
阅读量:0
文章目录
1.锁的问题
高性能系统中使用锁,往往带来的坏处要大于好处。
并发编程中,锁带解决了安全问题,同时也带来了性能问题,因为锁让并发处理变成了串行操作,所以如无必要,尽量不要显式使用锁。
锁和并发,貌似有一种相克相生的关系。
为了避免严重的锁竞争导致性能的下降,有些场景采用了无锁化设计,特别是在底层框架上。无锁化主要有两种实现,无锁队列和无锁数据结构。
2.无锁
2.1 串行无锁
串行无锁最简单的实现方式可能就是单线程模型了,如 Redis 6.0 之前采用了这种方式。但是这种方式利用不了 CPU 多核的优势,所以在网络编程模型中,常用的是单 Reactor 多线程模型。
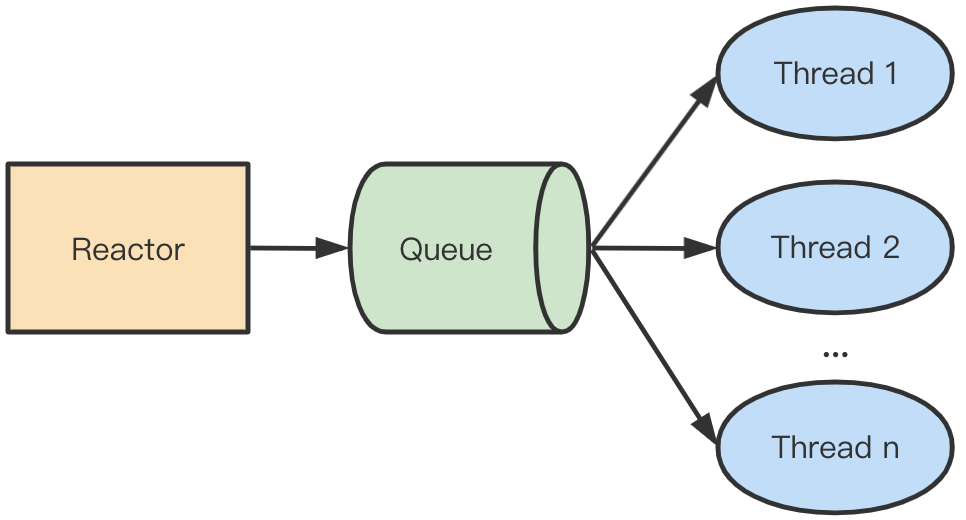
单 Reactor 多线程模型中,主线程负责处理 I/O 事件,并将读到的数据压入队列,工作线程则从队列中取出数据进行处理,多线程从队列获取数据时需要对队列加锁。如下图所示:
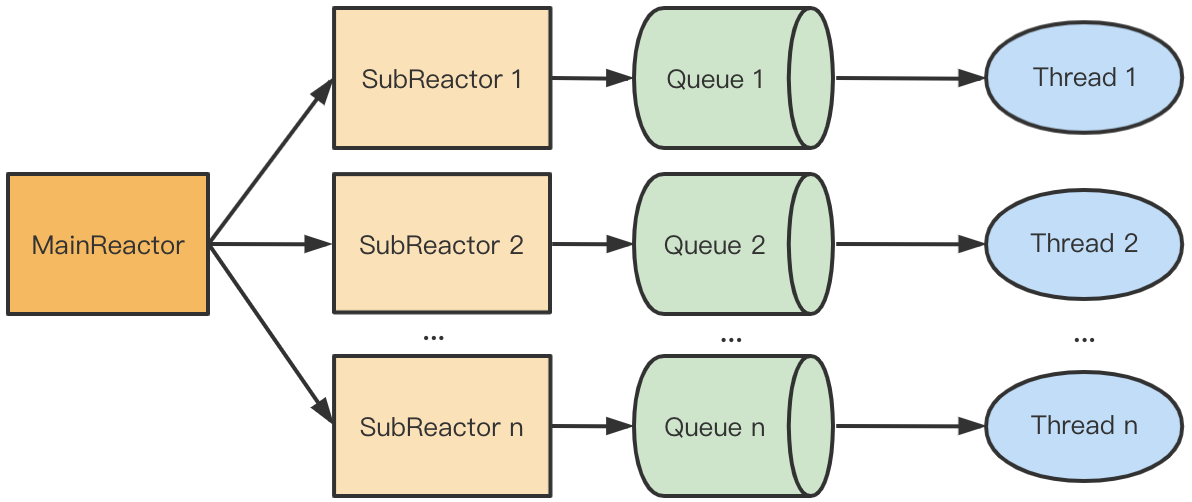
上图的模式可以改成串行无锁的形式,当 MainReactor accept 一个新连接之后从众多的 SubReactor 选取一个进行注册,通过创建一个 Queue 与 I/O 线程进行绑定,此后该连接的读写都在同一个队列和线程中执行,无需对队列加锁。这种模型叫主从 Reactor 多线程模型。
2.2 无锁数据结构
利用硬件支持的原子操作可以实现无锁的数据结构,很多语言都提供CAS原子操作(如 Go 中的 atomic 包和 C++11 中的 atomic 库),可以用于实现无锁数据结构,如无锁链表。
我们以一个简单的线程安全单链表的插入操作来看下无锁编程和普通加锁的区别。
template<typename T> struct Node { Node(const T &value) : data(value) {} T data; Node *next = nullptr; }; 有锁链表 WithLockList:
template<typename T> class WithLockList { mutex mtx; Node<T> *head; public: void pushFront(const T &value) { auto *node = new Node<T>(value); lock_guard<mutex> lock(mtx); // (1) node->next = head; head = node; } }; 无锁链表 LockFreeList:
template<typename T> class LockFreeList { atomic<Node<T> *> head; public: void pushFront(const T &value) { auto *node = new Node<T>(value); node->next = head.load(); while(!head.compare_exchange_weak(node->next, node)); // (2) } }; 从代码可以看出,在有锁版本中 (1) 进行了加锁。在无锁版本中,(2) 使用了原子 CAS 操作 compare_exchange_weak,该函数如果存储成功则返回 true,同时为了防止伪失败(即原始值等于期望值时也不一定存储成功,主要发生在缺少单条比较交换指令的硬件机器上),通常将 CAS 放在循环中。
下面对有锁和无锁版本进行简单的性能比较,分别执行 1000,000 次push操作。测试代码如下:
int main() { const int SIZE = 1000000; //有锁测试 auto start = chrono::steady_clock::now(); WithLockList<int> wlList; for(int i = 0; i < SIZE; ++i) { wlList.pushFront(i); } auto end = chrono::steady_clock::now(); chrono::duration<double, std::micro> micro = end - start; cout << "with lock list costs micro:" << micro.count() << endl; //无锁测试 start = chrono::steady_clock::now(); LockFreeList<int> lfList; for(int i = 0; i < SIZE; ++i) { lfList.pushFront(i); } end = chrono::steady_clock::now(); micro = end - start; cout << "free lock list costs micro:" << micro.count() << endl; return 0; } 三次输出如下,可以看出无锁版本有锁版本性能高一些。
with lock list costs micro:548118 free lock list costs micro:491570 with lock list costs micro:556037 free lock list costs micro:476045 with lock list costs micro:557451 free lock list costs micro:481470 3.减少锁竞争
如果加锁无法避免,则可以采用分片的形式,减少对资源加锁的次数,这样也可以提高整体的性能。
比如 Golang 优秀的本地缓存组件 bigcache 、go-cache、freecache 都实现了分片功能,每个分片一把锁,采用分片存储的方式减少加锁的次数从而提高整体性能。
以一个简单的示例,通过对map[uint64]struct{}分片前后并发写入的对比,来看下减少锁竞争带来的性能提升。
var ( num = 1000000 m0 = make(map[int]struct{}, num) mu0 = sync.RWMutex{} m1 = make(map[int]struct{}, num) mu1 = sync.RWMutex{} ) // ConWriteMapNoShard 不分片写入一个 map。 func ConWriteMapNoShard() { g := errgroup.Group{} for i := 0; i < num; i++ { g.Go(func() error { mu0.Lock() defer mu0.Unlock() m0[i] = struct{}{} return nil }) } _ = g.Wait() } // ConWriteMapTwoShard 分片写入两个 map。 func ConWriteMapTwoShard() { g := errgroup.Group{} for i := 0; i < num; i++ { g.Go(func() error { if i&1 == 0 { mu0.Lock() defer mu0.Unlock() m0[i] = struct{}{} return nil } mu1.Lock() defer mu1.Unlock() m1[i] = struct{}{} return nil }) } _ = g.Wait() } 看下二者的性能差异:
func BenchmarkConWriteMapNoShard(b *testing.B) { for i := 0; i < b.N; i++ { ConWriteMapNoShard() } } BenchmarkConWriteMapNoShard-12 3 472063245 ns/op func BenchmarkConWriteMapTwoShard(b *testing.B) { for i := 0; i < b.N; i++ { ConWriteMapTwoShard() } } BenchmarkConWriteMapTwoShard-12 4 310588155 ns/op 可以看到,通过对分共享资源的分片处理,减少了锁竞争,能明显地提高程序的并发性能。可以预见的是,随着分片粒度地变小,性能差距会越来越大。当然,分片粒度不是越小越好。因为每一个分片都要配一把锁,那么会带来很多额外的不必要的开销。可以选择一个不太大的值,在性能和花销上寻找一个平衡。
