
阅读量:3
目录
1 10大核心信息
AI在一些任务中已经打败了人类,但是并不是所有任务
在一些图像分类,视觉推理以及英语理解方面,AI已经超越了人类,但是在更复杂的任务上面,比如抽象的数学问题,视觉常识的推理以及规划上面,AI还是稍逊人类。工业界是AI研究的主导者
在2023年里,工业界产出了51个显著有影响力的机器学习模型,而学术界只贡献了15个,产学研一起研究的贡献了21个显著有影响力的模型。训练大模型变得更加昂贵
训练大模型变得成本越来越高,OpenAI训练出来GPT-4花了约7800万美金的,而google的Gimini花了约1.91亿美金。美国,中国,欧洲成为top AI模型的主要贡献者
在2023里,有61个优秀的AI模型来自美国研究,大大超过欧洲的21个,中国的15个。关于大模型在可靠性上面的评估,缺乏规范的评估准则
目前缺少规范的评估准则和数据对于AI模型可靠性的评估,导致系统的评估模型的风险变得更加复杂也受限了top AI模型的使用。生成式AI的投资飙升
生成式AI的投资资金飙升,从2022年增长了近8倍,达到了250亿美元。主要参与者包括OpenAI, Anthropic, Hugging Face等公司,在融资方面大幅增加。AI让工作者更加高效,并且能够产出更高的工作质量
在2023年的几个研究报告中,认为AI能够使得工作者更加快速的完成任务并且能够提高任务产出的质量。研究还表明,AI能够消除低能力与高能力工作者之间的技能gap。AI加速了科学以及医疗发展
2023年,更多重要的与科学相关的人工智能应用程序问世——从AlphaDev,它使算法排序更加高效,到GNoME,它促进了材料发现的过程。美国关于AI相关的条款准则急剧增加
在2023年,美国有25条关于人工智能的条款发布,而2016年只有一条。去年一年,关于AI相关的条款就增加了56.3%。来自世界各地的人越来越意识到AI的潜在影响,也带来了更多的紧张情绪
来自lpsos的调查显示,在过去的一年里,认为未来3到5年,AI会大幅度影响他们的生活的人增加了60%到66%。52%的人对AI相关的产品和服务表现出了紧张感,而这个数据在2022年只有13%。在美国,有52%的人对AI表达了更多是担忧而不是激动,这个数据在2022年只有37%。
2 AI研究和发展
2.1 核心要点
- 工业界继续主导前沿人工智能研究
- 有越来越多的基础模型发布,其中也有越来越多的模型公开源码
在2023年,有149个模型发布,其中发布的模型里面,有65.7%是公开源码的。 - 训练一个大的好的模型变得更加昂贵
- 美国,中国,欧洲国家成为AI大模型驱动的主导
- AI相关专利飞速增长,其中中国成为主导者
在2022年,中国发明的AI专利占比61.1%,其中美国占比20.9% - 在Github开源的AI研究资源暴增
自从2011年开始,在Github上关于AI的工程从845个急剧增长到180万个。 - 关于AI相关的论文发表持续增长
从2010年,发表AI相关的论文约8.8万篇,到2022年,有24万篇,近3倍的增长。
2.2 核心对比信息
2010年到2022年,AI相关的文章发表数量逐年增加,具体数据趋势如下: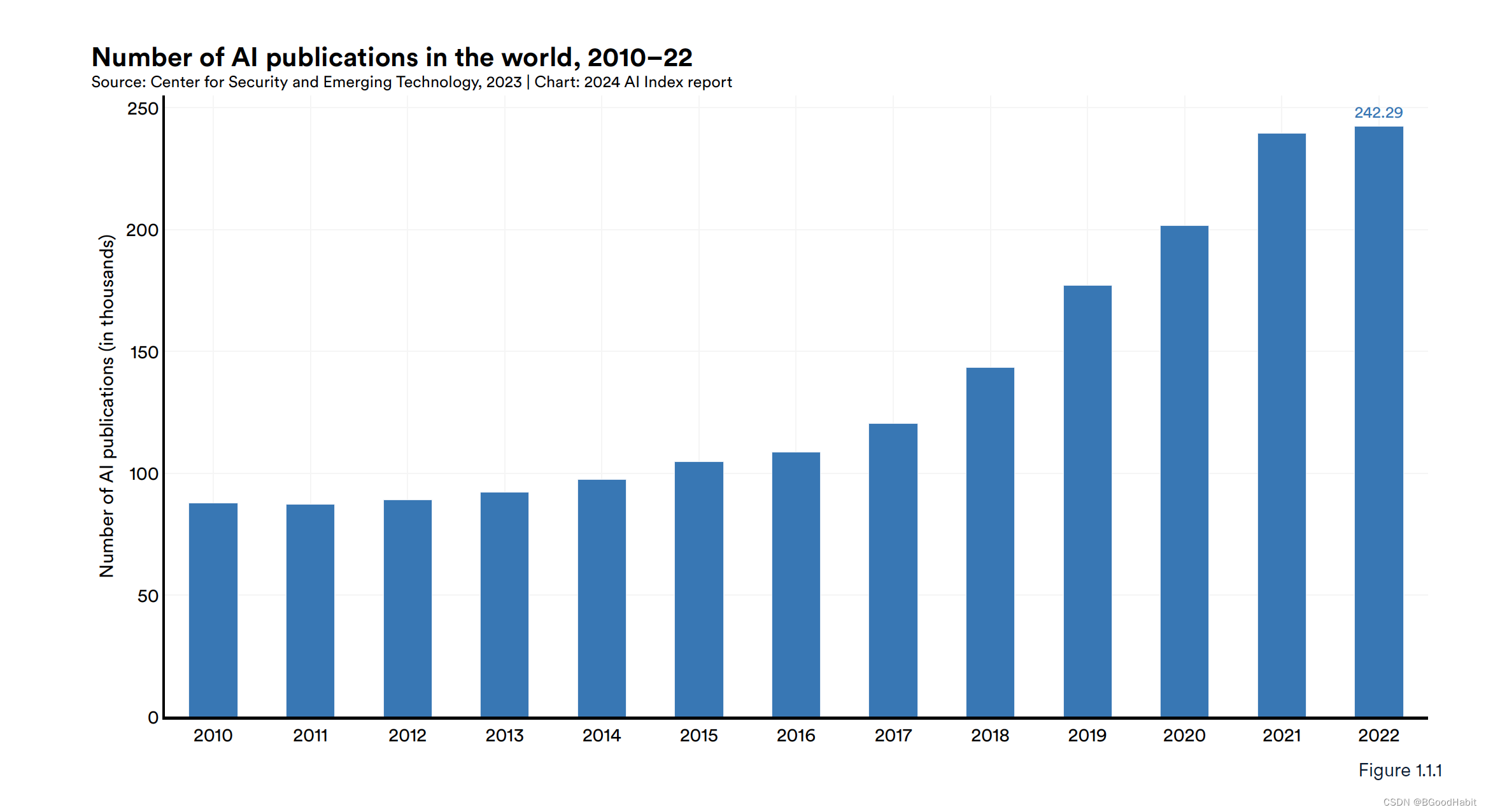
论文发表在不同平台数据对比如下: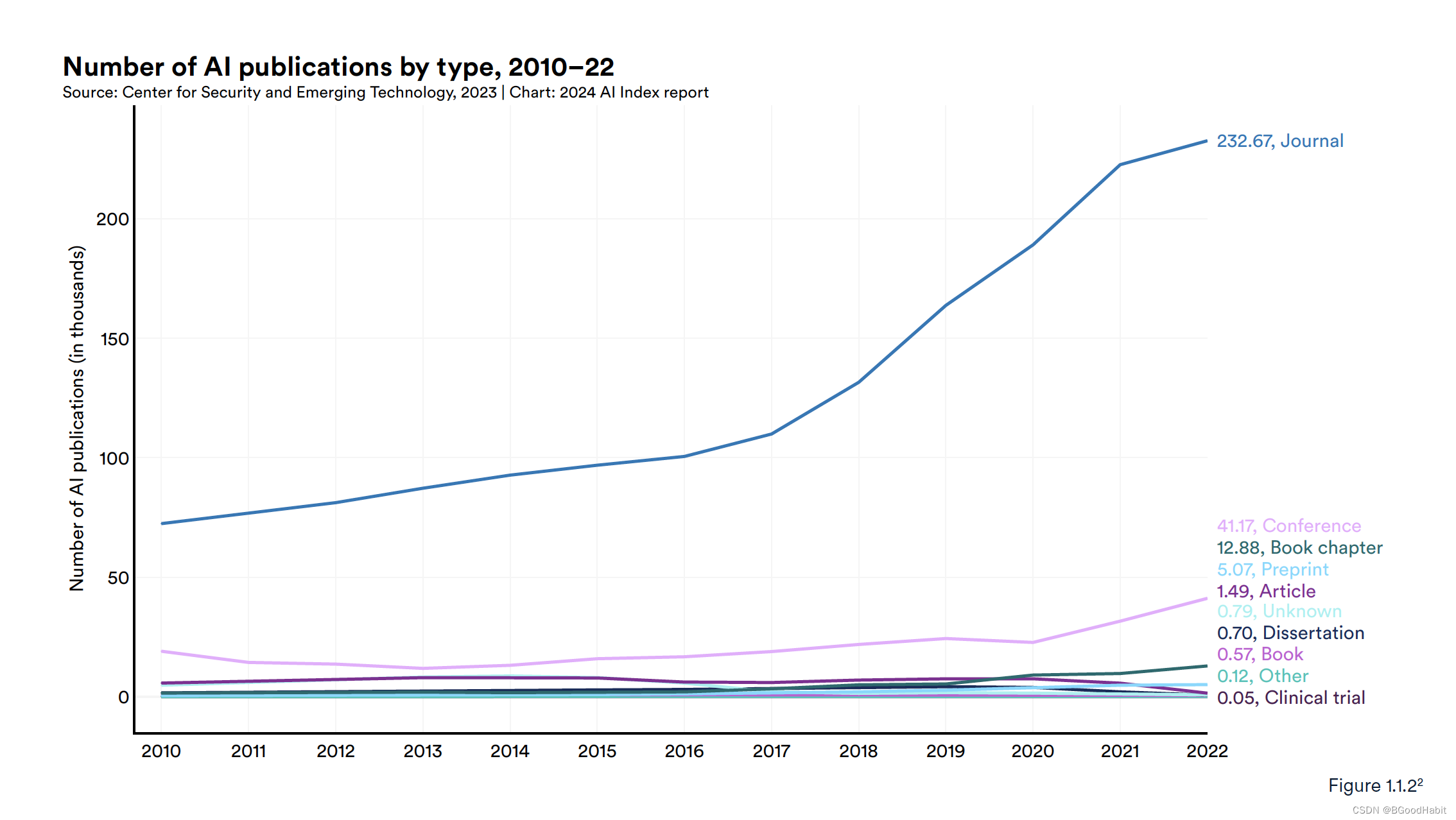
美国保持世界首位发布优秀的机器学习模型数量,对于情况如下: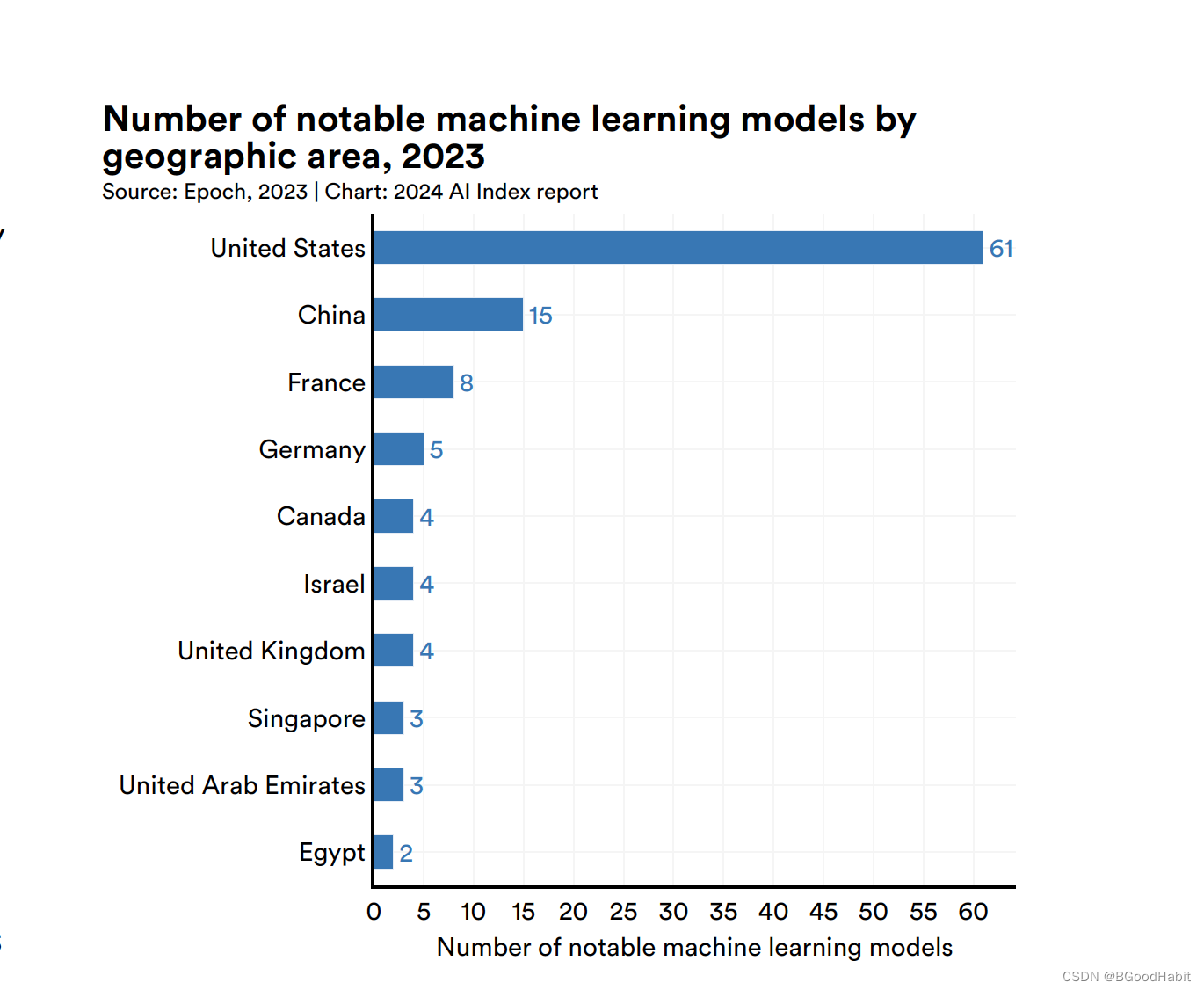
如下是有影响力的模型在参数变化情况以及不同类型机构主导分布图: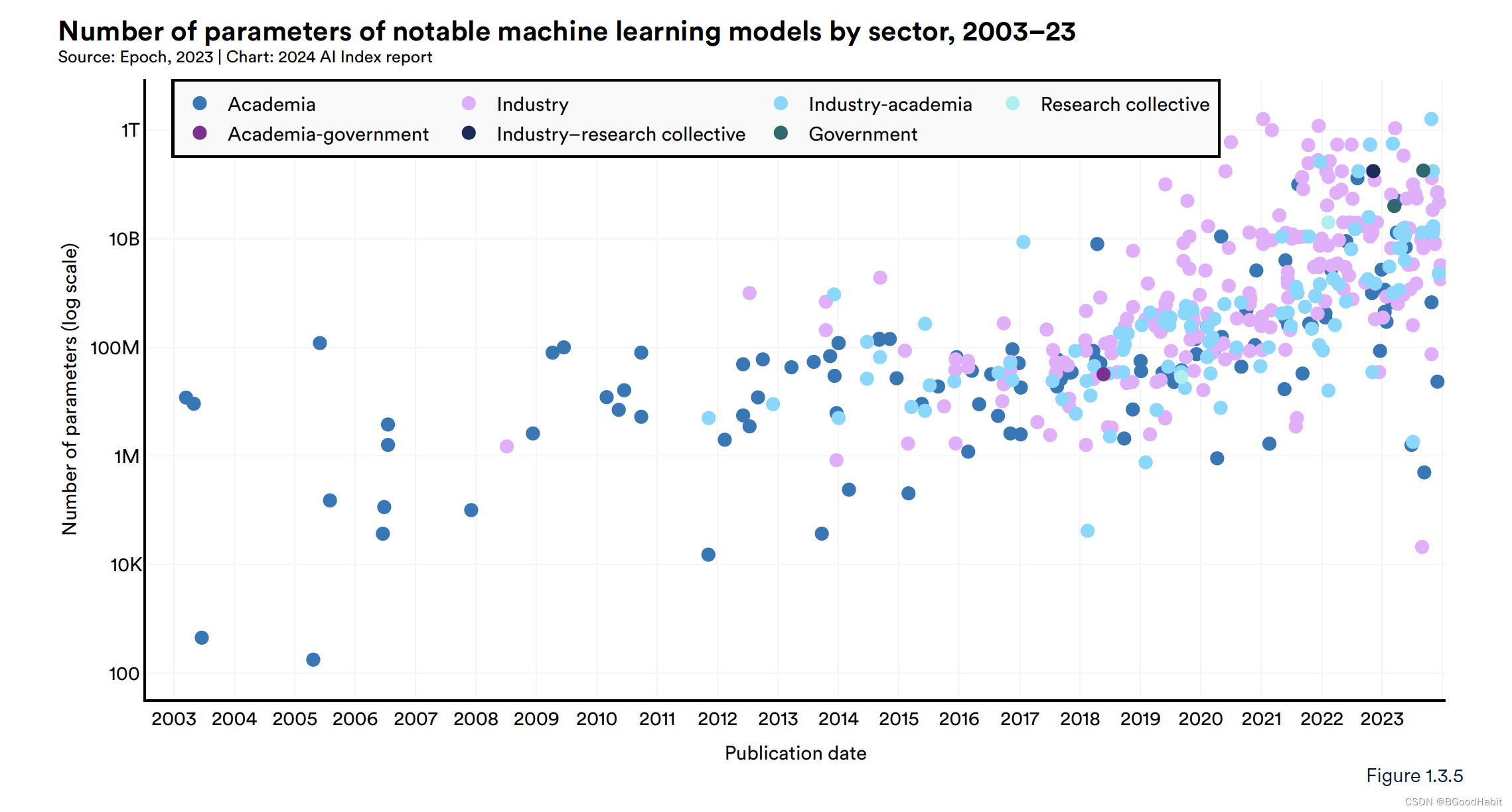
如下是发布大模型的时间抽: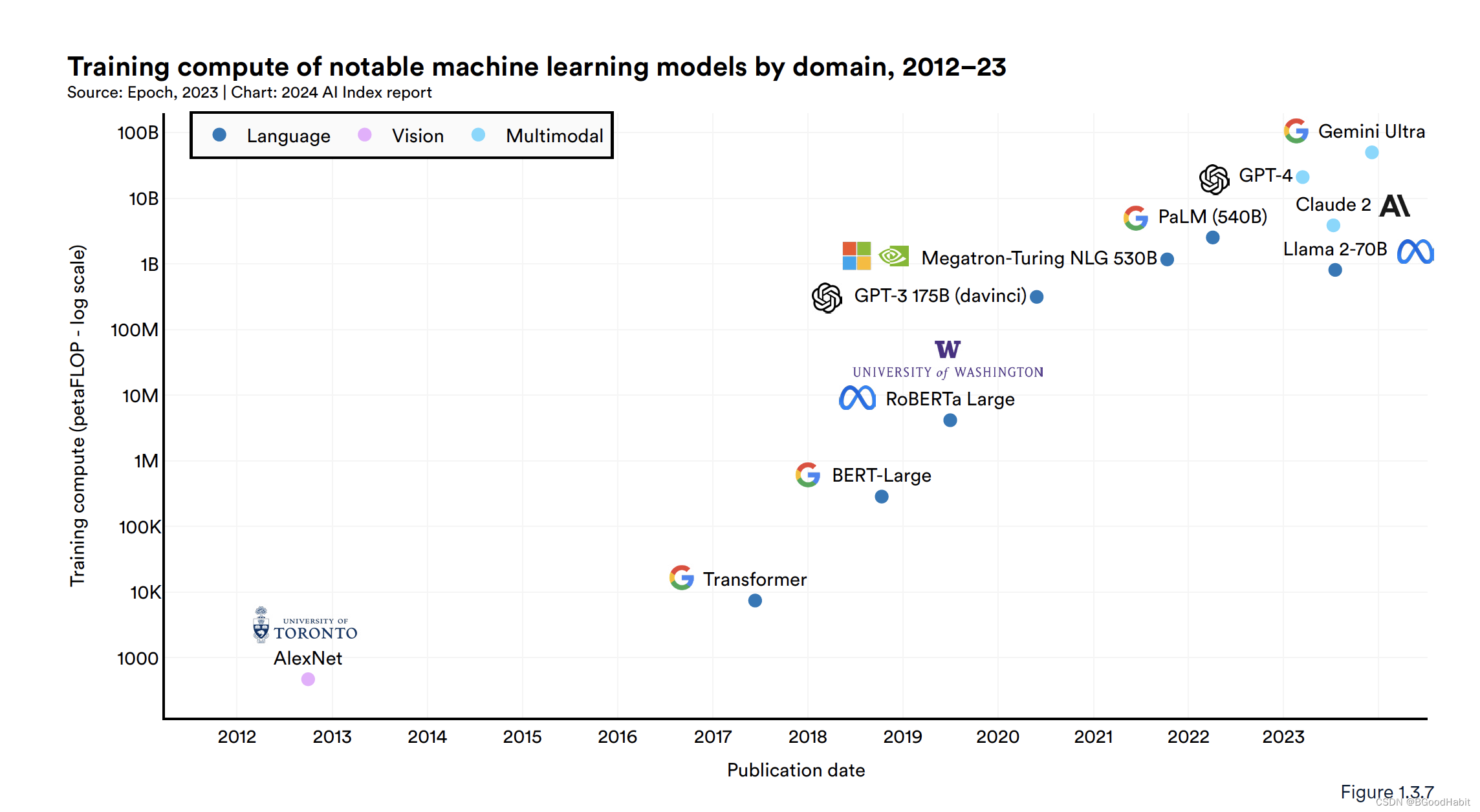
