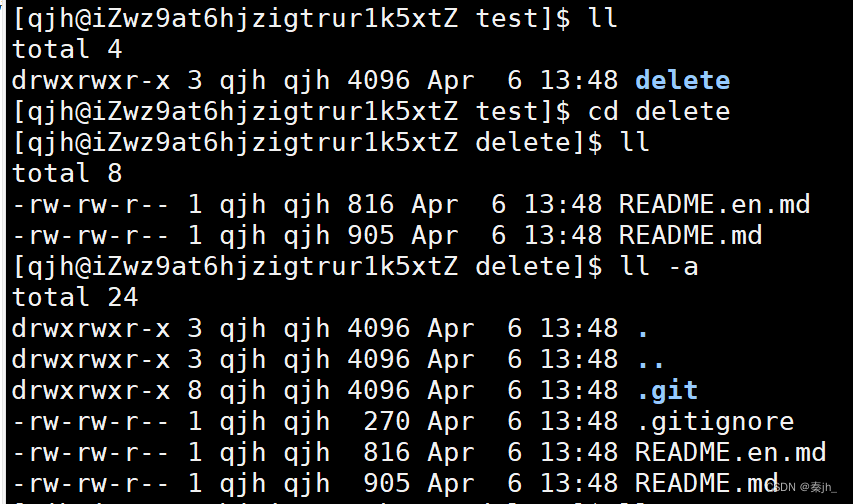
复制然后粘贴,这时就把远程仓库,拉取下来了。我们还能.git隐藏文件,它就是我们的工作目录,我们不能去修改它,不然就很容易出错。
本地传到远程
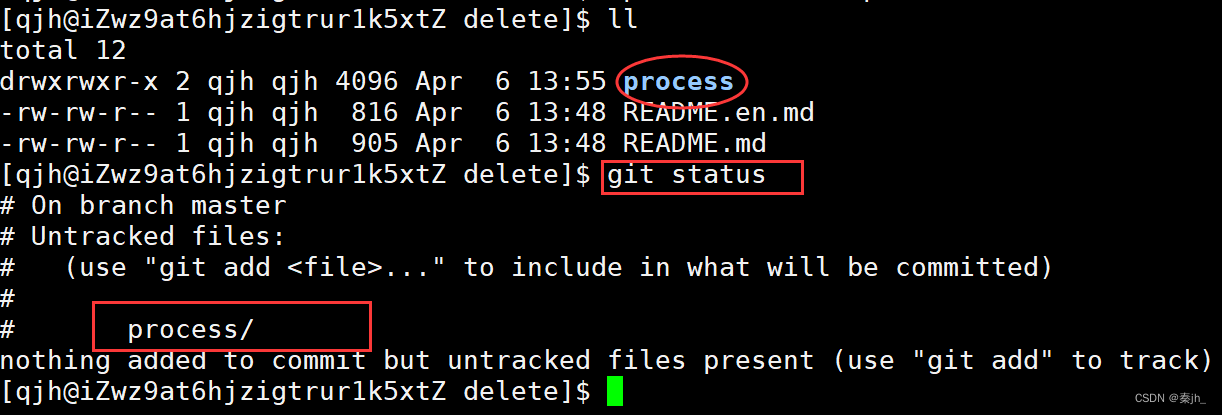
我们想把要上传的内容cp到本地,然后git status查看本地和远端仓库的状态,这里显示process是没有被添加到本地仓库的。
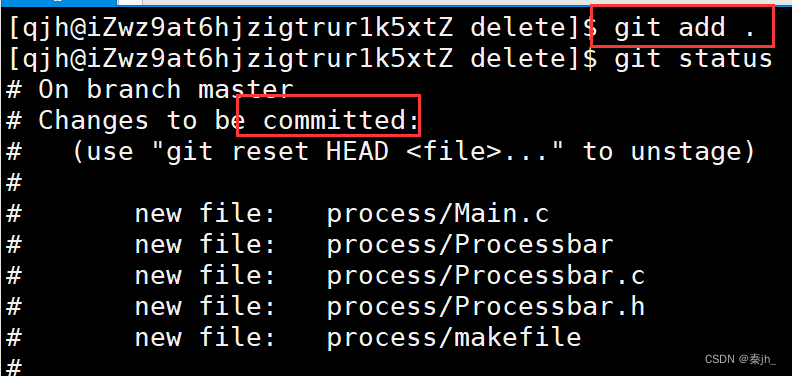
