
阅读量:1
腾讯宣布开源可控视频生成框架 MimicMotion,该框架可以通过提供参考人像及由骨骼序列表示的动作,来产生平滑的高质量人体动作视频
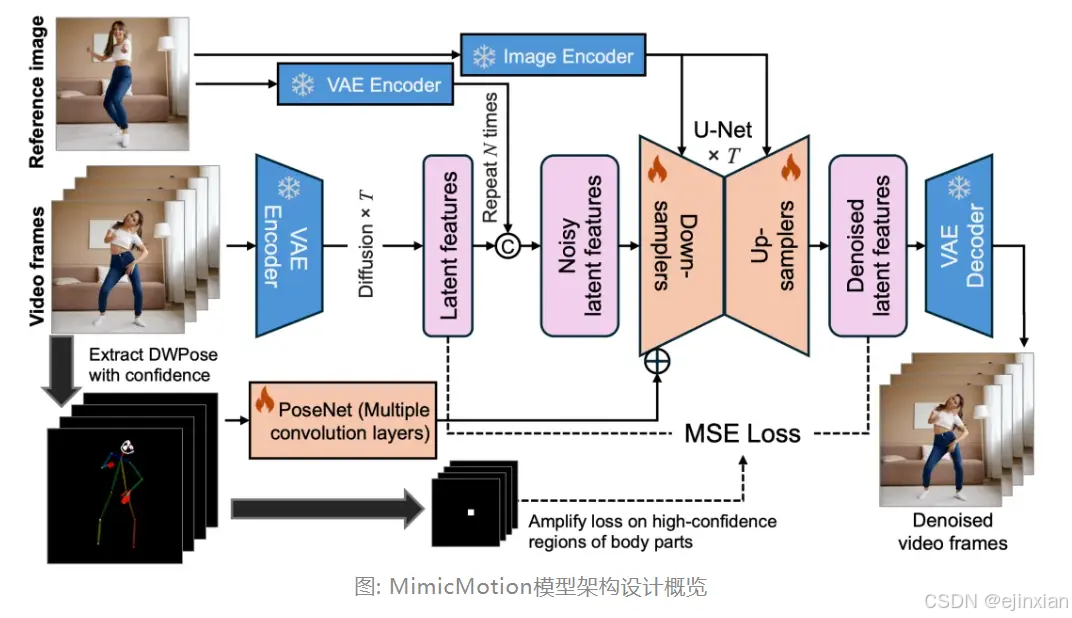
MimicMotion 具有以下几个亮点:
- 首先,通过引入了置信度感知的姿态引导信号,大幅提升了帧间一致性,使得产生的视频在时序上能够做到平滑自然。
- 其次,通过放大置信度感知的区域损失,显著减少了图像失真,使得局部画面如人体手部细节得到了大幅改善。
最后,通过结合扩散过程的渐进式潜在特征融合策略,MimicMotion 能够在有限的算力资源内生成无限长的视频同时保证画面连贯。

MimicMotion 在生成多种形式的人体动作视频上均具有良好的结果,包括半身动作、全身动作以及谈话动作视频。相比现有的开源方案如 MagicPose、Moore-AnimateAnyone 等;
MimicMotion 具有以下几点优势:
1. 生成结果细节更加丰富且清晰,包括人体手部细节;
2. 帧间连续性更加优秀,画面无明显跳变;
3. 支持平滑的长视频生成
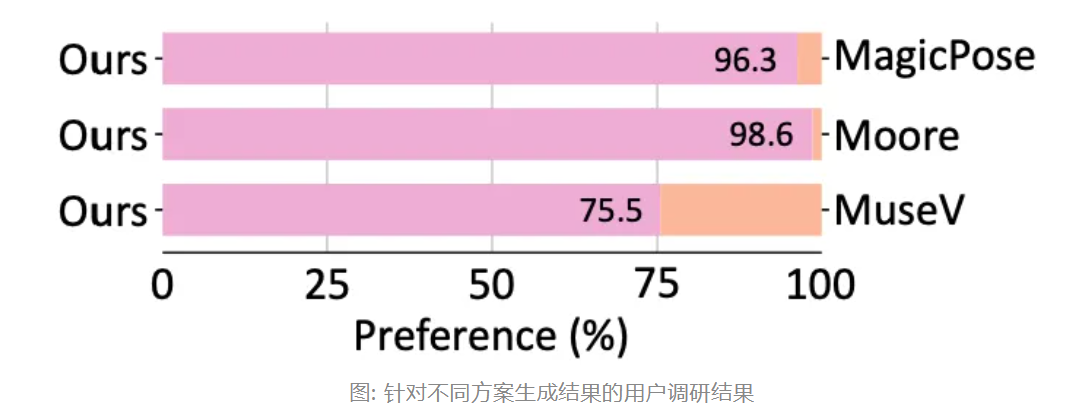
在量化指标评估实验中,MimicMotion 相比现有开源方案 MagicPose、Moore-AnimateAnyone 以及 MuseV,在 FID-VID 及 FVD 测试指标上均取得了领先。
- 官方网站:MimicMotion
- 代码仓库:https://github.com/Tencent/MimicMotion
- 论文地址:https://arxiv.org/abs/2406.19680
MagicPose:
MagicPose可以精确地生成外观一致的结果,而原始的文本到图像模型(如Stable Diffusion和ControlNet)很难准确地保持主体身份信息。
此外,MagicPose模块可以被视为原始文本到图像模型的扩展/插件,而无需修改其预训练的权重
论文链接:https://arxiv.org/pdf/2311.12052
项目链接:https://github.com/Boese0601/MagicDance