2.3 模型是否会用尽数据
我们知道最近AI的飞速发展,包括LLM的发展,其中主要一个原因在于用大量的数据进行训练。AI指数指导委员会成员Jack Clark指出,现在基础模型几乎已经用了大部分互联网上存在的数据。而AI模型主要依赖大数据,Jack Clark对未来的计算机科学家是否会用尽数据提出了质疑。研究人员估计,计算机科学家可能在2024年之前耗尽高质量语言数据的库存,在未来两十年内用尽低质量语言数据,并在2030年代末至2040年代中期之间消耗完图像数据。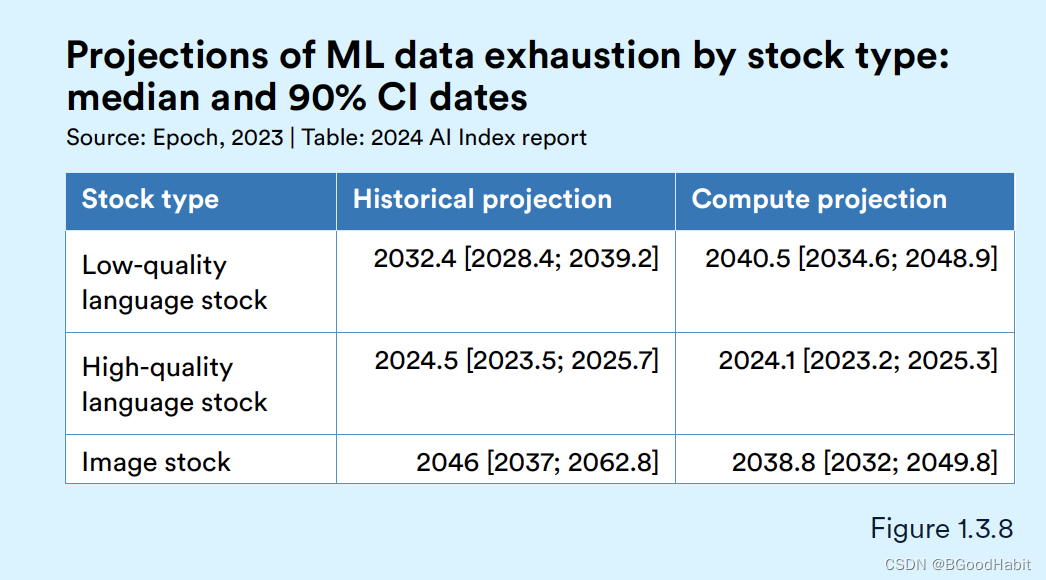
理论上,现实有限的数据可以通过合成数据缓解,比如可以通过AI模型生成新的数据,然后用新生成的数据训练其他模型。但是,一组英国和加拿大研究人员发现,用大量合成数据进行训练的模型会出现模型崩溃现象,即随着时间推移,它们失去了记住真实基础数据分布的能力,开始产生一系列狭窄的输出。如下图所示,通过加入合成的图像数据训练图像生成模型,性能下降:
2.4 基础模型发展
基础模型代表着一种快速发展和受欢迎的人工智能模型类别。它们在广泛的数据集上训练,具有多功能性,并适用于许多下游应用。像GPT-4、Claude 3和Llama 2这样的基础模型展示了出色的能力,并越来越多地被部署在实际场景中。基础模型可以有多种方式获取,比如不对外公开任何访问的模型,像Google的PaLM-E,还有一定限制的模型,比如OpenAI的GPT-4以及开源的模型,像Meta的 Llama-2, Llama-3等。下图展示了这三种类型的模型数量分布: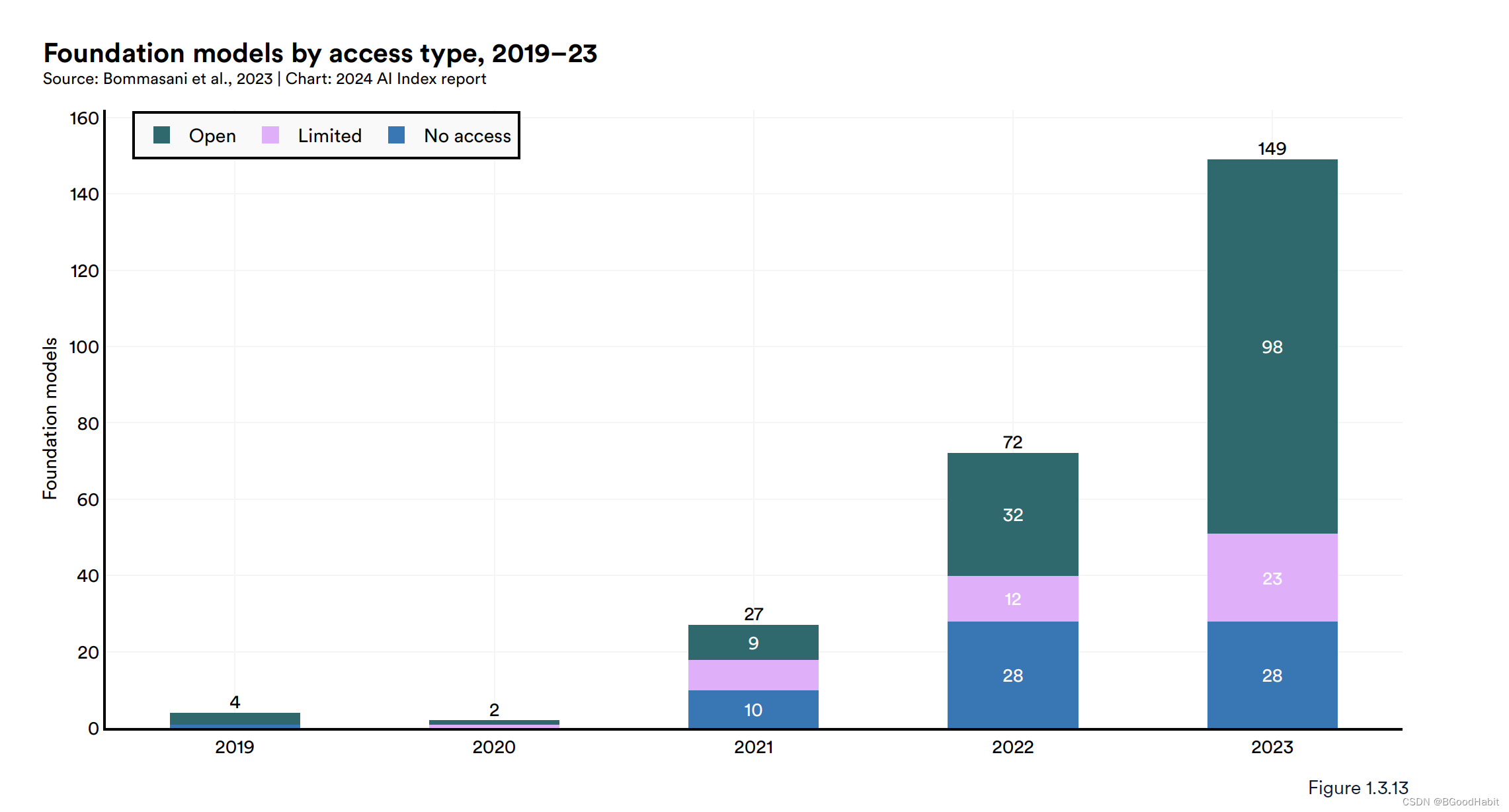
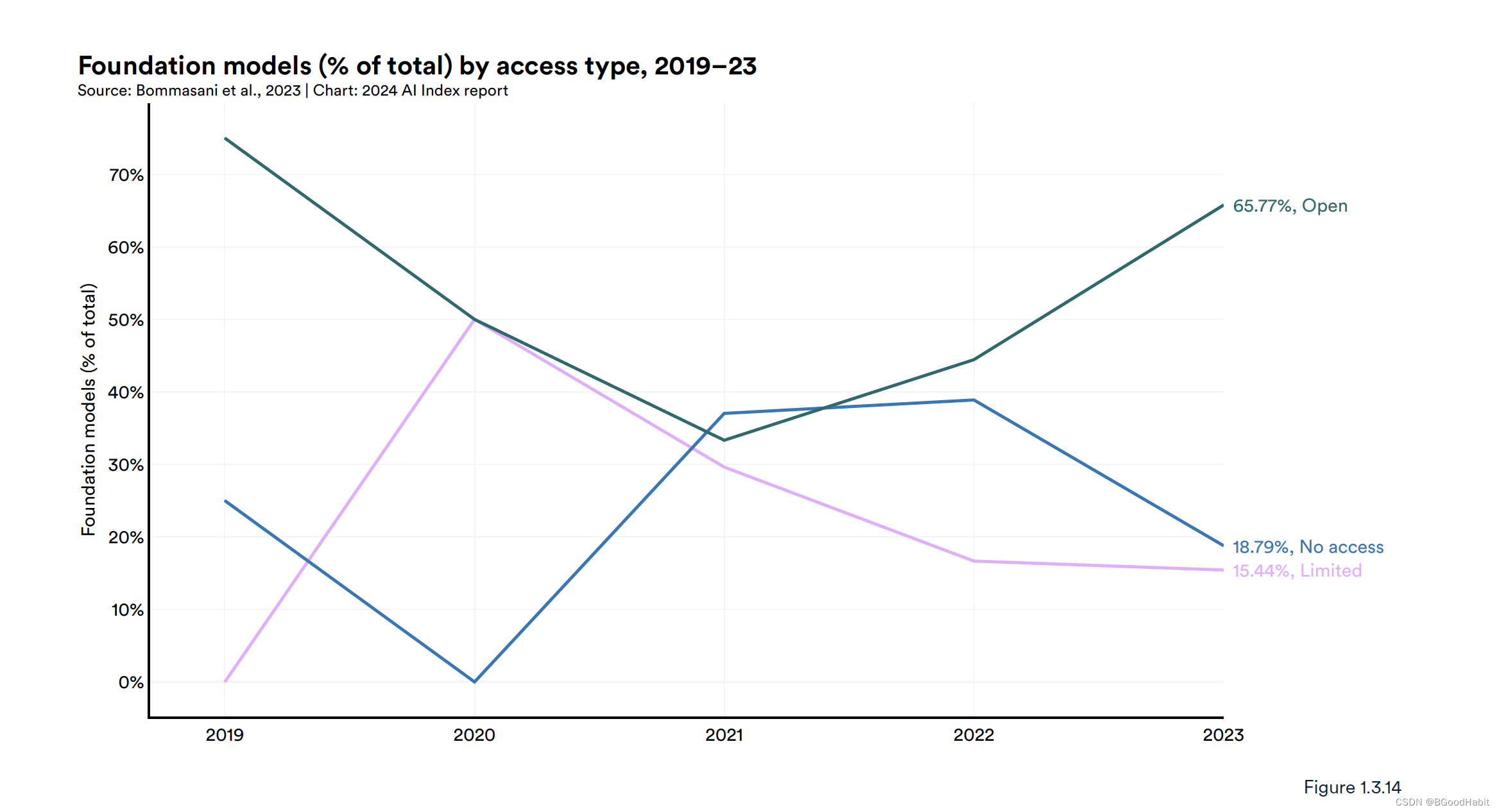
如下是基础模型数量在不同行业的分布,从中可以看出,主要以工业界为主: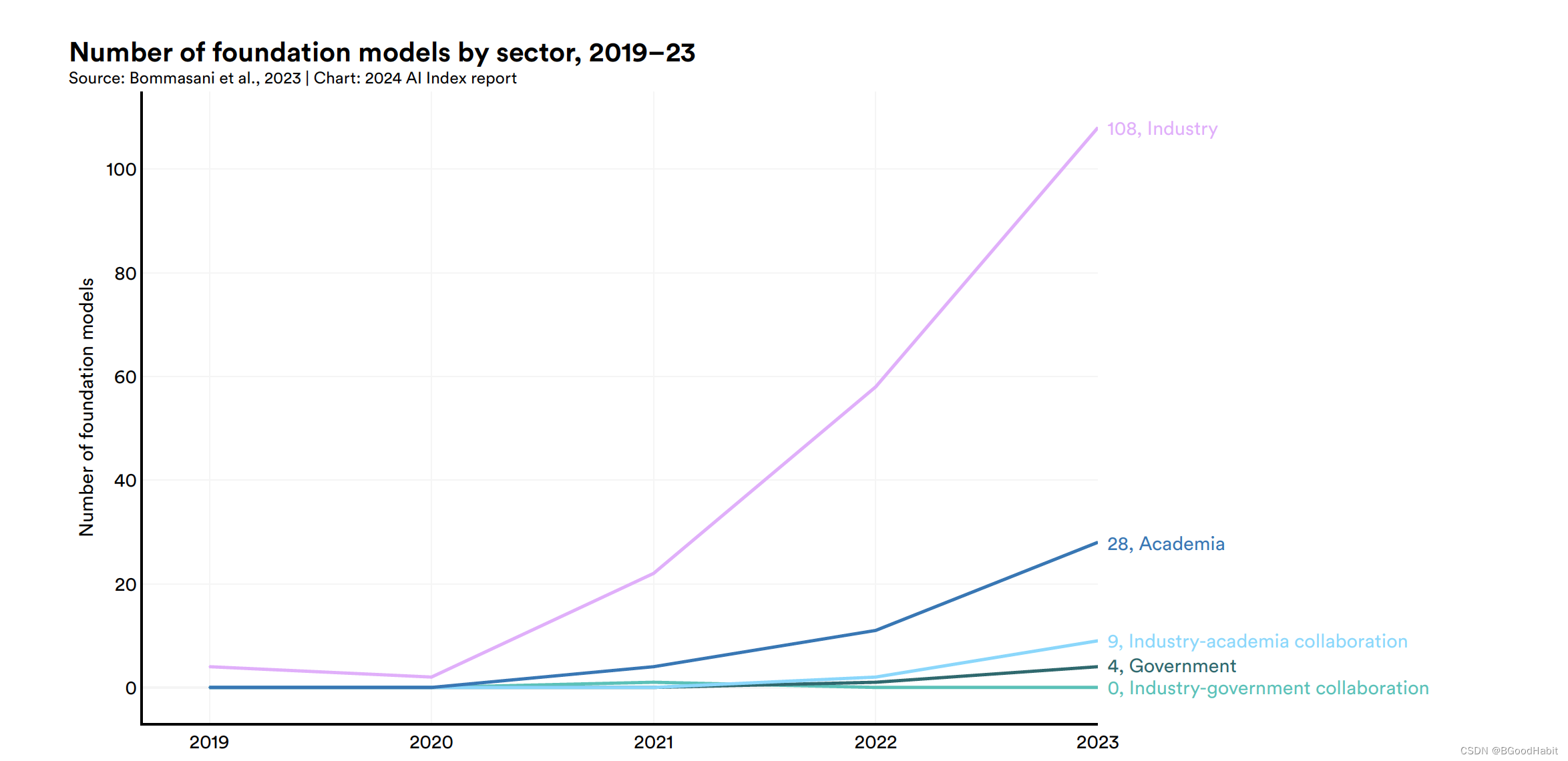
如下是在2023年不同组织对基础模型的发布数量情况,其中Google发布的数量最多: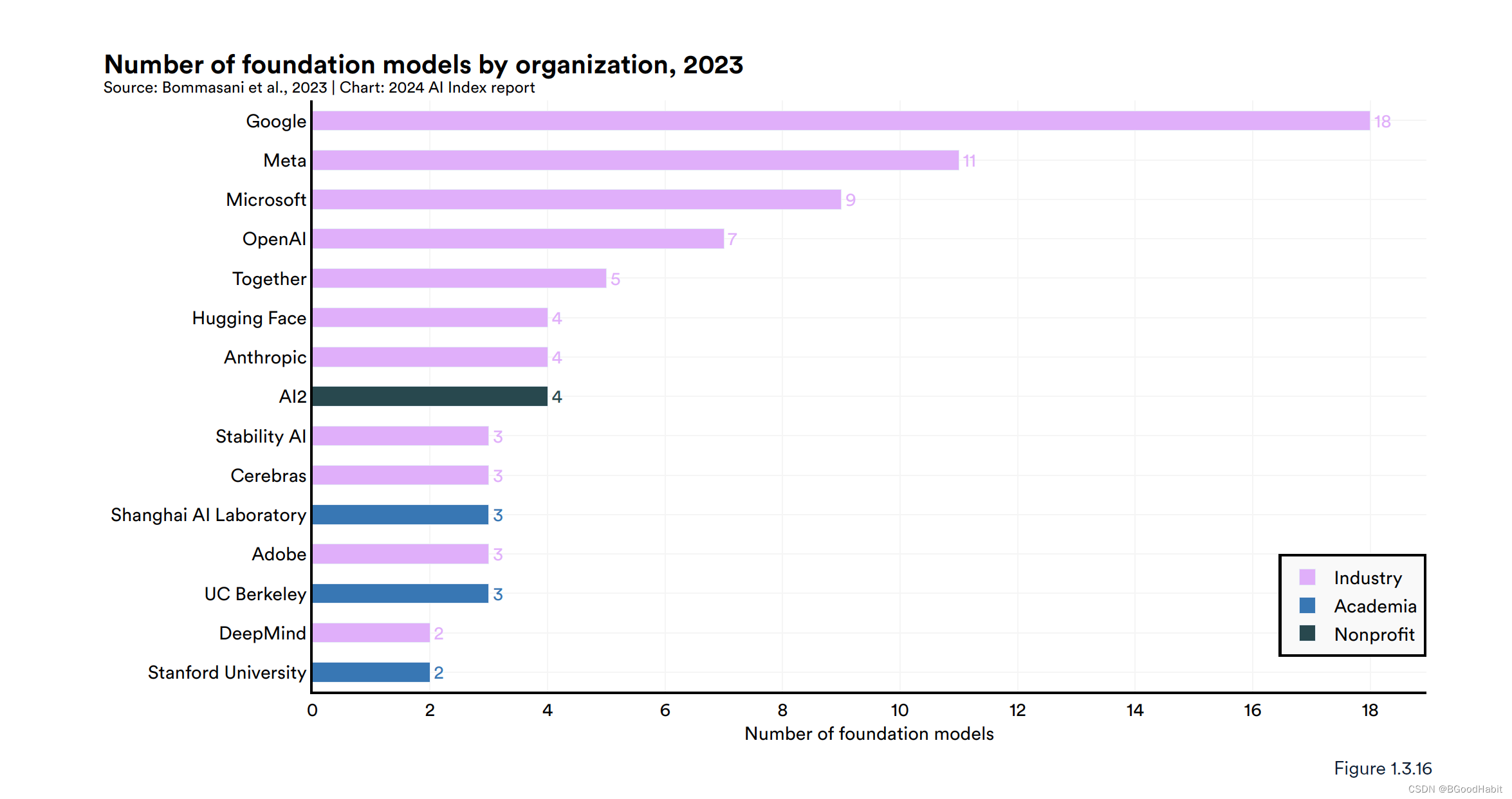
下面是不同国家在基础模型上发布数量对比,美国是主导力量: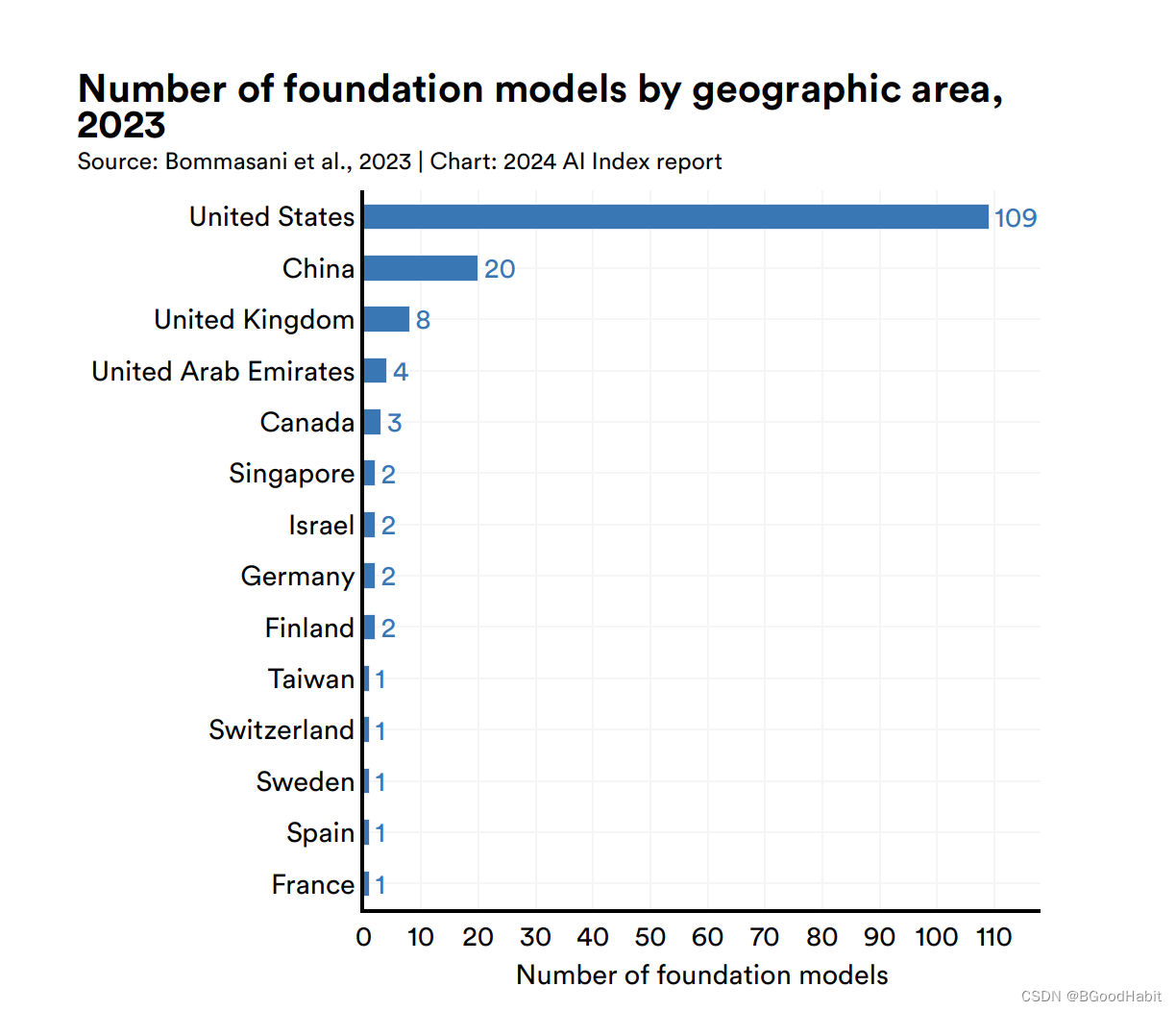
2.5 训练模型成本
如下是给出的核心基础模型训练花费的成本费用: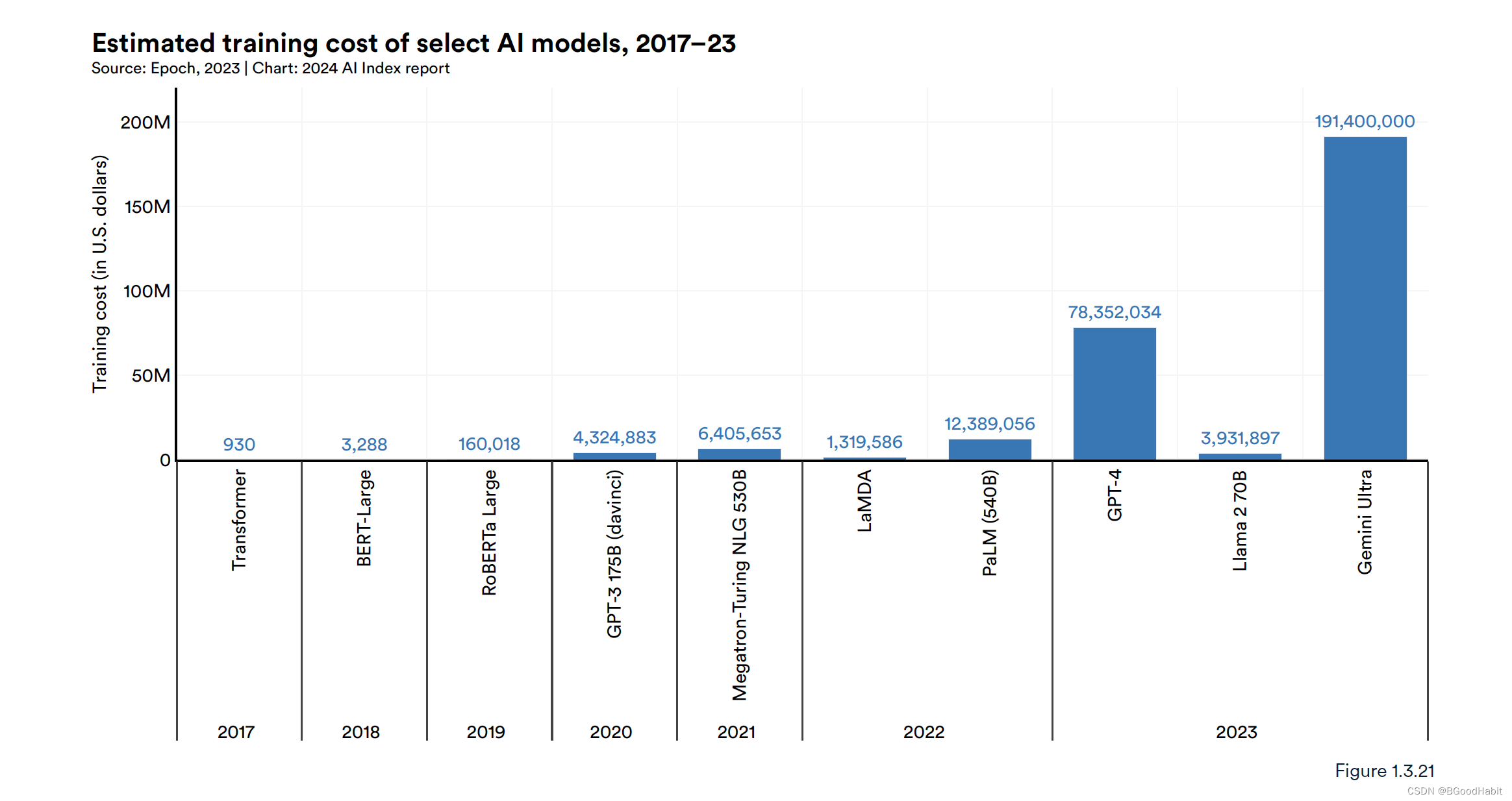
从上图可以看出,训练大模型的成本越来越高,达到几千万上亿美金的消费。
如下是对一些基础模型成本的大概预估,可以看出整体成本是飞速上升的: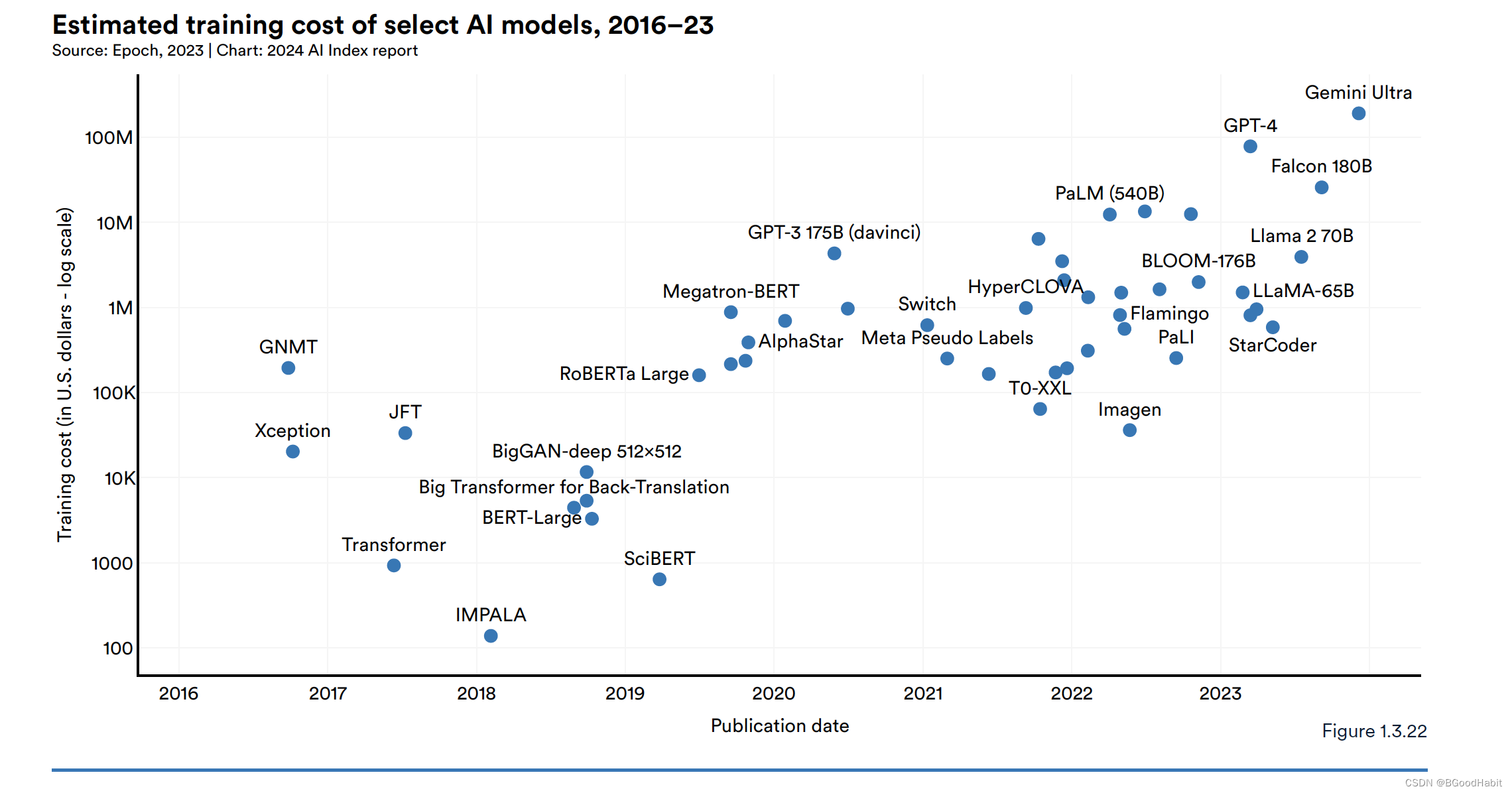
3 技术性能
3.1 核心要点
AI在一些任务上已经打败人类,但是不是所有的任务
多模态AI模型已经到来
Google的Gemini以及OpenAI的GPT-4等,这些模型能够将图像,文字信息进行融合,展示了强大的能力。在一些场景,还能够处理语音信息。更复杂的benchmarks出现
在2023年,出来了一些更具挑战的benchmark集,包括代码评估集SWE-bench , 图像生成评估集HEIM , 一般推理数据集MMMU, 道德推理集MoCa, AgentBench评估agent行为的, 而HaluEval用于幻觉评估。更好的数据创造更好的AI模型
数据对AI模型的提升至关重要,通过AI生成更多的数据来加强模型的表现,特别在一些比较困难的任务中比较明显。人类开始参与模型的评估
随着生成模型产生高质量的文本、图像等,基准测试逐渐开始转向纳入人类评估,例如聊天机器人竞技场排行榜,而不是像ImageNet或SQuAD这样的计算机排名。公众对人工智能的感受正逐渐成为追踪人工智能进展的越来越重要的考虑因素。LLM提升了机器人的灵活性
