
阅读量:2
一、目标检测与目标追踪
1. 目标检测
在目标检测任务中,主要目标是识别图像或视频帧中存在的物体的位置和类别信息。这意味着目标检测算法需要定位物体的边界框(Bounding Box)并确定每个边界框内的物体属于哪个类别(如人、汽车、狗等)。目标检测通常独立地处理每一帧图像,不考虑目标在不同帧之间的连续性。它通常用于静态图像的物体识别,也可以用于处理视频流中的每一帧以实现实时检测。
主流的目标检测算法:
YOLO(You Only Look Once):YOLO是一种非常流行的目标检测算法,它具有快速的实时检测能力。YOLO将图像分成网格,并在每个网格上进行预测,以同时获得多个边界框和它们的类别概率。YOLO的特点是快速、准确,适用于实时应用。
Faster R-CNN:Faster R-CNN采用了两阶段检测方法,其中第一阶段生成候选边界框,第二阶段对候选边界框进行分类和回归以获得最终检测结果。它的准确性较高,但速度相对较慢。
SSD(Single Shot MultiBox Detector):SSD是一种单阶段检测算法,它在每个位置上使用多个不同尺度的卷积层来预测边界框和类别。它具有良好的平衡性能,既准确又相对快速。
RetinaNet:RetinaNet结合了两阶段和单阶段方法的优点,使用了特殊的损失函数来解决类别不平衡问题,从而实现高效且准确的目标检测。
Mask R-CNN:Mask R-CNN是Faster R-CNN的扩展版本,它不仅可以检测目标的边界框,还可以生成目标的精确掩模,用于实现实例分割任务,即将不同实例的像素分离开来。
EfficientDet:EfficientDet是一种高效的目标检测算法,它基于EfficientNet的架构,并在目标检测中取得了很好的性能。它通过改进网络结构和训练策略来实现高效的目标检测。
目标检测示例:
目标检测
2. 目标追踪
与目标检测不同,目标跟踪的任务是在视频序列中跟踪特定物体的运动,即在不同的帧之间识别和跟踪同一物体。目标跟踪需要处理物体在时间上的连续性,通常涉及到将不同帧中的物体关联起来,以确保它们被正确标识为同一个物体。目标跟踪算法通常会分配唯一的ID给每个被跟踪的物体,以区分它们,并跟踪它们的位置随时间的变化。目标跟踪广泛用于视频监控、自动驾驶、人机互动等领域。
主流目标追踪算法:
Kalman滤波器:Kalman滤波器是一个常用于目标追踪的线性动态系统估计方法。它可以预测目标的位置和速度,然后通过观测来不断更新估计。
Particle Filter:粒子滤波器是一种用于非线性和非高斯问题的目标追踪方法。它通过随机粒子的采样来估计目标的状态。
Mean-Shift:均值漂移算法是一种非参数化方法,它通过寻找目标在颜色空间中的密度峰值来进行目标追踪。
KLT跟踪器:KLT(Kanade-Lucas-Tomasi)跟踪器是一种用于光流估计和目标追踪的方法,它可以用于跟踪特征点或区域。
MIL(多实例学习):MIL是一种多目标追踪方法,它在每帧中检测多个候选目标并使用学习算法确定目标的状态。
DeepSORT:DeepSORT是一种结合了深度学习和目标追踪的方法,它使用深度学习模型来提取目标特征,并使用关联算法来跟踪目标在视频中的位置。
SORT:SORT(Simple Online and Realtime Tracking)是一种实时目标追踪方法,它通过匹配边界框和跟踪目标来实现目标追踪。
目标追踪示例:
目标追踪
从上面的视频示例中可以看到,检测到的每个目标都有一个指定的唯一的ID,当目标追踪出现遮挡或者丢失的之后,再次检测,还能匹配到原本的ID。
二. DeepSORT目标追踪
1.算法简介
目前,主流的目标跟踪算法大多采用"Tracking-by-Detection"策略,即依赖目标检测的结果来进行目标跟踪。DeepSORT是一个代表性的算法,它也采用了这一策略。DeepSORT对目标进行跟踪,每个边界框(bbox)的左上角数字用于标识唯一的目标ID。
DeepSORT的前身是SORT(Simple Online and Realtime Tracking)算法,SORT是一种目标跟踪器,由目标检测器和跟踪器组成。在SORT中,跟踪器的核心是卡尔曼滤波算法和匈牙利算法。它利用卡尔曼滤波来预测目标在下一帧的状态,然后使用匈牙利算法将这一状态与下一帧的检测结果进行匹配,以实现目标跟踪。如果目标在下一帧未被检测到,例如因受到遮挡或其他原因,卡尔曼滤波预测的状态信息将无法与检测结果匹配,导致跟踪片段提前结束。
- 匈牙利算法可以确定当前帧的某个目标,是否与前一帧的某个目标相同。
- 卡尔曼滤波可以基于目标前一时刻的位置,来预测当前时刻的位置,并且可以比传感器(在目标跟踪中即目标检测器,比如Yolo等)更准确的估计目标的位置。

2.追踪流程
DeepSORT引入了深度学习中的重识别算法,以提取被检测物体的外观特征(低维向量表示)。在每一次检测和追踪后,它会执行外观特征提取,并将这些特征保存起来。随后的每一步,它都会计算当前帧中被检测物体的外观特征与先前存储的特征之间的相似度,这有助于避免漏检和身份丢失的情况。因此,DeepSORT不仅仅依赖于物体的速度和方向趋势来进行目标跟踪,还利用物体的外观特征来加强对是否为同一物体的判断。