使用git add 后面可以是文件名,也可以是 . ,.就是把当前位置的所有文件都添加到本地仓库。
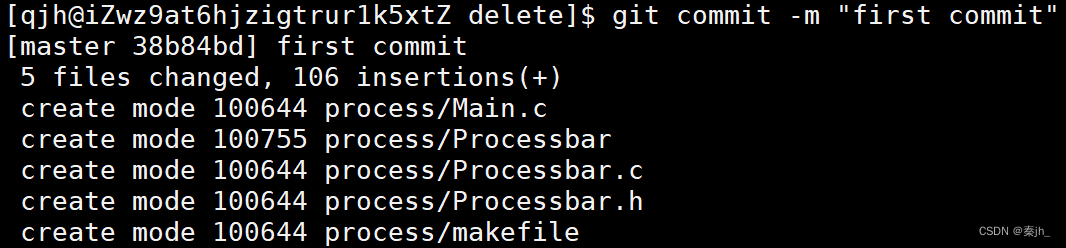
-m 后面跟的是本次提交的日志,必须要写,不能省略。 此步骤是把内容提交到本地仓库中,跟远端没有关系。
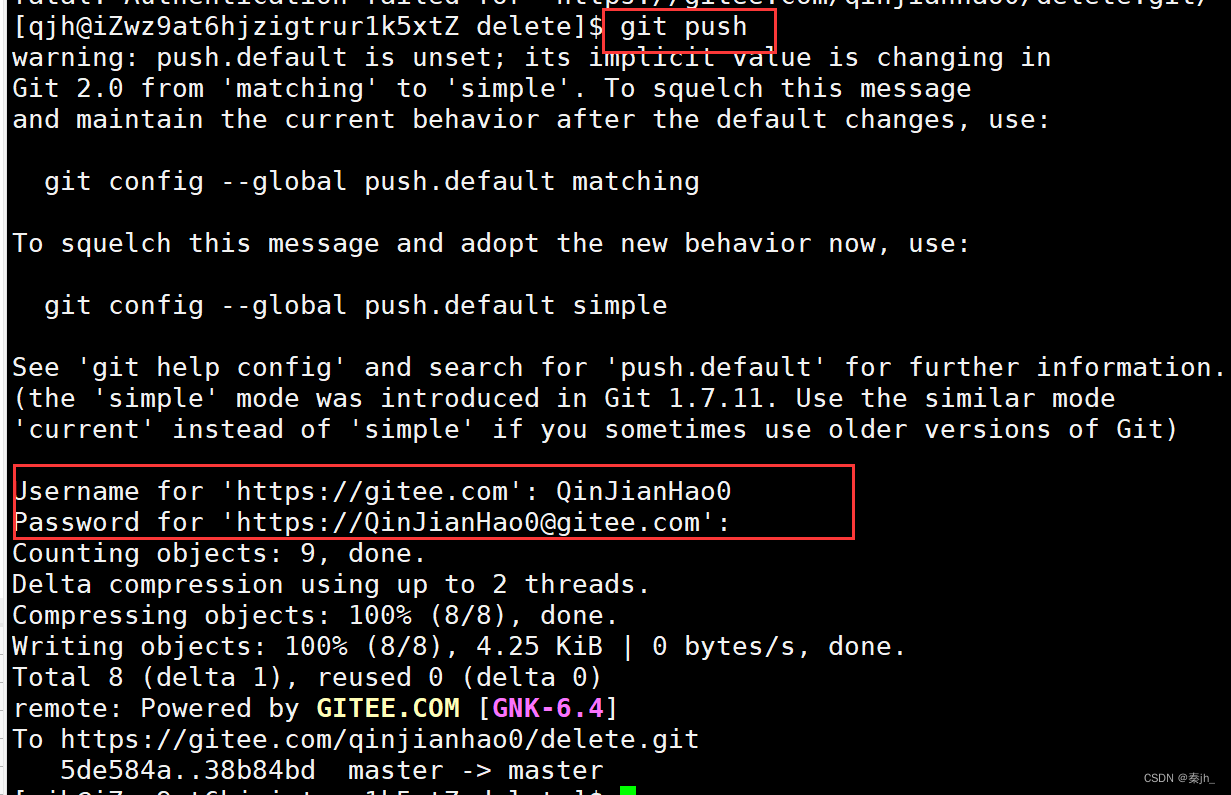


最后一步,git push 后,输入用户名和密码即可完成同步。这时就可以看到已经上传完毕了。
过程解释
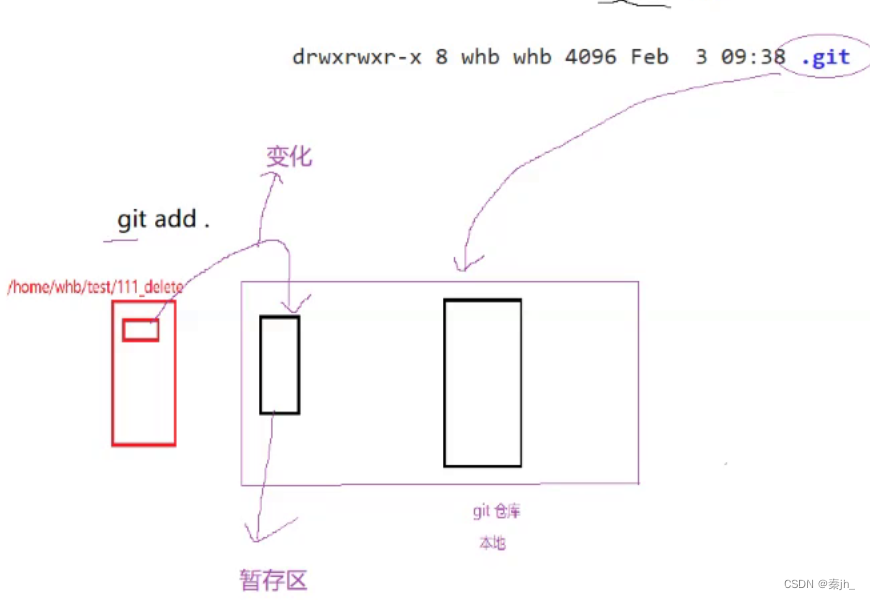
.git目录也就是git的本地仓库,add会把上传的内容中,有变化的部分放到一个暂存区。
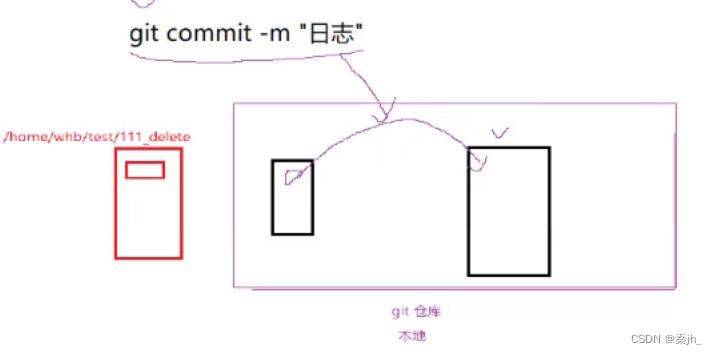
commit会把暂存区里的内容真正上传到本地仓库,并清空暂存区。最后push就是把本地仓库跟远端进行同步。
修改内容
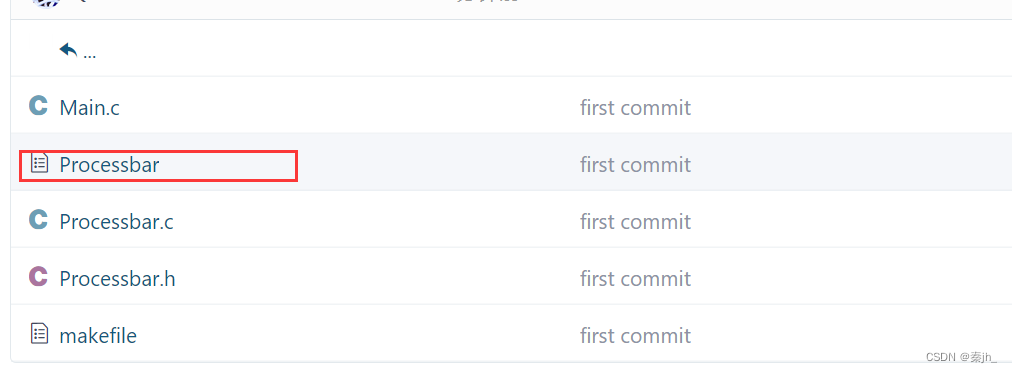
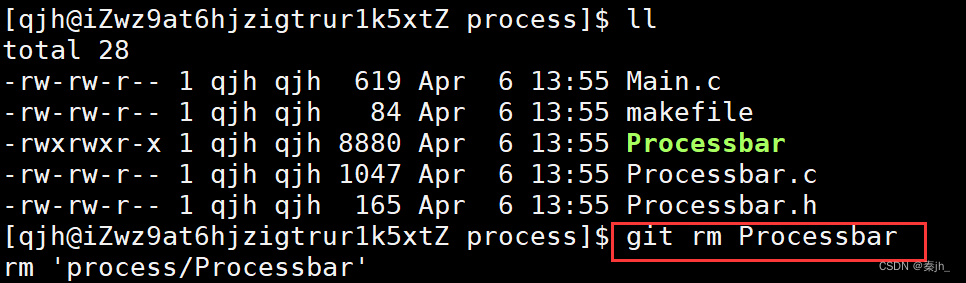

修改后,还是按照流程add、commit、push操作即可。