将语言模型融入到机器人中,使得机器人越来越灵活,比如机器人系统PaLM-E和 RT-2. 机器人可以进行自主的问问题,与现实世界的交互更加高效。AI agent获得越来越多的研究
AI agent就是一个系统能够在特定的场景中自动的处理一些列任务。虽然现在还面临很大的挑战,但是计算机科学家表面现在自动的AI agent也在不断提升。当前的智能体现在已经能够精通像Minecraft这样的复杂游戏,并有效地处理诸如在线购物和研究辅助等真实世界任务。不公开的大模型比公共的大模型表现好
在top 10个AI benchmark集上,不公开的大模型比公开的大模型表现效果好。
3.2 重要模型发布情况
| Date | Model | Type | Creators | Significance |
| 2023.3.14 | Claude | Large language model | Anthropic | Anthropic是OpenAI的一个主要竞争对手,Claude是一个有用,诚实的,尽可能少危害的这么一个模型 |
| 2023.3.14 | GPT-4 | Large lanuage model | OpenAI | GPT-4超越了GPT-3,是目前为止最强大的LLM,在多项benchmarks中,超越了人类水准 |
| 2023.3.23 | Stable Diffusion v2 | Text-to-image model | Stability AI | Diffusion v2是Stability AI的文本生成高像素高质量图像的模型 |
| 2023.4.5 | Segment Anything | Image segmentation | Meta | Segment Anything是一个AI model,可以对图片的照片进行物体的分割 |
| 2023.7.18 | Llama 2 | Large language model | Meta | Llama 2是开源模型,它的小尺寸版本(7B和13B)也取得了很不错的效果 |
| 2023.8.20 | DaLL-E 3 | Image generation | OpenAI | DaLL.E 3是OpenAI的文本生成图像模型,是DaLL-E升级版本 |
| 2023.8.29 | SynthID | watermarking | Google DeepMind | SynthID是一个可以给AI生成的图像和音乐打上水印的一个工具,即使在图像改变后,仍然可以检测到 |
| 2023.9.27 | Mistral 7B | Large language model | Mistral AI | Mistral 7B,是法国AI公司Mistral发布的,70亿的参数模型在benchmark上的效果上比Llama 13B的效果好 |
| 2023.9.27 | Ernie 4.0 | Large language model | Baidu | Baidu发布了Ernie 4.0,是目前效果最好的LLM |
| 2023.11.06 | GPT-4 Turbo | Large language model | OpenAI | GPT-4 Turbo是个升级后的LLM,降低了价格且可以提升到128K的上下文信息输入 |
| 2023.11.06 | Whisper v3 | Speech-to-text | OpenAI | Whisper v3是一个开源的将语音转化成文本的模型,它有较高的准确率,并且能够支持多种语言 |
| 2023.11.21 | Claude 2.1 | Large language model | Anthropic | Claude能够支持200K的信息输入,这加强了对长文本内容处理能力 |
