
阅读量:2
Spring AI概述
该Spring AI项目旨在简化包含人工智能功能的应用程序的开发,避免不必要的复杂性。
该项目从著名的 Python 项目(例如 LangChain 和 LlamaIndex)中汲取灵感,但 Spring AI 并非这些项目的直接移植。该项目的成立基于这样的信念:下一波生成式 AI 应用将不仅面向 Python 开发人员,还将遍及多种编程语言。
Spring AI 的核心是提供抽象,作为开发 AI 应用程序的基础。这些抽象具有多种实现,只需进行最少的代码更改即可轻松交换组件。
Spring AI 提供以下功能:
- 支持所有主要模型提供商,例如 OpenAI、Microsoft、Amazon、Google 和 Hugging Face。
- 支持的模型类型包括聊天、文本到图像、音频转录、文本到语音等。
- 适用于所有模型的跨 AI 提供商的可移植 API。支持同步和流式 API 选项。还支持下拉以访问特定于模型的功能。
- 将 AI 模型输出映射到 POJO。
- 支持所有主要的矢量数据库提供商,例如 Apache Cassandra、Azure Vector Search、Chroma、Milvus、Neo4j、Oracle、PostgreSQL/PGVector、PineCone、Qdrant、Redis 和 Weaviate。
- 跨 Vector Store 提供商的可移植 API,包括一种新颖的类似 SQL 的元数据过滤器 API,它也是可移植的。
- 函数调用。
- 用于 AI 模型和向量存储的 Spring Boot 自动配置和启动器。
- 数据工程的 ETL 框架。
人工智能概念
本节介绍 Spring AI 使用的核心概念。
模型
AI 模型是用于处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强各行各业的各种应用。
人工智能模型有很多种,每种模型都适用于特定的用例。虽然 ChatGPT 及其生成式人工智能功能通过文本输入和输出吸引了用户,但许多模型和公司都提供多样化的输入和输出。在 ChatGPT 之前,许多人对文本到图像的生成模型着迷,例如 Midjourney 和 Stable Diffusion。
下表根据输入和输出类型对几种模型进行了分类:
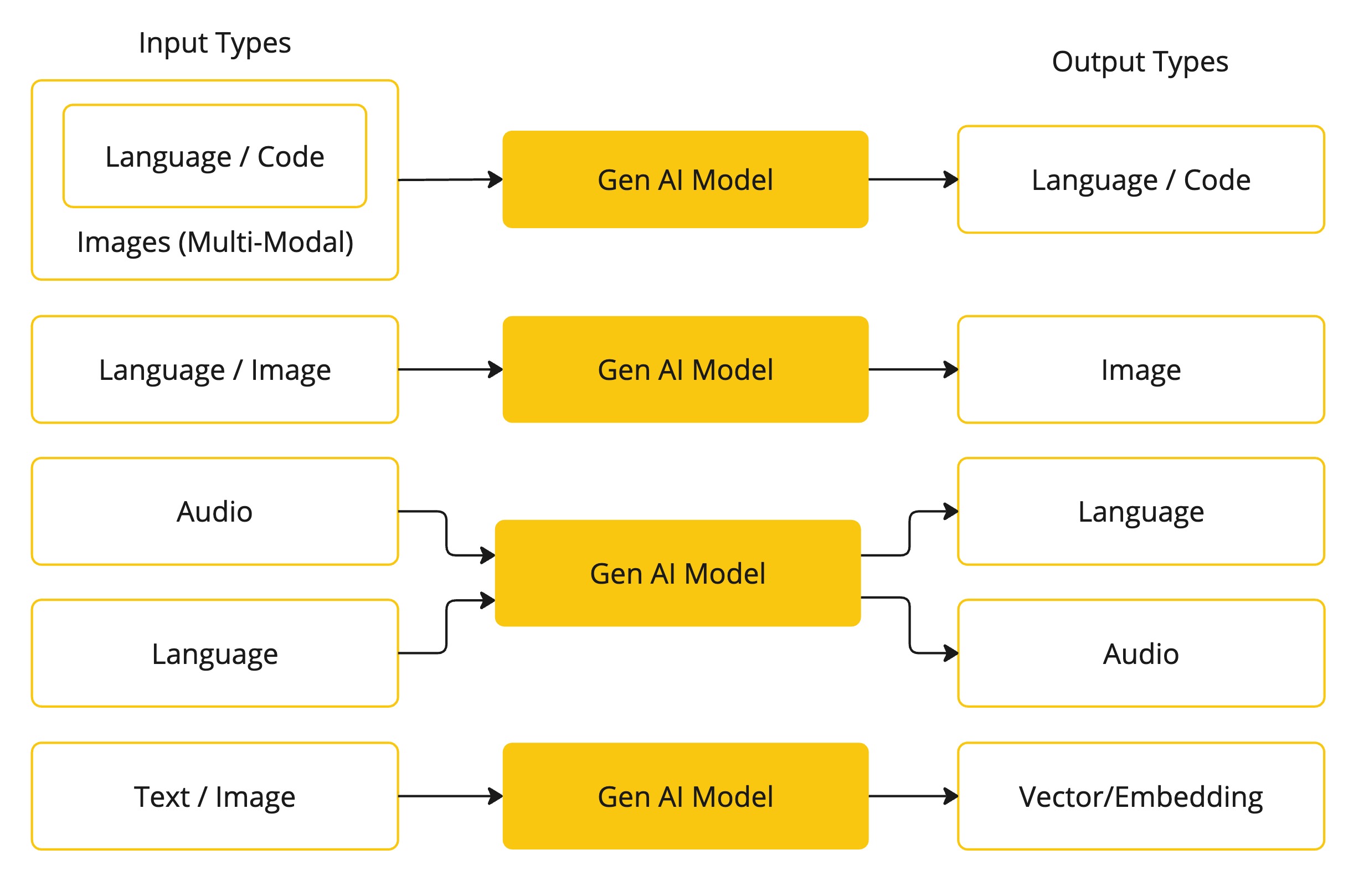
Spring AI 目前支持以语言、图像和音频形式处理输入和输出的模型。上表中的最后一行接受文本作为输入并输出数字,通常称为嵌入文本,表示 AI 模型中使用的内部数据结构。Spring AI 支持嵌入以支持更高级的用例。
GPT 等模型的独特之处在于其预训练特性,正如 GPT 中的“P”所示——Chat Generative Pre-trained Transformer。这种预训练功能将 AI 转变为通用的开发工具,不需要广泛的机器学习或模型训练背景。
提示词
提示词基于语言的输入的基础,可指导 AI 模型产生特定输出。对于熟悉 ChatGPT 的人来说,提示词可能看起来只是输入到对话框中并发送到 API 的文本。然而,它包含的内容远不止这些。在许多 AI 模型中,提示词的文本不仅仅是一个简单的字符串。
ChatGPT 的 API 在一个提示词中有多个文本输入,每个文本输入都被分配一个角色。例如,系统角色会告诉模型如何表现并设置交互的上下文。还有用户角色,通常是来自用户的输入。
制作有效的提示词既是一门艺术,也是一门科学。ChatGPT 是为人类对话而设计的。这与使用 SQL 之类的东西来“‘提出问题’”有很大不同。人们必须像与另一个人交谈一样与人工智能模型进行交流。
这种互动方式如此重要,以至于“提示词工程”一词已经发展成为一门学科。有越来越多的技术可以提高提示词的有效性。花时间制作提示词可以大大改善最终的输出。
分享提示词已成为一种公共实践,学术界也正在积极研究这一主题。作为创建有效提示词(例如,与 SQL 形成对比)是多么违反直觉的一个例子,最近的一篇研究论文发现,您可以使用的最有效的提示词之一以“深呼吸,一步一步地进行操作”这句话开头。这应该能让您明白为什么语言如此重要。我们尚未完全了解如何最有效地利用该技术的先前版本,例如 ChatGPT 3.5,更不用说正在开发的新版本了。
提示词模板
创建有效的提示词包括建立请求的上下文并用特定于用户输入的值替换请求的各部分。
此过程使用传统的基于文本的模板引擎来快速创建和管理。Spring AI为此使用了 OSS 库StringTemplate 。
例如,考虑简单的提示词模板:
Tell me a {adjective} joke about {content}. 在 Spring AI 中,提示词模板可以比作 Spring MVC 架构中的“视图”。java.util.Map提供一个模型对象(通常是),用于填充模板中的占位符。“rendered”字符串成为提供给 AI 模型的提示词内容。
发送给模型的提示词的具体数据格式存在相当大的差异。提示词最初只是简单的字符串,后来演变为包含多条消息,每条消息中的每个字符串都代表模型的不同角色。
嵌入
嵌入将文本转换为数值数组或向量,使 AI 模型能够处理和解释语言数据。从文本到数字的这种转换是 AI 与人类语言交互和理解的关键要素。
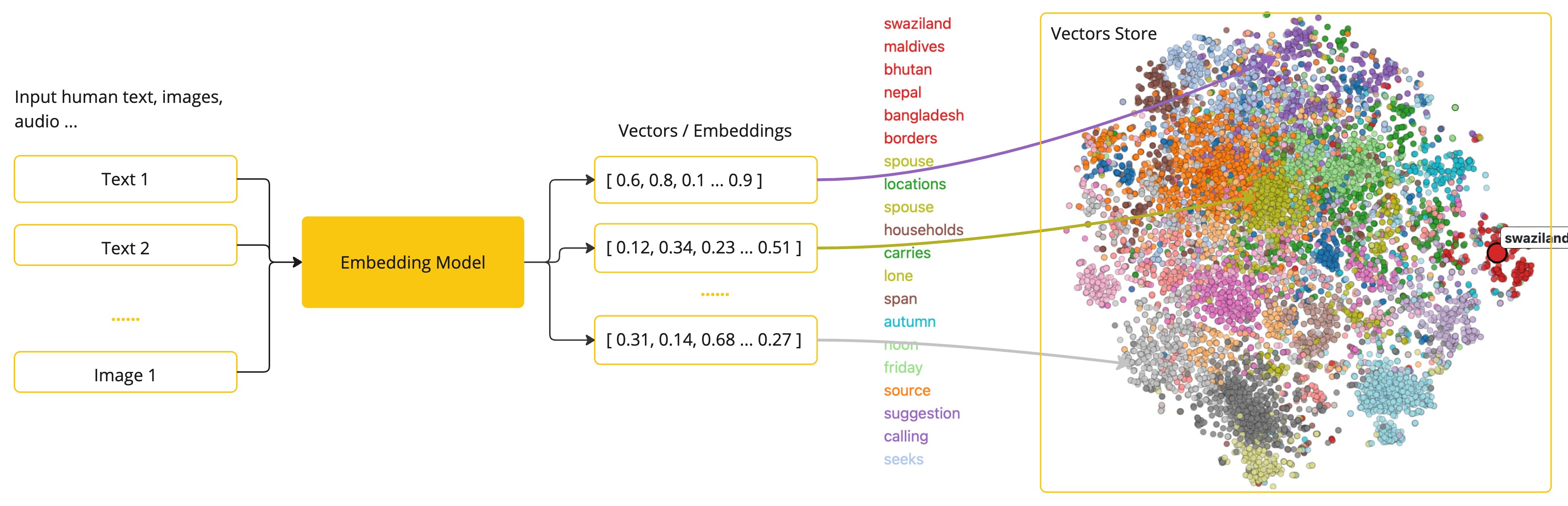
作为探索 AI 的 Java 开发人员,没有必要理解这些矢量表示背后的复杂数学理论或具体实现。对它们在 AI 系统中的作用和功能有基本的了解就足够了,特别是当您将 AI 功能集成到您的应用程序中时。
嵌入在实际应用中尤其重要,例如检索增强生成 (RAG) 模式。它们可以将数据表示为语义空间中的点,这类似于欧几里得几何的二维空间,但在更高的维度上。这意味着,就像欧几里得几何中平面上的点可以根据其坐标而接近或远离一样,在语义空间中,点的接近度反映了含义的相似性。关于相似主题的句子在这个多维空间中的位置更近,就像图上彼此靠近的点一样。这种接近度有助于文本分类、语义搜索甚至产品推荐等任务,因为它允许 AI 根据相关概念在这个扩展的语义景观中的“位置”来辨别和分组相关概念。
你可以把这个语义空间想象成一个向量。
Tokens
Tokens是 AI 模型工作原理的基石。输入时,模型将单词转换为Tokens。输出时,它们将Tokens转换回单词。
在英语中,一个 token 大约对应一个单词的 75%。作为参考,莎士比亚的全集总共约 90 万个单词,翻译过来大约有 120 万个 token。

也许更重要的是Tokens = 金钱。在托管 AI 模型的背景下,您的费用由使用的Tokens数量决定。输入和输出都会影响总Tokens数量。
此外,模型还受到 token 限制,这会限制单个 API 调用中处理的文本量。此阈值通常称为“上下文窗口”。模型不会处理超出此限制的任何文本。
例如,ChatGPT3 的Tokens限制为 4K,而 GPT4 则提供不同的选项,例如 8K、16K 和 32K。Anthropic 的 Claude AI 模型的Tokens限制为 100K,而 Meta 的最新研究则产生了 1M Tokens限制模型。
要使用 GPT4 总结莎士比亚全集,您需要制定软件工程策略来切分数据并在模型的上下文窗口限制内呈现数据。Spring AI 项目可以帮助您完成此任务。
模型输出
即使您要求回复为 JSON ,AI 模型的输出通常也会以 的形式出现java.lang.String。它可能是正确的 JSON,但它不是 JSON 数据结构。它只是一个字符串。此外,在提示词中询问“需要 JSON”并非 100% 准确。
这种复杂性导致了一个专门领域的出现,涉及创建提示词以产生预期的输出,然后将生成的简单字符串转换为可用于应用程序集成的数据结构。
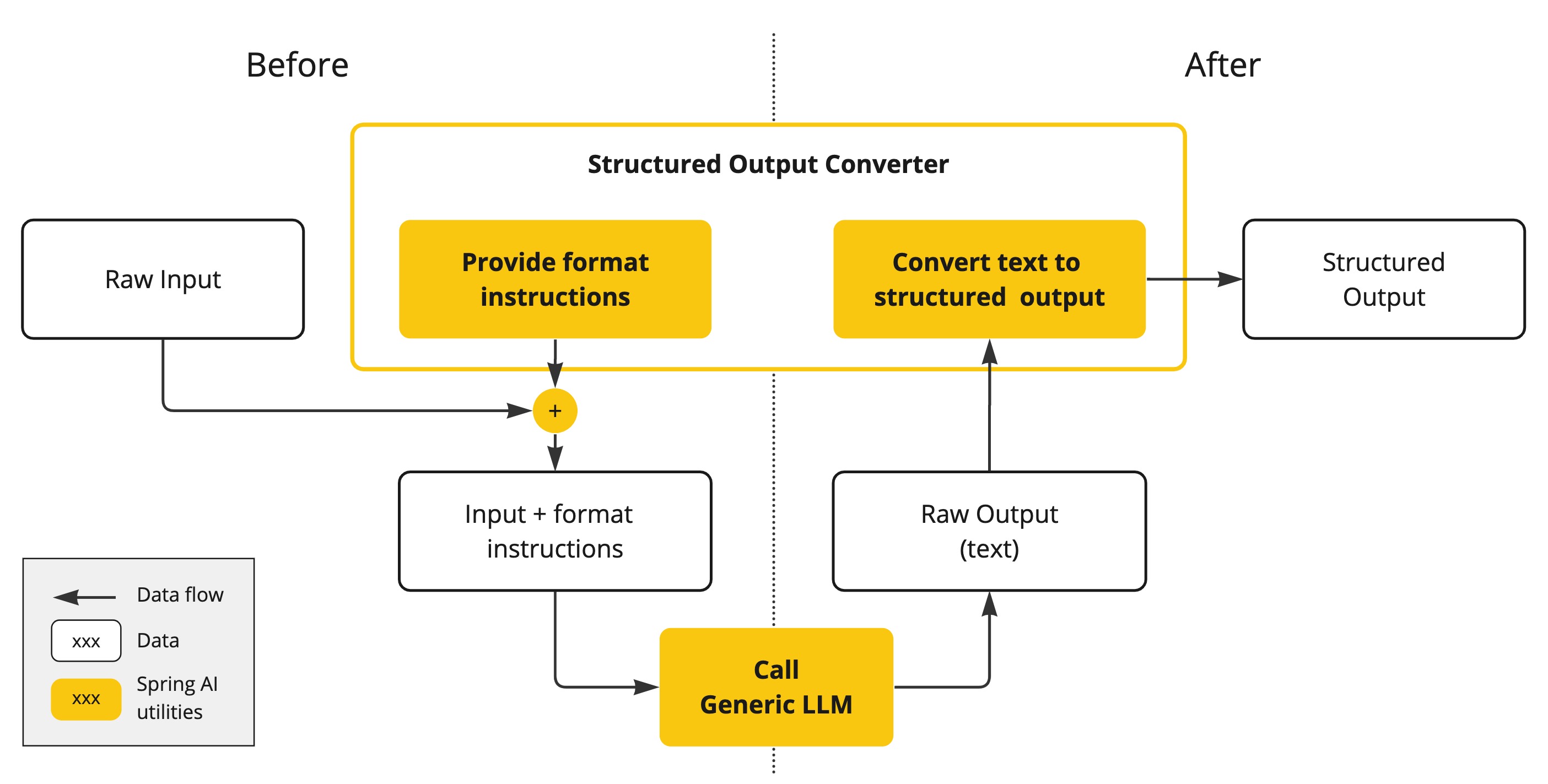
模型输出转换采用精心设计的提示词,通常需要与模型进行多次交互才能实现所需的格式。
将您的数据和 API 引入 AI 模型
如何为人工智能模型配备还未经过训练的信息?
