
阅读量:5
概叙
在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数,最常见的有redis和memcached等,既然是分布式,那么他们是怎么实现分布式的呢?本文主要介绍分布式缓存服务mencached的分布式实现原理。
缓存本质
计算机体系缓存
什么是缓存,我们先看看计算机体系结构中的存储体系,根据冯·诺依曼计算机体系结构模型,计算机分为五大部分:运算器、控制器、存储器、输入设备、输出设备。结合现代计算机,CPU包含运算器和控制器两个部分,CPU负责计算,其需要的数据由存储提供,存储分为几个级别,就拿我当前的PC举个例子,我的机器存储清单如下:
1.356G的磁盘
2.4G的内存
3.3MB三级缓存
4.256KB二级缓存(pre core)
除了上述部分,还有CPU内的寄存器,当然有的计算机还有一级缓存等。CPU运算器工作的时候需要数据,数据哪里来?首先从距离CPU最近的二级缓存去拿,这块缓存速度最快,通常也是体积最小,因为价格最贵:
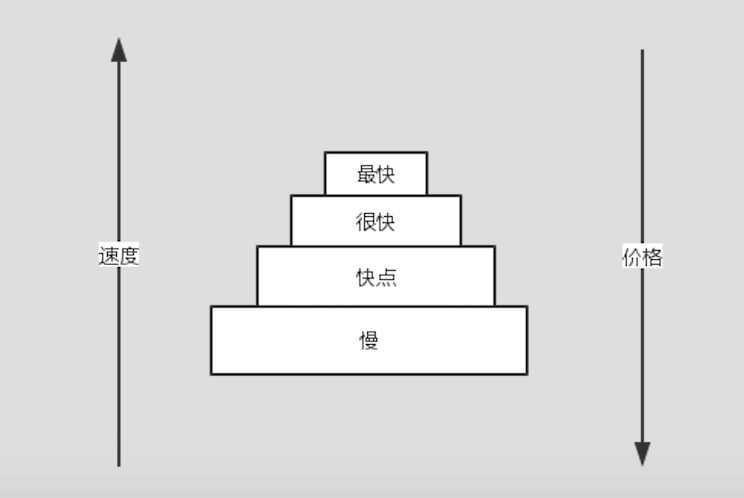
存储金字塔
如上图所示,存储体系就像个金子塔,最上层最快,价格最贵,最下层最慢,价格也最便宜,CPU的数据源优先级一层层从上到下去寻找数据。
很显然,除了最慢的那块存储,在计算机体系中,相对较快的那些存储都可以被称为缓存,他们解决的问题是让存储访问更快。
缓存应用系统
计算机体系存储系统模型扩展到应用也是一样,应用需要数据,数据哪里来?缓存(更快的存储)->DB(较慢的存储),他们的工作流程大致如下图所示:
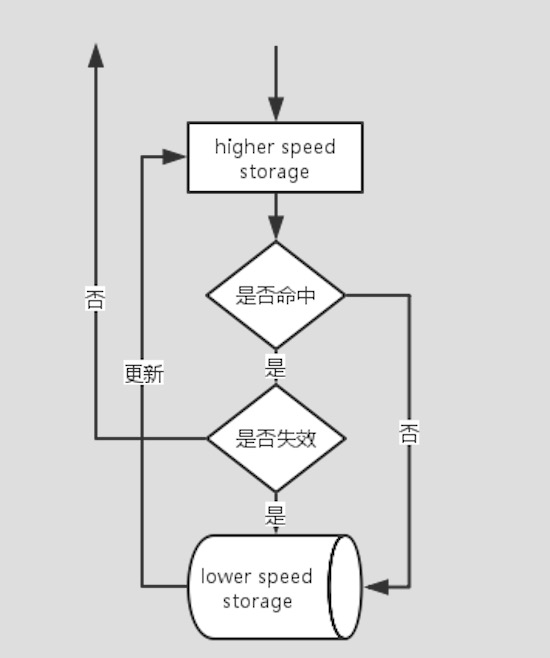