| 2023.11.22 | Inflection-2 | Large language model | Inflection | Inflection-2是由DeepMind人员创建的创业公司Inflection发布的LLM模型 |
| 2023.12.6 | Gemini | Large language model | Gemini的出现是GPT-4的强有力竞争对手,其中变版Gemini Ultra在多个benchmarks上已经超越了GPT-4 | |
| 2023.12.21 | Midjourney v6 | Text-to-image model | Midjourney | Midjourney发布的最新版本主要加强人们使用更加直观的prompt生成的图像,并且加强了生成图像的质量 |
3.3 AI表现情况
在最近几年里,AI在较多项任务中已经超越了人类的表现。以下是AI与人类在一些任务中的对比情况图: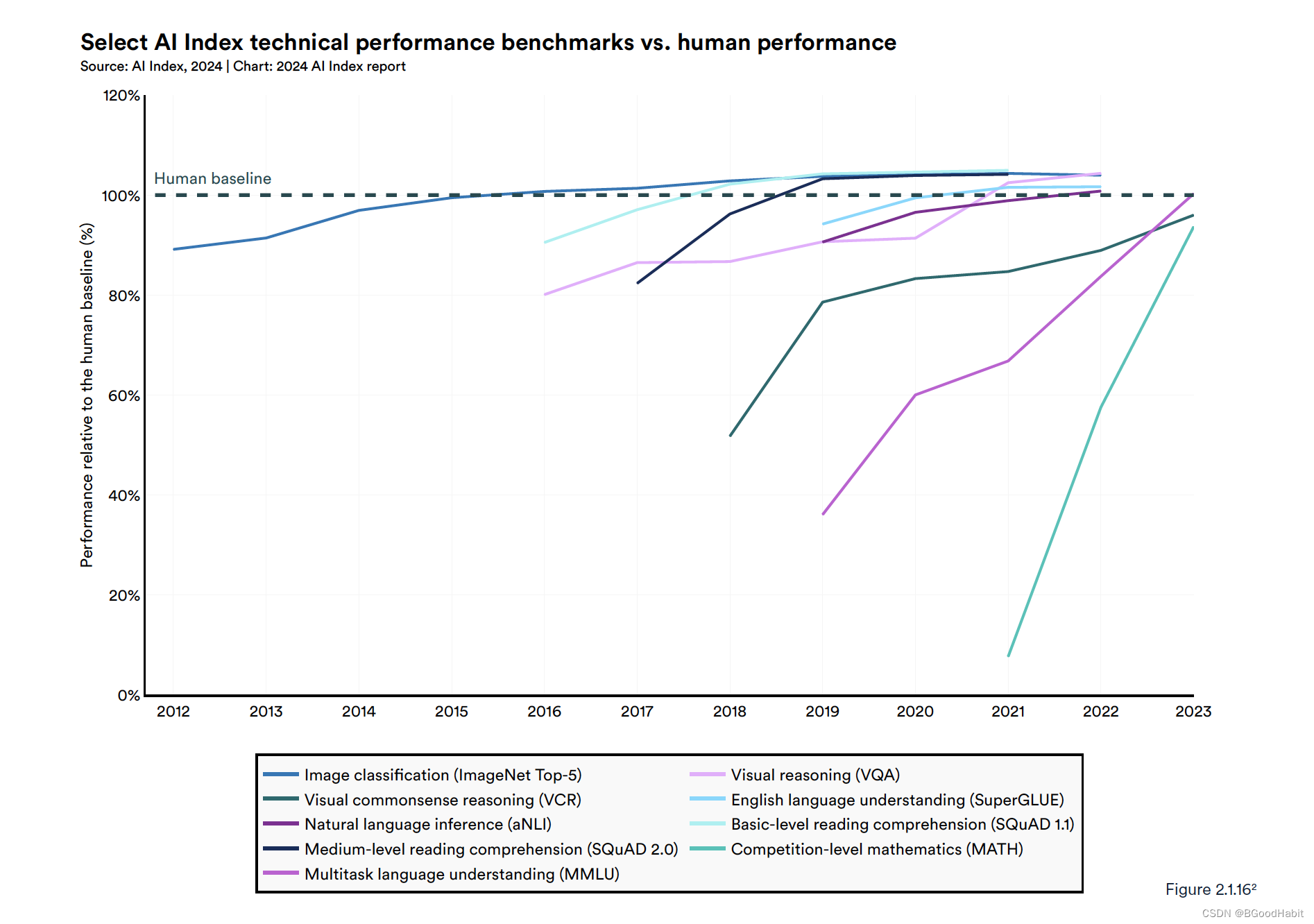
除了竞赛数学,多语言理解以及视觉常识推理这三个任务上,AI比人类稍微弱,但是在图像分类,英语理解,自然语言推理等其它任务中,AI都超越了人类水平。
由于AI的飞速发展,近一两年也新增了不少适应不同任务的benchmarks评估集,如下是一些不同任务新增的benchmarks集: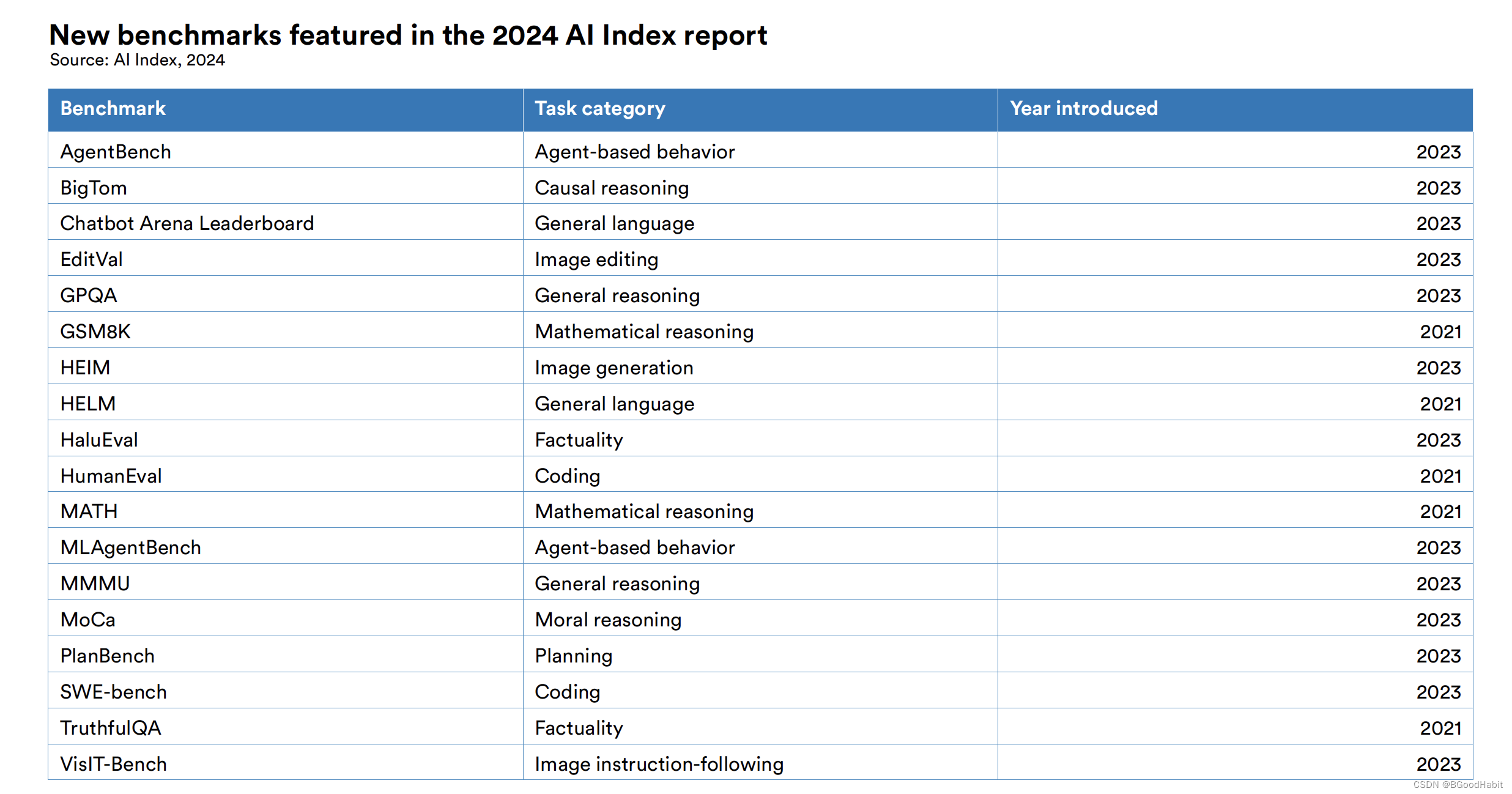
3.4 多学科、高难度评估集 (MMMU & GPQA & ARC)
随着AI模型越来越智能,传统评估集比如文本推理(SQuAD)以及视觉推理(VQA)这种单任务的数据集已经不能很好的评估现有模型的能力,需要更具有挑战的任务数据集。来自美国和加拿大的研究人员创建了MMMU评估集用来评估专家级别的AGI效果。MMMU收集了11500个大学级别的来自6个领域(艺术与设计,商业,科技,健康与医疗,人类学,技术与工程)的问题。问题包括了多种格式:图表,地图,表格,几何形状等多种格式,MMMU是一个最困难的数据集考验AI的认识,知识以及推理能力。截止2024年1月,目前表现最好的模型是Gemini Ultra。从目前的一个测试来看,AI的效果相比人类专家的水平还是差一些,如下是具体的数据表现:
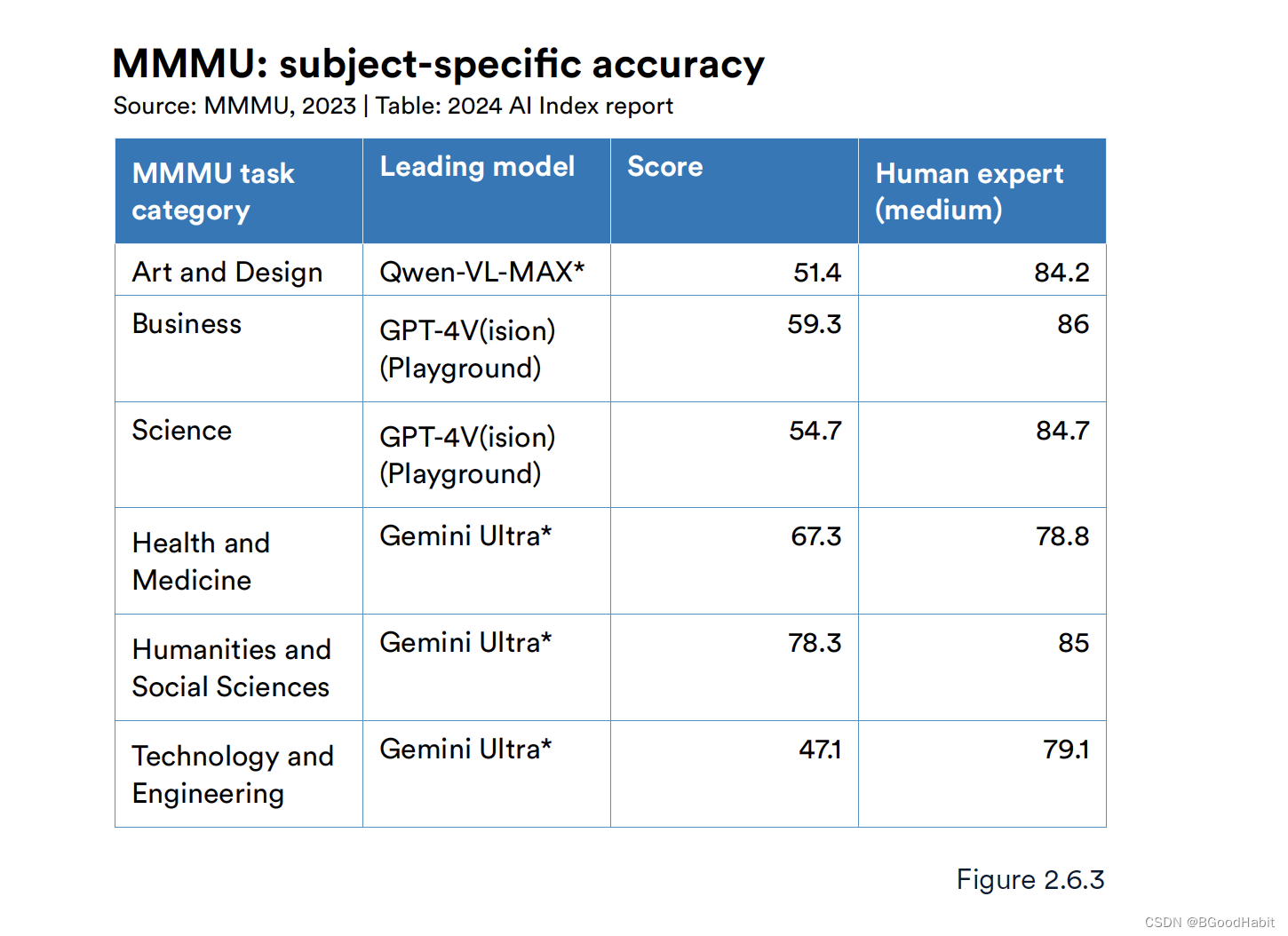
来自纽约大学(NYU),Anthropic以及Meta公司创立的CPQA
测试集用来测试AI模型的多学科的推理能力。这个数据集包含了448个困难的多选择题,这些题目答案不能轻易的从google搜索得到。这些问题是由各领域比如生物,物理,化学等学科专家设计的,PhD级别的专家在他们的领域里实现了大概65%的准确率,而不是专家领域的人类大概34%的准确率,而表现最好的GPT-4模型大概只实现41%的准确率,一些AI模型的表现如下: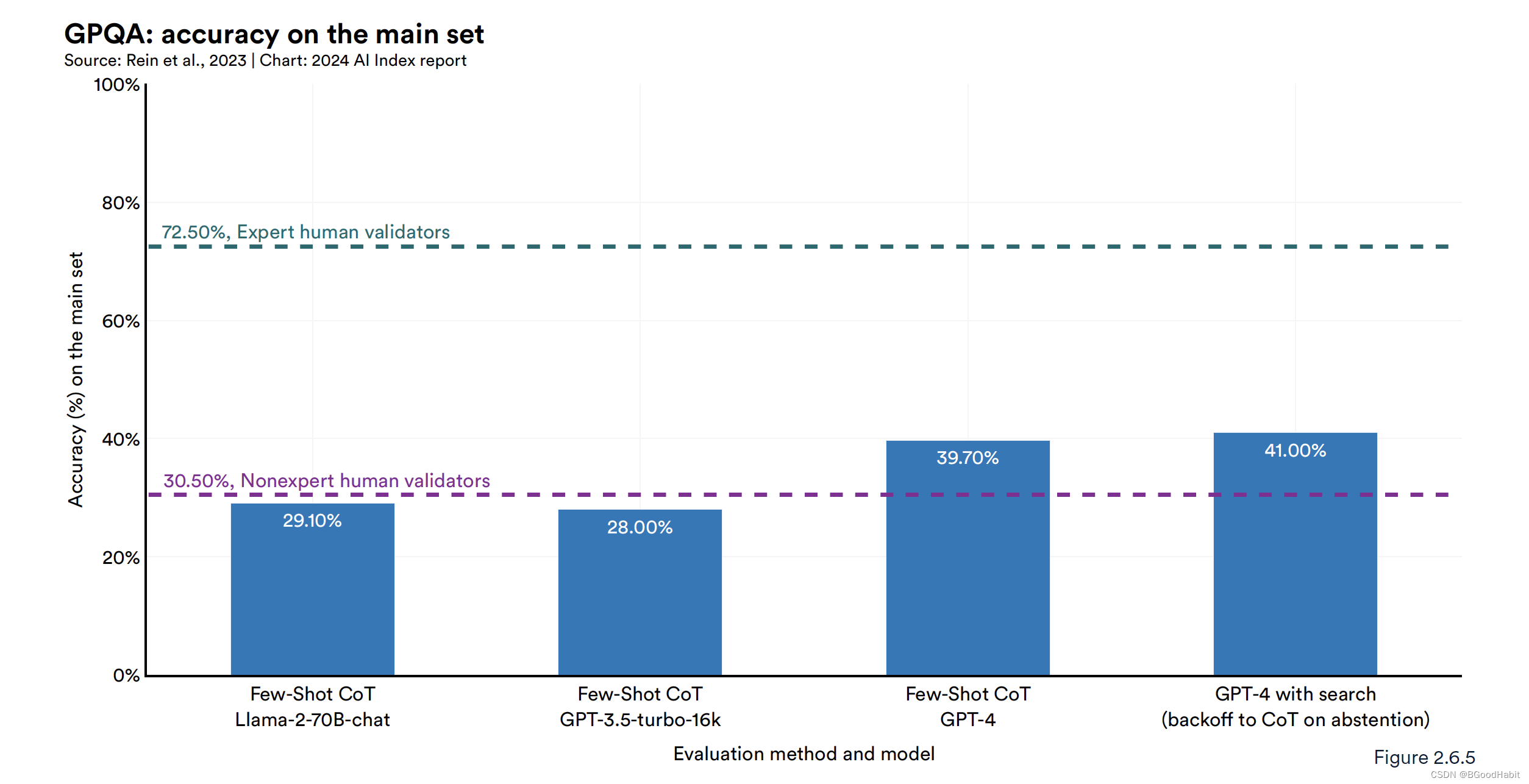
ConceptARC 评估集收集的是一些类比智能题,主要考察通用的一些抽象归纳能力。题型如下图所示: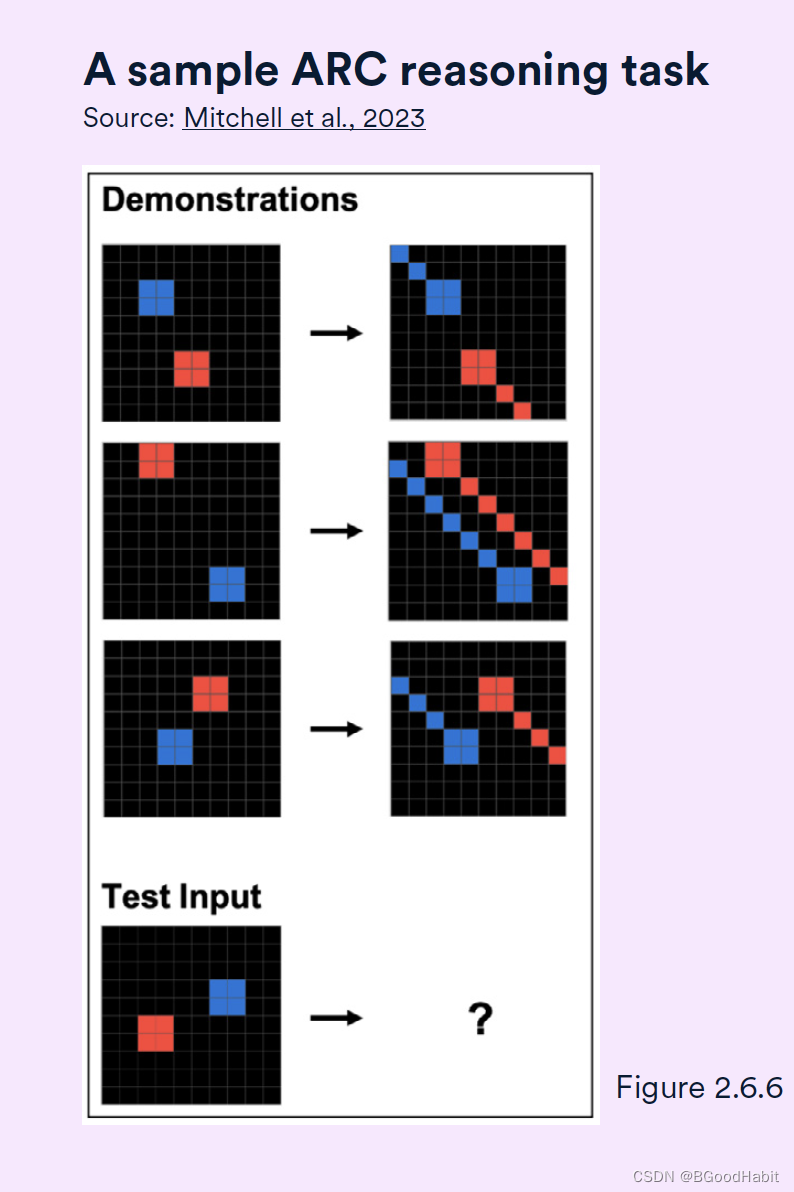
从测试来看,GPT-4的效果与人类比,还是差距较多,GPT-4实现了69%的准确率,而人类的水平是95%,如下图所示: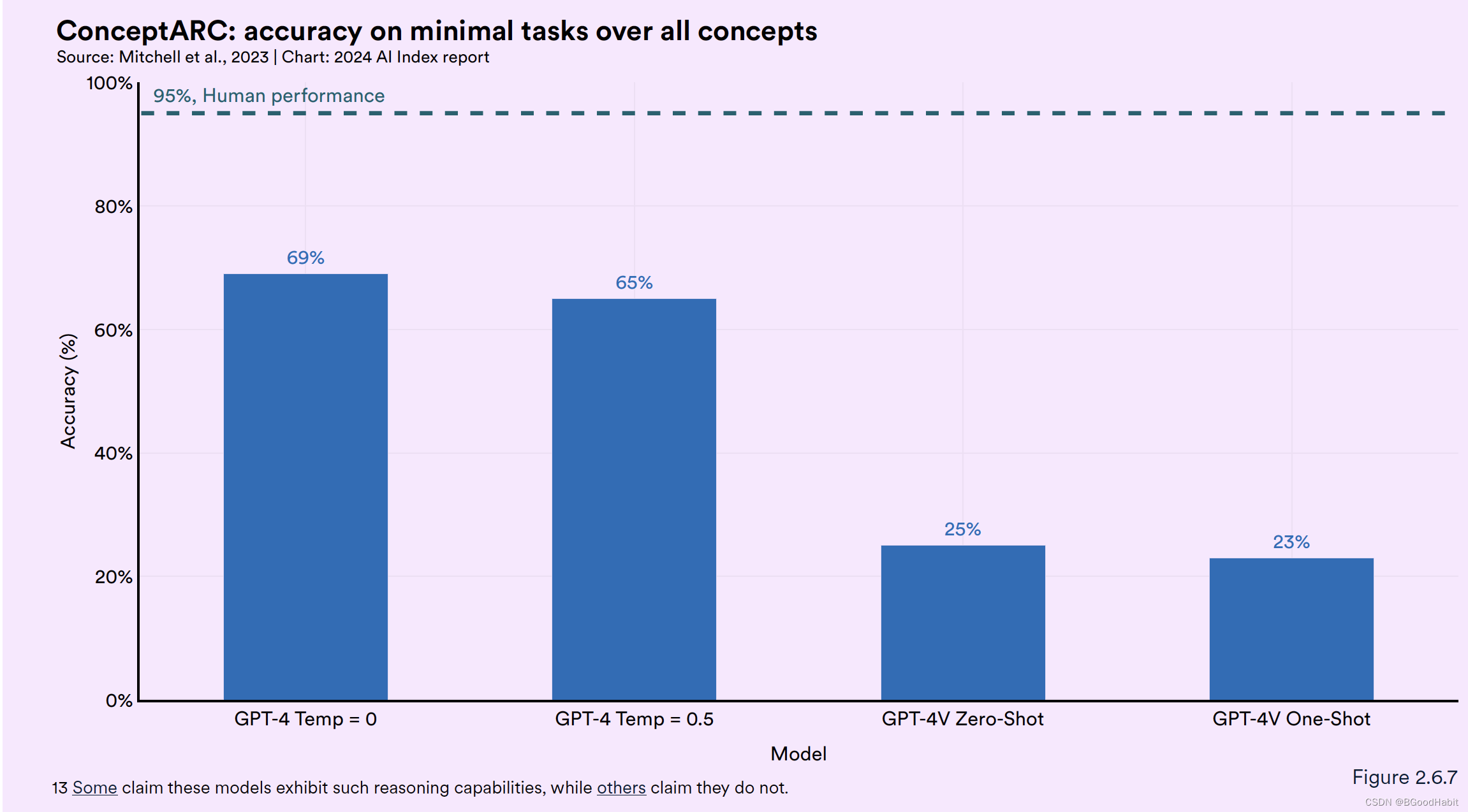
从上面几个高难度的评测集数据中可以看出,AI模型的表现目前来看相比专家人类还有一定的差距。
3.5 Agents