请注意,GPT 3.5/4.0 数据集仅延续到 2021 年 9 月。因此,该模型表示它不知道需要该日期之后知识的问题的答案。一个有趣的小知识是,这个数据集大约有 650GB。
有三种技术可以定制 AI 模型以整合您的数据:
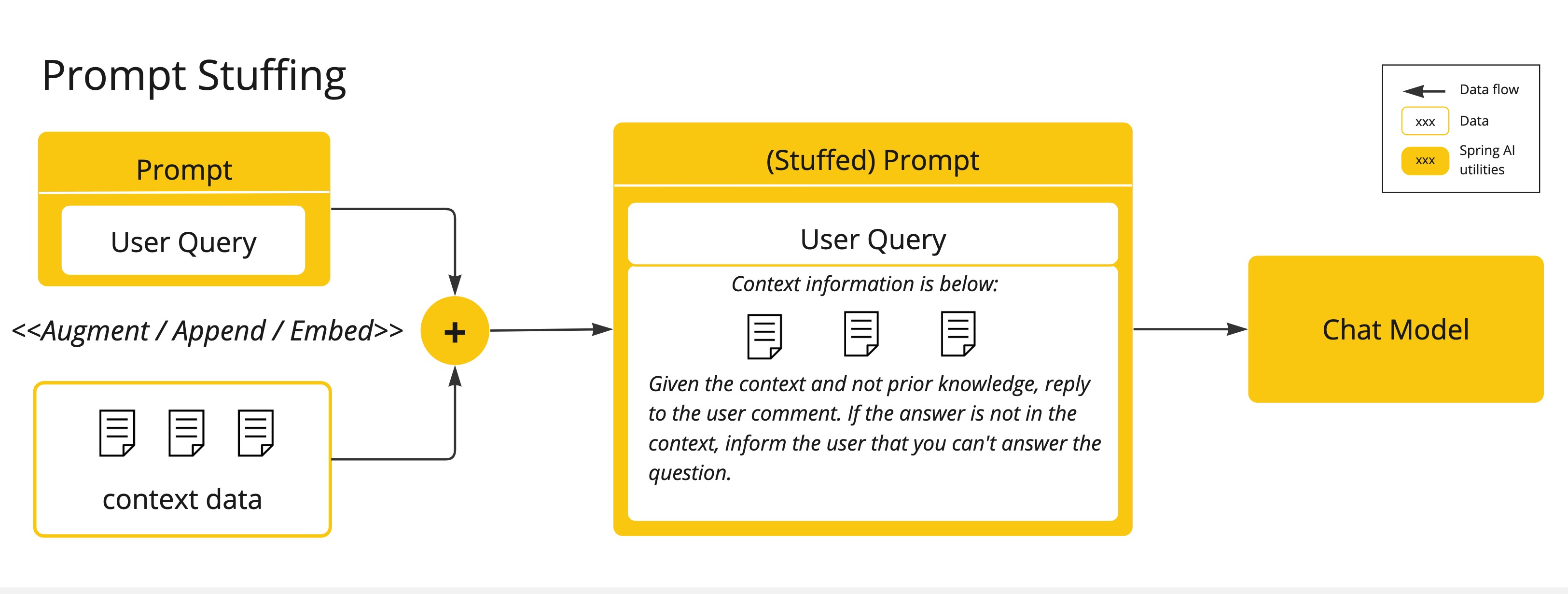
Fine Tuning:这种传统的机器学习技术涉及定制模型并更改其内部权重。然而,对于机器学习专家来说,这是一个具有挑战性的过程,而且由于 GPT 等模型的大小,它极其耗费资源。此外,有些模型可能不提供此选项。Prompt Stuffing:一种更实用的替代方案是将您的数据嵌入到提供给模型的提示词中。考虑到模型的令牌限制,需要使用技术在模型的上下文窗口中显示相关数据。这种方法俗称“填充提示词”。Spring AI 库可帮助您基于“填充提示词”技术(也称为检索增强生成 (RAG))实现解决方案。
检索增强生成
一种称为检索增强生成 (RAG) 的技术已经出现,旨在解决将相关数据纳入准确的 AI 模型响应提示词的挑战。
该方法涉及批处理样式的编程模型,其中作业从文档中读取非结构化数据,对其进行转换,然后将其写入矢量数据库。从高层次上讲,这是一个 ETL(提取、转换和加载)管道。矢量数据库用于 RAG 技术的检索部分。
在将非结构化数据加载到矢量数据库的过程中,最重要的转换之一是将原始文档拆分成较小的部分。将原始文档拆分成较小部分的过程有两个重要步骤:
- 将文档拆分成几部分,同时保留内容的语义边界。例如,对于包含段落和表格的文档,应避免在段落或表格中间拆分文档。对于代码,应避免在方法实现的中间拆分代码。
- 将文档的各部分进一步拆分成大小仅为 AI 模型令牌限制的一小部分的部分。
RAG 的下一个阶段是处理用户输入。当用户的问题需要由 AI 模型回答时,问题和所有“类似”的文档片段都会被放入发送给 AI 模型的提示词中。这就是使用矢量数据库的原因。它非常擅长查找类似内容。
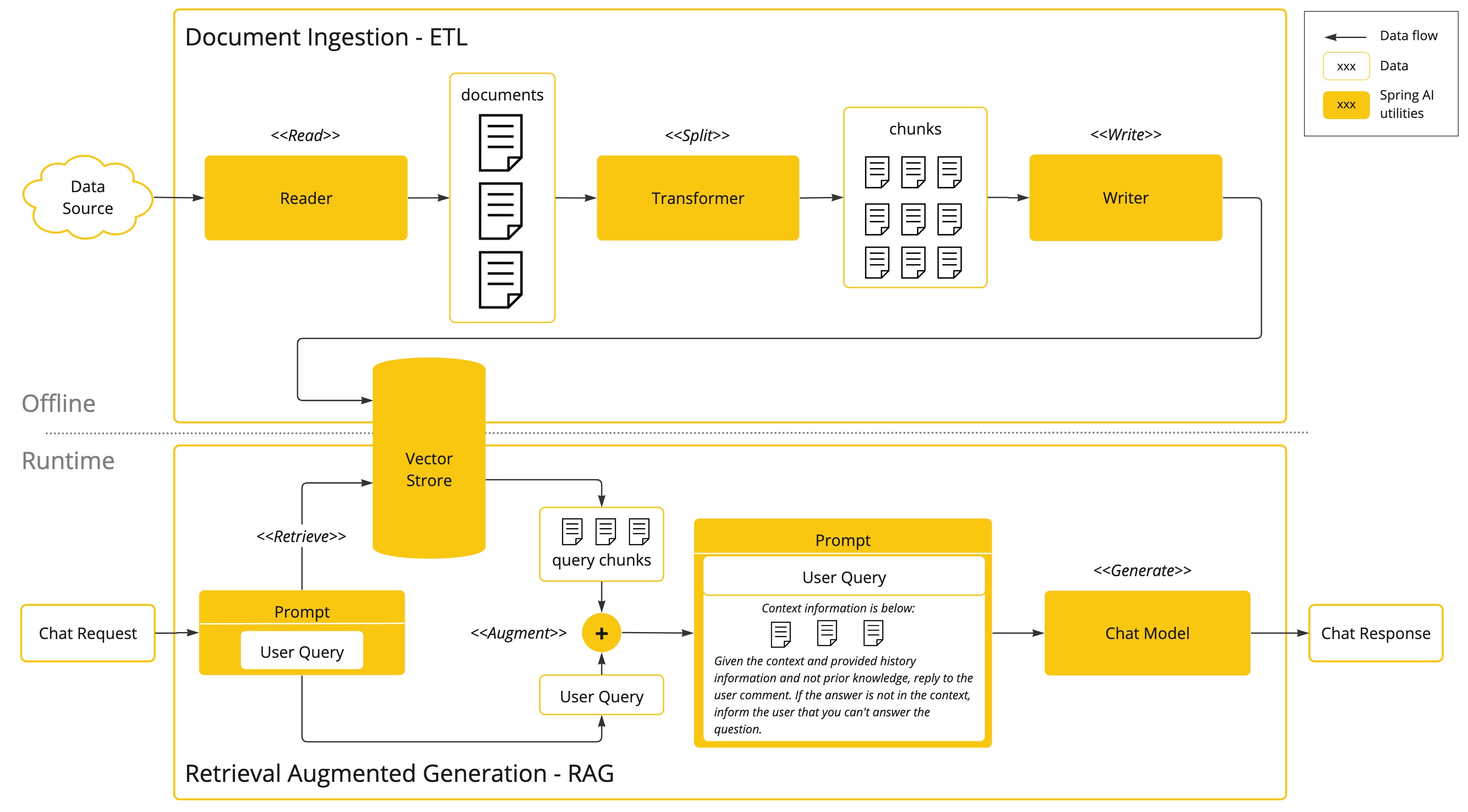
- ETL pipeline提供了有关协调从数据源提取数据并将其存储在结构化向量存储中的流程的更多信息,确保数据具有 AI 模型检索的最佳格式。
- ChatClient - RAG解释了如何使用
QuestionAnswerAdvisor顾问为您的应用程序启用 RAG 功能。
函数调用
大型语言模型 (LLM) 在训练后被冻结,导致知识陈旧,并且无法访问或修改外部数据。
函数调用机制解决了这些缺点。它允许您注册自己的函数,以将大型语言模型连接到外部系统的 API。这些系统可以为 LLM 提供实时数据并代表它们执行数据处理操作。
Spring AI 大大简化了您需要编写的代码以支持函数调用。它为您处理函数调用对话。您可以将函数作为提供,@Bean然后在提示词选项中提供该函数的 bean 名称以激活该函数。此外,您可以在单个提示词中定义和引用多个函数。
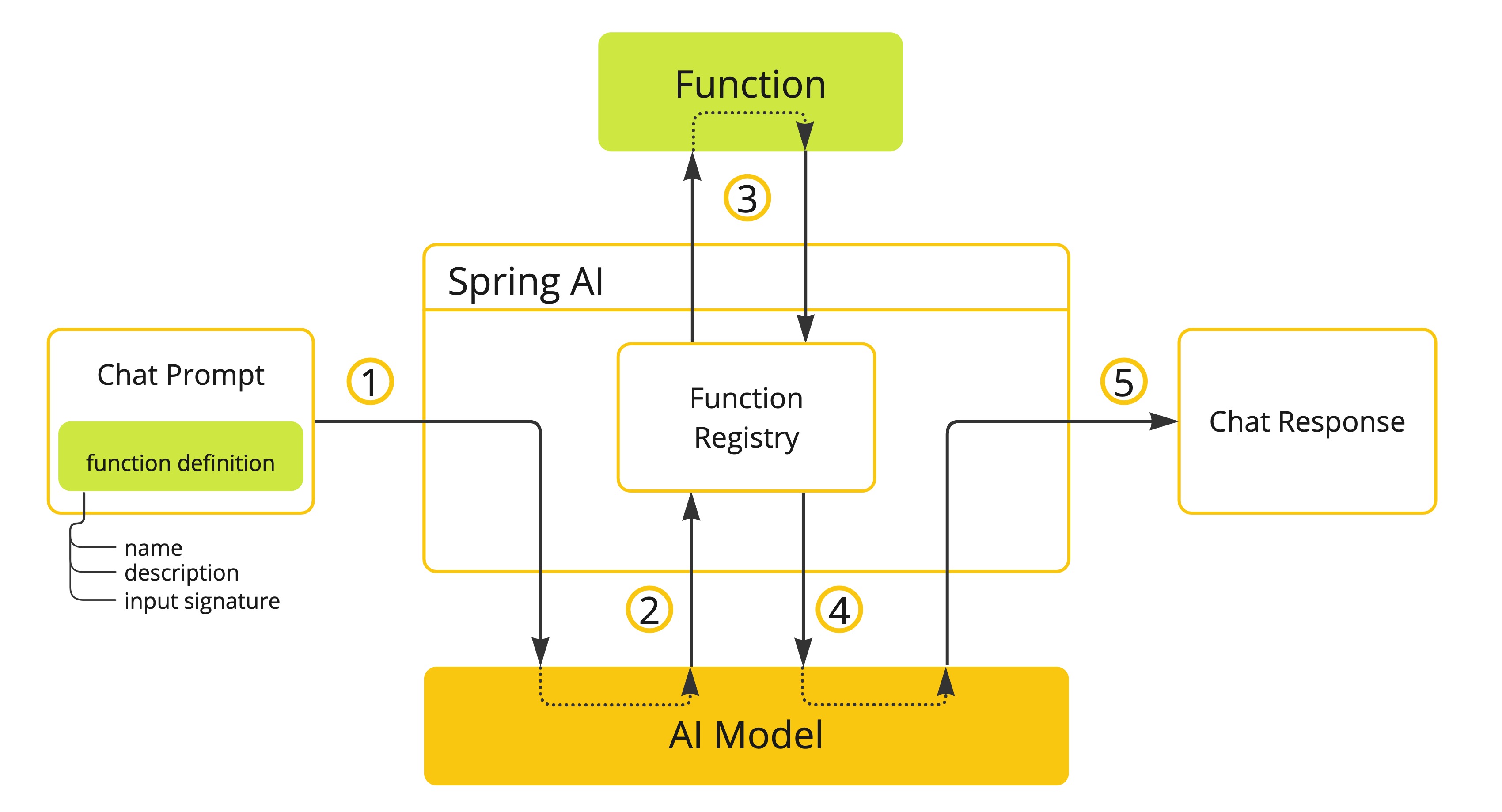
- (1)执行聊天请求以及函数定义信息。稍后提供
name(description例如,解释模型应何时调用该函数)和input parameters(例如,函数的输入参数模式)。 - (2)当模型决定调用该函数时,它将使用输入参数调用该函数,并将输出返回给模型。
- (3)Spring AI 为您处理此对话。它将函数调用分派给适当的函数,并将结果返回给模型(4)。模型可以执行多个函数调用来检索所需的所有信息。
- (5)一旦获取了所有需要的信息,模型就会生成响应。
请关注函数调用文档以获取有关如何在不同 AI 模型中使用此功能的更多信息。
AI响应评估
有效评估人工智能系统响应用户请求的输出对于确保最终应用程序的准确性和实用性非常重要。一些新兴技术使得预训练模型本身能够用于此目的。
此评估过程涉及分析生成的响应是否符合用户的意图和查询的上下文。相关性、连贯性和事实正确性等指标用于衡量 AI 生成的响应的质量。
一种方法是向模型呈现用户的请求和人工智能模型的响应,查询响应是否与提供的数据一致。
此外,利用矢量数据库中存储的信息作为补充数据可以增强评估过程,有助于确定响应的相关性。
Spring AI 项目目前提供了一些非常基本的示例,说明如何以提示词的形式评估响应以包含在 JUnit 测试中。
入门
本节提供如何开始使用 Spring AI 的起点。
您应该根据需要执行以下每个部分中的步骤。
Spring CLI
Spring CLI简化了直接从终端创建新应用程序的过程。对于熟悉 JavaScript 生态系统的人来说,Spring CLI 提供了spring boot new创建基于 Spring 的项目的命令,就像“create-react-app”命令一样。Spring CLI 还提供将外部代码库集成到当前项目中的功能,以及许多其他生产力功能。
| 重要的是要理解“Spring CLI”是一个与“Spring Boot CLI”不同的项目,每个项目都有自己的一套功能。 | |
|---|---|
要开始创建 Spring AI 应用程序,请按照以下步骤操作:
下载最新的Spring CLI 版本 并按照安装说明进行操作。
要创建一个基于 OpenAI 的简单应用程序,请使用以下命令:
spring boot new --from ai --name myai查阅生成的
README.md文件以获取有关获取 OpenAI API 密钥和运行您的第一个 AI 应用程序的指导。
目前,Spring CLI 仅支持 Maven 项目。
要将相同的简单 AI 应用程序添加到现有的Maven 项目,请执行:
spring boot add ai Spring CLI 允许用户定义自己的项目目录,定义可以创建哪些项目或将其添加到现有代码库中。
Spring 初始化
前往start.spring.io并选择您想要在新应用程序中使用的 AI 模型和矢量存储。
添加里程碑和快照存储库
如果您希望手动添加依赖项片段,请按照以下部分中的说明进行操作。
要使用 Milestone 和 Snapshot 版本,您需要在构建文件中添加对 Spring Milestone 和/或 Snapshot 存储库的引用。
对于 Maven,根据需要添加以下存储库定义:
<repositories> <repository> <id>spring-milestones</id> <name>Spring Milestones</name> <url>https://repo.spring.io/milestone</url> <snapshots> <enabled>false</enabled> </snapshots> </repository> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </repository> </repositories> 对于 Gradle,根据需要添加以下存储库定义:
repositories { mavenCentral() maven { url 'https://repo.spring.io/milestone' } maven { url 'https://repo.spring.io/snapshot' } } 依赖管理
Spring AI 物料清单 (BOM) 声明了给定 Spring AI 版本使用的所有依赖项的推荐版本。使用应用程序构建脚本中的 BOM 可避免您自己指定和维护依赖项版本。相反,您使用的 BOM 版本决定了使用的依赖项版本。它还确保您默认使用受支持和经过测试的依赖项版本,除非您选择覆盖它们。
如果你是 Maven 用户,可以通过将以下内容添加到 pom.xml 文件来使用 BOM -
<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.0.0-SNAPSHOT</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> Gradle 用户还可以通过利用 Gradle (5.0+) 原生支持使用 Maven BOM 声明依赖约束来使用 Spring AI BOM。这是通过向 Gradle 构建脚本的依赖项部分添加“平台”依赖项处理程序方法来实现的。如下面的代码片段所示,随后可以对您想要使用的一个或多个 spring-ai 模块(例如 spring-ai-openai)进行无版本的 Starter Dependencies 声明。
dependencies { implementation platform("org.springframework.ai:spring-ai-bom:1.0.0-SNAPSHOT") // Replace the following with the starter dependencies of specific modules you wish to use implementation 'org.springframework.ai:spring-ai-openai' } 添加特定组件的依赖项
文档中的以下每个部分都显示了您需要添加到项目构建系统中的依赖项。
嵌入模型
聊天模型
- Chat Completion API
- OpenAI Chat Completion (流和函数调用支持)
- Microsoft Azure Open AI Chat Completion (流式传输和函数调用支持)
- Ollama Chat Completion
- Hugging Face Chat Completion (不支持流媒体)
- Google Vertex AI PaLM2 Chat Completion (不支持流媒体)
- Google Vertex AI Gemini Chat Completion (流媒体、多模式和函数调用支持)
- Amazon Bedrock
- MistralAI Chat Completion (流媒体和函数调用支持)
图像生成模型
音频模型
矢量数据库
- Vector Database API
- Azure Vector Search - The Azure vector store.
- ChromaVectorStore - The Chroma vector store.
- MilvusVectorStore - The Milvus vector store.
- Neo4jVectorStore - The Neo4j vector store.
- PgVectorStore - The PostgreSQL/PGVector vector store.
- PineconeVectorStore - PineCone vector store.
- QdrantVectorStore - Qdrant vector store.
- RedisVectorStore - The Redis vector store.
- WeaviateVectorStore - The Weaviate vector store.
- SimpleVectorStore - A simple (in-memory) implementation of persistent vector storage, good for educational purposes.
示例项目
OpenAI
Azure OpenAI
Spring AI API
介绍
Spring AI API 涵盖了广泛的功能。每个主要功能在其专门的部分中都有详细介绍。为了提供概述,以下是可用的关键功能:
AI 模型 API
Model API`可跨 AI 提供商移植,适用于`Chat`、`Text to Image`、`Audio Transcription`、`Text to Speech`和`Embedding`模型。支持`synchronous`和API 选项。还支持下拉以访问特定于模型的功能。`stream 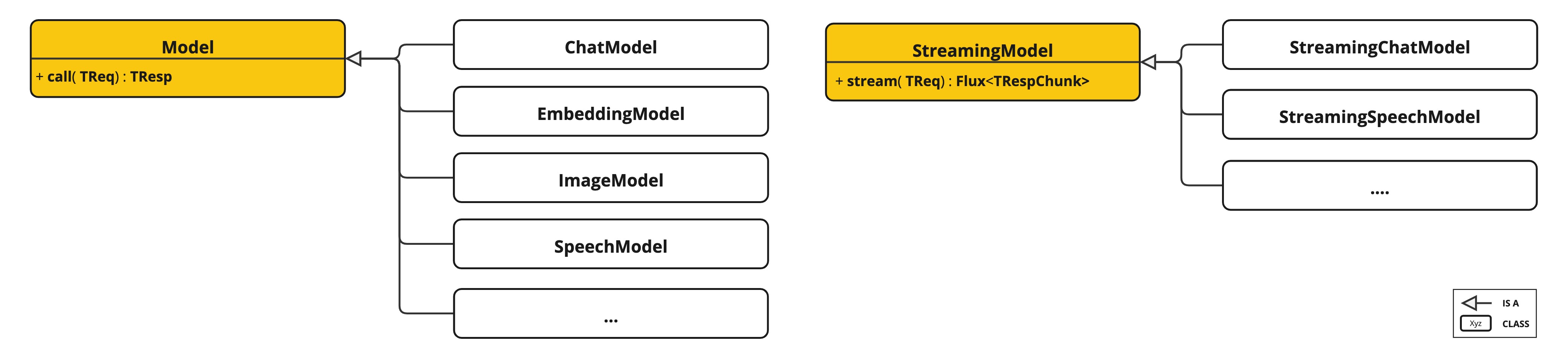
支持 OpenAI、微软、亚马逊、谷歌、亚马逊 Bedrock、Hugging Face 等公司的 AI 模型。
矢量存储 API
可跨多个提供商移植Vector Store API,包括也可移植的小说SQL-like metadata filter API。支持 14 个矢量数据库。
函数调用 API
Function calling。Spring AI 使得 AI 模型可以轻松调用您的 POJOjava.util.Function对象。
查看 Spring AI函数调用文档。
自动配置
用于 AI 模型和向量存储的 Spring Boot 自动配置和启动器。
ETL数据工程
数据工程的 ETL 框架。这为将数据加载到矢量数据库提供了基础,有助于实现检索增强生成模式,使您能够将数据带入 AI 模型以纳入其响应中。

聊天客户端 API
它ChatClient提供了与 AI 模型进行通信的流畅 API。它支持同步和反应式编程模型。
Fluent API 具有构建Prompt组成部分的方法,Prompt 将作为输入传递给 AI 模型。其中Prompt包含指导 AI 模型输出和行为的说明性文本。从 API 的角度来看,提示词由一组消息组成。
AI 模型处理两种主要类型的消息:用户消息(来自用户的直接输入)和系统消息(由系统生成以引导对话)。
这些消息通常包含占位符,这些占位符在运行时根据用户输入进行替换,以定制 AI 模型对用户输入的响应。
还可以指定提示词选项,例如要使用的 AI 模型的名称和控制生成输出的随机性或创造性的温度设置。
创建 ChatClient
使用对象ChatClient创建ChatClient.Builder。您可以ChatClient.Builder为任何ChatModel Spring Boot 自动配置获取一个自动配置实例,也可以通过编程创建一个。
使用自动配置的 ChatClient.Builder
在最简单的用例中,Spring AI 提供 Spring Boot 自动配置,ChatClient.Builder为您创建一个原型 bean 以注入到您的类中。这是一个检索对简单用户请求的字符串响应的简单示例。
@RestController class MyController { private final ChatClient chatClient; public MyController(ChatClient.Builder chatClientBuilder) { this.chatClient = chatClientBuilder.build(); } @GetMapping("/ai") String generation(String userInput) { return this.chatClient.prompt() .user(userInput) .call() .content(); } } 在这个简单的示例中,用户输入设置了用户消息的内容。call 方法向 AI 模型发送请求,content 方法以字符串形式返回 AI 模型的响应。
以编程方式创建 ChatClient
您可以ChatClient.Builder通过设置属性来禁用自动配置spring.ai.chat.client.enabled=false。如果多个聊天模型一起使用,这很有用。然后以编程方式ChatClient.Builder为每个聊天模型创建一个实例ChatModel:
