阅读量:1
吾名爱妃,性好静亦好动。好编程,常沉浸于代码之世界,思维纵横,力求逻辑之严密,算法之精妙。亦爱篮球,驰骋球场,尽享挥洒汗水之乐。且喜跑步,尤钟马拉松,长途奔袭,考验耐力与毅力,每有所进,心甚喜之。
吾以为,编程似布阵,算法如谋略,需精心筹谋,方可成就佳作。篮球乃团队之艺,协作共进,方显力量。跑步与马拉松,乃磨炼身心之途,愈挫愈勇,方能达至远方。愿交志同道合之友,共探此诸般妙趣。
诸君,此文尚佳,望点赞收藏,谢之!
1. 下载llama.cpp框架编译环境(llama.cpp/docs/build.md at master · ggerganov/llama.cpp · GitHub):
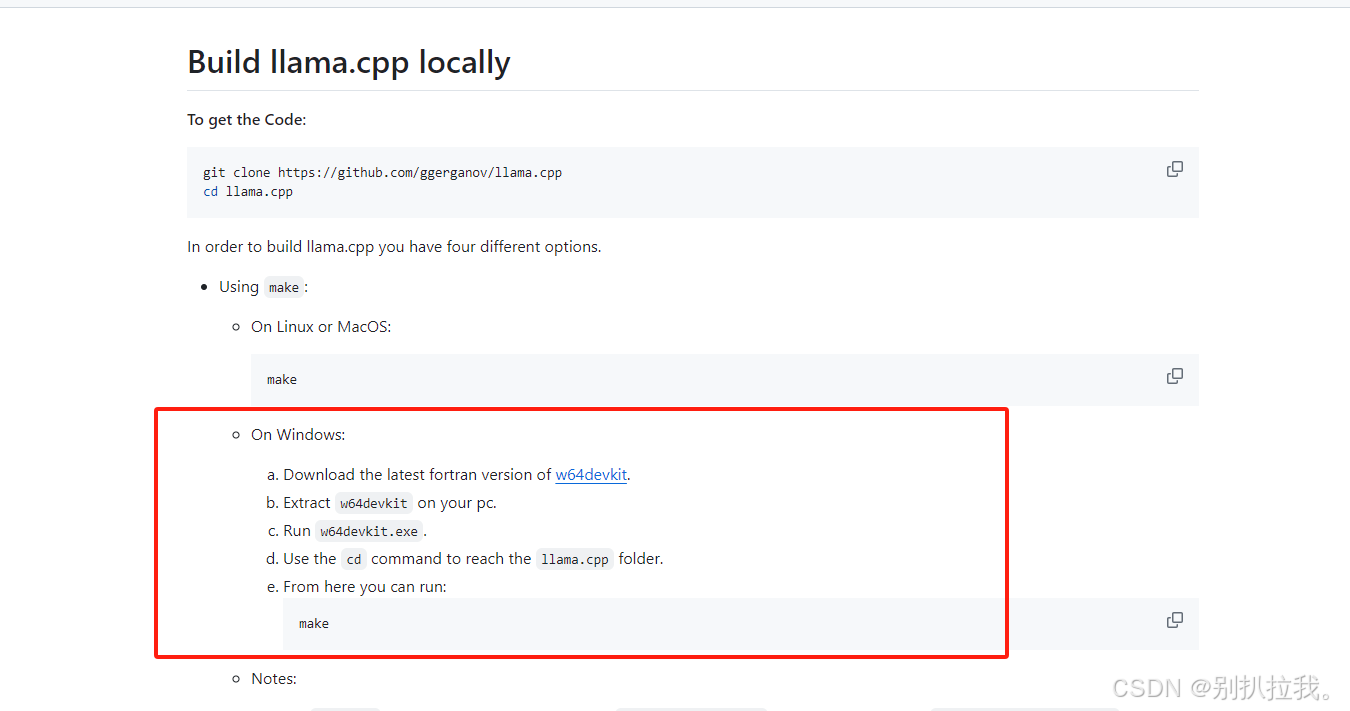
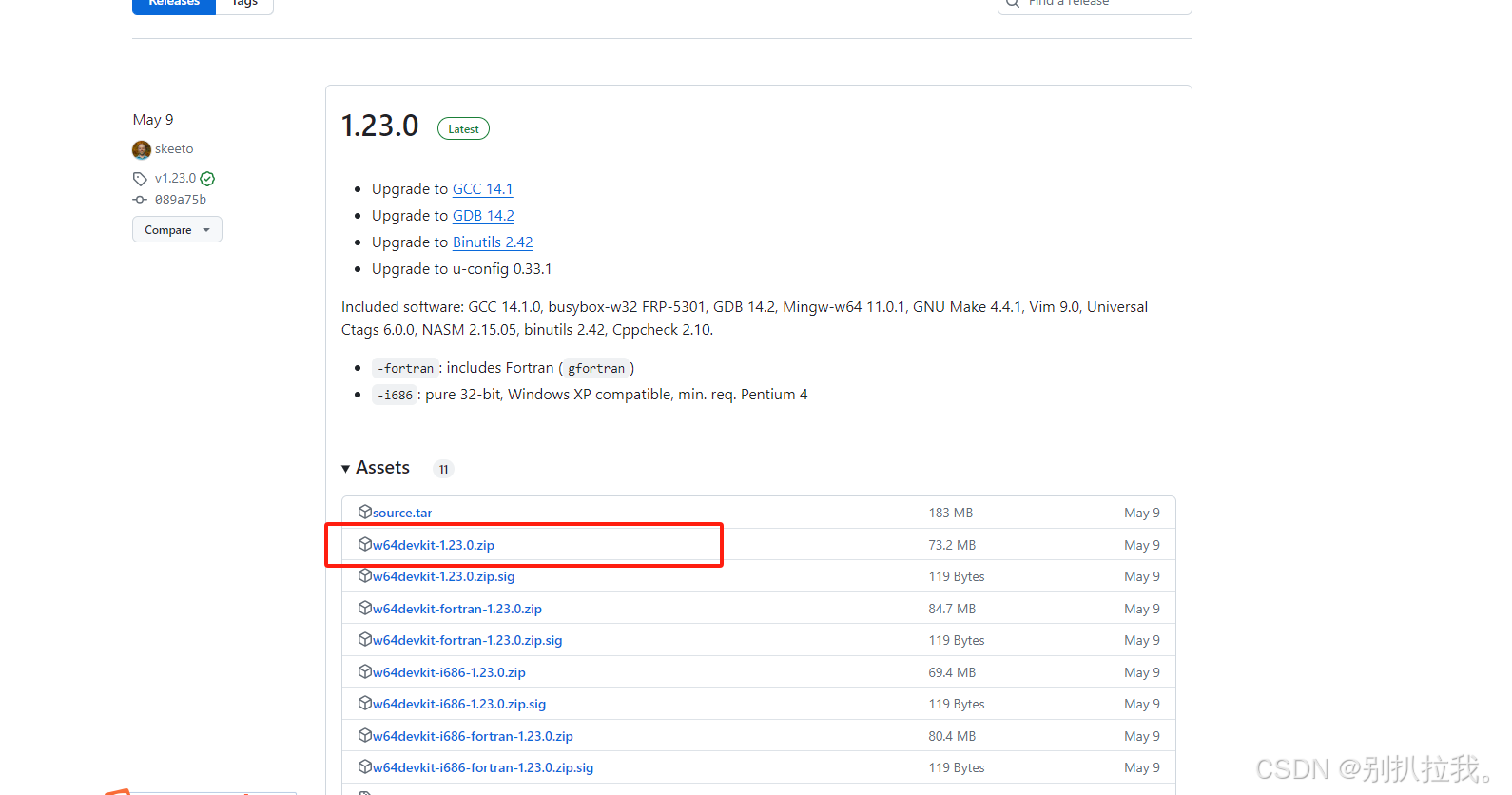
2. 下载w64devkit:Releases · skeeto/w64devkit · GitHub