带缓存的存储访问一般模型
如上图所示,缓存应用系统一般存储访问流程:首先访问缓存较快的存储介质,如果命中且未失效则返回内容,如果未命中或失效则访问较慢的存储介质将内容返回同时更新缓存。
memcached
什么是memcached
memcached是LiveJournal旗下的Danga Interactive公司的Brad Fitzpatric为首开发的一款软件。现在已经成为mixi、hatena、Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。传统的Web应用都将数据保存到RDBMS中,应用服务器从RDBMS中读取数据、处理数据并在浏览器中显示。但是随着数据量增大、访问的集中、就会出现RDBMS的负担加重、数据库响应变慢、导致整个系统响应延迟增加。
而memcached就是为了解决这个问题而出现的,memcached是一款高性能的分布式内存缓存服务器,一般目的是为了通过缓存数据库的查询命中减少数据库压力、提高应用响应速度、提高可扩展性。
memcached缓存特点
1.协议简单
2.基于libevent的事件处理
3.内置内存存储方式
4.memcached不相互通信的分布式
memcached分布式原理
今天的内容主要涉及memcached特点的第四条,memcached不相互通信,那么memcached是如何实现分布式的呢?memcached的分布式实现主要依赖客户端的实现:
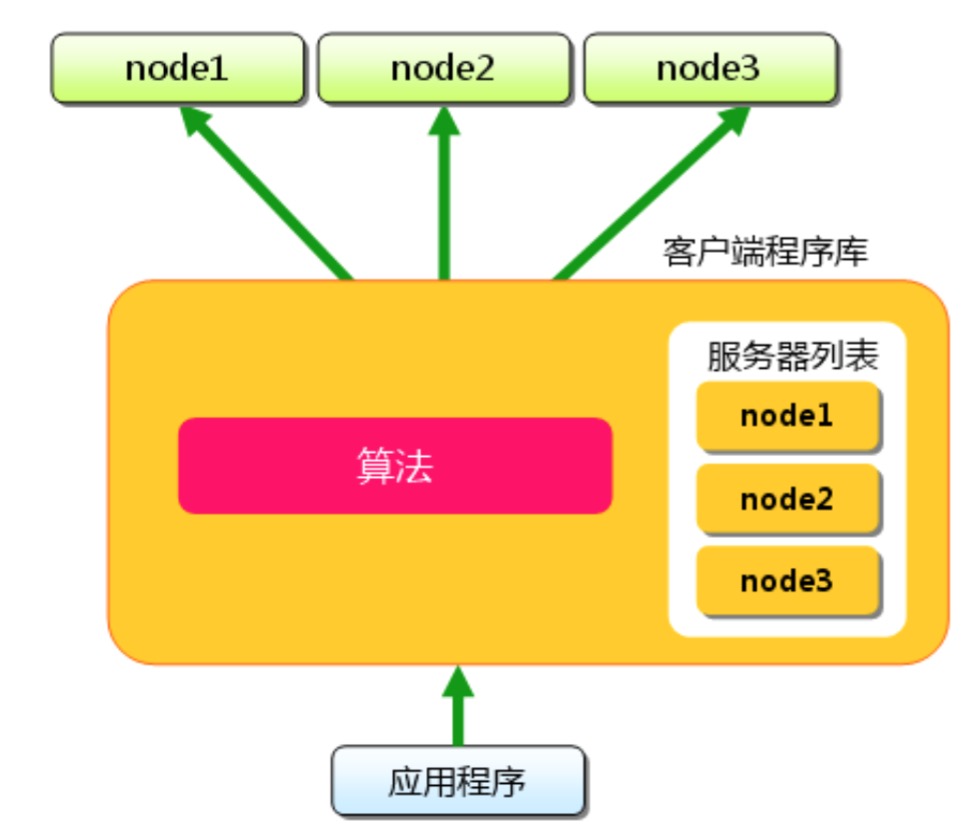
memcached分布式
如上图所示,我们看下缓存的存储的一般流程:
当数据到达客户端,客户端实现的算法就会根据“键”来决定保存的memcached服务器,服务器选定后,命令他保存数据。取的时候也一样,客户端根据“键”选择服务器,使用保存时候的相同算法就能保证选中和存的时候相同的服务器。
余数计算分散法
余数计算分散法是memcached标准的memcached分布式方法,算法如下:
CRC($key)%N
该算法下,客户端首先根据key来计算CRC,然后结果对服务器数进行取模得到memcached服务器节点,对于这种方式有两个问题值得说明一下:
1.当选择到的服务器无法连接的时候,一种解决办法是将尝试的连接次数加到key后面,然后重新进行hash,这种做法也叫rehash。
2.第二个问题也是这种方法的致命的缺点,尽管余数计算分散发相当简单,数据分散也很优秀,当添加或者移除服务器的时候,缓存重组的代价相当大。
Consistent Hashing算法
Consistent Hashing算法描述如下:首先求出memcached服务器节点的哈希值,并将其分配到0~2^32的圆上,这个圆我们可以把它叫做值域,然后用同样的方法求出存储数据键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上,如果超过0~2^32仍找不到,就会保存在第一台memcached服务器上:
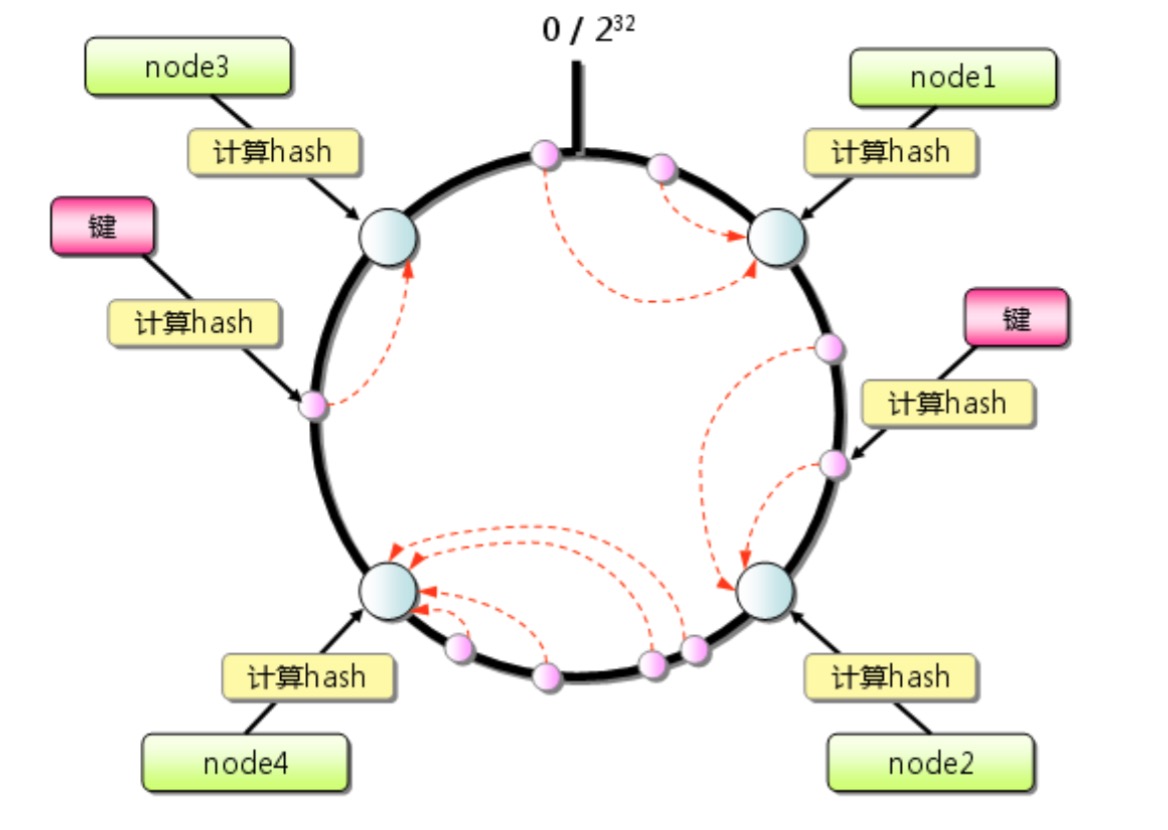
memcachd基本原理
再抛出上面的问题,如果新添加或移除一台机器,在consistent Hashing算法下会有什么影响。上图中假设有四个节点,我们再添加一个节点叫node5:
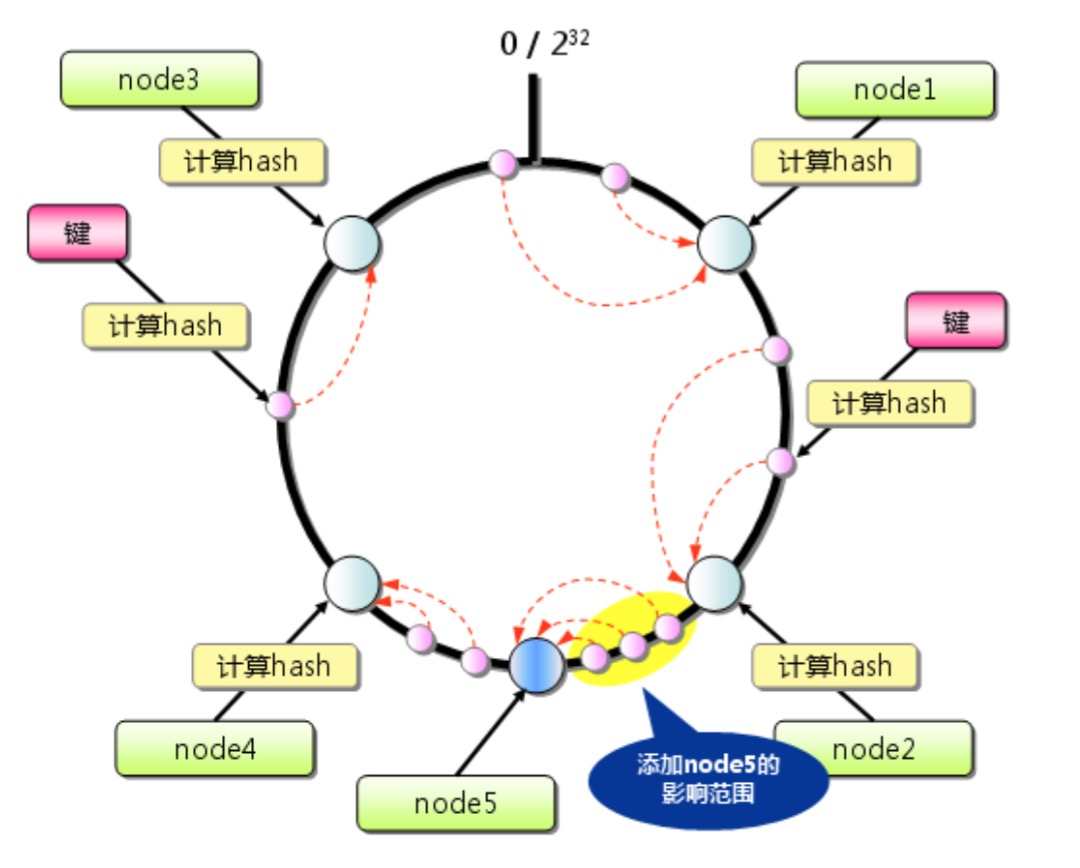
添加了node节点之后
node5被放在了node4与node2之间,本来映射到node2和node4之间的区域都会找到node4,当有node5的时候,node5和node4之间的还是找到node4,而node5和node2之间的此时会找到node5,因此当添加一台服务器的时候受影响的仅仅是node5和node2区间。
优化的Consistent Hashing算法
上面可以看出使用consistent Hashing最大限度的抑制了键的重新分配,且有的consistent Hashing的实现方式还采用了虚拟节点的思想。问题起源于使用一般hash函数的话,服务器的映射地点的分布非常不均匀,从而导致数据库访问倾斜,大量的key被映射到同一台服务器上。为了避免这个问题,引入了虚拟节点的机制,为每台服务器计算出多个hash值,每个值对应环上的一个节点位置,这种节点叫虚拟节点。而key的映射方式不变,就是多了层从虚拟节点再映射到物理机的过程。这种优化下尽管物理机很少的情况下,只要虚拟节点足够多,也能够使用得key分布的相对均匀。
memcached安装和使用
一、准备工作
下载memcached的windows版
再下载一个java_memcached-release.jar
二、安装
解压memcached-1.2.5-win32-bin.zip,CMD进入其目录,然后执行如下命令:
c:>memcached.exe -d install
c:>memcached.exe -l 127.0.0.1 -m 32 -d start第一行是安装memcached成为服务,这样才能正常运行,否则运行失败!
第二行是启动memcached的,这里简单的只分配32M内存了(默认64M),然后监听本机端口和以守护进行运行。
执行完毕后,我们就可以在任务管理器中看到memcached.exe这个进程了。
如果想要在同一台Windows机器中安装2个Memcached,请看这里
三、使用
现在服务器已经正常运行了,下面我们就来写java的客户端连接程序。
将java_memcached-release.zip解压,把java_memcached-release.jar文件复制到java项目的lib目录下,
然后我们来编写代码,比如我提供的一个应用类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
|
写个Main方法测试下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
执行结果如下:
1 2 3 4 5 6 7 |
|
说明:
1.第二次add失败是因为"hello"这个key已经存在了。
2.调用set成功,是因为set的时候覆盖了已存在的键值对,这正是add和set的不同之处
3.设置过期之间之后,cache按时自动失效
上面的例子是对于基本数据类型,对于普通的POJO而言,如果要进行存储的话,那么比如让其实现java.io.Serializable接口。
因为memcached是一个分布式的缓存服务器,多台服务器间进行数据共享需要将对象序列化的,所以必须实现该接口,否则会报错的(java.io.NotSerializableException)。
下面来试试POJO的存储:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
简单的POJO对象
Main方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
上面的代码中,我们通过p2.setName("Rose")修改了对象的名字,
最后一行打印的会是什么呢?
name=Jack
name=JackWhy?
这是因为我们修改的对象并不是缓存中的对象,而是通过序列化过来的一个实例对象
那么要修改怎么办?使用replace,注释掉的那一行把注释去掉就可以了。
四、其他
Memcached的命令参数说明
-p <num> 监听的端口
-l <ip_addr> 连接的IP地址, 默认是本机
-d start 启动memcached服务
-d restart 重起memcached服务
-d stop|shutdown 关闭正在运行的memcached服务
-d install 安装memcached服务
-d uninstall 卸载memcached服务
-u <username> 以<username>的身份运行 (仅在以root运行的时候有效)
-m <num> 最大内存使用,单位MB。默认64MB
-M 内存耗尽时返回错误,而不是删除项
-c <num> 最大同时连接数,默认是1024
-f <factor> 块大小增长因子,默认是1.25
-n <bytes> 最小分配空间,key+value+flags默认是48
-h 显示帮助
Memcached也可以在控制台中添加键值对,首先使用命令“telnet 127.0.0.1 11211”进入到Memcached控制台,
然后使用set、add、replace、get、delete来操作。
更详细操作可参照这里
五、Memcached的优势和不足
说到Memcached的优势,那当然是:速度快,操作简便,易扩展
不足的话,主要有2点:
1.数据的临时性(数据仅保存在内存中)
2.只能通过指定键来读取数据,不支持模糊查询
六、Memcached停止时的保障措施
如果数据库的访问量比较大,就需要提前做好准备,以便应对在memcached停止时发生的负载问题。
如果能在停止memcached之前,把数据复制到其他的server就好了。恩,这个可以通过repcached来实现。
repcached是日本人开发的实现memcached复制功能,
它是一个单master、单slave的方案,但它的master/slave都是可读写的,而且可以相互同步
如果master坏掉,slave侦测到连接断了,它会自动listen而成为master