ChatModel myChatModel = ... // usually autowired ChatClient.Builder builder = ChatClient.builder(myChatModel); // or create a ChatClient with the default builder settings: ChatClient chatClient = ChatClient.create(myChatModel); 聊天客户端响应
ChatClient API 提供了多种方法来格式化来自 AI 模型的响应。
返回 ChatResponse
AI 模型的响应是一种由ChatResponse类型定义的丰富结构。它包含有关如何生成响应的元数据,还可以包含多个响应(称为Generation),每个响应都有自己的元数据。元数据包括用于创建响应的令牌数量(每个令牌大约为一个单词的 3/4)。此信息很重要,因为托管 AI 模型根据每个请求使用的令牌数量收费。
ChatResponse下面显示了通过调用chatResponse()该方法返回包含元数据的对象的示例call()。
ChatResponse chatResponse = chatClient.prompt() .user("Tell me a joke") .call() .chatResponse(); 返回实体
您经常希望返回从返回的映射而来的实体类String。该entity方法提供了此功能。
例如,给定 Java 记录:
record ActorFilms(String actor, List<String> movies) { } 您可以使用该方法轻松地将 AI 模型的输出映射到此记录entity,如下所示:
ActorFilms actorFilms = chatClient.prompt() .user("Generate the filmography for a random actor.") .call() .entity(ActorFilms.class); 还有一种entity带有签名的重载方法entity(ParameterizedTypeReference<T> type),可让您指定通用列表等类型:
List<ActorFilms> actorFilms = chatClient.prompt() .user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.") .call() .entity(new ParameterizedTypeReference<List<ActorsFilms>>() { }); 流式响应
让stream您获得异步响应,如下所示
Flux<String> output = chatClient.prompt() .user("Tell me a joke") .stream() .content(); 您还可以ChatResponse使用该方法进行流式传输Flux<ChatResponse> chatResponse()。
在 1.0.0 M2 中,我们将提供一种便捷方法,让您使用反应式stream()方法返回 Java 实体。同时,您应该使用结构化输出转换器明确转换聚合响应,如下所示。这也演示了流畅 API 中参数的使用,本文档后面的部分将对此进行更详细的讨论。
var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<List<ActorsFilms>>() { }); Flux<String> flux = this.chatClient.prompt() .user(u -> u.text(""" Generate the filmography for a random actor. {format} """) .param("format", converter.getFormat())) .stream() .content(); String content = flux.collectList().block().stream().collect(Collectors.joining()); List<ActorFilms> actorFilms = converter.convert(content); call() 返回值
指定call方法后,ChatClient响应类型有几种不同的选项。
String content():返回响应的字符串内容ChatResponse chatResponse():返回ChatResponse包含多个代以及有关响应的元数据的对象,例如使用了多少个令牌来创建响应。entity返回 Java 类型- entity(ParameterizedTypeReference type):用于返回实体类型的集合。
- entity(Class type): 用于返回特定的实体类型。
- entity(StructuredOutputConverter structuredOutputConverter): 用于指定一个实例,
StructuredOutputConverter将一个实例转换String为实体类型。
您还可以调用该stream方法而call不是
stream() 返回值
在指定stream方法后ChatClient,响应类型有几个选项:
Flux<String> content():返回由AI模型生成的字符串的Flux。Flux<ChatResponse> chatResponse():返回对象的 FluxChatResponse,其中包含有关响应的附加元数据。
使用默认值
在@Configuration类中创建带有默认系统文本的ChatClient简化了运行时代码。通过设置默认值,您只需要在调用ChatClient时指定用户文本,从而消除了在运行时代码路径中为每个请求设置系统文本的需要。
默认系统文本
在以下示例中,我们将配置系统文本以始终以海盗的声音回复。为了避免在运行时代码中重复系统文本,我们将ChatClient在类中创建一个实例@Configuration。
@Configuration class Config { @Bean ChatClient chatClient(ChatClient.Builder builder) { return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a Pirate") .build(); } } 并@RestController调用它
@RestController class AIController { private final ChatClient chatClient; AIController(ChatClient chatClient) { this.chatClient = chatClient; } @GetMapping("/ai/simple") public Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) { return Map.of("completion", chatClient.prompt().user(message).call().content()); } } 通过 curl 调用它
❯ curl localhost:8080/ai/simple {"generation":"Why did the pirate go to the comedy club? To hear some arrr-rated jokes! Arrr, matey!"} 带参数的默认系统文本
在下面的例子中,我们将使用系统文本中的占位符来指定在运行时而不是设计时完成的语音。
@Configuration class Config { @Bean ChatClient chatClient(ChatClient.Builder builder) { return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}") .build(); } } @RestController class AIController { private final ChatClient chatClient AIController(ChatClient chatClient) { this.chatClient = chatClient; } @GetMapping("/ai") Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message, String voice) { return Map.of( "completion", chatClient.prompt() .system(sp -> sp.param("voice", voice)) .user(message) .call() .content()); } } 答案是
http localhost:8080/ai voice=='Robert DeNiro' { "completion": "You talkin' to me? Okay, here's a joke for ya: Why couldn't the bicycle stand up by itself? Because it was two tired! Classic, right?" } 其他默认设置
在ChatClient.Builder级别上,您可以指定默认提示词。
defaultOptions(ChatOptions chatOptions):传入ChatOptions类中定义的可移植选项或特定于模型的选项(例如 中的选项)OpenAiChatOptions。有关特定于模型的ChatOptions实现的更多信息,请参阅 JavaDocs。defaultFunction(String name, String description, java.util.function.Function<I, O> function):name用于在用户文本中引用该函数。description解释该函数的用途并帮助 AI 模型选择正确的函数以获得准确的响应。参数function是模型将在必要时执行的 Java 函数实例。defaultFunctions(String… functionNames):应用程序上下文中定义的 java.util.Function 的 bean 名称。defaultUser(String text)、、defaultUser(Resource text):defaultUser(Consumer<UserSpec> userSpecConsumer)这些方法允许您定义用户文本。Consumer<UserSpec>允许您使用 lambda 指定用户文本和任何默认参数。defaultAdvisors(RequestResponseAdvisor… advisor):顾问允许修改用于创建的数据Prompt。该实现通过在提示词中附加与用户文本相关的上下文信息来QuestionAnswerAdvisor实现模式。Retrieval Augmented GenerationdefaultAdvisors(Consumer<AdvisorSpec> advisorSpecConsumer):此方法允许您定义一个Consumer以使用配置多个顾问AdvisorSpec。顾问可以修改用于创建最终的数据Prompt。Consumer<AdvisorSpec>允许您指定 lambda 来添加顾问,例如QuestionAnswerAdvisor,它Retrieval Augmented Generation通过根据用户文本附加带有相关上下文信息的提示词来支持。
您可以在运行时使用不带前缀的相应方法覆盖这些默认值default。
options(ChatOptions chatOptions)function(String name, String description, java.util.function.Function<I, O> function)- `函数(字符串… 函数名称)
user(String text),,user(Resource text)``user(Consumer<UserSpec> userSpecConsumer)advisors(RequestResponseAdvisor… advisor)advisors(Consumer<AdvisorSpec> advisorSpecConsumer)
提示
使用用户文本调用 AI 模型时的一个常见模式是使用上下文数据附加或扩充提示词。
这些上下文数据可以是不同类型的。常见类型包括:
- 您自己的数据:这是 AI 模型尚未训练过的数据。即使模型已经看到过类似的数据,附加的上下文数据也会优先生成响应。
- 对话历史记录:聊天模型的 API 是无状态的。如果您告诉 AI 模型您的姓名,它不会在后续交互中记住它。每次请求都必须发送对话历史记录,以确保在生成响应时考虑到之前的交互。
检索增强生成
向量数据库存储的是 AI 模型不知道的数据。当用户问题被发送到 AI 模型时,它会在QuestionAnswerAdvisor向量数据库中查询与用户问题相关的文档。
来自向量数据库的响应被附加到用户文本中,为 AI 模型生成响应提供上下文。
假设您已将数据加载到中VectorStore,则可以通过向提供实例来执行检索增强生成 (RAG QuestionAnswerAdvisor) ChatClient。
ChatResponse response = ChatClient.builder(chatModel) .build().prompt() .advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults())) .user(userText) .call() .chatResponse(); 在这个例子中,SearchRequest.defaults()将对 Vector 数据库中的所有文档执行相似性搜索。为了限制要搜索的文档类型,采用SearchRequest了可移植到所有数据库中的类似 SQL 的筛选表达式VectorStores。
Chat Memory
该接口ChatMemory表示聊天对话历史记录的存储。它提供向对话添加消息、从对话中检索消息以及清除对话历史记录的方法。
有一种实现InMemoryChatMemory可以为聊天对话历史记录提供内存存储。
两个顾问实现都使用ChatMemory接口来向提示词提供对话历史记录,它们在如何将记忆添加到提示词的细节上有所不同
MessageChatMemoryAdvisor:内存被检索作为消息集合添加到提示词中PromptChatMemoryAdvisor:内存被检索并添加到提示词的系统文本中。VectorStoreChatMemoryAdvisor:构造函数“VectorStoreChatMemoryAdvisor(VectorStore vectorStore, String defaultConversationId, int chatHistoryWindowSize)”允许您指定要从中检索聊天历史记录的 VectorStore、唯一的对话 ID、要检索的聊天历史记录的大小(以令牌大小为单位)。
@Service下面是一个使用多个顾问的示例实现