AgentBench,是一个用来评估基于大模型的agents。包含了8种不一样的人机交互环境:包括网页浏览,在线购物,家务处理,智力游戏,数字纸牌游戏等。测评了基于LLM的25个agents,包括OpenAI的GPT-4,Anthropic的Claude 2以及Meta的Llama 2。整体测评来看,GPT-4表现效果最好。如下是关于AgentBench的说明情况: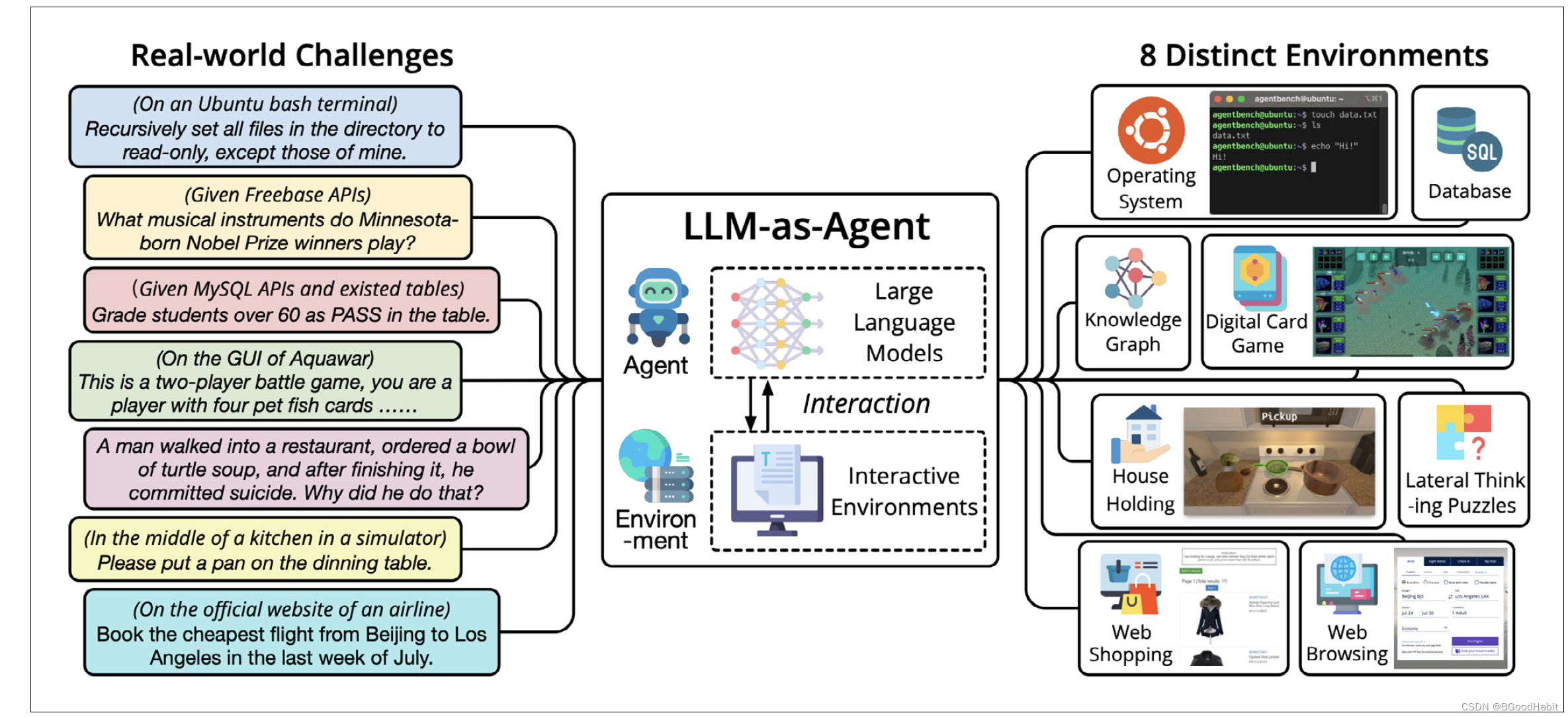
各种大模型的表现情况如下:
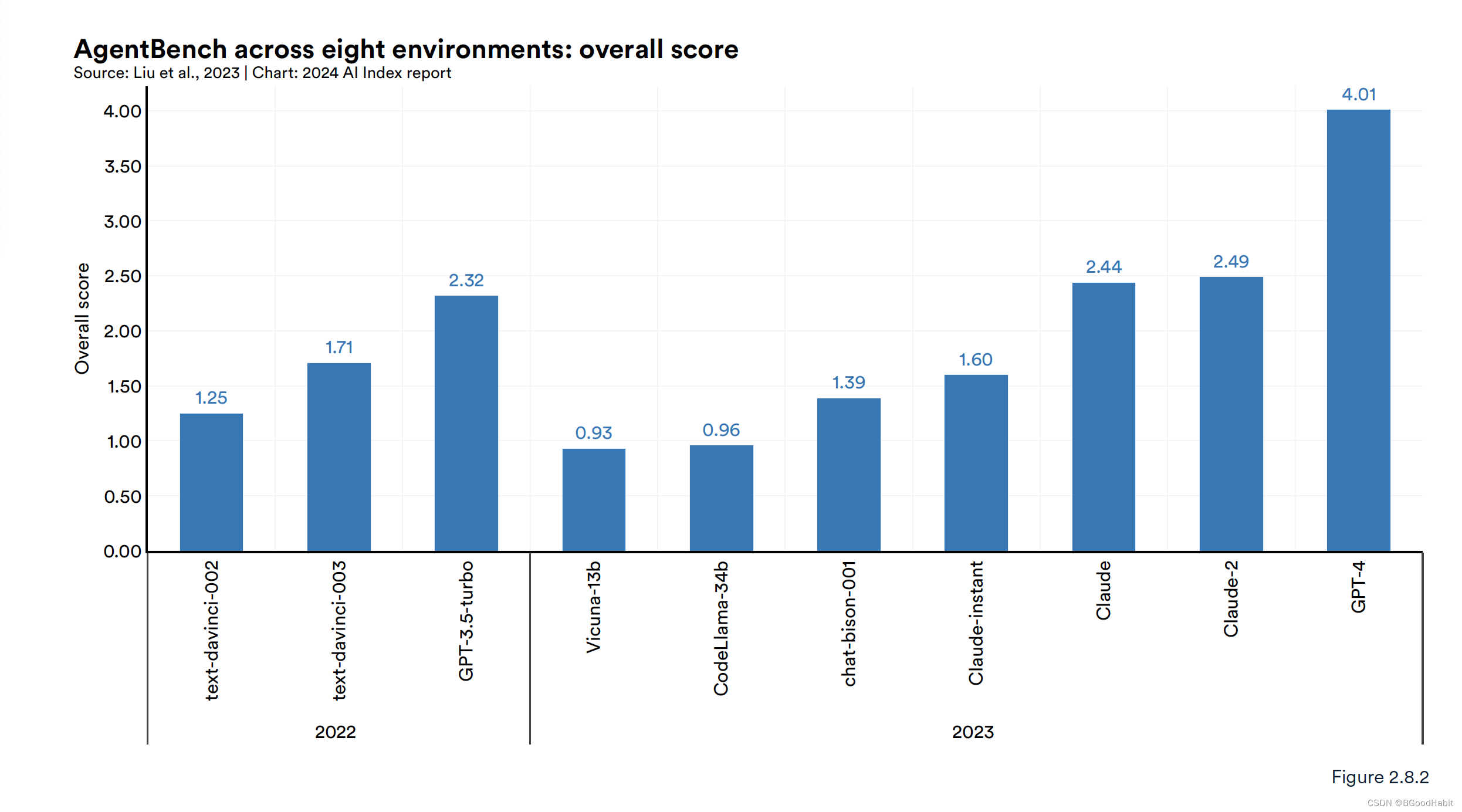
3.6 RLHF & RLAIF
RLHF (Reinforcement Learning from Human Feedback) 通过加入用户的反馈到奖励函数,使得模型能够训练成更加有用无害的特性。RLHF对LLM的提升也证明是有效果的,在一些基础的大模型上,加入RLHF都有一定提升,如下所示:
RLAIF (Reinforcement Learning from AI Feedback)是基于强化学习的LLM去调整其它AI模型向人类的偏好靠齐。来自google research对比了RLHF,RLAIF与SFT (supervisd fine-tuning)在摘要生成和对话是否无害任务两方面效果对比如下: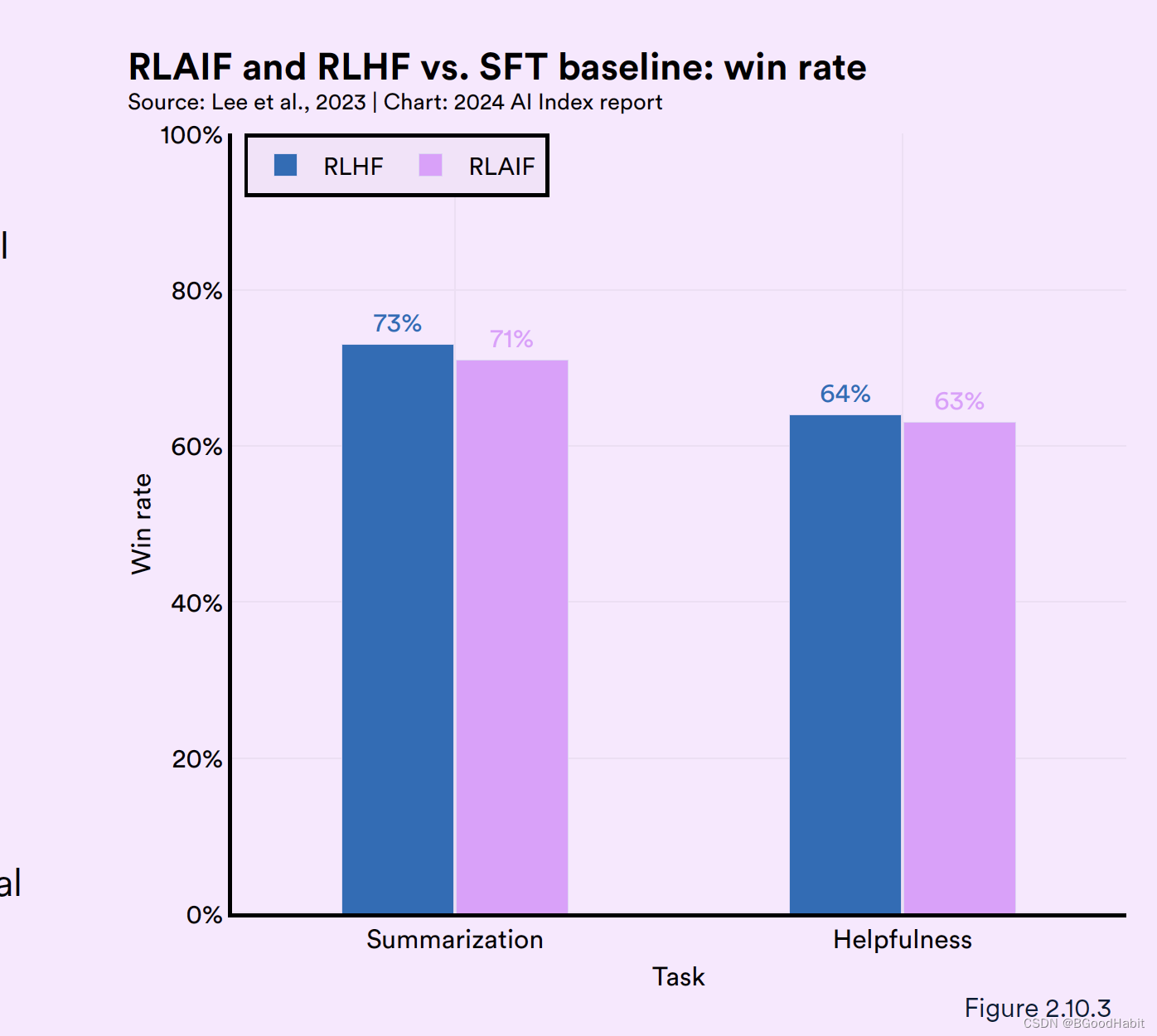
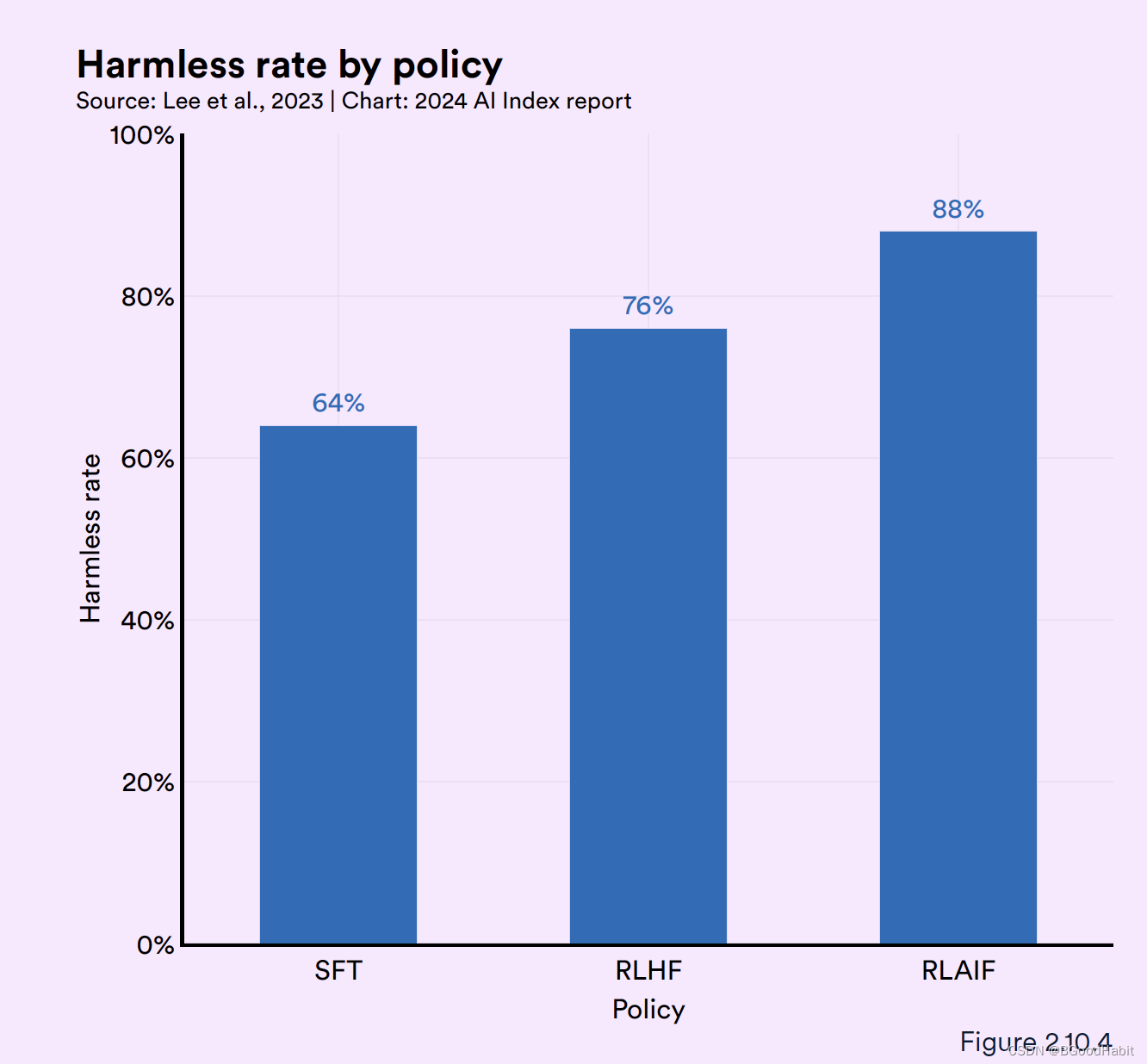
可以看出RLHF,RLAIF都比SFT效果好,在摘要生成任务中,RLHF与RLAIF效果差异不大,但是在生成无害对话任务中,RLAIF 88%的效果比RLHF 78%效果好。这个表面,RLAIF可能是一个更加高效并且代价最少的一个方法用来训练对齐人类偏好的AI模型。
3.7 LLM随着时间迭代效果对比
随着新的数据以及用户的反馈,开发者对于LLM随着时间迭代不同的版本效果对比,来自Stanford和Berkeley发表的一份研究报告,发现随着不同时间更新后的GPT-3.5和GPT-4比他们对应的老版本在几项任务中,效果还变差了,如下所示: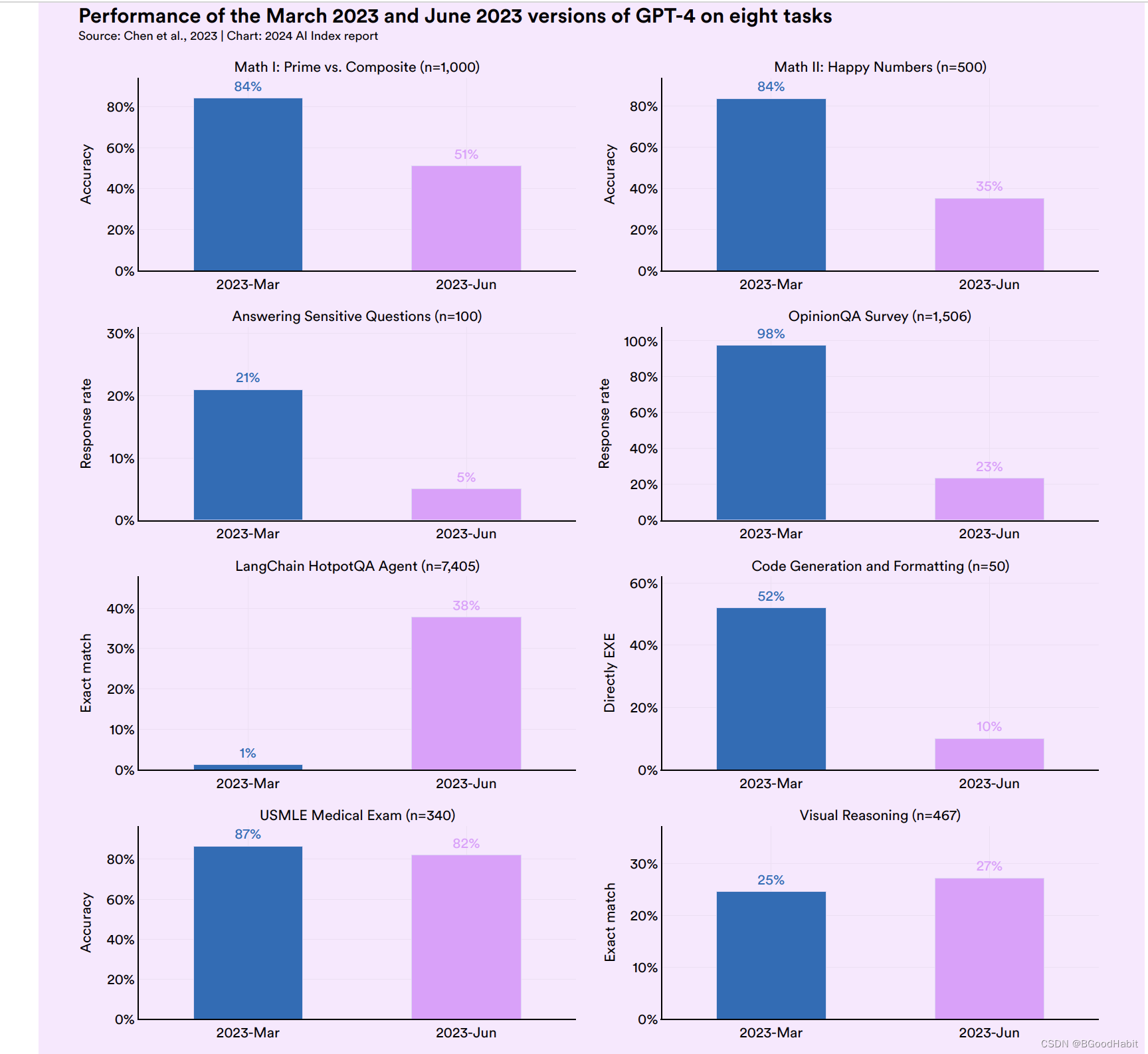
3.8 提升LLM效果的技巧
Prompting: prompting通过自然语言描述任务让模型进行执行,这是是非重要的一个阶段。通过设置有效的prompt对大模型的效果提升十分有效。通过Chain of Thought(CoT)以及Tree of Thoughts (ToT)这两种prompting方法可以提升LLM的效果。在2023年,欧洲研究者提出了另外一种prompting方法,Graph of Thoughts (GoT) 在很多任务中取得了很大的提升。GoT可以使得LLM用一种更加灵活的类似人类推理图结构过程方式进行生成结果,如下图所示:
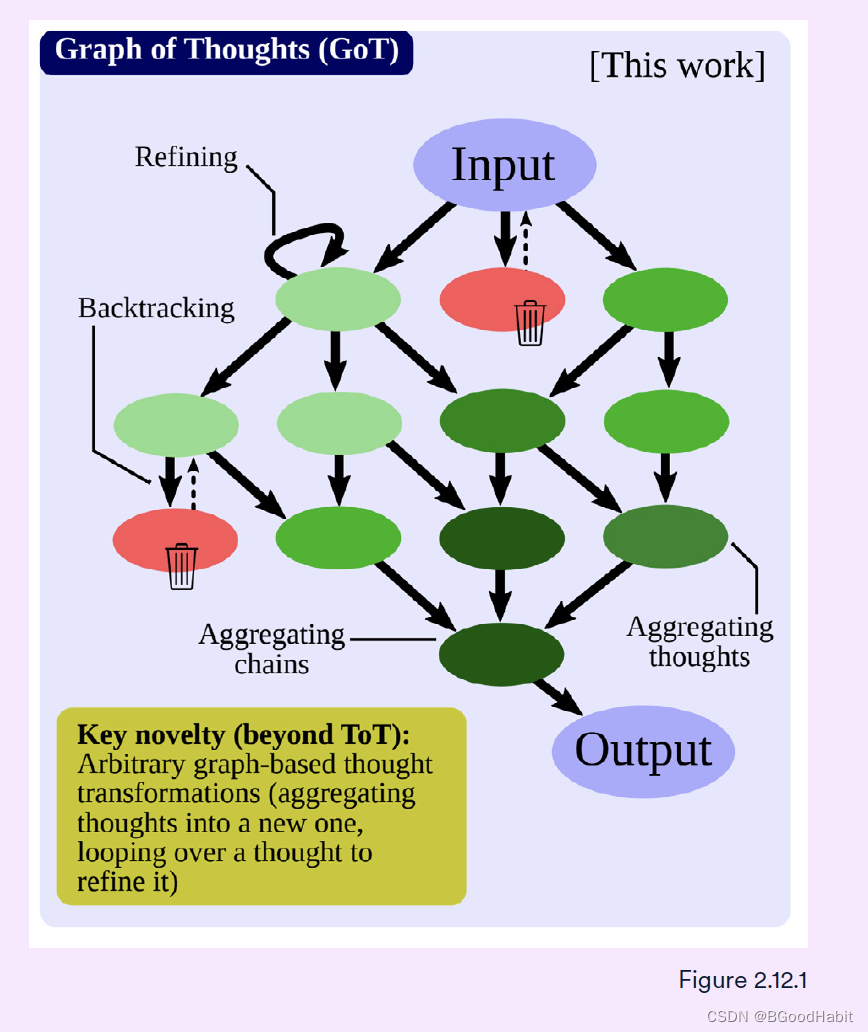
如下是对比效果,从数据表现来看,GoT表现较好的效果: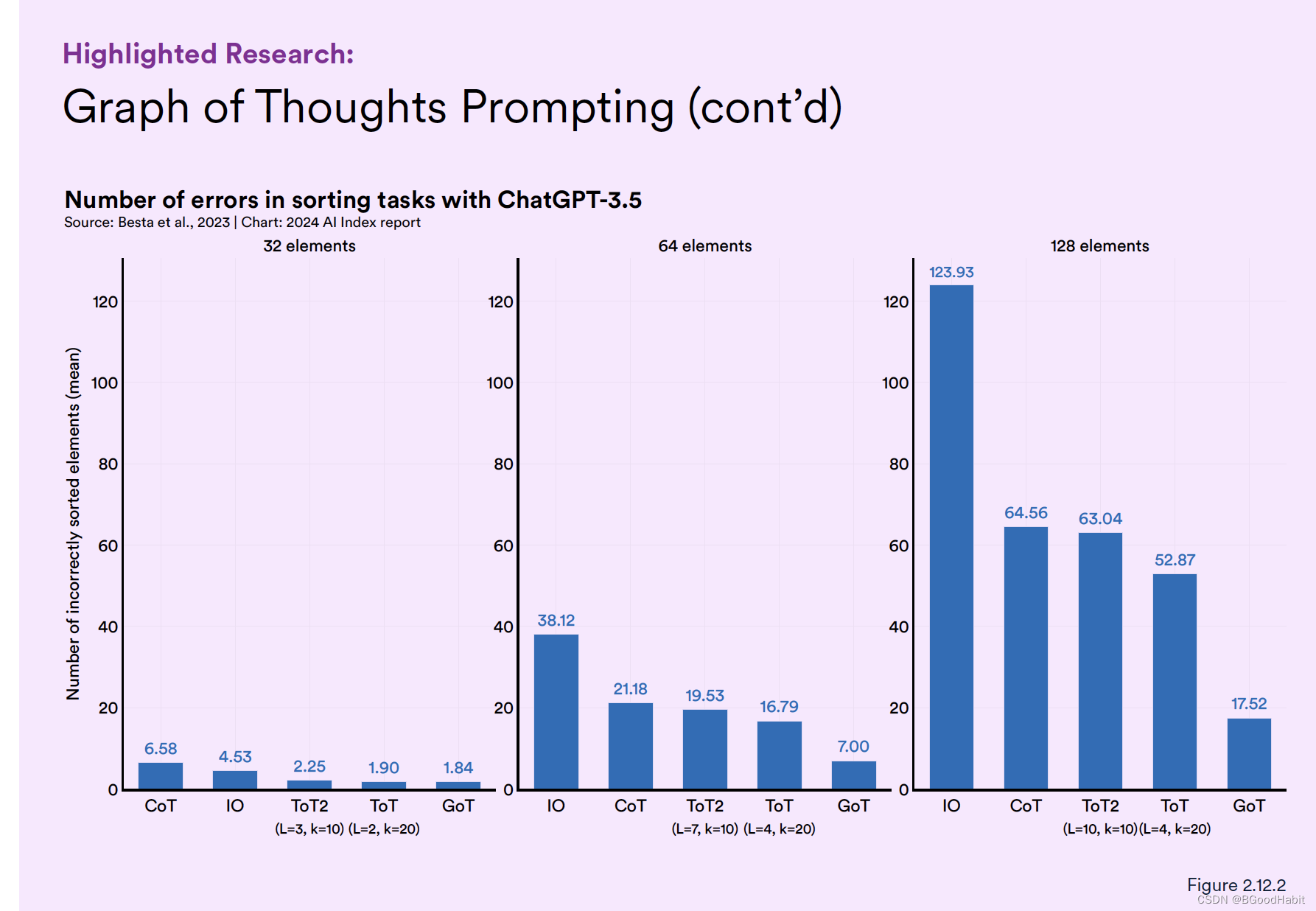
OPRO: 来自DeepMind介绍的一种使得LMM反复生成prompts提高算法效果的一种方法叫做:Optimization by PROmpting。OPRO通过对问题的描以及之前的步骤,用自然语言描述方法让LLM自己产生新的prompts。下面是OPRO的一个例子如下:

与其它prompting方法比如"let’s think step by step" 或者 an empty starting point对比,ORPO在多个任务中准确率上显著提升。如下图所示: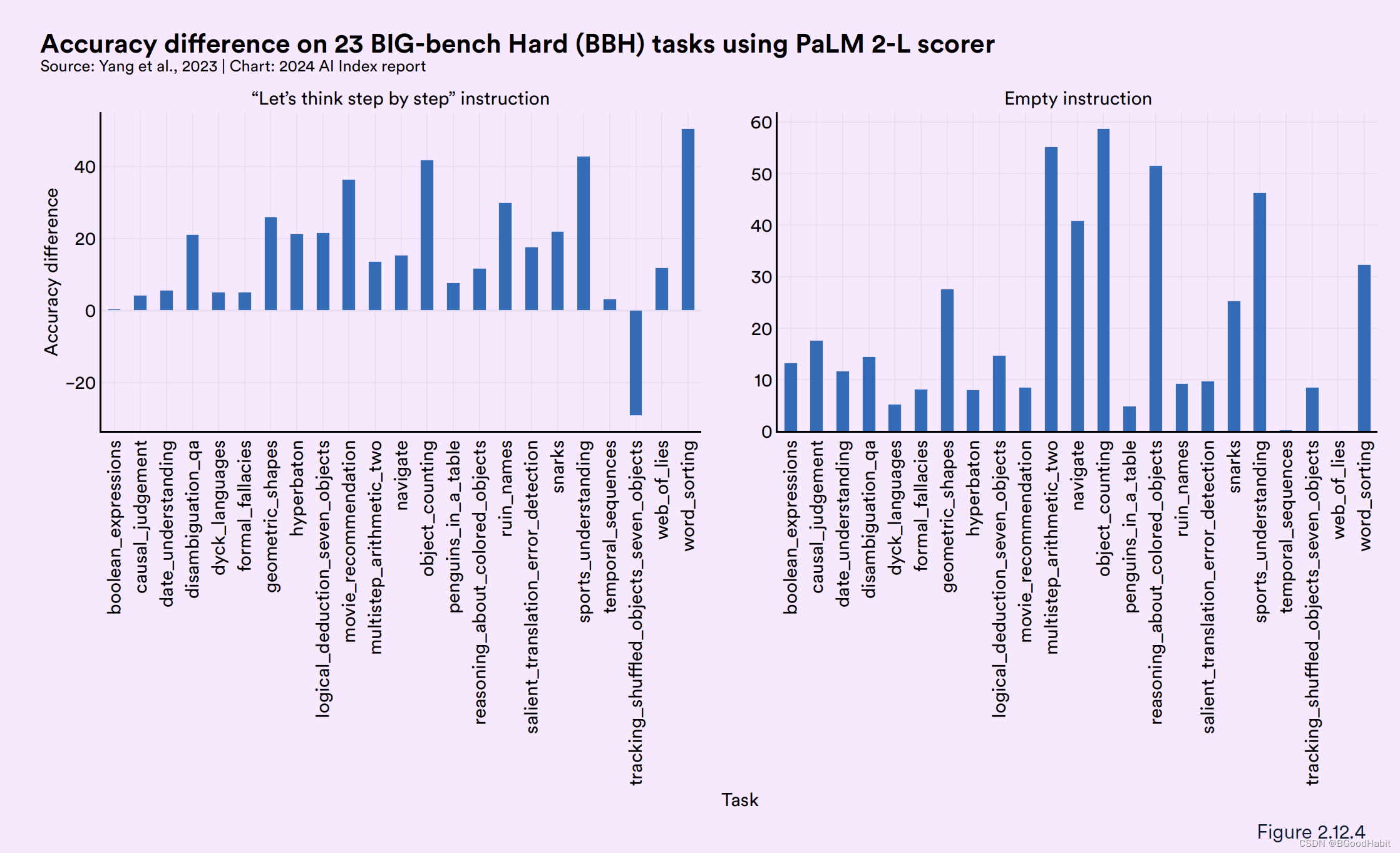