这个过程有点像在每一帧中为每个被检测的物体创建一个独特的ID,并在后续帧中使用这些ID来识别和跟踪物体。这种方法提高了目标追踪的鲁棒性,因为即使目标在某些帧中被遮挡或重新出现,根据外观特征的相似性,DeepSORT仍能够正确地将其与之前的跟踪关联起来,从而保持目标的身份标识。
DeepSORT跟踪算法归纳为以下几个步骤: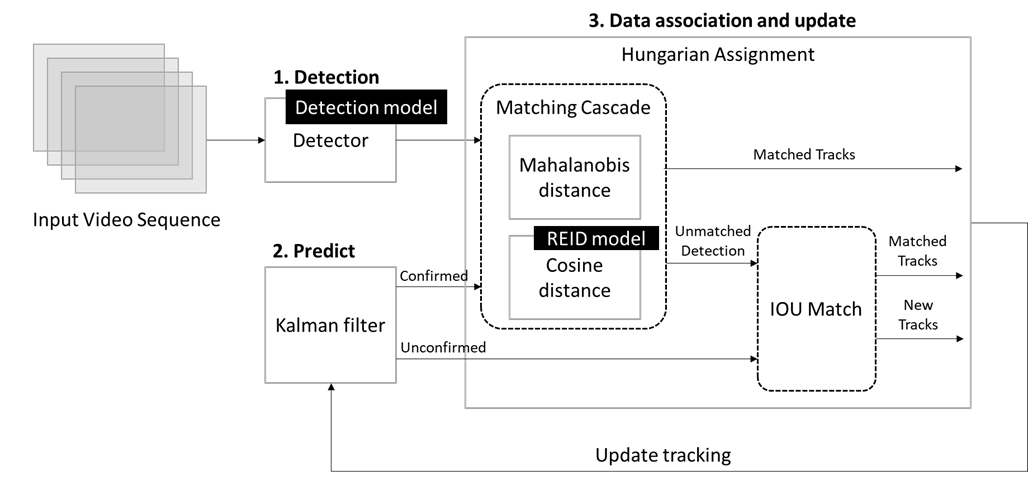
3.算法实现
当使用DeepSORT进行目标跟踪时,正常分两个步骤:
3.1 目标检测
首先,使用常规的目标检测模型(比如YOLO)对单帧图像进行分析,检测到感觉兴趣的目标的坐标位置 ,如果上面的示例视频,首先要使用目标检测算法对图像的中的行人做检测。
3.2目标预测
在这一步中,使用卡尔曼滤波算法。它基于当前的一系列运动变量来预测下一时刻的运动变量。首次检测结果用于初始化卡尔曼滤波的运动变量。预测结果被分为两种状态:确认态(confirmed)和不确认态(unconfirmed)。新生成的跟踪对象处于不确认态,只有在与检测结果连续匹配一定次数后才能转化为确认态。而处于确认态的跟踪对象需要与检测结果连续匹配一定次数才会被删除。
接下来,需要将检测到的物体与预测的物体进行关联。DeepSORT使用匈牙利算法,并根据不同的代价函数来找到最佳匹配。如果卡尔曼滤波输出了确认态的预测结果,DeepSORT将使用马氏距离和余弦距离的级联方法来关联相关信息。马氏距离提供了不同状态下物体之间的距离信息。如果某次关联的马氏距离低于指定的阈值,那么运动状态的关联成功。但DeepSORT不仅考虑帧与帧之间框的距离,还考虑框内的外观特征以更好地进行关联匹配。因此,DeepSORT引入了外观特征余弦距离度量,通过一个重识别模型获取不同物体的特征向量,然后构建余弦距离代价函数,计算预测对象与检测对象的相似度。当两个预测框的马氏距离和外观特征余弦距离都小于一定阈值时,它们被认为是同一个物体。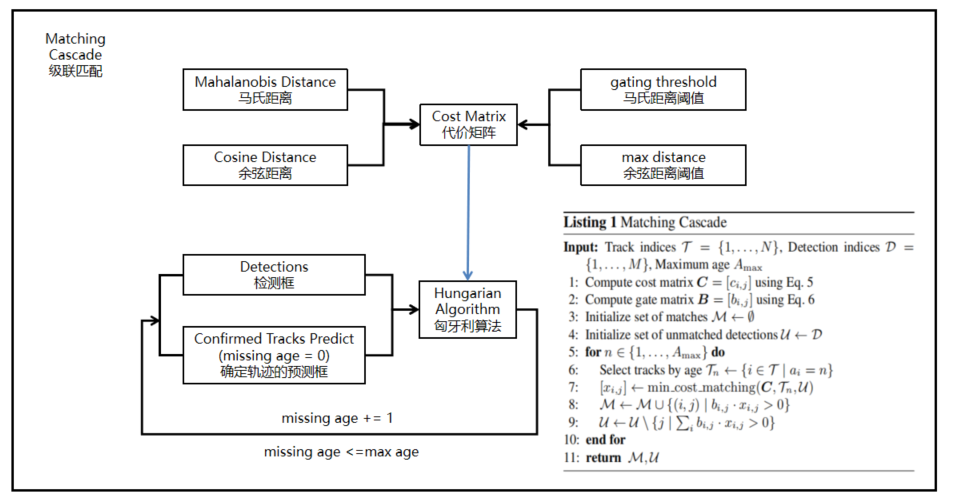
DeepSORT之所以引入这种级联方法,是因为在物体运动状态变化较剧烈的情况下,基于目标状态之间的关联可能不可靠。例如,当一个人在奔跑时,如果相机是静止的或与人的运动方向相反,相机中的人在每帧之间的运动状态会有很大的差异。这种情况下,运动的不确定性增加,先验状态与目标检测之间的匹配差异较大。为了弥补这一缺陷,DeepSORT采用特征相似距离关联。然而,在目标的运动状态变化不剧烈的情况下,马氏距离成为更好的数据关联度量选择。
在数据关联的第二步,DeepSORT计算了不确认态下的预测框和未被上一步级联方法匹配的检测框之间的IOU交并比。然后,使用匈牙利算法来找到最佳匹配的IOU结果。如果预测框和检测框的IOU低于阈值,它们的关联将被删除。
最后,利用当前帧的关联结果来更新所有分配了ID的跟踪对象的状态。这有助于保持跟踪对象的准确性和一致性。
三、源码解析
DeepSORT在每一帧的处理流程如下:
1.检测
在每一帧中,目标检测器识别并提取出边界框(bbox),这些边界框表示在当前帧中检测到的目标物体。
def detect(self,cv_src): boxes, scores, class_ids = self.detector(cv_src) pred_boxes = [] for i in range(len(boxes)): x1,y1 = int(boxes[i][0]),int(boxes[i][1]) x2,y2 = int(boxes[i][2]),int(boxes[i][3]) lbl = class_names[class_ids[i]] # print(class_ids[i]) # if lbl in ['person','sack','elec','bag','box','caron']: # continue pred_boxes.append((x1,y1,x2,y2,lbl,class_ids[i])) return cv_src,pred_boxes 2. 生成detections
从这些检测到的边界框中,生成称为"detections"的目标检测结果。每个detection通常包含有关目标的信息,如边界框坐标和可信度分数。