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY; import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY; @Service public class CustomerSupportAssistant { private final ChatClient chatClient; public CustomerSupportAssistant(ChatClient.Builder builder, VectorStore vectorStore, ChatMemory chatMemory) { this.chatClient = builder .defaultSystem(""" You are a customer chat support agent of an airline named "Funnair".", Respond in a friendly, helpful, and joyful manner. Before providing information about a booking or cancelling a booking, you MUST always get the following information from the user: booking number, customer first name and last name. Before changing a booking you MUST ensure it is permitted by the terms. If there is a charge for the change, you MUST ask the user to consent before proceeding. """) .defaultAdvisors( new PromptChatMemoryAdvisor(chatMemory), // new MessageChatMemoryAdvisor(chatMemory), // CHAT MEMORY new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()), new LoggingAdvisor()) // RAG .defaultFunctions("getBookingDetails", "changeBooking", "cancelBooking") // FUNCTION CALLING .build(); } public Flux<String> chat(String chatId, String userMessageContent) { return this.chatClient.prompt() .user(userMessageContent) .advisors(a -> a .param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId) .param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)) .stream().content(); } } 聊天模型 API
聊天模型 API 让开发人员能够将 AI 支持的聊天完成功能集成到他们的应用程序中。它利用预先训练的语言模型(例如 GPT(生成式预训练 Transformer))以自然语言生成对用户输入的类似人类的响应。
API 的工作原理通常是向 AI 模型发送提示词或部分对话,然后 AI 模型根据其训练数据和对自然语言模式的理解生成完整或延续的对话。完整的响应随后返回到应用程序,应用程序可以将其呈现给用户或用于进一步处理。
旨在Spring AI Chat Model API成为一个简单且可移植的接口,用于与各种AI 模型进行交互,允许开发人员以最少的代码更改在不同的模型之间切换。这种设计符合 Spring 的模块化和可互换性理念。
此外,借助Prompt用于输入封装和ChatResponse输出处理的配套类,聊天模型 API 统一了与 AI 模型的通信。它管理请求准备和响应解析的复杂性,提供直接且简化的 API 交互。
API 概述
本节提供了 Spring AI 聊天模型 API 接口和相关类的指南。
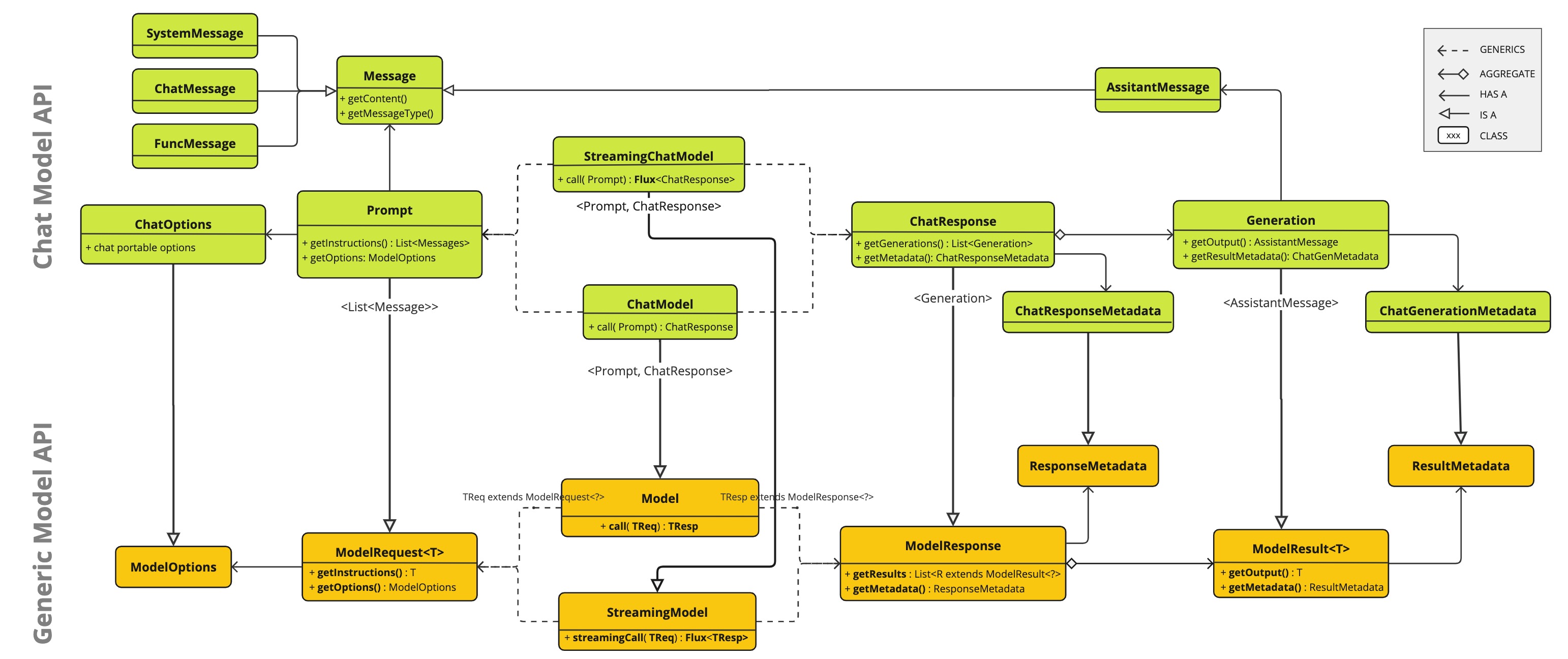
ChatModel
以下是ChatModel接口定义:
public interface ChatModel extends Model<Prompt, ChatResponse> { default String call(String message) {// implementation omitted } @Override ChatResponse call(Prompt prompt); } call`带参数的方法简化了初始使用,避免了更复杂的和类`String`的复杂性。在实际应用中,更常见的是使用接受实例并返回的方法。`Prompt``ChatResponse``call``Prompt``ChatResponse StreamingChatModel
以下是StreamingChatModel接口定义:
public interface StreamingChatModel extends StreamingModel<Prompt, ChatResponse> { @Override Flux<ChatResponse> stream(Prompt prompt); } 该stream方法接受Prompt类似的请求,ChatModel但它使用反应式 Flux API 来流式传输响应。
Prompt
Prompt封装了一系列Message对象和可选的模型请求选项。以下列表显示了 Prompt 类的截断版本,不包括构造函数和其他实用方法:ModelRequest
public class Prompt implements ModelRequest<List<Message>> { private final List<Message> messages; private ChatOptions modelOptions; @Override public ChatOptions getOptions() {..} @Override public List<Message> getInstructions() {...} // constructors and utility methods omitted } Message
该Message接口封装了文本消息、属性集合( )Map和分类( )MessageType。该接口定义如下:
public interface Message extends Node<String> { String getContent(); List<Media> getMedia(); MessageType getMessageType(); } Node 接口是
public interface Node<T> { T getContent(); Map<String, Object> getMetadata(); } 该Message接口有多种实现,与 AI 模型可以处理的消息类别相对应。某些模型(如 OpenAI 的聊天完成端点)根据对话角色区分消息类别,这些角色由 有效映射MessageType。
例如,OpenAI 可以识别不同对话角色的消息类别,如system、或。user``function``assistant
虽然该术语MessageType可能暗示特定的消息格式,但在这种情况下,它实际上指定了消息在对话中所扮演的角色。
对于不使用特定角色的 AI 模型,UserMessage实现充当标准类别,通常表示用户生成的查询或指令。要了解实际应用以及Prompt和之间的关系,特别是在这些角色或消息类别的上下文中,请参阅提示词Message部分中的详细解释。
ChatOptions
表示可以传递给 AI 模型的选项。该类ChatOptions是的子类ModelOptions,用于定义可以传递给 AI 模型的一些可移植选项。该类ChatOptions定义如下:
public interface ChatOptions extends ModelOptions { Float getTemperature(); void setTemperature(Float temperature); Float getTopP(); void setTopP(Float topP); Integer getTopK(); void setTopK(Integer topK); } 此外,每个特定于模型的 ChatModel/StreamingChatModel 实现都可以有自己的选项,这些选项可以传递给 AI 模型。例如,OpenAI Chat Completion 模型有自己的选项,如、presencePenalty等。frequencyPenalty``bestOf
这是一个强大的功能,允许开发人员在启动应用程序时使用特定于模型的选项,然后在运行时使用提示词请求覆盖它们:
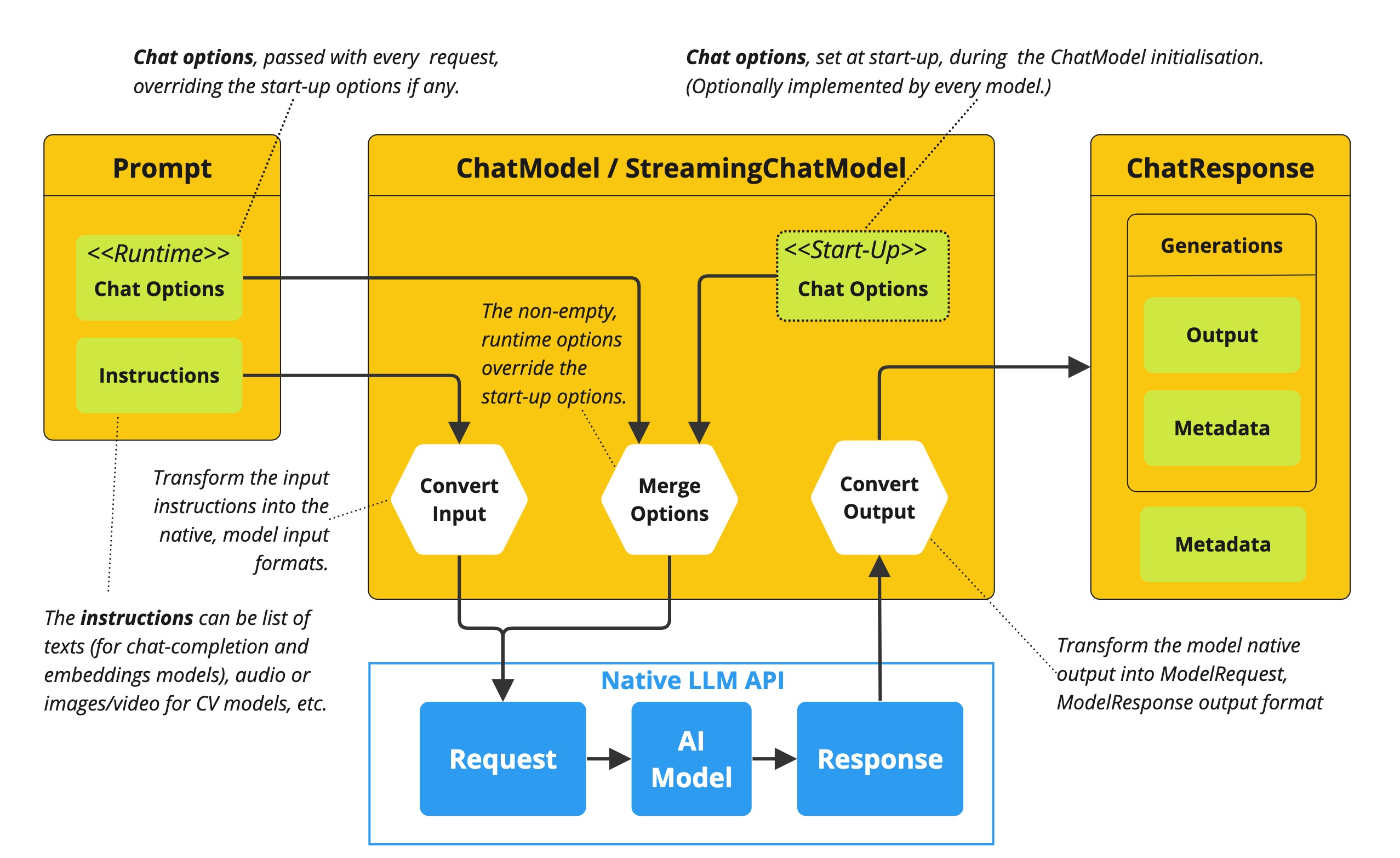
ChatResponse
该类的结构ChatResponse如下:
public class ChatResponse implements ModelResponse<Generation> { private final ChatResponseMetadata chatResponseMetadata; private final List<Generation> generations; @Override public ChatResponseMetadata getMetadata() {...} @Override public List<Generation> getResults() {...} // other methods omitted } ChatResponse类保存 AI 模型的输出,每个Generation实例包含单个提示词产生的多个潜在输出之一。
该ChatResponse类别还携带ChatResponseMetadata有关 AI 模型响应的元数据。
Generation
最后,Generation类从 扩展而来,ModelResult表示关于此结果的输出助手消息响应和相关元数据:
public class Generation implements ModelResult<AssistantMessage> { private AssistantMessage assistantMessage; private ChatGenerationMetadata chatGenerationMetadata; @Override public AssistantMessage getOutput() {...} @Override public ChatGenerationMetadata getMetadata() {...} // other methods omitted } 实现案例
为以下模型提供程序提供了和ChatModel实现:StreamingChatModel
- OpenAI Chat Completion (streaming & function-calling support)
- Microsoft Azure Open AI Chat Completion (streaming & function-calling support)
- Ollama Chat Completion
- Hugging Face Chat Completion (no streaming support)
- Google Vertex AI PaLM2 Chat Completion (no streaming support)
- Google Vertex AI Gemini Chat Completion (streaming, multi-modality & function-calling support)
- Amazon Bedrock
- Mistral AI Chat Completion (streaming & function-calling support)
- Anthropic Chat Completion (streaming)
聊天模型 API
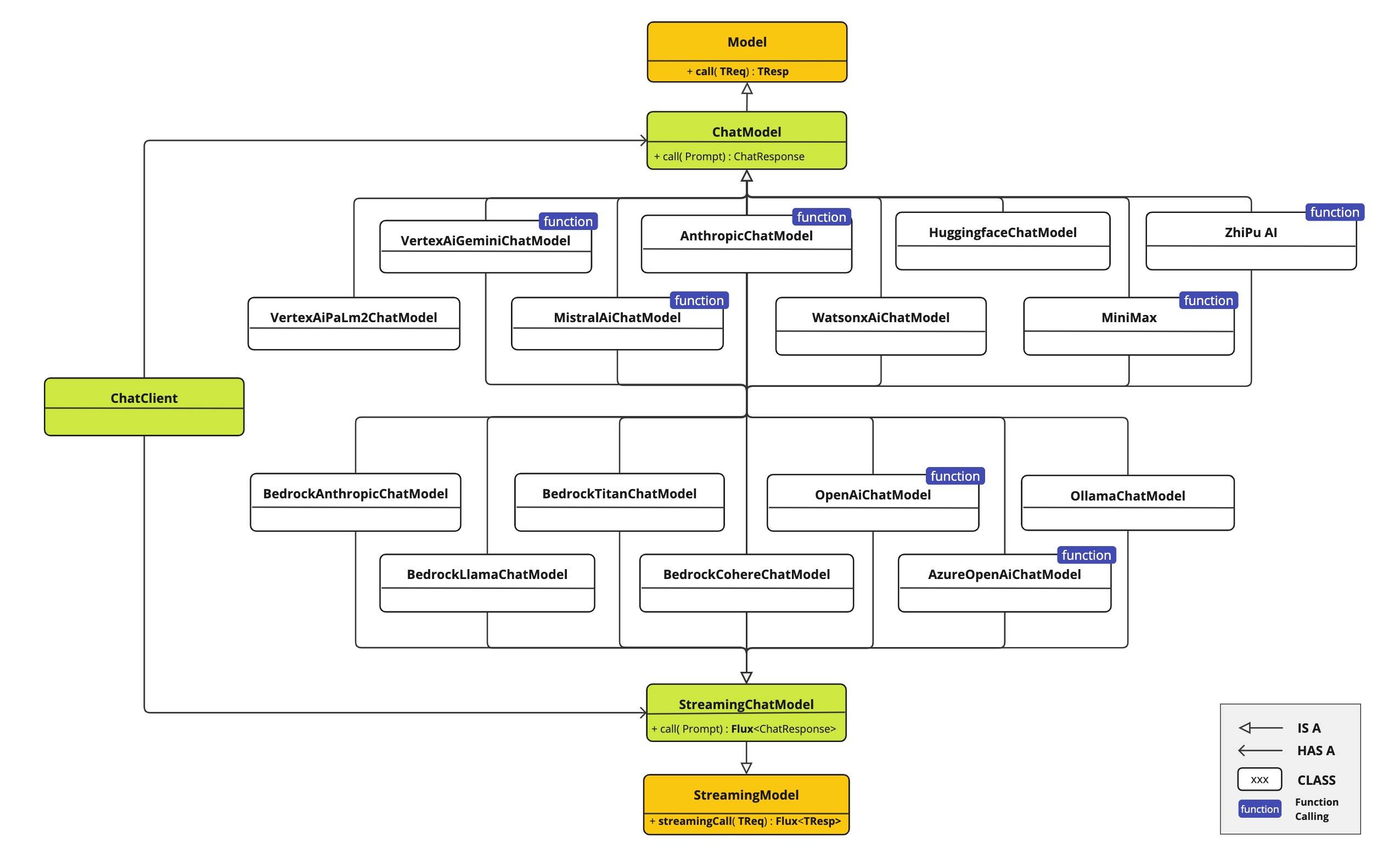
Spring AI 聊天模型 API 建立在 Spring AI 之上,Generic Model API提供特定于聊天的抽象和实现。以下类图说明了 Spring AI 聊天模型 API 的主要类和接口。
OpenAI 聊天
Spring AI 支持 OpenAI 的 AI 语言模型 ChatGPT。ChatGPT 凭借其创建业界领先的文本生成模型和嵌入,在激发人们对 AI 驱动的文本生成的兴趣方面发挥了重要作用。
先决条件
您需要使用 OpenAI 创建 API 来访问 ChatGPT 模型。在OpenAI 注册页面创建一个帐户,并在API 密钥页面生成令牌。Spring AI 项目定义了一个名为的配置属性spring.ai.openai.api-key,您应该将其设置为从 openai.com 获取的值API Key。导出环境变量是设置该配置属性的一种方法:
export SPRING_AI_OPENAI_API_KEY=<INSERT KEY HERE> 添加存储库和 BOM
Spring AI 工件已发布在 Spring Milestone 和 Snapshot 存储库中。请参阅存储库部分以将这些存储库添加到您的构建系统中。
为了帮助进行依赖项管理,Spring AI 提供了 BOM(物料清单),以确保在整个项目中使用一致版本的 Spring AI。请参阅依赖项管理部分,将 Spring AI BOM 添加到您的构建系统中。
自动配置
Spring AI 为 OpenAI Chat Client 提供 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter' } 依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
聊天属性
重试属性
该前缀spring.ai.retry用作属性前缀,可让您配置 OpenAI 聊天模型的重试机制。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.retry.max-attempts | 最大重试次数。 | 10 |
| spring.ai.retry.backoff.initial-interval | 指数退避策略的初始睡眠持续时间。 | 2 sec. |
| spring.ai.retry.backoff.multiplier | 退避间隔乘数。 | 5 |
| spring.ai.retry.backoff.max-interval | 最大退避持续时间。 | 3 min. |
| spring.ai.retry.on-client-errors | 如果为 false,则抛出 NonTransientAiException,并且不要尝试重试4xx客户端错误代码 | false |
| spring.ai.retry.exclude-on-http-codes | 不应触发重试的 HTTP 状态代码列表(例如抛出 NonTransientAiException)。 | empty |
| spring.ai.retry.on-http-codes | 应触发重试的 HTTP 状态代码列表(例如抛出 TransientAiException)。 | empty |
连接属性
该前缀spring.ai.openai用作允许您连接到 OpenAI 的属性前缀。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.base-url | 要连接的 URL | api.openai.com |
