
阅读量:5
目录
【哈夫曼树的构造及相关的分析(2012、2018、2021、2023)】
5.5.1哈夫曼树和哈夫曼编码
1.哈夫曼树的定义
在介绍哈夫曼树之前,先介绍几个相关的概念:
从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
路径上的分支数目称为路径长度。
在许多应用中,树中结点常常被赋予一个表示某种意义的数值,称为该结点的权。
从树的根到一个结点的路径长度与该结点上权值的乘积,称为该结点的带权路径长度。
树中所有叶结点的带权路径长度之和称为该树的带权路径长度,记为
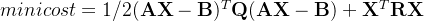
式中,wi是第i个叶结点所带的权值,li是该叶结点到根结点的路径长度。
在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树。
例如,图 5.25 中的3棵二叉树都有4个叶结点 a,b,c,d,分别带权 7,5,2,4,
它们的带权路径长度分别为
(a) WPL=7x2+5x2+2x2+4x2 =36。
(b) WPL=4x2+ 7x3+5x3+ 2x1=46。
(c) WPL=7x1+5x2+2x3+4x3=35。
其中,图 5.25(c)树的 WPL 最小。可以验证,它恰好为哈夫曼树。
2.哈夫曼树的构造
给定n个权值分别为w1,w2,…wn的结点,构造哈夫曼树的算法描述如下:
1) 将这n个结点分别作为n棵仅含一个结点的二叉树,构成森林F。
【分析哈夫曼树的路径上权值序列的合法性(2010)】
2) 构造一个新结点,从F中选取两棵根结点权值最小的树作为新结点的左、右子树,并且将新结点的权值置为左、右子树上根结点的权值之和。
3) 从F中删除刚才选出的两棵树,同时将新得到的树加入F中。
4) 重复步骤2) 和 3),直至F中只剩下一棵树为止。
【哈夫曼树的性质(2010、2019)】
从上述构造过程中可以看出哈夫曼树具有如下特点:
1) 每个初始结点最终都成为叶结点,且权值越小的结点到根结点的路径长度越大。
2) 构造过程中共新建了n-1个结点(双分支结点),因此哈夫曼树的结点总数为2n-1。
3) 每次构造都选择2棵树作为新结点的孩子,因此哈夫曼树中不存在度为1的结点。
例如,权值{7,5,2,4}的哈夫曼树的构造过程如图 5.26 所示。

3.哈夫曼编码
在数据通信中,若对每个字符用相等长度的二进制位表示,称这种编码方式为固定长度编码。若允许对不同字符用不等长的二进制位表示,则这种编码方式称为可变长度编码。
可变长度编码比固定长度编码要好得多,其特点是对频率高的字符赋以短编码,而对频率较低的字符则赋以较长一些的编码,从而可以使字符的平均编码长度减短,起到压缩数据的效果。
【根据哈夫曼编码对编码序列进行译码(2017)】
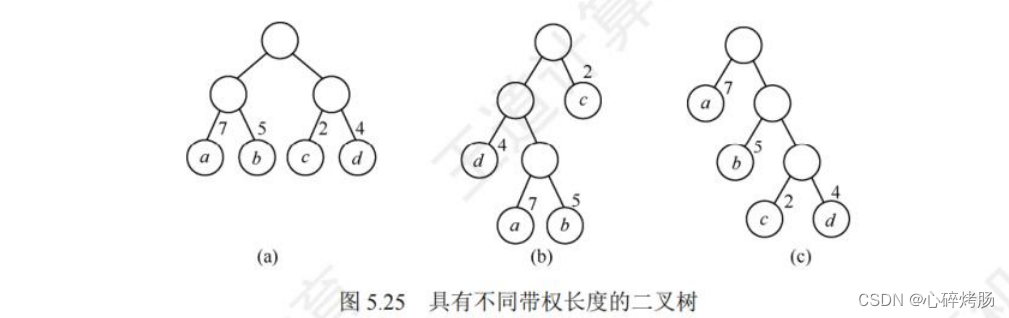
若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码。举例:设计字符A,B和 C对应的编码 0,10 和 110是前缀编码。
对前缀编码的解码很简单,因为没有一个编码是其他编码的前缀。所以识别出第一个编码,将它翻译为原字符,再对剩余的码串执行同样的解码操作。
例如,码串 0010110 可被唯一地翻译为A,A,B和C。另举反例:若再将字符D 的编码设计为 11,此时11是110的前缀,则上述码串的后三位就无法唯一翻译。
【哈夫曼树的构造及相关的分析(2012、2018、2021、2023)】
【前缀编码的分析及应用(2014、2020)】
可以利用二叉树来设计二进制前缀编码。假设为A,B,C,D四个字符设计前缀编码,可以用图 5.27 所示的二叉树来表示,4个叶结点分别表示4个字符,且约定左分支表示 0,右分支表示1,从根到叶结点的路径上用分支标记组成的序列作为该叶结点字符的编码,可以证明如此得到的必为前缀编码。
由图5.27 得到字符 A,B,C,D的前缀编码分别为 0,10,110,111。
【哈夫曼编码和定长编码的差异(2022)】
哈夫曼编码是一种非常有效的数据压缩编码。由哈夫曼树得到哈夫曼编码是很自然的过程。
首先,将每个字符当作一个独立的结点,其权值为它出现的频度(或次数),构造出对应的哈夫曼树。
然后,将从根到叶结点的路径上分支标记的字符串作为该字符的编码。
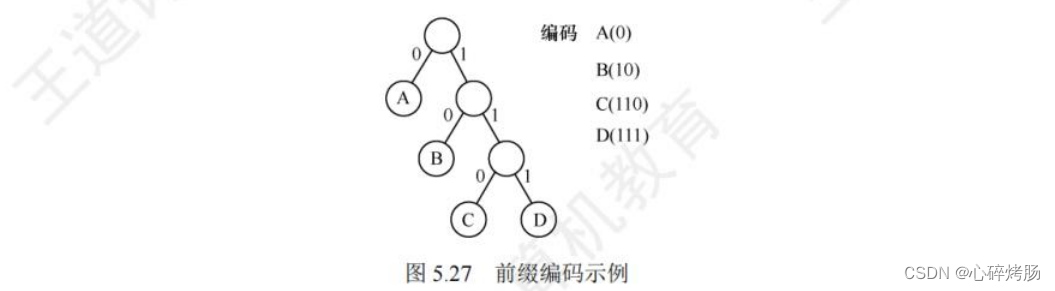
图 5.28 所示为一个由哈夫曼树构造哈夫曼编码的示例,矩形方块表示字符及其出现的次数。
这棵哈夫曼树的 WPL为
WPL=1x45+3x(13+12+16)+4x(5 +9)=224
此处的 WPL 可视为最终编码得到二进制编码的长度,共 224位。若采用3位固定长度编码,则得到的二进制编码长度为 300 位,因此哈夫曼编码共压缩了 25%的数据。
利用哈夫曼树可以设计出总长度最短的二进制前缀编码。
注意:左分支和右分支究竟是表示0还是表示1没有明确规定,因此构造出的哈夫曼树并不唯一,但各哈夫曼树的带权路径长度 WPL 相同且为最优。
此外,如有若干权值相同的结点,则构造出的哈夫曼树更可能不同,但WPL 必然相同且为最优。
5.5.2并查集(补充)
1.并查集的概念
并查集是一种简单的集合表示,它支持以下3种操作:
1) Initial(S):将集合S中的每个元素都初始化为只有一个单元素的子集合。
2) Union(S,Root1,Root2):把集合S中的子集合 Root2并入子集合 Root1。要求 Root1和 Root2 互不相交,否则不执行合并。
3) Find(S,x):查找集合S中单元素x所在的子集合,并返回该子集合的根结点。
2.并查集的存储结构
通常用树的双亲表示作为并查集的存储结构,每个子集合以一棵树表示。所有表示子集合的树,构成表示全集合的森林,存放在双亲表示数组内。
通常用数组元素的下标代表元素名,用根结点的下标代表子集合名,根结点的双亲域为负数(可设置为该子集合元素数量的相反数)。
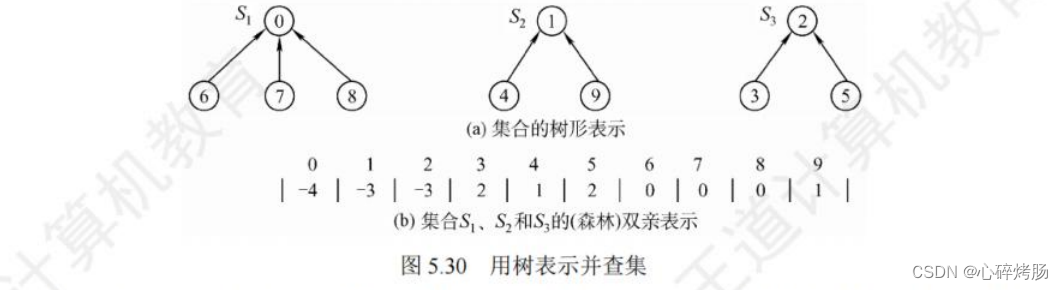
例如,若设有一个全集合为S=(0,1,2,3,4,5,6,7,8,9},初始化时每个元素自成一个单元素子集合,每个子集合的数组值为-1,如图5.29所示。

经过一段时间的计算后,这些子集合合并为3个更大的子集合,即S1=(0,6,7,8},S2={1,4,9},S3={2,3,5},此时并查集的树形和存储结构如图 5.30 所示。
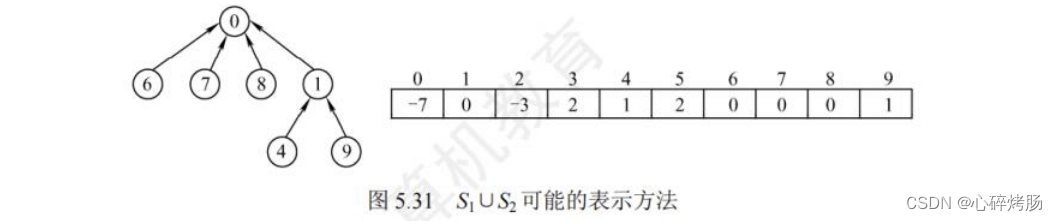
为了得到两个子集合的并,只需将其中一个子集合根结点的双亲指针指向另一个集合的根结点。因此,S1 U S2(S1并S2),可以具有如图 5.31所示的表示。
在采用树的双亲指针数组表示作为并查集的存储表示时,集合元素的编号从0到SIZE-1。其中 SIZE 是最大元素的个数。
3.并查集的基本实现
并查集的结构定义如下:
#define SIZE 100 int UFSets[SIZE]; //集合元素数组(双亲指针数组) 下面是并查集主要运算的实现。
(1) 并查集的初始化操作
void Initial(int S[]){ //S即为并查集 for(int i=0;i<SIZE;i++) //每个自成单元素集合 S[i]=-1; }(2) 并查集的 Find 操作
在并查集S中查找并返回包含元素x的树的根。
int Find(int S[],int x){ while(S[x]>=0) //循环寻找x的根 x=S [x]; return x; //根的 s[]小于 0 }判断两个元素是否属于同一集合,只需分别找到它们的根,再比较根是否相同即可。
(3) 并查集的 Union 操作
求两个不相交子集合的并集。若将两个元素所在的集合合并为一个集合,则需要先找到两个元素的根,再令一棵子集树的根指向另一棵子集树的根。
void Union(int S[],int Rootl,int Root2){ if(Root1==Root2) return; //要求 Root1与Root2 是不同的集合 S [Root2]=Root1; //将根 Root2连接到另一根 Root1下面 }Find 操作和 Union 操作的时间复杂度分别为 O(d)和 O(1),其中d为树的深度。
4.并查集实现的优化
在极端情况下,n个元素构成的集合树的深度为n,则 Find 操作的最坏时间复杂度为 O(n)。
改进的办法是:在做 Union 操作之前,首先判别子集中的成员数量,然后令成员少的根指向成员多的根,即把小树合并到大树,为此可令根结点的绝对值保存集合树中的成员数量。
(1) 改进的 Union 操作
void Union(int S[],int Rootl,int Root2){ if(Root1==Root2) return; if(S[Root2]>S[Root1]){ //Root2 结点数更少 S[Root1]+=S[Root2]; //累加集合树的结点总数 S[Root2]=Root1; //小树合并到大树 } else{ //Root1结点数更少 S[Root2]+=S[Root1]; //累加结点总数 S[Root1]=Root2; //小树合并到大树 } }采用这种方法构造得到的集合树,其深度不超过
随着子集逐对合并,集合树的深度越来越大,为了进一步减少确定元素所在集合的时间,还可进一步对上述 Find 操作进行优化,当所査元素x不在树的第二层时,在算法中增加一个“压缩路径”的功能,即将从根到元素x路径上的所有元素都变成根的孩子。
(2) 改进的 Find 操作
int Find(int S[],int x){ int root=x; while(s[root]>=0) //循环找到根 root=s[root]; while(x!=root){ //压缩路径 int t=S[x]; //t指向x的父结点 S[x]=root; //x直接挂到根结点下面 x=t; } return root; //返回根结点编号 }通过 Find 操作的“压缩路径”优化后,可使集合树的深度不超过 O(α(n)),其中 α(n)是一个增长极其缓慢的函数,对于常见的正整数 n,通常 α(n)<=4。