# deep_sort.py def update(self, bbox_xywh, confidences, ori_img): self.height, self.width = ori_img.shape[:2] # 提取每个bbox的feature features = self._get_features(bbox_xywh, ori_img) # [cx,cy,w,h] -> [x1,y1,w,h] bbox_tlwh = self._xywh_to_tlwh(bbox_xywh) # 过滤掉置信度小于self.min_confidence的bbox,生成detections detections = [Detection(bbox_tlwh[i], conf, features[i]) for i,conf in enumerate(confidences) if conf > self.min_confidence] # NMS (这里self.nms_max_overlap的值为1,即保留了所有的detections) boxes = np.array([d.tlwh for d in detections]) scores = np.array([d.confidence for d in detections]) indices = non_max_suppression(boxes, self.nms_max_overlap, scores) detections = [detections[i] for i in indices] ... 3. 卡尔曼滤波预测
对于已知的跟踪对象(“tracks”),在下一帧中进行卡尔曼滤波预测,以估计其新的位置和速度。
# track.py def predict(self, kf): """Propagate the state distribution to the current time step using a Kalman filter prediction step. Parameters ---------- kf: The Kalman filter. """ self.mean, self.covariance = kf.predict(self.mean, self.covariance) # 预测 self.age += 1 # 该track自出现以来的总帧数加1 self.time_since_update += 1 # 该track自最近一次更新以来的总帧数加1 4.使用匈牙利算法将预测后的tracks和当前帧中的detections进行匹配
这是DeepSORT中的核心步骤。DeepSORT使用匈牙利算法来将预测的tracks和当前帧的detections进行匹配。这个匹配可以采用两种级联方法:首先,通过计算马氏距离来估算预测对象与检测对象之间的关联,如果马氏距离小于指定的阈值,则将它们匹配为同一目标。其次,DeepSORT还使用外观特征余弦距离度量,通过一个重识别模型获得不同物体的特征向量,然后构建余弦距离代价函数,以计算预测对象与检测对象的相似度。这两个代价函数的结果都趋向于小,如果边界框接近且特征相似,则将它们匹配为同一目标。
# tracker.py def _match(self, detections): def gated_metric(racks, dets, track_indices, detection_indices): """ 基于外观信息和马氏距离,计算卡尔曼滤波预测的tracks和当前时刻检测到的detections的代价矩阵 """ features = np.array([dets[i].feature for i in detection_indices]) targets = np.array([tracks[i].track_id for i in track_indices] # 基于外观信息,计算tracks和detections的余弦距离代价矩阵 cost_matrix = self.metric.distance(features, targets) # 基于马氏距离,过滤掉代价矩阵中一些不合适的项 (将其设置为一个较大的值) cost_matrix = linear_assignment.gate_cost_matrix(self.kf, cost_matrix, tracks, dets, track_indices, detection_indices) return cost_matrix # 区分开confirmed tracks和unconfirmed tracks confirmed_tracks = [i for i, t in enumerate(self.tracks) if t.is_confirmed()] unconfirmed_tracks = [i for i, t in enumerate(self.tracks) if not t.is_confirmed()] # 对confirmd tracks进行级联匹配 matches_a, unmatched_tracks_a, unmatched_detections = \ linear_assignment.matching_cascade( gated_metric, self.metric.matching_threshold, self.max_age, self.tracks, detections, confirmed_tracks) # 对级联匹配中未匹配的tracks和unconfirmed tracks中time_since_update为1的tracks进行IOU匹配 