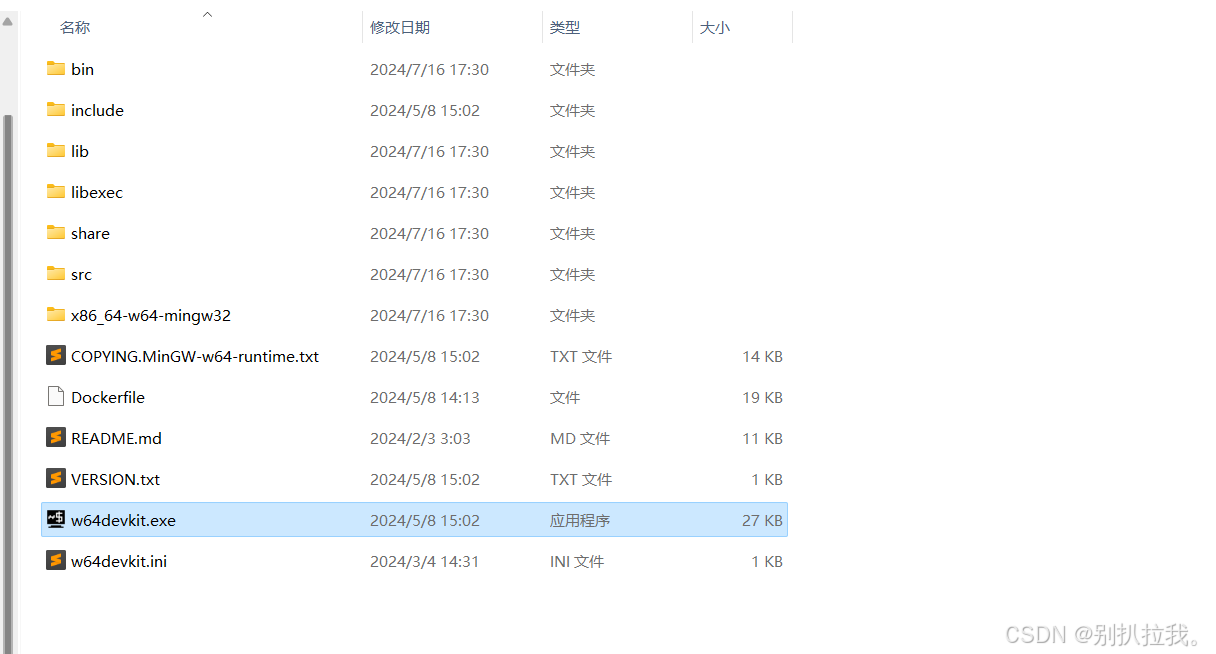
3. 解压后直接运行w64devkit.exe:

4. 下载llama.cp源码:
git clone https://github.com/ggerganov/llama.cpp进入llama.cpp目录,执行make命令:
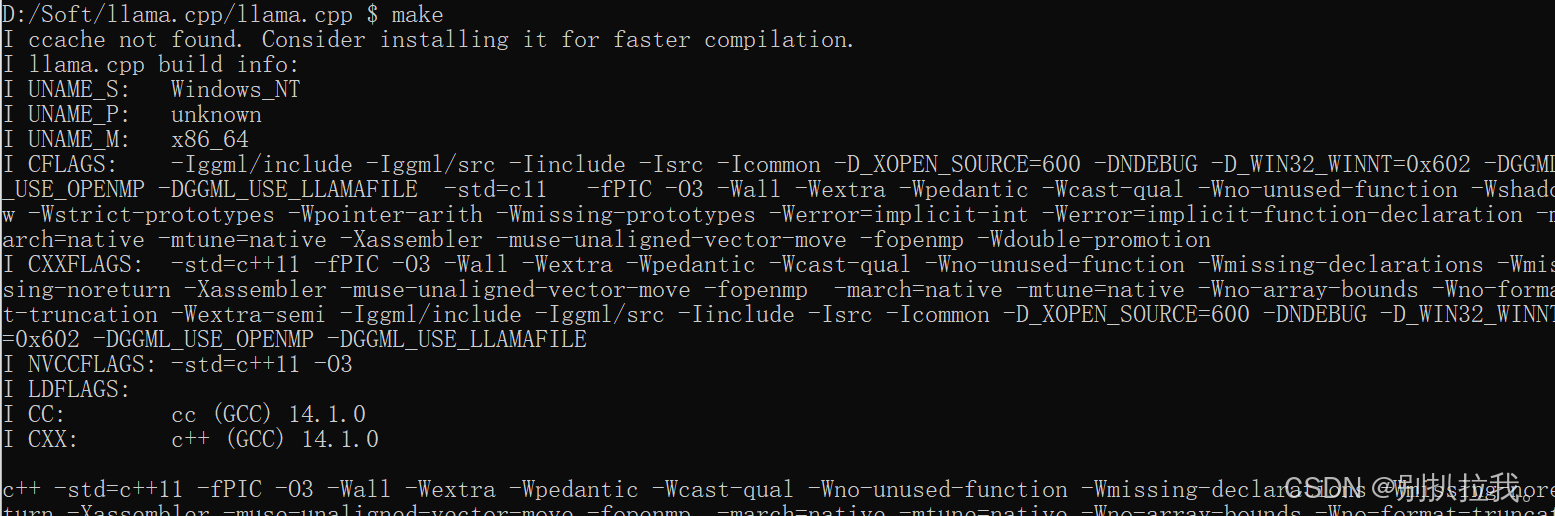