Fine-Tuning:fine-tune是进一步调整LLM在小数据集上效果的一种很受欢迎的方法。fine-tuning不仅可以提升模型的整体表现效果,而且能够加强模型在特定任务中的效果。==QLoRA==是由华盛顿大学研究团队在2023年提出来的一种fine-tuning方法。QLoRA能够大大降低内存,可以使得65B的大模型能够在一个48G的GPU上进行微调。如下图是QLoRA与Full Finetuning以及LoRA的训练对比:
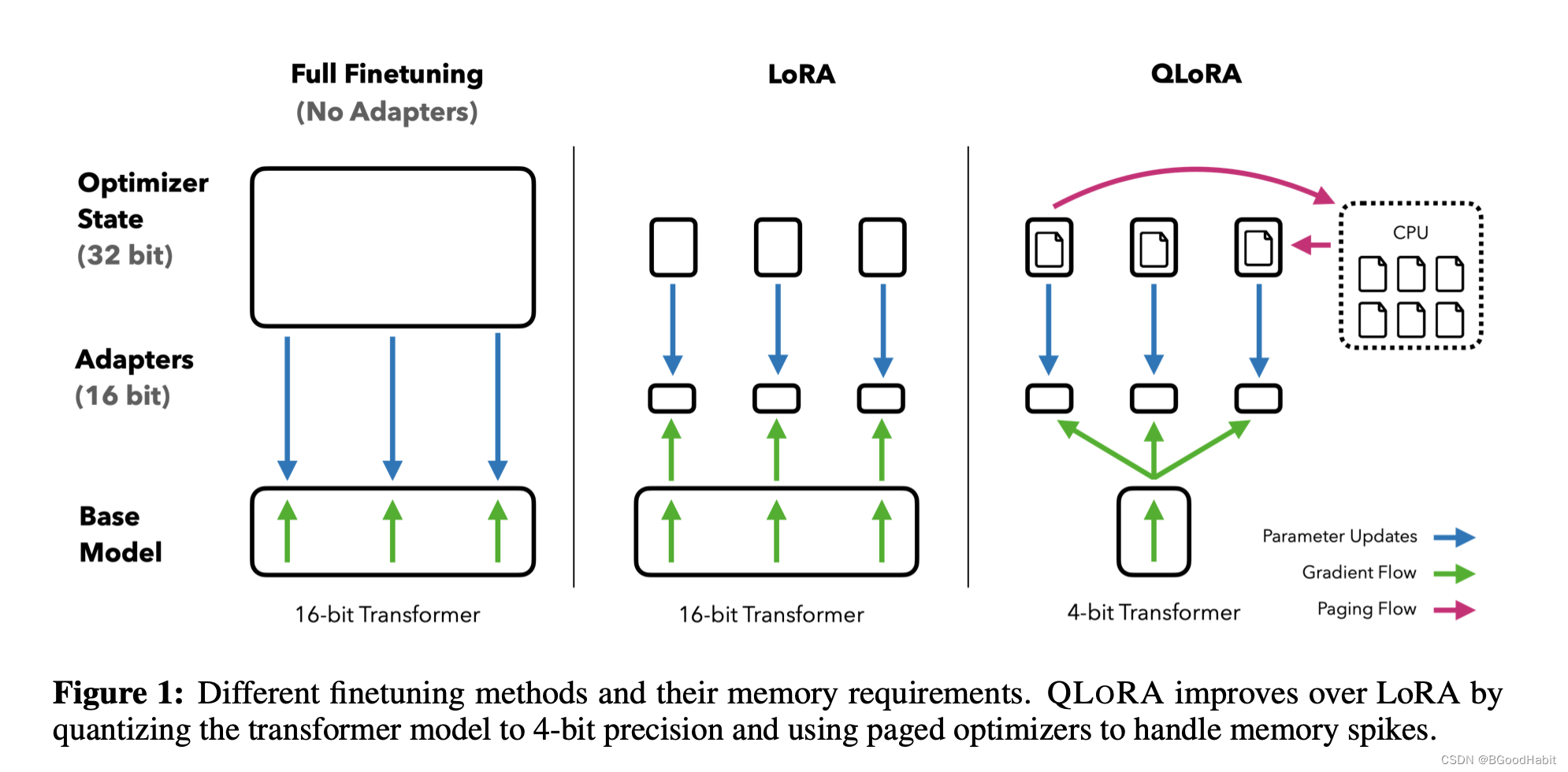
QLoRa 能够在更少的资源上进一步优化和提高模型的效果,这大大提高了模型的使用能力。Flash-Decoding: Flash-Decoding for long-context inference由斯坦福研究者提出来,主要解决传统中LLM对attention机制的计算效率问题。特别在处理很长的序列,Flash-Decoding通过平行的处理加载keys和values,然后单独进行缩放,最终结合一起计算attention输出。Flash-Decoding 大大降低了AI在推理的代价。流程计算如下:
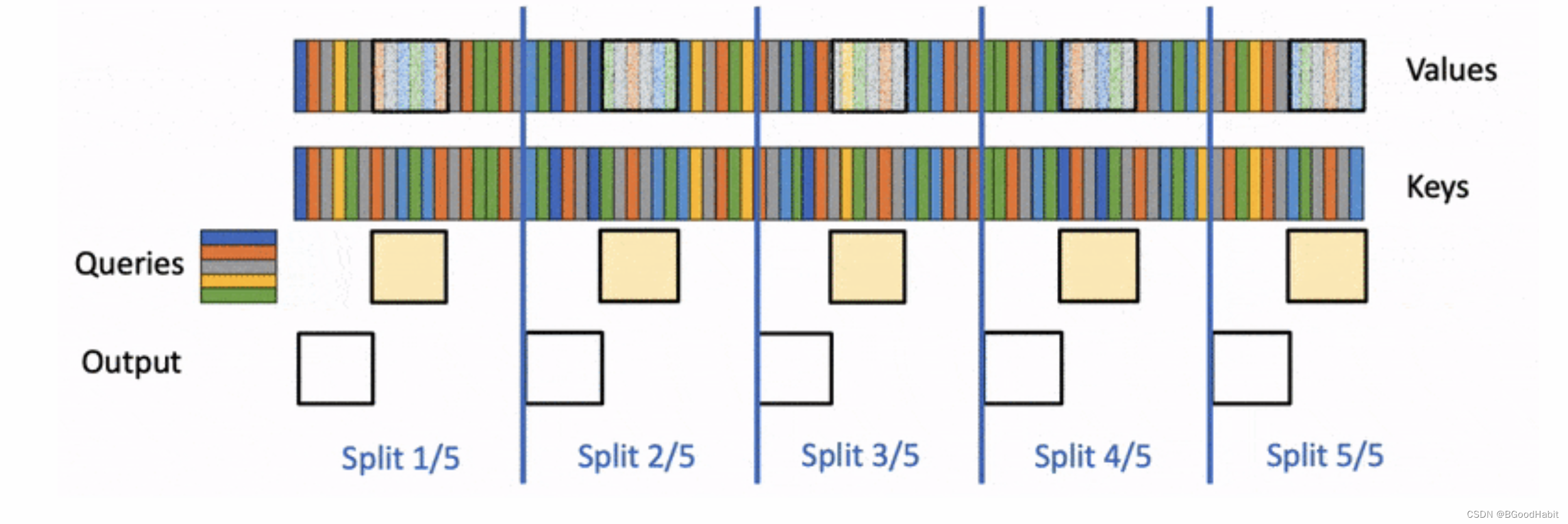
如下是pyTorch,Flash-Attention以及Flash-Decoding三者在计算multihead attention在across batch以及sequence length上的速度效率对比情况: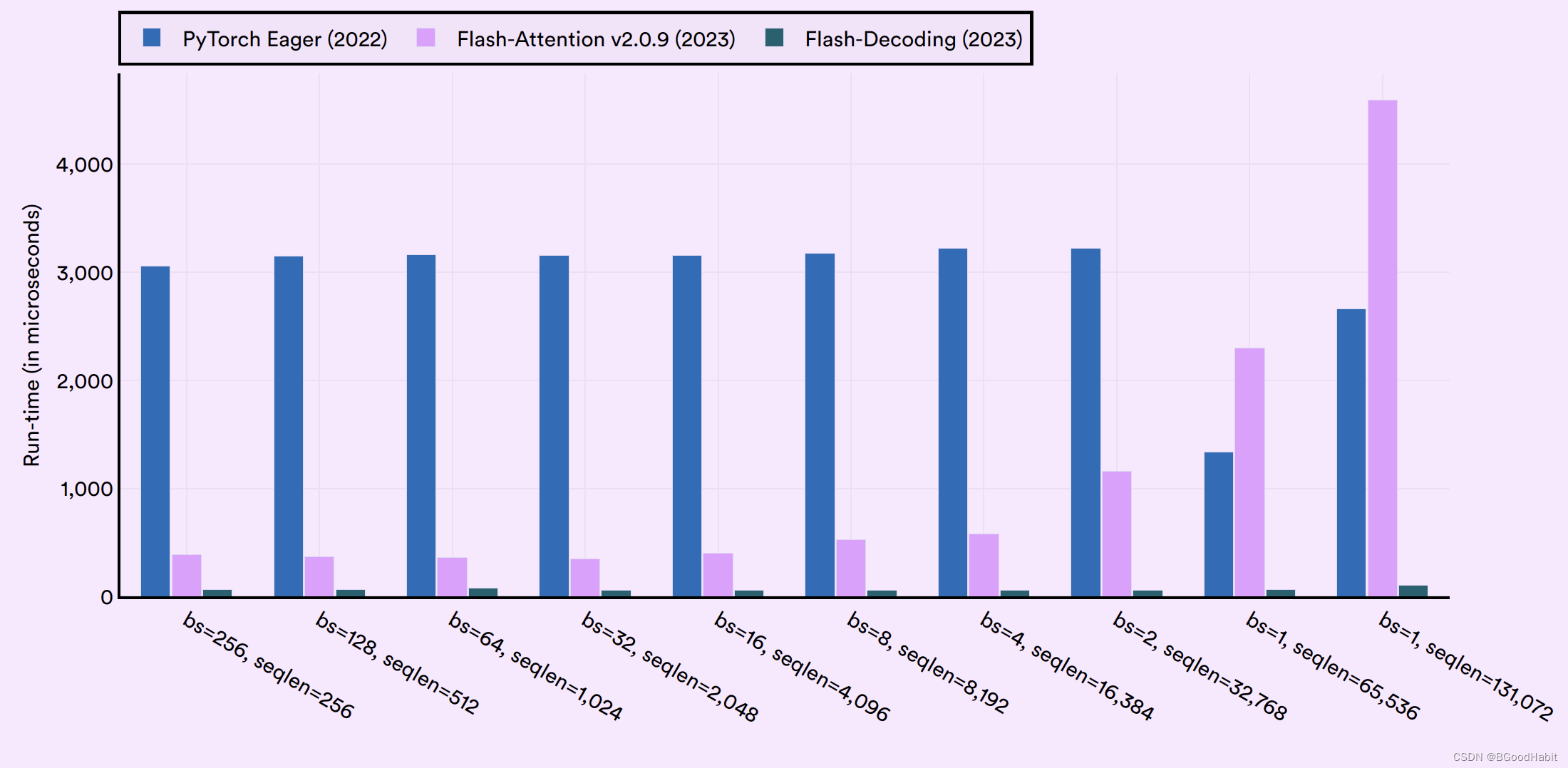
3.9 训练AI系统对环境的影响
训练大模型消耗的资源会释放大量的二氧化碳对环境造成影响,OpenAI训练的GPT-3就排放502吨的二氧化碳,如下图是各种模型训练过程中耗费资源产生的二氧化碳拍排放量情况: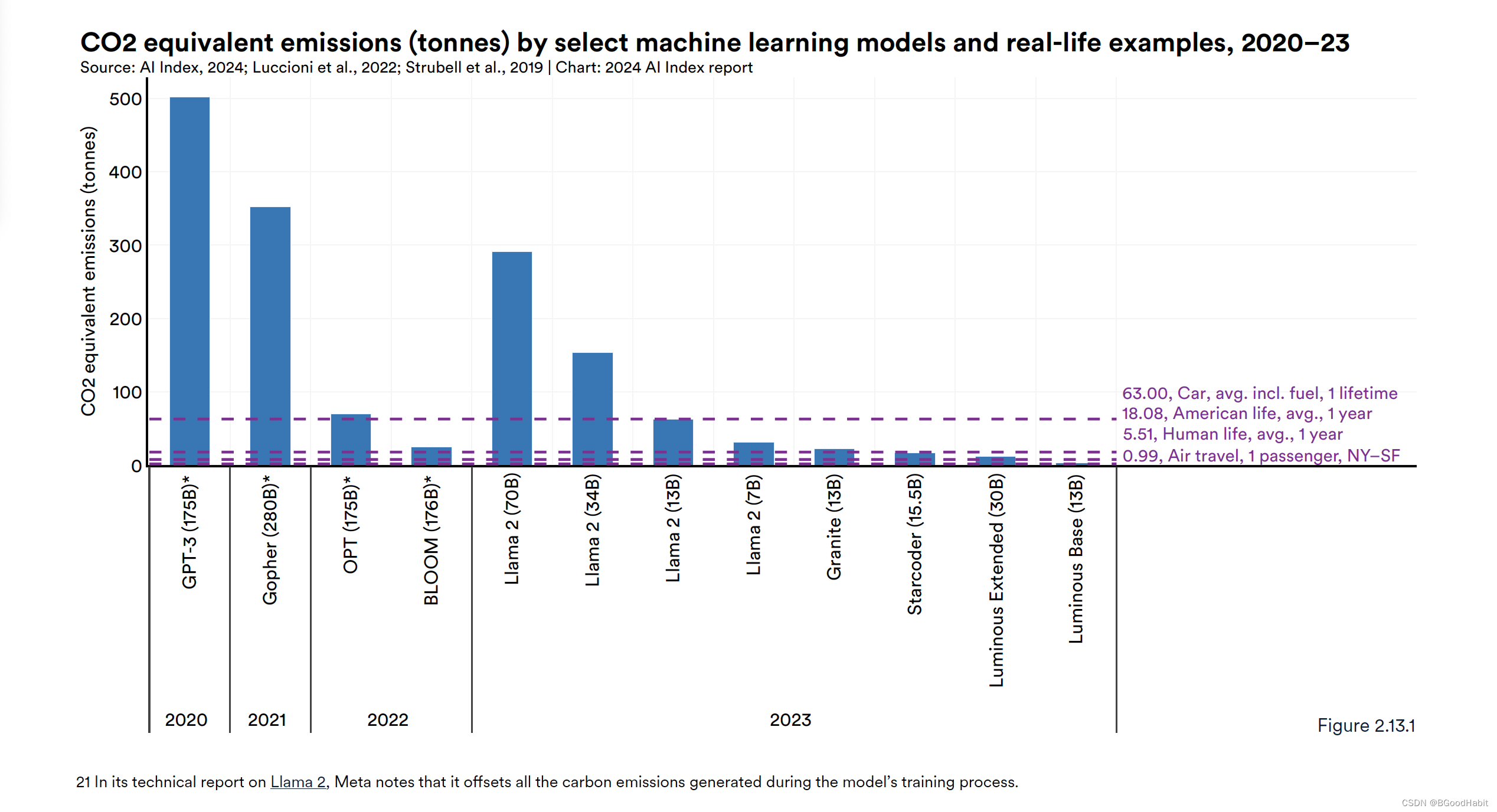
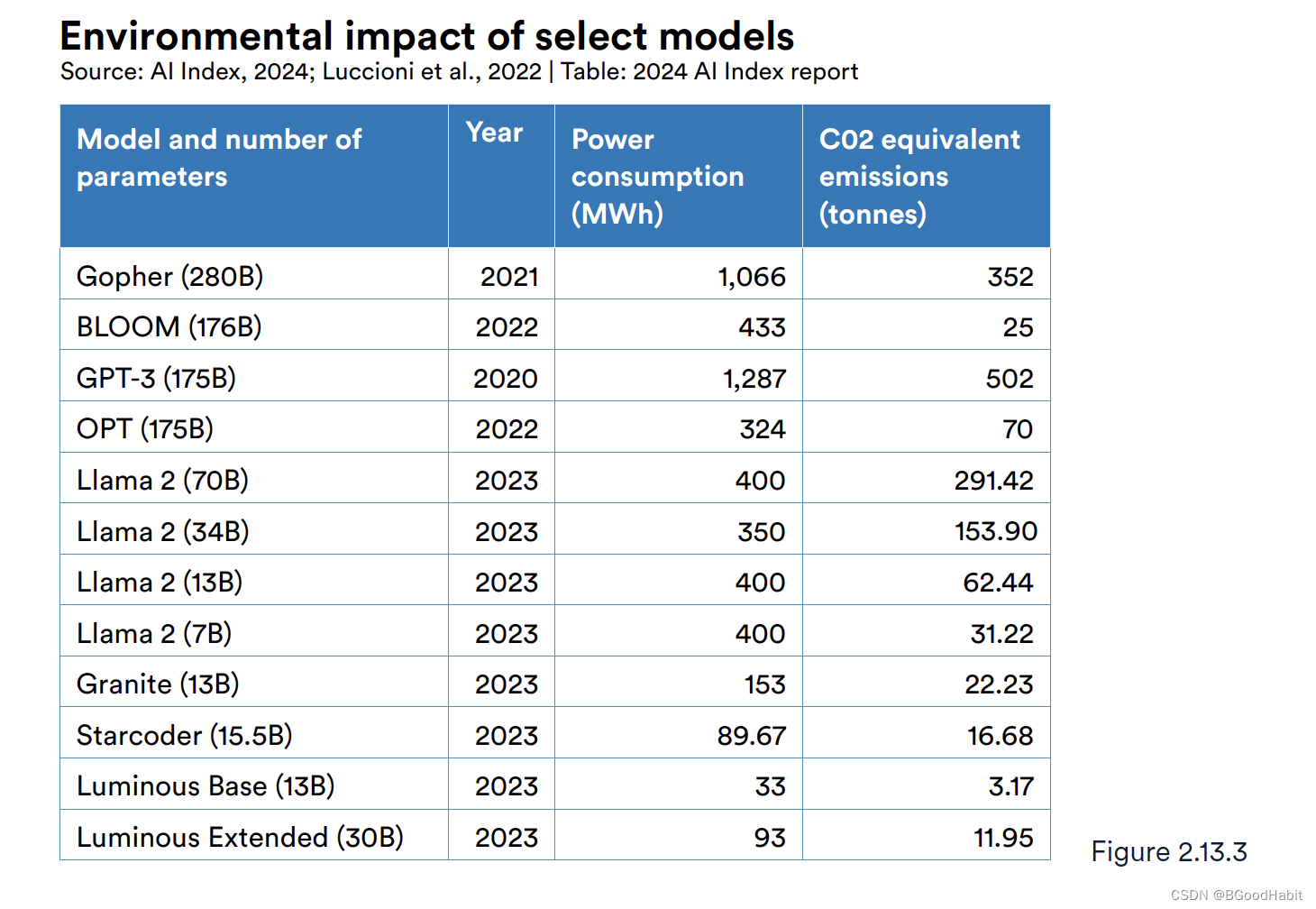
虽然训练大模型需要很大的资源消耗,排放大量的二氧化碳,但是使用大模型也有些对环境有利的方面:
比如可以用AI系统预测城市空气质量,可以用来优化空调的能力使用等。
4 AI可靠性
AI现在在我们的生活已经广泛应用,例如:教育,医疗,金融等。但是这也带来潜在的风险,所以需要更加关注评估AI系统的影响以及带来的风险。而评估AI的可靠性主要从四个方面评估:隐私与数据治理, 透明性和可解释性,安全性和公平性。核心结论如下:
- 对LLM可靠性进行全面标准的评估还存在很大的缺陷。
- 政治伪造很容易产生却很难检测:现在AI可以很容易生成一些虚假的内容并且散播,这对世界各国的政治选举都会产生影响。
- ChatGPT有政治上的偏见:研究者发现,ChatGPT在对美国民主党以及英国工党选举上存在很大的偏见。
4.1 AI可靠性定义
可靠性从四个维度定义如下所示:
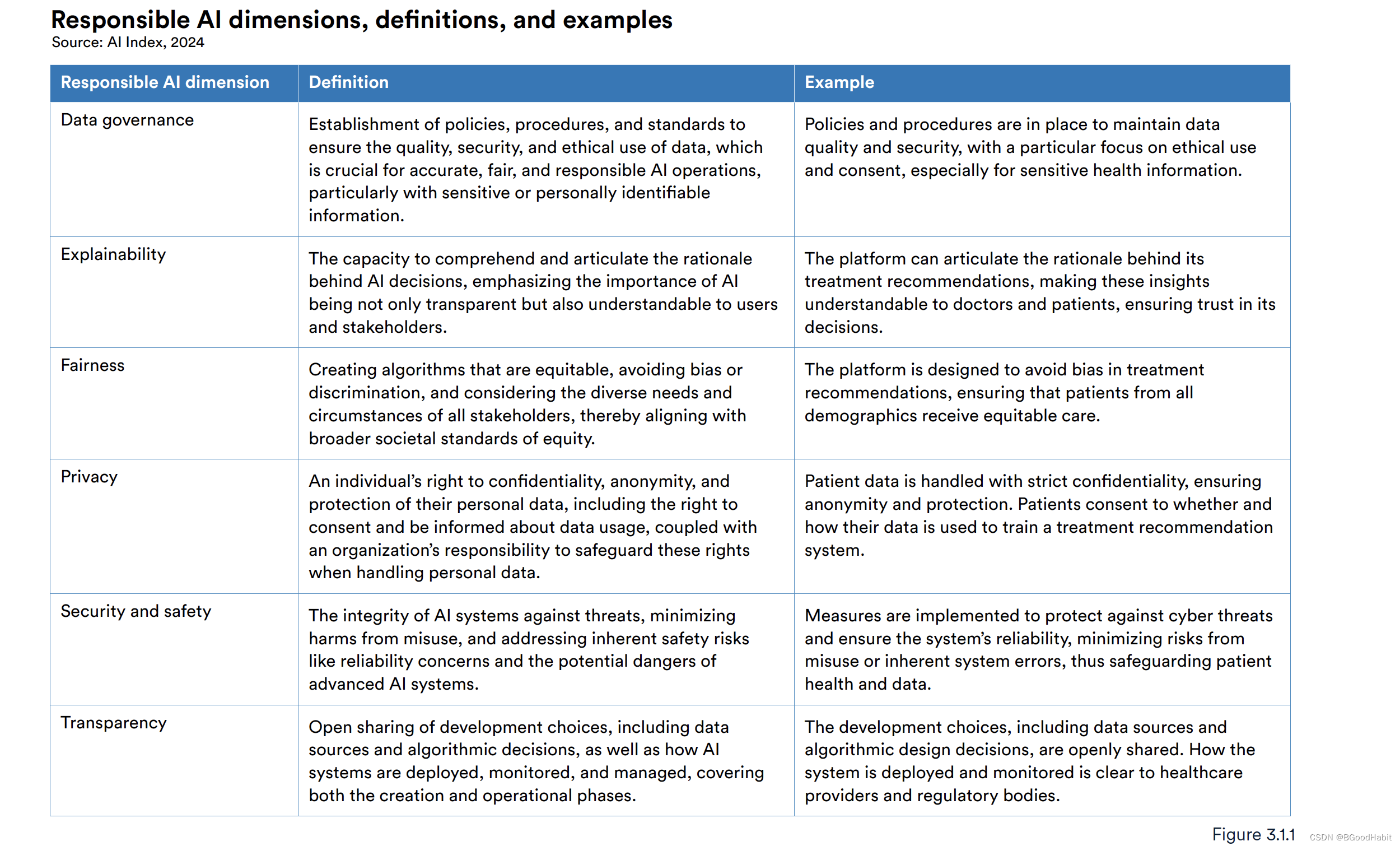
从上面多个维度信息去评估AI的可靠性:
- 数据治理(Data governance): 需要定义政策,标准等确保使用的数据质量,安全。这对于准确,公平,AI可靠性来时尤其重要
- 可解释性(Explainability): 能够理解并且明确清楚AI决策,AI的重要性不仅体现透明性还需要用户能够理解背后的决策。
- 公平性(Fairness):创建一个公平,避免偏见的算法是很重要的,因此需要对齐社会广泛的公平性的标准。
- 隐私(Privacy): 对个人用户数据的保护,匿名等也是十分重要的,特别是一些涉及病人病历数据需要对自己隐私保护
- 安全性(Security and safety): AI系统需要反对威胁,减少危害,加强系统的稳定。
- 透明性(Transparency): 公开算法的决策,特别是在AI医疗系统里,AI系统做的决策和监测对用户来说十分重要。
5 AI对经济的影响
预测AI将提高整个经济生产效率,但是某种程度上还存在一些未知的问题。其中最关注的一个问题是大量的工作是否会被AI取代,而且取代到什么程度?一些公司早已将AI通过各种方式应用到各行各业。在世界上的一些地方对这项具有改革能力的技术涌现了大量的投资。本章通过来自Lightcast, LinkedIn, Quid, McKinsey, Stack Overflow以及the International Federation of Robotics (IFR)的数据分析了与AI相关的职业,覆盖的工作需求,招聘趋势以及人才的供给。并且评估当前的AI的使用以及开发人员应该怎样采用这些技术。本章的核心重点提炼如下:
- 对生成式AI的投资增长飞速:从2022年,在AI这块的投资增长近8倍,达到了252亿美金。
- 在美国以及全世界各地,AI相关的工作在减少:在2022年,AI相关的职位大概占比所有岗位的2%,而数据统计在2023年,这个占比降低到1.6%。在AI相关工作的降低主要归因于核心AI公司提供更少的技术岗位。
- AI降低了企业支出提升了收益:在McKinsey调查中揭露,有42%企业报道说通过实施AI降低了企业支出,有59%企业说提升了收益。
- 对AI投资在下降,但是新成立的AI公司在增加:整体全球人工智能在私人投资上是下降了,但是新成立的AI公司增加到了1812家,比先前年增加了42%。
- 中国主导工业机器人领域:在2013年,中国超越日本,成为世界上最大工业机器设备主导者。而在2013年,中国的安装量占全球总量的20.8%,到2022年这一比例上升到了52.4%。
- AI让工作者更加高产能并且提高了工作效率:调查显示,使用AI能够让工作者更快地完成任务,并且提高工作效率。AI可能会打破高技能和低技能工作者之间的技术差距。
- 《财富》500强公司开始大量讨论人工智能,特别是生成式人工智能:
2023年,AI在394次财报电话会议中被提及(几乎占据了所有《财富》500强公司的80%),较2022年的266次提及有显著增加。
5.1 AI重大新闻
| 时间 | 新闻 |
|---|---|
| 2023.1.10 | BioNTech (一家生物公司,因发明新冠疫苗而出名)用6.8亿美金收购了一家AI新兴创业公司InstaDeep,用来加大AI驱动的药物发现,研发等 |
| 2023.1.23 | 微软花费100亿美金投资创建ChatGPT人工智能公司OpenAI |
| 2023.2.14 | Githup Copilot一款集成了OpenAI的Codex模型用来提升代码质量的商用软件开放 |
| 2023.3.7 | Einstein GPT第一个全面管理用户关系的AI系统,通过使用OpenAI模型,CRM系统能够更好的服务用户,管理用户 |
| 2023.3.16 | 微软融合GPT-4的Copilot应用到office软件,提供AI协助在Word, PowerPoint和Excel |
| 2023.3.30 | Bloomberg美国财经咨询公司彭博将一个50B参数的LLM用来进行金融数据分析,模型能够基于Bloomberg数据库的数据进行金融数据分析 |
| 2023.5.23 | Adobe发布了生成式AI工具嵌入到Photoshop |
| 2023.6.8 | Cohere一家专做企业生态AI公司,融资2.7亿美元 |
| 2023.6.13 | Nvidia市值达1万亿美金,主要来自AI驱动芯片的需求,这是Nvidia继苹果,Alphabet,微软,亚马逊成为第五个市值1万亿的估值公司 |
| 2023.6.26 | Databricks一家领先的数据存储和管理公司以13亿美金收购一家新兴的AI公司MosaicML,用来加强生成式AI能力 |
| 2023.8.24 | Hugging Face一家致力于机器学习和数据科学的平台公司募集到2.35亿美金的投资,市值估值上升到45亿美金 |
| 2023.9.27 | 亚马逊对OpenAI的竞争对手Anthropic公司投资40亿美金,google投资20亿美金 |
| 2023.11.5 | 李开复成立了开源的大模型LLM,并募集10亿美金 |
| 2023.12.11 | Mistral是一家欧洲AI公司,联合创始人有来自Google’s DeepMind以及Meta公司,聚焦基础开源大模型的研发,对标OpenAI公司。融资4亿美金 |
5.2 工作信息
以下是AI工作2014-2023这些年在整个工作市场的占比情况: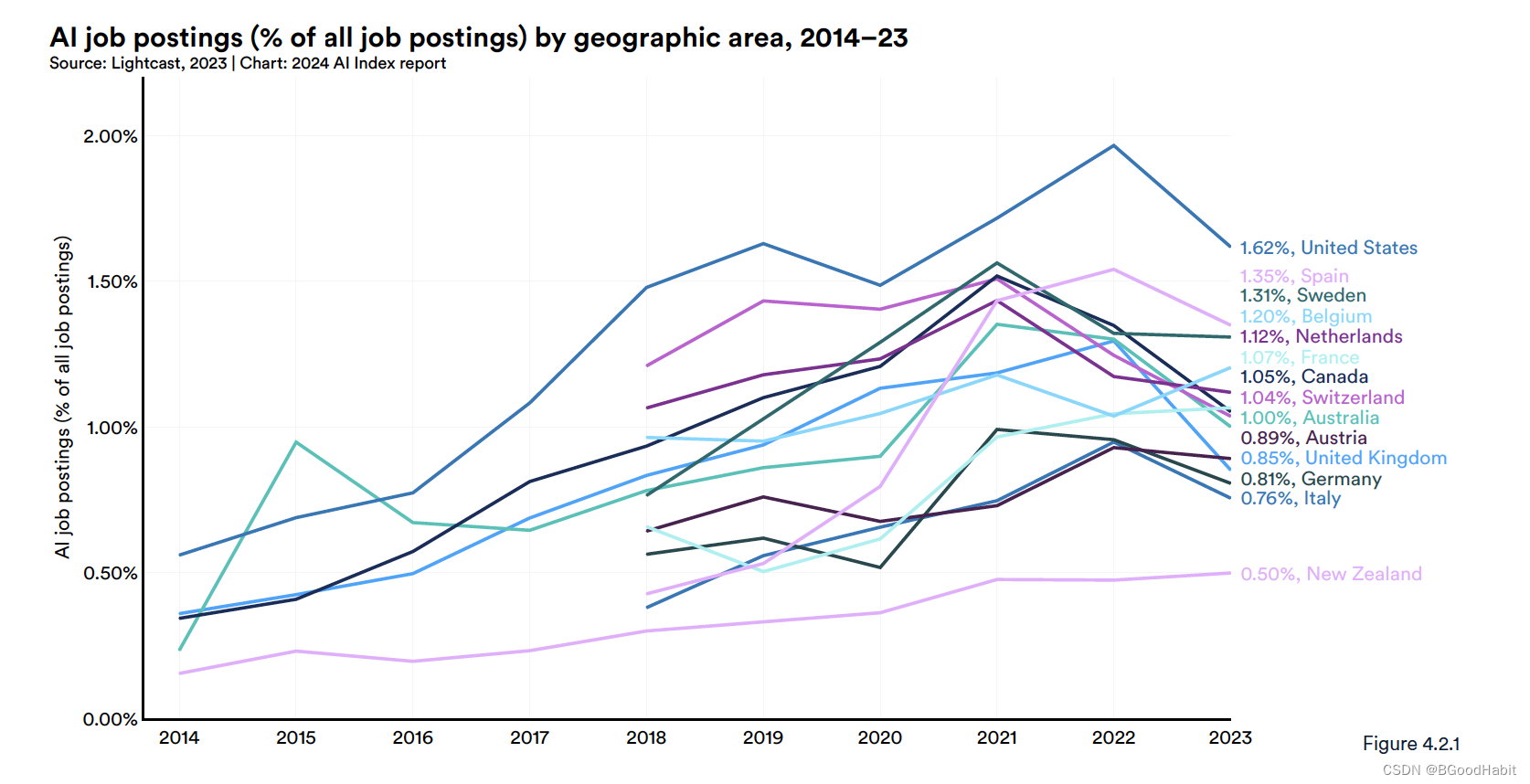
关于AI工作在美国top10的技能2023年前后的对比情况如下: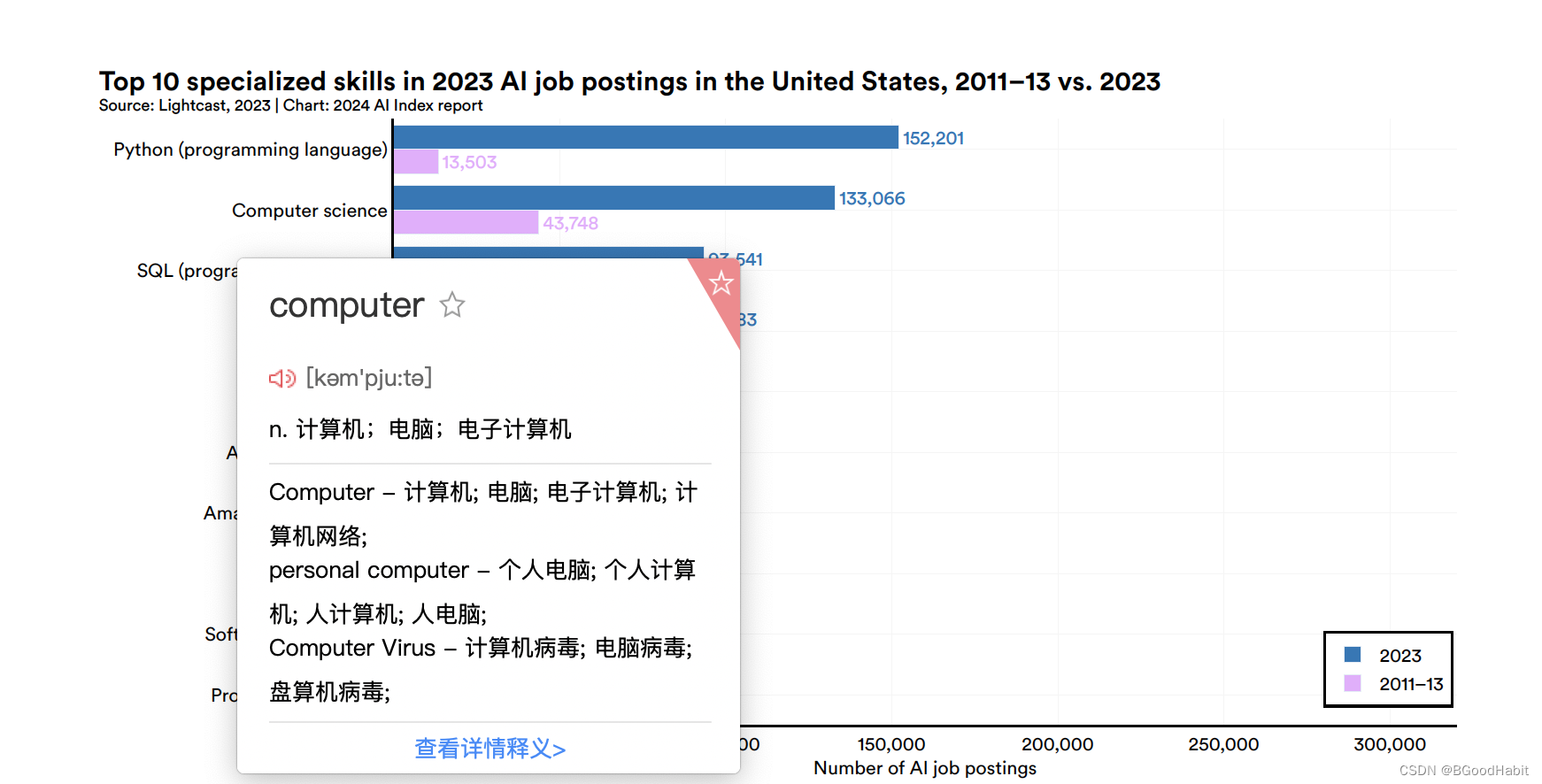
如下是一些地区关于AI职位招聘相对提升幅度: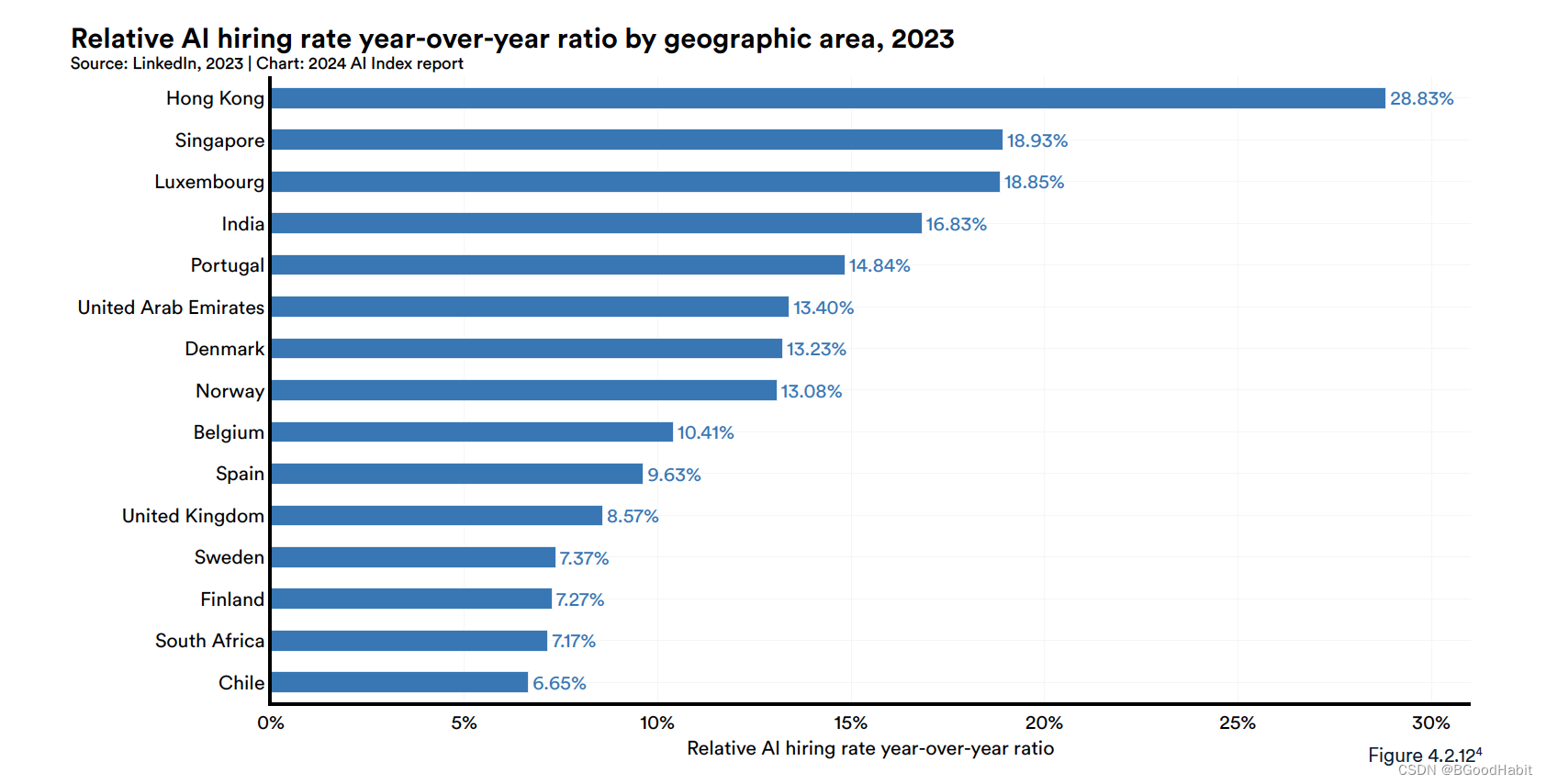
可以看出香港对AI人才的需求占比与多个国家对比整体是比较高的。如下是每个地区的具体每年对AI人才需求情况: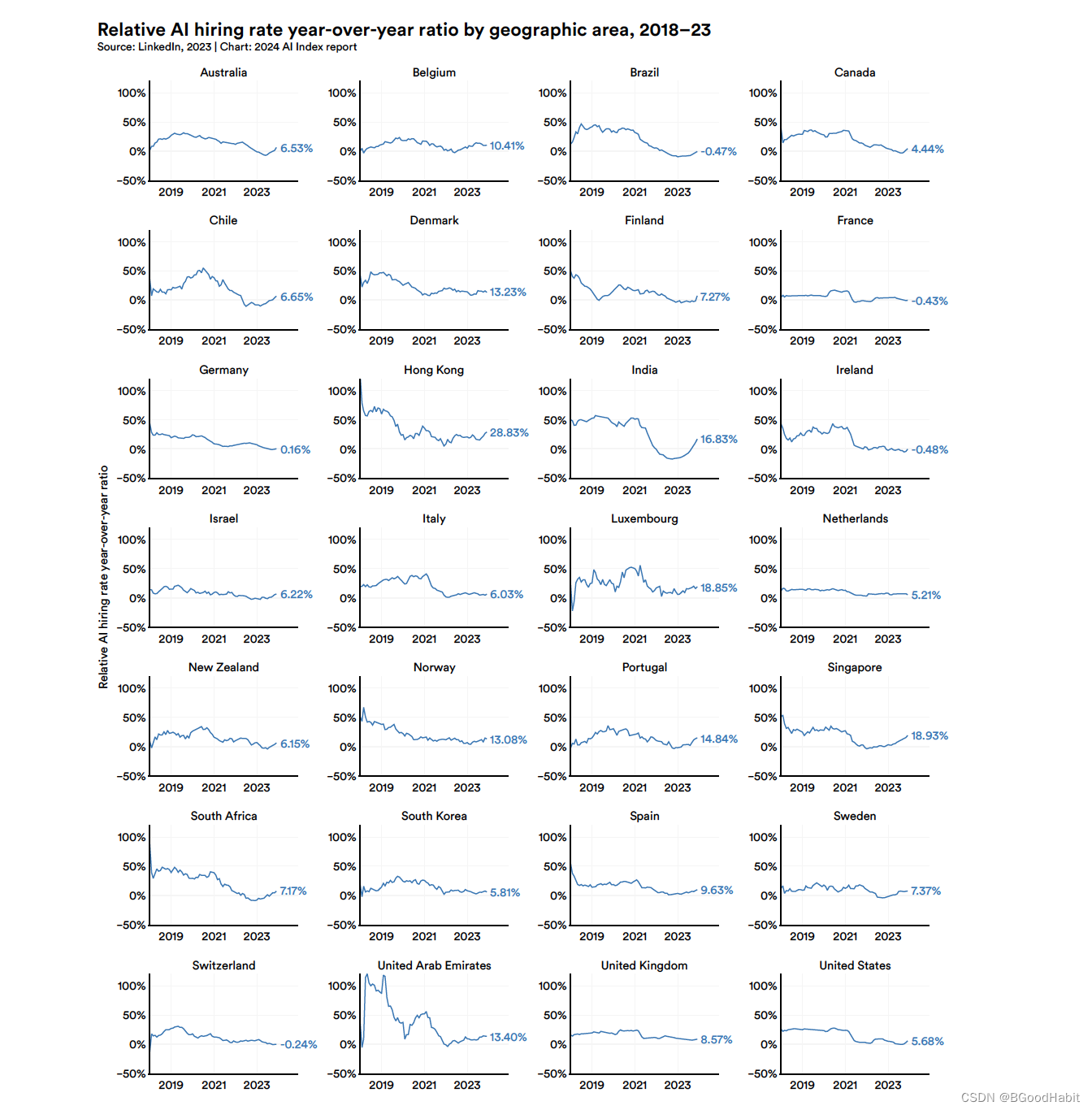
如下是全世界新兴成立的AI公司数量如下: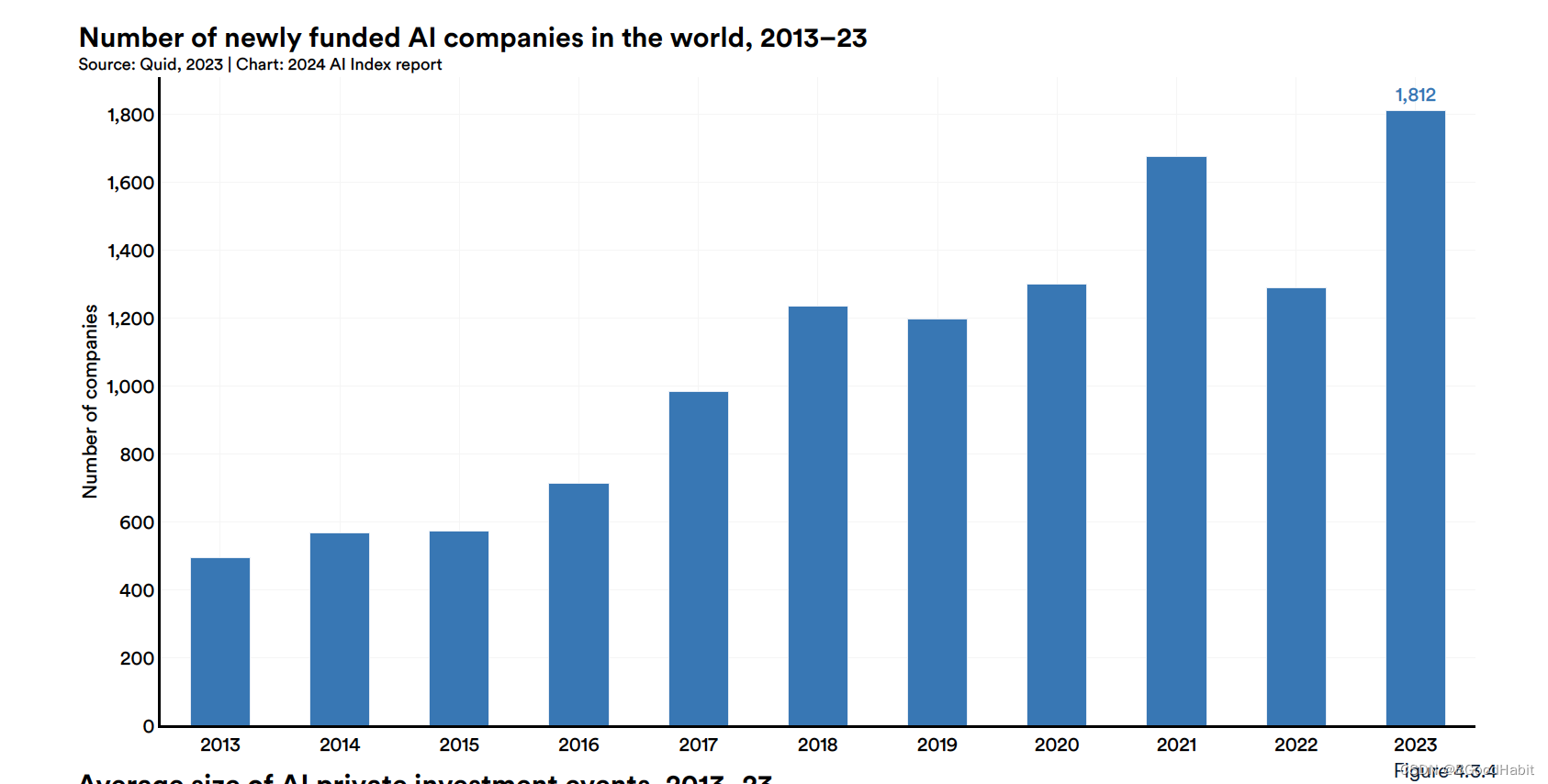
如下是2013年世界各地新成立的AI公司数量情况: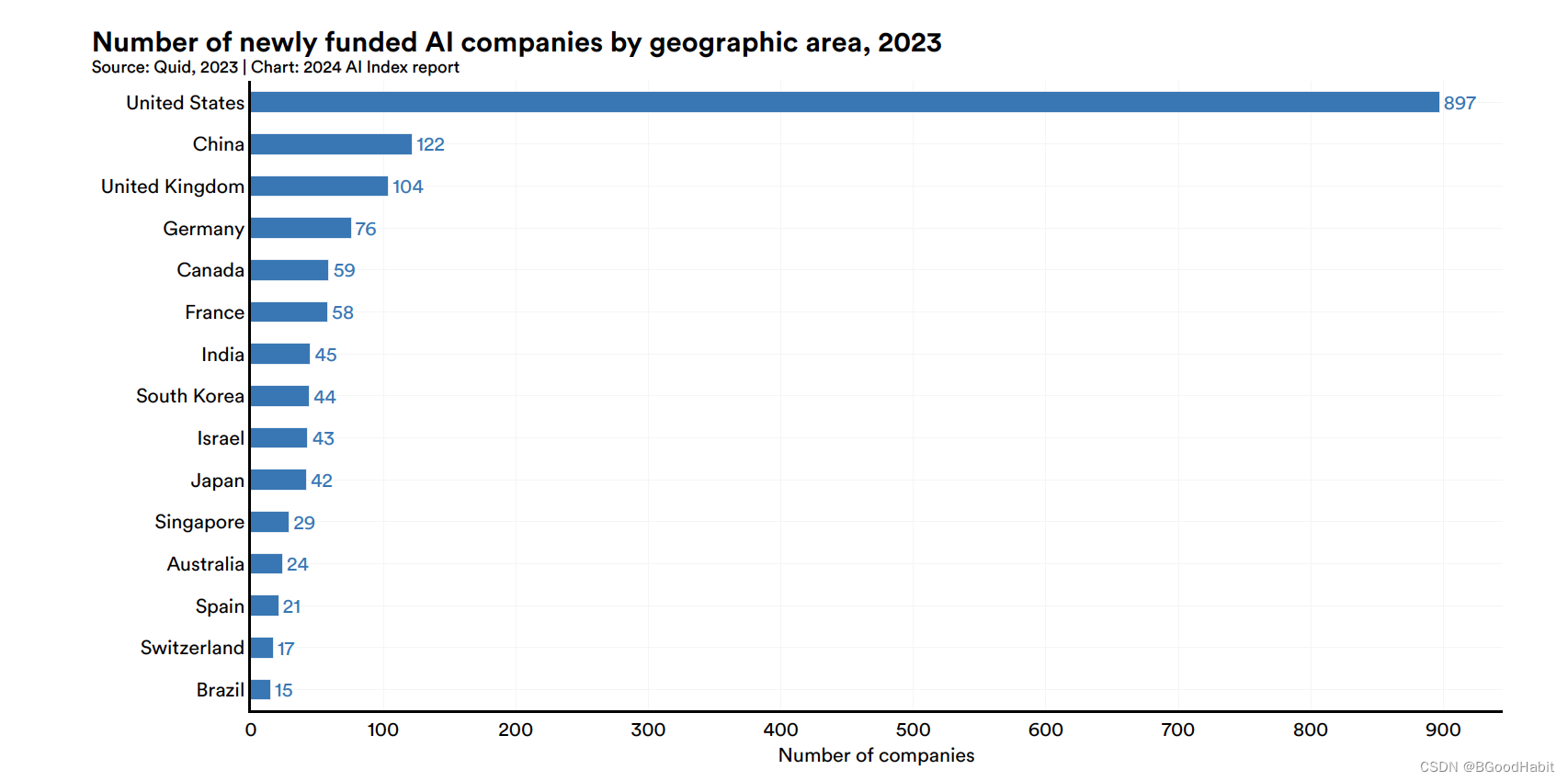
而2013-2023年总成立的AI公司数量情况如下: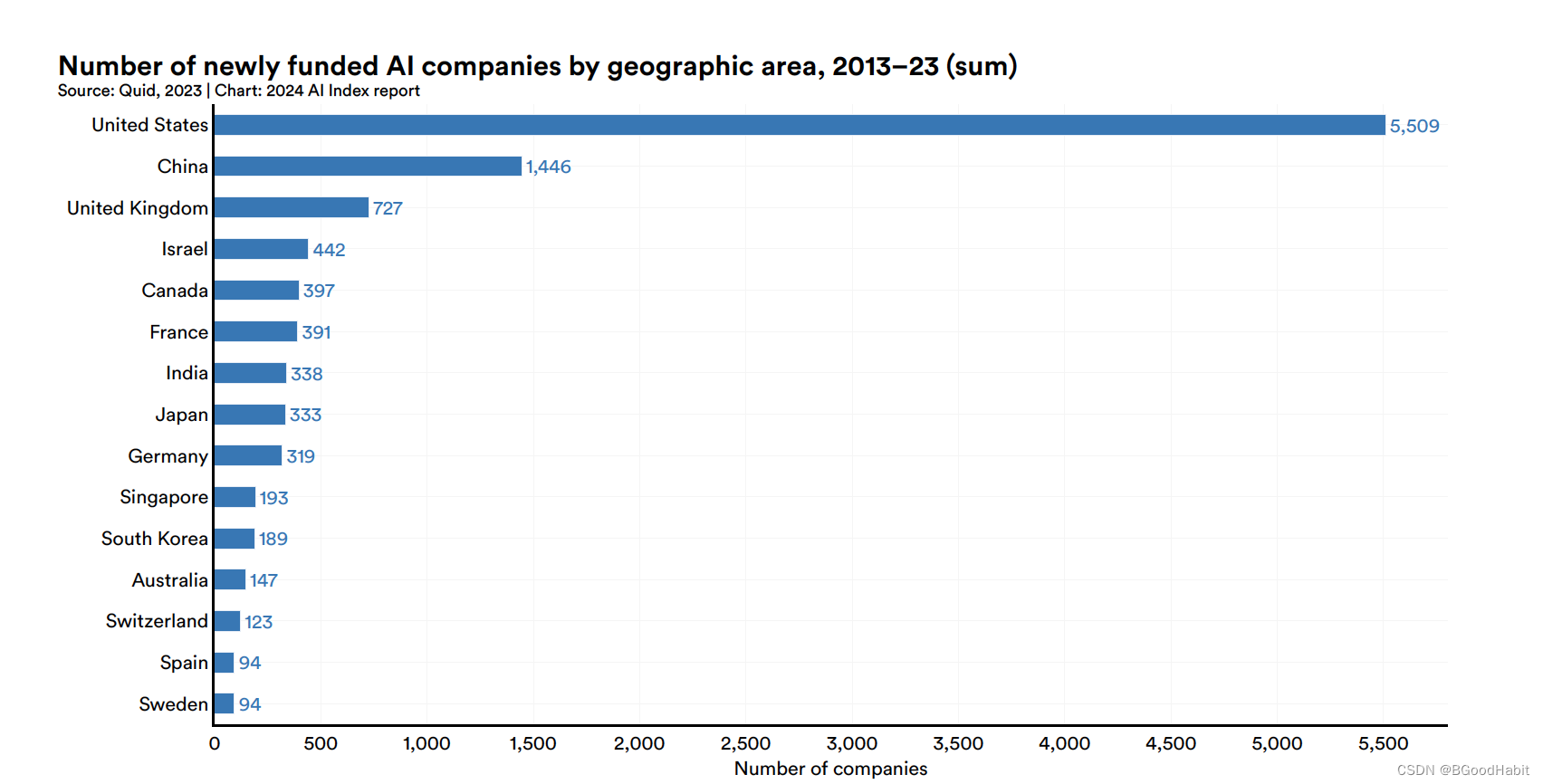
5.3 开发者对AI工具使用情况
如下是针对超过9万个开发者关于AI工具使用情况,其中GitHub Copilot使用量超过一半,使用AI工具对比占比情况如下: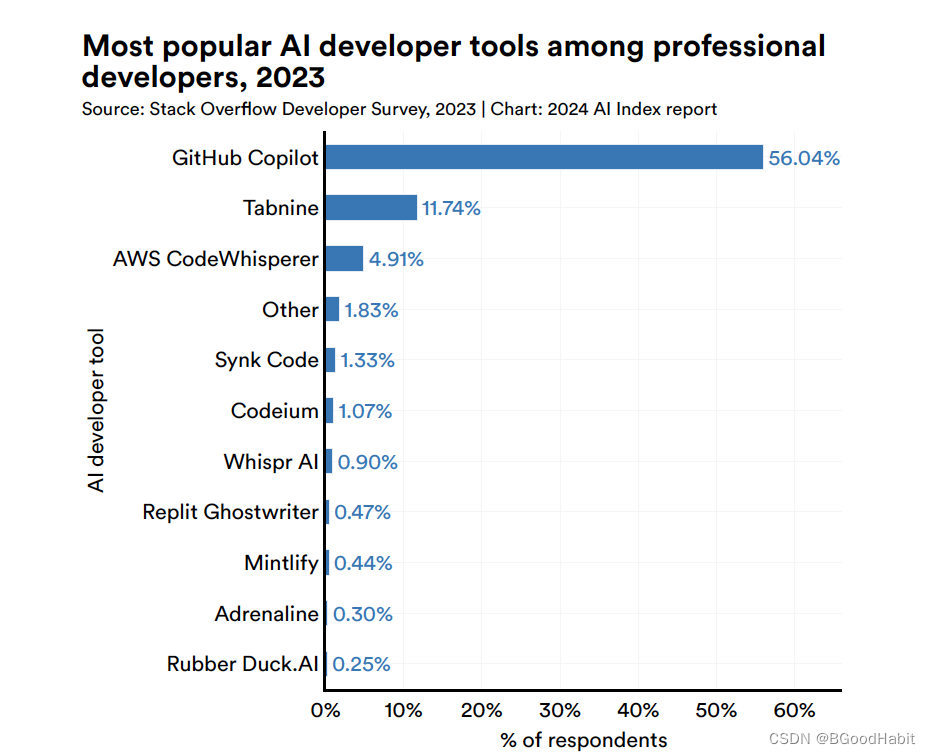
其中搜索AI工具ChatGPT使用最高,情况如下: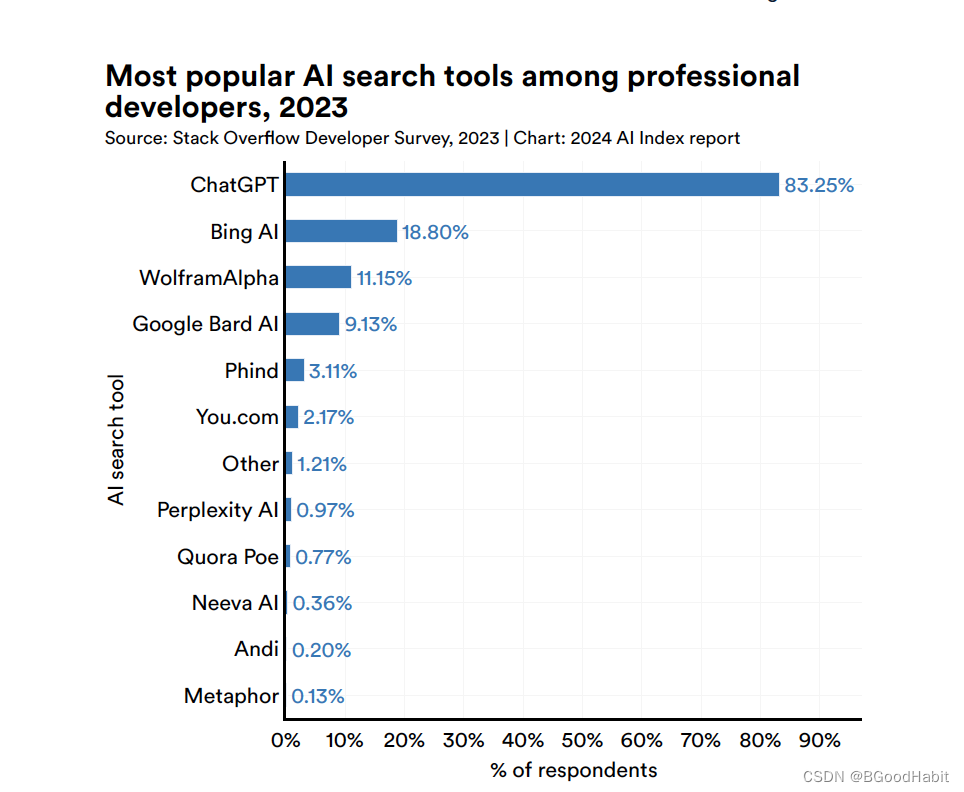
使用最多的top 10个云服务平台如下: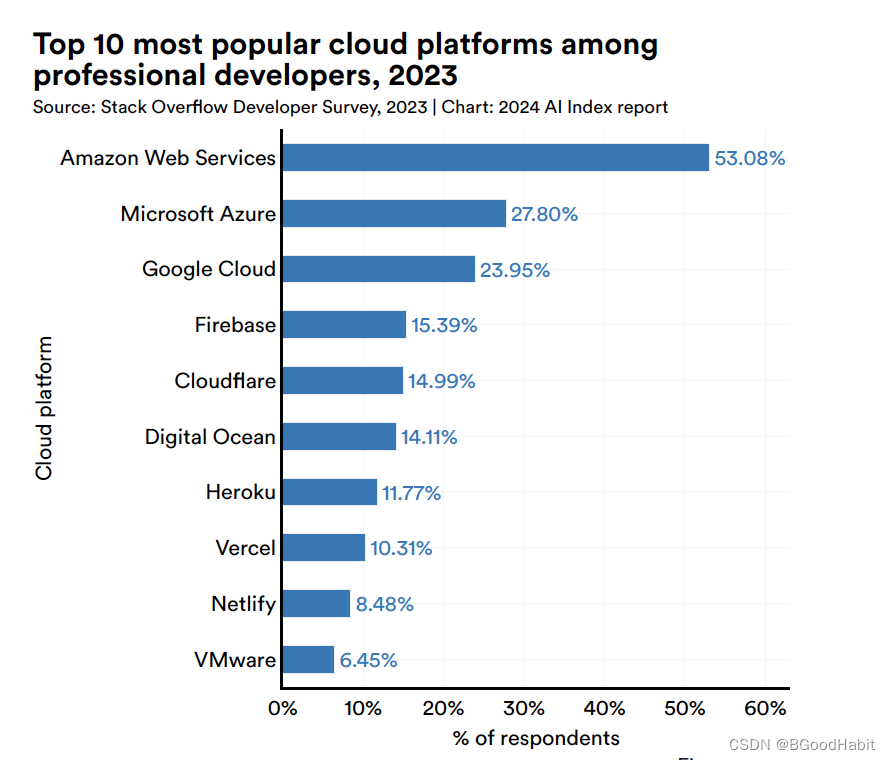
6 AI在医疗与教育的进展
本章的核心信息要点:
- AI加快了科技的进展:比如AlphaDev让算法排序更高效,GNoME加速了金属材料的发现
- AI 在医药领域又加快了一个新进程:在2023年,好几个重要的医疗系统发布,包括EVEscape,提高了大疾病的预测。以及AlphaMissence, 基于AI协助基因的分类。AI加强了医疗的进步。
- FDA批准了越来越多的AI相关的医疗设备:在2022年,FDA批准了139个AI相关的医疗设备,相比2021年提升了2.1%,AI已经在真实世界的医疗上应用。
- 国际上人工智能相关的学位课程正在迅速增加:自2017年以来,英语授课的人工智能相关高等教育课程数量已经增长了两倍。全球各地的大学都在提供更多以人工智能为重点的学位课程
7 公众对AI的观点
- 来自世界各地的人更加关注AI的潜在影响,也变得更加紧张
- 西方国家对人工智能的情绪持续低迷,但正在逐渐改善
- 公众对人工智能的经济影响持悲观态度
- ChatGPT已经被广泛知道和使用
如下是不同国家对ChatGPT的态度: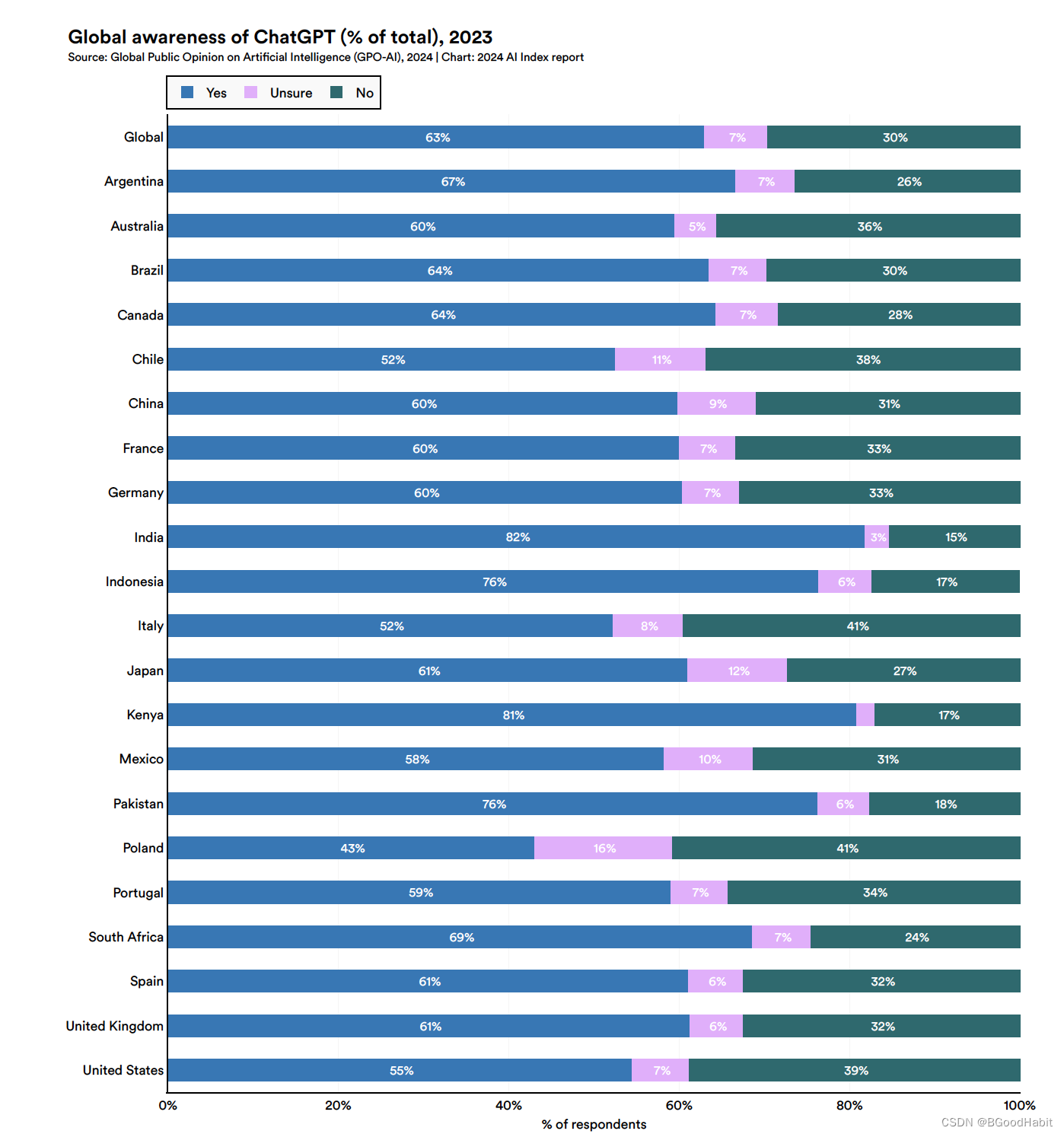
整体来看,所有国家基本都是持积极的态度。如下是对大模型发布后,吸引公众的一些注意力: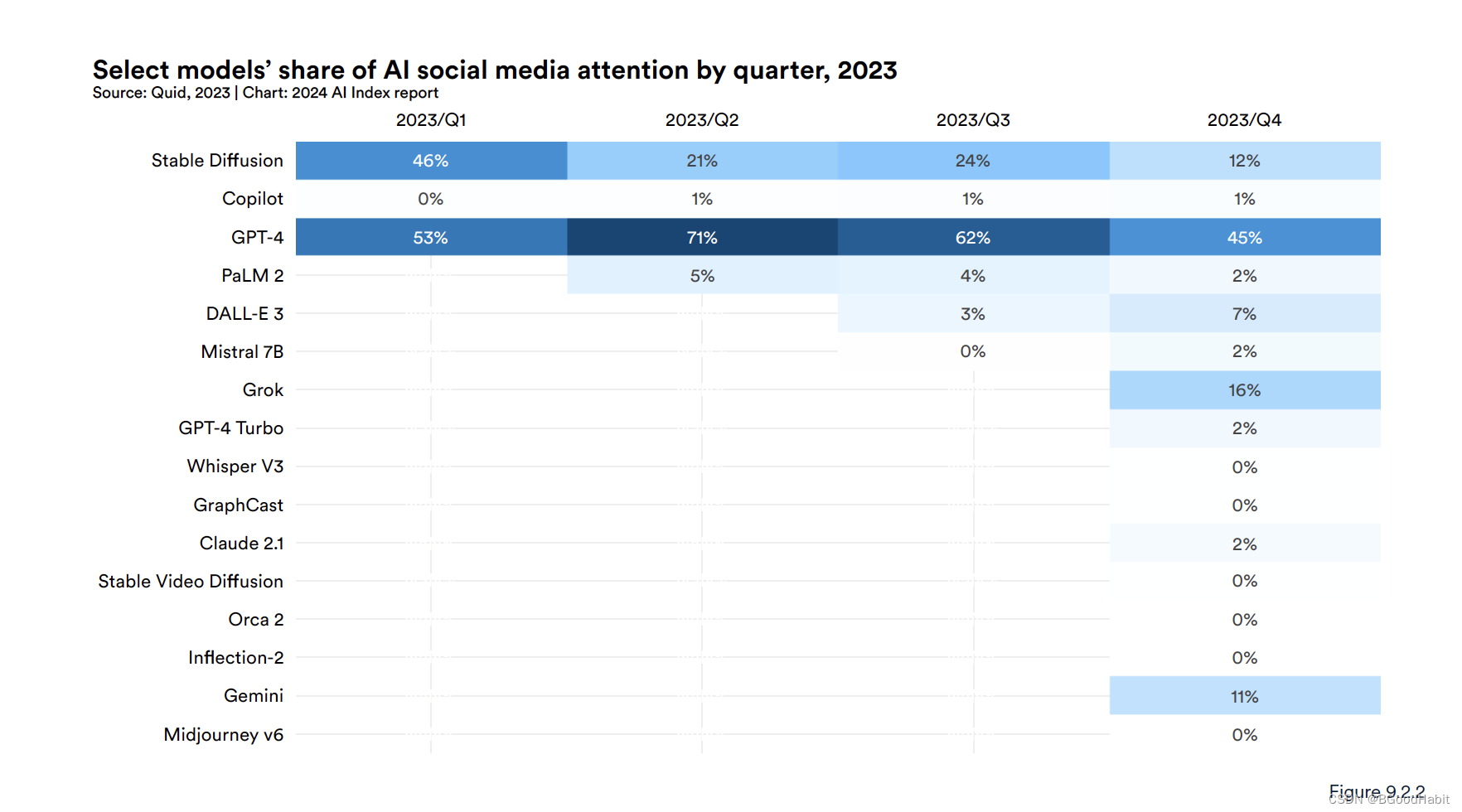
其中GPT-4还是占据公众注意力的主导。