iou_track_candidates = unconfirmed_tracks + [k for k in unmatched_tracks_a if self.tracks[k].time_since_update == 1] unmatched_tracks_a = [k for k in unmatched_tracks_a if self.tracks[k].time_since_update != 1] matches_b, unmatched_tracks_b, unmatched_detections = \ linear_assignment.min_cost_matching( iou_matching.iou_cost, self.max_iou_distance, self.tracks, detections, iou_track_candidates, unmatched_detections) # 整合所有的匹配对和未匹配的tracks matches = matches_a + matches_b unmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b)) return matches, unmatched_tracks, unmatched_detections # 级联匹配源码 linear_assignment.py def matching_cascade(distance_metric, max_distance, cascade_depth, tracks, detections, track_indices=None, detection_indices=None): ... unmatched_detections = detection_indice matches = [] # 由小到大依次对每个level的tracks做匹配 for level in range(cascade_depth): # 如果没有detections,退出循环 if len(unmatched_detections) == 0: break # 当前level的所有tracks索引 track_indices_l = [k for k in track_indices if tracks[k].time_since_update == 1 + level] # 如果当前level没有track,继续 if len(track_indices_l) == 0: continue # 匈牙利匹配 matches_l, _, unmatched_detections = min_cost_matching(distance_metric, max_distance, tracks, detections, track_indices_l, unmatched_detections) matches += matches_l unmatched_tracks = list(set(track_indices) - set(k for k, _ in matches)) return matches, unmatched_tracks, unmatched_detections 5. 卡尔曼滤波更新
匹配后,DeepSORT使用检测到的detections来更新每个已知的跟踪对象的状态,例如位置和速度。这有助于保持跟踪对象的准确性和连续性。
def update(self, detections): """Perform measurement update and track management. Parameters ---------- detections: List[deep_sort.detection.Detection] A list of detections at the current time step. """ # 得到匹配对、未匹配的tracks、未匹配的dectections matches, unmatched_tracks, unmatched_detections = self._match(detections) # 对于每个匹配成功的track,用其对应的detection进行更新 for track_idx, detection_idx in matches: self.tracks[track_idx].update(self.kf, detections[detection_idx]) # 对于未匹配的成功的track,将其标记为丢失 for track_idx in unmatched_tracks: self.tracks[track_idx].mark_missed() # 对于未匹配成功的detection,初始化为新的track for detection_idx in unmatched_detections: self._initiate_track(detections[detection_idx]) ... 