| spring.ai.openai.api-key | API 密钥 | - |
配置属性
前缀spring.ai.openai.chat是允许您为 OpenAI 配置聊天模型实现的属性前缀。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.chat.enabled | 启用 OpenAI 聊天模型。 | true |
| spring.ai.openai.chat.base-url | 可选覆盖 spring.ai.openai.base-url 以提供聊天特定的 url | - |
| spring.ai.openai.chat.api-key | 可选覆盖 spring.ai.openai.api-key 以提供聊天特定的 api-key | - |
| spring.ai.openai.chat.options.model | 这是要使用的OpenAI Chat 模型。gpt-4o,,,,,,,,,,。有关更多信息gpt-4-turbo,请参阅模型页面gpt-4-turbo-2024-04-09。gpt-4-0125-preview``gpt-4-turbo-preview``gpt-4-vision-preview``gpt-4-32k``gpt-3.5-turbo``gpt-3.5-turbo-0125``gpt-3.5-turbo-1106 | gpt-3.5-turbo |
| spring.ai.openai.chat.options.temperature | 用来控制生成的完成的表观创造性的采样温度。较高的值将使输出更加随机,而较低的值将使结果更加集中和确定。不建议修改同一完成请求的温度和 top_p,因为这两个设置的相互作用很难预测。 | 0.8 |
| spring.ai.openai.chat.options.frequencyPenalty | -2.0 到 2.0 之间的数字。正值会根据新标记在文本中出现的频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。 | 0.0f |
| spring.ai.openai.chat.options.logitBias | 修改指定标记在完成中出现的可能性。 | - |
| spring.ai.openai.chat.options.maxTokens | 聊天完成中要生成的最大标记数。输入标记和生成的标记的总长度受模型的上下文长度限制。 | - |
| spring.ai.openai.chat.options.n | 为每个输入消息生成多少个聊天完成选项。请注意,您将根据所有选项中生成的令牌数量付费。将 n 保持为 1 以最小化成本。 | 1 |
| spring.ai.openai.chat.options.presencePenalty | -2.0 到 2.0 之间的数字。正值会根据新标记是否出现在文本中来惩罚新标记,从而增加模型讨论新主题的可能性。 | - |
| spring.ai.openai.chat.options.responseFormat | 指定模型必须输出的格式的对象。设置为{ "type": "json_object" }启用 JSON 模式,可确保模型生成的消息是有效的 JSON。 | - |
| spring.ai.openai.chat.options.seed | 此功能处于测试阶段。如果指定,我们的系统将尽最大努力进行确定性采样,以便使用相同种子和参数的重复请求应返回相同的结果。 | - |
| spring.ai.openai.chat.options.stop | 最多 4 个序列,API 将停止生成进一步的令牌。 | - |
| spring.ai.openai.chat.options.topP | 温度采样的替代方法是核采样,其中模型考虑具有 top_p 概率质量的标记的结果。因此 0.1 表示仅考虑包含前 10% 概率质量的标记。我们通常建议更改此值或温度,但不能同时更改两者。 | - |
| spring.ai.openai.chat.options.tools | 模型可调用的工具列表。目前,仅支持将函数用作工具。使用此列表提供模型可为其生成 JSON 输入的函数列表。 | - |
| spring.ai.openai.chat.options.toolChoice | 控制模型调用哪个函数(如果有)。none 表示模型不会调用函数,而是生成一条消息。auto 表示模型可以在生成消息或调用函数之间进行选择。通过 {"type: “function”, “function”: {“name”: “my_function”}} 指定特定函数会强制模型调用该函数。当没有函数时,none 是默认值。如果存在函数,则 auto 是默认值。 | - |
| spring.ai.openai.chat.options.user | 代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。 | - |
| spring.ai.openai.chat.options.functions | 函数列表,按其名称标识,用于在单个提示词请求中启用函数调用。具有这些名称的函数必须存在于 functionCallbacks 注册表中。 | - |
您可以覆盖和实现的通用 和spring.ai.openai.base-url。如果设置了和属性,则它们优先于通用属性。如果您想对不同的模型和不同的模型端点使用不同的 OpenAI 帐户,这将非常有用。 spring.ai.openai.api-key``ChatModel``EmbeddingModel``spring.ai.openai.chat.base-url``spring.ai.openai.chat.api-key
通过在调用中添加请求特定的运行时选项,spring.ai.openai.chat.options可以在运行时覆盖 所有以 为前缀的属性。 Prompt
运行时选项
OpenAiChatOptions.java提供模型配置,例如要使用的模型、温度、频率惩罚等。
在启动时,可以使用OpenAiChatModel(api, options)构造函数或spring.ai.openai.chat.options.*属性配置默认选项。
在运行时,您可以通过向调用添加新的、特定于请求的选项来覆盖默认选项Prompt。例如,要覆盖特定请求的默认模型和温度:
ChatResponse response = chatModel.call( new Prompt( "Generate the names of 5 famous pirates.", OpenAiChatOptions.builder() .withModel("gpt-4-32k") .withTemperature(0.4) .build() )); 除了模型特定的OpenAiChatOptions之外,您还可以使用通过ChatOptionsBuilder#builder()创建的可移植ChatOptions实例。
函数调用
您可以使用 OpenAiChatModel 注册自定义 Java 函数,并让 OpenAI 模型智能地选择输出包含参数的 JSON 对象以调用一个或多个已注册函数。这是一种将 LLM 功能与外部工具和 API 连接起来的强大技术。阅读有关OpenAI 函数调用的更多信息。
多模态
多模态是指模型能够同时理解和处理来自各种来源的信息,包括文本、图像、音频和其他数据格式。目前,OpenAIgpt-4-visual-preview和模型提供多模态支持。有关更多信息,gpt-4o请参阅Vision指南。
OpenAI用户消息 API可以将 base64 编码的图像或图像 URL 列表与消息合并。Spring AI 的消息接口通过引入媒体类型来促进多模式 AI 模型。此类型包含有关消息中媒体附件的数据和详细信息,利用 Spring 的org.springframework.util.MimeType和java.lang.Object原始媒体数据。
下面是摘录自OpenAiChatModelIT.java的代码示例,说明了如何使用该模型将用户文本与图像融合GPT_4_VISION_PREVIEW。
byte[] imageData = new ClassPathResource("/multimodal.test.png").getContentAsByteArray(); var userMessage = new UserMessage("Explain what do you see on this picture?", List.of(new Media(MimeTypeUtils.IMAGE_PNG, imageData))); ChatResponse response = chatModel.call(new Prompt(List.of(userMessage), OpenAiChatOptions.builder().withModel(OpenAiApi.ChatModel.GPT_4_VISION_PREVIEW.getValue()).build())); 或者使用模型等效的图像 URL GPT_4_O:
var userMessage = new UserMessage("Explain what do you see on this picture?", List.of(new Media(MimeTypeUtils.IMAGE_PNG, "https://docs.spring.io/spring-ai/reference/1.0-SNAPSHOT/_images/multimodal.test.png"))); ChatResponse response = chatModel.call(new Prompt(List.of(userMessage), OpenAiChatOptions.builder().withModel(OpenAiApi.ChatModel.GPT_4_O.getValue()).build())); 您也可以传递多幅图像。
它将图像作为输入multimodal.test.png:

以及文本消息“解释一下你在图片上看到了什么?”,并生成如下响应:
这是一张设计简单的水果碗图片。碗由金属制成,边缘有弯曲的金属丝, 创造一个开放的结构,让水果从各个角度都可见。碗内有两个 黄色的香蕉放在看起来像是红苹果的东西上面。香蕉有点熟了,因为 果皮上有棕色斑点,表明该属植物是野生的。碗的顶部有一个金属环,可能用作把手 便于携带。碗放在平坦的表面上,背景为中性色,可以提供清晰的 查看水果内部。 Sample Controller
创建一个新的 Spring Boot 项目并将其添加spring-ai-openai-spring-boot-starter到您的 pom(或 gradle)依赖项中。
在目录下添加一个application.properties文件src/main/resources,以启用和配置 OpenAi 聊天模型:
spring.ai.openai.api-key=YOUR_API_KEY spring.ai.openai.chat.options.model=gpt-3.5-turbo spring.ai.openai.chat.options.temperature=0.7 将api-key替换成你的OpenAI凭证
这将创建一个OpenAiChatModel可以注入到类中的实现。下面是一个@Controller使用聊天模型进行文本生成的简单类的示例。
@RestController public class ChatController { private final OpenAiChatModel chatModel; @Autowired public ChatController(OpenAiChatModel chatModel) { this.chatModel = chatModel; } @GetMapping("/ai/generate") public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) { return Map.of("generation", chatModel.call(message)); } @GetMapping("/ai/generateStream") public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) { Prompt prompt = new Prompt(new UserMessage(message)); return chatModel.stream(prompt); } } 手动配置
OpenAiChatModel实现了并ChatModel使用StreamingChatModelLow -level OpenAiApi Client连接到 OpenAI 服务。
将spring-ai-openai依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
接下来,创建一个OpenAiChatModel并使用它进行文本生成:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY")); var openAiChatOptions = OpenAiChatOptions.builder() .withModel("gpt-3.5-turbo") .withTemperature(0.4) .withMaxTokens(200) .build(); var chatModel = new OpenAiChatModel(openAiApi, openAiChatOptions) ChatResponse response = chatModel.call( new Prompt("Generate the names of 5 famous pirates.")); // Or with streaming responses Flux<ChatResponse> response = chatModel.stream( new Prompt("Generate the names of 5 famous pirates.")); 提供OpenAiChatOptions聊天请求的配置信息。OpenAiChatOptions.Builder是流畅的选项生成器。
Low-level OpenAiApi Client
OpenAiApi为 OpenAI Chat API OpenAI Chat API提供了轻量级 Java 客户端。
下面的类图说明了OpenAiApi聊天接口和构建块:
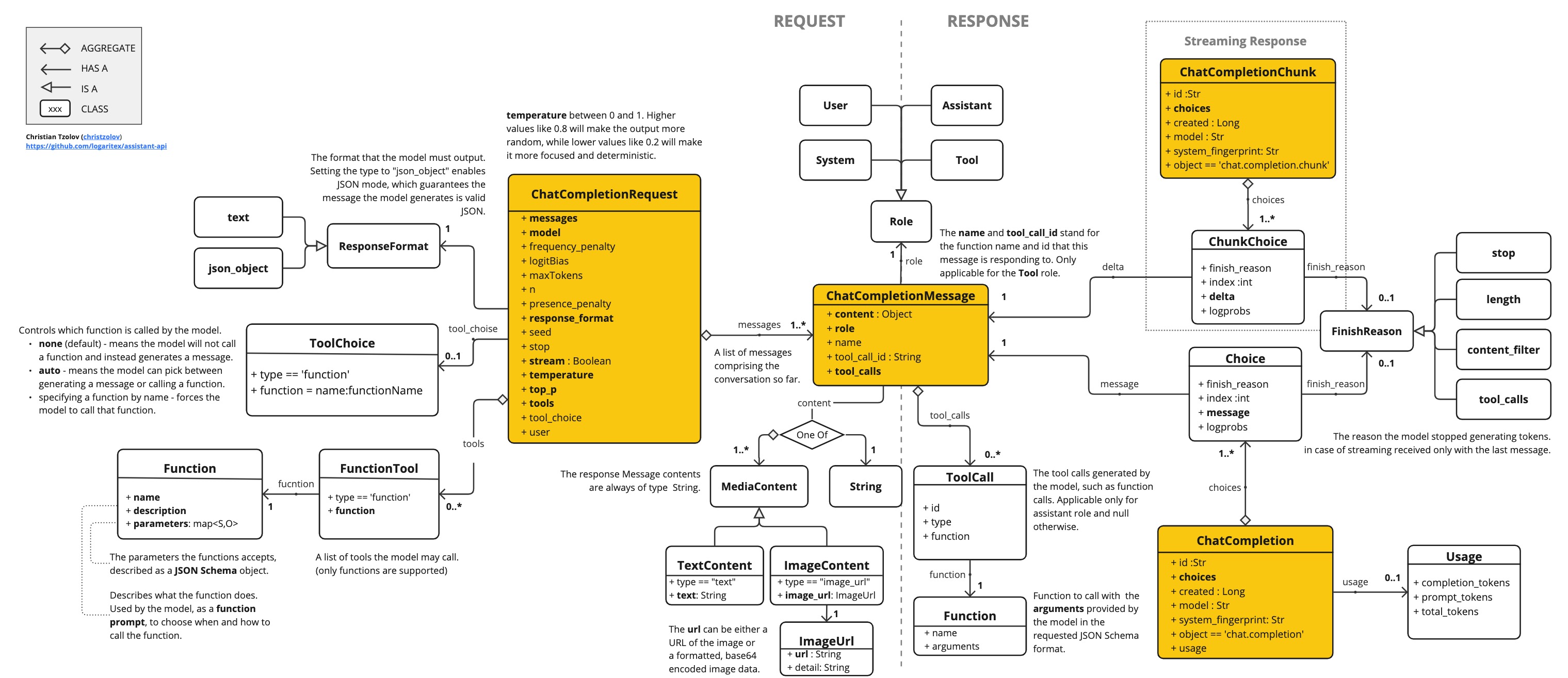
以下是以编程方式使用 API 的简单代码片段:
OpenAiApi openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY")); ChatCompletionMessage chatCompletionMessage = new ChatCompletionMessage("Hello world", Role.USER); // Sync request ResponseEntity<ChatCompletion> response = openAiApi.chatCompletionEntity( new ChatCompletionRequest(List.of(chatCompletionMessage), "gpt-3.5-turbo", 0.8f, false)); // Streaming request Flux<ChatCompletionChunk> streamResponse = openAiApi.chatCompletionStream( new ChatCompletionRequest(List.of(chatCompletionMessage), "gpt-3.5-turbo", 0.8f, true)); 请关注OpenAiApi.java的 JavaDoc 以获取更多信息。
Low-level API Examples
- OpenAiApiIT.java测试提供了一些如何使用轻量级库的一般示例。
- OpenAiApiToolFunctionCallIT.java测试展示了如何使用低级 API 调用工具函数。基于OpenAI 函数调用教程。
嵌入模型 API
该EmbeddingModel接口旨在直接与人工智能和机器学习中的嵌入模型集成。其主要功能是将文本转换为数字向量,通常称为嵌入。这些嵌入对于语义分析和文本分类等各种任务至关重要。
EmbeddingModel 接口的设计围绕两个主要目标:
- 可移植性:此接口确保轻松适应各种嵌入模型。它允许开发人员以最少的代码更改在不同的嵌入技术或模型之间切换。此设计符合 Spring 的模块化和可互换性理念。
- 简单性:EmbeddingModel 简化了将文本转换为嵌入的过程。通过提供
embed(String text)和等简单方法embed(Document document),它消除了处理原始文本数据和嵌入算法的复杂性。这种设计选择使开发人员(尤其是 AI 新手)更容易在其应用程序中使用嵌入,而无需深入研究底层机制。
API 概述
嵌入模型 API 建立在通用Spring AI 模型 API之上,后者是 Spring AI 库的一部分。因此,EmbeddingModel 接口扩展了该Model接口,该接口提供了一组用于与 AI 模型交互的标准方法。EmbeddingRequest和EmbeddingResponse类扩展自ModelRequest和ModelResponse,分别用于封装嵌入模型的输入和输出。
反过来,嵌入 API 被更高级别的组件用来实现特定嵌入模型的嵌入客户端,例如 OpenAI、Titan、Azure OpenAI、Ollie 等。
下图说明了嵌入 API 及其与 Spring AI 模型 API 和嵌入客户端的关系:
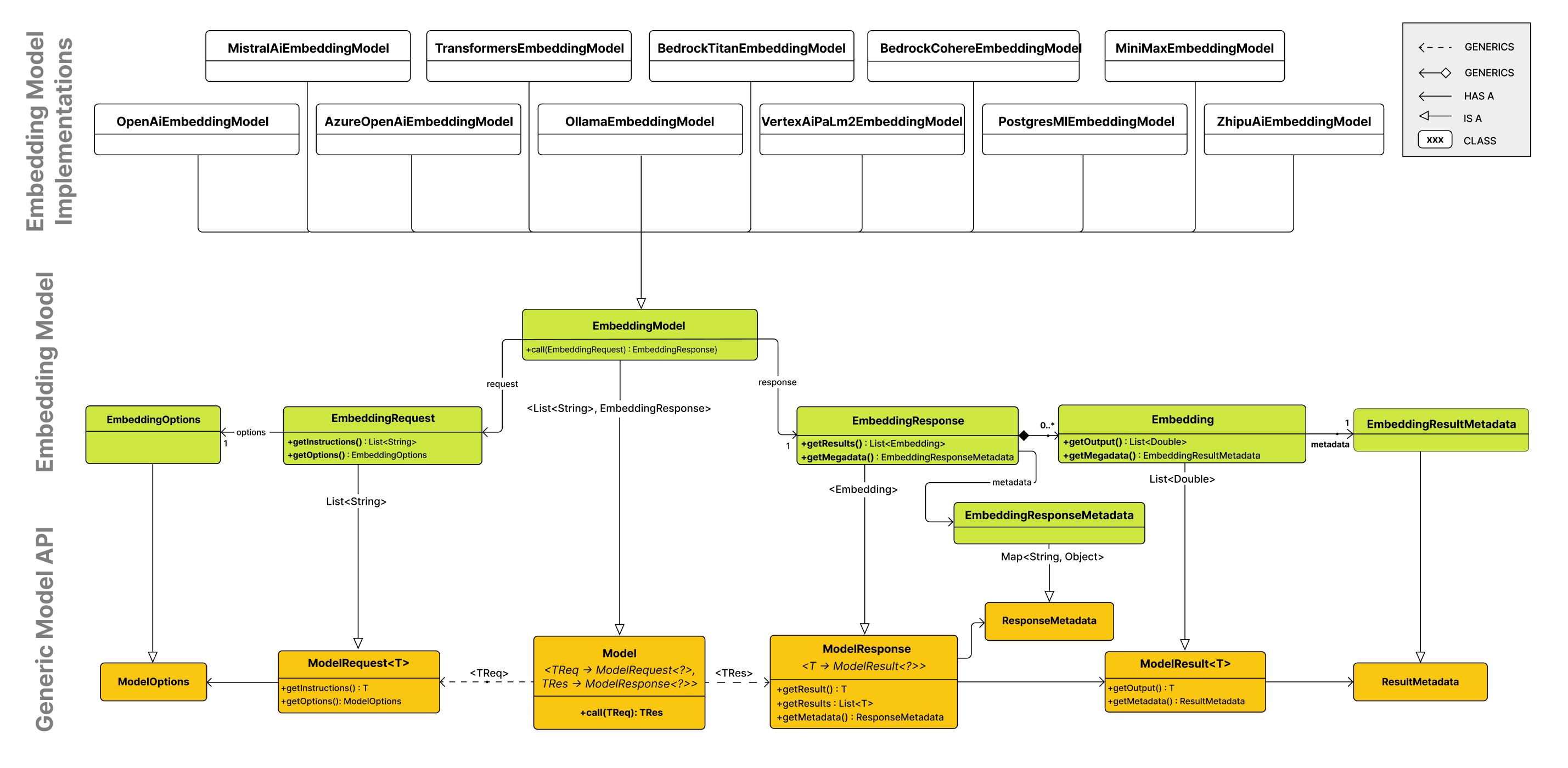
EmbeddingModel
EmbeddingModel本节提供了接口和相关类的指南。
public interface EmbeddingModel extends Model<EmbeddingRequest, EmbeddingResponse> { @Override EmbeddingResponse call(EmbeddingRequest request); /** * Embeds the given document's content into a vector. * @param document the document to embed. * @return the embedded vector. */ List<Double> embed(Document document); /** * Embeds the given text into a vector. * @param text the text to embed. * @return the embedded vector. */ default List<Double> embed(String text) { Assert.notNull(text, "Text must not be null"); return this.embed(List.of(text)).iterator().next(); } /** * Embeds a batch of texts into vectors. * @param texts list of texts to embed. * @return list of list of embedded vectors. */ default List<List<Double>> embed(List<String> texts) { Assert.notNull(texts, "Texts must not be null"); return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY)) .getResults() .stream() .map(Embedding::getOutput) .toList(); } /** * Embeds a batch of texts into vectors and returns the {@link EmbeddingResponse}. * @param texts list of texts to embed. * @return the embedding response. */ default EmbeddingResponse embedForResponse(List<String> texts) { Assert.notNull(texts, "Texts must not be null"); return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY)); } /** * @return the number of dimensions of the embedded vectors. It is generative * specific. */ default int dimensions() { return embed("Test String").size(); } } 嵌入方法提供了将文本转换为嵌入、容纳单个字符串、结构化Document对象或文本批次的各种选项。
为嵌入文本提供了多种快捷方法,包括方法embed(String text),该方法接受单个字符串并返回相应的嵌入向量。所有快捷方式都是围绕该call方法实现的,该方法是调用嵌入模型的主要方法。
通常,嵌入会返回双精度列表,以数值向量格式表示嵌入。
该embedForResponse方法提供了更全面的输出,可能包括有关嵌入的附加信息。
维度方法是帮助开发人员快速确定嵌入向量大小的便捷工具,这对于理解嵌入空间和后续处理步骤非常重要。
EmbeddingRequest
是EmbeddingRequest一个ModelRequest采用文本对象列表和可选嵌入请求选项的函数。以下列表显示了 EmbeddingRequest 类的截断版本,不包括构造函数和其他实用方法:
public class EmbeddingRequest implements ModelRequest<List<String>> { private final List<String> inputs; private final EmbeddingOptions options; // other methods omitted } EmbeddingResponse
该类的结构EmbeddingResponse如下:
public class EmbeddingResponse implements ModelResponse<Embedding> { private List<Embedding> embeddings; private EmbeddingResponseMetadata metadata = new EmbeddingResponseMetadata(); // other methods omitted } 该类EmbeddingResponse保存 AI 模型的输出,每个Embedding实例包含来自单个文本输入的结果向量数据。
该EmbeddingResponse类别还携带EmbeddingResponseMetadata有关 AI 模型响应的元数据。
Embedding
代表Embedding单个嵌入向量。
public class Embedding implements ModelResult<List<Double>> { private List<Double> embedding; private Integer index; private EmbeddingResultMetadata metadata; // other methods omitted } 实现案例
内部,各种EmbeddingModel实现使用不同的低级库和 API 来执行嵌入任务。以下是一些可用的实现EmbeddingModel:
- Spring AI OpenAI Embeddings
- Spring AI Azure OpenAI Embeddings
- Spring AI Ollama Embeddings
- Spring AI Transformers (ONNX) Embeddings
- Spring AI PostgresML Embeddings
- Spring AI Bedrock Cohere Embeddings
- Spring AI Bedrock Titan Embeddings
- Spring AI VertexAI PaLM2 Embeddings
- Spring AI Mistral AI Embeddings
OpenAI 嵌入
Spring AI 支持 OpenAI 的文本嵌入模型。OpenAI 的文本嵌入可以测量文本字符串的相关性。嵌入是浮点数的向量(列表)。两个向量之间的距离可以测量它们的相关性。距离越小,相关性越高;距离越大,相关性越低。
先决条件
您需要使用 OpenAI 创建一个 API 来访问 OpenAI 嵌入模型。
在OpenAI 注册页面创建一个帐户,并在API 密钥页面生成令牌。Spring AI 项目定义了一个名为的配置属性spring.ai.openai.api-key,您应该将其设置为从 openai.com 获取的值API Key。导出环境变量是设置该配置属性的一种方法:
export SPRING_AI_OPENAI_API_KEY=<INSERT KEY HERE> 添加存储库和 BOM
Spring AI 工件已发布在 Spring Milestone 和 Snapshot 存储库中。请参阅存储库部分以将这些存储库添加到您的构建系统中。
为了帮助进行依赖项管理,Spring AI 提供了 BOM(物料清单),以确保在整个项目中使用一致版本的 Spring AI。请参阅依赖项管理部分,将 Spring AI BOM 添加到您的构建系统中。
自动配置
Spring AI 为 Azure OpenAI 嵌入客户端提供 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
嵌入属性
重试属性
该前缀spring.ai.retry用作属性前缀,可让您配置 OpenAI Embedding 客户端的重试机制。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.retry.max-attempts | 最大重试次数。 | 10 |
| spring.ai.retry.backoff.initial-interval | 指数退避策略的初始睡眠持续时间。 | 2 sec. |
| spring.ai.retry.backoff.multiplier | 退避间隔乘数。 | 5 |
| spring.ai.retry.backoff.max-interval | 最大退避持续时间。 | 3 min. |
| spring.ai.retry.on-client-errors | 如果为 false,则抛出 NonTransientAiException,并且不要尝试重试4xx客户端错误代码 | false |
| spring.ai.retry.exclude-on-http-codes | 不应触发重试的 HTTP 状态代码列表(例如抛出 NonTransientAiException)。 | empty |
| spring.ai.retry.on-http-codes | 应触发重试的 HTTP 状态代码列表(例如抛出 TransientAiException)。 | empty |
连接属性
该前缀spring.ai.openai用作允许您连接到 OpenAI 的属性前缀。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.base-url | 要连接的 URL | api.openai.com |
| spring.ai.openai.api-key | API 密钥 | - |
配置属性
前缀是配置OpenAI 实现的spring.ai.openai.embedding属性前缀。EmbeddingModel
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.embedding.enabled | 启用 OpenAI 嵌入模型。 | true |
| spring.ai.openai.embedding.base-url | 可选覆盖 spring.ai.openai.base-url 以提供嵌入特定 url | - |
| spring.ai.openai.embedding.api-key | 可选覆盖 spring.ai.openai.api-key 以提供嵌入特定的 api-key | - |
| spring.ai.openai.embedding.metadata-mode | 文档内容提取模式。 | EMBED |
| spring.ai.openai.embedding.options.model | 要使用的模型 | text-embedding-ada-002(其他选项:text-embedding-3-large、text-embedding-3-small) |
| spring.ai.openai.embedding.options.encodingFormat | 返回嵌入的格式。可以是浮点数或 base64。 | - |
| spring.ai.openai.embedding.options.user | 代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。 | - |
| spring.ai.openai.embedding.options.dimensions | 生成的输出嵌入应具有的维数。仅在text-embedding-3及更高版本的模型中受支持。 | - |
您可以为和实现 覆盖通用spring.ai.openai.base-url和。如果设置了和属性,则它们优先于通用属性。同样,如果设置了和属性,则它们优先于通用属性。如果您想为不同的模型和不同的模型端点使用不同的 OpenAI 帐户,这将非常有用。 spring.ai.openai.api-key``ChatModel``EmbeddingModel``spring.ai.openai.embedding.base-url``spring.ai.openai.embedding.api-key``spring.ai.openai.embedding.base-url``spring.ai.openai.embedding.api-key
通过在调用中添加请求特定的运行时选项,spring.ai.openai.embedding.options可以在运行时覆盖 所有以 为前缀的属性。 EmbeddingRequest
运行时选项
OpenAiEmbeddingOptions.java提供 OpenAI 配置,例如要使用的模型等。
spring.ai.openai.embedding.options也可以使用属性来配置默认选项。
在启动时使用OpenAiEmbeddingModel构造函数设置用于所有嵌入请求的默认选项。在运行时,您可以使用实例OpenAiEmbeddingOptions作为 的一部分来覆盖默认选项EmbeddingRequest。
例如,要覆盖特定请求的默认模型名称:
EmbeddingResponse embeddingResponse = embeddingModel.call( new EmbeddingRequest(List.of("Hello World", "World is big and salvation is near"), OpenAiEmbeddingOptions.builder() .withModel("Different-Embedding-Model-Deployment-Name") .build())); 样品控制器
这将创建一个EmbeddingModel可以注入到类中的实现。下面是一个@Controller使用该EmbeddingModel实现的简单类的示例。
spring.ai.openai.api-key=YOUR_API_KEY spring.ai.openai.embedding.options.model=text-embedding-ada-002 @RestController public class EmbeddingController { private final EmbeddingModel embeddingModel; @Autowired public EmbeddingController(EmbeddingModel embeddingModel) { this.embeddingModel = embeddingModel; } @GetMapping("/ai/embedding") public Map embed(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) { EmbeddingResponse embeddingResponse = this.embeddingModel.embedForResponse(List.of(message)); return Map.of("embedding", embeddingResponse); } } 手动配置
如果您不使用 Spring Boot,则可以手动配置 OpenAI Embedding Client。为此,将spring-ai-openai依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
依赖项spring-ai-openai还提供对的访问OpenAiChatModel。有关的更多信息,请OpenAiChatModel参阅OpenAI 聊天客户端部分。
接下来,创建一个OpenAiEmbeddingModel实例并用它来计算两个输入文本之间的相似度:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY")); var embeddingModel = new OpenAiEmbeddingModel( openAiApi, MetadataMode.EMBED, OpenAiEmbeddingOptions.builder() .withModel("text-embedding-ada-002") .withUser("user-6") .build(), RetryUtils.DEFAULT_RETRY_TEMPLATE); EmbeddingResponse embeddingResponse = embeddingModel .embedForResponse(List.of("Hello World", "World is big and salvation is near")); 提供OpenAiEmbeddingOptions嵌入请求的配置信息。选项类提供了builder()用于轻松创建选项的选项。
图像模型 API
该设计Spring Image Model API旨在成为一个简单且可移植的接口,用于与各种专门用于图像生成的AI 模型进行交互,允许开发人员以最少的代码更改在不同的与图像相关的模型之间切换。这种设计符合 Spring 的模块化和可互换性理念,确保开发人员可以快速使其应用程序适应与图像处理相关的不同 AI 功能。
ImagePrompt此外,借助输入封装和输出处理等配套类的支持ImageResponse,图像模型 API 统一了与专用于图像生成的 AI 模型的通信。它管理请求准备和响应解析的复杂性,为图像生成功能提供直接且简化的 API 交互。
Spring Image Model API 建立在 Spring AI 之上Generic Model API,提供特定于图像的抽象和实现。
API 概述
本节提供了 Spring Image Model API 接口和相关类的指南。
ImageModel
以下是ImageModel接口定义:
@FunctionalInterface public interface ImageModel extends Model<ImagePrompt, ImageResponse> { ImageResponse call(ImagePrompt request); } ImagePrompt
ImagePrompt封装了ImageMessage对象列表和可选模型请求选项。以下列表显示了该类的精简版本,不包括构造函数和其他实用方法:ModelRequest``ImagePrompt
public class ImagePrompt implements ModelRequest<List<ImageMessage>> { private final List<ImageMessage> messages; private ImageOptions imageModelOptions; @Override public List<ImageMessage> getInstructions() {...} @Override public ImageOptions getOptions() {...} // constructors and utility methods omitted } ImageMessage
该类ImageMessage封装了要使用的文本以及文本对生成图像的影响应具有的权重。对于支持权重的模型,权重可以是正的,也可以是负的。
public class ImageMessage { private String text; private Float weight; public String getText() {...} public Float getWeight() {...} // constructors and utility methods omitted } ImageOptions
表示可以传递给图像生成模型的选项。该类ImageOptions扩展了ModelOptions接口,用于定义一些可以传递给 AI 模型的可移植选项。
该类ImageOptions定义如下:
public interface ImageOptions extends ModelOptions { Integer getN(); String getModel(); Integer getWidth(); Integer getHeight(); String getResponseFormat(); // openai - url or base64 : stability ai byte[] or base64 } 此外,每个特定于模型的 ImageModel 实现都可以有自己的选项,这些选项可以传递给 AI 模型。例如,OpenAI 图像生成模型有自己的选项,如quality、style等。
这是一个强大的功能,允许开发人员在启动应用程序时使用特定于模型的选项,然后在运行时使用覆盖它们ImagePrompt。
ImageResponse
该类的结构ChatResponse如下:
public class ImageResponse implements ModelResponse<ImageGeneration> { private final ImageResponseMetadata imageResponseMetadata; private final List<ImageGeneration> imageGenerations; @Override public ImageGeneration getResult() { // get the first result } @Override public List<ImageGeneration> getResults() {...} @Override public ImageResponseMetadata getMetadata() {...} // other methods omitted } ImageResponse类保存 AI 模型的输出,每个ImageGeneration实例包含单个提示产生的多个潜在输出之一。
该ImageResponse类别还携带ImageResponseMetadata有关 AI 模型响应的元数据。
ImageGeneration
最后,ImageGeneration类从中扩展以ModelResult表示有关此结果的输出响应和相关元数据:
public class ImageGeneration implements ModelResult<Image> { private ImageGenerationMetadata imageGenerationMetadata; private Image image; @Override public Image getOutput() {...} @Override public ImageGenerationMetadata getMetadata() {...} // other methods omitted } 实现案例
ImageModel为以下模型提供程序提供了实现:
API 文档
您可以在这里找到 Javadoc 。
OpenAI 图像生成
Spring AI 支持 OpenAI 的图像生成模型 DALL-E。
先决条件
您需要使用 OpenAI 创建 API 密钥才能访问 ChatGPT 模型。在OpenAI 注册页面创建一个帐户,并在API 密钥页面生成令牌。Spring AI 项目定义了一个名为的配置属性spring.ai.openai.api-key,您应该将其设置为从 openai.com 获取的值API Key。导出环境变量是设置该配置属性的一种方法:
export SPRING_AI_OPENAI_API_KEY=<INSERT KEY HERE> 自动配置
Spring AI 为 OpenAI 图像生成客户端提供了 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
图像生成属性
前缀是允许您配置OpenAI 实现的spring.ai.openai.image属性前缀。ImageModel
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.image.enabled | 启用 OpenAI 图像模型。 | true |
| spring.ai.openai.image.base-url | 可选覆盖 spring.ai.openai.base-url 以提供聊天特定的 url | - |
| spring.ai.openai.image.api-key | 可选覆盖 spring.ai.openai.api-key 以提供聊天特定的 api-key | - |
| spring.ai.openai.image.options.n | 要生成的图像数量。必须介于 1 到 10 之间。对于 dall-e-3,仅支持 n=1。 | - |
| spring.ai.openai.image.options.model | 用于图像生成的模型。 | OpenAiImageApi.DEFAULT_IMAGE_MODEL |
| spring.ai.openai.image.options.quality | 将生成的图像的质量。高清图像具有更精细的细节和更高的图像一致性。此参数仅支持 dall-e-3。 | - |
| spring.ai.openai.image.options.response_format | 返回生成的图像的格式。必须是 URL 或 b64_json 之一。 | - |
spring.ai.openai.image.options.size | 所生成图像的大小。对于 dall-e-2,必须是 256x256、512x512 或 1024x1024 之一。对于 dall-e-3 模型,必须是 1024x1024、1792x1024 或 1024x1792 之一。 | - |
spring.ai.openai.image.options.size_width | 所生成图像的宽度。对于 dall-e-2,必须是 256、512 或 1024 之一。 | - |
spring.ai.openai.image.options.size_height | 所生成图像的高度。对于 dall-e-2,必须是 256、512 或 1024 之一。 | - |
spring.ai.openai.image.options.style | 生成图像的风格。必须是生动或自然之一。生动使模型倾向于生成超现实和戏剧性的图像。自然使模型生成更自然、不太超现实的图像。此参数仅支持 dall-e-3。 | - |
spring.ai.openai.image.options.user | 代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。 | - |
连接属性
该前缀spring.ai.openai用作允许您连接到 OpenAI 的属性前缀。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.base-url | 要连接的 URL | api.openai.com |
| spring.ai.openai.api-key | API 密钥 | - |
配置属性
重试属性
该前缀spring.ai.retry用作属性前缀,可让您配置 OpenAI Image 客户端的重试机制。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.retry.max-attempts | 最大重试次数。 | 10 |
| spring.ai.retry.backoff.initial-interval | 指数退避策略的初始睡眠持续时间。 | 2 sec. |
| spring.ai.retry.backoff.multiplier | 退避间隔乘数。 | 5 |
| spring.ai.retry.backoff.max-interval | 最大退避持续时间。 | 3 min. |
| spring.ai.retry.on-client-errors | 如果为 false,则抛出 NonTransientAiException,并且不要尝试重试4xx客户端错误代码 | false |
| spring.ai.retry.exclude-on-http-codes | 不应触发重试的 HTTP 状态代码列表(例如抛出 NonTransientAiException)。 | empty |
| spring.ai.retry.on-http-codes | 应触发重试的 HTTP 状态代码列表(例如抛出 TransientAiException)。 | empty |
运行时选项
OpenAiImageOptions.java提供模型配置,例如要使用的模型、质量、尺寸等。
启动时,可以使用OpenAiImageModel(OpenAiImageApi openAiImageApi)构造函数和withDefaultOptions(OpenAiImageOptions defaultOptions)方法配置默认选项。或者,使用spring.ai.openai.image.options.*前面描述的属性。
在运行时,您可以通过向调用添加新的、特定于请求的选项来覆盖默认选项ImagePrompt。例如,要覆盖 OpenAI 特定选项(如质量和要创建的图像数量),请使用以下代码示例:
ImageResponse response = openaiImageModel.call( new ImagePrompt("A light cream colored mini golden doodle", OpenAiImageOptions.builder() .withQuality("hd") .withN(4) .withHeight(1024) .withWidth(1024).build()) ); 除了模型特定的OpenAiImageOptions之外,您还可以使用通过ImageOptionsBuilder#builder()创建的可移植ImageOptions实例。
音频模型 API
OpenAI 转录
Spring AI 支持OpenAI 的转录模型。
先决条件
您需要使用 OpenAI 创建 API 密钥才能访问 ChatGPT 模型。在OpenAI 注册页面创建一个帐户,并在API 密钥页面生成令牌。Spring AI 项目定义了一个名为的配置属性spring.ai.openai.api-key,您应该将其设置为从 openai.com 获取的值API Key。导出环境变量是设置该配置属性的一种方法:
自动配置
Spring AI 为 OpenAI 图像生成客户端提供了 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
转录属性
该前缀spring.ai.openai.audio.transcription用作属性前缀,可让您配置 OpenAI 图像模型的重试机制。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.audio.transcription.options.model | 要使用的模型的 ID。目前只有 whisper-1(由我们的开源 Whisper V2 模型提供支持)可用。 | whisper-1 |
| spring.ai.openai.audio.transcription.options.response-format | 输出的格式,可以是以下选项之一:json、text、srt、verbose_json 或 vtt。 | json |
| spring.ai.openai.audio.transcription.options.prompt | 可选文本,用于指导模特的风格或继续之前的音频片段。提示应与音频语言相匹配。 | |
| spring.ai.openai.audio.transcription.options.language | 输入音频的语言。以 ISO-639-1 格式提供输入语言将提高准确性并减少延迟。 | |
| spring.ai.openai.audio.transcription.options.temperature | 采样温度,介于 0 和 1 之间。较高的值(如 0.8)会使输出更加随机,而较低的值(如 0.2)会使输出更加集中和确定。如果设置为 0,模型将使用对数概率自动增加温度,直到达到某些阈值。 | 0 |
| spring.ai.openai.audio.transcription.options.timestamp_granularities | 此转录要填充的时间戳粒度。response_format 必须设置为 verbose_json 才能使用时间戳粒度。支持以下任一选项或两个选项:word 或segment。注意:segment 时间戳没有额外的延迟,但生成 word 时间戳会产生额外的延迟。 | segment |
运行时选项
该类OpenAiAudioTranscriptionOptions提供转录时要使用的选项。启动时,spring.ai.openai.audio.transcription将使用指定的选项,但您可以在运行时覆盖这些选项。
例如:
OpenAiAudioApi.TranscriptResponseFormat responseFormat = OpenAiAudioApi.TranscriptResponseFormat.VTT; OpenAiAudioTranscriptionOptions transcriptionOptions = OpenAiAudioTranscriptionOptions.builder() .withLanguage("en") .withPrompt("Ask not this, but ask that") .withTemperature(0f) .withResponseFormat(responseFormat) .build(); AudioTranscriptionPrompt transcriptionRequest = new AudioTranscriptionPrompt(audioFile, transcriptionOptions); AudioTranscriptionResponse response = openAiTranscriptionModel.call(transcriptionRequest); 手动配置
将spring-ai-openai依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件。
dependencies { implementation 'org.springframework.ai:spring-ai-openai' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
接下来,创建一个OpenAiAudioTranscriptionModel
var openAiAudioApi = new OpenAiAudioApi(System.getenv("OPENAI_API_KEY")); var openAiAudioTranscriptionModel = new OpenAiAudioTranscriptionModel(openAiAudioApi); var transcriptionOptions = OpenAiAudioTranscriptionOptions.builder() .withResponseFormat(TranscriptResponseFormat.TEXT) .withTemperature(0f) .build(); var audioFile = new FileSystemResource("/path/to/your/resource/speech/jfk.flac"); AudioTranscriptionPrompt transcriptionRequest = new AudioTranscriptionPrompt(audioFile, transcriptionOptions); AudioTranscriptionResponse response = openAiTranscriptionModel.call(transcriptionRequest); 示例代码
- OpenAiTranscriptionModelIT.java测试提供了一些如何使用该库的一般示例。
OpenAI 文本转语音 (TTS) 集成
介绍
音频 API 提供了基于 OpenAI 的 TTS(文本转语音)模型的语音端点,使用户能够:
- 叙述一篇书面博客文章。
- 制作多种语言的音频。
- 使用流媒体提供实时音频输出。
先决条件
- 创建 OpenAI 帐户并获取 API 密钥。您可以在OpenAI 注册页面注册,并在API 密钥页面生成 API 密钥。
- 将依赖项添加
spring-ai-openai到项目的构建文件中。有关更多信息,请参阅依赖项管理部分。
自动配置
Spring AI 为 OpenAI 文本转语音客户端提供 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件:
dependencies { implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
TTS 属性
该前缀spring.ai.openai.audio.speech用作属性前缀,可让您配置 OpenAI 文本到语音客户端。
| 属性 | 描述 | 默认 |
|---|---|---|
| spring.ai.openai.audio.speech.options.model | 要使用的模型的 ID。目前只有 tts-1 可用。 | tts-1 |
| spring.ai.openai.audio.speech.options.voice | 用于 TTS 输出的语音。可用选项有:alloy、echo、fable、onyx、nova 和 shimmer。 | alloy |
| spring.ai.openai.audio.speech.options.response-format | 音频输出的格式。支持的格式有 mp3、opus、aac、flac、wav 和 pcm。 | mp3 |
| spring.ai.openai.audio.speech.options.speed | 语音合成的速度。可接受的范围是 0.0(最慢)到 1.0(最快)。 | 1.0 |
运行时选项
该类OpenAiAudioSpeechOptions提供发出文本转语音请求时要使用的选项。启动时,spring.ai.openai.audio.speech将使用指定的选项,但您可以在运行时覆盖这些选项。
例如:
OpenAiAudioSpeechOptions speechOptions = OpenAiAudioSpeechOptions.builder() .withModel("tts-1") .withVoice(OpenAiAudioApi.SpeechRequest.Voice.ALLOY) .withResponseFormat(OpenAiAudioApi.SpeechRequest.AudioResponseFormat.MP3) .withSpeed(1.0f) .build(); SpeechPrompt speechPrompt = new SpeechPrompt("Hello, this is a text-to-speech example.", speechOptions); SpeechResponse response = openAiAudioSpeechModel.call(speechPrompt); 手动配置
将spring-ai-openai依赖项添加到项目的 Mavenpom.xml文件中:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai</artifactId> </dependency> 或者你的 Gradlebuild.gradle构建文件:
dependencies { implementation 'org.springframework.ai:spring-ai-openai' } 请参阅依赖管理部分,将 Spring AI BOM 添加到您的构建文件中。
接下来,创建一个OpenAiAudioSpeechModel:
var openAiAudioApi = new OpenAiAudioApi(System.getenv("OPENAI_API_KEY")); var openAiAudioSpeechModel = new OpenAiAudioSpeechModel(openAiAudioApi); var speechOptions = OpenAiAudioSpeechOptions.builder() .withResponseFormat(OpenAiAudioApi.SpeechRequest.AudioResponseFormat.MP3) .withSpeed(1.0f) .withModel(OpenAiAudioApi.TtsModel.TTS_1.value) .build(); var speechPrompt = new SpeechPrompt("Hello, this is a text-to-speech example.", speechOptions); SpeechResponse response = openAiAudioSpeechModel.call(speechPrompt); // Accessing metadata (rate limit info) OpenAiAudioSpeechResponseMetadata metadata = response.getMetadata(); byte[] responseAsBytes = response.getResult().getOutput(); 流式传输实时音频
Speech API 使用块传输编码支持实时音频流。这意味着可以在生成完整文件并使其可访问之前播放音频。
var openAiAudioApi = new OpenAiAudioApi(System.getenv("OPENAI_API_KEY")); var openAiAudioSpeechModel = new OpenAiAudioSpeechModel(openAiAudioApi); OpenAiAudioSpeechOptions speechOptions = OpenAiAudioSpeechOptions.builder() .withVoice(OpenAiAudioApi.SpeechRequest.Voice.ALLOY) .withSpeed(1.0f) .withResponseFormat(OpenAiAudioApi.SpeechRequest.AudioResponseFormat.MP3) .withModel(OpenAiAudioApi.TtsModel.TTS_1.value) .build(); SpeechPrompt speechPrompt = new SpeechPrompt("Today is a wonderful day to build something people love!", speechOptions); Flux<SpeechResponse> responseStream = openAiAudioSpeechModel.stream(speechPrompt); 示例代码
- OpenAiSpeechModelIT.java测试提供了一些如何使用该库的一般示例。