5. 运行后,在llama.cpp目录找到llama-cli.exe表示安装成功
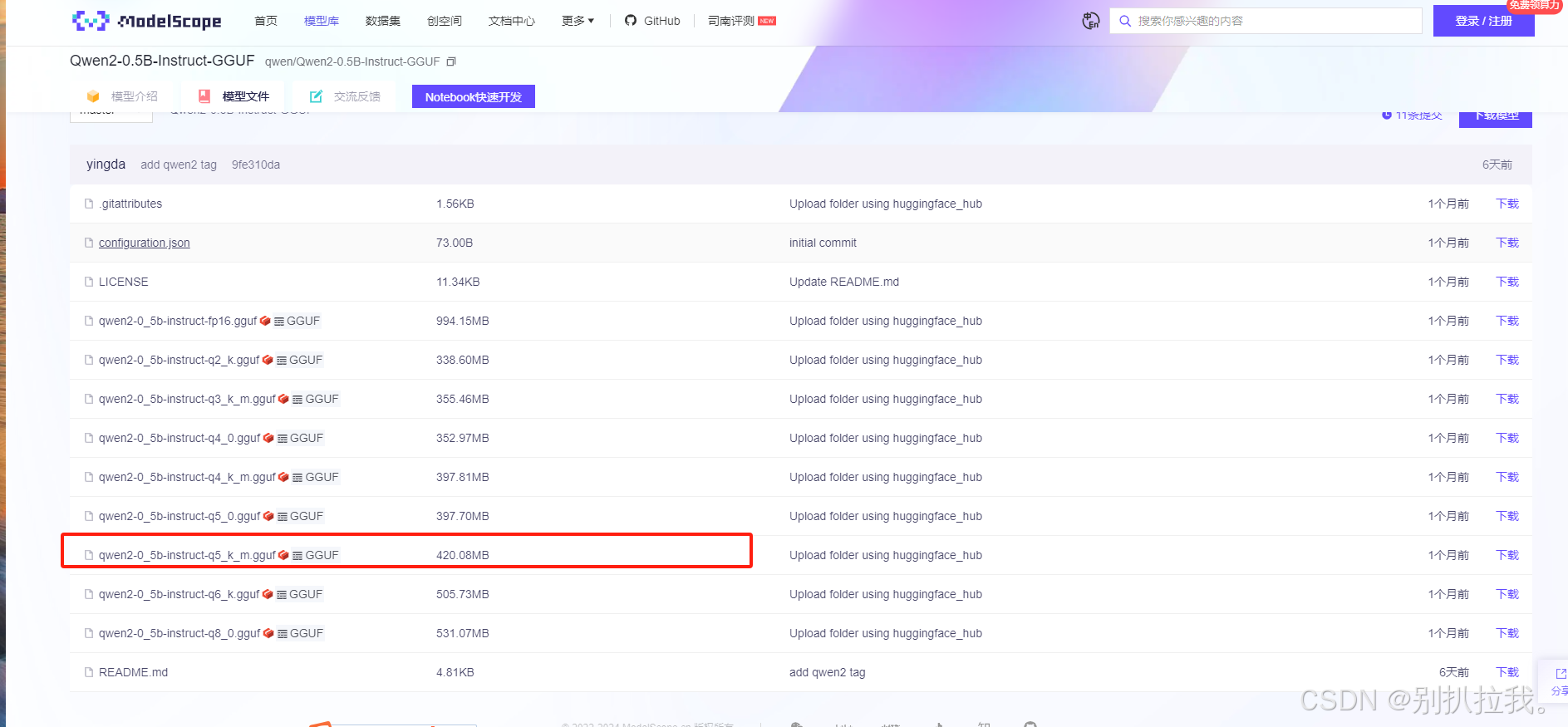
6. 下载Qwen2-0.5B-Instruct-GGUF格式模型:魔搭社区
7.在llama-cli.exe文件所在目录新建chat-with-qwen.txt文件,内容为:You are a helpful assistant.
在llama-cli.exe文件所在目录打开命中行,执行:
llama-cli.exe -m ..\Qwen2-0.5B-Instruct-GGUF\qwen2-0_5b-instruct-q5_k_m.gguf -n 512 -co -i -if -f chat-with-qwen.txt --in-prefix "<|im_start|>user\n" --in-suffix "<|im_end|>\n<|im_start|>assistant\n" -ngl 24结果:
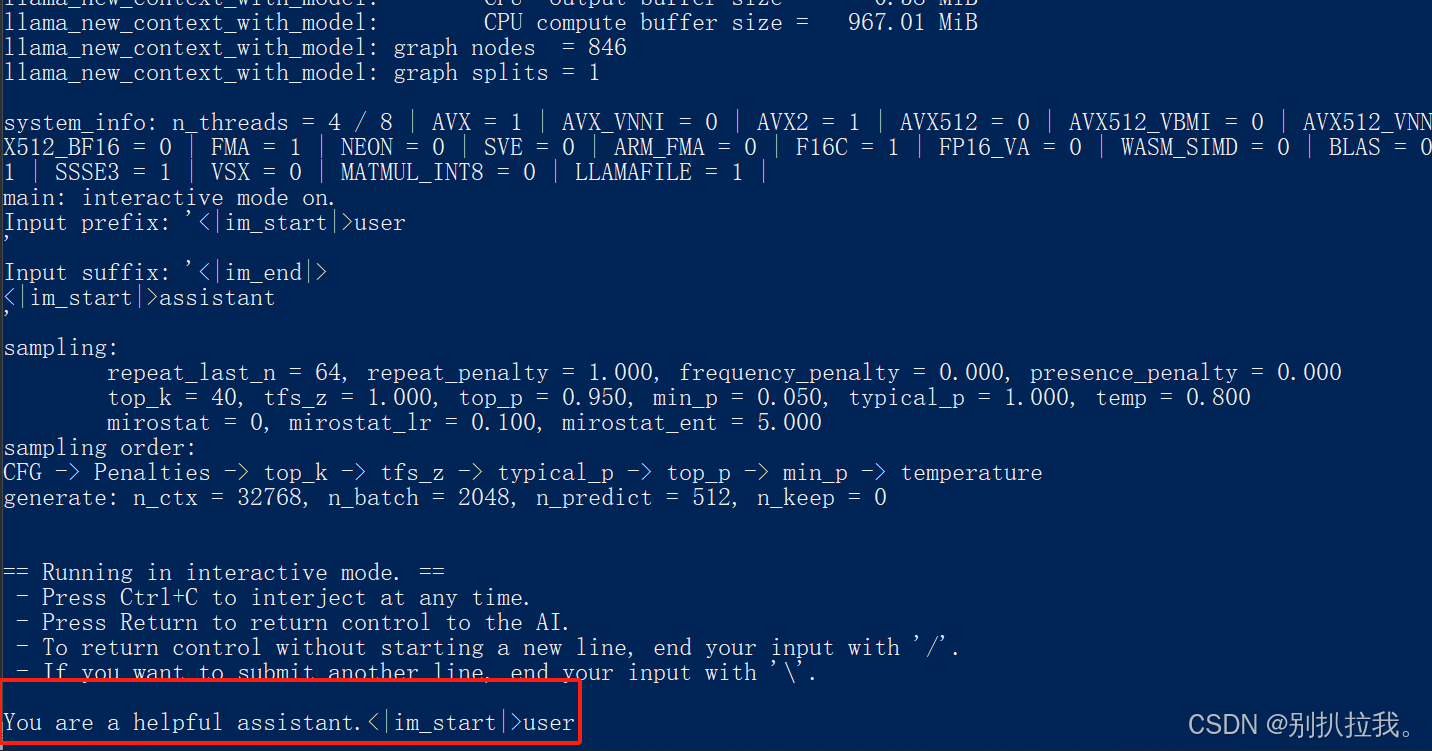
可以进行交互了~
8. 以服务的形式运行模型:
llama-server.exe -m ..\Qwen2-0.5B-Instruct-GGUF\qwen2-0_5b-instruct-q5_k_m.gguf -ngl 24 -fa结果:
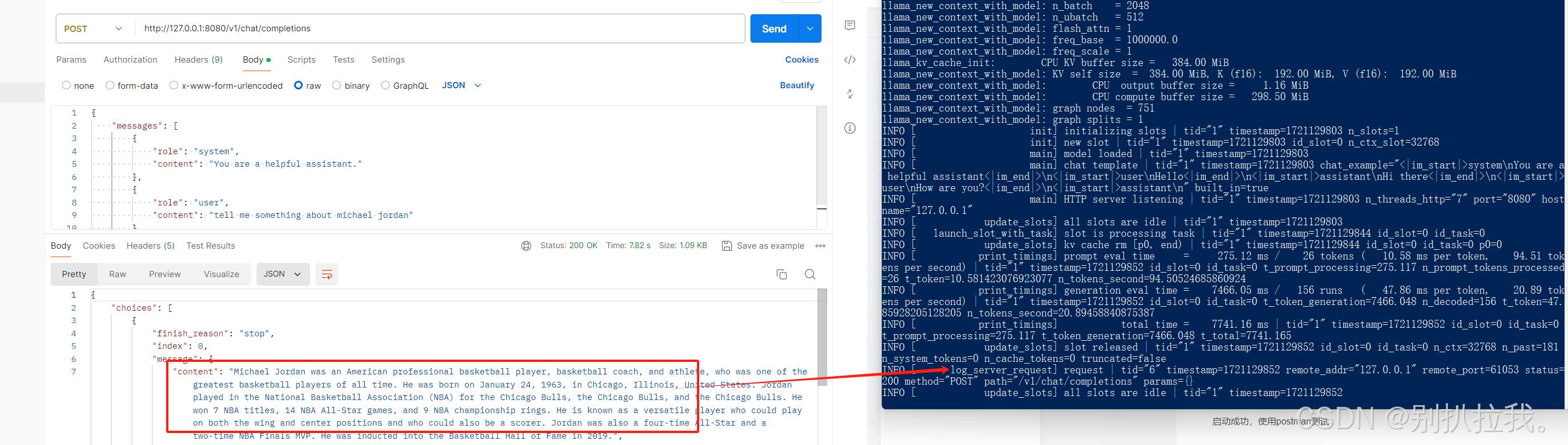
启动成功,使用postman测试: